Azure AI Studio の Prompt flow によるテストと評価のハンズオン第三回目では RAG の評価をしていきたいと思います。まずはシンプルなチャットフローから始めましょう。Azure AI Studio の「プロンプトフロー」メニューからプロンプトフローの「+作成」ボタンをクリックして名前を入力して作成します。

シンプルなチャットフローが表示されますので、すぐに右上の「コンピューティングセッションの開始」をクリックしてフローの実行を行う VM を稼働させます。状況によって数分かかる場合がありますので先に押しておきます。
コンピューティングセッションが実行中になったら、右上の「チャット」ボタンをクリックしてチャットペインを表示させます。ここでチャットフローのテストができます。
モデルの指定
「chat」ノードでは、LLM の実行ができます。ここでプロンプトエンジニアリングの作業を実施します。まずは必須項目として、実行する LLM を指定しなければなりません。「接続」ドロップダウンをクリックすると、すでに設定で接続に追加しておいた Azure OpenAI リソースが表示されますので、この LLM ノードに使いたいモデルを選択します。接続設定が完了しているので、ポチポチと選んでいくだけで設定が完了します。

設定が完了したら右上の「保存」ボタンをクリックします。
ここでデフォルトのプロンプトの状態で以下のテキストをチャットに打ち込んでみましょう。
花ケ咲神社って何ですか?
これは AI Challenge Day で使用した架空の世界遺産の名前なのでモデルが知る由もありません。
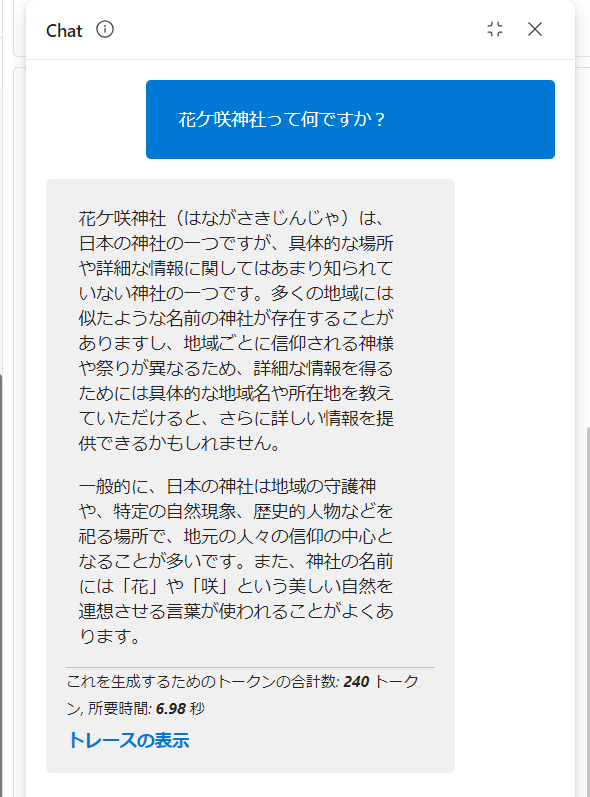
モデルの知識を最大限使って回答しようとしていますが、当然欲しい回答にはなりませんし、ハルシネーション(幻覚)を起こしてしまう場合もあります。
