AWS Kinesis、Apache Kafka、Apache Stormを連携させるサンプルプログラム
以下のようなサンプルプログラムを作りました。
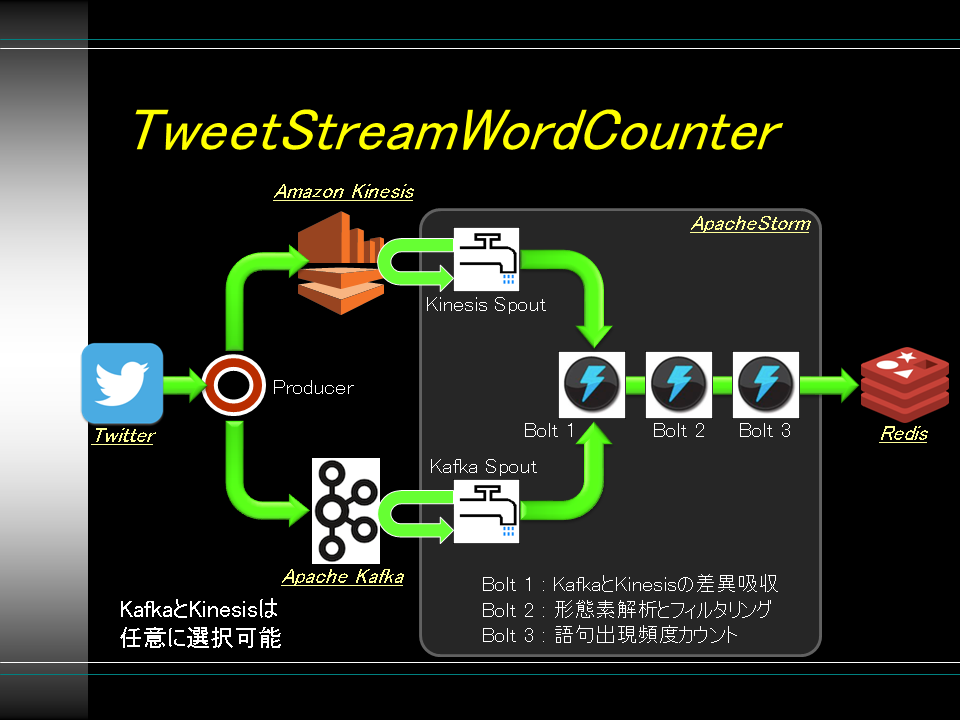
Twitter Streaming API
-> Producer -> (AWS Kinesis | Apache Kafka) -> Apache Storm[WordCounter]
-> Redis
Vagrant
環境構築用のVagrantfile、Berksfile、各種Cookbook
検証した環境
- HostOS
- MacOS X(10.7)
- Oracle VM VirtualBox(4.3.14)
- Berkshelf(3.1.3)
- Vagrant(1.6.3)
- vagrant-omnibus(1.4.1)
- vagrant-vbguest(0.10.0)
インストール
- VirtualBox、Vagrant、Berkshelfをインストール
git clone https://github.com/nmatsui/twitter-kinesis-kafka-storm_vagrant.gitberks vendor cookbooksvagrant up --provision
これにより、下記2つのVMが立ち上がり、/etc/hostsが設定されます。
- VM 1: Apache Zookeeper & Apache Kafka用
- Ubuntu Server(14.04.1 LTS)
- Oracle JDK(1.8.0_20)
- Apache Zookeeper(3.3.3) [Apache Kafka install packageに内包されたバージョン]
- Apache Kafka(0.8.1.1)
- VM 2: Apache Storm & Redis用
- Ubuntu Server(14.04.1 LTS)
- Oracle JDK(1.8.0_20)
- SBT(0.13.5)
- Apache Storm(0.9.2-incubating)
WordCounter
Apache Storm用の単語出現頻度をカウントするプログラム
- AWS Kinesis用のSpout or Apache Kafka用のSpoutを用いてTweetを取得
- 下記3つのBoltを用いて単語の出現頻度をカウント
- KinesisとKafkaのデータ構造差異を吸収
- kuromojiを用いて形態素解析
- 単語数のカウント
- 出現数をスコアとして単語をRedisのソート済みセット型に登録
インストール
- VM 2上で
git clone https://github.com/nmatsui/twitter-kinesis-kafka-storm_wordcounter.git -
src/main/resources/*.properties.templateをsrc/main/resources/*.propertiesにリネーム -
AwsCredentials.propertiesにAWSのAPI情報をセット
- もしプロキシ配下で動作させる場合、
kinesis.propertiesにプロキシ情報をセット
sbt compile
- Scala本体や各種依存ライブラリを取得するため、初回はかなり時間がかかる
sbt assembly
依存ライブラリ
- Java
- Oracle JDK(1.8.0_20)
- Scala(2.10.4)
- SBT(0.13.5)
- Library
- Apache Storm(0.9.2-incubating)
- KafkaSpout(0.9.2-incubating)
- KinesisSpout
- Kuromoji(0.7.7)
- Redis Client(2.12)
KinesisSpoutは、awslabsのkinesis-storm-spoutにbuild.sbtを追加し、バグフィックスしたもの( https://github.com/nmatsui/kinesis-storm-spout )を利用
