はじめに
Microsoft Azire AKSのKubernetes上に、Prometheus & Grafanaによるリソース監視、Elasticsearch & fluentd & Kibanaによるログ集約、及びGrafanaによるリソースとログのアラート通知を構築するという連載の2回目です。
第一回: https://qiita.com/nmatsui/items/6d8319f3216bd8786eb9
第二回: https://qiita.com/nmatsui/items/ef7cf8f5c957f82d2ca1
前回は、Azure AKS上にPrometheusとGrafanaを構築し、イイカンジにリソース監視をするところまでを解説しました。今回は、Azure AKS上にElasticsearch + Fluentd + Kibanaを立ち上げて各NodeやPodのログを集約し、Curatorで削除運用をまわし、ログに特定の文字列が存在する場合にはGrafanaからSlackへ通知させる、というところまで解説します。
検証した環境
- クラウド側
| バージョン | |
|---|---|
| Microsoft Azure AKS | 1.11.1 |
- クライアント側
| バージョン | |
|---|---|
| kubectl | 1.11.2 |
| azure-cli | 2.0.44 |
| helm | 2.9.1 |
検証で用いたyaml等の詳細は、githubに公開しています。nmatsui/kubernetes-monitoringを参照してください。
環境構築
Microsoft Azure AKSの確認
前回作成したAzure AKSの環境をそのまま使います。
$ az aks show --resource-group k8s --name k8saks
$ az aks get-credentials --resource-group k8s --name k8saks
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-14983502-0 Ready agent 6h v1.11.1
aks-nodepool1-14983502-1 Ready agent 6h v1.11.1
aks-nodepool1-14983502-2 Ready agent 6h v1.11.1
Elasticsearch + Fluentd + Kibanaのインストール
前回、CoreOS謹製のHelm Chartを用いてさくっとPrometheus + Grafanaをインストールしました(Azure AKSに適合させるようにパッチするのは、さくっとはいきませんでしたが・・・)。
しかしElasticsearch + Fluentd + Kibanaについては、まるっとインストールしてくれるイイカンジなHelm Chartが見当たりません(個人的に公開されているHelm Chartはありますが、最新版への追従がいまいちだったり)。
そこで今回は、kubernetes本体のリポジトリに内包されるElasticsearch Add-Onを改造して使うことにします。見る限りではこのリポジトリはきちんとメンテナンスされており、またfluentdのルールもconfigmapにそのまま格納する形となっているため、扱いやすそうだからです。
Elasticsearchのインストール
ElasticsearchのStatefulSet登録
StatefulSetとしてElasticsearchをインストールします。replicaは最低限の2としています。kubernetes/cluster/addons/fluentd-elasticsearch/es-statefulset.yamlからの変更点は、次の2点です。
- namespaceを
kube-systemからmonitoringに変更- 前回
monitoringにインストールしたGrafanaと連携できるようにするため
- 前回
- データ領域は、podのemptyDirではなくPersistentVolumeを使用
データ領域のサイズは、必要に応じて適切に変更してください。
@@ -3,7 +3,7 @@
kind: ServiceAccount
metadata:
name: elasticsearch-logging
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
@@ -30,7 +30,7 @@
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
- namespace: kube-system
+ namespace: monitoring
name: elasticsearch-logging
labels:
k8s-app: elasticsearch-logging
@@ -39,7 +39,7 @@
subjects:
- kind: ServiceAccount
name: elasticsearch-logging
- namespace: kube-system
+ namespace: monitoring
apiGroup: ""
roleRef:
kind: ClusterRole
@@ -51,7 +51,7 @@
kind: StatefulSet
metadata:
name: elasticsearch-logging
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: elasticsearch-logging
version: v6.2.5
@@ -96,9 +96,6 @@
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- volumes:
- - name: elasticsearch-logging
- emptyDir: {}
# Elasticsearch requires vm.max_map_count to be at least 262144.
# If your OS already sets up this number to a higher value, feel free
# to remove this init container.
@@ -108,3 +105,12 @@
name: elasticsearch-logging-init
securityContext:
privileged: true
+ volumeClaimTemplates:
+ - metadata:
+ name: elasticsearch-logging
+ spec:
+ accessModes: ["ReadWriteOnce"]
+ storageClassName: managed-premium
+ resources:
+ requests:
+ storage: 64Gi
$ kubectl apply -f logging/es-statefulset.yaml
数分後、ElasticsearchのStatefulSetとPod、及びPersistentVolumeが構築されていることが確認できます。
$ kubectl get statefulsets --namespace monitoring -l k8s-app=elasticsearch-logging
NAME DESIRED CURRENT AGE
elasticsearch-logging 2 2 6m
$ kubectl get pods --namespace monitoring -l k8s-app=elasticsearch-logging
NAME READY STATUS RESTARTS AGE
elasticsearch-logging-0 1/1 Running 0 7m
elasticsearch-logging-1 1/1 Running 0 4m
$ kubectl get persistentvolumeclaims --namespace monitoring -l k8s-app=elasticsearch-logging
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
elasticsearch-logging-elasticsearch-logging-0 Bound pvc-a1c884f6-a36d-11e8-8990-caec6aa008cf 64Gi RWO managed-premium 7m
elasticsearch-logging-elasticsearch-logging-1 Bound pvc-f4494adf-a36d-11e8-8990-caec6aa008cf 64Gi RWO managed-premium 5m
ElasticsearchのService登録
同様に、namespaceをkube-systemからmonitoringに変更してElasticsearchのServiceも構築します。
@@ -2,7 +2,7 @@
kind: Service
metadata:
name: elasticsearch-logging
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: elasticsearch-logging
kubernetes.io/cluster-service: "true"
$ kubectl apply -f logging/es-service.yaml
$ kubectl get services --namespace monitoring -l k8s-app=elasticsearch-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-logging ClusterIP 10.0.150.102 <none> 9200/TCP 1m
Elasticsearchの設定
StatefulSetを起動した段階で、自動的にクラスタリングまで行われます。ついでにShardの移動も許可しておきます。
$ kubectl exec -it elasticsearch-logging-0 --namespace monitoring -- curl -H "Content-Type: application/json" -X PUT http://elasticsearch-logging:9200/_cluster/settings -d '{"transient": {"cluster.routing.allocation.enable":"all"}}'
この段階で、Elasticsearchは2nodeのクラスタとして利用可能になっていいます。
$ kubectl exec -it elasticsearch-logging-0 --namespace monitoring -- curl -H "Content-Type: application/json" http://elasticsearch-logging:9200/_cluster/health?pretty=true
{
"cluster_name" : "kubernetes-logging",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Fluentdのインストール
Fluentdのconfigmap登録
namespaceをkube-systemからmonitoringに変更し、Fluentdのconfigmapを登録します。不要なログなどがあれば、この段階でフィルタしてしまえば良いでしょう。
@@ -2,7 +2,7 @@
apiVersion: v1
metadata:
name: fluentd-es-config-v0.1.4
- namespace: kube-system
+ namespace: monitoring
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
$ kubectl apply -f logging/fluentd-es-configmap.yaml
