はじめに
Azure Cognitive Services の 画像認識 API である、Computer Vision API v3.2 の一般提供が 2021 年 4 月に開始されました。このアップデートには、73 言語で利用可能な OCR (Read) が含まれており、日本語の OCR を Read API を使って利用することができるようになりました。※手書き文字は英語のみ対応。
私は、Read API 以前の Vision API v2.1 の頃から日本語 OCR の認識精度を評価してきましたが、このアップデートによって恐ろしいほど認識精度が向上していることが確認できました。
本記事に示したコードを使うことで、どなたでもすぐに Microsoft の最新 OCR を利用することができます。
目次
- Read API v3.2 を利用する
- 事前準備
- 呼び出しコード
- 認識結果の評価(行情報の取得)
- 認識結果の評価(JSON構造)
- 認識結果の評価(文字単位)
- 認識結果の評価(回転耐性)
- Vision API v2.1 の評価
- 追加で評価
- オンプレ環境での実行
- さいごに
Read API v3.2 を利用する
Computer Vision の Read API は、印刷されたテキスト (複数の言語)、手書きのテキスト (英語のみ)、数字、通貨記号を、画像や複数ページの PDF ドキュメントから抽出する、Azure の最新の OCR テクノロジです。これは、テキストの多い画像や、混合言語を含む複数ページの PDF ドキュメントからテキストを抽出するように最適化されています。
本記事では、Python を用いますが、C# や Java、JavaSctipt、Go 言語、SDK を利用した呼び出しなどのコードサンプルを公開しています。こちらを参照してください。
事前準備
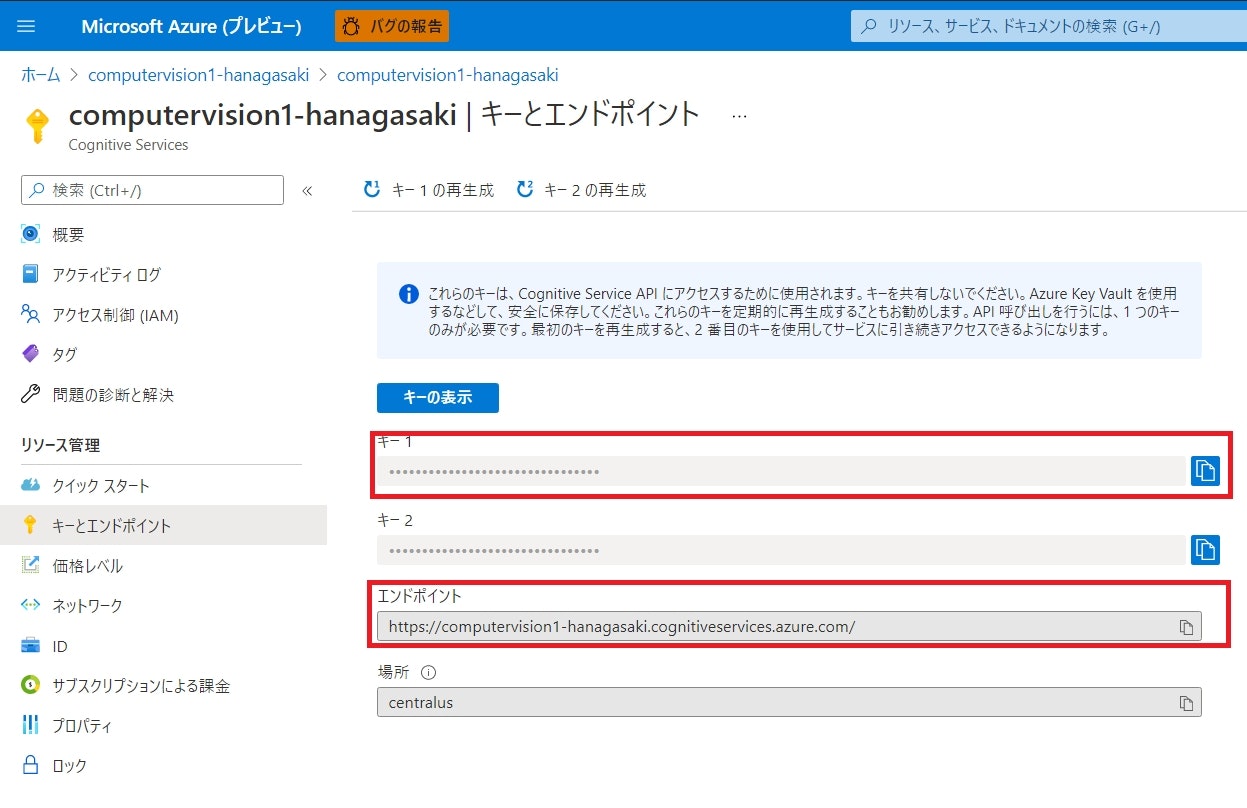
Azure Portal から新規にリソースの作成を行います。Marketplace で「Computer Vision」と検索し、Computer Vision サービスを作成します。

必要情報を入力して、デプロイした後、Computer Vision サービスポータルの左メニューから「キーとエンドポイント」を選択し、キー1 と エンドポイント の値を控えておきます。
呼び出しコード
本記事では、Python コードを Jupyter Notebook 上で動作させています。Jupyter Notebook はブラウザ上で、Python コードを実行したり実行結果を即時に確認することができるデータサイエンティスト必携ツールです。インストール方法はググるなどしていただければと思います。
Read API は非同期的に実行され、処理のリクエストと結果の取得という 2 段階のプロセスに分かれています。以下のコードでは、処理をリクエストした後、結果を取得するための ID を使って結果をポーリングする処理を組み込んでいます。
import json
import requests
import time
import codecs
imFilePath = './wagahaiwa_nekodearu.png'
with open(imFilePath, 'rb') as f:
data = f.read()
# https://{endpoint}/vision/v3.2/read/analyze[?language][&pages][&readingOrder][&model-version]
subscription_key = "<your-subscription-key>"
endpoint = "https:/<your-service-name>.cognitiveservices.azure.com/"
text_recognition_url = endpoint + "vision/v3.2/read/analyze"
headers = {'Ocp-Apim-Subscription-Key': subscription_key,
'Content-Type':'application/octet-stream' }
params = { 'language ': 'ja',
