はじめに
Claude Codeを使っていて、こんな経験はないでしょうか。
- CLAUDE.mdにルールを書いたのに守ってくれない
- プロジェクトの暗黙の了解を毎回説明するのが手間
- プロンプトが肥大化してコンテキストを圧迫している
これらの問題に対して、2026年3月に発表された論文が新しいアプローチを提案しています。
NFD(Nurture-First Development:育成優先開発) と名付けられたこの手法は、エージェントを「プロンプトで書く」のではなく「対話を通じて育てる」というパラダイムシフトです。
本記事では、NFDの理論を解説したうえで、Claude Codeの機能を使って今日から実践できる具体的な手順を紹介します。
従来アプローチの限界
現在のAIエージェント開発には、2つの主流なアプローチがあります。
| アプローチ | 方法 | 課題 |
|---|---|---|
| コードファースト | if文やパイプラインでハードコーディング | 暗黙知を表現できない |
| プロンプトファースト | システムプロンプトにルールを網羅的に記述 | 巨大化してコンテキストを圧迫 |
しかし、実務で使われる専門知識には3つの厄介な特性があります。
- 暗黙的(Tacit) ── 「この命名はイマイチ」「このエラーは無視していい」など、直面して初めて言語化できる
- 個人的(Personal) ── 同じタスクでも人によってアプローチが異なる
- 進化的(Evolving) ── プロジェクトの状況変化で正解が変わり続ける
事前定義では流動的な知識を捉えきれず、論文ではこれをコンフィギュレーション・ギャップと呼んでいます。CLAUDE.mdに「完璧なルール」を書こうとして挫折した経験がある方は、まさにこのギャップに直面しています。
NFDの核心:3つのパラダイムシフト
NFDは以下の3つの発想転換を提案しています。
1. 開発と運用の境界をなくす
従来のコードファースト・プロンプトファーストでは、「作ってからデプロイ」という直線的な流れでした。NFDでは「使いながら作り、作りながら使う」を同時に進めます。
2. 知識は対話から自然に移転する
マニュアルを読ませるのではなく、一緒に仕事をする中で知識を伝えます。「なぜその判断をしたのか?」を議論する徒弟制度のようなイメージです。
3. 結晶化としてのエンジニアリング
開発者の仕事はプロンプトを書くことではなく、日々の対話ログから再利用可能なルールを抽出して結晶化することです。
3層認知アーキテクチャ
NFDでは、エージェントの知識を1つの巨大なプロンプトにまとめるのではなく、更新頻度と抽象度に応じて3つのレイヤーに分割します。
Claude Codeでのマッピング
この3層は、Claude Codeの既存機能にそのまま対応します。
| レイヤー | Claude Codeでの実装 | コンテキスト占有 |
|---|---|---|
| 基盤層 | CLAUDE.md |
10〜15%(毎セッション読み込み) |
| スキル層 |
.claude/skills/ や外部スキル |
必要時のみ読み込み |
| 経験層 |
.claude/memory/ やセッションログ |
検索で参照 |
それぞれの具体的な構成例を見てみましょう。
基盤層:CLAUDE.mdの設計
基盤層にはアイデンティティと原則だけを書きます。詳細な手順やルールは書かないのがポイントです。
# プロジェクト概要
TypeScript + Next.js のSaaSプロダクト。
チーム3名、2週間スプリント。
## 基本原則
- テスト駆動で実装する(テストを先に書く)
- 既存コードを読んでから変更する
