はじめに
本記事は、2025年2月10日に公開されたElastic 社の公式ブログ 「How to set up vector search in Elasticsearch」 を元にした日本語訳です。
元記事の著者: Valentin Crettaz
これまでElasticsearchのバージョン8.0 ~ 8.17に渡り、ベクトル検索においては様々な改良が行われ、オプションや検索クエリーの書き方が追加されていきました。本記事はその変遷を含め、バージョン8.xの最終的ばなベクトル検索の使い方を網羅的に抑えることができる良記事となっています。
Elasticsearch でベクター検索をセットアップする方法
このブログ記事は、ベクター検索(セマンティック検索とも呼ばれる)の詳細と、その Elasticsearch での実装方法を解説する全3回シリーズの2回目にあたります。
前回の記事では、埋め込み(ベクター)とベクター検索の基本を中心に紹介しました。
ここでは、それらの知識を活かして Elasticsearch 上でベクター検索を設定し、k-NN 検索を実行する手順を説明します。
最終回となる第3回目の記事では、ハイブリッド検索(ベクター検索と従来のテキスト検索の組み合わせ)をどのように Elasticsearch で実装するかについて解説します。
最初に少し背景を
Elasticsearch はバージョン 8.0 までは _knn_search API の技術プレビューが登場するまでベクター検索を公式にはサポートしていませんでした。しかし実際には、7.0 リリース時点で dense_vector フィールドタイプを利用して ベクター自体を格納することは可能でした。ただし、当時は 最初の記事 で紹介したようなアルゴリズムを用いてインデックスされるわけではなく、単にバイナリドックバリューとして保存されているだけでした。これは次に控えるベクター検索機能への準備段階でもありました。
Elasticsearch が現在のベクター検索機能を実装するまでの議論については、こちらのイシュー や このイシュー を参照すると、Elastic がどういった課題を乗り越えてきたかを知ることができます。簡単に言えば、すでに Elasticsearch では検索エンジンとして Lucene を大々的に活用していたため、ベクター検索エンジンとしても同じ Lucene を用いることにしました。その理由づけについては こちらの記事 で詳しく説明されています。
歴史的経緯はこれくらいにして、さっそく本題に入りましょう。
k-NN の設定方法
Elasticsearch ではベクター検索機能がネイティブに利用でき、特別なプラグインや追加インストールは不要です。最初にすべきことは、少なくとも 1 つの dense_vector 型フィールドを定義したインデックスを作成することです。ここにベクターを保存し、インデックス化することで k-NN 検索を行います。
下のマッピング例では、title_vector と呼ばれる次のような dense_vector フィールドを定義しています。これは 3 次元のベクターを格納し、前回の記事で紹介した dot_product の類似度計算を利用しています。なお、8.11 までは Apache Lucene がサポートするアルゴリズムとして HNSW (Hierarchical Navigable Small Worlds) のみでしたが、8.11 以降は他のアルゴリズムが追加され、今後も Lucene 側の対応に合わせて Elasticsearch も対応を進める可能性があります。
"title_vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "dot_product",
"index_options": {
"type": "hnsw",
"ef_construction": 128,
"m": 24
}
}
下の表にあるように、Elasticsearch が提供する dense_vector フィールドタイプに設定可能なパラメータは多岐にわたります。
| パラメータ | 必須か | 説明 |
|---|---|---|
| dims | Yes (<8.11) No (8.11+) |
ベクターの次元数です。8.9.2 までは 1024、8.10.0 からは 2048、8.11.0 からは 4096 が最大です。8.11 以降は設定しなくてもよく、最初に挿入されるベクターの次元数が自動的に利用されます。 |
| element_type | No | ベクター要素のデータ型です。未指定の場合は float (4 バイト) がデフォルトで、他に byte (1 バイト) や bit などを使用できます。 |
| index | No | ベクターを専用の最適化データ構造にインデックス化するか (true)、単にバイナリドックバリューとして格納するか (false) を決定します。8.10 までは未指定だと false でしたが、8.11 以降は未指定だと true がデフォルトです。 |
| similarity | Yes (<8.11) No (8.11+) |
