はじめに
うわっ、私のチャット UI シンプルすぎ…?
OpenAI / Azure OpenAI の Responses API と、最新推論モデル GPT-5.4/5.5 シリーズの登場により、生成 AI アプリケーションの作り方は確実に「次の段階」に入りました。
単に chat.completions.create() でテキストを流すだけの時代から、
- 推論プロセス自体を構造化イベントとして扱う
- ツール(MCP / Function / Tool Search)を動的に編成する
- 長時間ストリーミング・キャンセル・冪等再接続を前提に UX を設計する
のような、よりエージェント指向のアーキテクチャが主流になりつつあります。
ということで、本記事では、エージェント指向のアーキテクチャを Python Flask で構築したリッチなチャット UI 例 を紹介します。

GPT-5.4/5.5 新機能
1. 推論モード(Reasoning Effort)5 段階の切替
GPT-5.4/5.5 は reasoning.effort に none / low / medium / high / xhigh の 5 段階を受け付けます。本 UI ではサイドバーのラジオボタンから即切り替えでき、リクエストごとにサーバへ載せます。
# app.py
if effort == "none":
base_kwargs["reasoning"] = {"effort": "none"}
else:
base_kwargs["reasoning"] = {"effort": effort, "summary": "detailed"}
-
noneは抽出・ルーティング・定型変換など推論を必要としない単純処理タスク向け。レイテンシ最小。 -
mediumがデフォルト推奨。計画・合成・コーディングに十分。 -
high/xhighは評価でメリットが確認できた場合のみ。トークンコストが跳ねるため、運用では「モード × タスク種別」のマトリクスで制御したい。
UI 側では実際のレスポンス進行を created → queued → in_progress → reasoning → tool → text → completed の フェーズタイムライン として可視化しているため、リクエスト中に「今モデルが何をしているか」が一目で分かります。

2. Reasoning Summary のライブストリーミング表示
GPT-5.4/5.5 は summary: "detailed" を指定すると、モデル自身が書き起こした 思考プロセスの要約を response.reasoning_summary_text.delta として逐次送ってきます。さらに reasoning_summary_part.added でセクション区切りが通知されるため、UI 上では 段落ごとに折りたためる構造で描画できます。

現状英語から変えることはできません。必要であれば、別途翻訳が必要か… でも delta で送信されてくるからなぁ…
3. Tool Search と Deferred Loading
従来の課題
エンタープライズ用途で関数(tools)を数十〜数百本用意すると、すべてのツール定義をリクエストに積むだけで数千トークンを消費してしまい、コストとレイテンシが劇的に悪化します。また、モデルが無関係なツールを選んでしまう「選択事故」も発生しやすくなります。
GPT-5.4 の解決策:Tool Search + Deferred Loading
GPT-5.4/5.5 は ネームスペースでツールを束ね、defer_loading: true を付けることで、「必要になるまでツール定義をモデルに渡さない」設計を可能にしました。モデルは組込みの tool_search ツールで検索を行い、ヒットしたツールだけがロードされます。
本実装では以下の 3 関数を CRM ネームスペースに束ねています。
CRM_NAMESPACE = {
"type": "namespace",
"name": "crm",
"description": "CRM tools for customer lookup and order management.",
"tools": [
{"type": "function", "name": "list_open_orders", "defer_loading": True, ...},
{"type": "function", "name": "get_shipping_eta", "defer_loading": True, ...},
{"type": "function", "name": "search_customer", "defer_loading": True, ...},
],
}
tools = [CRM_NAMESPACE, {"type": "tool_search"}]
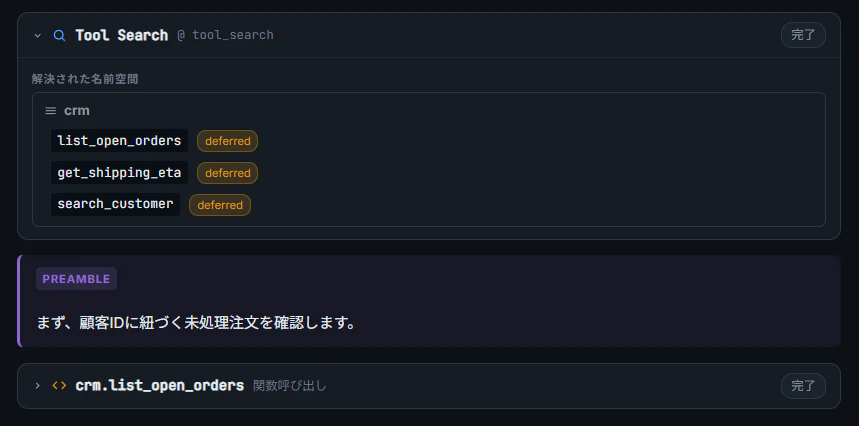
- 公式ガイドはツール定義が大規模な場合に Tool Search を推奨しているが、実務的には、ツール定義をすべて積んだ際の入力トークン数とレイテンシを計測し、コスト/精度のトレードオフが悪化し始めた時点で導入を検討するのが現実的かと。
- 公式ガイドは namespace 内の関数本数を 10 本未満に保つことをベストプラクティスとして推奨している。トークン効率とモデル性能の両面で有利。
4. Preambles と Verbosity ― 出力の「説明責任」を制御する
GPT-5.4/5.5 では、出力の意味的レイヤーを 2 種類の独立した軸で制御できるようになりました。本実装では両者を UI で実現しています。
4.1 Preambles(ツール呼び出し前の説明テキスト)
Preamble は 「ツールを呼ぶ前にモデルが宣言する計画・進捗ナレーション」 です。OpenAI 公式 GPT-5 prompting guide が推奨する <tool_preambles> ブロックをそのまま instructions パラメータに注入することで挙動を引き出します。
# app.py
if use_preambles:
base_kwargs["instructions"] = (
"<tool_preambles>\n"
"- Always begin by rephrasing the user's goal in a friendly, clear, and concise manner, before calling any tools.\n"
"- Then, immediately outline a structured plan detailing each logical step you'll follow.\n"
"- As you execute your file edit(s) or tool call(s), narrate each step succinctly and sequentially, marking progress clearly.\n"
"- Finish by summarizing completed work distinctly from your upfront plan.\n"
"- Respond in the same language as the user's question.\n"
"</tool_preambles>"
)