$ kubectl get configmap --namespace monitoring | grep fluentd
fluentd-es-config-v0.1.4 6 48s
FluentdのDaemonSet登録
今回は、Podのstdout&stderrをnodeごとに起動しているfluentdが集約し、Elasticsearchへと送るパターンとなります。
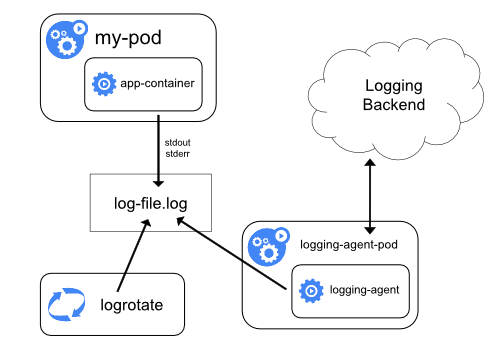
出展: https://kubernetes.io/docs/concepts/cluster-administration/logging/
FluentdはDaemonSetとして起動しますが、kubernetes/cluster/addons/fluentd-elasticsearch/fluentd-es-ds.yamlからは次の3点を変更しています。
- namespaceを
kube-systemからmonitoringに変更 -
priorityClassNameは定義しない- 2018/08/19時点では、Azure AKSはpriorityClassの作成ができない模様(次のようなエラーになる)
no matches for kind "PriorityClass" in version "scheduling.k8s.io/v1alpha1"
- nodeSelectorを削除
- Azure AKSのnodeには、
fluentd-ds-readyのようなラベルは付いていないため
- Azure AKSのnodeには、
@@ -2,7 +2,7 @@
kind: ServiceAccount
metadata:
name: fluentd-es
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
@@ -38,7 +38,7 @@
subjects:
- kind: ServiceAccount
name: fluentd-es
- namespace: kube-system
+ namespace: monitoring
apiGroup: ""
roleRef:
kind: ClusterRole
@@ -49,7 +49,7 @@
kind: DaemonSet
metadata:
name: fluentd-es-v2.2.0
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: fluentd-es
version: v2.2.0
@@ -73,7 +73,7 @@
scheduler.alpha.kubernetes.io/critical-pod: ''
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
- priorityClassName: system-node-critical
+ # priorityClassName: system-node-critical
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
@@ -95,8 +95,6 @@
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
- nodeSelector:
- beta.kubernetes.io/fluentd-ds-ready: "true"
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
$ kubectl apply -f logging/fluentd-es-ds.yaml
各Nodeに一つずつFluentdが起動していることを確認します。
$ kubectl get daemonsets --namespace monitoring -l k8s-app=fluentd-es
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-es-v2.2.0 3 3 3 3 3 <none> 40s
$ kubectl get pods --namespace monitoring -l k8s-app=fluentd-es -o wide
NAME READY STATUS RESTARTS AGE IP NODE
fluentd-es-v2.2.0-5dcnm 1/1 Running 0 1m 10.244.1.9 aks-nodepool1-14983502-2
fluentd-es-v2.2.0-qrlws 1/1 Running 0 1m 10.244.2.9 aks-nodepool1-14983502-1
fluentd-es-v2.2.0-sfw8j 1/1 Running 0 1m 10.244.0.8 aks-nodepool1-14983502-0
Kibanaのインストール
KibanaのDeployment登録
Kibana自身は落ちても再起動してくれれば問題ないため、replica数は1で起動します。kubernetes/cluster/addons/fluentd-elasticsearch/kibana-deployment.yamlからは次の2点を変更しています。
- namespaceを
kube-systemからmonitoringに変更 -
SERVER_BASEPATH環境変数を削除- proxyではなくport-forwardで接続するため
@@ -2,7 +2,7 @@
kind: Deployment
metadata:
name: kibana-logging
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
@@ -31,8 +31,6 @@
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch-logging:9200
- - name: SERVER_BASEPATH
- value: /api/v1/namespaces/kube-system/services/kibana-logging/proxy
ports:
- containerPort: 5601
name: ui
$ kubectl apply -f logging/kibana-deployment.yaml
Kibanaのpodが一つだけ起動していることを確認します。
$ kubectl get deployments --namespace monitoring -l k8s-app=kibana-logging
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kibana-logging 1 1 1 0 1m
$ kubectl get pods --namespace monitoring -l k8s-app=kibana-logging
NAME READY STATUS RESTARTS AGE
kibana-logging-7444956bf8-55dd6 1/1 Running 0 1m
KibanaのService登録
やはりnamespaceをkube-systemからmonitoringに変更して、KibanaのServiceを構築します。
@@ -2,7 +2,7 @@
kind: Service
metadata:
name: kibana-logging
- namespace: kube-system
+ namespace: monitoring
labels:
k8s-app: kibana-logging
kubernetes.io/cluster-service: "true"
$ kubectl apply -f logging/kibana-service.yaml
$ kubectl get services --namespace monitoring -l k8s-app=kibana-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kibana-logging ClusterIP 10.0.39.78 <none> 5601/TCP 12s
CuratorのCronJobのインストール
ここまででElasticsearch + Fluentd + Kibanaのインストールは完了しましたが、PersistentVolumeのサイズも有限ですし、不要になったログはバックアップして削除する運用も必要です。そこでCuratorの出番がやってきます。
今回はサンプルとして、2日以上前のログは消してしまう運用を登録します。
まずはCuratorの設定をconfigmapとして登録します。
apiVersion: v1
kind: ConfigMap
metadata:
name: curator-config
namespace: monitoring
data:
action_file.yml: |-
---
actions:
1:
action: delete_indices
description: "Clean up ES by deleting old indices"
options:
timeout_override:
continue_if_exception: False
disable_action: False
ignore_empty_list: True
filters:
- filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 2
field:
stats_result:
epoch:
exclude: False
config.yml: |-
---
client:
hosts:
- elasticsearch-logging
port: 9200
url_prefix:
use_ssl: False
certificate:
client_cert:
client_key:
ssl_no_validate: False
http_auth:
timeout: 30
master_only: False
logging:
loglevel: INFO
logfile:
logformat: default
blacklist: ['elasticsearch', 'urllib3']
$ kubectl apply -f logging/curator-configmap.yaml
$ kubectl get configmap --namespace monitoring | grep curator
curator-config 2 20s
次に、この設定をもとにCuratorをJobとして走らせるCronJobを登録します。起動するスケジュールはUTCで指定するため、0 18 * * *と指定すれば、毎日日本時間の深夜3時にCuratorのJobが走ることになります。
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: elasticsearch-curator
namespace: monitoring
labels:
k8s-app: elasticsearch-curator
spec:
schedule: "0 18 * * *"
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 3
concurrencyPolicy: Forbid
startingDeadlineSeconds: 120
jobTemplate:
spec:
template:
spec:
containers:
- image: bobrik/curator:5.5.4
name: curator
args: ["--config", "/etc/config/config.yml", "/etc/config/action_file.yml"]
volumeMounts:
- name: config
mountPath: /etc/config
volumes:
- name: config
configMap:
name: curator-config
restartPolicy: OnFailure
$ kubectl apply -f logging/curator-cronjob.yaml
$ kubectl get cronjobs --namespace monitoring -l k8s-app=elasticsearch-curator
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
elasticsearch-curator 0 18 * * * False 0 <none> 45s
翌日に確認してみると、CronJobが実行され、日本時間の深夜3時にJobが実行されたことがわかります。
$ kubectl get cronjobs --namespace monitoring -l k8s-app=elasticsearch-curator
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
elasticsearch-curator 0 18 * * * False 0 4h 16h
$ kubectl describe jobs elasticsearch-curator-1534701600 --namespace monitoring
Name: elasticsearch-curator-1534701600
Namespace: monitoring
# ...(省略)...
Controlled By: CronJob/elasticsearch-curator
Parallelism: 1
Completions: 1
Start Time: Mon, 20 Aug 2018 03:00:08 +0900
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
# ...(省略)...
Elasticsearch + Fluentd + Kibanaの動作確認
では、Elasticsearchにログが集約されているか、Kibanaで確認してみましょう。
Kibanaの5601ポートをforwardし、ブラウザで http://localhost:5601/ にアクセスしてダッシュボードを表示します。
$ kubectl port-forward $(kubectl get pod --namespace monitoring -l k8s-app=kibana-logging -o template --template "{{(index .items 0).metadata.name}}") --namespace monitoring 5601:5601
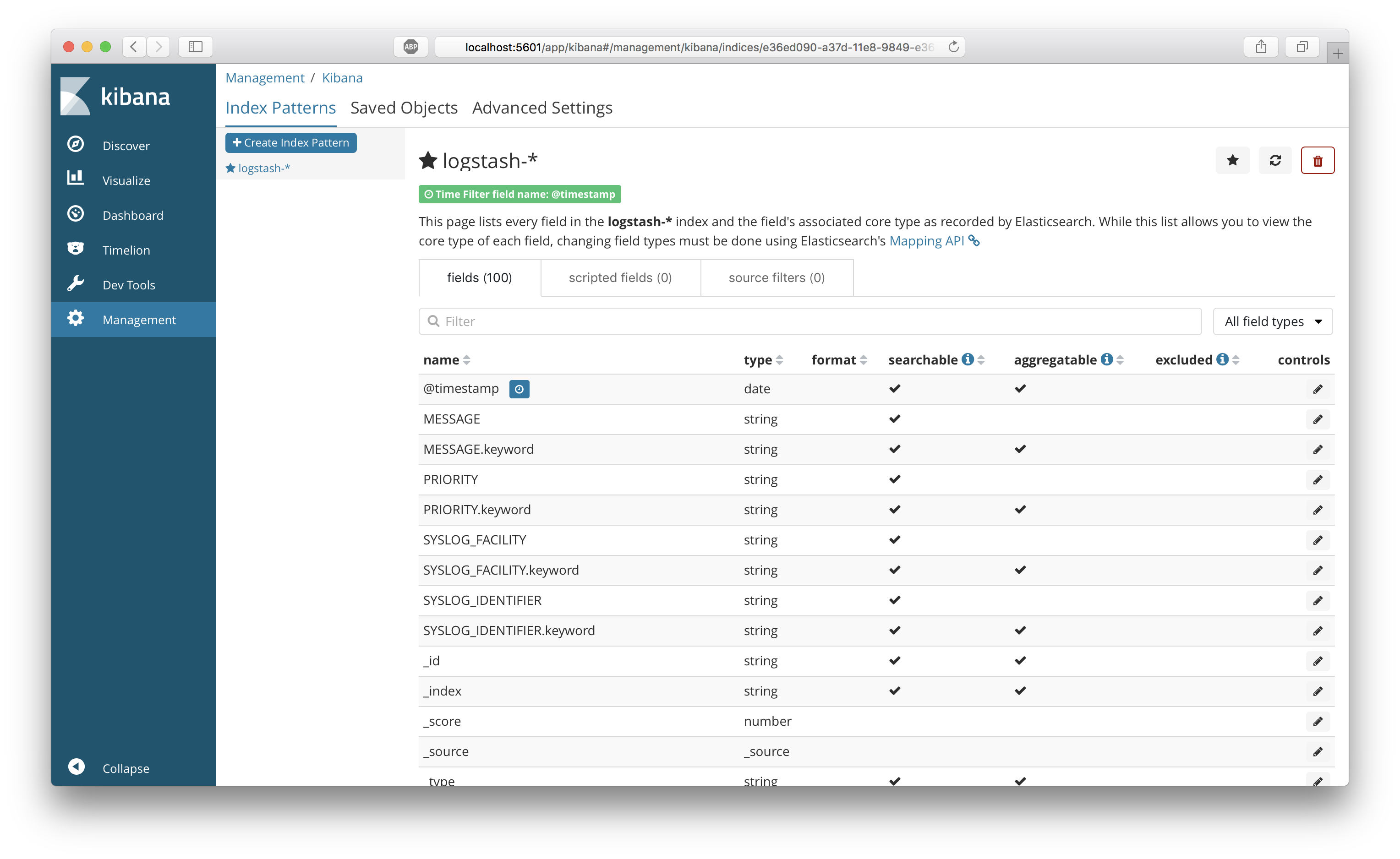
Management -> Index Patterns から、Index Patternとして logstash-* を指定し、Time filter fieldとして @timestamp を指定して、Indexを作成します。
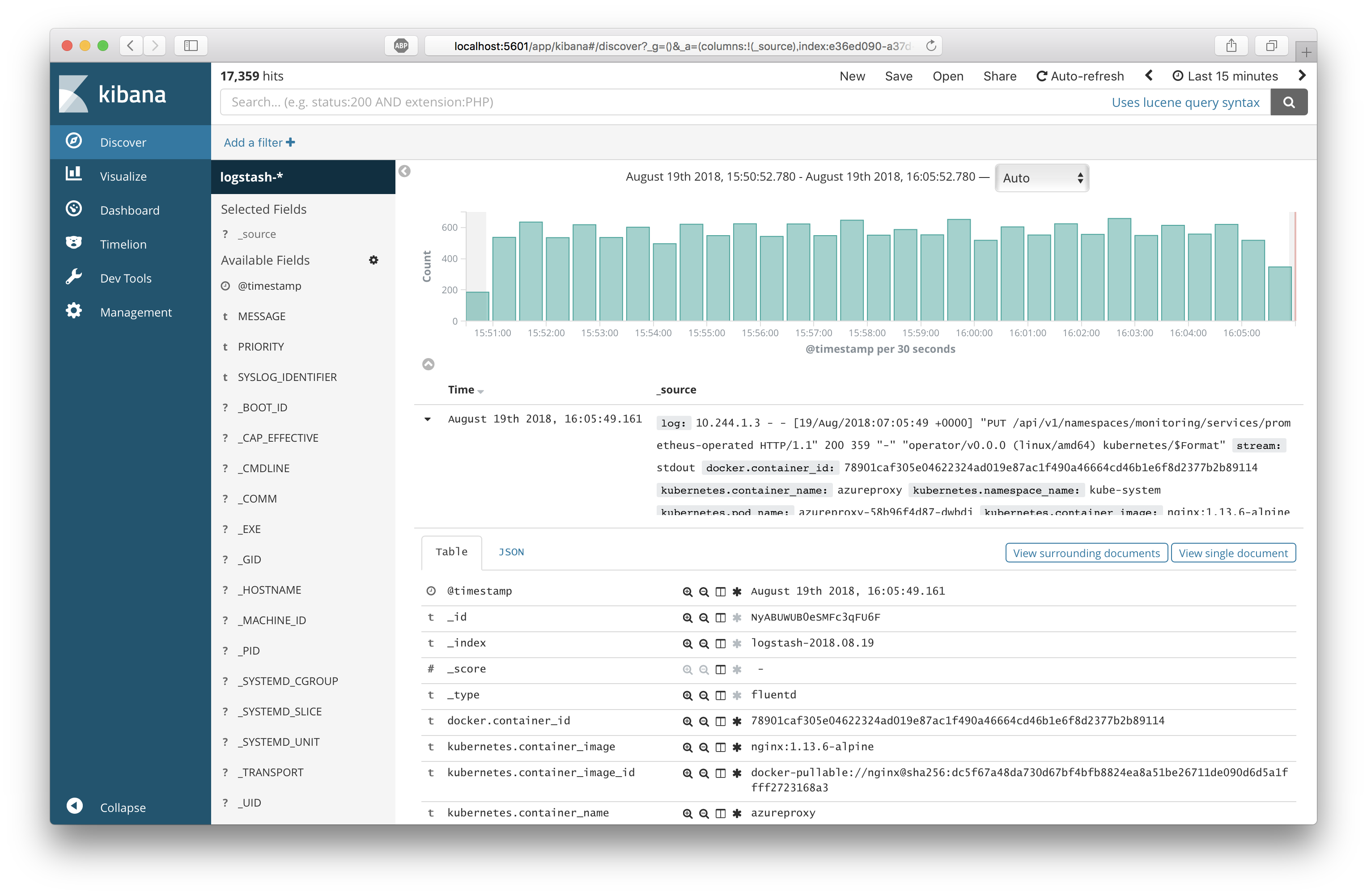
Kuberntesに関する様々メタデータとともに、各Nodeと各PodのログがIndexされていることがわかります。
Esaticsearch + Grafanaによるログアラート通知