Producer
Twitter Streaming APIから取得したTweetをAWS KinesisもしくはApache Kafkaへ連続的に投入するプログラム
- Twitter Streaming APIから指定したFilterQueryを用いてTweetを連続的に取得
- AWS KinesisもしくはApache Kafkaへ投入
インストール
- VM 2上で
git clone https://github.com/nmatsui/twitter-kinesis-kafka-storm_producer.git -
src/main/resources/*.properties.templateをsrc/main/resources/*.propertiesにリネーム -
AwsCredentials.propertiesにAWSのAPI情報をセット
- もしプロキシ配下で動作させる場合、
kinesis.propertiesとtwitter.propertiesにプロキシ情報をセット
sbt compile
- Scala本体や各種依存ライブラリを取得するため、初回はかなり時間がかかる
sbt assembly
依存ライブラリ
- Java
- Oracle JDK(1.8.0_20)
- Scala(2.10.4)
- SBT(0.13.5)
- Library
- Twitter4J(4.0.2)
- Apache Kafka Library(0.8.1.1)
- Amazon Kinesis Client Library(1.1.0)
利用方法
AWS Kinesis準備
- AWS Kinesisに"tweets"という名前のStreamを作成
- 現在のバージョンではUS EAST(N.Virginia)のKinesisにのみ対応
Apache Kafka準備
- VM 1にログイン
- Apache Zookeeper起動
- Apache Kafka起動
- Apache Kafkaへ"tweets"という名前のtopicを作成
ZookeeperやKafkaの起動手順等は、公式サイトのQuickStartを参照
Redis起動確認
-
redis-cli -h redis --rawでRedisに接続できることを確認
Apache StromのTopology起動
java -jar target/scala-2.10/wordcounter.jar (TEST|KAFKA|KINESIS)
- TEST: AWS KinesisやApache Kafkaに接続せず、ランダムな文章をBoltに流すSpoutに接続
- KAFKA: KafkaSpoutに接続
- KINESIS: KinesisSpoutに接続
Producer起動
java -jar target/scala-2.10/tweetstreamer.jar (TEST|KAFKA|KINESIS) query_words...
- TEST: AWS KinesisやApache Kafkaに接続せずTwitter Streaming APIから取得したTweetをログ出力するのみ
- KAFKA: Apache KafkaにTweetをputする
- KINESIS: AWS KinesisにTweetをputする
-
query_wordsは、Twitter Streaming APIの"statuses/filter"エンドポイントに渡されるフィルタワード
- 空白区切りで複数の単語を指定可能
- 指定した単語のいづれかが含まれるTweetが抽出される
正しく環境構築できていれば、取得したTweetがログ出力され、Redisに登録される
Redis確認
-
redis-cli -h redis --rawでRedisに接続 - Redis-CLI上で
zrange words 0 -1 withscoresを実行すると、出現頻度の昇順で単語が表示される
Redisの結果をクリアする場合、Redis-CLI上でdel wordsを実行