最近コンピュータグラフィックス(CG)に入門中のマンボウです。
CG × Deep で面白いのを求めて漂っていたらレンダリングの微分なるものを見つけ興味を持ちました。
そこで本記事では、Neural 3D Mesh Renderer で遊んでみます。
論文情報
論文:Neural 3D Mesh Renderer [CVPR 2018]
著者:Kato Hiroharu, Ushiku Yoshitaka, Harada Tatsuya
実装1: https://github.com/hiroharu-kato/neural_renderer (著者らの Chainer 実装)
実装2: https://github.com/daniilidis-group/neural_renderer (PyTorch 実装)
arXiv:https://arxiv.org/abs/1711.07566
概要
レンダリング関数のパラメータによる微分を提案し、誤差逆伝播に組み込めるようにした。
論文の内容を一文で表現すると、上のようになるのではないかと思います。
ここでいうパラメータとは、レンダリングに必要な以下のようなやつらです。
- 三角形メッシュの位置(頂点の3次元座標)
- メッシュに付与されるテクスチャ
- カメラパラメータ(カメラ座標、向きなど)
- ライト(論文では Directional Light の向きと強さ、Ambient Light の強さ)
レンダリング関数は、これらのパラメータを引数にとって画像を出力する関数です。
関数をパラメータによって微分できると、勾配法を使うことができます。
レンダリングで勾配法を使えると、ある画像を表現する( = loss を最小化する)パラメータを
自動で求めることができます。

(借りました:https://groups.csail.mit.edu/graphics/classes/6.837/F03/models/teddy.obj )
例えば、「こんな画像↑を出力するような3Dモデルをくれ」と命令したら .obj ファイルが返ってくる
みたいなことが可能になります(そんな簡単にはいきませんが……)。
ちなみに、以下のようなことは今のところできないようです。
- 頂点の関係性(どの頂点同士が繋がっているか)を変更
- つまり、メッシュの張り替えは無理です
- 頂点数による微分
- よって、いい感じに頂点を増やしたり減らしたりは無理です
内容の詳しい説明はいくつかスライドが上がっているので省きます。
著者のスライド:https://www.slideshare.net/100001653434308/23d-neural-3d-mesh-renderer-cvpr-2018
勉強会のスライド:https://www.slideshare.net/DeepLearningJP2016/dlneural-3d-mesh-renderer
手法
コードを読んでいて、気になった部分だけ説明します。
Chainer
著者らは Chainer で実装しています。
Chainer では、chainer.Function を継承したクラスを作成し、
backward_gpu と forward_gpu というメソッドをオーバーライドしておくと、
その関数は Chainer の自動微分(誤差逆伝播)の仕組みに組み込むことができます。
これにより、そのクラスを用いた loss の計算を行い loss.backward() を呼び出すだけで、
loss を最小にするようなパラメータを勝手に計算してくれます。
また、CUDA による高速化を実現するために、chainer.cuda.elementwise を用いています。
これは cupy.ElementwiseKernel とほぼ同じで、並列化したい部分だけ CUDA で記述できる機能です。
cupy.ElementwiseKernel に関しては記事を書いたからよかったら見てくれよな!
レンダリングの微分
正直あまり自信が無いので間違っていたら教えてください!
この手法では、レンダリング( = Lighting + Projection + Rasterization)の中でも Rasterization の微分を提案しています(他の2つはほとんど四則演算なので簡単に微分できます)。
Rasterization の forward, backward は rasterize.py に実装されています。
backward の中でも要点となりそうな backward_pixel_map_gpu メソッドだけ説明します。

簡単のため、一つのメッシュが表示されていて、赤いピクセルがさらに暗くなってほしい(三角形の中に入っていてほしい)という誤差が伝搬してきたとします。その時の backward の動作を説明することにします。
① face (三角形メッシュ)1つを CUDA のスレッド1つに割り当てます。
# for each face
loop = self.xp.arange(self.batch_size * self.num_faces).astype('int32')
chainer.cuda.elementwise(
'int32 _, '...
(略)
)(
loop, ...
)
② edge ごとにループを回し、edge の上を沿って移動します(オレンジ)。