それでは最後に、Esaticsearch + Grafanaによるログアラート通知を試してみましょう。
なおElasticsearchをDatasourceにしてのAletingは、最新のGrafana 5.2から導入された新機能になります。5.2以前のGrafanaの場合、Elasticsaerchのログを収集して可視化することはできますが、Alertを設定することができませんので注意が必要です。
任意にエラーログを出力できるPodを登録
検証用に、/error/というパスにアクセスするとエラーログを出力する、というテスト用のREST APIをPodとして登録します。このPodの詳細はnmatsui/kubernetes-monitoring/test-logging-apiを参照してください。
$ kubectl apply -f test-pod/test-pod.yaml
起動していることを確認します。
$ kubectl get pods -l app=test-pod
NAME READY STATUS RESTARTS AGE
test-pod-7d9c9b85f9-mktl5 1/1 Running 0 30s
ログを出力してみましょう。このPodの3030ポートにport-forwadし、同時に別の端末でこのPodのログもtailしておきます。
$ kubectl port-forward $(kubectl get pod -l app=test-pod -o template --template "{{(index .items 0).metadata.name}}") 3030:3030
$ kubectl logs -f $(kubectl get pod -l app=test-pod -o template --template "{{(index .items 0).metadata.name}}")
curlで http://loalhost:3030/ をGETしてみましょう。下記のようなDEBUGログが1行出力されたことが確認できます。
[2018-08-19T08:43:26.595] [DEBUG] app - request path: /
Grafanaの設定
ElasticsearchをDataSourceとして追加
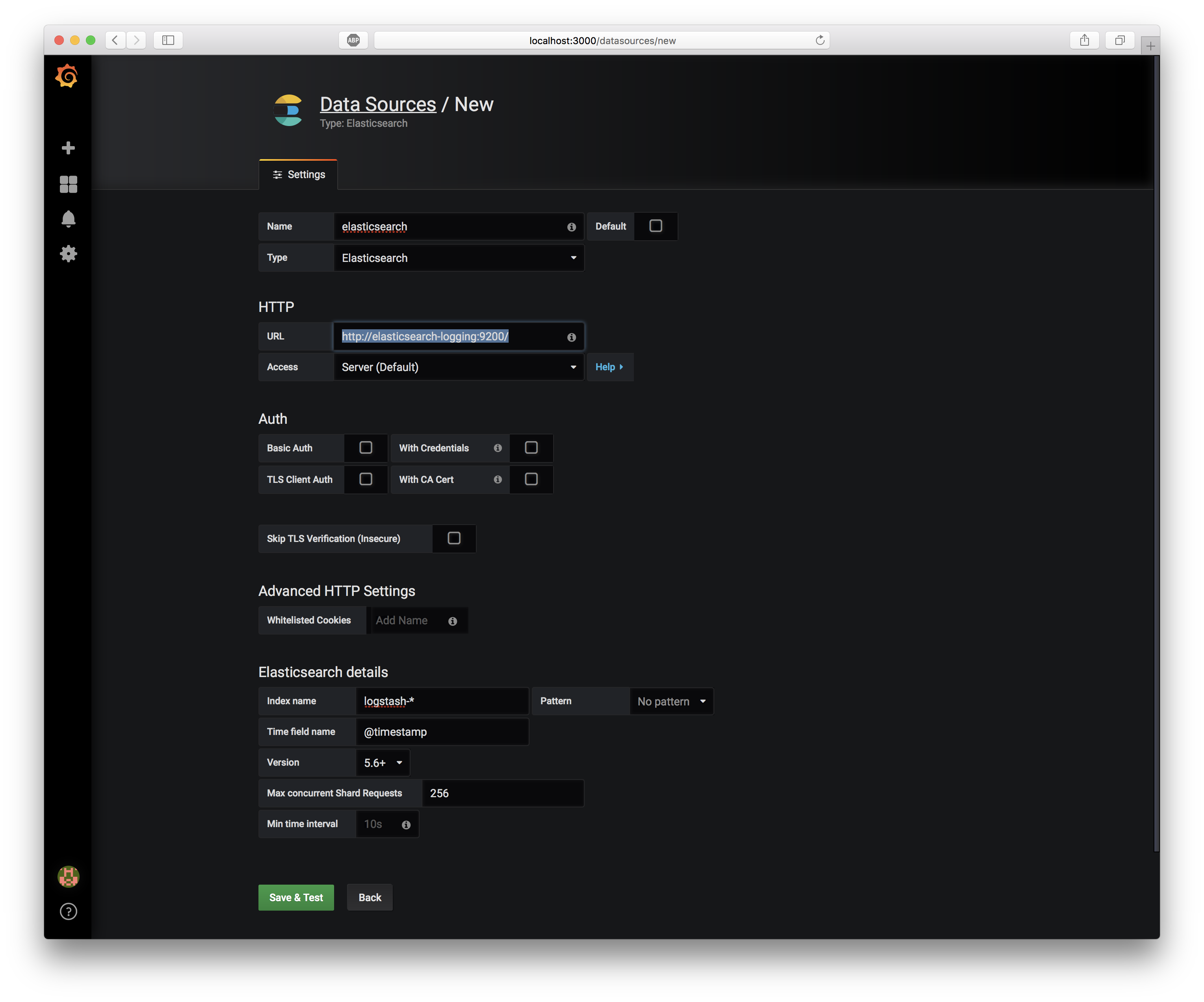
Elsaticsearch Serviceの名前とポートを確認し、GrafanaへElasticsearchをDataSourceとして追加します。
$ kubectl get services --namespace monitoring -l k8s-app=elasticsearch-logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-logging ClusterIP 10.0.150.102 <none> 9200/TCP 3h
- name:
elasticsearch - Type:
Elasticsearch - URL:
http://elasticsearch-logging:9200/ - Access:
Server(Default) - Index name:
logstash-* - Time field nama:
@timestamp - Version: 5.6+
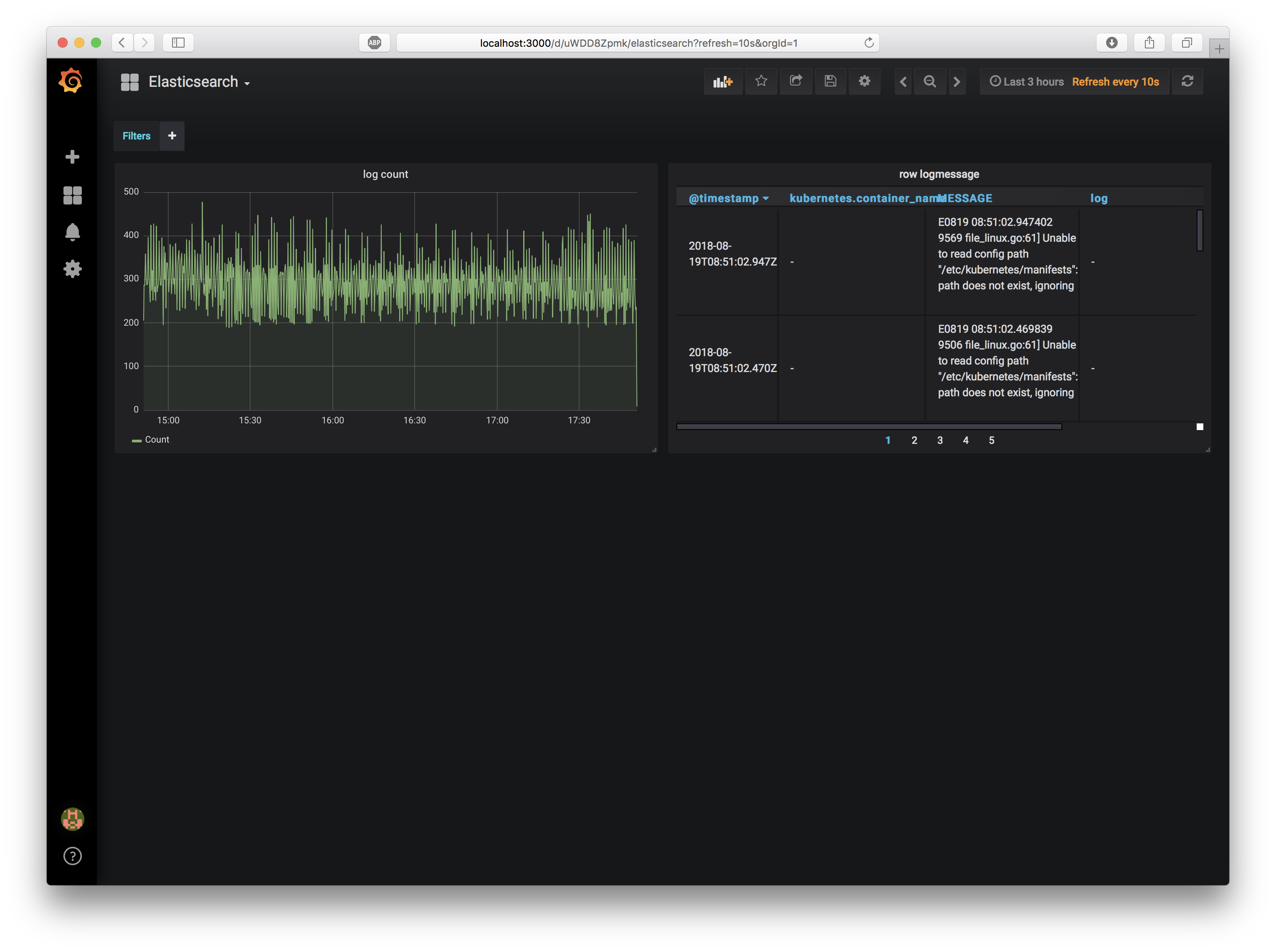