1. プロンプトエンジニアリング
では、デフォルトのシステムプロンプトを改良して、回答に制約を加えたいと思います。例えば以下のようなプロンプトです。
あなたは日本の歴史の教師です。提供された出典からのみ回答してください。
答えに迷うようなことがあれば、「わかりません」と答えてください。
可能な限り各文の後に「(出典:引用)」の形で引用を加えてください。

この状態で保存し、もう一度同じ質問を投げます。設定を変えたので、新しいセッションを作成(テキストボックスの左の💬+ボタン)して実行します。
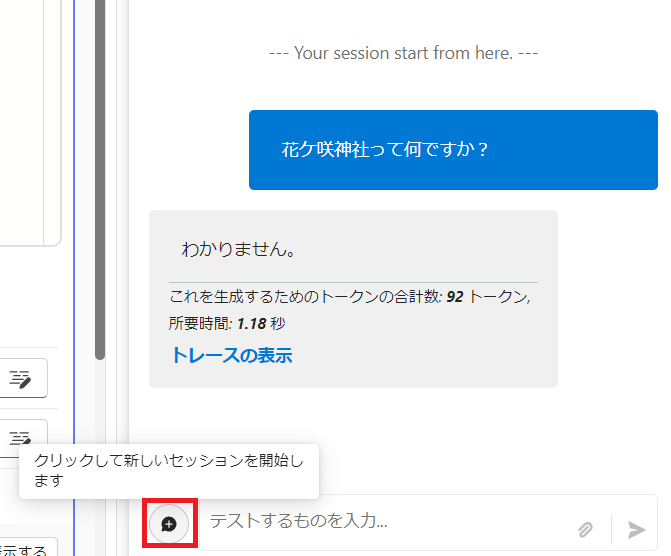
はい、ちゃんと「わかりません」と回答しましたね。
このようにしてシナリオに適したプロンプトへ改良していきます。
2. RAG
ここからは、ユーザーの質問で一旦検索インデックスを検索し、その検索結果をプロンプトに挿入する一般的な RAG の構成を作成していきます。
2.1. インデックスの作成
検索インデックスは Azure AI Studio 上で簡単に作成できます。左メニューの「インデックス」から「新しいインデックス」をクリックします。そしてデータソースから「ファイルのアップロード」を選択して RAG を行いたい社内ドキュメント等のファイルをアップロードして「次へ」をクリックします。

デフォルトの検索インデックスとして Azure AI Search が指定されており、新たに作成するインデックス名を設定します。インデックス作成(チャンク化、ベクトル化等)を行うための VM を指定する必要があります。ここは有料となりますのでご注意ください。
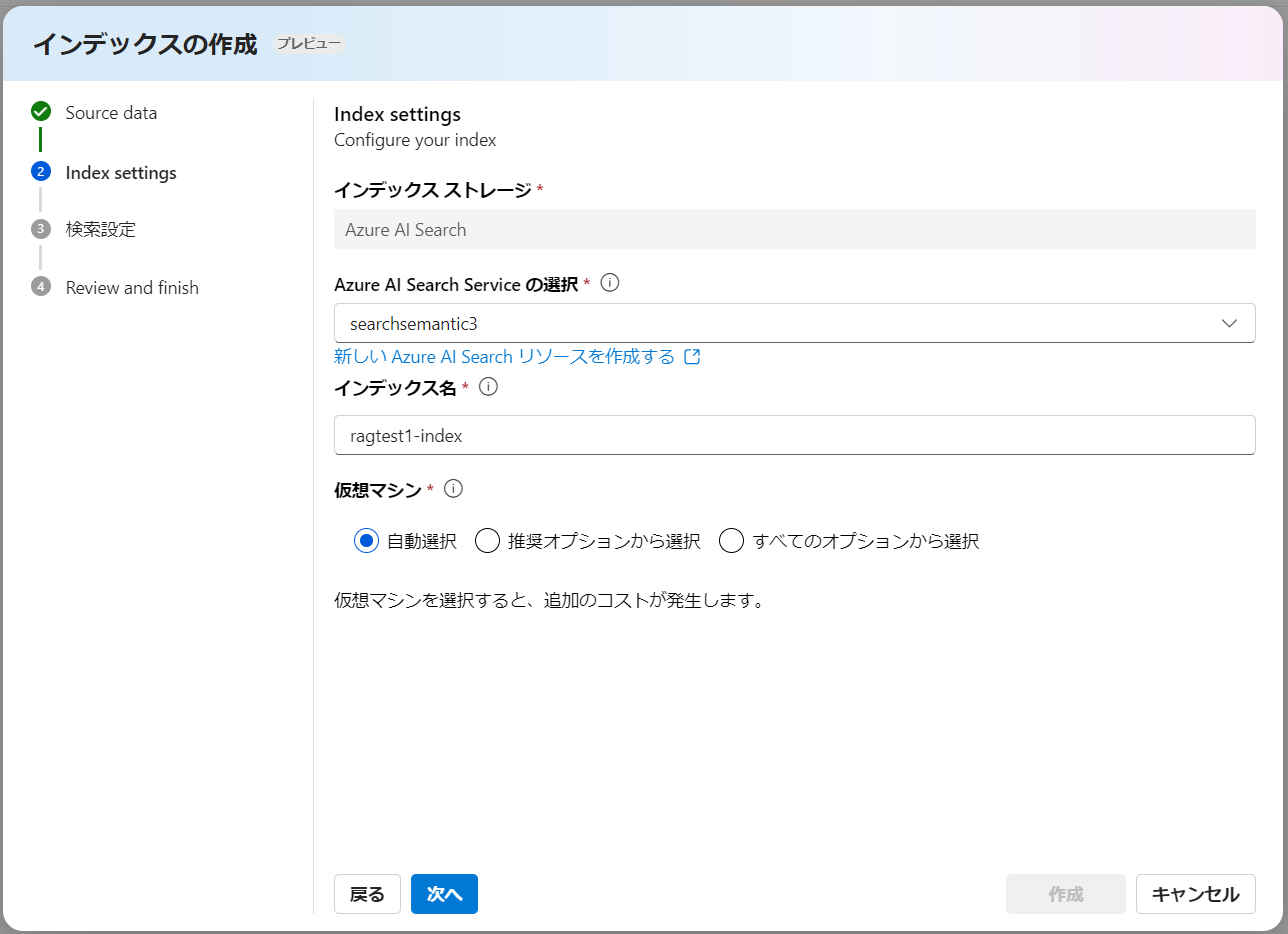