/* for each edge */
for (int edge_num = 0; edge_num < 3; edge_num++) {
(略)
/* for dy, dx */
for (int axis = 0; axis < 2; axis++) {
(略)
/* along edge */
int d0_from, d0_to;
d0_from = max(ceil(min(p[0][0], p[1][0])), 0.);
d0_to = min(max(p[0][0], p[1][0]), is - 1.);
for (int d0 = d0_from; d0 <= d0_to; d0++) {
(略)
}
}
}
③ 移動している edge 上の点がスクリーンに表示されていなければ無視します。
他の面で edge が隠れている場合などがこれにあたります。
このような場合には勾配は0になります。
bool is_in_fn = (face_index_map[map_index_in] == fn);
if (is_in_fn) {
(略)
}
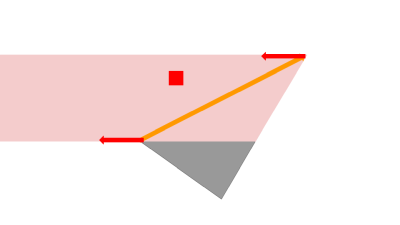
④ x軸方向、y軸方向にそれぞれ見ていき、対象画素が含まれていたら、対象画素が暗くなってほしい/明るくなってほしいという情報にもとづき、頂点をどちらに動かすか( = パラメータの更新方向)を決めます。
| x軸方向 | y軸方向 |
|---|---|
 |
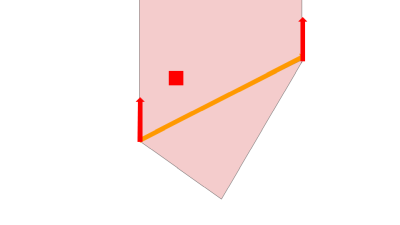 |
今見ている例では赤い画素は三角形の中に入って欲しいので、画像の赤矢印のような方向に動けば良いと分かります。
/* out(三角形から出ていく方向) */
for (int d1 = d1_from; d1 <= d1_to; d1++) {
(略)
}
/* in (三角形の中に入っていく方向) */
for (int d1 = d1_from; d1 <= d1_to; d1++) {
(略)
}
⑤勾配の合計を使ってパラメータを更新したいので、実際はx軸方向、y軸方向の矢印を合計した方向に更新します。このとき、x軸方向、y軸方向に見て、対象画素が edge に近いほど勾配を大きくし、遠いほど勾配を小さくします。つまり、近くの画素の影響を大きくしています。
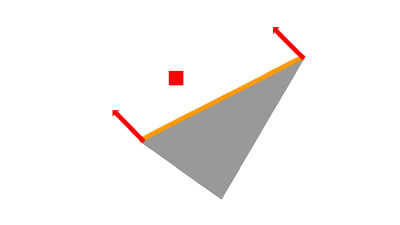
grad_face[pi[0] * 3 + (1 - axis)] -= diff_grad / dist;
(略)
grad_face[pi[1] * 3 + (1 - axis)] -= diff_grad / dist;
以上でレンダリング関数の微分を計算できたことになります。
この方法を用いると、メッシュから離れた画素の誤差も考慮することができ、rasterizationという離散的な関数でも勾配消失することなく誤差逆伝搬させることができます。
ちなみに、forward は通常のレンダリングと同じ挙動になります。
公式実装
論文では応用例として以下の3つが提示されています。
- Single-image 3D mesh reconstruction
- 2D-to-3D style transfer
- 3D DeepDream
GitHub には、レンダリングの微分を簡単に試せる以下の4つの実装が上がっています。
- Drawing an object from multiple viewpoints
- Optimizing vertices
- Optimizing textures
- Finding camera parameters
2, 3, 4 はコードが非常に似ています。
最適化したいパラメータを chainer.Parameter に設定→ loss を計算 → backward というシンプルな流れになっており、Neural 3D Mesh Renderer が DeepLearning に出てくる様々な関数と同じようなノリで使えることが分かります。
遊んでみた
設定
ちょうど example2 : Optimizing vertices が画像の見た目を loss としてメッシュを変形する例なので、これを少し変更して遊んでみました。今回は、以下のような設定で、メッシュの位置(頂点の座標)をパラメータとして最適化を行います。
| 入力 | 出力して欲しいもの |
|---|---|
 |
 |
| (借りました:https://groups.csail.mit.edu/graphics/classes/6.837/F03/models/teddy.obj ) |
入力:多視点(今回は9個の視点)のシルエット
出力して欲しいもの:入力のシルエットを表現するようなメッシュ( .obj ファイル)
カメラパラメータは既知とし、シルエットを出力した時と同じものを用います。
また、頂点数を増やしたり減らしたりはできないので、変形元のメッシュが必要です。
今回は変形元のメッシュとして以下のような球を用いました
三角形メッシュの数は、クマが3192、球が960なので完璧な再現は無理です。
粗くても良いのでクマっぽくなってくれることを期待して実験しました。

(借りました:https://github.com/SaschaWillems/Vulkan/blob/master/data/models/sphere.obj )
loss の計算
loss は論文でも用いられている silhouette loss を用いました。
レンダリングした画像のシルエット同士の square error をとっているだけです。
loss = 0
for azimuth in range(9): # 視点の数は9(方位各のみ変更した画像を9パターン用意している)
self.renderer.eye = neural_renderer.get_points_from_angles(
self.camera_distance, self.elevation, azimuth)
image = self.renderer.render_silhouettes(self.vertices, self.faces)
loss += cf.sum(cf.square(image - self.images_ref[azimuth, :, :]))
結果
最適化過程