- 1PRあたりの変更は300行以内に収める
## コーディングスタイル
- 関数型を優先(副作用を局所化)
- エラーは Result 型で表現
- 命名は具体的に(data, info, handler は避ける)
## 参照
- アーキテクチャ詳細 → skills/ のドキュメント
- 過去の判断履歴 → memory/ のログ
ここでのポイントは「索引と原則」を書き、詳細はスキル層に委譲していることです。論文ではコンテキストウィンドウの10〜15%に収めることを推奨しています。
スキル層:タスク別のスキルファイル
スキル層はモジュール化された知識で、必要なときだけ読み込まれます。
# コードレビュースキル
## 観点
1. 型安全性: any の使用、型アサーションの妥当性
2. エラーハンドリング: 想定外の入力への対処
3. パフォーマンス: N+1クエリ、不要な再レンダリング
4. セキュリティ: SQLインジェクション、XSS
## プロジェクト固有の注意点
- UserRepository の findById は null を返す可能性がある
→ 必ず null チェックを確認
- 決済関連の金額計算は Decimal 型を使用
→ float での計算はレビューで即指摘
## 過去のレビューで頻出した指摘
- [ERROR] useEffect の依存配列漏れ(2026-02, 3回発生)
- [ERROR] APIレスポンスの型定義が実態と乖離(2026-01)
スキルファイルの特徴は、プロジェクト固有の経験が反映されている点です。汎用的なレビュー観点だけでなく、「過去に何度も指摘した問題」が含まれています。これが後述する「結晶化」の成果物です。
経験層:日々のログ蓄積
経験層は対話の中で自然に蓄積される生データです。
# 2026-03-17 セッションログ
## [DECISION] API設計の判断
- ページネーションをoffset方式からcursor方式に変更
- 理由: データ量増加でoffsetのパフォーマンスが劣化
- 影響範囲: /api/users, /api/orders の2エンドポイント
## [ERROR] テスト失敗の原因
- UserService.create のテストがCI環境で失敗
- 原因: タイムゾーン依存のDate比較
- 対処: テスト内でタイムゾーンを固定
## [INSIGHT] コンポーネント設計
- フォームのバリデーションロジックをカスタムフックに分離すると
テストが書きやすくなる
- 今後のフォーム実装ではこのパターンを標準にしたい
[DECISION]、[ERROR]、[INSIGHT] のタグを付けることで、結晶化のときにパターンを抽出しやすくなります。
知識結晶化サイクル(KCC)
経験層の生データをスキル層の使える知識に昇華させるプロセスが、KCC(Knowledge Crystallization Cycle) です。
Phase 1〜2: 日常業務での蓄積
普段のClaude Codeとの作業中に、意識的にログを残します。
あなた: このAPIのエラーレスポンス、どう設計すべき?
Claude Code: RFC 7807のProblem Details形式を提案します。
{ "type": "...", "title": "...", "status": 400, "detail": "..." }
あなた: いいね。ただうちのフロントエンドチームは
error.code でハンドリングしてるから、
codeフィールドも追加してほしい。
これ [DECISION] として記録しておいて。