ElasticsearchのDashboardをImpoort
monitoring/dashboard_elasticsearch.json をimportします。
ログの数を可視化したGraphと、生のログを表示するTableを持ったDashboardが追加されます。
通知チャネルにSlackを追加
Grafanaは、Slackへアラートを通知する機能を最初から備えています。
Alerting -> Notification channelsから、新たなSlack Channelを追加してください。
- Name:
slack - Type:
Slack - Url:
SlackのWebhook URL
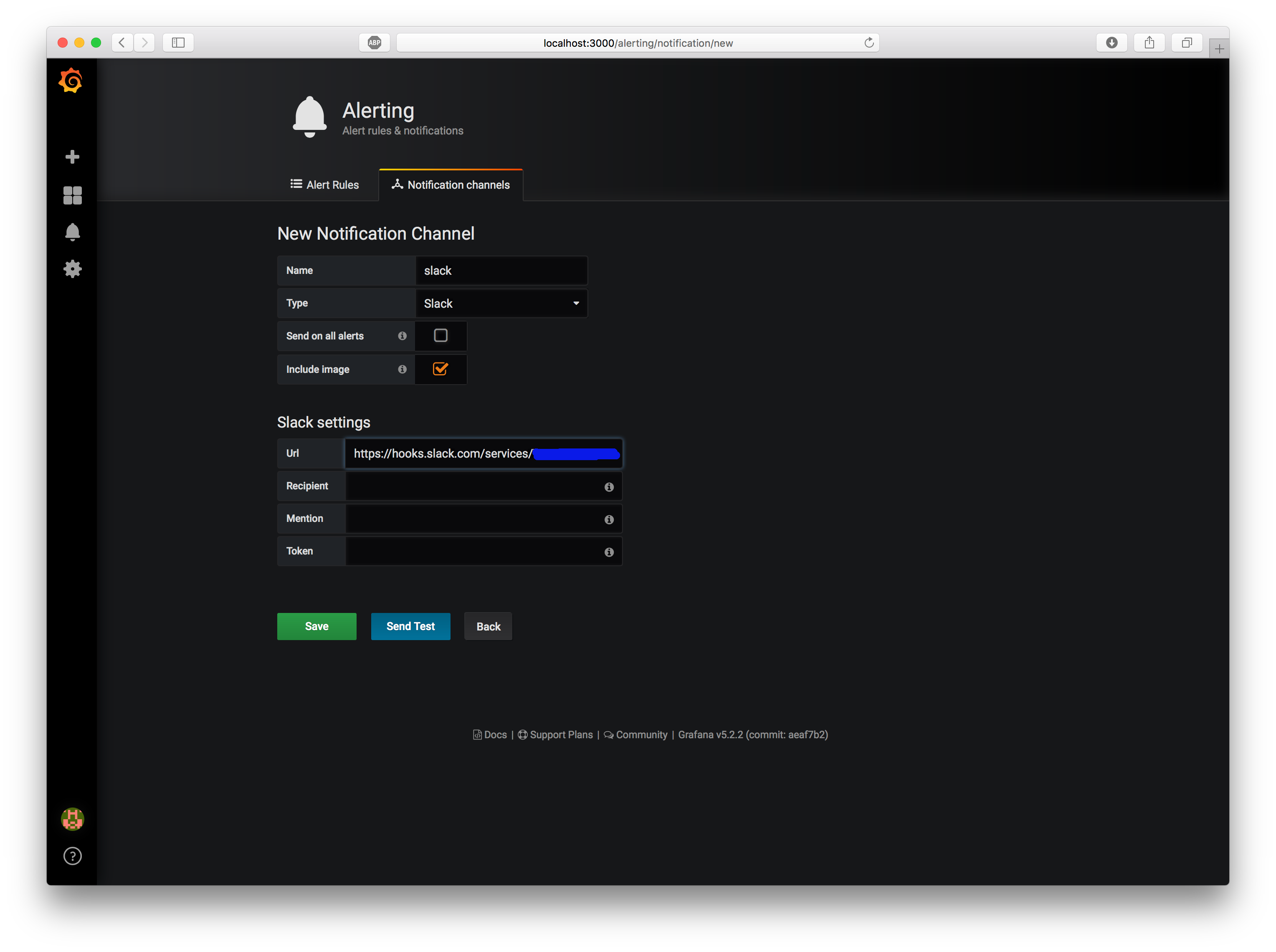
"Send Test" ボタンを押し、Slackのチャネルへ "[Alerting] Test notification" というメッセージが到着することを確認してください。
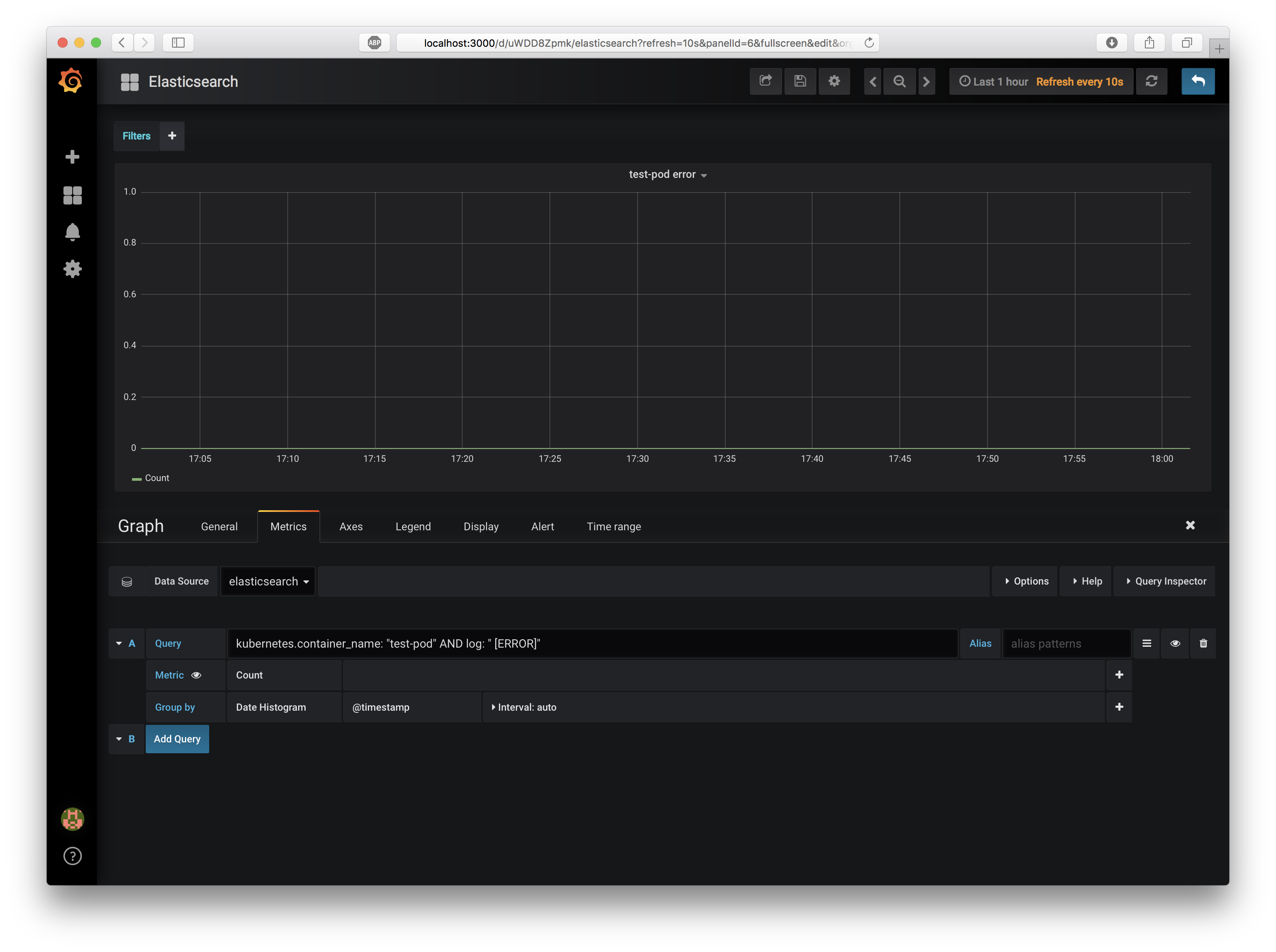
Grafanaへtest-podの[ERROR]を検知するパネルを追加
このElasticsearchDashboardに、test-podが[ERROR]というログを出力したら検知するパネルを追加しましょう。
上部の "Add Panel" アイコンを押してGraphを一つ追加し、生成されたGraphの "Edit" して以下のように修正します。
- General
- Title:
test-pod error
- Title:
- Metrics
- DataSource:
elasticsearch - A
- Query:
kubernetes.container_name:"test-pod" AND log:"[ERROR]" - Metric:
Count
- Query:
- DataSource:
- Axis
- LeftY
- Y-Min:
0
- Y-Min:
- LeftY
では、エラーメッセージを出力させてみましょう。
$ curl -i http://localhost:3030/error/
HTTP/1.1 500 Internal Server Error
X-Powered-By: Express
Content-Type: application/json; charset=utf-8
Content-Length: 27
ETag: W/"1b-BKZcJDCXkpfhBOSVMNakKtV/a+s"
Date: Sun, 19 Aug 2018 09:03:32 GMT
Connection: keep-alive
{"result":"Error: error!!"}
$ kubectl logs -f $(kubectl get pod -l app=test-pod -o template --template "{{(index .items 0).metadata.name}}")
[2018-08-19T08:37:01.080] [INFO] app - Server running on port 3030
[2018-08-19T08:43:26.595] [DEBUG] app - request path: /
[2018-08-19T09:03:32.730] [ERROR] app - Error: error!!