最終的にできた3Dモデル

うーん…
ぱっと見で分かることとして、メッシュがぐちゃぐちゃになっています。
あるメッシュが他のメッシュに食い込んだり、鋭いメッシュが突き出しだりしているのが分かります。
スクリーンのx軸方向とy軸方向に鋭いメッシュが突き出すのは、rasterization の微分を計算する時に、
x軸方向とy軸方向のみを見ているのが原因な気がします。
論文では smoothness loss というものが紹介されていて、メッシュの面同士の角度が180°に近くなるように制約を付けているようなので、これを実装すればもっと良くなるかもしれません。
また、三角形の面積がバラバラなので、三角形の面積の分散を loss にしてみるのも良いかもしれません。
時間があるときにやってみたいです。
あまり綺麗な結果にはなりませんでしたが、コード全文を掲載しておきます。
example2 とほとんど同じなので、見比べると分かりやすいかもしれません。
import argparse
import os
import subprocess # noqa
import chainer
import chainer.functions as cf
import numpy as np
import scipy.misc
import glob
import imageio
import tqdm
import neural_renderer
class Model(chainer.Link):
def __init__(self, filename_obj, ref_dir, camera_distance, elevation):
super(Model, self).__init__()
self.camera_distance = camera_distance # 固定
self.elevation = elevation # 固定
with self.init_scope():
# load .obj
vertices, faces = neural_renderer.load_obj(filename_obj)
self.vertices = chainer.Parameter(vertices[None, :, :])
self.faces = faces[None, :, :]
self.areas = np.zeros((1, self.faces.shape[1])).astype('float32')
# create textures
texture_size = 2
textures = np.ones((1, self.faces.shape[1], texture_size, texture_size, texture_size, 3), 'float32')
self.textures = textures
# load reference image
imgs = []
for ref_name in glob.glob(ref_dir + '*.png'):
# グレースケールでシルエット画像群を読み込み
img = imageio.imread(ref_name).astype('float32').mean(-1) / 255.
imgs.append(img)
self.images_ref = np.array(imgs)
# setup renderer
renderer = neural_renderer.Renderer()
self.renderer = renderer
def to_gpu(self, device=None):
super(Model, self).to_gpu(device)
self.faces = chainer.cuda.to_gpu(self.faces, device)
self.textures = chainer.cuda.to_gpu(self.textures, device)
self.images_ref = chainer.cuda.to_gpu(self.images_ref, device)
self.areas = chainer.cuda.to_gpu(self.areas, device)
def __call__(self):
loss = 0
for azimuth in range(9):
self.renderer.eye = neural_renderer.get_points_from_angles(
self.camera_distance, self.elevation, azimuth)
image = self.renderer.render_silhouettes(self.vertices, self.faces)
loss += cf.sum(cf.square(image - self.images_ref[azimuth, :, :]))
return loss
def run():
parser = argparse.ArgumentParser()
parser.add_argument('-io', '--filename_obj', type=str, default='./examples/data/sphere.obj')
parser.add_argument('-ref', '--ref_dir', type=str, default='./ref/')
parser.add_argument('-op', '--output_progress_dir', type=str, default='./progress/')
parser.add_argument('-or', '--output_result_dir', type=str, default='./result/')
parser.add_argument('-g', '--gpu', type=int, default=0)
args = parser.parse_args()
out_result_dir = args.output_result_dir
out_progress_dir = args.output_progress_dir
ref_dir = args.ref_dir
filename_obj = args.filename_obj
os.makedirs(out_result_dir, exist_ok=True)
os.makedirs(out_progress_dir, exist_ok=True)
iteration = 10000
camera_distance = 2.732
elevation = 30
model = Model(filename_obj, ref_dir, camera_distance, elevation)
model.to_gpu()
optimizer = chainer.optimizers.Adam()
optimizer.setup(model)
loop = tqdm.tqdm(range(iteration))
for i in loop:
loop.set_description('Optimizing')
optimizer.target.cleargrads()
loss = model()
loss.backward()
optimizer.update()
if i % 10 == 0:
images = model.renderer.render(model.vertices, model.faces, model.textures)
image = images.data.get()[0].transpose((1, 2, 0))
scipy.misc.toimage(image, cmin=0, cmax=1).save('%s/optimizing_%04d.png' % (out_progress_dir, i))
# draw object
loop = tqdm.tqdm(range(0, 360, 4))
for num, azimuth in enumerate(loop):
loop.set_description('Drawing')
model.renderer.eye = neural_renderer.get_points_from_angles(camera_distance, elevation, azimuth)
images = model.renderer.render(model.vertices, model.faces, model.textures)
image = images.data.get()[0].transpose((1, 2, 0))
scipy.misc.toimage(image, cmin=0, cmax=1).save('%s/output_%04d.png' % (out_result_dir, num))
if __name__ == '__main__':
run()