シリーズ記事
Elasticsearchのマシン・ラーニング異常検知の動きを理解しよう(1)
Elasticsearchのマシン・ラーニング異常検知の動きを理解する(2) [アラート編]
Elasticsearchのマシン・ラーニング異常検知の動きを理解する(3) [変更設定編]
はじめに
今回からElasticsearchのMachine Learningの異常検知(Anomaly Detection)の機能について解説した記事をシリーズで書きたいと思います。
ElasticsearchのMachine Learningは非常に汎用的に作られています。
Elaticsearchに入っているデータならログ、メトリック、ビジネスデータだろうと何でも対象にして使うことができます。この辺りは、他の運用監視系製品の機械学習系の機能にはない特徴です。
ただし、汎用的に作られている分、チューニングパラメータも多く、故に初心者には少しハードルが高い機能であると感じています。
習得するには実践が一番であり、問題事象をわざと起こして、異常検知するかの実験を行いたいところです。
そこで、今回のシリーズでは誰でも同じデータを使ってMachine Learning機能を繰り返し何度もテストできる方法を紹介しつつ、Machine Learningの機能についてそれぞれ確認していきます。
最初の1本目のこの記事ではこのための環境のセットアップを行います。自分のPCなどでも試せる手順となります。
Elasticsearch環境のセットアップ
環境はオンプレへのインストールもしくはElastic Cloudどちらでも使えます。
個人的に試す分にはPCにElatic Stackをインストールするのが良いでしょう。いくつか参考記事があります。
https://qiita.com/nobuhikosekiya/items/35ae0d94f3356a16f984
https://qiita.com/takeo-furukubo/items/c2f194679afadc06a4e9
PCにインストールした場合、Stack Management のLicence managementからStart a 30-day trialを押せばその場ですぐにMachine Learning機能が使えるようになります。