8.10 までは index: true の場合に必須で、k-NN 検索に使うベクター類似度を指定します。選択可能なメトリックは以下のとおりです:a) l2_norm:L2 距離 b) dot_product:ドット積 c) cosine:コサイン類似度 d) max_inner_product:最大内積 また、ベクターがすでに正規化(長さ1)されている場合は dot_product、そうでない場合は cosine や max_inner_product を使うのが一般的です。8.11 以降は未指定の場合、element_type が bit のときは l2_norm、それ以外は cosine がデフォルトとなります。 |
| index_options | No | ベクターをインデックス化するアルゴリズム・手法を指定します。バージョンによって使用可能な値が異なります。 ・8.11 までは hnsw のみ・8.12 からはスカラー量子化対応の int8_hnsw が追加・8.13 で flat およびそのスカラー量子化版 int8_flat が追加・8.15 で int4_hnsw および int4_flat が追加・8.18 でバイナリ量子化対応の bbq_hnsw と bbq_flat が追加詳細は 公式ドキュメント を参照してください。 |
8.11 以降はこのようにベクターフィールドの設定が大幅に簡単化されています。

スカラー量子化(8.12 で追加)については、前回の記事 でも触れたとおり、ベクターを圧縮する技術です。Lucene での実装詳細は Search Labs の別記事で紹介されています。同様に 8.18 で追加された BBQ (Better Binary Quantization) についても こちらの記事 をご覧ください。
結論としては、dense_vector フィールドを定義して設定するだけで、knn 検索オプションまたは knn DSL クエリ(8.12 以降導入)を使い、Elasticsearch でベクター検索をすぐに利用できます。Elasticsearch では大きく分けて 2 種類のベクター検索モードがあり、1) script_score クエリを用いた正確な検索 (exact search) と、2) knn 検索オプション/knn クエリを用いた近似的な最近傍探索 (approximate nearest neighbor search) です。以下ではこれらを順に見ていきます。
正確な検索 (Exact search)
前回の記事で触れたように、正確なベクター検索はベクター全体に対して線形探索(いわゆる brute-force)を行います。クエリベクターとすべての格納ベクターの類似度を計算し、最も近いものを探すというシンプルな仕組みです。このモードではベクターを HNSW グラフでインデックス化する必要はなく、バイナリドックバリューとして格納しておき、検索時に Painless スクリプトを使って類似度を計算します。
まずは以下のように、index: false とsimilarityメトリックを設定しないマッピングを作成し、ベクターをインデックス化しないように設定します。
# 1. Create a simple index with a dense_vector field of dimension 3
PUT /my-index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
},
"title_vector": {
"type": "dense_vector",
"dims": 3,
"index": false
}
}
}
}
# 2. Load that index with some data
POST my-index/_bulk
{ "index": { "_id": "1" } }
{ "title_vector": [2.2, 4.3, 1.8], "price": 23}
{ "index": { "_id": "2" } }
{ "title_vector": [3.1, 0.7, 8.2], "price": 9}
{ "index": { "_id": "3" } }
{ "title_vector": [1.4, 5.6, 3.9], "price": 124}
{ "index": { "_id": "4" } }
{ "title_vector": [1.1, 4.4, 2.9], "price": 1457}
こうすると、ベクターをインデックス化しない分だけ取り込み(インジェスト)時間が非常に短くなります。HNSW グラフを構築しなくて済むためです。ただし、データ量が増えると検索速度は低下しやすくなります。線形検索の計算量は O(n) となるため、格納ベクター数が多いほど計算負荷は大きくなります。
インデックス作成後、データを投入したら、以下のように script_score クエリを使って検索できます。
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"query": {
"script_score": {
"query" : {
"bool" : {
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
},
"script": {
"source": "cosineSimilarity(params.queryVector, 'title_vector') + 1.0",
"params": {