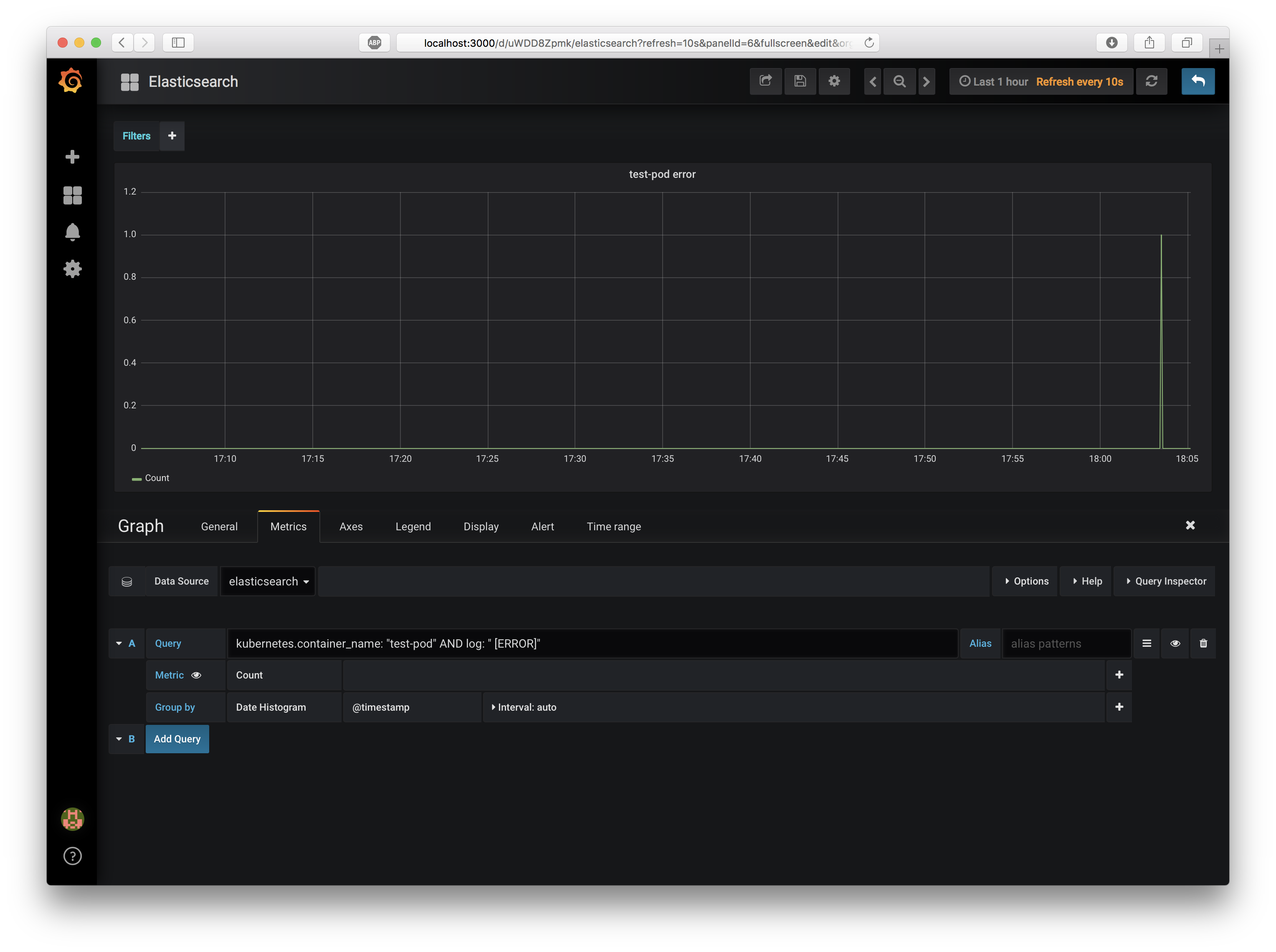
見事、PodのログをElasticsearchが収集し、Grafanaでフィルターして可視化することができましたね!
test-podの[ERROR]を検知したらSlackへ通知するAlertを追加
ではこのパネルへ、Alertルールを追加しましょう。Alert Tabの "Create Alert" ボタンを押し、Alertを一つ追加して以下の情報を入力してください。
- Alert Config
- Name:
test-pod error alert - Evaluate Every:
10s - Conditions
- WHEN:
sum() - OF:
query(A, 1m, now) - IS ABOVE:
0
- WHEN:
- Name:
- Notifications
- send to:
slack - Message:
test-pod raise a ERROR. Please check this pod!