ベクトル検索を実行したい場合は以下にチェックを入れ、text-embedding-ada-002 モデルをデプロイ済みのリソースを選択します。

設定を確認して、「作成」ボタンをクリックします。

インデックス作成処理が開始されます。全行程が完了するのに大体 10 分程度掛かりました。「ジョブの詳細」をクリックすると、インデックス作成のジョブパイプラインを見ることができます。Azure Machine Learning のパイプラインですので、実行時間、そんなに早くないです。。。
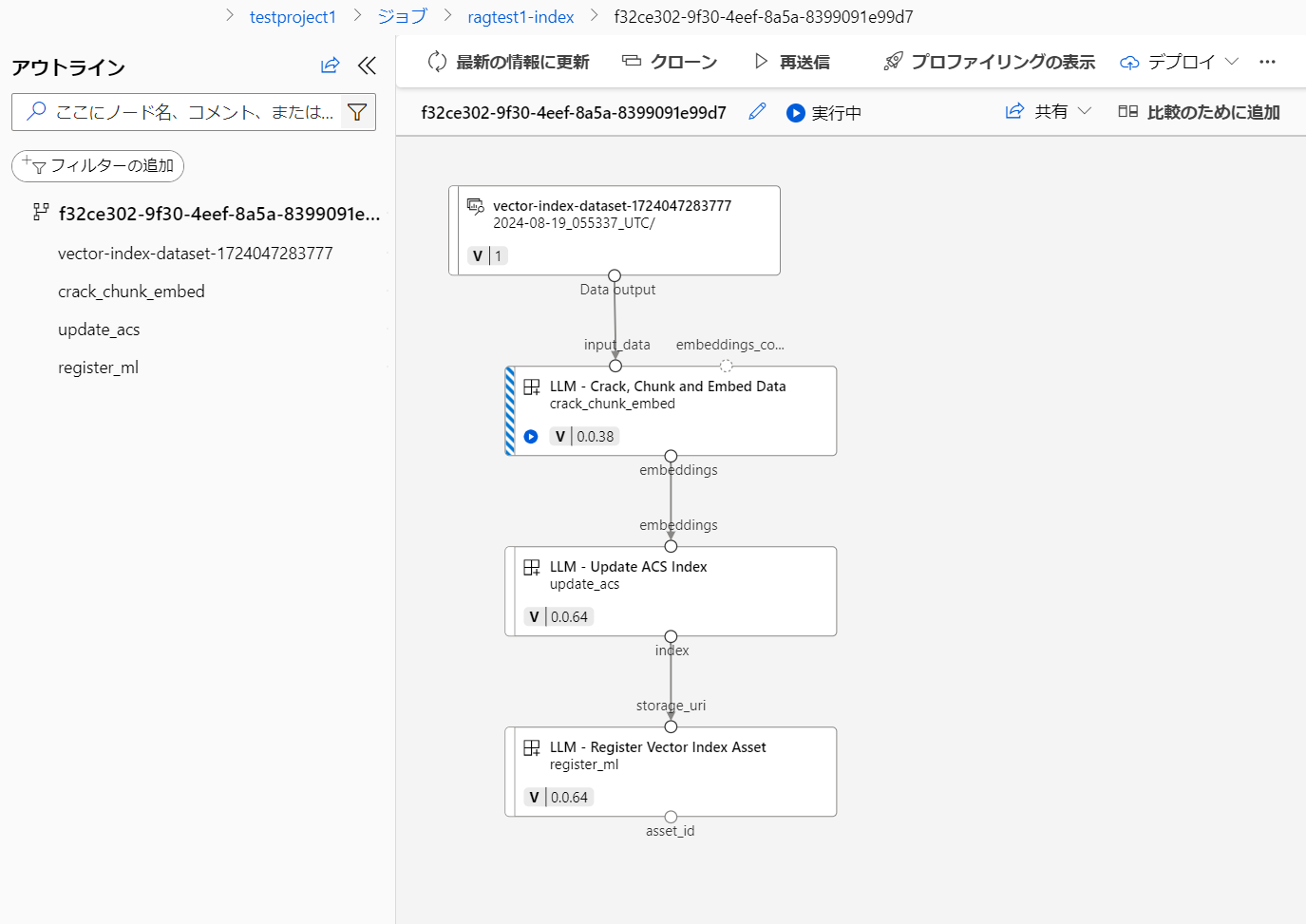
全行程完了しましたら、ステータスが Completed となります。

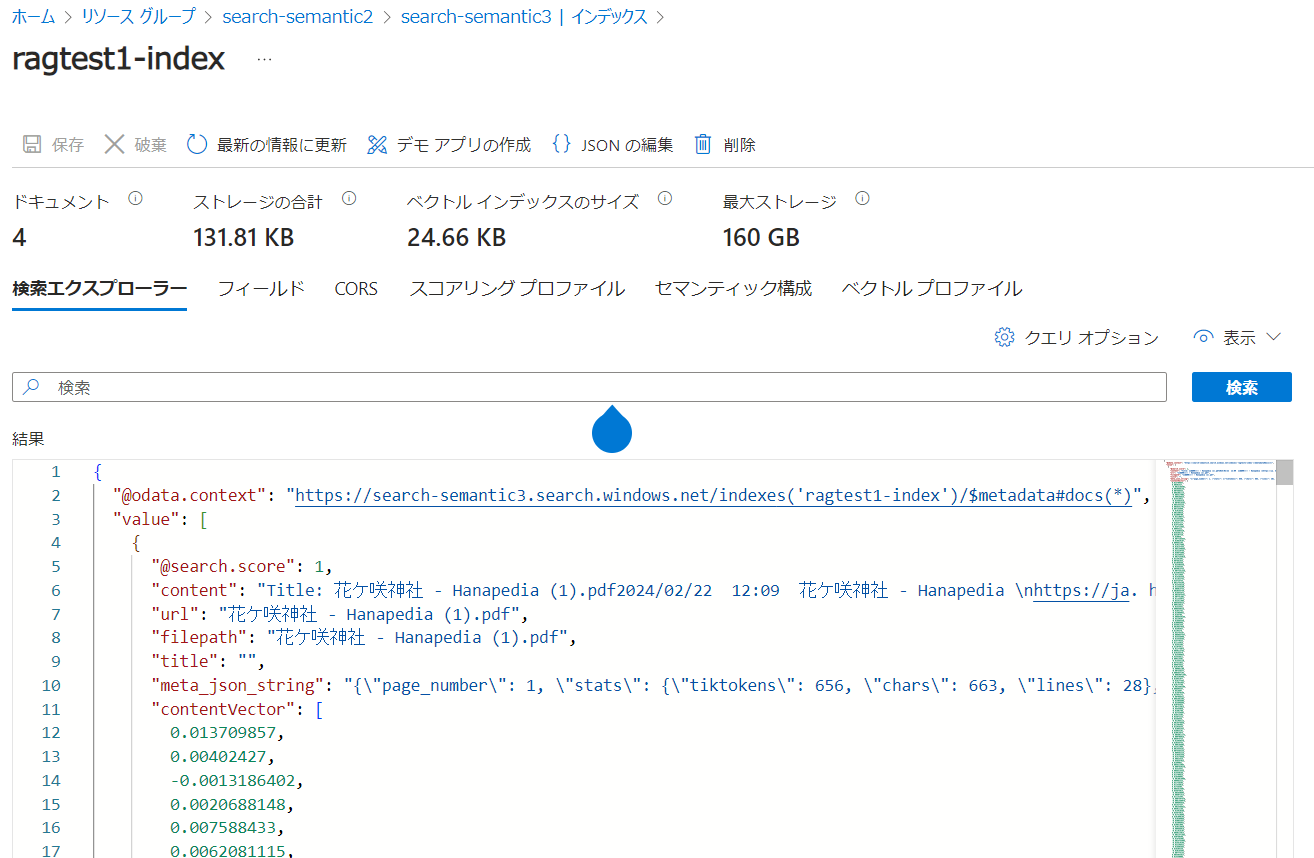
参考として、Azure Portal から実際に Azure AI Search のリソースで作成されたインデックスを確認することができます。ドキュメントは 4 つのチャンクに分割されてインデックス化されたことが分かります。
2.2. インデックスの読み込み
それでは先ほどのフローに戻り、作成したインデックスを読み込ませましょう。ツールメニューの「+その他のツール」から「Index Lookup」ツールを選択します。名前には「AISearch」とでも入力しておきます。
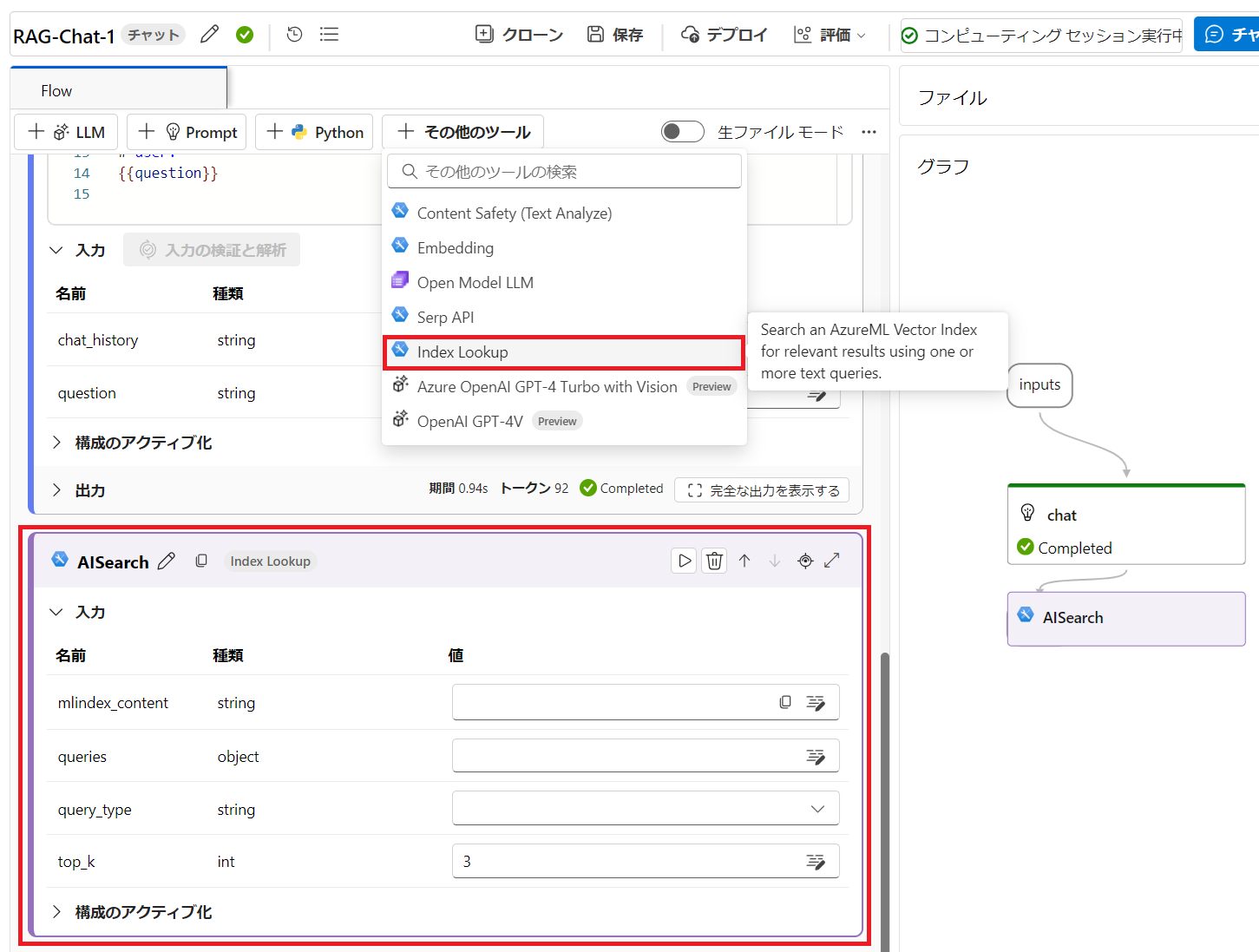
- mlindex_content: インデックス設定

- queries:
${inputs.question} - query_type:
Hybrid (vector + keyword) - top_k:
3
各設定項目は上記のように設定します。
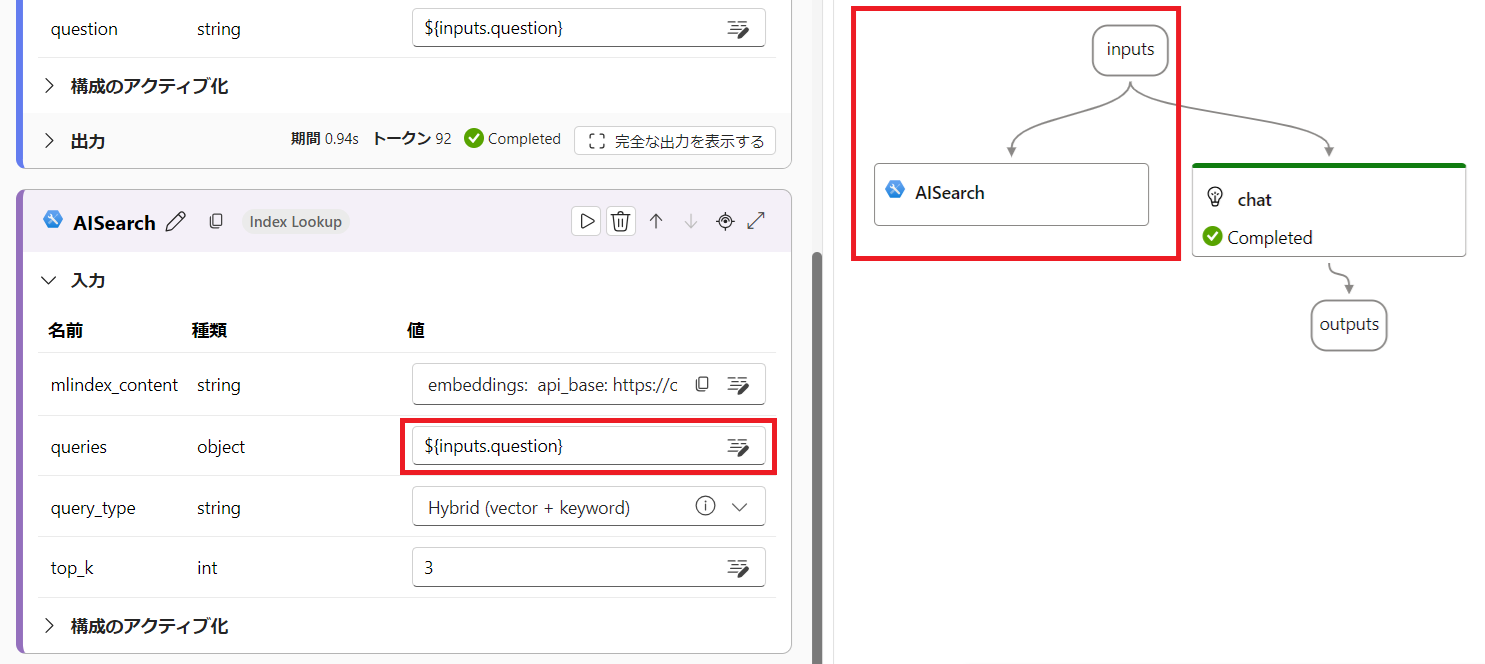
