はじめに
「新しい AI 機能を追加したい」──そのたびにコードを書いてデプロイして…を繰り返していませんか?
Claude Code の「スキル」機能をご存知でしょうか。PDF をスライドに変換する、Excel レポートを生成する、コードレビューを自動化する──こうした専門タスクを、Markdown ファイルを1つ追加するだけで LLM にこなせるようにする仕組みです。
いま、このスキルのエコシステムは爆発的に広がっています。Anthropic 公式のスキルに加え、コミュニティが作成したスキルがマーケットプレイスに16万件以上公開されています。2025年12月には Agent Skills の仕様がオープン標準として公開され、OpenAI の Codex CLI や ChatGPT でも同じフォーマットが採用されました。
これだけ多くのスキルが揃っているなら、自分の Web アプリにも同じ仕組みを組み込めたら、どれだけ楽に機能拡張できるだろう? そう考えて、実際にサンプルアプリ(Skill Agent Chat)を作ってみました。結果、コード変更ゼロ・デプロイ不要で新しい AI 機能を追加できる仕組みが実現できました。
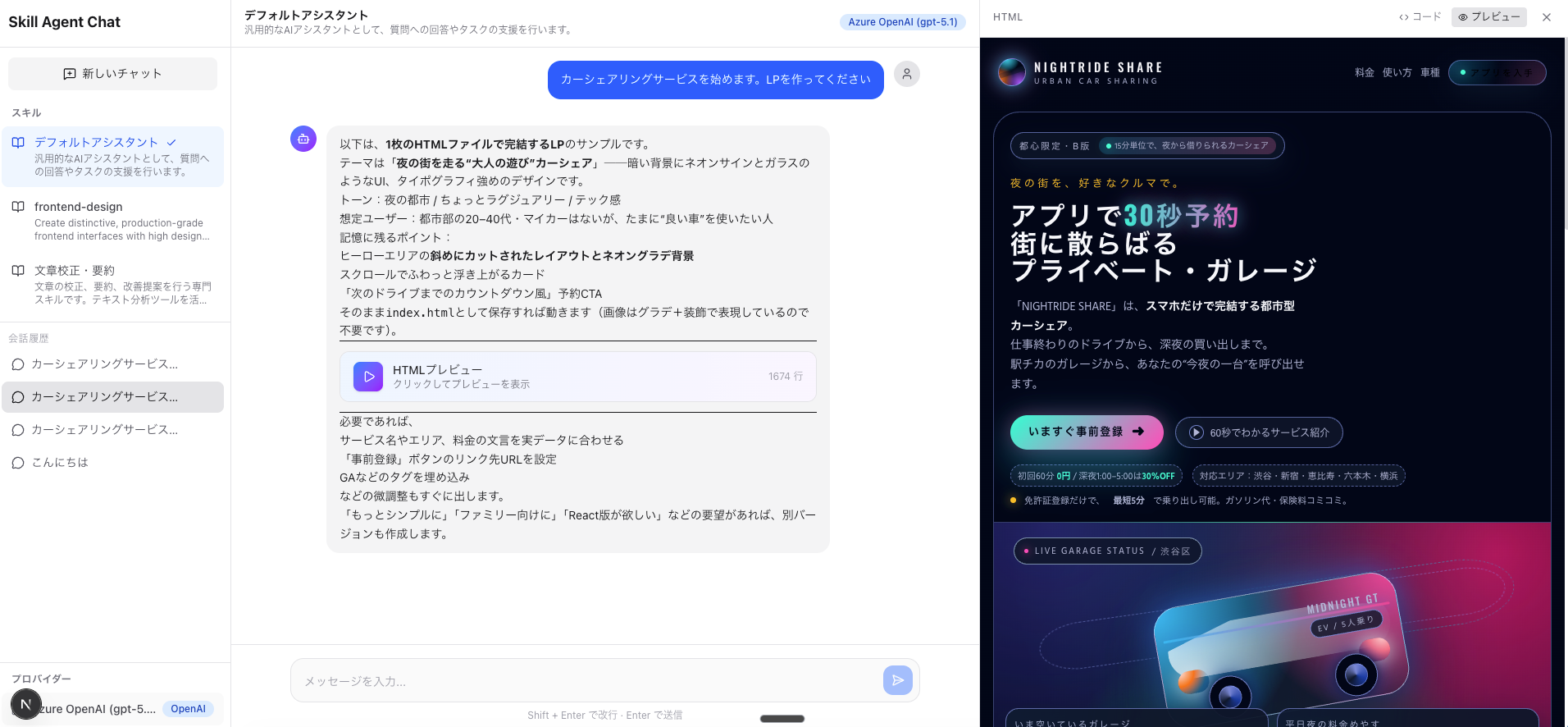
この記事では、この「スキル」の仕組みを分解し、自分の LLM エージェントアプリに同等の機能を組み込む方法をステップごとに丁寧に解説します。実際に動作するデモアプリのコードも公開しています。
対象読者:
- LLM を使ったアプリを開発している、またはこれから開発したい方
- Azure OpenAI / OpenAI API / Azure Anthropic(Azure Foundry 上の Claude)のいずれかを利用している方
- Python または TypeScript でコードが書ける方
スキルの本質 ── 3つの構成要素を理解する
まず、Claude Code の「スキル」が何で出来ているかを理解しましょう。スキルは、以下の3つの要素で構成されています。
1. システムプロンプト(SKILL.md)
スキルの「頭脳」にあたる部分です。Markdown 形式で書かれた詳細な指示書で、LLM がそのタスクをどのように遂行すべきかを定義しています。
たとえば「PDF をスライドに変換するスキル」の SKILL.md には、以下のような内容が含まれます:
- PDF の各ページをどう処理するか
- 出力する HTML のフォーマットやデザイン方針
- エラーが起きたときの対処方針
これはLLM にとっての業務マニュアルのようなものです。
2. 補助スクリプト
LLM 単体ではできない処理(ファイルの読み書き、外部コマンドの実行、画像の変換など)を担当するスクリプトです。LLM はこれらを「ツール」として呼び出します。
たとえば pdf_to_images.py は、PDF をページごとの JPEG 画像に変換するスクリプトです。LLM 自身が PDF のバイナリを直接処理するわけではなく、このスクリプトに処理を委譲します。
3. リファレンス資料
デザインパターンやテンプレート、スタイルガイドなど、LLM が参照する補助的な資料です。これがあることで、LLM は「自分の知識だけ」で動くのではなく、プロジェクト固有のルールや規約に従った出力を生成できます。
汎用 LLM で再現するための基本方針
これら3つの要素を、Azure OpenAI や OpenAI、あるいは Azure Anthropic(Azure Foundry 上の Claude)の API を使って自作アプリに組み込むには、以下の対応関係を押さえておきましょう:
| Claude Code のスキル要素 | 自作アプリでの対応 |
|---|---|
SKILL.md(指示書) |
System Message |
| 補助スクリプト | Function Calling + ローカル実行 |
| リファレンス資料 | System Message に追加、または RAG で検索 |
| エージェントループ | 自前で while / for ループを実装 |
では、1つずつ実装していきましょう。
プロジェクトのディレクトリ構成
実装に入る前に、スキル対応エージェントアプリの推奨ディレクトリ構成を確認しておきましょう。スキル定義ファイル(.md)は、アプリケーションのプロジェクトディレクトリ内に配置します。
Python 版
my-agent-app/
├── src/
│ ├── agent.py # エージェント本体(エージェントループ)
│ ├── tools.py # ツール定義と実行ロジック
│ └── skill_router.py # スキル選択ロジック(複数スキル対応時)
├── skills/ # スキル定義を格納するディレクトリ
│ ├── slide-converter.md # PDF→スライド変換スキル
│ ├── doc-generator.md # ドキュメント自動生成スキル
│ ├── code-reviewer.md # コードレビュー支援スキル
│ └── data-analyzer.md # データ分析レポート生成スキル
├── tools/ # 補助スクリプト(LLM がツールとして呼ぶ外部処理)
│ ├── pdf_to_images.py # PDF→画像変換
│ └── chart_generator.py # グラフ生成
├── references/ # リファレンス資料(スタイルガイド等)
│ ├── design-patterns.md
│ └── coding-standards.md
├── requirements.txt
└── .env # API キーなどの環境変数
TypeScript 版
my-agent-app/
├── src/
│ ├── agent.ts # エージェント本体(エージェントループ)
│ ├── tools.ts # ツール定義と実行ロジック
│ └── skill-router.ts # スキル選択ロジック(複数スキル対応時)
├── skills/ # スキル定義を格納するディレクトリ
│ ├── slide-converter.md # PDF→スライド変換スキル
│ ├── doc-generator.md # ドキュメント自動生成スキル
│ ├── code-reviewer.md # コードレビュー支援スキル
│ └── data-analyzer.md # データ分析レポート生成スキル
├── tools/ # 補助スクリプト(LLM がツールとして呼ぶ外部処理)
│ ├── pdf_to_images.py # PDF→画像変換
│ └── chart_generator.py # グラフ生成
├── references/ # リファレンス資料(スタイルガイド等)
│ ├── design-patterns.md
│ └── coding-standards.md
├── package.json
├── tsconfig.json
└── .env # API キーなどの環境変数
共通のポイント: どちらの言語でも skills/・tools/・references/ の構成は同じです。スキル定義は言語に依存しない Markdown ファイルなので、Python でも TypeScript でもそのまま使い回せます。
各ディレクトリの役割
| ディレクトリ | 役割 | 中に置くもの |
|---|---|---|
src/ |
アプリケーション本体 | エージェントループ、ツール定義、スキル選択ロジック |
skills/ |
スキル定義(LLM への指示書) |
.md ファイル。1スキル = 1ファイルが基本 |
tools/ |
補助スクリプト | LLM が Function Calling で呼び出す外部処理スクリプト |
references/ |
リファレンス資料 | デザインガイド、テンプレート、コーディング規約など |
なぜ skills/ ディレクトリを分けるのか
スキル定義をアプリコードと分離しておくと、以下のメリットがあります:
-
スキルの追加・変更がコード変更不要 ──
.mdファイルを追加・編集するだけで、新しいスキルの追加やプロンプトの改善ができる - 非エンジニアでもスキル作成が可能 ── Markdown を書ける人なら、プログラミングなしでスキルを定義できる
-
バージョン管理しやすい ── Git で
.mdファイルの変更履歴を追跡でき、プロンプトの改善過程を記録できる - テストしやすい ── 同じエージェントコードに異なるスキルを差し替えて動作を検証できる
スキルが1つだけの場合はルート直下に SKILL.md を1ファイル置くだけでも十分です。スキルが増えてきたら skills/ ディレクトリにまとめましょう。
ステップ1:システムプロンプトとして SKILL.md を組み込む
何をするのか
SKILL.md の内容を、LLM API の system message として渡します。これにより、LLM はその後の全てのやり取りにおいて、SKILL.md に書かれた指示に従って振る舞うようになります。
なぜこれが重要なのか
LLM は「何も言わなければ汎用的に振る舞う」モデルです。system message を設定することで、そのセッション全体にわたる振る舞いの方針を定義できます。
たとえば、同じ「スライドを作って」という依頼でも:
- system message なし → 汎用的なテキストベースの回答
- SKILL.md を system message に設定 → HTML/CSS を使った本格的なスライド生成
このように、system message がスキルの「知性」を担うのです。
Python 版
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint="https://your-resource.openai.azure.com/",
api_key="your-key",
api_version="2024-10-21"
)
# skills/ ディレクトリからスキル定義を読み込み
with open("skills/slide-converter.md", "r") as f:
skill_prompt = f.read()
response = client.chat.completions.create(
model="gpt-5.1",
messages=[
{"role": "system", "content": skill_prompt}, # ← ここがスキルの頭脳