'model-version':'2021-04-12'}
# 指定した画像の read メソッドを呼び出します。これによって operation ID が返され、画像の内容を読み取る非同期プロセスが開始されます
response = requests.post(text_recognition_url, headers=headers, params=params, json=None, data=data)
response.raise_for_status()
# レスポンスから operation location(末尾にIDが付いたURL)を取得する
operation_url = response.headers["Operation-Location"]
analysis = {}
poll = True
# read の呼び出しから返された operation location ID を取得し、操作の結果をサービスに照会します。
# 次のコードは、結果が返されるまで 1 秒間隔で操作をチェックします
while (poll):
response_final = requests.get(response.headers["Operation-Location"], headers=headers)
analysis = response_final.json()
print(json.dumps(analysis, indent=4, ensure_ascii=False))
time.sleep(1)
if ("analyzeResult" in analysis):
poll = False
if ("status" in analysis and analysis['status'] == 'failed'):
poll = False
# JSON ファイルを出力
with codecs.open('output_read3.2.json', 'w+', 'utf-8') as fp:
json.dump(analysis, fp, ensure_ascii=False, indent=2)
処理結果は JSON 形式で返却されます。この JSON ファイルをパースして認識結果を利用していきますが、上記コードのように一旦 JSON ファイルとして保存し、後段にてその JSON をロードして分析することをおススメします。毎度リクエストする必要もありませんので。
Read API v3.2 の API 定義書はこちらにあります。
本記事では、テストデータとして毎度おなじみ青空文庫の「吾輩は猫である」のスキャン画像を利用します。

認識結果の評価(行情報の取得)
それでは、以下のように認識結果の JSON をロードし、結果を描画してみましょう。
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import numpy as np
with open('./output_read3.2.json', 'r', encoding='utf-8') as f:
analysis = json.load(f)
im = Image.open('wagahaiwa_nekodearu.png')
draw = ImageDraw.Draw(im)
fnt = ImageFont.truetype('./meiryo.ttc', 15)
count = 0
lines = []
output = ""
if ("analyzeResult" in analysis):
lines = [(line["boundingBox"], line["text"])
for line in analysis["analyzeResult"]["readResults"][0]["lines"]]
for line in lines:
p = line[0]
text = line[1]
draw.rectangle([p[0], p[1], p[4], p[5]], fill=None, outline=(0, 255, 0), width=2)
draw.text((p[0] - 15, p[1]), str(count), font=fnt, fill=(0, 0, 255))
output += str(count) + ": " + text
