はじめに
組織内に貯まっている大量な構造化・非構造化データから、新たな価値を見出すためのフルマネージド全文検索サービスである Azure Cognitive Search を使えば、誰でも簡単に AI 搭載検索エンジンを開発することができます。今回はこれまでも多くの検証をしてきた OCR スキルのアップデートについて紹介します。
OCR スキル
今回のアップデートによって OCR スキルが Read API v3.2 をバックグラウンドで使用することになり、画像ファイルに含まれる日本語印刷テキストや手書きテキストを簡単かつ高精度で認識することができます。
利用方法
試すのは簡単、Azure Portal の画面 UI や REST API を用いてインデックスを作るだけ。初めての方は Azure-Cognitive-Search-Workshop のノーコード全文検索インデックスの作成に従って簡単に構築できます。すでにインデックスを作成済みの方は、一度インデクサーをリセットし、再実行することで最新の OCR スキルの結果が適用されます。
実行結果
いつも使わせていただいている青空文庫の「吾輩は猫である」のスキャン画像を OCR スキルで読み取ってみましょう。
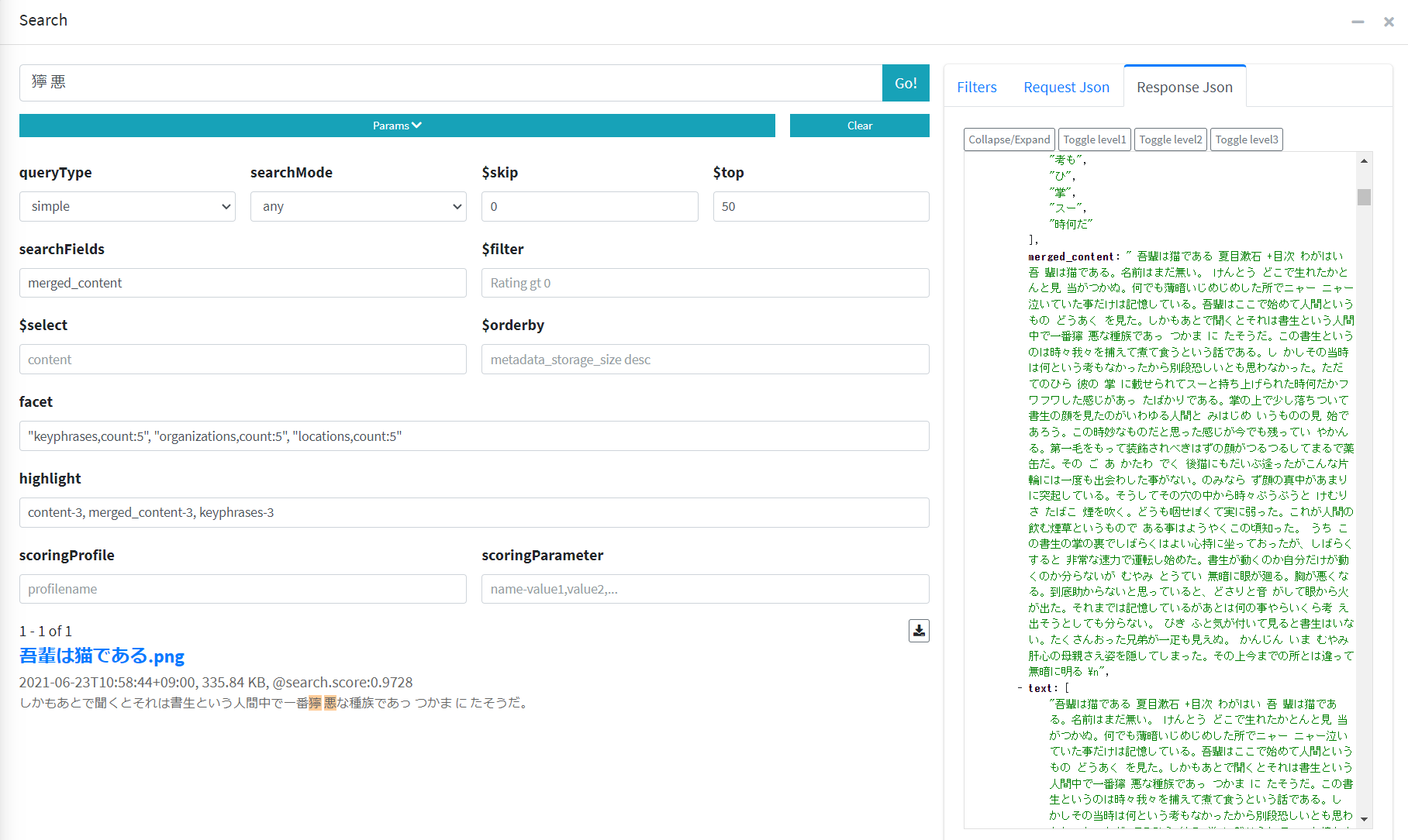
おおー! merged_content フィールドにしっかりと(細切れではない)文章が格納されていますね!精度についても最新の Read API v3.2 のモデルが使われているため、「ニャー」のところの「ャ」と、「一疋」の「疋」が正しく認識されていることが分かります。
気になる点
ただ、よく見ると Read API v3.2 の結果をそのまま格納しているため、OCR が読み取った半角スペースが所々含まれてしまっていることが分かります。Azure Cognitive Search の日本語アナライザーは、半角スペースによって強制的にトークンを分割するため、画像のように「獰 悪」と読み取られてしまった場合、検索クエリーに「獰悪」と入れても検索結果が出てきません。これが気になるという方はこれまで通り Azure Cognitive Search で Python のカスタムスキルを Azure Functions で簡単に実装する (Read API v3.2)を参考にしてください。こちらは半角スペース除去処理を入れていますので。(この仕様が気になる方、Microsoft サポートまで Feedback いただけると助かります)
まとめ
ちょっと気になる点はありますが、日本語手書きにも対応した OCR スキルをこんなに簡単に使えるようになったのはとてもうれしいことです。特に最新の OCR モデル(2022-04-30) によって日本語印刷テキストの精度も向上しているのでぜひお試しいただければと思います。
参考
Azure Cognitive Search の全文検索を重点的に学習するワークショップを公開
Azure Cognitive Search で Python のカスタムスキルを Azure Functions で簡単に実装する (Read API v3.2)
ダウンロードするだけで即使える検索 UI: Simple-Cognitive-Search-Tester