{"role": "user", "content": "スライドを作成してください"}
]
)
TypeScript 版
import { AzureOpenAI } from "openai";
import { readFileSync } from "fs";
const client = new AzureOpenAI({
endpoint: "https://your-resource.openai.azure.com/",
apiKey: "your-key",
apiVersion: "2024-10-21",
});
// skills/ ディレクトリからスキル定義を読み込み
const skillPrompt = readFileSync("skills/slide-converter.md", "utf-8");
const response = await client.chat.completions.create({
model: "gpt-5.1",
messages: [
{ role: "system", content: skillPrompt }, // ← ここがスキルの頭脳
{ role: "user", content: "スライドを作成してください" },
],
});
ポイント
- SKILL.md は Markdown 形式で書かれているため、そのまま system message に渡せます
- SKILL.md が非常に長い場合は、トークン制限に注意してください。必要に応じて要約や分割を検討しましょう
- 複数のスキルを切り替えたい場合は、リクエストに応じて異なる SKILL.md を読み込むロジックを組めば OK です
ステップ2:Function Calling でツール(補助スクリプト)を登録する
何をするのか
LLM が「ファイルを書き出したい」「PDF を画像に変換したい」といった外部処理を必要とするとき、直接実行するのではなく、Function Calling という仕組みを通じてアプリ側に処理を依頼します。このステップでは、LLM に「どんなツールが使えるか」を定義します。
Function Calling とは
Function Calling は、LLM が自ら「今、この関数を呼びたい」と判断し、関数名と引数を JSON で返してくれる仕組みです。実際の関数の実行はアプリ側(あなたのコード)が行います。
この設計により、LLM は「何をすべきか考える」ことに専念し、「実際の処理」はアプリ側が安全に制御できます。
Python 版
tools = [
{
"type": "function",
"function": {
"name": "pdf_to_images",
"description": "PDFファイルを各ページのJPEG画像に変換する",
"parameters": {
"type": "object",
"properties": {
"pdf_path": {
"type": "string",
"description": "PDFファイルのパス"
},
"output_dir": {
"type": "string",
"description": "出力ディレクトリ"
},
"dpi": {
"type": "integer",
"default": 200
}
},
"required": ["pdf_path", "output_dir"]
}
}
},
{
"type": "function",
"function": {
"name": "write_file",
"description": "ファイルを書き出す",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "出力先ファイルパス"
},
"content": {
"type": "string",
"description": "ファイルの内容"
}
},
"required": ["path", "content"]
}
}
}
]
response = client.chat.completions.create(
model="gpt-5.1",
messages=messages,
tools=tools, # ← 使用可能なツールの一覧を渡す
tool_choice="auto" # ← LLM に自動判断させる
)
TypeScript 版
import { ChatCompletionTool } from "openai/resources/chat/completions";
const tools: ChatCompletionTool[] = [
{
type: "function",
function: {
name: "pdf_to_images",
description: "PDFファイルを各ページのJPEG画像に変換する",
parameters: {
type: "object",
properties: {
pdf_path: {
type: "string",
description: "PDFファイルのパス",
},
output_dir: {
type: "string",
description: "出力ディレクトリ",
},
dpi: {
type: "integer",
default: 200,
},
},
required: ["pdf_path", "output_dir"],
},
},
},
{
type: "function",
function: {
name: "write_file",
description: "ファイルを書き出す",
parameters: {
type: "object",
properties: {
path: {
type: "string",
description: "出力先ファイルパス",
},
content: {
type: "string",
description: "ファイルの内容",
},
},
required: ["path", "content"],
},
},
},
];
const response = await client.chat.completions.create({
model: "gpt-5.1",
messages,
tools, // ← 使用可能なツールの一覧を渡す
tool_choice: "auto", // ← LLM に自動判断させる
});
ツール定義のコツ
| 項目 | 説明 |
|---|---|
name |
LLM がツールを呼ぶ際の識別子。英数字とアンダースコアで命名 |
description |
最も重要。LLM はこの説明文を読んで「このツールをいつ使うべきか」を判断します。具体的かつ簡潔に書きましょう |
parameters |
JSON Schema 形式で引数を定義。description を各パラメータにも付けると、LLM がより正確に引数を生成してくれます |
required |
必須パラメータの指定。任意パラメータには default 値を設定しておくとよい |
ステップ3:エージェントループを構築する
何をするのか
ここがスキル機能の心臓部です。LLM が「考えて → ツールを呼んで → 結果を見て → また考えて…」を繰り返す エージェントループ を実装します。
なぜエージェントループが必要なのか
通常の LLM API 呼び出しは「1回の質問 → 1回の回答」で終わります。しかし、スキルが行うような複雑なタスクでは、1回のやり取りでは完了しません。
たとえば「PDF をスライドに変換して」というタスクは、内部的には以下のような複数ステップを経ます:
1. PDF を画像に変換(pdf_to_images ツール呼び出し)
2. 変換された画像の一覧を確認(list_files ツール呼び出し)
3. 各画像を見て HTML を生成(Vision + write_file ツール呼び出し)
4. 全スライドをまとめて最終確認
5. ユーザーへの完了報告
エージェントループがあることで、LLM は自律的に複数ステップを判断・実行できるようになります。
ループの基本構造
Python 版
import json
import subprocess
def execute_tool(name: str, args: dict) -> str:
"""ツール名に応じて実際の処理を実行する"""
if name == "pdf_to_images":
result = subprocess.run(
["python", "pdf_to_images.py", args["pdf_path"], args["output_dir"]],
capture_output=True,
text=True
)
return result.stdout or result.stderr
elif name == "write_file":
with open(args["path"], "w", encoding="utf-8") as f:
f.write(args["content"])
return f"Wrote {len(args['content'])} chars to {args['path']}"
elif name == "read_file":
with open(args["path"], "r", encoding="utf-8") as f:
return f.read()
else:
return f"Unknown tool: {name}"
def run_agent(user_request: str, skill_prompt: str) -> str:
"""エージェントループ:LLMが完了するまでツール呼び出しを繰り返す"""
messages = [
{"role": "system", "content": skill_prompt},
{"role": "user", "content": user_request}
]
max_iterations = 20 # 無限ループ防止の安全弁
for _ in range(max_iterations):
# ① LLM にメッセージを送信
response = client.chat.completions.create(
model="gpt-5.1",
messages=messages,
tools=tools,
tool_choice="auto"
)
msg = response.choices[0].message