output += '\n'
count += 1
print(output)
plt.figure(figsize=(20, 20))
plt.imshow(np.array(im))
im.save("./output_read3.2_line_result.png")

このコードによって、元データの上に、認識された行単位の情報を描画しています。テキスト領域の検出の精度は完璧と言ってよいでしょう。Vision API v2.1 では取得できなかった行ごとのテキストが得られています。
0: 吾輩は猫である
1: 夏目漱石
2: +目次
3: わがはい
4: 吾 輩は猫である。名前はまだ無い。
5: けんとう
6: どこで生れたかとんと見 当がつかぬ。何でも薄暗いじめじめした所でニヤー
7: ニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というもの
8: どうあく
9: を見た。しかもあとで聞くとそれは書生という人間中で一番獰 悪な種族であっ
10: つかま
11: に
12: たそうだ。この書生というのは時々我々を捕えて煮て食うという話である。し
13: かしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ
14: てのひら
15: 彼の 掌 に載せられてスーと持ち上げられた時何だかフワフワした感じがあっ
16: たばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間と
17: みはじめ
18: いうものの見始であろう。この時妙なものだと思った感じが今でも残ってい
19: やかん
20: る。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。その
21: ご
22: あ
23: かたわ
24: でく
25: 後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。のみなら
26: ず顔の真中があまりに突起している。そうしてその穴の中から時々ぷうぷうと
27: けむり
28: む
29: たばこ
30: 煙を吹く。どうも咽せぽくて実に弱った。これが人間の飲む煙草というもので
31: ある事はようやくこの頃知った。
32: うち
33: この書生の掌の裏でしばらくはよい心持に坐っておったが、しばらくすると
34: 非常な速力で運転し始めた。書生が動くのか自分だけが動くのか分らないが
35: むやみ
36: とうてい
37: 無暗に眼が廻る。胸が悪くなる。到底助からないと思っていると、どさりと音
38: がして眼から火が出た。それまでは記憶しているがあとは何の事やらいくら考
39: え出そうとしても分らない。
40: ぴき
41: ふと気が付いて見ると書生はいない。たくさんおった兄弟が一定も見えぬ。
42: かんじん
43: いま
44: むやみ
45: 肝 心の母親さえ姿を隠してしまった。その上今までの所とは違って無暗に明る
いったいどこが間違っているのでしょうか!?それはこの後、ワード単位での認識の際に計算します。(Vision API v2.1 と基準を合わせるため)
あと行単位でのテキストには、半角スペースが含まれる場合がありますね。利用する場合は、注意する必要がありそうです。
認識結果の評価(JSON構造)
ここで、Read API v3.2 の認識結果 JSON の構造を解説します。Visual Studio Code の JSON Editor を使って可視化しています。
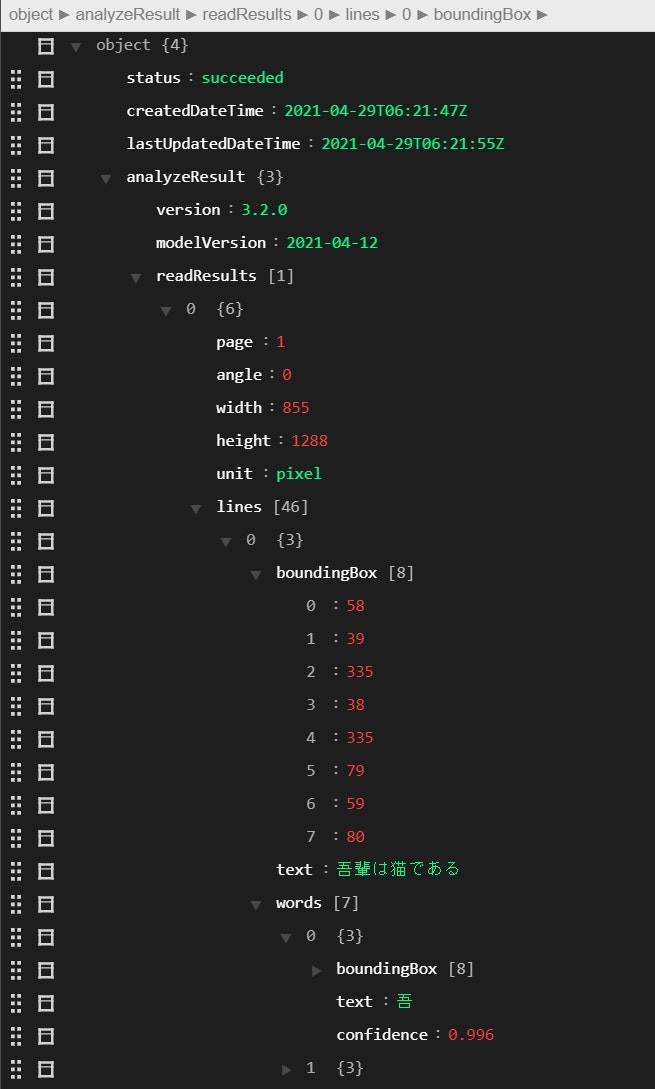
認識結果は、要素数 1 の readResults[] に格納されます。
その中には、入力データのページ数、回転角度、サイズなどのデータとともに、lines[]という行情報が格納されています。
lines[] 配列の要素には、
-
boundingBox[]:[topleft_x, topleft_y, topright_x, topright_y, bottomright_x, bottomright_y, bottomleft_x, bottomleft_y]の順で矩形座標を格納 -
text:行ごとのテキスト -