queries に ${inputs.question} を設定すると、フローの inputs---AISearch 間がつながります。プロンプトフローはデータの流れを表します。これでユーザーからの入力値が AISearch 側へ渡るようになりました。
ではここで保存して、一度チャットに質問してみましょう。
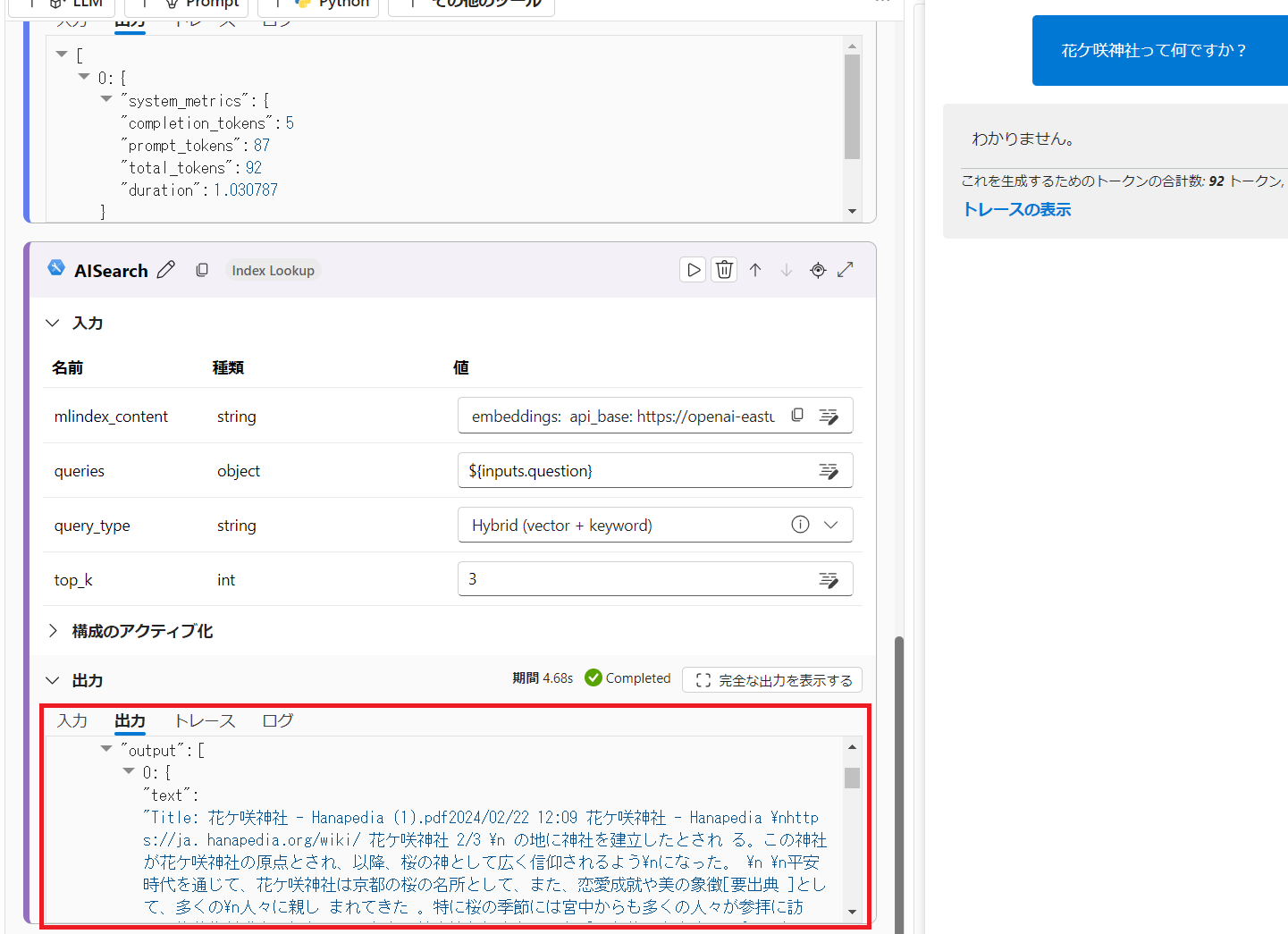
当然チャットの出力は「わかりません」のままですが、AISearch ノードの出力をご覧ください。Azure AI Search からの生の検索結果が表示されていることが分かりますね。ノード単体のテストとしてはこれで成功です。全文を確認したい場合は「完全な出力を表示する」ボタンをクリックします。
ただし、この生の出力結果(配列)をプロンプトに挿入するための加工・結合をしたいですよね。top_k 分のテキストだけを取り出したい。そのための後処理ノードを追加しましょう。
2.3. 検索結果を結合
Azure AI Search からの検索結果(JSON)の中身をループしてテキストだけを取り出して、結合した文字列を返す Python コードを以下のように貼り付けます。これはもうおまじないなのでコピペするだけで OK です。
from typing import List
from promptflow import tool
from promptflow_vectordb.core.contracts import SearchResultEntity
@tool
def generate_prompt_context(search_result: List[dict]) -> str:
def format_doc(doc: dict):
return f"Content: {doc['Content']}"
retrieved_docs = []
for item in search_result:
entity = SearchResultEntity.from_dict(item)
content = entity.text or ""
retrieved_docs.append({
"Content": content
})
doc_string = "\n\n".join([format_doc(doc) for doc in retrieved_docs])
return doc_string

引数、パラメータなどを編集した後は、「入力の検証と解析」ボタンをクリックする必要があります。フローからの入力値を引数に紐づけるため、自動的にコード内の引数を抽出します。コード内の search_result に AISearh ノードからの出力値である ${AISearch.output} をセットすれば右のフローにあるように、AISearch---MergeResults 間のデータ接続がつながります。
前のノードの出力値-->ノードの入力値
という関係ですね。
ではここでフローを保存して、またチャットで同じ質問をしてみましょう。

ハイ今度は、検索結果 3 件分のテキストがすべて結合された文字列のみが返ってきたことが分かります。
これをプロンプトに挿入していきましょう。
2.4. 検索結果の挿入
最後に MergeResults からの結果を chat ノードに挿入するためのプロンプトを以下のように追加します。追加したら必ず「入力の検証と解析」をクリックし、source の入力値として ${MergeResults.output} を指定します。
# source:
{{source}}

すると MergeResults---chat 間のデータ接続がつながりました!
