この記事はeeic Advent Calendar 2016の12日目分です. 記事の目的は,今年登場した(?)MySQL8.0を利用してMySQLの基本的な使い方を追うことです.
データベース使って何かしたいぞ!って人向けです.
MySQL
リレーショナルデータベースの管理システムのことです. リレーショナルモデルよく分からんって人は
- データを表形式で保存できる
ぐらいにざっくり捉えておけば問題ないと思います. リレーショナルモデルってのは表みたいに見出し(カラム名)と本体のペアでデータを扱うモデルのことです.
| id | account | password |
|---|---|---|
| 0001 | mazamachi | hogehoge |
| 0002 | dedede | fugafuga |
| 0003 | mazacchi | piyopiyo |
上の場合はid, account, passwordという見出しと,{0001, mazamachi, hogehoge}というデータが一緒になって意味をなしています.見出しだけ,本体だけではデータが何なのか分かりません. 見出しと本体の関連(リレーション)があって初めて意味を成すモデルです.
環境構築
文章だけで説明しても仕方ないので仮想環境でMySQL8.0を試せるような手順を載せておきます. Mac OS Xでしか試していません.ですが,dockerを入れられる環境なら大して変わらない気がします.
docker
コンテナ型の仮想環境を手軽に作れるアプリケーションです.
dockerのインストール
docker公式ページからdocker.dmgをダウンロードしてインストールします. 起動して右上にクジラのアイコンが出れば(Macは)OKです.
MySQL
MySQLの公式がdocker用のイメージを公開しています.ターミナルを開いて以下を打ち込みます.
% docker pull mysql/mysql-server:8.0
ちょっと時間がかかった気もしますが数分でダウンロードは終わります.
データを永続化させるための下準備
このままmysql-serverコンテナにデータベースを作ってもコンテナを削除すると消えてしまうので,データを永続化させるための下準備をします.
% docker run -d -v /var/lib/mysql --name {好きなデータ格納用のコンテナ名を打ってね!} busybox true
今回はmysql8_storageというコンテナ名を付けました.
MySQL8.0のコンテナの起動 ※1
% docker run -d --volumes-from mysql8_storage(上で付けた名前) -e MYSQL_ROOT_PASSWORD={MySQLにログインする用のパスワード} -p {空いてるポート番号}:3306 --name {好きなMySQL用のコンテナ名を打ってね!} mysql/mysql-server:8.0
今回はmysql8_serverというコンテナ名を付けました. これでMySQL8.0の入った仮想サーバが立ち上がりました.この後,
% docker stop mysql8_server
% docker rm mysql8_server
を行ったとしても,MySQLの中に作ったデータベースは消えず,再び※1のコマンドを打てば同じデータベースにログインできます.
MySQL8.0のコンテナへのログイン
% docker exec -it mysql8_server mysql -u root -p
パスワードを求められるので先程設定したパスワードを入力しましょう.
余談 : MySQLWorkbenchからログイン
MySQLが公式に配布しているMySQLクライアントアプリケーションであるMySQLWorkbenchからdockerで作ったMySQLサーバにアクセスすることも可能です. 新規コネクションを開いて,
- Connection Method : Standard
- Hostname : 127.0.0.1
- Port : {上で指定したポート番号}
- Username : root
- Password : {上で指定したパスワード}
- Default Schema : 既に何か作ってあるなら
で接続できます.
余談 : PhpStormからログイン
PHPを書いててPhpStormを使わない人はいないと言われるくらい優秀なIDE.もちろん接続できます. ViewからDatabaseパネルを開いたら,新規データベースでMySQLを選択し,
- Host : 127.0.0.1
- Port : {上で指定したポート番号}
- User : root
- Password : {上で指定したパスワード}
- Detabse : 既に何か作ってあるなら
これでIDEと連携できます.PyCharmとかでも同じなはず.
MySQLの基本的な使い方(初めての人向け)
上記のどれかの方法でMySQLにログインします. MySQLでは
-
データベース1
- テーブル1
- テーブル2
- テーブル3...
-
データベース2
- テーブル1
- テーブル2
- テーブル3...
のようにしてデータを格納しています.こんな感じ.
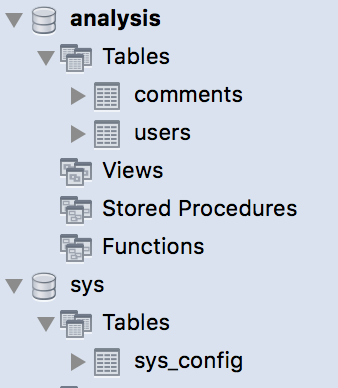
ここにはanalysisとsysという2つのデータベースが存在し,analysisにはusersとcommentsというテーブルが,sysにはsys_configというテーブルが入っています.
上の画像はMySQLWorkbenchで出してますがターミナルから見ることも出来ます.