words[]:単語ごとのリスト(日本語の場合は一文字)-
boundingBox[]:一文字の場所を示す矩形座標。順番はlines[]と同じ。 -
text:一文字のテキスト -
confidence:0 から 1 までの信頼値
-
が含まれ、行の中から、一文字レベルの words[] を取得することができます。
認識結果の評価(文字単位)
では、文字単位で認識結果を描画してみましょう。
from PIL import Image, ImageDraw, ImageFont
import matplotlib.pyplot as plt
import numpy as np
with open('./output_read3.2.json', 'r', encoding='utf-8') as f:
analysis = json.load(f)
im = Image.open('./wagahaiwa_nekodearu.png')
draw = ImageDraw.Draw(im)
fnt = ImageFont.truetype('./meiryo.ttc', 15)
count = 0
polygons = []
if ("analyzeResult" in analysis):
# 行ごとにデータを格納する
lines = [(line["boundingBox"], line["text"], line["words"])
for line in analysis["analyzeResult"]["readResults"][0]["lines"]]
print("lines: ", len(lines))
# 行レベル
for line in lines:
boundingBox = line[0]
text = line[1]
words = line[2]
# 文字レベル
for word in words:
wp = word["boundingBox"]
wtext = word["text"]
wconfidence = word['confidence']
#"boundingBox": [topleft_x, topleft_y, topright_x, topright_y, bottomright_x, bottomright_y, bottomleft_x, bottomleft_y]
# 矩形を描画
draw.rectangle([wp[0], wp[1], wp[4], wp[5]], fill=None, outline=(0, 255, 0), width=1)
# テキストを描画
draw.text((wp[6] + 5, wp[7] - 5), wtext, font=fnt, fill=(0, 0, 255))
plt.figure(figsize=(20, 20))
plt.imshow(np.array(im))
im.save("./output_read3.2_word_result.png")

はい、矩形領域の座標については、若干ズレが見受けられますね。処理に文字座標を利用する場合は注意が必要です。「ニャー」のところの長音記号や、句読点の領域検出にちょっとクセがあります。これは Vision API v2.1 と大きく異なる仕様です。行単位の領域検出アルゴリズムは、単に各文字の領域をマージしたものではないことが示唆されます。
特筆すべきは、各文字の精度ですが、本文書は 743 文字あり、誤認識はたった 2 文字だけでした。
つまり、(741/743) * 100 = 99.7% という結果になります。

誤認識した文字は、「ニャー」のところの「ャ」が「ヤ」になっていたのと、「一疋」のところが「定」になっていた程度でした。上のコードの wconfidence に各文字の信頼度が格納されているので、信頼度 0.90 より小さい値の文字を出力すると、
ニ 0.39
ャ 0.882
っ 0.87
ぽ 0.405
ぴ 0.607
定 0.577
となります。ある程度苦手な文字が分かったような気がします。この信頼度の値と要件を考慮して、閾値とするラインを決め、それよりも低いものについては、後段で専用モデルによる認識を検討するか、ルール等による後処理を検討してください。