messages.append(msg) # LLM の応答を会話履歴に追加
# ② ツール呼び出しがなければ → タスク完了
if not msg.tool_calls:
return msg.content
# ③ ツールを実行し、結果を会話履歴に追加
for tool_call in msg.tool_calls:
name = tool_call.function.name
args = json.loads(tool_call.function.arguments)
print(f" [Tool] {name}({args})")
result = execute_tool(name, args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
return "Max iterations reached"
# 使用例
answer = run_agent(
"PDFをHTMLスライドに変換してください: input.pdf",
skill_prompt
)
print(answer)
TypeScript 版
import { execSync } from "child_process";
import { readFileSync, writeFileSync } from "fs";
import {
ChatCompletionMessageParam,
} from "openai/resources/chat/completions";
/** ツール名に応じて実際の処理を実行する */
function executeTool(name: string, args: Record<string, unknown>): string {
switch (name) {
case "pdf_to_images": {
const result = execSync(
`python pdf_to_images.py "${args.pdf_path}" "${args.output_dir}"`,
{ encoding: "utf-8" }
);
return result;
}
case "write_file": {
writeFileSync(args.path as string, args.content as string, "utf-8");
return `Wrote ${(args.content as string).length} chars to ${args.path}`;
}
case "read_file": {
return readFileSync(args.path as string, "utf-8");
}
default:
return `Unknown tool: ${name}`;
}
}
/** エージェントループ:LLMが完了するまでツール呼び出しを繰り返す */
async function runAgent(
userRequest: string,
skillPrompt: string
): Promise<string> {
const messages: ChatCompletionMessageParam[] = [
{ role: "system", content: skillPrompt },
{ role: "user", content: userRequest },
];
const maxIterations = 20; // 無限ループ防止の安全弁
for (let i = 0; i < maxIterations; i++) {
// ① LLM にメッセージを送信
const response = await client.chat.completions.create({
model: "gpt-5.1",
messages,
tools,
tool_choice: "auto",
});
const msg = response.choices[0].message;
messages.push(msg); // LLM の応答を会話履歴に追加
// ② ツール呼び出しがなければ → タスク完了
if (!msg.tool_calls || msg.tool_calls.length === 0) {
return msg.content ?? "";
}
// ③ ツールを実行し、結果を会話履歴に追加
for (const toolCall of msg.tool_calls) {
const name = toolCall.function.name;
const args = JSON.parse(toolCall.function.arguments);
console.log(` [Tool] ${name}(${JSON.stringify(args)})`);
const result = executeTool(name, args);
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: result,
});
}
}
return "Max iterations reached";
}
// 使用例
const answer = await runAgent(
"PDFをHTMLスライドに変換してください: input.pdf",
skillPrompt
);
console.log(answer);
エージェントループの重要なポイント
max_iterations は必ず設定する
LLM が無限にツールを呼び続けるバグを防ぐためのガードレールです。タスクの複雑さに応じて 10〜30 程度が目安です。
messages 配列が「記憶」になる
エージェントループでは、LLM の応答もツールの実行結果もすべて messages 配列に蓄積していきます。これが LLM にとっての「作業メモリ」になり、過去のステップを踏まえた判断が可能になります。
ツール実行結果は role: "tool" で返す
OpenAI API では、ツールの実行結果は role: "tool" として、対応する tool_call_id と一緒に返す必要があります。これにより、LLM はどのツール呼び出しに対するどの結果かを正確に紐付けできます。
ステップ4:画像入力(Vision)を活用する
何をするのか
LLM に画像を「見せて」処理させます。たとえば、PDF から変換したスライド画像を LLM に見せて「この見た目を忠実に HTML で再現して」と指示する場合に使います。
なぜ画像入力が必要なのか
テキストだけでは伝えられない情報があります。「このスライドのレイアウトを再現して」と言葉で説明するより、画像を直接見せた方が圧倒的に正確です。
GPT-4o や Claude 4 などのマルチモーダルモデルは、画像を直接理解できるため、以下のようなタスクが可能になります:
- スライド画像 → HTML/CSS の再現
- UI のスクリーンショット → コンポーネントコードの生成
- 手書きのワイヤーフレーム → 実装コードの生成
- グラフ画像 → データの読み取り
Python 版
import base64
def encode_image(path: str) -> str:
"""画像ファイルを Base64 エンコードする"""
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode()
# 画像付きメッセージを追加
messages.append({
"role": "user",
"content": [
{
"type": "text",
"text": "この画像を忠実にHTMLで再現してください"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{encode_image('slide_001.jpg')}"
}
}
]
})
TypeScript 版
import { readFileSync } from "fs";
function encodeImage(path: string): string {
return readFileSync(path).toString("base64");
}
// 画像付きメッセージを追加
messages.push({
role: "user",
content: [
{
type: "text",
text: "この画像を忠実にHTMLで再現してください",
},
{
type: "image_url",
image_url: {
url: `data:image/jpeg;base64,${encodeImage("slide_001.jpg")}`,
},
},
],
});
画像入力の注意点
| 項目 | 推奨値・注意点 |
|---|---|
| 画像サイズ | 長辺 2000px 以下にリサイズ。大きすぎるとトークン消費が膨大になる |
| 画像形式 | JPEG が最もトークン効率が良い。PNG も使えるがファイルサイズが大きくなりがち |
| 枚数 | 1回のリクエストに複数画像を含められるが、多すぎるとコストが跳ね上がるため注意 |
| Base64 エンコード | 画像を Data URI として埋め込む。URL 参照も可能だが、ローカルファイルの場合は Base64 が確実 |
ステップ5:全要素を統合した完全版エージェント
ここまでの4つのステップ(システムプロンプト、Function Calling、エージェントループ、Vision)を全て統合した、動作する完全なサンプルコードです。
TypeScript 版(完全版)
import { AzureOpenAI } from "openai";
import { execSync } from "child_process";
import {
readFileSync,
writeFileSync,
mkdirSync,
existsSync,
readdirSync,
} from "fs";
import { join } from "path";
import {
ChatCompletionMessageParam,
ChatCompletionTool,
} from "openai/resources/chat/completions";
// ============================================================
// 設定
// ============================================================
