今回は、VyOSにアクセスしてくる端末(IPアドレス)が正規なものか判定するために、NetFlow監視の環境構築していきます。NetFlowのコレクターとなるサーバは、Fluent,Elasticsearch,Kibanaの構成でUbuntu16.04に実装していきます。
用語解説
今回使うパッケージについて私自身も利用は初めてだってので、簡単な解説を書いておきます。
Fluentd
Fluentd(フルエントディー)は、ログ収集管理ツールです。OSSで提供されていて、Linuxや各種Unixで動作します。ログと言っても種類は多数あり、syslog,access-log,Flow情報など多数ありますが、fluentdではイベントの受け取り(input)およびストレージへの格納(output)がすべてプラグインとして実装されています。今回であれば、fluent-plugin-netflowでNetFlow情報を受け取り(input)、fluent-plugin-elasticsearchで解析を行うElasticsearchに格納(output)していきます。
また、Fluentdではログの種類はタグで管理され、ログの内容はJSON形式です。この点を覚えておくと後の設定内容がわかりやすいです。
Fluentdは柔軟性に利点があるので、今回の環境だけでなく、様々なプログラミング言語やサービスと連携させると良いと思います。
Elasticsearch
Elasticsearch(エラスティックサーチ)は、全文検索エンジンです。全文検索エンジンとは、大量にあるデータを分析して検索したり、特定のデータを抽出したりする仕組みです。OSSで提供されていて、Linuxや各種Unixで動作します。
様々な特徴がありますが、優れているポイントは分析の柔軟性と速度です。簡単に強力な検索機能を利用することが可能であり、RESTインターフェースで入出力が行われることから、JSONライブラリを利用できれば、開発言語に関わらずデータの入出力が可能です。
また、他のソフトウェアとも連携が可能であり、Kibanaと連携すれば検索結果をWebフロント上に簡単に可視化できます。ビッグデータ処理基盤のHadoopと連携させれば、テキストデータのエンリッチメント/データ整形処理などが容易に行えます。
Elasticsearchの構造は、indexと呼ばれるDB的な領域の中に、type(テーブル),document(レコード),field(カラム),text(データ自体)が存在することで成り立っていることを覚えておくと、後の作業がわかりやすいです。
Kibana
Kibana(キバナ)は、Elasticsearchの検索結果をグラフ表示するツールです。以下のような、かっこいい監視画面(Webから参照)はKibanaによって作成されたものです。
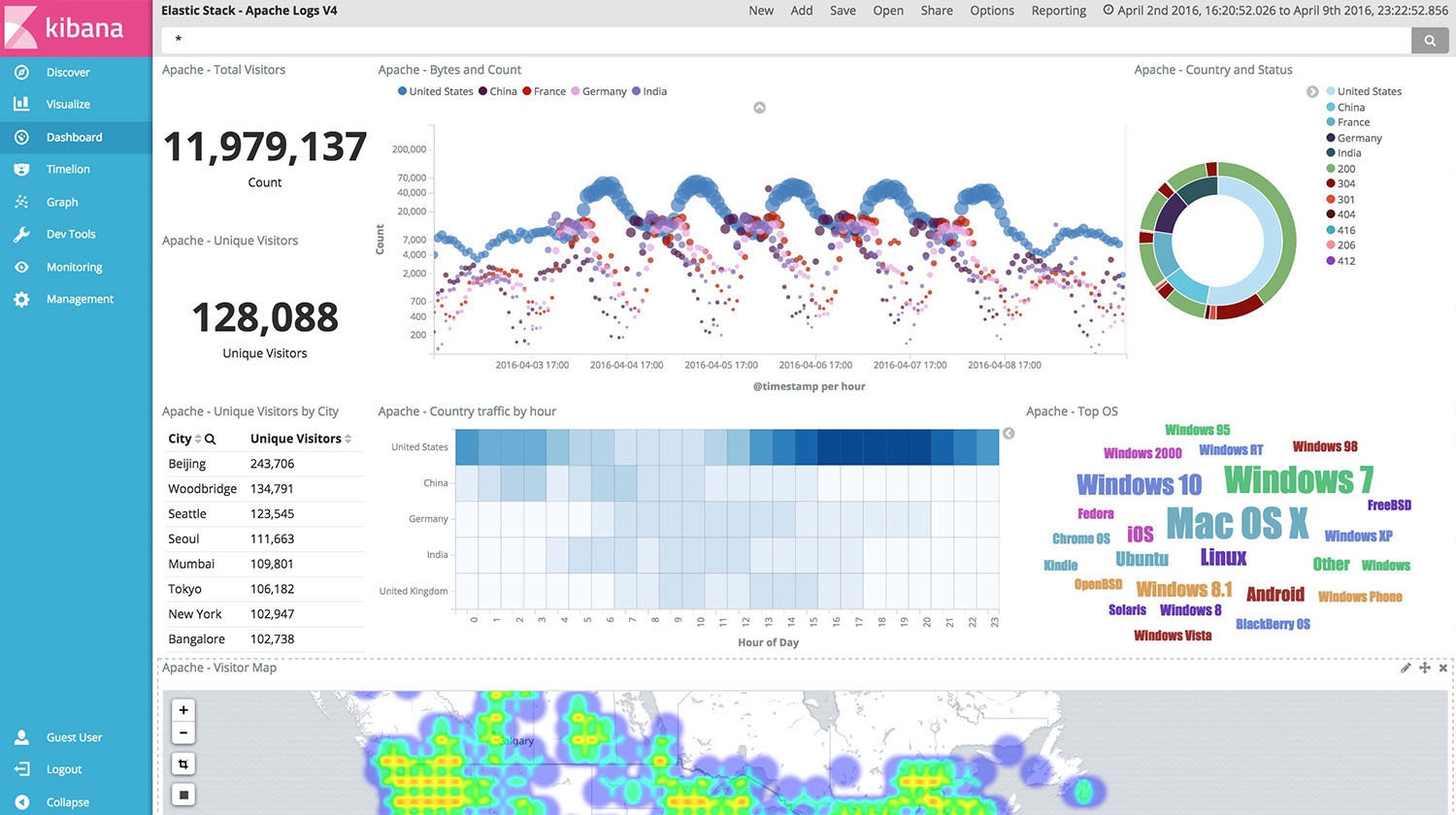
ダッシュボードの作成、グラフの作成、クエリ・フィルタの作成が自由にでき、使いこなすことができると監視がスマートにできます。私もこの点については、現在も勉強中です。
以下のサイトは私も大変参考にしているサイトです。
処理の流れ
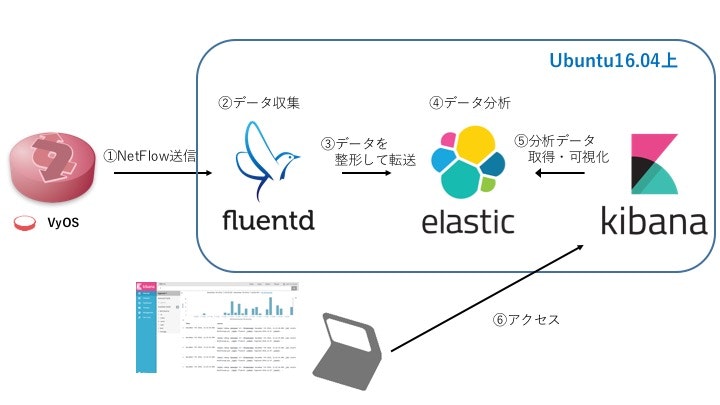
構築環境
- ubuntu 16.04
- Fluentd(td-agent) 0.14.16
- Elasticsearch 5.5.2
- Kibana 5.5.2
- VyOS 1.1.7
- NetFlow version 5
NetFlowコレクターの構築
Fluentd
公式サイトのInstalling Fluentd Using rpm Packageを参考にインストールしていきます。ステータスとバージョンが正常に確認できればOK
$ curl -L https://toolbelt.treasuredata.com/sh/install-ubuntu-xenial-td-agent3.sh | sh
$ /etc/init.d/td-agent restart
$ /etc/init.d/td-agent status
$ td-agent --version
FluentdでNetFlowを収集して、転送するためのプラグイン(fluent-plugin-elasticsearch,fluent-plugin-netflow)と関連パッケージをインストール
