はじめに
前略、ADKで出力トークンを抑える方法が知りたかったのでしらべました。
出力トークンの上限を設定したい
LLMの料金は使用したトークンの量によって決まります。
そのため、AIエージェントを一般公開する場合、想定外の請求が来ないよう、トークン消費を抑える仕組みが必要になります。
入力についてはバリデーションなどで弾けますが、アウトプットに関しても制御を行いたいです。
また、出力トークンのほうが基本的には高いです。
max_output_tokens
ADKにおいては、max_output_tokensという項目で出力トークンの最大を指定できるようです。
出力を制限できるものの、レスポンスに返ってきてこないだけで実際には消費しているのか、そもそも消費していないのか、この辺は未確認です。
実装はこんな感じで指定します。
from google.genai import types
root_agent = Agent(
model=os.environ.get("MODEL"),
instruction="挨拶を返してください。猫のような口調で会話してください。",
generate_content_config=types.GenerateContentConfig(
safety_settings=[
types.SafetySetting(
category=types.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=types.HarmBlockThreshold.BLOCK_LOW_AND_ABOVE,
),
],
max_output_tokens=20,
),
)
試してみると、以下のように出力が制限されました。

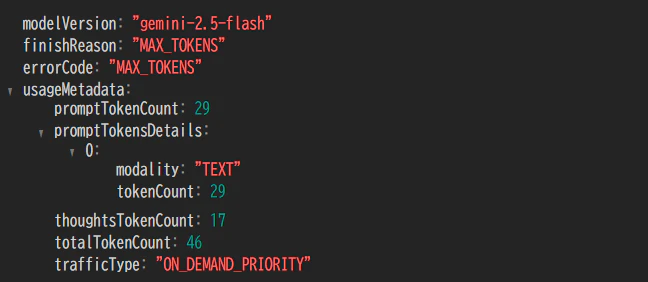
finishReasonがMAX_TOKENSとなっています。
一方で、errorCodeもMAX_TOKENSとなっており、エラー扱いとされている?
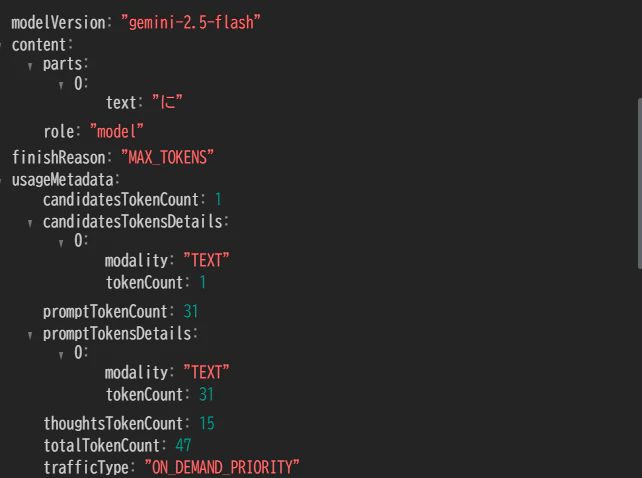
何度か試していると、「に」だけ出力できる場合もありました。

その場合、finishReasonがMAX_TOKENSとなっているもののerrorCodeエラー扱いにはなってなさそうです。
どういう制御なのかいまいちつかめませんが、とりあえず制御はできてそう、、、?
上限を70くらいまで上げるとfinishReasonが通常通りになりました。

thoughtsTokenCount(思考トークン)が56ほどどなっており、candidatesTokenCount(回答のトークン)と足すと64です。
出力トークンはこの二つが該当するので、どうやら思考トークンを含めたトークンが上限となっているようですね。

おわりに
今回はADKでmax_token_outputを試してみました。
本来の目的は請求を抑えることなので、ちゃんと抑えることができているかは別途確認してみようと思います。
ここまでご覧いただきありがとうございました!