const client = new AzureOpenAI({
endpoint: process.env.AZURE_OPENAI_ENDPOINT!,
apiKey: process.env.AZURE_OPENAI_API_KEY!,
apiVersion: "2024-10-21",
});
const MODEL = "gpt-5.1";
// ============================================================
// ツール定義
// LLM に「何ができるか」を教えるためのカタログ
// ============================================================
const tools: ChatCompletionTool[] = [
{
type: "function",
function: {
name: "pdf_to_images",
description:
"PDFを各ページのJPEG画像に変換する。pdftoppm (poppler) を使用。",
parameters: {
type: "object",
properties: {
pdf_path: { type: "string", description: "入力PDFファイルパス" },
output_dir: { type: "string", description: "画像出力ディレクトリ" },
dpi: { type: "integer", default: 200, description: "解像度 (DPI)" },
},
required: ["pdf_path", "output_dir"],
},
},
},
{
type: "function",
function: {
name: "list_files",
description: "ディレクトリ内のファイル一覧を取得する",
parameters: {
type: "object",
properties: {
dir_path: { type: "string", description: "ディレクトリパス" },
},
required: ["dir_path"],
},
},
},
{
type: "function",
function: {
name: "read_file",
description: "テキストファイルを読み込む",
parameters: {
type: "object",
properties: {
path: { type: "string", description: "ファイルパス" },
},
required: ["path"],
},
},
},
{
type: "function",
function: {
name: "write_file",
description: "テキストファイルを書き出す",
parameters: {
type: "object",
properties: {
path: { type: "string", description: "出力先ファイルパス" },
content: { type: "string", description: "ファイルの内容" },
},
required: ["path", "content"],
},
},
},
];
// ============================================================
// ツール実行エンジン
// LLM の「やりたい」を「実際の処理」に変換する層
// ============================================================
function executeTool(name: string, args: Record<string, unknown>): string {
try {
switch (name) {
case "pdf_to_images": {
const outDir = args.output_dir as string;
if (!existsSync(outDir)) mkdirSync(outDir, { recursive: true });
const dpi = (args.dpi as number) || 200;
execSync(
`pdftoppm -jpeg -r ${dpi} "${args.pdf_path}" "${join(outDir, "slide")}"`,
{ encoding: "utf-8" }
);
const files = readdirSync(outDir).filter((f) => f.endsWith(".jpg"));
return `Converted to ${files.length} images in ${outDir}`;
}
case "list_files": {
const files = readdirSync(args.dir_path as string);
return files.join("\n");
}
case "read_file":
return readFileSync(args.path as string, "utf-8");
case "write_file":
writeFileSync(args.path as string, args.content as string, "utf-8");
return `OK: wrote ${args.path}`;
default:
return `Unknown tool: ${name}`;
}
} catch (err) {
return `Error: ${(err as Error).message}`;
}
}
// ============================================================
// 画像メッセージヘルパー
// Vision API を使うためのユーティリティ
// ============================================================
function createImageMessage(
text: string,
imagePaths: string[]
): ChatCompletionMessageParam {
return {
role: "user",
content: [
{ type: "text", text },
...imagePaths.map((p) => ({
type: "image_url" as const,
image_url: {
url: `data:image/jpeg;base64,${readFileSync(p).toString("base64")}`,
},
})),
],
};
}
// ============================================================
// エージェントループ(心臓部)
// 「考える → 行動する → 観察する」のサイクルを回す
// ============================================================
async function runAgent(
userRequest: string,
skillPrompt: string
): Promise<string> {
const messages: ChatCompletionMessageParam[] = [
{ role: "system", content: skillPrompt },
{ role: "user", content: userRequest },
];
for (let i = 0; i < 30; i++) {
console.log(`\n--- Iteration ${i + 1} ---`);
const response = await client.chat.completions.create({
model: MODEL,
messages,
tools,
tool_choice: "auto",
});
const msg = response.choices[0].message;
messages.push(msg);
if (msg.content) {
console.log(`[Assistant] ${msg.content.slice(0, 200)}...`);
}
// ツール呼び出しがなければタスク完了
if (!msg.tool_calls || msg.tool_calls.length === 0) {
return msg.content ?? "";
}
// 各ツール呼び出しを実行し、結果を返す
for (const toolCall of msg.tool_calls) {
const fnName = toolCall.function.name;
const fnArgs = JSON.parse(toolCall.function.arguments);
console.log(` [Tool] ${fnName}(${JSON.stringify(fnArgs)})`);
const result = executeTool(fnName, fnArgs);
console.log(` [Result] ${result.slice(0, 100)}`);
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: result,
});
}
}
return "Max iterations reached";
}
// ============================================================
// メイン
// ============================================================
async function main() {
const skillPrompt = readFileSync("skills/slide-converter.md", "utf-8");
const pdfPath = process.argv[2];
if (!pdfPath) {