$ sudo apt-get install libcurl4-openssl-dev -y
$ sudo apt-get install gcc -y
$ sudo /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-elasticsearch
$ sudo /opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-netflow
/etc/td-agent/td-agent.confにNetFlow収集のための設定をする
以下では、NetFlow version5,9をポート番号5141で待ち受ける。また、NetFlowのデータはlocalhostのポート番号9200で動く、Elastisearchにファイルフォーマットを指定して転送することを記述している。
$ sudo vim /etc/td-agent/td-agent.conf
--省略--
<match netflow.**>
type elasticsearch
host localhost
port 9200
type_name netflow
logstash_format true
logstash_prefix flow
logstash_dateformat %Y%m%d
</match>
<source>
type netflow
tag netflow.event
port 5141
versions [5, 9]
</source>
Fluentd(td-agent)の再起動
$ /etc/init.d/td-agent restart
Elasticsearch
Elasticsearch を動かすには、少なくともJava 7のバージョンが必要であるため、推奨されているOracle JDK version 1.8.0_xxをインストールしていきます。
$ sudo apt-get install openjdk-8-jdk
$ java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-8u131-b11-2ubuntu1.16.04.3-b11)
OpenJDK 64-Bit Server VM (build 25.131-b11, mixed mode)
以降は公式サイトのInstall Elasticsearch with Debian Packageに沿ってElasticsearchの構築をしていきます。
Elasticsearchリポジトリの登録
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
パッケージのダウンロード元の定義を/etc/apt/sources.listに追記する
echo "deb http://packages.elastic.co/elasticsearch/5.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-5.x.list
apt-getを更新した上で、Elasticsearchをインストールする
sudo apt-get update
sudo apt-get install elasticsearch
Elasticsearchのバージョンを5.5.2にアップデートする(後にインストールするKibanaとバージョンを合わせる)
$ curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.2.deb
$ sudo dpkg -i elasticsearch-5.5.2.deb
リモートアクセスを許可するために/etc/elasticsearch/elasticsearch.ymlを編集する
$ sudo vim /etc/elasticsearch/elasticsearch.yml
--省略--
変更前
# network.host: "localhost"
変更後
network.host: "0.0.0.0"
設定を反映させて、Elasticsearchを起動する
$ sudo systemctl daemon-reload
$ sudo systemctl enable elasticsearch
$ sudo systemctl start elasticsearch
動作確認
$ curl http://localhost:9200