テストデータのセットアップ
KibanaのHomeからTry sample dataからサンプルデータをロードできます。

こちらのSample web logsを使います。

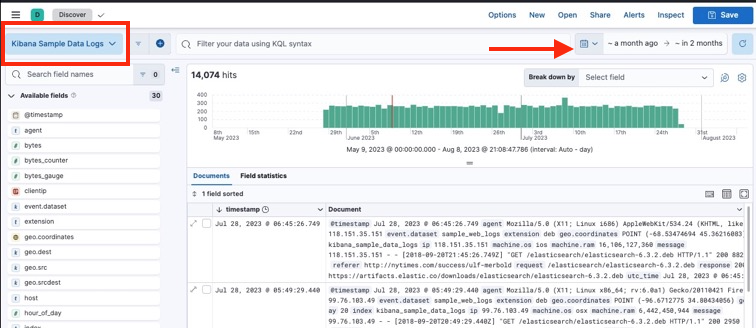
Discoverで追加されたデータを見てみます。(左上のData View欄でKibana Sample Data Logsを選択してください)
右上のタイムレンジを前後に広くとってみると、追加日を基準に将来日付を含め2ヶ月分くらいのデータが生成されているのがわかります。このデータの最初と最後の日付をなんとなく覚えておいてください(最初のデータがサンプルデータ追加時点のおおよそ2週前、最後のデータがおおよそ1.5ヶ月後くらいのはずです)
異常検知のジョブを作る
メインメニューのAnalytics配下のMachine Learning -> Anomaly Detection - Jobsに移動し、Create jobボタンを押します。
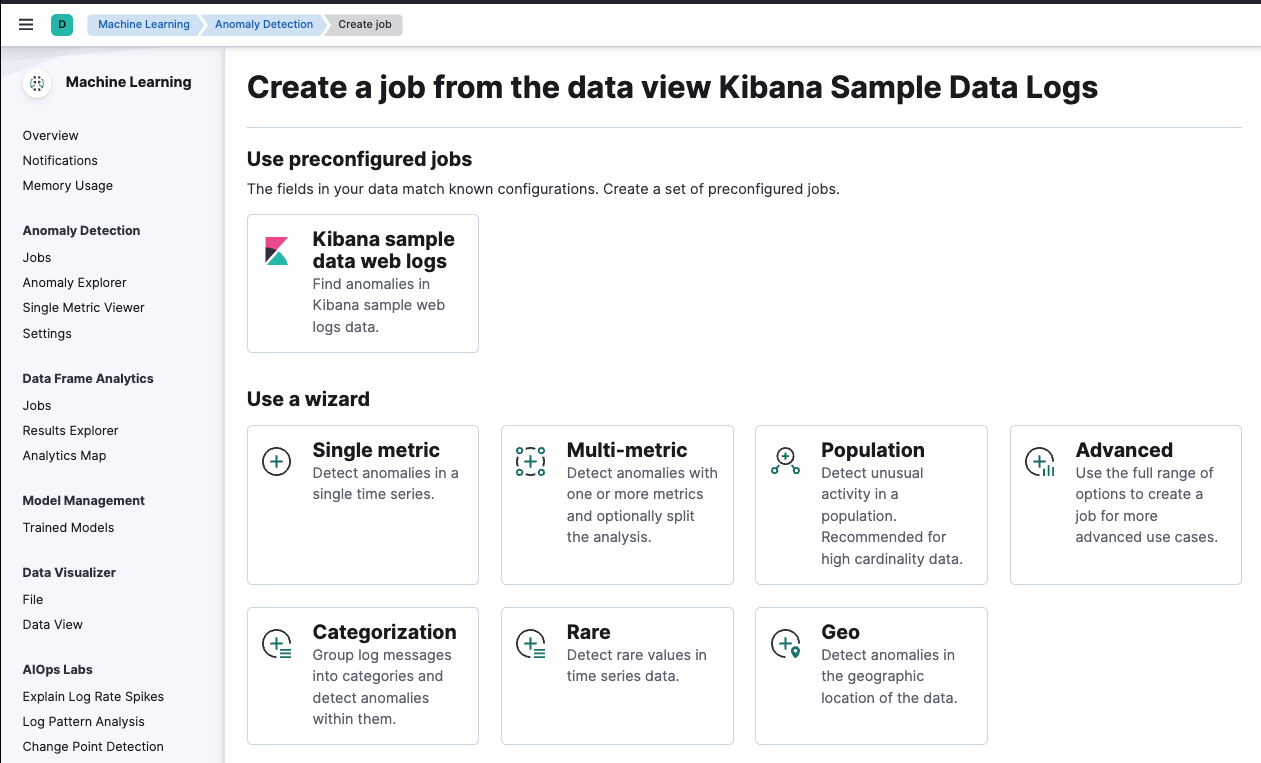
次のSelect data viewの画面でKibana Sample Data Logsを選択すると、下の画面が表示されますが、このサンプルデータセットに付属しているpreconfigured jobs(設定済みのジョブ)がありますので、今回はこれを使います。このジョブは今回のサンプルデータに付属している事前定義済みのジョブとなります。
次の画面はデフォルトのままCreate jobsをクリックしてください。

ジョブの作成完了後に表示されるview resultsボタンを押すと、Anomaly Explorerが表示されます。ここまで成功すればMachine Learning機能が無事に動いています。

異常検知ジョブの管理の基礎
実行結果のリセット方法
これから何回もテストをしていくので、ジョブの管理について詳しくなりましょう。
Anomaly Detection下のJobsを開くと、作成された3つのジョブが表示されます。