console.error("Usage: npx tsx agent.ts <pdf_path>");
process.exit(1);
}
const result = await runAgent(
`以下のPDFをHTMLスライドに変換してください: ${pdfPath}`,
skillPrompt
);
console.log("\n=== 完了 ===");
console.log(result);
}
main();
補足:Azure Anthropic(Azure Foundry 上の Claude)で実装する場合
ここまでのサンプルは Azure OpenAI(GPT 系モデル)を前提にしていましたが、Azure Foundry 上の Claude モデルでもまったく同じ設計パターンでスキル機能を実現できます。
Azure Foundry では以下の Claude モデルが利用可能で、Anthropic の Messages API(tool_use 含む)がそのまま使えます。
| モデル | デプロイメント名 |
|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
| Claude Opus 4.5 | claude-opus-4-5 |
| Claude Sonnet 4.5 | claude-sonnet-4-5 |
| Claude Opus 4.1 | claude-opus-4-1 |
| Claude Haiku 4.5 | claude-haiku-4-5 |
SDK のインストール
Azure Foundry 上の Claude を使うには、Foundry 専用の SDK をインストールします。
# Python
pip install -U anthropic
# TypeScript
npm install @anthropic-ai/foundry-sdk
Azure OpenAI との主な違い
| 項目 | Azure OpenAI(GPT) | Azure Anthropic(Claude) |
|---|---|---|
| SDK |
openai パッケージ |
anthropic(Python) / @anthropic-ai/foundry-sdk(TS) |
| クライアント | AzureOpenAI |
AnthropicFoundry |
| API 形式 | Chat Completions API | Messages API |
| ツール呼び出し |
function type + tool_calls
|
tool_use type + tool_use content block |
| ツール結果の返し方 | role: "tool" |
role: "user" + tool_result content block |
| 画像入力 |
image_url type |
image type + source block |
| エンドポイント | https://<resource>.openai.azure.com/ |
https://<resource>.services.ai.azure.com/anthropic |
Python 版:クライアント初期化
import os
from anthropic import AnthropicFoundry
# Azure Foundry 上の Claude に接続
# resource 指定の場合(SDK が URL を自動構築)
client = AnthropicFoundry(
api_key=os.environ.get("ANTHROPIC_FOUNDRY_API_KEY"),
resource="your-resource-name", # ← リソース名だけでOK
)
# または base_url を直接指定する場合(resource と排他)
# client = AnthropicFoundry(
# api_key=os.environ.get("ANTHROPIC_FOUNDRY_API_KEY"),
# base_url="https://your-resource.services.ai.azure.com/anthropic",
# )
Python 版:ツール定義(Anthropic 形式)
Anthropic の tool_use は OpenAI の Function Calling と構造が似ていますが、書き方が少し異なります。
tools = [
{
"name": "pdf_to_images",
"description": "PDFファイルを各ページのJPEG画像に変換する",
"input_schema": { # ← OpenAI では "parameters"
"type": "object",
"properties": {
"pdf_path": {
"type": "string",
"description": "PDFファイルのパス"
},
"output_dir": {
"type": "string",
"description": "出力ディレクトリ"
},
"dpi": {
"type": "integer",
"description": "解像度 (DPI)"
}
},
"required": ["pdf_path", "output_dir"]
}
},
{
"name": "write_file",
"description": "ファイルを書き出す",
"input_schema": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "出力先ファイルパス"
},
"content": {
"type": "string",
"description": "ファイルの内容"
}
},
"required": ["path", "content"]
}
}
]
Python 版:エージェントループ
Messages API ではレスポンスの構造が異なるため、ツール呼び出しの判定・結果の返し方が変わります。
import json
def run_agent_anthropic(user_request: str, skill_prompt: str) -> str:
"""Azure Anthropic 版エージェントループ"""
messages = [
{"role": "user", "content": user_request}
]
max_iterations = 20
for _ in range(max_iterations):
# ① Claude にメッセージを送信
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
system=skill_prompt, # ← system は別パラメータで渡す
messages=messages,
tools=tools
)
# ② stop_reason で判定("end_turn" なら完了、"tool_use" ならツール呼び出し)
if response.stop_reason == "end_turn":
# テキストブロックを結合して返す
return "".join(
block.text for block in response.content
if block.type == "text"
)
# ③ アシスタントの応答を会話履歴に追加
messages.append({
"role": "assistant",
"content": response.content # content block をそのまま渡す
})
# ④ tool_use ブロックを探してツールを実行
tool_results = []
for block in response.content:
if block.type == "tool_use":
name = block.name
args = block.input
print(f" [Tool] {name}({args})")
result = execute_tool(name, args)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id, # ← OpenAI の tool_call_id に相当
"content": result
})
# ⑤ ツール結果を user ロールで返す(Anthropic の仕様)
messages.append({
"role": "user",
"content": tool_results
})
return "Max iterations reached"
TypeScript 版:クライアント初期化とエージェントループ
import AnthropicFoundry from "@anthropic-ai/foundry-sdk";
import {
MessageParam,
Tool,
} from "@anthropic-ai/foundry-sdk/resources/messages";
// Azure Foundry 上の Claude に接続
const client = new AnthropicFoundry({
apiKey: process.env.ANTHROPIC_FOUNDRY_API_KEY!,
resource: "your-resource-name", // ← リソース名だけでOK
});
// ツール定義(Anthropic 形式)
const tools: Tool[] = [
{
name: "pdf_to_images",
description: "PDFファイルを各ページのJPEG画像に変換する",
input_schema: {
type: "object" as const,
properties: {
pdf_path: { type: "string", description: "PDFファイルのパス" },
output_dir: { type: "string", description: "出力ディレクトリ" },
dpi: { type: "integer", description: "解像度 (DPI)" },
},
required: ["pdf_path", "output_dir"],
},
},
{
name: "write_file",
description: "ファイルを書き出す",
input_schema: {
type: "object" as const,
properties: {