"name" ,"cluster_name" ,"cluster_uuid" ,"version"などが表示されればOK
Kibana
Kibanaリポジトリの登録
$ sudo wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
httpsに対応したapt methodをインストール
$ sudo apt-get install apt-transport-https
パッケージのダウンロード元の定義を/etc/apt/sources.listに追記する
$ echo "deb https://artifacts.elastic.co/packages/5.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-5.x.list
apt-getを更新した上で、Kibanaをインストールする
$ sudo apt-get update
$ sudo apt-get install kibana
リモートアクセスを許可するために/etc/kibana/kibana.ymlを編集する
$ sudo vim /etc/kibana/kibana.yml
--省略--
変更前
# server.host: "localhost"
変更後
server.host: "0.0.0.0"
設定を反映させて、Kibanaを起動する
$ sudo systemctl daemon-reload
$ sudo systemctl enable kibana
$ sudo systemctl start kibana
Kibanaはデフォルトでポート番号5601で動作するため、
動作確認としてWebブラウザを立ち上げhttp://<ipアドレス|FQDN>:5601にアクセスする。
Kibanaがエラーなく起動できればインストール完了
VyOSにNetFlow設定
VyOSにはNetFlowを流す設定とサーバの指定、その他オプションを設定する。
# 設定モードに入る
configure
# Flow監視するインターフェースの指定
set system flow-accounting interface eth0
# NetFlow version 5で動作させることを設定
set system flow-accounting netflow version 5
# サンプリングレートの指定(300個ごとに1個のパケット)
set system flow-accounting netflow sampling-rate 300
# Flowを集めるサーバの指定
set system flow-accounting netflow server 192.168.1.100 port 5141
# 60秒で動作しなければタイムアウトとみなす
set system flow-accounting timeout expiry-interval 60
# 変更のコミットおよび設定保存
commit
save
flow-accountingが正常に動作しているか確認
$ show flow-accounting
Kibana(Webフロント)の設定
フロントエンドの動作確認前に、CLIでサーバ側にNetFlow情報が来ているか確認する
まずIndexの確認を行う
$ curl -XGET 'localhost:9200/_cat/indices?v&pretty'
yellow open .kibana GI9kYoEQQyevSkezhedEUw 1 1 3 1 17.1kb 17.1kb
yellow open flow-YYYYMMDD AeGvmzhgSbeq0C_wtbnjlw 5 1 261 0 428.7kb 428.7kb
NetFlowが受信できていれば、flow-YYYYMMDDというindexが確認できるので、ここからその詳細を確認する。
$ curl -XGET 'localhost:9200/flow-YYYYMMDD/_search?pretty'
これでFlow情報が確認できればOK
Webフロントでは、はじめに初期設定が必要である。
http://<ipアドレス|FQDN>:5601で表示された画面において、デフォルトindexの登録をはじめに行う。以下の通りに設定。
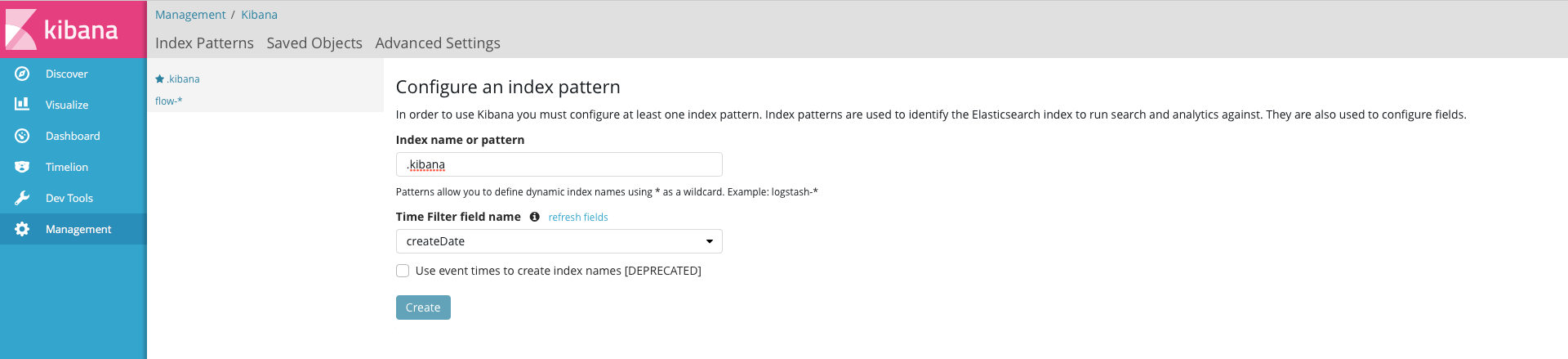