SHOW databases;
SHOW TABLES FROM sys;
MySQLにデータを格納していく際は,
- データベースを作成.基本的に数は1つ
- テーブルを作成.基本的に数は複数
- テーブルにデータを格納
の流れになります.例えば,twitterのようなシステムを作る際には,
- twitterデータベースを作成
- twitterデータベースの中に必要なテーブルを作成
- テーブルにデータを格納
という感じです.1番大変なのが2のテーブルを作成です. テーブルの作成は大雑把に以下のような手順で行います.
- 格納したいデータを事前に決めておく
- データの意味,種類ごとに,作成するテーブルを決定
- 各テーブルの定義を作成
1.格納したいデータを決める
先程のtwitterのデータベースを考えましょう.まずデータベースを作ります.
CREATE SCHEMA twitter DEFAULT CHARACTER SET utf8; /*データベース作成*/
USE twitter; /*データベースの中に移動(コマンドで言うcdのようなもの)*/
最初から難しいことは考えたくないので,エセtwitterシステムは以下の機能だけを前提にします.
- ユーザが複数いて,ログインすることでtweetが出来るようになる.
- ユーザはtweetだけ行う(フォローとかLikeとかは考えない)
フォローもLikeもRTもないtwitter,激ヤバですが今回は仮定だから許して. さて,エセtwitterシステムが上のような機能を持つには,
- ユーザデータ
- tweetデータ
この2つのデータをきちんと保存しておく必要があります.
2. 作成するテーブルを決定
というわけで,上の2つのデータを保存しておくには
- ユーザテーブル
- tweetテーブル
の2つが必要になりそうな気がします. 最初はこのテーブル分けに苦労します.データをどうテーブルに分割して保持するか,正直に言うとある程度は慣れです. 複雑なデータをある程度シンプルになれまで小分けにしていく,というのが大きなイメージです. 「大雑把な話してんじゃねぇちゃんと説明しろ」って人はデータベース 正規化とかでググってください.たくさん出てきます.
3. 各テーブルの定義を作成
順番に見ていきましょう.
ユーザテーブル
ログインするために必要なもの...それは
- アカウント
- パスワード ですね.最低限必要なデータは実はこれだけです.というわけで作るぞ!!(※作らないでください)
CREATE TABLE `users` (
`account` VARCHAR(20) NULL,
`password` VARCHAR(20) NULL);
MySQLでの操作は全てSQLと呼ばれる宣言型言語を通して行います.たいていシンプルな英単語しか出てこないので,初見でもなんとなく意味はつかめます. 上のSQLは,usersという表(TABLE)を作成(CREATE)する命令です. 表にはaccountという見出しとpasswordという見出しが存在します.どちらも文字を20文字まで保存できます(VARCHAR(20)). NULLというのはピンと来づらいですが,これは「このカラムには値を格納しなくても良い」ということを意味します.
さて,上の定義文ですが間違ってはいませんが間違っています. 確かに,データを保存する上では上のSQLで問題ないのですが,データを正しく保存するには問題ありです.そして悲しいことに世の中には上のような`SQLで作られたデータベースが数多くあります.
では上の文の何が問題なのか,3つの観点から見ていきましょう.
1. 重複データの問題
上のSQLでは,同じアカウント名を保存することが可能です. 例えば,ある一人目のユーザAが[account:"mazamachi", passwoed:"hogehoge"]で登録したとします. そして次のユーザBが同じように[account:"mazamachi",password:"fugafuga"]で登録します. すると,このデータベースではAとBの2人を区別することが出来ません. データベースではこのようなエラーを防ぐため,重複データを保存しない機能を提供しています.
それがUNIQUE KEYの存在です.
UNIQUE KEYはカラムに対して,そのカラムに保存されるデータが常に一意であることを保証する機能です. つまり,accountというカラムに対してUNIQUE KEYを指定すると,accountの部分が同じ値のデータは保存できなくなります. 一度誰かがアカウント名をmazamachiにして登録すると,以降そのデータが削除されるまで,アカウント名をmazamachiにして登録することは出来なくなります(一意性の保証)
実はUNIQUE INDEXの更に上に,PRIMARY KEY があります.PRIMARY KEYとUNIQUE KEYは中身はほとんど同じです. 提供する機能も同じで,PRIMARY KEYを指定したカラムは重複が許されなくなります.
では何が違うのかというと,これが非常に大切なことなのですが,PRIMARY KEYは各テーブルにつき1つまでしか作成できない.ただし,必ず1つ作成しなければならない というものです. UNIQUE KEYは作成しなくても複数作成しても大丈夫です.
なぜ1つ作成しなければならないかというと,データベースはテーブルに保存されたデータをB+木によって管理するからです.B+木の分岐に利用するのがPRIMARY KEYであるため,必ず1つ必要になります.PRIMARY KEYで作成したB+木のリーフノードに実際のデータが一つずつ格納されます.
UNIQUE KEYも同じようにB+木を作成しますが,無駄を省くためにリーフノードには実データではなく,実データのPRIMARY KEYに指定されたカラムの値だけ保存します.その値を利用して,PRIMARY KEYから作られたB+木を辿り,実データまで行き着くことが出来るのです.