にしても精度 99.7% って… 高すぎる精度には懐疑的になるべきです。もしかしたら、「吾輩は猫である」が学習データに含まれてた可能性があるやろ!!という疑念などもあるため、この後、私が投稿したばかりの記事を OCR にかけてみようと思います。
Vision API v2.1 の評価
Read API v3.2 が GA する前は、Vision API v2.1 というのが日本語対応の OCR としては最新でした。以前同じ「吾輩は猫である」の画像に対して精度の評価を行った結果がありますので、以下に示します。

Vision API v2.1 のほうは、文字領域の検出精度が高いことがわかります。しかし、文字の認識精度はというと、21 文字の誤認識があります。
つまり、(722/743) * 100 = 97.2% という結果になります。
Read API v3.2 のほうが、2.5% も高精度という結果になりました。これは凄まじい進化といえるでしょう。
実際の認識結果を分析すると、Vision API v2.1 は全角長音が半角ハイフンになっていたり、濁点・半濁点の認識が得意ではないことが分かります。
吾輩は猫である
夏目漱石
+目次
わがはい
吾輩は猫である。名前はまだ無い。
けんとう
どこで生れたかとんと見当がつかぬ。何でも薄日音いしめしめした所でニャ-
ニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というもの
とうあく
を見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であっ
つかま
に
たそうだ。この書生というのは時々我々を捕えて煮て食うという話である。し
かしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ
てのひら
彼の掌に載せられてス-と持ち上げられた時何だかフワフワした感しがあっ
たはかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間と
みはしめ
いうものの見始であろう。この時妙なものたと思った感しが今でも残ってい
やかん
る。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。その
あ
かたわ
後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。のみなら
す顔の真中があまりに突起している。そうしてその穴の中から時々ふうふうと
けむり
む
煙を吹く。どうも咽せぼくて実に弱った。これが人間の飲む煙草というもので
ある事はようやくこの頃知った。
うち
この書生の掌の裏でしはらくはよい心持に坐っておったが、しはらくすると
非常な速力で連転し始めた。書生が動くのか自分たけが動くのか分らないが
むやみ
とうてい
無暗に眼が廻る。胸が悪くなる。到底助からないと思っていると、どさりと音
がして眼から火が出た。それまでは記億しているがあとは何の事やらいくら考
え出そうとしても分らない。
ふと気が付いて見ると書生はいない。たくさんおった兄弟が一疋も見えぬ。
力、んしん
いま
むやみ
肝心の母親さえ姿を隠してしまった。その上今までの所とは違って無暗に明る
認識結果の評価(回転耐性)
もしドキュメントが傾いていた場合は認識結果にどう影響するのでしょうか。手作業でスキャンした時などによくありますよね。
OCR の中には、少し傾いただけで精度がガタ落ちするものもありますので、この辺の評価も重要です。

画像編集ソフトを使用して、画像を 5度 傾けました。このくらいの傾きでは全く問題なく行の検出ができています。
画像が回転しているため、矩形描画には、draw.polygon([p], fill=None, outline=(0, 255, 0)) を使っています。最初からこっちを使っとけばよかった…
また、readResults の angle を確認すると、4.9201 となっており、ほぼ正しい回転角度を検出できていることになります。
"readResults": [
{
"page": 1,
"angle": 4.9201,
"width": 966,
"height": 1360,
"unit": "pixel",
"lines": [
{
次に文字単位での認識精度を確認します。

おーっ、これは素晴らしい。うまく認識できていますね!