この状態でフローを保存し、チャットで質問してみましょう。

はい、成功ですね。ちゃんと出典にある回答をしてくれました。(内容はダミーテキストです)chat ノードの入力値には、それぞれの変数に渡ってきたテキストが格納されていることが確認できますね。
3. チャット履歴の考慮
デフォルトのプロンプトには以下のようなプロンプトが入っているのが分かります。Azure AI Studio は専用の変数 chat_history に過去のやり取りを蓄積しており、これをループしてプロンプトに展開することで一緒に LLM に投げることができます。
{% for item in chat_history %}
# user:
{{item.inputs.question}}
# assistant:
{{item.outputs.answer}}
{% endfor %}
そういえばあの神社ってなんでしたっけ?もう一度説明して
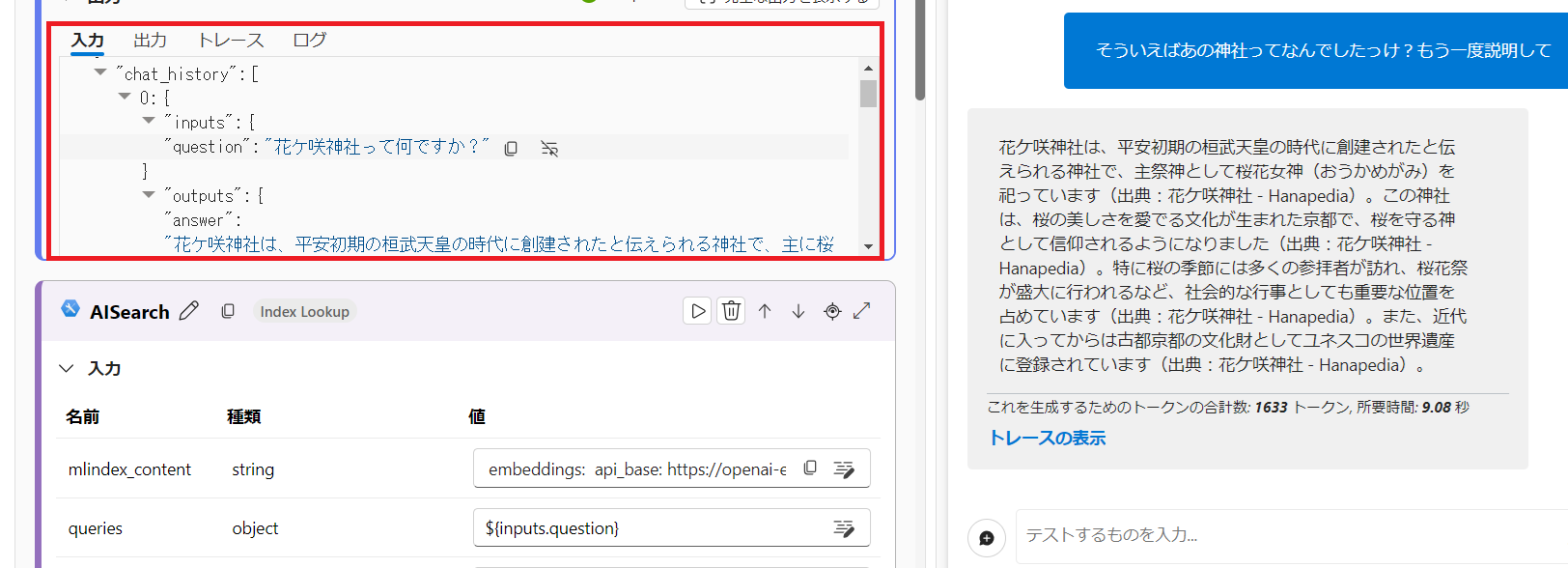
chat ノードの入力値に過去の質問・回答が入ってきていることが分かりますね。
4. RAG 評価
コンテキストを含む評価メトリクス
Groundedness(接地性、根拠性)
回答がコンテキストに基づいているかどうかを 5 段階評価します。
必須項目:コンテキスト、回答
Relevance(関連性)
コンテキストを考慮した上で、質問と回答との関連性を 5 段階評価します。
必須項目:コンテキスト、質問、回答
4.1. コンテキストを出力