MySQLはもう一つ,検索効率を高めるためにただのINDEXというものが存在します.これも結局はB+木ですが,一意性は保証しません.あとで詳しく説明します.
まとめると
種類 | 構造 | 一意性 | 必須 | リーフノード
:---------: | :-------------: | :-: | :-: | :---------:
PRIMARY KEY | 指定カラムでソートされたB+木 | ○ | ○ | 実データ
UNIQUE KEY | 指定カラムでソートされたB+木 | ○ | ☓ | PRIMARY KEY
INDEX | 指定カラムでソートされたB+木 | ☓ | ☓ | PRIMARY KEY
さて,以上の話により,accountカラムにはPRIMARY KEYを指定しなければならないことが分かります. もう少し踏み込んだ話をすると,PRIMARY KEYに指定するカラムは出来るだけバイト数が少ない方が良い,という前提があります.多くのケースではこの前提を満たすために,敢えてaccountをPRIMARYに指定せず,UNIQUEの指定にとどめ,もう一つidというint型のカラムを付け足し,こちらをPRIMARYに指定することがほとんどです.
2. NULLの問題
MySQLは何も考えずにテーブルを作ると各カラムはNULL(値を代入しないこと)を許容します. しかし,NULLがあって良いことは一つもなく,後々NULLは厄介な障害となることがほとんどです. このカラムは必ずデータを入れる必要がある と言えるのなら絶対にNOT NULL制約を付けましょう.
例えば今回は,アカウントもパスワードもユーザ登録には必須です.なのでNULLを許容することは許されません. もし仮にユーザ登録時にユーザの善意で性別を入力してもらうなら,性別カラムはNULLを許容しても良いでしょう. ※そういうケースでもNULLを除外することは可能です.正規化でググってください.ただ,正規化はやりすぎてもアレなのでいい感じに諦めることも必要です.
3. セキュリティの問題
先程はaccountカラムに注目しました.今度はpasswordカラムを見てみましょう.passwordにはUNIQUEを指定する必要がありません.別にユーザAとユーザBがたまたま同じパスワードを設定したらと言って問題はありあせん. ただし,セキュリティを考える上でやってはいけないのはパスワードをそのまま保存することです. データは盗まれるかもしれません.もしパスワードが盗まれると,そのシステムへの不正ログインだけでなく,複数サイトで同じパスワードを設定しているユーザにとっては他のシステムの不正ログインをされる可能性が出てきてしまいます. なので必ずパスワードは暗号化して保存します.PHPでは安全な暗号化としてpassword_hash関数が用意されています. そしてPHPの公式ページでは将来の拡張性を考え,password_hashで暗号化したパスワードを保存する際はVARCHAR(255)のカラムを用意するよう勧めています.従いましょう.password_hashと対になるpassword_verifyはタイミング攻撃というセキュリティ攻撃にも頑健です.
以上を踏まえるとこんな感じのSQLが良いでしょう.
CREATE TABLE `users` (
`user_id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`account` varchar(20) NOT NULL,
`password` varchar(255) NOT NULL,
PRIMARY KEY (`user_id`),
UNIQUE KEY `account_UNIQUE` (`account`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
AUTO_INCREMENTは,データベースが自動で数字を連番で割り振ってくれることを意味します.こちらがidを生成しなくても,データベースが勝手にidを挿入してくれるので楽です.
tweetテーブル
先程の話を踏まえるとこんな感じ
CREATE TABLE `tweets` (
`tweet_id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL,
`body` varchar(140) NOT NULL,
PRIMARY KEY (`tweet_id`),
KEY `fk_tweets_users_idx` (`user_id`),
CONSTRAINT `fk_tweets_users` FOREIGN KEY (`user_id`) REFERENCES `users` (`user_id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
誰が(user_id)どんな(body)発言をしたのかを保存しています.idとしてtweet_idを作成しています. 見慣れないのはCONSTRAINT~~~ ON DELETE ~~ NO ACTIONの部分です. これは外部キー制約と呼ばれる機能です. 誰が,を保存するuser_idカラムは,既にusersに登録されているuser_id以外の値が入ってはいけません.誰かが発言している以上,それは既に登録されたユーザのtweetのはずです. それを保証するのが外部キーです.外部キーはあるテーブルAのカラムの値が,あるテーブルBのカラムの値に必ず含まれていることを保証します. 外部キーによって,別々の表同士結びつきが生まれ,データ表現が一気に豊かになります. 外部キーを貼るべき場所には必ず外部キーを貼る 習慣を付けましょう.確かに外部キーがなくてもデータは保存できますが,いつか整合性が崩れます.そして何より外部キーが貼られていると,後からそのデータベースを見た人がテーブル同士の関係を容易に理解できるようになります.
長くなりましたが,以上がMySQLの簡単な使い方です.ちなみにMySQLWorkbenchはこれをポチポチするだけで作成できます.