このやり取りで、「RFC 7807 + 独自codeフィールド」というプロジェクト固有の判断が記録されます。
Phase 3: 結晶化セッションの実践
週に1回、30分程度の「結晶化セッション」を行います。Claude Code上で以下のように進めます。
あなた: 今週の memory/ ログを振り返って、
繰り返し出てきたパターンや
スキルファイルに追加すべき知見を抽出して。
Claude Code: 今週のログを分析しました。以下のパターンが見つかりました。
1. [ERROR] が3件ともDate関連
→ タイムゾーン処理のベストプラクティスをスキル化
2. [DECISION] でAPI設計の判断が5件
→ API設計ガイドラインにcursor方式の優先ルールを追加
3. [INSIGHT] でフォームのカスタムフック分離が2回言及
→ コンポーネント設計スキルに標準パターンとして追記
あなた: 1と2をスキルファイルに反映して。
3はもう少し事例が溜まってからにしよう。
結晶化のポイントは以下の3つです。
- パターン抽出 ── 複数のログから共通する判断基準を見つける
- 脱文脈化 ── 特定の状況に依存する部分を取り除き、汎用化する
- 人間によるバリデーション ── 最終判断は必ず人間が行う
Phase 4: 適用と検証
結晶化したスキルは次のセッションから自動的に活用されます。期待通りに機能するか確認し、ずれがあればフィードバックして改善します。
デュアルワークスペース
NFDでは、日常業務と結晶化を別の環境で行うデュアルワークスペースを推奨しています。
| ワークスペース | 目的 | Claude Codeでの運用 |
|---|---|---|
| 育成(Nurturing) | 日常業務 + 経験蓄積 | 通常のプロジェクトディレクトリでの作業 |
| 外科的(Surgical) | 知識の結晶化・整理 | 別セッションでmemory/やskills/を編集 |
育成ワークスペースでは普段通りにコードを書きます。経験層にログが蓄積されていきます。
外科的ワークスペースでは、蓄積されたログを分析し、スキルファイルを更新します。日常業務とは切り離された環境で行うことで、作業の混乱を防ぎます。
Gitのブランチに例えると、mainブランチでの通常作業が「育成」、定期的なリファクタリング用ブランチが「外科的」にあたります。
スパイラル開発モデル:段階的に育てる
NFDはウォーターフォールではなく、スパイラルで段階的にエージェントを育てます。
Phase 0: ブートストラップ(1〜3日)
最小限の土台を作ります。完璧を目指す必要はありません。
Claude Codeで以下のファイルを用意します。
# ディレクトリ構成
.claude/
├── CLAUDE.md # 基盤層(原則のみ)
├── skills/ # スキル層(最初は空でもOK)
│ └── .gitkeep
└── memory/ # 経験層(ログ蓄積場所)
└── .gitkeep
CLAUDE.mdには最低限の原則だけを書きます。
# プロジェクト概要
<プロジェクトの一行説明>
## 基本原則
- <最も重要なルール 3〜5個>
## 参照
- スキル: .claude/skills/
- 経験ログ: .claude/memory/
ブートストラップ段階で完璧なルールセットを書こうとしないでください。それは従来のプロンプトファーストの発想です。原則だけ書いて、あとは育成フェーズで補完します。
もし過去のプロジェクトドキュメントやADR(Architecture Decision Records)がある場合は、それらをmemory/に変換して取り込むことで、コールドスタート問題を緩和できます。
