pandasを使って複数行ヘッダー(multi columns/マルチカラム)の持つExcelファイルを読み込む際、その複数行ヘッダーの扱いについて色々調べたのですがあまりノウハウ記事が見当たらなかったので、自分のやったやり方を紹介します。
もしもこれ以外に良い方法を知っている方は是非コメント頂けたらと思います。
やりたかったことと問題点
ここでは前提となるExcelファイルの構成とpandasのread_excel関数を実行しただけではどういうものが作られるかの紹介をします。
前提となるExcelファイル
まず以下のようなExcelファイルがあったとしましょう。ヘッダーが2行あり、マージセルも含まれてます。
これをpandasで開いてDataFrameにしてあれこれ処理したい場合の話になります。

当Excelファイルをpandasで読込んだ際に、以下のような定義でDataFrameを作りたいとします。

ここで問題になるのがこの赤枠で示した複数行のヘッダー、要は項目列になります。
pandasでのExcelファイルの読込み
次にpandasで実際にread_excel関数を用いて上記Excelファイルを読込んでみます。(シートはデフォルトのsheet1でシートの指定はしないこととします。)
通常、以下のコードで実現可能です。
df = pd.read_excel(excel_file_path, skiprows=2, header=[0, 1])
簡単に説明すると、Excelファイル内で表のある3行目まで飛ばして、その後1,2行目(Excelファイル上の3,4行目)をヘッダー指定してるだけです。
これはDataFrameとして出力されますが、実際にprintしてみると以下のようになります。
>>> print(df)
No 状態 備考
体重 体脂肪率 Unnamed: 2_level_1
1001 65.5 19.5 NaN
1002 66.0 18.1 飲み過ぎ
1003 65.7 19.1 NaN
1004 65.8 19.3 NaN
1005 65.3 20.1 NaN
ちょっとくどいですが、JupyterNotebook上との結果も載せておきます。
JupyterNotebook上で表示すると明白なように、Excelファイル上で縦にマージされた"備考"セルにおいてUnnamed~という項目が作成されてしまっています。