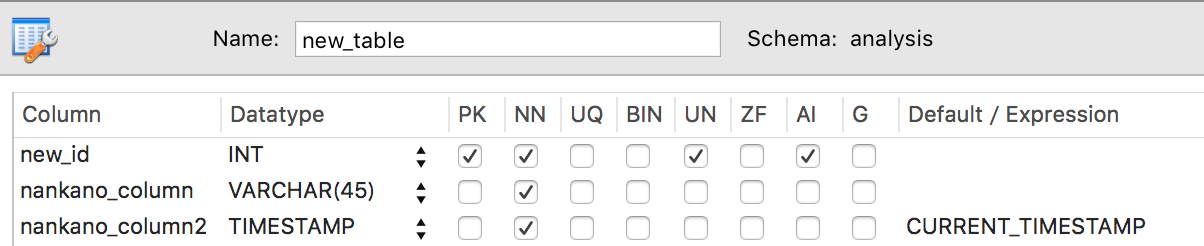
実はMySQLで大変なところの4割くらいがこのテーブル定義です. それでは実際にMySQLにデータを保存して,その機能を見ていきましょう.
MySQLの実践
データの用意
スキーマの作成
CREATE DATABASE `analysis` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `analysis`;
どんな名前でもいいですが取り敢えず今回はanalysisというデータベースを作成しました. 続いて,適当なダミーデータを放り込むためのテーブルを2つほど用意します. それぞれユーザを記録するuserテーブルと,ユーザのコメントを保存するcommentsテーブルを用意します. なんでさっきのtweetテーブルを利用しないのか,それは書いてる順番が逆で上の話は急遽付け加えたからです. 余計なことは考えたくないんで必要最小限のテーブル構成にします.
CREATE TABLE `users` (
`user_id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`created` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`user_id`),
UNIQUE KEY `name_UNIQUE` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `comments` (
`comment_id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(10) unsigned NOT NULL,
`body` varchar(140) NOT NULL,
`created` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`comment_id`),
KEY `fk_comments_users_idx` (`user_id`),
KEY `body_idx` (`body`),
CONSTRAINT `fk_comments_users` FOREIGN KEY (`user_id`) REFERENCES `users` (`user_id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
これでテーブルが2つ出来ました.
スキーマが完成したので,実データを放り込んでいきます. ユーザ数を1000人くらい,コメント数を100万件ぐらい用意しようと思います.
usersテーブル
まず最初に
INSERT INTO users(`name`)
SELECT SUBSTRING(MD5(RAND()), 1, 20);
を実行します.1個データが追加されました. 後は倍々方式でデータを増やします.
INSERT INTO users(`name`)
SELECT SUBSTRING(MD5(RAND()), 1, 20) FROM users;
を何度か実行すればデータ数が倍増していきます.好きなところで打ち切りましょう.今回はぴったり1000件になるよう,調整しました.
commentsテーブル
INSERT INTO comments (`user_id`, `body`)
SELECT `user_id`, substring(CONCAT(MD5(RAND(`user_id`)), MD5(RAND()), MD5(RAND()), MD5(RAND()),MD5(RAND())),1,140) FROM users;
上を一度実行した後は
INSERT INTO comments (`user_id`, `body`)
SELECT `user_id`, substring(CONCAT(MD5(RAND(`user_id`)), MD5(RAND()), MD5(RAND()), MD5(RAND()),MD5(RAND())),1,140) FROM comments;
を何度か実行してデータ数を増やせばいいと思います.後半は結構時間かかるんで100万件超えたら十分だと思います. 僕は間違えて200万件までやってしまいました.倍々なので正確には2048000件です.規模的には小〜中規模のデータベースに当たると思います.
さて,それでは早速MySQL8.0から追加されたinvidible indexを通してINDEXについて追っていきましょう.
INDEX
INDEXは上でも書きましたが,検索効率を高めるための索引です.例えば,「abcから始まるcommentを全部取得したい!」と思ったとしましょう. INDEXが存在しなければ,MySQLは全データのcommentカラムを1つ1つ見ていき,abcから始まるかどうかをチェックしていきます. 一方でcommentカラムにINDEXを貼っておくと,MySQLは実データとは別に,予めcommentカラムをソートして作成したB+木を保存します. ソートしてあるため,abcから始まるcommentについて,必要最小限のアクセスで取得できます.
ただし,あくまで指定したカラムの内容でソートしてあるため,「abcという文字列を含むデータ」や「末尾がabcであるデータ」という検索に対しては全く効力を発揮できません.(辞書の索引もそうですよね.「あ」から始まる単語を調べるのは高速で出来ますが,「あ」で終わる単語を調べるには索引を見てもあまり意味がありません)
Invisible Index
MySQLを使っていて無限に直面する問題は,「このカラムにINDEXを貼るべきか」や「このカラムのINDEXは残すべきか」 です.INDEXを適切に貼れば,検索効率や速度が飛躍的に上がるというメリットがあります.一方で,データの追加や更新には弊害となったり,B+木の保存領域が場合によっては大きくなるというデメリットがあります. INDEXを新しく検討するときは,使用されるクエリ群を調べてINDEXを貼るべき最適なカラムの組み合わせの候補を出して,そして最終的に実際にINDEXを貼ってみて速度を調べてみる,というのが最もよくある流れです.逆にINDEXを削除するときは,EXPLAINなどでINDEXの使用状況を調べ,疑似テーブルを作って削除した場合のパフォーマンスをチェックするといった感じでしょうか. いずれの場合においても,INDEXを貼ったり削除したりするのは中々コストの掛かるものです.