右側のActionsのボタンをクリックし、Reset Jobしてみてください。結果としてProcessed recordsが0にリセットされます。
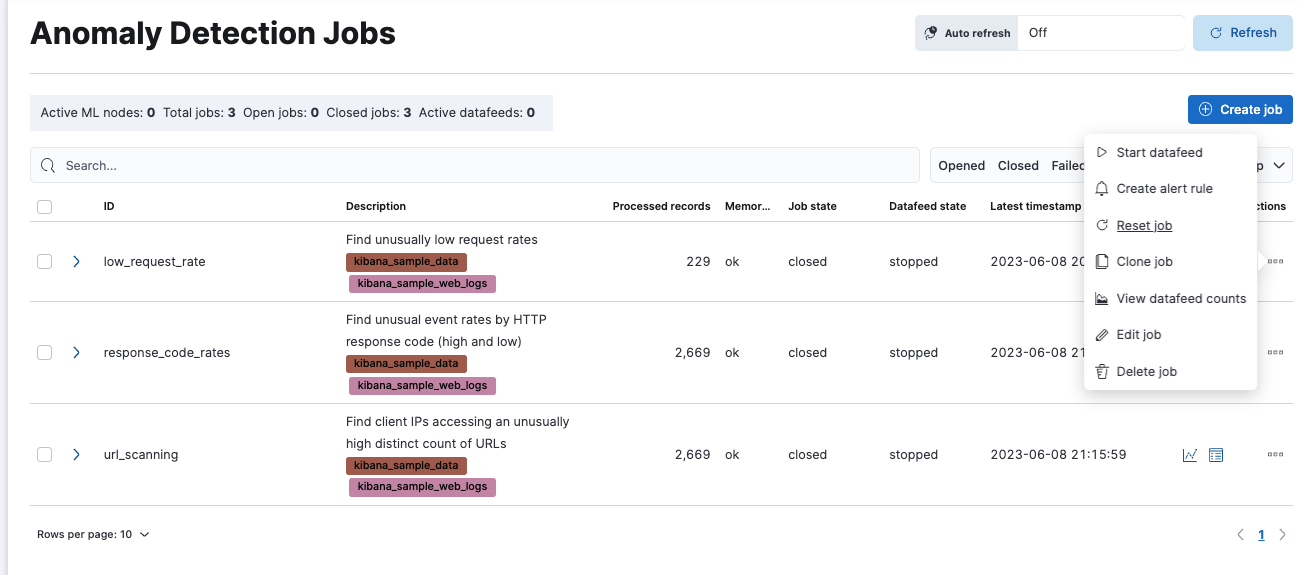
データフィードをする (バッチ分析)
Datafeedをすることで、ジョブに対して分析をさせることができます。分析対象のデータは時間の範囲を指定でき、過去のデータ、さらにはデータが存在するのならば未来日付のデータも分析できてしまいます。
バッチ的に特定期間を分析したり、リアルタイムに入っている新しいデータを継続的に分析させることもできます。
では、データをリセット後、ActionsからStart datafeedをクリックします。
分析させるデータの範囲を指定できます。ここではデフォルト値のままStartしてください。デフォルトはStartが最初のデータ(2週間前の日付のデータ)とEndが現在時刻となっているはずです。

Datafeedで分析が行われ、Job state:open, Datafeed state: startedになります。こちらすぐに分析が完了してしまってclosed/stoppedに変わります。
Datafeed完了後、チャートアイコンをクリックしてください。
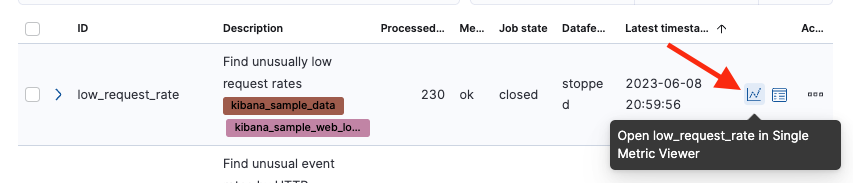
Single Metric Viewerが表示され、Datafeedで指定したデータの範囲の分析が行われた結果が確認できます。