今回の記事の内容としては、このように「pandasで複数行ヘッダーを持つExcelファイルを変換したけど、ちょっと使いにくいので列項目を良い感じに変換してみた」という物になります。
実現のために行った処理とコード
実際にread_excelしただけでは、Unnamed~なる項目が追加されていたり、一番左列の項目がindexになってしまったりと、少々不便な感じがします。
ですので、Excelファイルから作成したDataFrameを直感的に使うためにいくつか加工しました。
今回の整形において「実現したいこと」としては、
- マージセル列は、その列項目単独指定で列データを取得できるようにしたい
例えばdf[“備考"]といった形 - 複数行列の内容はDataFrame["親項目", "子項目"]と言うようにアクセスしたい
例えば体重へのアクセスはdf["状態", "体重"]といった形 - 親項目を指定したら子項目全てが選択されるようにしたい
といったことになります。これが実現出来るようにしたものが以下のようなコードになります。
def multi_columns(data_frame):
df = data_frame.copy()
if type(df.columns) is not pd.MultiIndex:
return df
# 列にUnnamedという文字の入った内容を削除しインデックスを振り直す
df = df.rename(columns=lambda x: x if not 'Unnamed' in str(x) else '')
df = df.reset_index()
cols = df.columns
copy_col = list(cols)
# column.namesを新しいcolumnの一番上(インデックスセルの一番左)に持ってくる
name_col = tuple([(name if name is not None else '') for name in cols.names])
copy_col[0] = name_col
# 無効セルは上に詰める
for i, col in enumerate(copy_col):
pack = [content for content in col if content != ""]
copy_col[i] = tuple(pack + ([""] * (len(col) - len(pack))))
df.columns = pd.MultiIndex.from_tuples(copy_col)
cols.names = tuple([None for x in cols.names])
return df
実行例は以下のようになります。
>>> df = pd.read_excel(excel_file_path, skiprows=2, header=[0, 1])
>>> df = multi_columns(df)
>>> print(df)
No 状態 備考
体重 体脂肪率
0 1001 65.5 19.5 NaN
1 1002 66.0 18.1 飲み過ぎ
2 1003 65.7 19.1 NaN
3 1004 65.8 19.3 NaN
4 1005 65.3 20.1 NaN
上記をJupyterNotebook上で実行してみるときちんと整形されているのが確認できました。
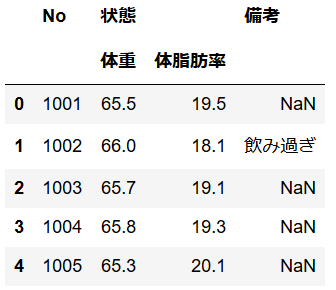
きちんと操作できるかも確かめてみます。
※以下はPandasのMultiIndexに対するアクセスと同等のものなので特に目立つ話はありませんが一応確認。
まずはNo.列の取り出し。変換後の"No"列はindexではなく列項目になります。
>>> df["No"]
0 1001
1 1002
2 1003
3 1004
4 1005
Name: No, dtype: int64
階層化してある列項目へのアクセスは以下のようにします。
>>> df["状態", "体重"]
0 65.5
1 66.0
2 65.7
3 65.8
4 65.3
Name: (状態, 体重), dtype: float64
また、複数行列において子項目のある親のみを指定した場合は、付属する子項目の列内容が取得出来ます。
>>> df["状態"]
体重 体脂肪率
0 65.5 19.5
1 66.0 18.1
2 65.7 19.1
3 65.8 19.3
4 65.3 20.1
ちょっと蛇足的な話ですが、No.列をインデックスにする場合は以下になります。
また、もしも子項目のある列を削除する場合は項目をdrop(columns=タプル("親項目", "子項目"))というような形で指定します。
>>> df.index = df["No"]
>>> df.index.name = "No"
>>> df = df.drop(columns="No")
>>> df
状態 備考
体重 体脂肪率
No
1001 65.5 19.5 NaN
1002 66.0 18.1 飲み過ぎ
1003 65.7 19.1 NaN
1004 65.8 19.3 NaN
1005 65.3 20.1 NaN
これできちんとNoがindexに指定できました。
動作確認はここまで。細かいサンプルについては「コードと実行例のリンク」の各実施例(JupyterNotebook)にありますので、ご参照頂ければと思います。
解説
ここからは興味ある方のみご確認いただければと思います。
知らなければ実行出来ないという話ではないです。
変換例と問題
実際、上記の「2行ヘッダーを持つExcelファイルのPandas変換例」を解決するものを探したところ、stackoverflowに以下のような回答を見つけました。
Fix DataFrame columns when reading an Excel file with a header with merged cells