そこで登場したのがInvisible Indexです.Invisible IndexはINDEXを一時的に隠すことが出来ます.隠す,とは何からでしょうか.それはオプティマイザからです.オプティマイザはMySQLの頭脳で,SQLを分析して最適な実行計画を練る部分です.Invisibleに設定されたINDEXはオプティマイザから認識されなくなり,実行計画を作る際に利用されなくなります.つまり,一時的にINDEXを削除した時と同様の効果が得られます.
INDEXの効果
話が長くなりました.それでは早速試してみます.
先程usersテーブルとcommentsテーブルを作成しました.commentsテーブルのcommentカラムはvarchar(140)ですが,ここに敢えてINDEXを貼っています.まずはこの状態でクエリを発行してみましょう.クエリの実行結果と計算時間を取得します.この時きちんとクエリキャッシュをオフにしておきましょう.
SELECT `body` FROM comments WHERE body LIKE '12%';
このクエリの実行結果です.
time : 0.0019 [sec]
Fetchにかかった時間は更に少ないです. ここで,INDEXをINVISIBLEにしてみます.
ALTER TABLE comments ALTER INDEX body_index INVISIBLE
これでオプティマイザはINDEXを使わずに実行計画を立てます.実際に実行時間は
time : 0.015 [sec]
7~8倍くらい遅くなりますね.誤差はそこそこあるので真面目に計るときは何度か計った方がいいです. 実行計画を見てみます.
EXPLAIN SELECT `body` FROM comments WHERE body LIKE '12%';
INDEXあり実行計画
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | comments | NULL | range | body_index | body_index | 422 | NULL | 12476 | 100.00 | "Using where; Using index" |
INDEXなし実行計画
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | comments | NULL | ALL | NULL | NULL | NULL | NULL | 1833259 | 11.11 | "Using where" |
予想通りの実行計画が表示されます.実行計画の見方は漢のコンピュータ道が分かりやすいですが,先日情報を収集しようという素晴らしい記事を読んだので,MySQL公式のEXPLAIN句に関するdocumentを貼っておきます. ちなみに大正義MySQLWorkbenchは可視化してくれます.EXPLAINを付けなくてもExecution Planで見られます.
INDEXありではUsing indexとあるのでINDEXのみを使ってクエリを実行しているのがわかります. これはWHERE句でbodyのみが指定されていること,前方一致検索を行っていること,SELECTの対象がbodyであることが理由です. 例えば,似たようなクエリでも
SELECT created FROM comments WHERE body LIKE '12%'
ではUsing indexがUsing index condition(indexを使って絞り込んだ後実際にデータをフェッチする)に変わります.これはINDEXツリーだけを用いてクエリを解決できないことを意味します.
SELECT `body` FROM comments WHERE body LIKE '%12';
後方一致検索ではどうでしょうか.
time: 0.057 [sec]
時間かかってますね.INDEXを使用しない前方一致検索よりもはるかに時間かかっています. 実を言うとINDEXを使用しない後方一致検索よりも遅いです. おそらく,オプティマイザがSQLを見て「おっINDEXだけでいけるじゃん!」と思ってINDEXツリーを使用したのでしょう. しかし後方一致検索では文字列の先頭からソートしてあるB+木において全く意味をなさず結局ツリーをフルスキャンしています.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | comments | NULL | index | NULL | body_index | 422 | NULL | 1833259 | 11.11 | "Using where; Using index" |
やはりINDEXで解決しようとしています.ただし,前方一致検索と違いtypeがrangeではなくindexです.これはINDEXを使って範囲を絞り込んで検索を向上させている前方一致検索と違い,INDEXツリーを見るけれど結局絞り込みは行えず全てチェックしていることを意味します.
INDEXの強さと弱さが次第に見えてきましたね.INDEXはどのようにカラムが検索されるか十分に検討し,正しく設定することで場合によっては数百倍以上の検索効率を得られます. 一方で誤った設定をすると多くの面で負の影響を及ぼします.色々試して実行計画を見たり速度を計ってみたりしましょう.
MySQLのINDEXのガイドラインを貼っておきます
Invisible Index機能のおかげでこのようにINDEXのあり/なしの結果を手軽に得ることが出来るため,INDEX戦略を立てやすくなります. ただし,INSERTやUPDATEにかかる負荷はINDEXをINVISIBLEにしても消えません.
JOINの効果
INDEXに続いて今度はJOINを見ていきましょう.
スキーマ作成
JOINを行うためのデータベースを作成しましょう. 先程のテーブルはもういらないので削除しちゃいましょう. ちなみに削除系のSQLはいくつか抑えておくと良いです.
DROP - テーブルやスキーマをファイルレベルで削除します.高速.