"queryVector": [0.1, 3.2, 2.1]
}
}
}
}
}
上記のクエリでは、query セクションでまず price >= 100 というフィルタをかけ、それを満たすドキュメントのみを対象にスクリプトによるスコアリングを行っています。もし query セクションを指定しなければ、match_all と同等となり、インデックス内の全ベクターに対してスクリプトが実行されます。データ量が多いとこの処理が非常に重くなることに注意しましょう。
script_score を用いることで、Painless スクリプトを通じてベクター類似度を計算します。インデックス化されていないため、内蔵アルゴリズムに任せられず、手動でスクリプトによる計算が必要になります。Painless には以下のようなベクター向け関数が用意されています:
-
l1norm(vector, field):L1 距離(マンハッタン距離) -
l2norm(vector, field):L2 距離(ユークリッド距離) -
hamming(vector, field):ハミング距離 -
cosineSimilarity(vector, field):コサイン類似度 -
dotProduct(vector, field):ドット積
さらに、独自の類似度アルゴリズム をスクリプトで記述することも可能です。doc[<field>].vectorValue や doc[<field>].magnitude を使えば、ベクターの要素やベクターの長さにもアクセスできます。
まとめると、厳密な検索 (exact search) はデータ量が非常に小さい場合には有用ですが、大規模データの場合は検索レイテンシが大きくなりやすいため、通常は次に紹介する k-NN 検索を使うことが推奨されます。
近似的な k-NN 検索 (Approximate k-NN search)
大規模データを扱う場合、そして検索速度を重視する場合は、近似k-NN検索がほとんどのケースで最適な選択となります。インデックス作成時にLuceneがHNSWグラフを構築し、検索時にはメモリを多く消費する傾向があります。また「近似」という名の通り、常に真の近傍を100%返すわけではない点も特筆すべき点です。それでも検索レイテンシが大幅に下がり、数百万〜数十億規模のベクトルにも対応可能です(適切にクラスタを構成した場合)。
具体的な例を見てみましょう。まずは以下のように、index: true と similarity を指定したdense_vector フィールドを持つマッピングを作成し、必要なデータを投入します(ここではスカラー量子化されたHNSWを使う例):
# 1. Create a simple index with a dense_vector field of dimension 3
PUT /my-index
{
"mappings": {
"properties": {
"price": {
"type": "integer"
},
"title_vector": {
"type": "dense_vector",
"dims": 3,
"index": true, # default since 8.11
"similarity": "cosine", # default since 8.11
"index_options": {
"type": "int8_hnsw", # default value since 8.12
"ef_construction": 128,
"m": 24
}
}
}
}
}
# 2. Load that index with some data
POST my-index/_bulk
{ "index": { "_id": "1" } }
{ "title_vector": [2.2, 4.3, 1.8], "price": 23}
{ "index": { "_id": "2" } }
{ "title_vector": [3.1, 0.7, 8.2], "price": 9}
{ "index": { "_id": "3" } }
{ "title_vector": [1.4, 5.6, 3.9], "price": 124}
{ "index": { "_id": "4" } }
{ "title_vector": [1.1, 4.4, 2.9], "price": 1457}
シンプルな k-NN 検索
上記の操作により、スカラー量子化されたHNSWグラフが作成され、ベクトルデータがインデックス化されました。
8.11 までは、k-NN 検索をするには下記のように query セクションと同階層にある knn セクションを使う必要がありました。検索結果として、最も近い k 個のドキュメントを返します(以下の例では k=2)。
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100
}
}
8.12以降は新たにknnクエリが導入され、ハイブリッド検索など高度なクエリに対応しやすくなりました。通常はシンプルな knn 検索オプションを使うだけで十分ですが、ハイブリッド検索など複雑なシナリオでは knn クエリを組み合わせる利点があります。
knn クエリは k パラメータではなく size を使い、さらに bool クエリを組み合わせてフィルタをかけることが可能です。以下は例です。