path: { type: "string", description: "出力先ファイルパス" },
content: { type: "string", description: "ファイルの内容" },
},
required: ["path", "content"],
},
},
];
/** Azure Anthropic 版エージェントループ */
async function runAgentAnthropic(
userRequest: string,
skillPrompt: string
): Promise<string> {
const messages: MessageParam[] = [
{ role: "user", content: userRequest },
];
for (let i = 0; i < 30; i++) {
console.log(`\n--- Iteration ${i + 1} ---`);
// ① Claude にメッセージを送信
const response = await client.messages.create({
model: "claude-sonnet-4-5",
max_tokens: 4096,
system: skillPrompt, // ← system は別パラメータ
messages,
tools,
});
// ② stop_reason で判定
if (response.stop_reason === "end_turn") {
return response.content
.filter((block): block is AnthropicFoundry.TextBlock => block.type === "text")
.map((block) => block.text)
.join("");
}
// ③ アシスタントの応答を会話履歴に追加
messages.push({
role: "assistant",
content: response.content,
});
// ④ tool_use ブロックを探してツールを実行
const toolResults: AnthropicFoundry.ToolResultBlockParam[] = [];
for (const block of response.content) {
if (block.type === "tool_use") {
const name = block.name;
const args = block.input as Record<string, unknown>;
console.log(` [Tool] ${name}(${JSON.stringify(args)})`);
const result = executeTool(name, args);
toolResults.push({
type: "tool_result",
tool_use_id: block.id,
content: result,
});
}
}
// ⑤ ツール結果を user ロールで返す
messages.push({
role: "user",
content: toolResults,
});
}
return "Max iterations reached";
}
画像入力(Vision)の違い
Azure Anthropic で画像を送る場合、OpenAI とは形式が異なります。
# Azure Anthropic(Claude)の画像入力
messages.append({
"role": "user",
"content": [
{
"type": "text",
"text": "この画像を忠実にHTMLで再現してください"
},
{
"type": "image", # ← OpenAI では "image_url"
"source": { # ← OpenAI では "image_url.url"
"type": "base64",
"media_type": "image/jpeg",
"data": encode_image("slide_001.jpg")
}
}
]
})
OpenAI 形式と Anthropic 形式の早見表
| 概念 | OpenAI(Azure OpenAI) | Anthropic(Azure Anthropic) |
|---|---|---|
| system message |
messages 内に role: "system"
|
system パラメータで別途指定 |
| ツール定義のスキーマ | parameters |
input_schema |
| ツール呼び出しの検出 |
msg.tool_calls の有無 |
stop_reason === "tool_use" |
| ツール結果の返却 | role: "tool" |
role: "user" + type: "tool_result"
|
| 画像の送り方 |
type: "image_url" + Data URI |
type: "image" + source ブロック |
| 完了判定 |
tool_calls が無い |
stop_reason === "end_turn" |
設計パターンは同じ、API の書き方だけが違う ── これが最も重要なポイントです。スキルの本質(SKILL.md + ツール + エージェントループ)はモデルやプロバイダーに依存しないため、クライアント初期化とメッセージ構造を差し替えるだけで移行できます。
実践ユースケース集
ここまでの実装パターンを応用して、さまざまなスキルを自作エージェントに組み込めます。以下に具体的なユースケースを紹介します。
ユースケース1:ドキュメント自動生成エージェント
シナリオ: ソースコードを読み取り、API ドキュメントを自動生成する
SKILL.md の内容:
- ソースコードから公開 API を抽出するルール
- ドキュメントのフォーマット(JSDoc / OpenAPI 形式)
- 出力テンプレート
ツール:
- read_file: ソースコードの読み取り
- list_files: プロジェクト構造の把握
- write_file: ドキュメントの書き出し
エージェントの動作:
1. プロジェクトのファイル一覧を取得
2. 各ソースファイルを読み取り
3. 公開 API を分析
4. ドキュメントを生成・書き出し
得られる効果: コードに変更が入るたびに、最新のドキュメントを自動生成できる。人手によるドキュメントの陳腐化を防止。
ユースケース2:データ分析レポート生成エージェント
シナリオ: CSV データを読み込み、分析レポートを生成する
SKILL.md の内容:
- データ分析の手順(概要 → 詳細 → 考察)
- グラフ生成のルール
- レポートのフォーマット
ツール:
- read_file: CSV データの読み取り
- execute_python: Python スクリプトの実行(pandas, matplotlib)
- write_file: レポート(HTML / PDF)の書き出し
エージェントの動作:
1. CSV ファイルを読み込みデータ構造を把握
2. 基本統計量を算出
3. グラフを生成(Python スクリプト経由)
4. 分析結果をまとめたレポートを書き出し
得られる効果: 非エンジニアでも「この CSV を分析して」と依頼するだけで、整形されたレポートが手に入る。
ユースケース3:コードレビュー支援エージェント
シナリオ: Git の差分を読み取り、コードレビューコメントを生成する
SKILL.md の内容:
- レビュー観点(セキュリティ、パフォーマンス、可読性)
- コメントのトーンやフォーマット
- プロジェクト固有のコーディング規約
ツール:
- execute_command: git diff の実行
- read_file: 関連ファイルの読み取り
- post_review: レビューコメントの投稿(GitHub API 連携)
エージェントの動作:
1. git diff で変更差分を取得
2. 変更されたファイルの全体を読み取り(コンテキスト把握)
3. 変更内容を分析し、レビューコメントを生成
4. GitHub にコメントを投稿
得られる効果: PR が作られた時点で自動的に一次レビューが走り、レビュアーの負担を軽減。
ユースケース4:社内ナレッジ検索&回答エージェント
シナリオ: 社内ドキュメントを検索し、質問に回答する
SKILL.md の内容:
- 回答のフォーマット(出典を必ず示す)
- 「わからない」場合の対応方針
- 社内用語の定義
ツール:
- search_documents: ベクトル検索(RAG)
- read_file: ドキュメント全文の読み取り
エージェントの動作:
1. ユーザーの質問をベクトル検索にかける
2. 関連ドキュメントを取得
3. 必要に応じて追加検索(深掘り)
4. 出典付きで回答を生成
得られる効果: 社内 FAQ や手順書を探す時間を大幅に短縮。新入社員のオンボーディング支援にも活用可能。
アーキテクチャ全体像
ここまでの内容を俯瞰すると、スキル対応エージェントのアーキテクチャは以下のようになります。
応用:複数スキルの切り替え
実用的なエージェントでは、複数のスキルを持ち、ユーザーの依頼内容に応じて適切なスキルを切り替えたいケースがあります。
スキルルーター(ディスパッチャー)の実装例
import os
import glob
def load_skills(skills_dir: str) -> dict[str, str]:
"""スキルディレクトリから全スキルを読み込む"""
skills = {}
for skill_file in glob.glob(os.path.join(skills_dir, "*.md")):
skill_name = os.path.splitext(os.path.basename(skill_file))[0]
with open(skill_file, "r") as f:
skills[skill_name] = f.read()
return skills
def select_skill(user_request: str, skills: dict[str, str]) -> str:
"""ユーザーの依頼に最適なスキルを選択する(LLM に判断させる)"""
skill_list = "\n".join(
f"- {name}: {content[:100]}..."