DELETE - トランザクションを守ってデータを削除します
TRUNCATE - 一度テーブルをDROPして再びCREATEすることで高速にデータを削除します.
DROP TABLE comments;
DROP TABLE users;
順番に気をけてください.commentsにはusersを参照する外部キーがあるので,commentsテーブルより先にusersテーブルは削除できません.
スキーマとテーブルを作成するSQLが以下です.今回は履修登録システムyoutmateを作成します.
youtmateデータベースは,生徒と科目と履修情報を保存する必要があります.
生徒と科目は別のテーブルに保存しましょう.履修情報は生徒のidと科目のidをペアで保存しておけば大丈夫そうです.う〜ん,科目によっては先生が複数いるかもしれないというちょっと複雑な条件を考えてみます.科目とは別に先生テーブルを作成し,担当情報は科目idと先生idのペアを保存して持っておくことにしましょう.
1対多や多対1を保存するのは必ずテーブル分けを行なうべきです.RDB界隈も色々宗教が存在し対立を繰り返していますがこれは全宗教共通の考えです.最悪なのは1対多の関係を,カンマ区切りのデータを1つのカラムに保存して表現することです.アンチパターンとしてもよく知られています.今回の例で言うと,科目テーブルに担当教員カラムを持ち,そのカラムの中に先生idを必要な数だけカンマで区切って保存するというやり方です.そういうテーブルを見ると「あっ」ってなります.
CREATE DATABASE `youtmate` DEFAULT CHARACTER SET utf8;
USE `youtmate`;
CREATE TABLE `courses` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`place` varchar(10) NOT NULL,
PRIMARY KEY (`id`),
KEY `course_place_index` (`place`),
KEY `course_name_index` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `students` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`grade` tinyint(1) unsigned NOT NULL,
`class` tinyint(1) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `teachers` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` tinyint(2) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `course_charges` (
`course_id` int(10) unsigned NOT NULL,
`teacher_id` int(10) unsigned NOT NULL,
PRIMARY KEY (`course_id`),
KEY `fk_charge_teacher_idx` (`teacher_id`),
CONSTRAINT `fk_charge_course_idx` FOREIGN KEY (`course_id`) REFERENCES `courses` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `fk_charge_teacher_idx` FOREIGN KEY (`teacher_id`) REFERENCES `teachers` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `course_registrations` (
`student_id` int(10) unsigned NOT NULL,
`course_id` int(10) unsigned NOT NULL,
PRIMARY KEY (`student_id`,`course_id`),
KEY `fk_regist_course_idx` (`course_id`),
CONSTRAINT `fk_regist_course_idx` FOREIGN KEY (`course_id`) REFERENCES `courses` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `fk_regist_student_idx` FOREIGN KEY (`student_id`) REFERENCES `students` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
例によって例のごとくこれ以上難しいことは考えたくないんで教室変更〜だのSタームとAターム〜だのは切り捨てます.
続いて仮データを保存します.今回はデータ数は少なくて大丈夫です.
生徒1024件,授業128件,先生64件,履修登録131072件(1024×128)にしましょう.全生徒は全授業を履修することにします.eeic.
# 1回目
INSERT INTO students(`name`, grade, class)
SELECT SUBSTRING(MD5(RAND()), 1, 20), CEIL(RAND() * 4), CEIL(RAND() * 8);
# 2回目以降
INSERT INTO students(`name`, grade, class)
SELECT SUBSTRING(MD5(RAND()), 1, 20), CEIL(RAND() * 4), CEIL(RAND() * 8) FROM students;
# 1回目
INSERT INTO courses(`name`, place)
SELECT SUBSTRING(MD5(RAND()), 1, 20), SUBSTRING(MD5(RAND()), 1, 10);
# 2回目以降
INSERT INTO courses(`name`, place)
SELECT SUBSTRING(MD5(RAND()), 1, 20), SUBSTRING(MD5(RAND()), 1, 10) FROM courses;
# 1回目
INSERT INTO teachers(`name`, age)
SELECT SUBSTRING(MD5(RAND()), 1, 20), 20+CEIL(RAND() * 45);
# 2回目以降
INSERT INTO teachers(`name`, age)
SELECT SUBSTRING(MD5(RAND()), 1, 20), 20+CEIL(RAND() * 45) FROM teachers;
INSERT INTO course_charges(`course_id`, `teacher_id`)
SELECT id ,(SELECT id FROM teachers WHERE id <= 32 ORDER BY rand() LIMIT 1) AS teacher_id FROM courses;
INSERT INTO course_registrations (student_id, course_id)
SELECT students.id, courses.id FROM students, courses;
JOIN
JOINを実際に行なう前にJOINについて説明します.
JOINはデータベースを作る上で欠かせない動作です.外部キー制約を覚えているでしょうか.
あるテーブルAのカラムaが取りうる値を,別のテーブルBのカラムbに保存されている値だけに制限する,という制約です.
JOINはこの外部キー制約と同時に使われることが多い操作です.