- 実線が実際のデータです。このサンプルの場合、縦軸の数値はログの件数を表しています。毎日同じようなログ発生のトレンドがあることがわかります。
- 水色に塗られているバンドがデータを学習した結果のベースライン値(期待値)です。最初の3日間のデータ学習後にベースラインが出来始めていることがわかります。
データフィード (リアルタイム分析)
では、再度Jobs画面からStart Datafeedを開きます。
今度は、end timeをNo end time (Real-time search) に設定してStartしてください。
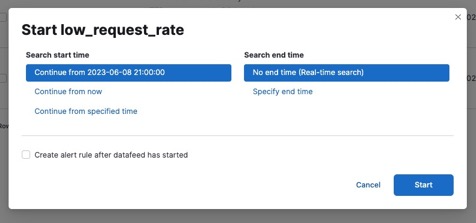
Startすると、Job state: opened、Datafeed state: startedに変わり、今度はこのステータスがずっと続くようになります。
1,2時間後に、チャートアイコンからSingle Metric Viewerを開くと、分析が進んでいるのが確認できるはずです。

Machine Learningノードのメモリの使用の確認
Machine LearningメニューのMemory Usageを開いてください。
Job state: openedのジョブだけが動作中なので、その分だけがメモリを使っていることがわかります。他の2つのジョブはここではメモリを使っていないことがわかります。

ジョブをバッチ的に使うか、リアルタイムで常時稼働させるかによってメモリの消費状況が異なることがここから確認できました。
Datafeedとジョブの停止
ジョブのActionsメニューからStop datafeedをクリックしてみてください。Datafeed stateはstoppedとなりますが、Job stateはまだopenedです。この時点ではまだメモリを消費しています。
次に、ActionsメニューからClose Jobをクリックしてください。Job stateはこれでclosedとなります。メモリも消費されなくなっていることを確認してみてください。
データを最後まで分析
再びStart Datafeedを実行し、今度はサンプルデータの最後の日付が含まれるようにend timeを設定してください。このように未来の日付でも、データがあれば分析できてしまいます。
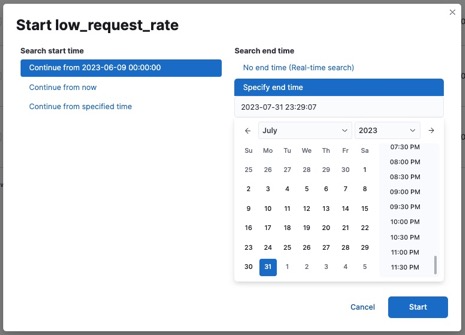
本日が6月8日なのですが、このように1ヶ月先の未来のデータの異常検知もできていることがわかります。

学習データが増えるにつれてのベースラインの変化を確認
学習期間が進むにつれ、水色の幅の部分が太くなっています。学習が進み、ある程度は値が振れるということが学習されました。結果序盤のデータで敏感に検知してしまった異常が後半では(正しく)検知していません。(なお、学習が進むにつれてバンド幅が太くなるか細くなるかはデータ次第です)

データのクリーンアップ
最後、この画面からサンプルデータのRemoveができます。そしてまたテストしたいときにAdd dataすれば、テストデータを作ることができるのです。データはAdd dataしたタイミングでスライドしてくれるtimestamp値以外は全て同じデータなので、再現性のあるテストができます。

Anomaly Detectionのジョブは残ったままですが、こちらはこの記事の最初でやったようにResetをすれば学習データをクリアして初めからテストをし直すことが簡単にできます。
終わり
今回サンプルデータを使って、ElasticsearchのMachine Learningの動きを確認することができました。
Elasticsearchはデータの投入が自由にできる分、ML機能のテストもシミュレーションが可能です。今回のように過去、未来の日付のデータを自由に分析できます。これはテストデータの投入を簡単にはできない他の監視ツールではできないことです。リアルな監視データを作らないといけないので、非常にテストが難しいです。