- send to:
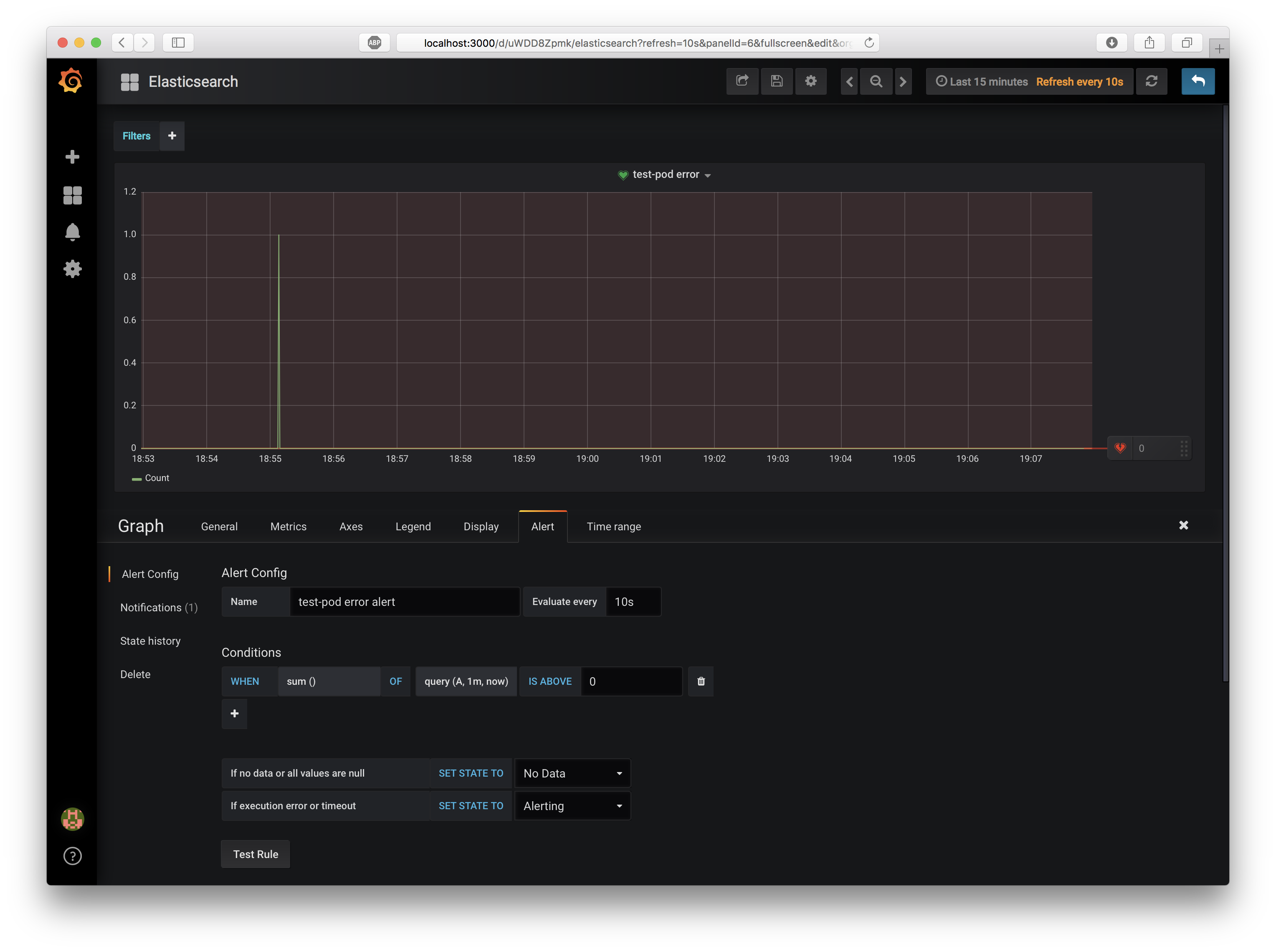
直近1分間で、エラー検知の合計が0より大きい(つまり1回でもエラー検知された)ならば、slackへ通知します。
では、実際にエラーを発生させてみましょう。先程と同様、curlで http://localhost:3030/error/ をGETしてエラーを発生させてください。
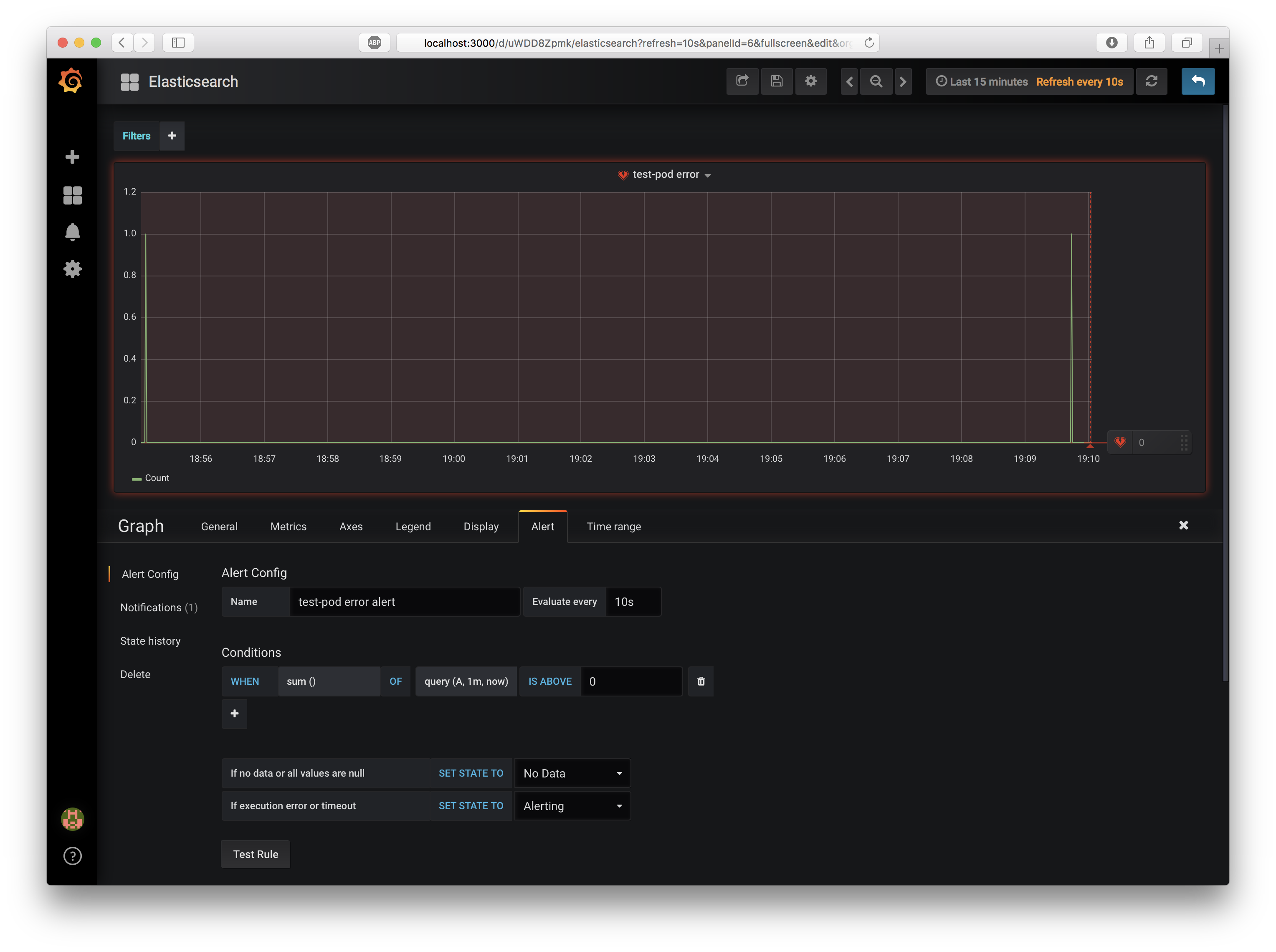
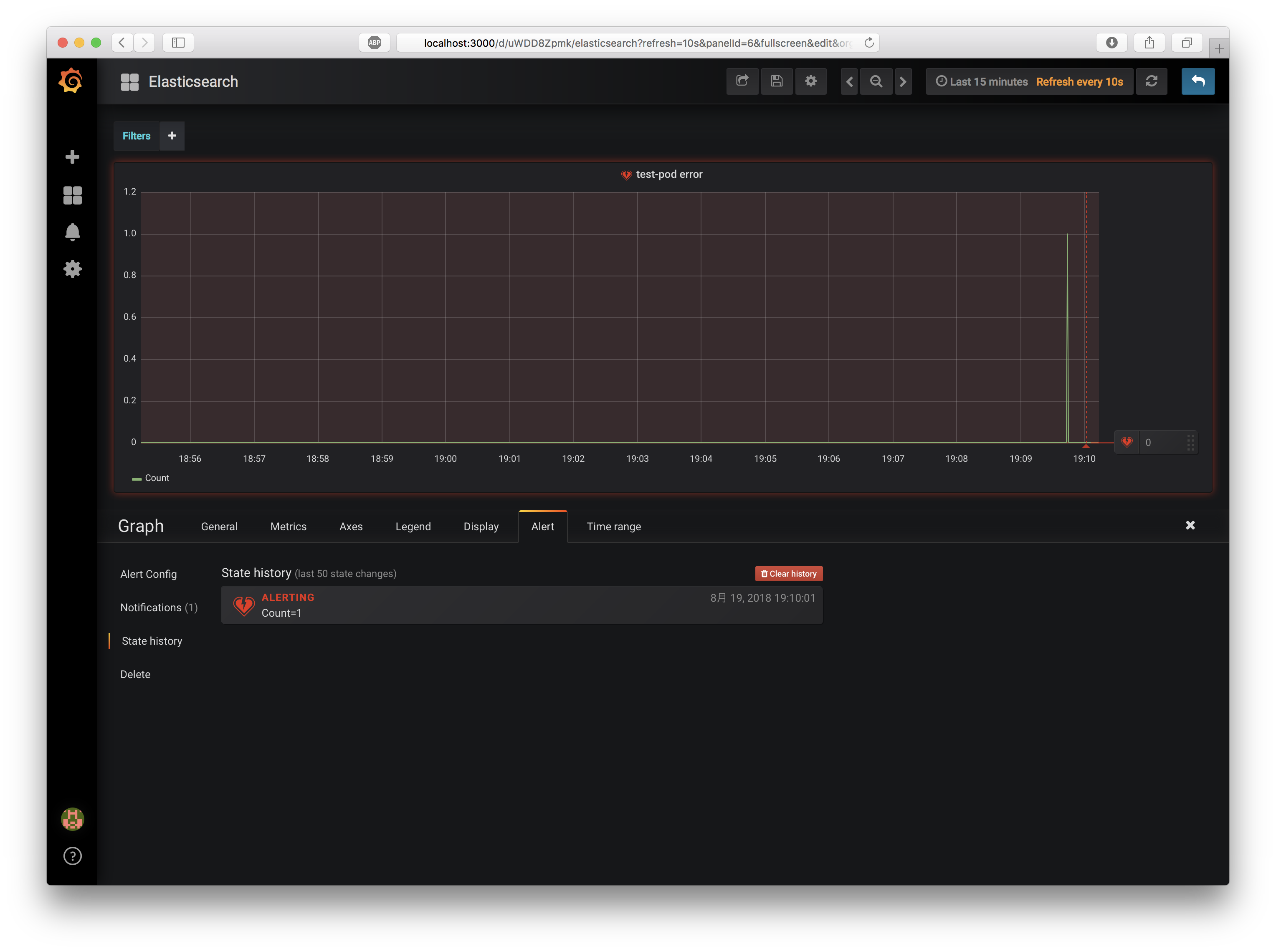
エラーを検知したPanelが、Alertを送信したことがわかります。また1分弱経過すると、エラー状態が正常状態に自動的に復帰します。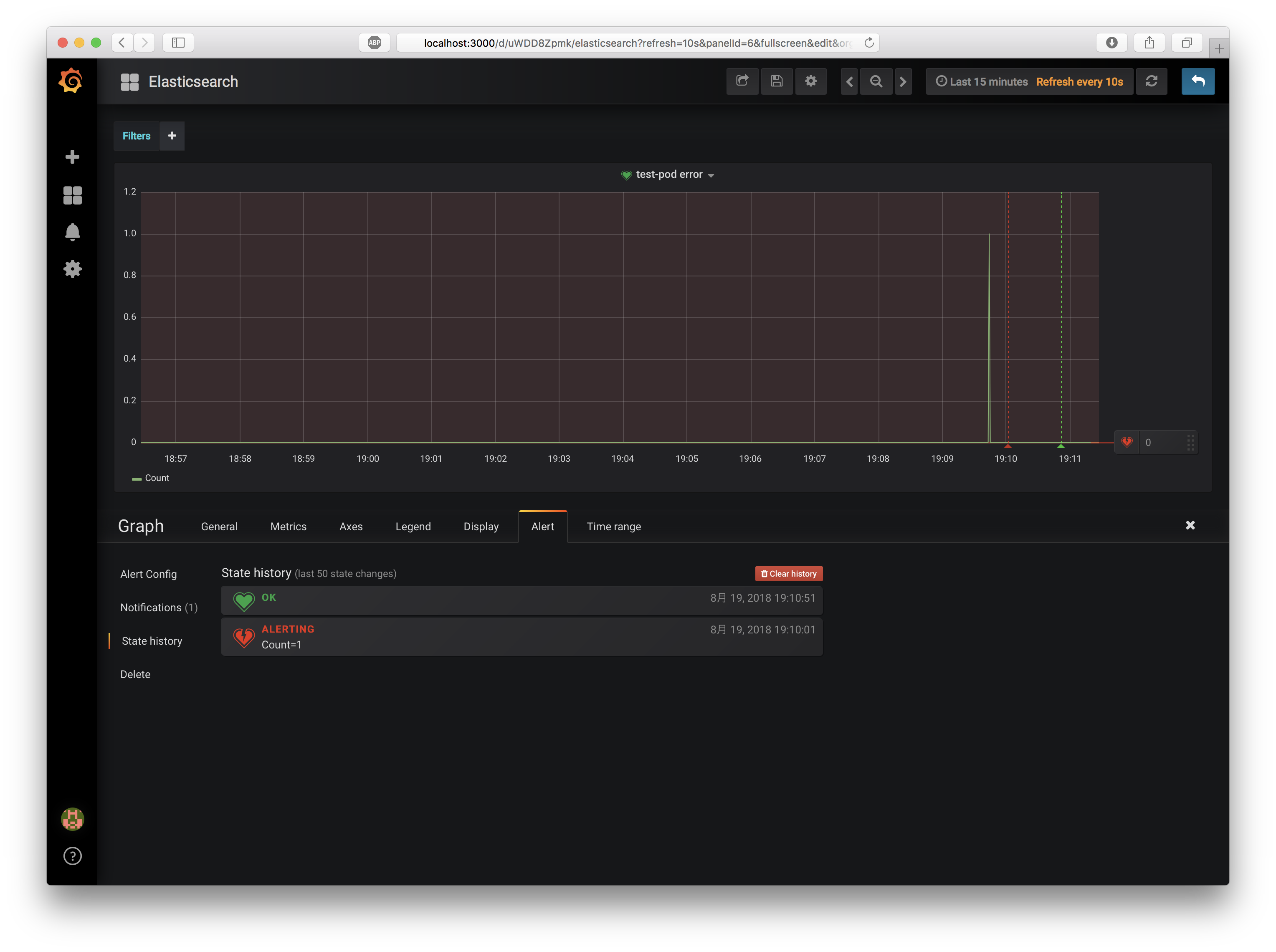