デフォルトでは、最終出力として answer のみを出力しますが、評価のために MergeResults ノードからの出力も context として追加します。こうすることで評価の項目として使用することができるようになります。チャットの出力ラジオボタンを answer に指定しているので最終出力は chat ノードからのままとなります。
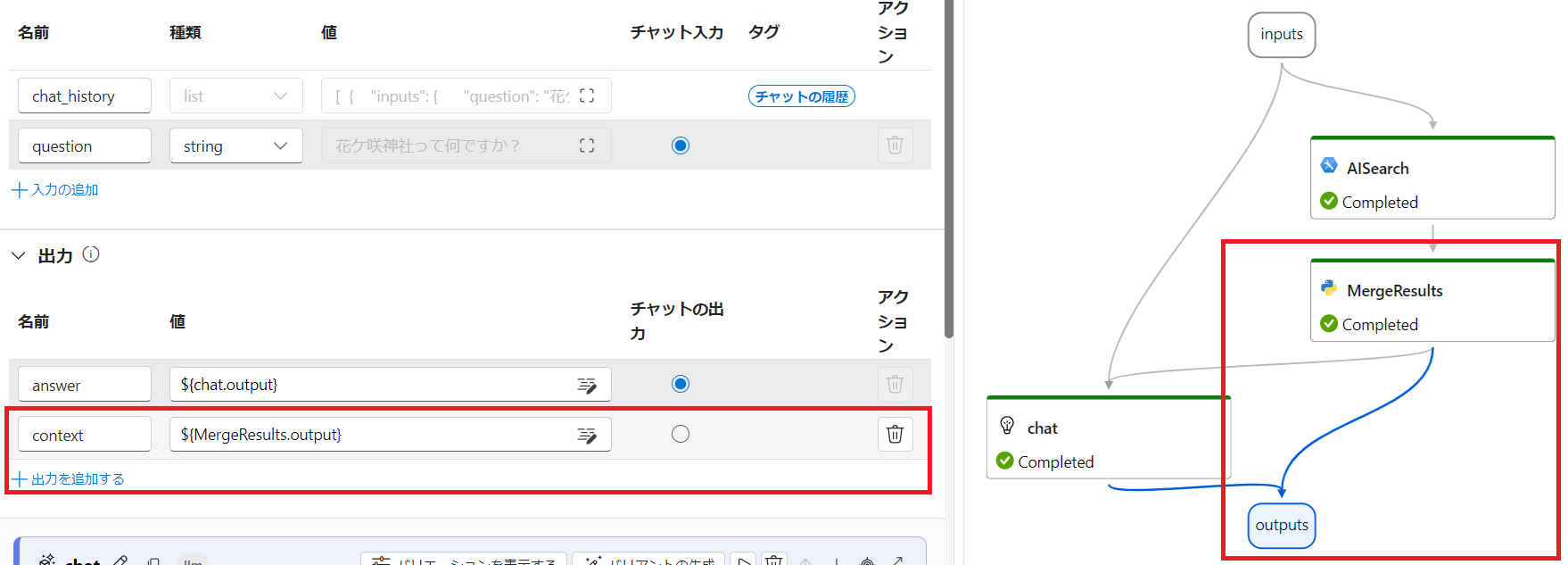
また、簡単のために AISearch ノードからの検索結果の top_k を 1 件に変更しておきます。
4.2. 自動評価
ツールバーから評価→自動評価を選択します。
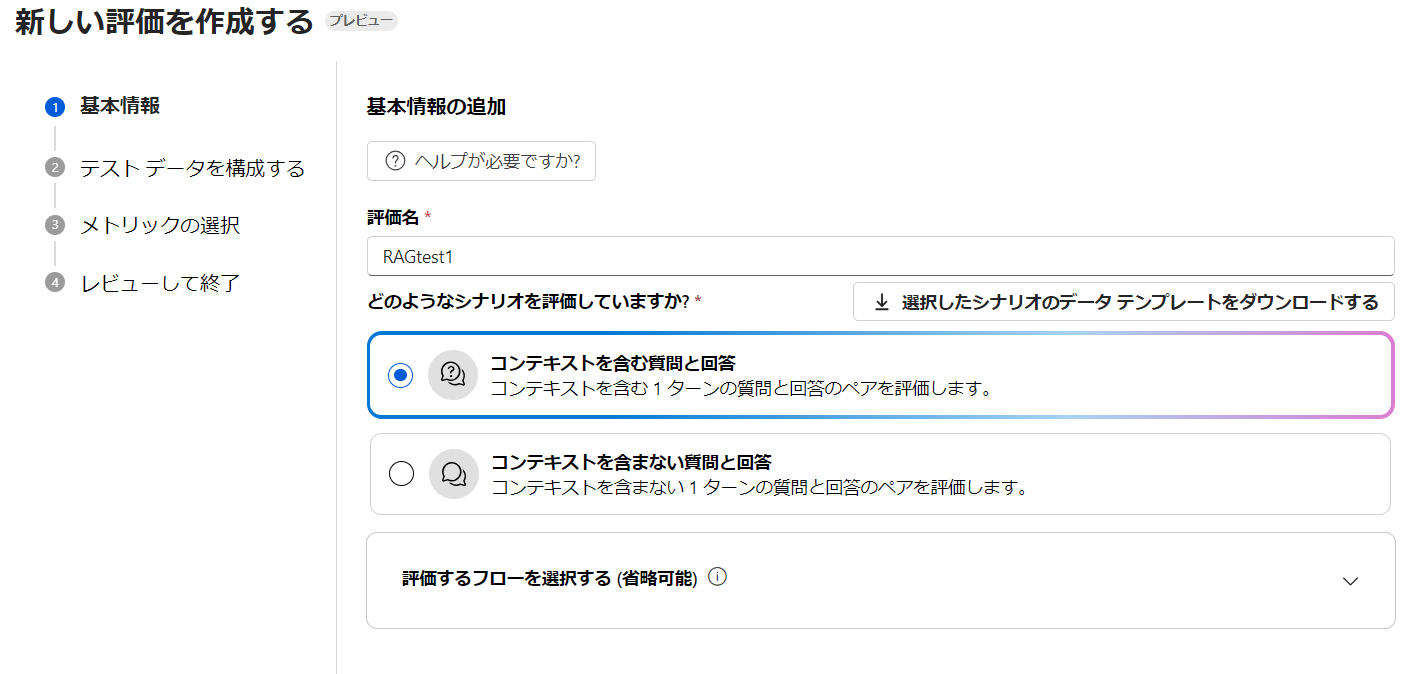
「コンテキストを含む質問と回答」が選択されていることを確認し、次へ進みます。
4.3. CSV のアップロード
以下のようなシンプルな CSV ファイルを作成してアップロードします。question と ground_truth のみを記載しておき、context と answer はフローからの出力をマッピングするために空欄にしてあります。chat_history リストは今回使用しないので [] にしてあります。
question,answer,ground_truth,context,chat_history
"花ケ咲神社の本殿が建造されたのは何年ですか?","","花ケ咲神社の本殿が建造されたのは794年です。","",[]
"花ケ咲神社の最寄り駅はどこ?","","花ケ咲神社の最寄駅は京都市営地下鉄烏丸線北山駅です。","",[]
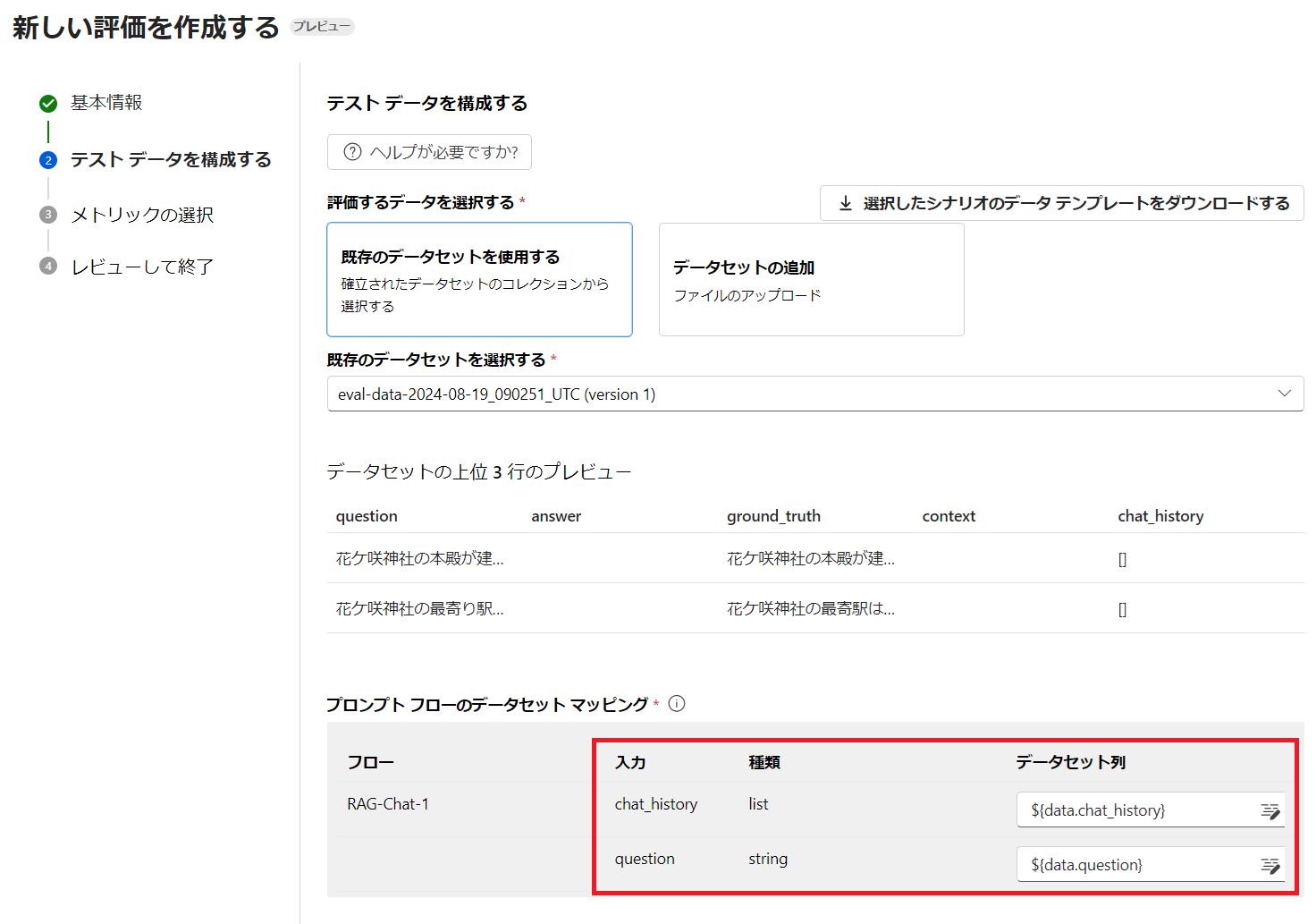
カラム名を合わせてあるので、自動的に chat_history と question がマッピングされます。