例えば上のスキーマ作成で作成したデータベースではcourse_registrationsテーブルのstudent_idカラムには外部キー制約が貼られており,studentsテーブルのidに保存されている値しか登録できません.これにより,存在しない生徒の履修データがデータベースに保存されるのを防いでいます.
例えばある授業Aを履修している生徒の名簿リストを作りたい!と思ったとしましょう.
どのテーブルを見ればリストを作れるでしょうか.course_registrationsテーブルでしょうか.
しかし,course_registrationsテーブルだけ見ても,授業IDと生徒IDが並んでいるだけです.
どれが授業Aでどの生徒IDが誰なのかまるで分かりません.
確かに,まず1回目のクエリでcoursesテーブルからnameがAである授業のIDであるAIDを取得し,次に2回目のクエリでcourse_registrationsのcourse_idがAIDのものを取得し,最後に3回目のクエリでそこからstudent_idを利用してstudentsテーブルから生徒の名前を取得することはできます.
しかしこれはあまりにコストが大きい作業です.
そこで登場するのがJOINです.JOINは離れたテーブル同士をくっつけることができます.
例えばさっきのcourse_registrationsテーブルにcoursesテーブルとstudentsテーブルをくっつければ,欲しい情報は一度にとれます.
JOINはまずメインとなるテーブルを決めます.これは外部表と呼ばれます.
例えば今回は「course_registrationsにcoursesとstudentsをくっつける」という操作なので,course_registrationsが外部表です.
くっつける2つのテーブルは**内部表(駆動表)**と呼ばれます.
JOINを利用したSQLの前に,ちょっとした準備します.
UPDATE courses SET name='数学' WHERE id = 1;
UPDATE courses SET name='英語' WHERE id = 2;
UPDATE courses SET name='C言語' WHERE id = 3;
UPDATE courses SET name='OS' WHERE id = 4;
さすがに乱数の科目名は分かりづらいんでcoursesテーブルのidが1~4について分かりやすい名前に変えました.
さて,それではOSを履修している生徒一覧を取得しましょう.
SELECT
c.name AS course_name,
s.name AS student_name
FROM
course_registrations AS cr
INNER JOIN
students AS s ON cr.student_id = s.id
INNER JOIN
courses AS c ON cr.course_id = c.id
WHERE
c.name = 'OS'
このSQLを実行すると目的のリストが得られます.
つまり,JOINは
`外部表`
INNER JOIN
`内部表` ON `外部表`.`カラムA` = `内部表`.`カラムB`
のように書きます.途中に出てきたASは単に名前が長いから短い別名を割り振るだけの命令です.
ちょっと話を脱線させます.
INNER JOINという表現ですが,これは内部結合と呼ばれ,ON以下の等式が成立するカラムだけを取得することを意味します.
他にもOUTER JOINと書く外部結合があります.これは外部表のカラムは問答無用で全部取得し,ON以下の等式が成立するカラムには内部表のデータを連結させ(INNER JOINと同じ),等式が成立しないカラムにはNULLを連結させます.
例えば,教師全員がどの授業を担当しているか調べることを考えます.
SELECT
t.name AS teacher_name, cc.course_id AS course_id
FROM
teachers AS t
INNER JOIN
course_charges AS cc ON t.id = cc.teacher_id
SELECT
t.name AS teacher_name, cc.course_id AS course_id
FROM
teachers AS t
LEFT OUTER JOIN
course_charges AS cc ON t.id = cc.teacher_id
この両方のクエリは実は違う結果を返します.内部結合の方のクエリは「どの授業も担当していない教師」は結果に含まれません.
一方で外部結合の方は外部表に教師テーブルを指定した以上,全ての教師について結果を返します.しかし,どの授業も担当していない教師については,course_idが存在しないのでNULLが入って返ってきます.仮に全教師が何らかの授業を担当していれば,同じ結果が返ってきます.
内部結合と外部結合,最初はいまいちピンと来ないかもしれませんが,使い方を間違えると想定した結果と異なる結果を返すので気をつけましょう.
話をOSを履修している生徒一覧に戻します.実は,内部結合のJOINは,外部表と内部表を入れ替えても結果が同じという面があります.
試してみましょう.
SELECT
c.name AS course_name,
s.name AS student_name
FROM
students AS s
INNER JOIN
course_registrations AS cr ON cr.student_id = s.id
INNER JOIN
courses AS c ON cr.course_id = c.id
WHERE
c.name = 'OS'
SELECT
c.name AS course_name,
s.name AS student_name
FROM
courses AS c
INNER JOIN
course_registrations AS cr ON cr.course_id = c.id
INNER JOIN
students AS s ON cr.student_id = s.id
WHERE
c.name = 'OS'
順序に違いはあるかもしれませんが同じ結果になります.順序も揃えたい人は各SQLの末尾に
ORDER BY s.id ASC;
を付け加えれば順序が揃います.
JOINの実行計画
JOINで気をつけなければならないのはコストの大きさです.
JOINは実際のところforループのようなものです.
外部表の指定したカラムを1つ取り出し,内部表をforループで回して指定したカラムが同じになるものを取ってくる,と考えれば分かると思います.