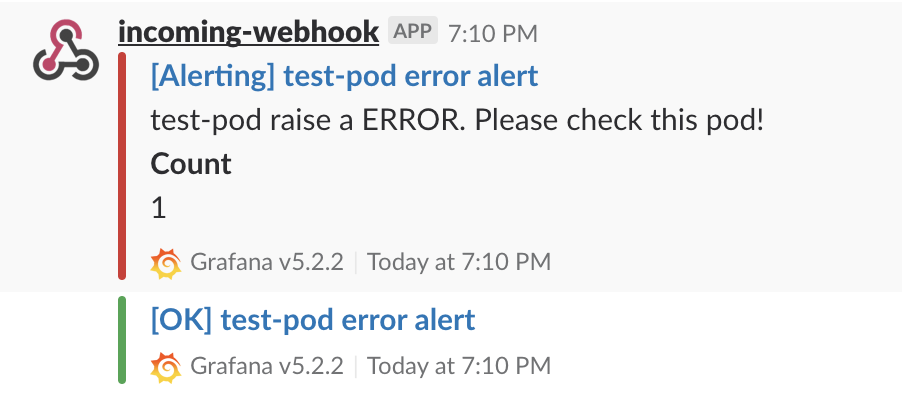
Slackを確認すると、確かにエラーメッセージが通知されていることがわかります。
最後に
ということで、Azure AKS上にElasticsearch + Fluentd + Kibana + Curaotrの環境を構築してログ集約を行い、加えてGrafanaとも連携させることで、指定したPodで特定の文字列がログ出力された場合にSlackへ通知させることができました。
単なる文字列チェック以上の複雑な条件でアラートを上げたい場合はElastAlertを導入したほうが良いかもしれませんが、シンプルなアラート条件であればGrafanaで十分だと思います。
それでは皆様、良いKubernetesライフを!