次に、[Management]-[+Creat Index Pattern]からNetFlowのindexを登録する。
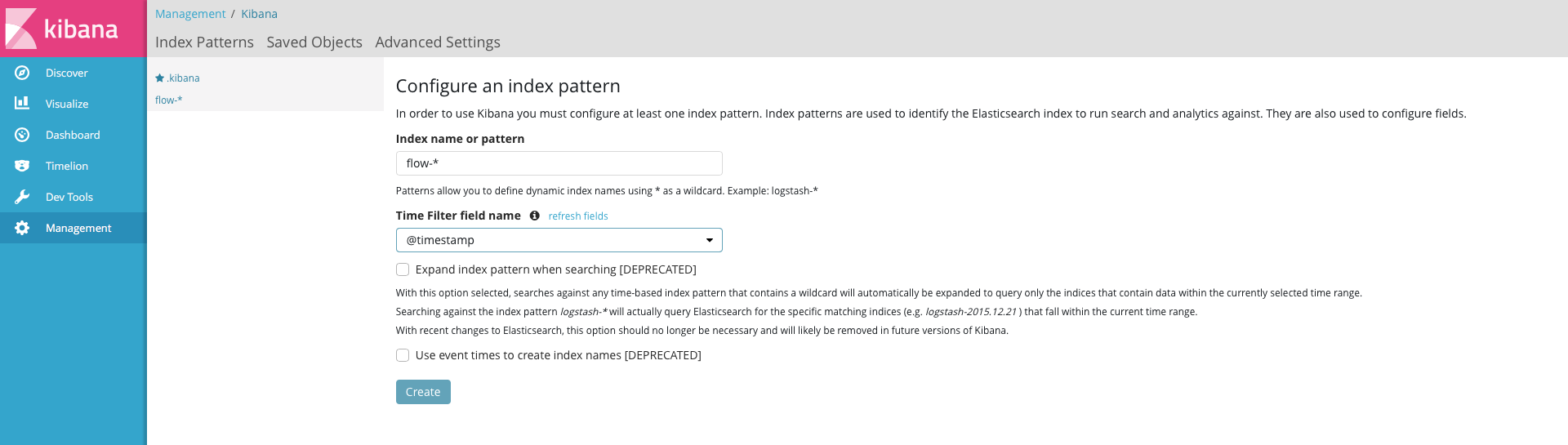
[Discover]で.kibanaタブの▼を押してflow-*を選択する。これで、以下の例のようにNetFlow情報が可視化される。

初期では、VyOSのFlow情報がLast 15 minuteで表示される。表示時間区間を変えたければ、右上から変更する。
以上までがNetFlow監視環境の基本的な構築です。
(おまけ1)Indexの自動削除
Indexファイルは今回の例のように日付毎に溜まっていくので、これが増加していくと
Elastisearch,KibanaがメモリやCPU面において重たくなったり、サーバ自体のディスク容量が少なってくる問題がある。
そのため、定期的にインデックスファイルを削除する必要がでてくる。
コマンドからindexを削除する方法は以下である。
$ curl -XDELETE 'http://localhost:9200/[index名]?pretty'
しかし、できれば自動でこれらを行いたいものである。
それを行うための便利なツールとして、curatorがある。
curatorはpythonで動作するツールなので、事前準備としてPythonとpipをインストールする。
$ sudo apt-get install python
$ cd /tmp
$ wget https://raw.github.com/pypa/pip/master/contrib/get-pip.py
$ sudo python get-pip.py
pipでcuratorをインストールする。
$ sudo pip install elasticsearch-curator
$ curator --version
curator, version 5.1.2
curatorはconfig.ymlとaction_file.ymlで動作します。
それらのファイルを格納するディレクトリを作成します。
$ mkdir ~/.curator/
config.ymlを作成します。これは、デフォルトのままで大丈夫そうなので、公式サンプルを持ってきてコメントアウトしておきます。
$ vim ~/.curator/curator.yml
---
# Remember, leave a key empty if there is no value. None will be a string,
# not a Python "NoneType"
# client:
# hosts:
# - 127.0.0.1
# port: 9200
# url_prefix:
# use_ssl: False
# certificate:
# client_cert:
# client_key:
# ssl_no_validate: False
# http_auth:
# timeout: 30
# master_only: False
#
# logging:
# loglevel: INFO
# logfile:
# logformat: default
# blacklist: ['elasticsearch', 'urllib3']
action_file.ymlを作成します。ここでは、10日以上前のindexをclose(Elasticsearchからindexの参照を外す)して、20日以上前のindexをdelete(indexの削除)してます。
以下の公式ドキュメントのExample参考に作成しています。
$ vim ~/.curator/close_delete_indices.yml
---
# Remember, leave a key empty if there is no value. None will be a string,
# not a Python "NoneType"
#
# Also remember that all examples have 'disable_action' set to True. If you
# want to use this action as a template, be sure to set this to False after
# copying it.
actions:
1:
action: delete_indices
description: >-
Delete indices older than 20 days (based on index name), for flow-
prefixed indices. Ignore the error if the filter does not result in an
actionable list of indices (ignore_empty_list) and exit cleanly.
options:
ignore_empty_list: True
disable_action: False
filters:
- filtertype: pattern
kind: prefix
value: flow-
- filtertype: age
source: name
direction: older
timestring: '%Y%m%d'
unit: days
unit_count: 20
2:
action: close
description: >-
Close indices older than 10 days (based on index name), for flow-
prefixed indices.
options:
ignore_empty_list: True
delete_aliases: False
disable_action: False
filters:
- filtertype: pattern
kind: prefix
value: flow-
- filtertype: age
source: name
direction: older
timestring: '%Y%m%d'
unit: days
unit_count: 10
実行は以下のコマンドです。
$ curator ~/.curator/close_delete_indices.yml
cronを利用してこれらを定期実行できるようにしておくと、定期的にインデックスファイルを削除することになります。
cronが動作していることを確認する。
$ systemctl status cron.service
● cron.service - Regular background program processing daemon
Loaded: loaded (/lib/systemd/system/cron.service; enabled; vendor preset: enabled)
Active: active (running) since 木 2017-08-17 15:07:19 JST; 6 days ago
cronにcuratorの定期実行を記述していく
$ crontab -e
(適当なエディタを選択)
cronファイルの書き方は以下のフォーマットである。
分 時 日 月 曜日 コマンド
* * * * * command
| 対象 | 入力できる数値 |
|---|---|
| 分 | 0〜59 |
| 時 | 0〜23 |
| 日 | 1〜31 |
| 月 | 1〜12 または jan〜dec |
| 曜日 | 0〜7 または sun〜sat |
よって、作成したcuratorの動作を毎週月曜の12時に行うように書く。
0 12 * * 1 curator ~/.curator/close_delete_indices.yml
cronに正しく登録されているか確認する。
$ crontab -l
また、正常に動作しているかを確認するコマンドを以下である。
$ cat /var/log/cron
ちなみに今回のindexのclose,deleteに伴って、デバック用に以下のコマンドは覚えておくと便利です。
# indexのクローズ
curl -XPOST 'localhost:9200/[index名]/_close'
# indexのオープン
curl -XPOST 'localhost:9200/[index名]/_open'
おわりに
今回は環境構築はできたものの、インストールしたパッケージの恩恵を受けるばかりで分からないことだらけです。特に、Kibanaでvisualize(グラフ)やDashboardをおしゃれに作っていく方法が理解できてないので勉強していく必要があります。
いつか記事を書こうと思っているので、Kibanaの使い方はその時に解説できるようにします。