4.4. 評価メトリクス
今回は「根拠性」、「関連性」そして「GPT の類似性」にチェックします。

context と answer にはフローからの出力がマッピングされていることを確認します。
- context:
${run.outputs.context}・・・フローから - answer:
${run.outputs.answer}・・・フローから - question:
${data.question}・・・CSV から - ground_truth:
${data.ground_truth}・・・CSV から
そして評価に使用するモデルを選択します。今回は「gpt-4o」をセットします。準備ができたら次へ進んで内容を確認して「送信」をクリックします。
4.5. 評価結果
評価には 1~2 分掛かります。完了しましたら、メトリック ダッシュボードに評価結果のグラフと表が表示されます。
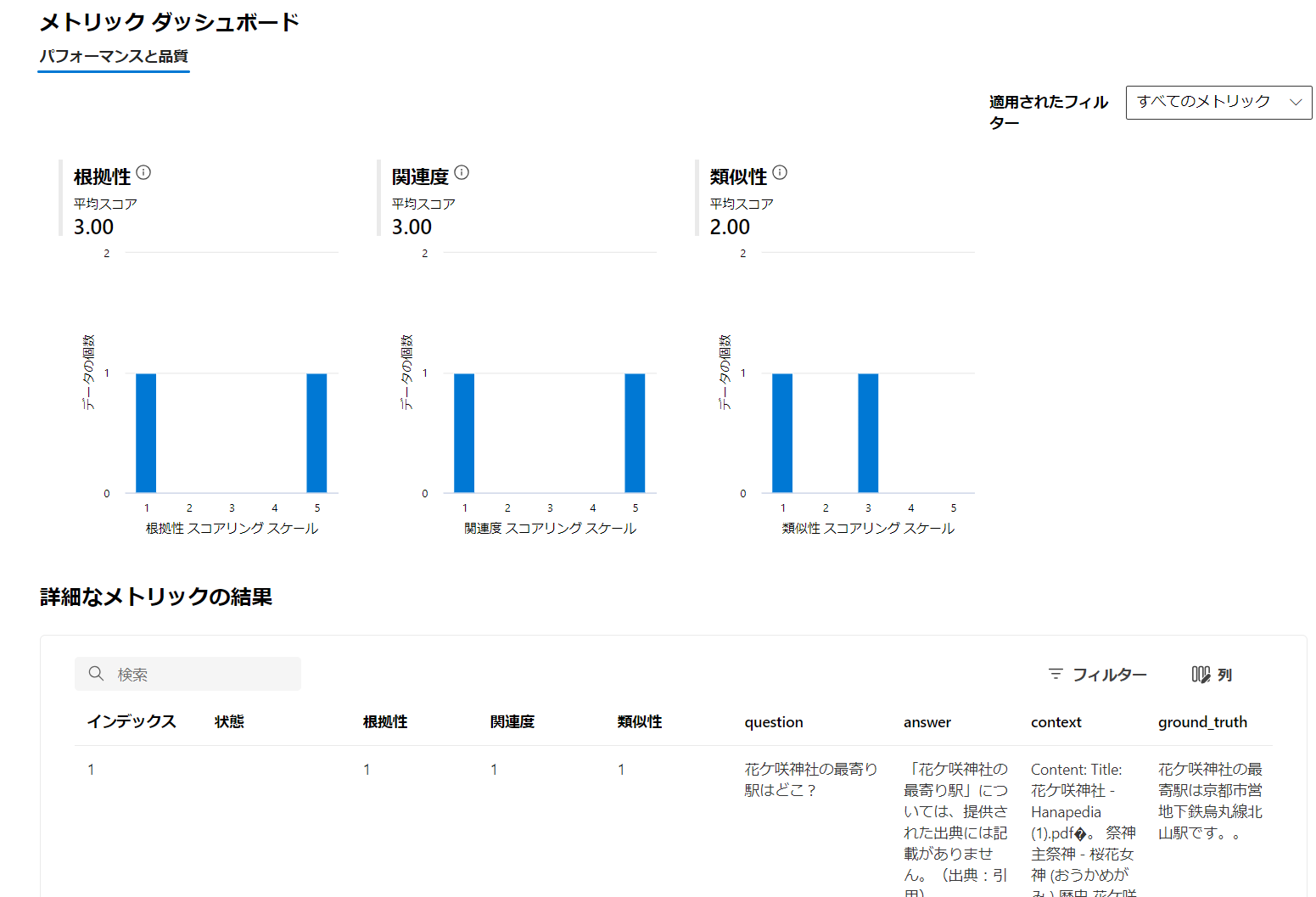
グラフには、評価メトリクスごとの平均スコアとヒストグラムが表示されます。表には CSV のレコードごとの結果が表示されます。わざと top_k を 1 件にしておいたので、検索結果に回答が含まれなかった場合が出てきますが、その場合は根拠性や関連性のメトリクスが 1 点となります。

レコード 2 は回答がコンテキストに存在したため、根拠性 5 点、関連性 5 点となっています。ただし、GPT 類似性では 3 点となっています。これは ground_truth と answer の類似性を判定しているためです。
シリーズ