for name, content in skills.items()
)
response = client.chat.completions.create(
model="gpt-5.1",
messages=[
{
"role": "system",
"content": "ユーザーの依頼に最も適したスキル名を1つだけ回答してください。"
},
{
"role": "user",
"content": f"利用可能なスキル:\n{skill_list}\n\n依頼: {user_request}"
}
]
)
selected = response.choices[0].message.content.strip()
return skills.get(selected, skills[list(skills.keys())[0]])
# 使用例
skills = load_skills("./skills/")
# skills = {"slide-converter": "...", "doc-generator": "...", "code-reviewer": "..."}
user_request = "このPDFをプレゼン用のHTMLにしてほしい"
skill_prompt = select_skill(user_request, skills)
answer = run_agent(user_request, skill_prompt)
この仕組みにより、1つのエージェントアプリが複数の専門スキルを持つ万能アシスタントとして機能するようになります。
推奨フレームワーク
エージェントループを一から書くのが大変な場合は、以下のフレームワークの利用を検討してください。
| フレームワーク | 言語 | 特徴 | 向いているケース |
|---|---|---|---|
| LangChain | Python / TS | 最も広く使われる LLM フレームワーク。ツール定義・エージェントループが簡潔に書ける | 汎用的な LLM アプリ全般 |
| Semantic Kernel | C# / Python / Java | Microsoft 公式。Azure OpenAI との統合が手厚い | 企業向け・Azure ベースのアプリ |
| AutoGen | Python | マルチエージェント構成に強い | 複数エージェントの協調が必要な場面 |
| Vercel AI SDK | TypeScript | Next.js / React との統合に優れる。ストリーミング対応が充実 | Web アプリのフロントエンド統合 |
| Mastra | TypeScript | エージェントフレームワーク。ツール定義が型安全 | TypeScript で型安全に作りたい場合 |
フレームワーク選定のポイント
- プロトタイプをすぐに作りたい → LangChain(ドキュメントとコミュニティが充実)
- Azure 環境で本番運用したい → Semantic Kernel(Microsoft 公式サポート)
- Web アプリに組み込みたい → Vercel AI SDK(React との親和性が高い)
- 型安全を重視したい → Mastra(TypeScript ファースト)
- 複数のエージェントを連携させたい → AutoGen(マルチエージェント設計)
本番運用時の注意事項
スキル対応エージェントを本番環境で運用する際には、以下の点に注意してください。
トークン制限
SKILL.md が長い場合、system message だけで大量のトークンを消費します。対策として:
- SKILL.md を必要最小限に簡潔化する
- タスクに応じて SKILL.md の必要な部分だけを動的に選択する
- 長いリファレンス資料は RAG(検索拡張生成)で必要な部分だけ取得する
コスト管理
エージェントループは、1回のユーザーリクエストに対して複数回の API 呼び出しが発生します。
1回のタスク = ループ回数 × (入力トークン + 出力トークン)
対策として:
-
max_iterationsを適切に設定する - 各イテレーションのトークン使用量をログに記録する
- コスト上限(バジェット)を設けて超過時は処理を中断する
エラーハンドリング
ツール実行が失敗した場合、そのエラー情報を LLM にフィードバックしましょう。LLM はエラー内容を読んで、リトライや代替手段を自律的に判断できます。
def execute_tool(name: str, args: dict) -> str:
try:
# ... ツールの実行
except Exception as e:
# エラー情報を LLM に返す(LLM がリカバリ方法を考える)
return f"Error executing {name}: {str(e)}"
セキュリティ
LLM がツールを通じてファイル操作やコマンド実行を行うため、以下の対策が重要です:
- サンドボックス化: ツールがアクセスできるディレクトリやコマンドを制限する
- 入力バリデーション: LLM が生成した引数(ファイルパスなど)を検証する
- 実行前確認: 破壊的な操作(ファイル削除など)はユーザーの承認を得てから実行する
デモアプリ:Skill Agent Chat
ここまで解説してきたスキル機能の実装パターン(システムプロンプト切替、Function Calling、エージェントループ)を、実際に動作する Web チャットアプリとしてまとめました。
技術スタック
| カテゴリ | 技術 |
|---|---|
| フレームワーク | Next.js 16(App Router) |
| 言語 | TypeScript / React 19 |
| AI SDK | Vercel AI SDK v6(ai, @ai-sdk/react) |
| LLM プロバイダー | OpenAI / Azure OpenAI / Azure Anthropic(環境変数で切替) |
| データベース | SQLite(better-sqlite3)+ Drizzle ORM |
| CSS | Tailwind CSS v4 |
プロジェクト構成
skill-agent-chat/
├── skills/ # スキル定義ファイル
│ ├── default.md # デフォルトアシスタント
│ ├── frontend-design/SKILL.md # フロントエンドデザイン
│ └── text-proofreading/SKILL.md # 文章校正・要約
├── src/
│ ├── app/api/
│ │ ├── chat/route.ts # チャットAPI(エージェントループ)
│ │ ├── skills/route.ts # スキル一覧API
│ │ └── conversations/ # 会話CRUD API
│ ├── lib/
│ │ ├── db/ # SQLiteデータベース
│ │ ├── providers.ts # LLMプロバイダー切替
│ │ ├── skills.ts # スキル読み込み
│ │ └── tools.ts # ツール定義
│ ├── components/
│ │ ├── chat/ # チャットUI(HTMLライブプレビュー含む)
│ │ └── sidebar/ # サイドバー(スキル選択・会話履歴)
│ └── hooks/
│ └── use-skill-chat.ts # チャット管理フック
└── .env.example
プリセットスキル
アプリには3つのプリセットスキルが付属しています。いずれも skills/ ディレクトリの Markdown ファイルで定義されています。
| スキル | 内容 |
|---|---|
| デフォルトアシスタント | 汎用的な質問応答・タスク支援。テキスト分析・Web検索・日時取得のツールを自動活用 |
| frontend-design | プロダクション品質のHTML/CSS/JSを生成する専門スキル。「ありがちなAIデザイン」を避け、タイポグラフィ・配色・モーションにこだわった独創的なUIを設計。生成したHTMLはサイドパネルでライブプレビュー可能 |
| 文章校正・要約 | 日本語テキストの校正・要約・改善提案。まず analyzeText ツールで文字数・段落数を自動計測し、その結果を踏まえて修正案を提示 |
frontend-design スキルは、スキルの指示書(プロンプト)だけでここまで専門的な振る舞いを実現できるという好例です。
主要コードの解説
スキル読み込み(src/lib/skills.ts)
skills/ ディレクトリから Markdown ファイルを読み込み、YAML frontmatter をパースしてスキル一覧を構築します。この記事のステップ1(SKILL.md をシステムプロンプトとして組み込む)に対応する部分です。
import fs from "fs";
import path from "path";
const SKILLS_DIR = path.join(process.cwd(), "skills");
function parseFrontmatter(content: string) {
const match = content.match(/^---\s*\n([\s\S]*?)\n---\s*\n([\s\S]*)$/);
if (!match) return { name: "", description: "", body: content };
const frontmatter = match[1];
const nameMatch = frontmatter.match(/^name:\s*(.+)$/m);
const descMatch = frontmatter.match(/^description:\s*(.+)$/m);
return {
name: nameMatch?.[1]?.trim() ?? "",
description: descMatch?.[1]?.trim() ?? "",
body: match[2].trim(),
};
}
export function loadSkills() {
const skills = [];
// ルート直下の .md ファイル
const defaultPath = path.join(SKILLS_DIR, "default.md");
if (fs.existsSync(defaultPath)) {
const { name, description, body } = parseFrontmatter(
fs.readFileSync(defaultPath, "utf-8")
);
skills.push({ id: "default", name, description, content: body });
}
// サブディレクトリ内の SKILL.md
for (const entry of fs.readdirSync(SKILLS_DIR, { withFileTypes: true })) {
if (!entry.isDirectory()) continue;
const skillPath = path.join(SKILLS_DIR, entry.name, "SKILL.md");
if (!fs.existsSync(skillPath)) continue;
const { name, description, body } = parseFrontmatter(