「ここで紹介されてるコードをやればできるんじゃね?」ってちょっとテンションあがったのですが、ここで紹介されていた解決例では上記の構成のみでしか実現できず、例えば以下のような3行ヘッダーでは上手く動きませんでした。
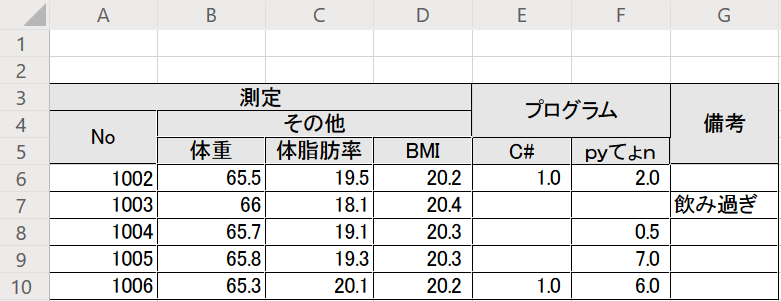
実際に上記の3行ヘッダーをread_excelで変換した直後は以下のような形になっています。
>>> df = pd.read_excel(excel_file_path, skiprows=2, header=[0, 1, 2])
>>> df
測定 測定 プログラム 備考
No その他 Unnamed: 3_level_1 Unnamed: 4_level_1 Unnamed: 5_level_1
体重 体脂肪率 BMI C# pyてょn Unnamed: 5_level_2
1002 65.5 19.5 20.216049 1.0 2.0 NaN
1003 66.0 18.1 20.370370 NaN NaN 飲み過ぎ
1004 65.7 19.1 20.277778 NaN 0.5 NaN
1005 65.8 19.3 20.308642 NaN 7.0 NaN
1006 65.3 20.1 20.154321 1.0 6.0 NaN
再度、くどいですがJupyterNotebookでの表示結果を示します。
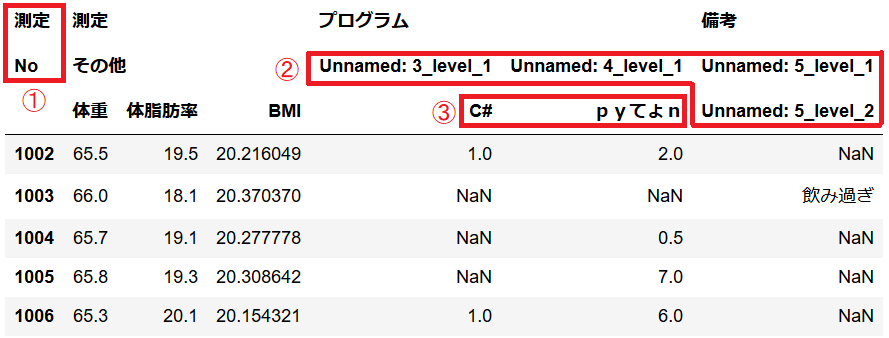
そのままread_excelを行った場合、各列項目名のみで列を取り出すには以下3点の問題があります
① 一番左の列がインデックス(index_col)に指定され、且つcolumnのlevels指定されていない(columns.namesに入る)
② Excel上、縦にマージされたセルはUnnamed~になっている
③上記 ②を空文字指定しても実際の子項目のアクセスには②の空文字を指定しなくてはいけない
(例えば、Undefined~を空文字""に置き換えただけでは、df["プログラム", "", "C#"]という冗長な空文字指定が増える)
そこで、PandasでExcelファイルを読み込んだ際の状況「縦にマージされたセルはUnnamed~という名前になる」「indexに指定された列(index_col)はcolumns.namesに入る」という特性を使って以下のような処理を行っています。
- 列にUnnamedという文字の入った内容を空文字""とする。
- indexをリセットし、自動生成されたcolumn.namesをcolumns.levelsに変換
→ index指定された項目が列として扱われる - 空文字""に指定した無効セル以下の項目は指定階層(levels)を上に詰める
3行ヘッダの例で言えば"C#"項目など
上記処理をまとめると以下の通り。

これを実現したのが、当記事のコードになります。
冒頭の2行ヘッダーや解説の3行ヘッダーも含め、いくつかパターンを当記事紹介のコードで変換できることを確認しています。
変換できない複数行ヘッダーを持つExcelファイルもあると思いますが、3行ヘッダーあたりであれば上手く動くはず。。。
一応、3行ヘッダーの変換例も示しておきますね。(JupyterNotebookで実行)

コードと実行例のリンク
GitHub上に当記事で紹介したコードと実行例のJupyterNotebookのファイルを置いておきますが、pandasでread_excel関数を使ってExcelファイルを開くには以下のパッケージが必要になるので、実行前に以下を実行下さい。入ってる方は読み飛ばしてくれればと思います。
Excelファイル読込みには「xlrd」というパッケージが必要になります。書込む場合は「xlwt」というパッケージが必要ですが、当実行例には使ってないので入れないでもOKです。
$ pip install xlrd
以下、当記事で紹介したコードと実行例のJupyterNotebook
- コードそのもの
- pandasで2行ヘッダーを持つExcelファイルを読込んだ例(JupyterNotebook)
- 2行ヘッダーの変換例(JupyterNotebook)
- 3行ヘッダーの変換例(JupyterNotebook)
※GitHub上でのJupyterNotebookファイルはIEでは上手く表示出来ない場合があるので、他のブラウザをご使用ください。