POST my-index/_search
{
"size": 3,
"_source": false,
"fields": [ "price" ],
"query" : {
"bool" : {
"must" : {
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"num_candidates": 100
}
},
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
}
}
上記のクエリは、まず最も近い隣接ベクトルを持つ上位 3 つのドキュメントを取得し、次に価格が 100 未満のドキュメントを除外します。この種の事後フィルタリングでは、フィルタが厳しすぎると結果がまったく得られない可能性があることに注意してください。また、この動作は、スコアリングが必要なドキュメント セットを減らすためにフィルタ部分が最初に実行される通常のboolean 全文クエリーとは異なることにも注意してください。knnトップレベル検索オプションと新しい検索クエリの違いについて詳しく知りたい場合は、詳細について別の優れた Search Labs こちらの記事をご覧ください。
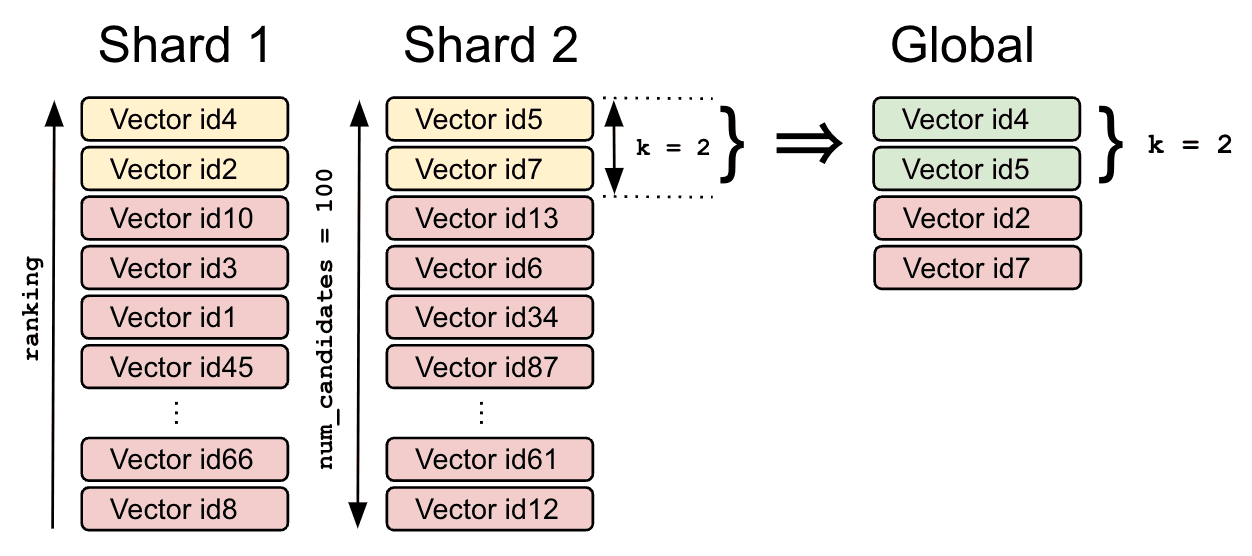
Figure 1: num_candidates を使った近傍候補の探索イメージ
例として、左のシャードでは id4 と id2 が k=2 のローカル近傍、右のシャードでは id5 と id7 がローカル近傍として得られます。その後、コーディネータノードでこれら 4 ドキュメントを再度マージ・再スコアリングし、最終的に id4 と id5 がグローバル上位 2 件として返ってくる、という流れです。
複数の k-NN 検索を同時に実行する
1 つのインデックスに複数のベクターフィールドがある場合、knn セクションには配列を指定できます。各フィールドや k 値を別々に設定し、それらのスコアを加重平均した結果を得ることも可能です。例えば以下のように書けます。
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": [
{
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100,
"boost": 0.4
},
{
"field": "content_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 5,
"num_candidates": 100,
"boost": 0.6
}
]
}
フィルタ付き k-NN 検索
先ほどのscript_scoreクエリと同様に、このknnセクションでは、近似検索を実行するベクトル空間を縮小するためのフィルターの指定も受け入れます。たとえば、以下の k-NN 検索では、価格が 100 以上のドキュメントのみに検索を制限しています。
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100,
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
}
気になるのは「フィルタを先にかけてベクター空間を絞り、その中で k-NN 検索するのか、それとも k-NN 検索した結果をフィルタで落とすのか」という点ですが、実際にはハイブリッドな仕組みです。フィルタが厳しすぎるとほとんど候補が残らず k-NN の精度が下がり、一方で事後フィルタでは近い候補も削ってしまう恐れがあります。そこで、knnセクションのfilterは事前フィルターとして使えるものの、Lucene 側でうまく処理を行い、最低限 k 件のドキュメントを見つけられるように検索が進められます。詳しくは Lucene の関連イシューを参照してください。
期待される類似度を指定したフィルタ付き検索
先ほどのフィルタは主に属性値などで絞り込みをするものでしたが、knn 検索では「最低限この類似度以上のドキュメントだけ返す」という条件を指定することもできます。次のように書けます。
POST my-index/_search
{
"_source": false,
"fields": [ "price" ],
"knn": {
"field": "title_vector",
"query_vector": [0.1, 3.2, 2.1],
"k": 2,
"num_candidates": 100,
"similarity": 0.975,
"filter" : {
"range" : {
"price" : {
"gte": 100
}
}
}
}
}
指定されたフィルタに合致しない、あるいは指定した類似度より低いベクトルはスキップされ、k件の近傍が見つかるまでベクトル空間を探索していく仕組みです。もし、フィルタが厳しすぎたり、期待する類似度が高すぎたりして k件を確保できない場合は、最低限 k件を返せるように、ブルートフォース検索が代わりに試行されます。