Phase 1: 初期育成(1〜3週間)
普段通りにClaude Codeと仕事をしながら、意識的に以下を行います。
- 判断の理由を伝える ── 「こうして」だけでなく「こういう理由でこうして」
-
タグ付きログを残す ──
[DECISION]、[ERROR]、[INSIGHT]で分類 - エージェントの推論を確認する ── 「なぜその実装にした?」と聞く
実際の対話例を見てみましょう。
あなた: この関数、パフォーマンスが気になる。改善して。
Claude Code: Promise.all で並列化する方法を提案します。
(コード提示)
あなた: いい方向だけど、うちのDBコネクションプールは
最大10なので、並列数を制限する必要がある。
p-limit を使って最大5並列にして。
これ [INSIGHT] として記録しておいて。
DBコネクションプールの制約は今後も頻出するはず。
この対話で「DBコネクションプール最大10、並列は5に制限」という暗黙知が言語化され、記録されます。
結晶化チェックポイント1(3週間後)
外科的ワークスペースで初回の結晶化を行います。
あなた: memory/ の過去3週間のログを分析して、
以下の観点でまとめて。
1. 繰り返し現れたパターン
2. 自分が当初書いた原則と実際の行動のズレ
3. スキルファイルにすべき知見
Claude Code: 分析結果です。
## 繰り返しパターン
- DB関連の制約への言及: 7回
- API設計の判断: 5回
- テスト設計の方針: 4回
## 原則と行動のズレ
- CLAUDE.md に「テスト駆動」と書いているが、
実際にはテストを後から書くケースが12件中8件
→ 原則の修正、または運用の改善が必要
## スキル化候補
- DB接続の制約と対処パターン → db-constraints.md
- API設計ガイドライン → api-design.md
論文の金融アナリスト事例では、この段階で「自分が報告していた手法」と「実際の行動」にズレがあることが発覚しています。結晶化プロセスが人間側の自己理解も深めるという副次的な効果です。
Phase 2以降: 構造的育成と成熟
Phase 2ではエージェントが蓄積された知識を活用して実質的なパートナーになります。結晶化は月1回程度のルーティンに移行し、エッジケースや新しい状況への対応に焦点が移ります。
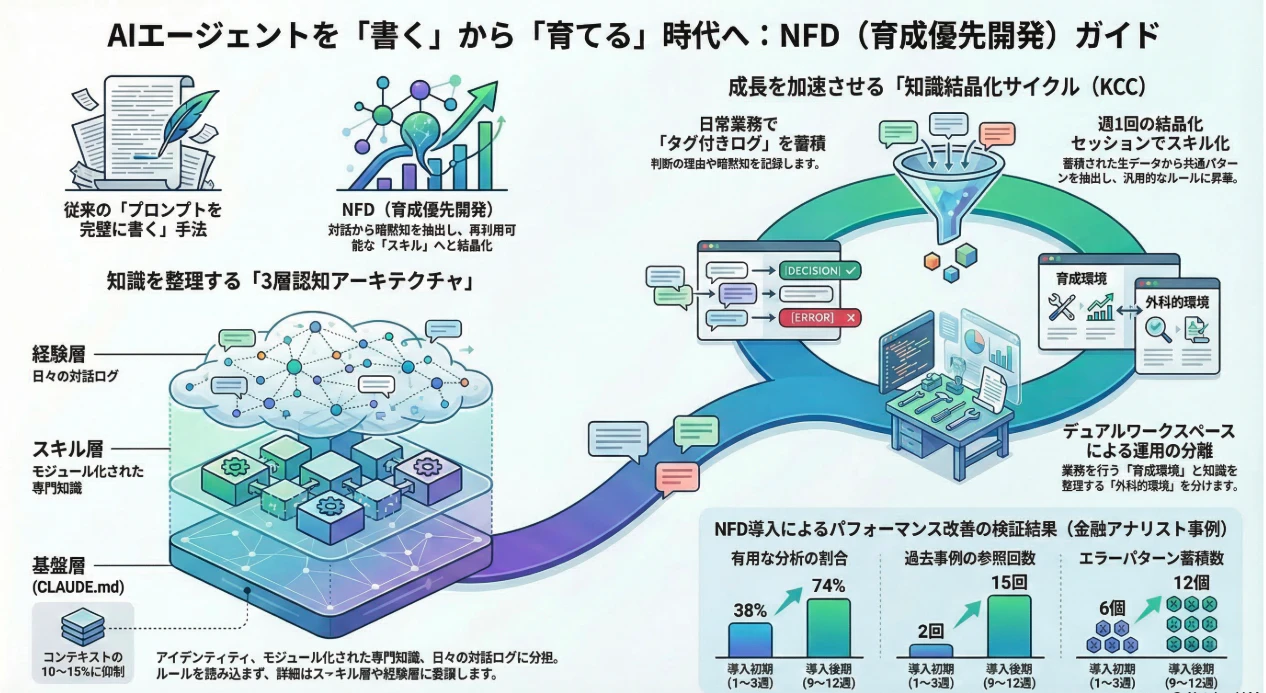
論文の実験結果
論文では、金融アナリスト(米国株式リサーチ、経験5年以上)にNFDを12週間適用した事例が報告されています。
| 指標 | 1〜3週目 | 結晶化1回目後 | 9〜12週目 | 結晶化2回目後 |
|---|---|---|---|---|
| 有用な分析の割合 | 38% | 52% | 71% | 74% |
| 過去事例の参照回数 | 2 | 5 | 12 | 15 |
| バイアス警告の回数 | 0 | 1 | 4 | 5 |
| スキルファイル数 | 2 | 4 | 6 | 8 |
| エラーパターン数 | 6 | 8 | 10 | 12 |
有用な分析の割合が38%から74%へ、約2倍に改善しています。
特筆すべきは創発的な振る舞いです。プログラムしていないにもかかわらず、エラーパターンの蓄積から「その判断は過去のバイアスパターンと類似しています」とエージェントが自発的に警告するようになりました。
この実験は単一ユーザーでの事例であり、対照群を設けた厳密な検証ではありません。「有用さ」の判定も主観的な評価です。論文の著者自身がこの点を限界として明記しています。
従来手法との比較