Preamble と Tool Call を時系列的に並べている例。
- Preamble は「ユーザに対する透明性」と「デバッグ可能性」を両立する非常に有用な仕組み。長時間タスクで「今モデルが何をしているか」を伝えられる。
- 一方で トークンコストは増える。短い問い合わせ(FAQ 系)では OFF にできる設計が現実的。
4.2 Verbosity(出力冗長度)
GPT-5.4/5.5 で text.verbosity が low / medium / high の 3 段階で受け付けられるようになりました。reasoning effort と直交する独立パラメータで、「深く考える」と「長く書く」を別々にチューニングできます。
# app.py
base_kwargs["text"] = {"verbosity": verbosity} # low / medium / high
| Verbosity | 想定用途 |
|---|---|
low |
コード生成、関数の純粋出力、API レスポンス的な簡潔回答 |
medium |
一般的なチャット応答(既定推奨) |
high |
教育的説明、コードに詳細コメント、ステップ・バイ・ステップ解説 |
-
コード生成系のエージェントでは
lowを既定にするだけで、出力トークンが大幅に下がりコスト削減につながる。 - ヘルプ系・チュートリアル系では
highで冗長に説明させた方が UX 評価が高い傾向。 -
verbosityとreasoning.effortは独立に組み合わせ可能。例:effort=high, verbosity=lowは「深く考えた結果を簡潔に出す」。
5. Refusal / Incomplete / Cancel の完全ハンドリング
エンタープライズ UI で軽視されがちな「失敗系」を、本実装では専用バナーで可視化しています。
| イベント | UI | 発生シナリオ |
|---|---|---|
response.refusal.done |
赤バナー:モデルによる拒否理由を表示 | コンテンツポリシー抵触 |
response.incomplete |
黄バナー:reason: max_output_tokens 等 |
出力が途中で打ち切られた |
/api/cancel 成功 |
グレーバナー:「キャンセルされました」 | ユーザが停止ボタン押下 |


incomplete は特に見落としやすいイベントです。GPT-5.4/5.5 は reasoning トークンだけで max_output_tokens を食い潰すケースがあり得るため(公式ガイドも推奨バッファを明記)、UI 側で明確に「途中で止まった」ことを示すのは UX の重要要素です。
これであなたのチャット UI もリッチに!
GitHub