fs.readFileSync(skillPath, "utf-8")
);
skills.push({ id: entry.name, name, description, content: body });
}
return skills;
}
LLM プロバイダー切替(src/lib/providers.ts)
環境変数 LLM_PROVIDER の値に応じて、OpenAI / Azure OpenAI / Azure Anthropic を切り替えます。Vercel AI SDK の createOpenAI / createAzure / createAnthropic を使い分けるだけなので、アプリ側のコードは共通です。
import { createAzure } from "@ai-sdk/azure";
import { createAnthropic } from "@ai-sdk/anthropic";
import { createOpenAI } from "@ai-sdk/openai";
import type { LanguageModel } from "ai";
export type LLMProvider = "azure-openai" | "azure-anthropic" | "openai";
export function getModel(): LanguageModel {
const provider = process.env.LLM_PROVIDER ?? "azure-openai";
if (provider === "openai") {
const openai = createOpenAI({ apiKey: process.env.OPENAI_API_KEY });
return openai(process.env.OPENAI_MODEL ?? "gpt-4o");
}
if (provider === "azure-openai") {
const azure = createAzure({
resourceName: new URL(process.env.AZURE_OPENAI_ENDPOINT!).hostname.split(".")[0],
apiKey: process.env.AZURE_OPENAI_API_KEY,
});
return azure(process.env.AZURE_OPENAI_DEPLOYMENT_NAME ?? "gpt-5.1");
}
// azure-anthropic
const resource = process.env.AZURE_ANTHROPIC_RESOURCE ?? "";
const anthropic = createAnthropic({
baseURL: `https://${resource}.services.ai.azure.com/anthropic`,
apiKey: process.env.AZURE_ANTHROPIC_API_KEY,
});
return anthropic(process.env.AZURE_ANTHROPIC_MODEL ?? "claude-sonnet-4-5");
}
ツール定義(src/lib/tools.ts)
Vercel AI SDK の tool() ヘルパーと Zod スキーマでツールを定義します。この記事のステップ2(Function Calling でツールを登録する)に対応します。
import { tool } from "ai";
import { z } from "zod";
export const demoTools = {
analyzeText: tool({
description: "テキストを分析し、文字数・段落数・文の数などの統計情報を返します。",
inputSchema: z.object({
text: z.string().describe("分析対象のテキスト"),
}),
execute: async ({ text }) => ({
charCount: text.length,
paragraphCount: text.split(/\n\s*\n/).filter((p) => p.trim()).length,
sentenceCount: text.split(/[。!?.!?]+/).filter((s) => s.trim()).length,
}),
}),
searchWeb: tool({
description: "キーワードでWeb検索を実行します(デモ用モックデータ)。",
inputSchema: z.object({
query: z.string().describe("検索クエリ"),
}),
execute: async ({ query }) => ({
query,
results: [
{ title: `「${query}」に関する最新記事`, url: "https://example.com/article-1" },
{ title: `${query} - 入門ガイド`, url: "https://example.com/guide" },
],
note: "デモ用のモックデータです。",
}),
}),
getCurrentDateTime: tool({
description: "現在の日時を取得します。",
inputSchema: z.object({}),
execute: async () => ({
formatted: new Date().toLocaleString("ja-JP", { timeZone: "Asia/Tokyo" }),
timezone: "Asia/Tokyo",
}),
}),
};
チャット API — エージェントループ(src/app/api/chat/route.ts)
ここが心臓部です。streamText + stopWhen: stepCountIs(10) でエージェントループを実現しています。この記事のステップ3(エージェントループ)を Vercel AI SDK で実装したものです。
import { streamText, stepCountIs, convertToModelMessages } from "ai";
import { getModel } from "@/lib/providers";
import { getSkillById } from "@/lib/skills";
import { demoTools } from "@/lib/tools";
export async function POST(req: Request) {
const { messages, skillId } = await req.json();
const skill = getSkillById(skillId ?? "default");
const systemPrompt = skill?.content ?? "あなたは親切なAIアシスタントです。";
// UIMessage → ModelMessage に変換
const modelMessages = await convertToModelMessages(messages, {
tools: demoTools,
});
const result = streamText({
model: getModel(), // 環境変数でプロバイダー切替
system: systemPrompt, // ← スキルの SKILL.md がここに入る
messages: modelMessages,
tools: demoTools, // ← Function Calling のツール一覧
stopWhen: stepCountIs(10), // ← エージェントループの上限(安全弁)
});
return result.toUIMessageStreamResponse();
}
Vercel AI SDK v6 では、自前で while ループを書く必要がありません。streamText に stopWhen を渡すだけで、LLM がツールを呼び出すたびに自動的に次のステップへ進み、ツール呼び出しが無くなった時点でストリームが完了します。
セットアップと動かし方
git clone https://github.com/nogataka/skill-agent-chat.git
cd skill-agent-chat
npm install
cp .env.example .env.local
# .env.local を編集してAPIキーを設定
npm run dev
.env.local の設定例(OpenAI を使う場合):
LLM_PROVIDER=openai
OPENAI_API_KEY=sk-your-api-key
OPENAI_MODEL=gpt-4o
対応プロバイダー
環境変数 LLM_PROVIDER
|
必要な環境変数 |
|---|---|
openai |
OPENAI_API_KEY, OPENAI_MODEL
|
azure-openai |
AZURE_OPENAI_ENDPOINT, AZURE_OPENAI_API_KEY, AZURE_OPENAI_DEPLOYMENT_NAME
|
azure-anthropic |
AZURE_ANTHROPIC_RESOURCE, AZURE_ANTHROPIC_API_KEY, AZURE_ANTHROPIC_MODEL
|
スキルの追加方法
skills/ ディレクトリに Markdown ファイルを追加するだけで、サイドバーに新しいスキルが表示されます。
---
name: 文章校正・要約
description: 文章の校正、要約、改善提案を行う専門スキルです。
---
あなたは文章校正と要約の専門家です。
## 作業手順
1. まず `analyzeText` ツールを使って文章の基本統計を分析してください
2. 分析結果を踏まえて、校正・要約・改善提案を行ってください
コードの変更は一切不要です。これが「スキル定義をコードと分離する」設計の実践例です。
まとめ
Claude Code のスキル機能を自作エージェントに組み込むための要点を振り返ります。
| ステップ | やること | 対応する概念 |
|---|---|---|
| 1 | SKILL.md を system message に設定 | LLM に「専門知識」を与える |
| 2 | Function Calling でツールを定義 | LLM に「手足」を与える |
| 3 | エージェントループを実装 | LLM に「自律的に動く能力」を与える |
| 4 | Vision API で画像入力に対応 | LLM に「目」を与える |
| 5 | 全要素を統合して完成 | 専門スキルを持つエージェントの完成 |
スキルの本質は、「LLM に対して、特定の専門領域で高品質な成果を出すための知識・道具・行動パターンを一式提供する仕組み」 です。
この設計パターンを理解すれば、Azure OpenAI でも Azure Anthropic(Claude)でも OpenAI でも、あるいは他の LLM API でも、同じ考え方でスキル機能を実装できます。API の書き方は異なっても、スキルの設計思想はプロバイダーに依存しません。まずは小さなスキル(ファイル読み書き + シンプルな指示)から始めて、徐々にツールやプロンプトを充実させていくことをおすすめします。