論文では3つのアプローチを10の観点で比較しています。主要な違いを抜粋します。
| 観点 | コードファースト | プロンプトファースト | NFD |
|---|---|---|---|
| 知識の形態 | 確定的なコード | 静的なプロンプト | 進化するメモリファイル |
| 開発フェーズ | デプロイ前 | デプロイ前 | 継続的・同時進行 |
| 暗黙知の扱い | 明示的ロジックのみ | 宣言的スナップショット | 暗黙知+明示知を進化 |
| 初期価値までの時間 | 数週間〜数ヶ月 | 数時間〜数日 | 数分(成長型) |
| 主な開発者 | ソフトウェアエンジニア | プロンプトエンジニア | ドメインの実務者 |
NFDの最大の特徴は、ドメインの実務者が主な開発者になる点です。プロンプトエンジニアリングの技術がなくても、日々の対話と定期的な結晶化でエージェントを育てられます。
NFDが適するケース・適さないケース
論文では適用条件も明確にしています。
NFDが適するケース
- 専門知識が暗黙的で、事前に全てを言語化できない
- 同じタスクでも人によってアプローチが異なる
- ドメインが頻繁に変化する
- 対話ベースでの作業が自然な形態
NFDが適さないケース
- 知識が完全に形式化できる(例:税務申告処理)
- ルールが静的で変わらない
- コードファーストで十分な精度が出る
実践チェックリスト:今日から始める3ステップ
ステップ1: CLAUDE.mdをスリム化する
巨大なルールセットを書いている場合は、原則だけを残して詳細をスキルファイルに分離します。
# Before: CLAUDE.md が200行以上
# After: CLAUDE.md は50行以内、詳細は skills/ に分離
mkdir -p .claude/skills .claude/memory
ステップ2: タグ付きログを始める
Claude Codeとの作業中に、重要な判断にタグを付けて記録します。
[DECISION] ○○の理由で△△を選択した
[ERROR] ○○が原因で△△が失敗した
[INSIGHT] ○○すると△△が改善できそう
手動で書くのが面倒な場合は、CLAUDE.mdに以下を追加するとエージェントが自動で記録します。
## 経験ログ
セッション中の重要な判断・エラー・気づきを
.claude/memory/YYYY-MM-DD.md にタグ付きで記録する。
タグ: [DECISION], [ERROR], [INSIGHT]
ステップ3: 週30分の結晶化タイムを設ける
金曜日の夕方など、週1回の振り返り時間を設けます。
あなた: 今週のmemory/ログを振り返って、
スキルファイルに追加すべきパターンを提案して。
最初は小さく始めて、サイクルが回り始めたら徐々に範囲を広げていくのが継続のコツです。
まとめ
NFDの本質は、AIエージェントを「設定するもの」から「育てるもの」へと捉え直すことです。
- 3層認知アーキテクチャで知識を整理し、コンテキストを節約する
- 知識結晶化サイクルで日々の経験をスキルに昇華させる
- デュアルワークスペースで日常業務と知識整理を分離する
完全なNFD基盤を構築するのは大がかりですが、「CLAUDE.mdの分割」「タグ付きログ」「週1回の結晶化」の3つだけでも、エージェントの振る舞いは着実に改善していきます。
論文が指摘する最も興味深い発見は、エージェントを育てるプロセスが人間側の自己理解も深めるという点です。暗黙知を言語化する過程で、自分自身の判断基準や思考のクセが明確になります。
AIエージェントとの協働は、ソフトウェアエンジニアリングから人間とAIの共同進化へと変わりつつあります。