次に、期待する最小類似度をどのように決めればいいか簡単に説明します。これはベクトルフィールドのマッピングでどの類似度指標を選択したかによります。もし l2_norm を選択したなら、これは距離ベースの関数なので(距離が大きくなるほど類似度が低下する)、k-NNクエリでは “最大許容距離” を設定します。つまり、クエリベクトルとの距離が 0 からその最大許容距離の範囲にあるベクトルを「十分近い」とみなし、類似していると判断します。
一方、dot_product や cosine のように、ベクトルの角度が開くほど類似度が低下する仕組みの “類似度関数” を選択した場合は、期待する “最小類似度” を設定します。クエリベクトルとの類似度が、その最小類似度以上、 1 以下にあるベクトルを「十分近い」と判断します。
先ほどのフィルタ付きクエリと、先にインデックスしたサンプルデータを例にすると、下の表 1 はクエリベクトルと各ベクトルのコサイン類似度を示しています。ご覧のとおり、フィルタ(price >= 100)によってベクトル 3 と 4 が候補となりますが、最小期待類似度(ここでは 0.975)を満たしているのはベクトル 3 のみです。
| Vector | Cosine similarity | Price |
|---|---|---|
| 1 | 0.8473 | 23 |
| 2 | 0.5193 | 9 |
| 3 | 0.9844 | 124 |
| 4 | 0.9683 | 1457 |
k-NN の制限事項
ここまで紹介してきた k-NN 検索には、いくつかの制限があります。
- 8.11 まで、
nestedドキュメント内のベクターに対しては k-NN 検索を実行できませんでした。8.12 以降は可能ですが、フィルタ付きのnestedknnは非対応です。 -
search_typeは常にdfs_query_then_fetchとなり、動的に変更できません。 - クロスクラスター検索 (CCS) を使う際、
ccs_minimize_roundtripsはサポートされません。 - HNSW など近似手法の性質上、「近似」である以上、厳密に真の最近傍を 100% 見つけられるわけではありません。
k-NN のチューニング
k-NN 検索のインデックス作成や検索性能を向上させるパラメータはまだ多く存在します。本記事では詳しく触れませんが、実運用で k-NN 検索を導入する場合は 公式ドキュメント も参照し、パラメータ調整を検討することを強くお勧めします。
k-NN を超えて
ここまで紹介してきたのは dense ベクターモデル(dense_vector フィールド)を使った手法です。Elasticsearch ではこれ以外にも、sparse ベクターモデルを活用する手段があります。
Elastic 社が提供する Elastic Learned Sparse EncodeR (ELSER) という疎ベクターモデルがあり、これは特定のドメインでトレーニングを行わなくても使える汎用的な NLP モデルです。約 3 万語のボキャブラリを使い、ほとんどの要素が 0 である疎ベクトルを生成します。
仕組みはとてもシンプルです。インデックス時には、inferenceインジェストプロセッサを利用してスパースベクトル(単語/重みのペア)を生成し、dense_vector のスパース版にあたる sparse_vector タイプのフィールドに格納します。クエリ時には、sparse_vector と呼ばれる専用のDSLクエリによって、元のクエリ用語がELSERモデルのボキャブラリに含まれる用語に置き換えられます。これらの用語は、重みに基づいて、クエリ用語に最も類似すると判断されたものです。
今後のトピックを少しだけ
Elasticsearch では従来のキーワード(テキスト)検索とベクター検索を組み合わせたハイブリッド検索もサポートしています。これは次回の最終回で扱う予定です。
さらに、これまでの例ではクエリベクターを自前で生成し、クエリリクエストにベクターを直接渡していましたが、Elasticsearch 上でクエリテキストから自動的にベクターを生成することも可能です。具体的には query_vector_builder(dense vector 用)や semantic_text フィールドタイプ+semantic クエリ(sparse vector 用)を活用すれば、クエリ文字列だけを指定してベクター検索ができます。詳細は こちらの記事をご覧ください。
まとめ
本記事では、Elasticsearch におけるベクター検索のサポートについて詳しく解説しました。
まずは Elasticsearch がベクター検索機能を実装するまでの背景に触れ、なぜ Apache Lucene をベクターエンジンとして選択したのかを紹介しました。
次に、script_score クエリを使う正確な検索 (exact search) と、knn 検索オプション/knn クエリを使う近似近傍探索 (approximate k-NN search) の2種類の方法を説明し、シンプルな k-NN 検索のやり方、フィルタや期待される類似度、複数 k-NN をまとめて実行する方法など、実践的な使い方を見てきました。
最後に、k-NN 検索の制限やパフォーマンスチューニングの必要性、疎ベクターモデル(ELSER)による別のアプローチにも簡単に触れました。
シリーズの他の記事もぜひご覧ください:
- パート1: ベクトル検索へのイントロダクション
- パート3: Elasticsearch でのハイブリッド検索 (近日公開予定)