実際の認識精度ですが、2 箇所に誤認識がありましたので、こちらも精度 99.7% ということになります。
「一疋」のところが「定」になっていたのと、ルビの「ぴき」が「びき」と誤認識されていました。「ぴ」が「び」になっている部分は、画像の品質的に認識が厳しくなっていたのではと考えられます。
追加で評価
Read API v3.2 で「吾輩は猫である」を読み込むと非常に高精度であることが分かったのですが、今度は私が最近投稿したばかりの記事を使って、OCR に挑戦してみたいと思います。

記事の内容を一旦 Word に入力し、画像を含めて、フォントを一般的な書類に用いられている MS P明朝 にしてみます。
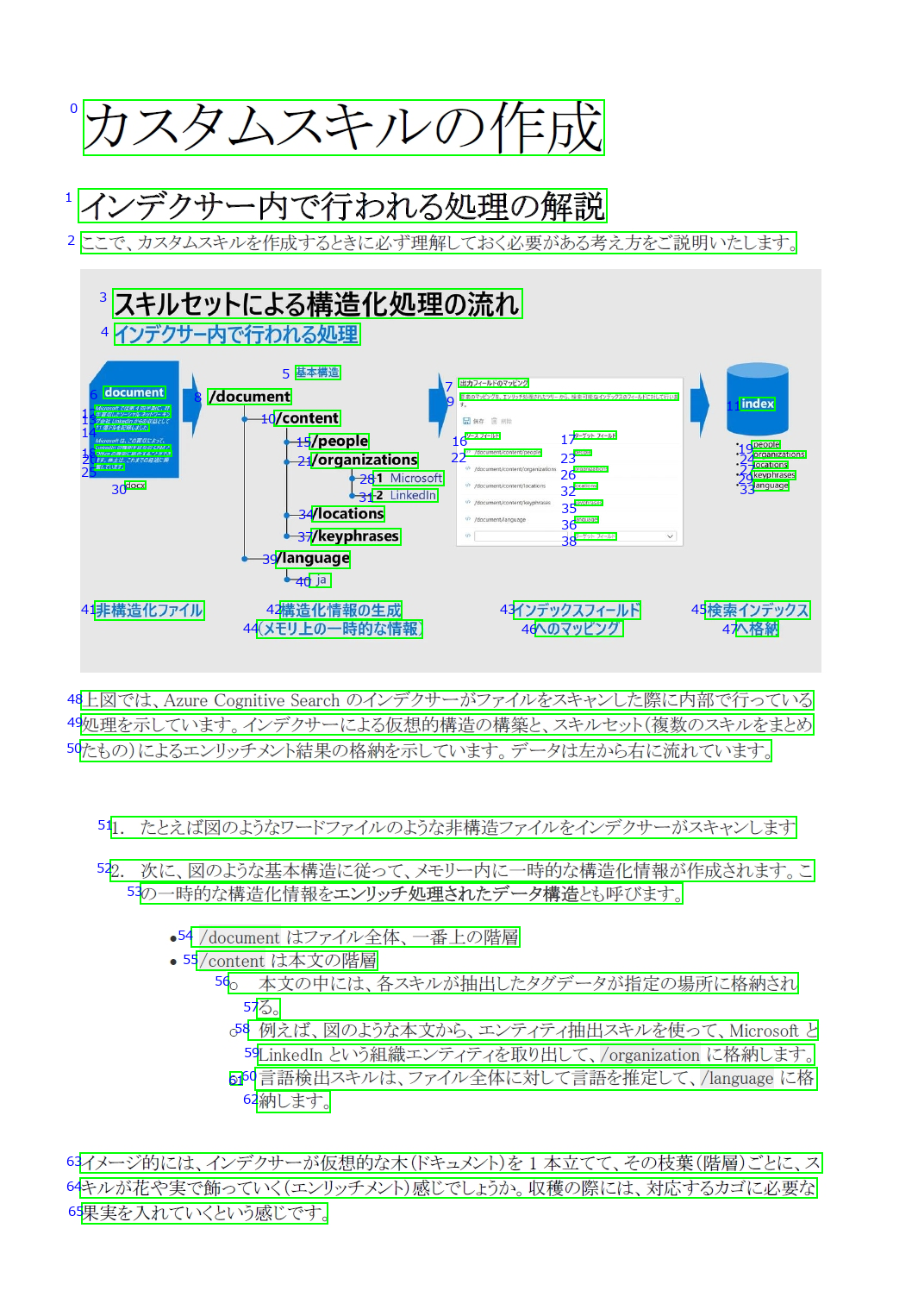
本文の行領域検出は完璧にされています。画像の中については、縮小によって潰れかけた文字に対しても頑張って検出を試みていることが分かります。検出可能と不可能の境界が見えたような気がします。
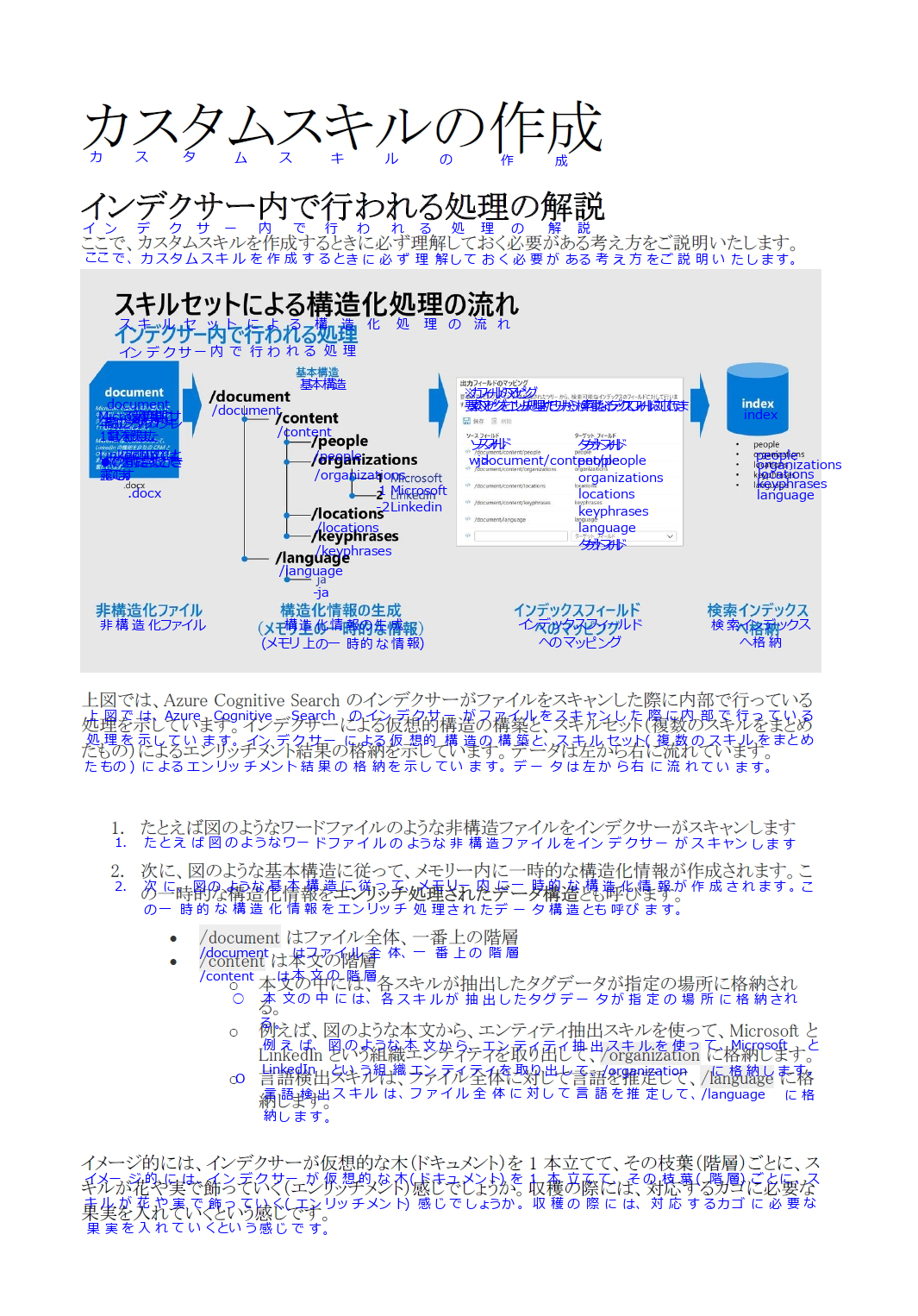
文字の認識については、やはり既存の日本語 OCR が不得意であった、濁点・半濁点や長音記号、小書き文字に対しての精度が高いことが分かります。
このような感じで、皆様の環境において、Read API v3.2 を評価していただければと思います。
オンプレ環境での実行
今回ご紹介した Read API v3.2 はオンプレでの実行を可能にする Read OCR Docker コンテナーに対応しています。これにより、セキュリティやコンプライアンスの観点からクラウド上にデータを流したくないお客様やネットワーク環境に制限があるお客様にもお使いいただけます。
Docker コンテナーでの実行手順についてはコチラを参照してください。
さいごに
今回は、Read API v3.2 において、「吾輩は猫である」のドキュメントに対して高い精度が出るということが確認できました。
このレベルの OCR が、Azure Cognitive Search の OCR スキルとして実装されれば、より高品質なナレッジマイニングが可能になると期待しています。
OCR の特性上、画像ファイルの形式、ノイズ、光の程度、前処理の有無うんぬんで結果が変化するため、必ず利用を検討する条件下にて評価条件を定義してから評価するようにしてください。
今回使用したデータと .ipynb ファイルは、私の Github に上げておきますのでご自由にお使いください。