つまり,内部表へのアクセスが頻発します.そのため,内部表の指定するカラムはPRIMARY KEYかUNIQUE KEYが貼ってあることが望ましく,無理ならINDEXが貼ってあることが期待されます.
先程のSQLを見てみましょう.
EXPLAIN
SELECT
c.name AS course_name, s.name AS student_name
FROM
course_registrations AS cr
INNER JOIN
students AS s ON cr.student_id = s.id
INNER JOIN
courses AS c ON cr.course_id = c.id
WHERE
c.name = 'OS'
ORDER BY s.id
実行計画
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | c | NULL | ref | "PRIMARY, course_name_index" | course_name_index | 62 | const | 1 | 100.00 | "Using index; Using temporary; Using filesort" |
| 1 | SIMPLE | cr | NULL | ref | "PRIMARY, fk_regist_course_idx" | fk_regist_course_idx | 4 | analysis.c.id | 1 | 100.00 | "Using index" |
| 1 | SIMPLE | s | NULL | eq_ref | PRIMARY, PRIMARY | 4 | analysis.cr.student_id | 1 | 100.00 | NULL |
s(students)テーブルへのアクセスはeq_ref,つまりPRIMARY KEYを通して行われています.cr(course_registrations)とc(courses)はPRIMARY KEYではなく,INDEXを通してアクセスされます.つまり,まずcoursesテーブルからINDEXを使用して授業名がOSのIDを取得します.
続いてcourse_registrationsのcourse_idに貼られたINDEXを通して,course_registrationsのPRIMARY KEYである(student_id, course_id)を取得します.最後に,取得したstudent_idを利用してstudentsテーブルから生徒の名前を取得します.
この順序で実行すると不要なデータに触れることがなく高速であるとオプティマイザが判断したのでしょう.
実際これが最も賢い方法だと思います.
実行計画は少しの差で大きく変動します.WHERE c.name = 'OS'を取り除いて実行計画を見てみましょう.
EXPLAIN
SELECT
c.name AS course_name, s.name AS student_name
FROM
course_registrations AS cr
INNER JOIN
students AS s ON cr.student_id = s.id
INNER JOIN
courses AS c ON cr.course_id = c.id
ORDER BY s.id
実行計画
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | s | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 1024 | 100.00 | NULL |
| 1 | SIMPLE | cr | NULL | ref | "PRIMARY, fk_regist_course_idx" | PRIMARY | 4 | analysis.s.id | 100 | 100.00 | "Using index" |
| 1 | SIMPLE | c | NULL | eq_ref | PRIMARY | PRIMARY | 4 | analysis.cr.course_id | 1 | 100.00 | NULL |
今度はまずstudentsテーブルからPRIMARY KEYを通してB+木をフルスキャンします.そうして生徒情報を全部取得した後,student_idを利用してPRIMARY KEYを通してcourse_registrationsから(student_id, course_id)を取得します.最後に取得したcourse_idからPRIMARY KEYを通して授業名を取得します.
JOINの入ったSQLで何か致命的に遅いな,と思ったら実行計画を見て,typeがconst,eq_ref, refになっているか,keyにPRIMARY KEYやINDEXが選択されているか,refでkeyと比較されているのは何かなどを見ていくと良いと思います.
遅いJOIN
先程の話の脱線で出てきた各教師たちの担当科目一覧を取得するSQLの実行計画を見てみましょう
EXPLAIN
SELECT
t.name AS teacher_name, cc.course_id AS course_id
FROM
teachers AS t
LEFT OUTER JOIN
course_charges AS cc ON t.id = cc.teacher_id
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| '1' | 'SIMPLE' | 't' | NULL | 'ALL' | NULL | NULL | NULL | NULL | '64' | '100.00' | NULL |
| '1' | 'SIMPLE' | 'cc' | NULL | 'ref' | 'fk_charge_teacher_idx' | 'fk_charge_teacher_idx' | '4' | 'analysis.t.id' | '1' | '100.00' | 'Using index' |
まず教師全員を得るためにteachersをテーブルフルスキャンして,取得したteacher_idからINDEXを利用して各教師たちの担当科目のIDを取得します.
遅いJOINを書こうと思ったのですがこのままの状態だと大体速いので敢えて外部キー制約によるINDEXを無効化します.
ALTER TABLE course_charges ALTER INDEX fk_charge_teacher_idx INVISIBLE;
さて,この状態で同じSQLの実行計画を見てみましょう.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| '1' | 'SIMPLE' | 't' | NULL | 'ALL' | NULL | NULL | NULL | NULL | '64' | '100.00' | NULL |
| '1' | 'SIMPLE' | 'cc' | NULL | 'ALL' | NULL | NULL | NULL | NULL | '128' | '100.00' | 'Using where; Using join buffer (Block Nested Loop)' |
cc(course_charges)のtypeがALLに変わり,INDEXを利用できず教師64名のIDに対して毎回course_charges128行をフルスキャンしていることが伺えます.この程度の規模のデータだとINDEXを削除したことで大体倍程度しかこのSQLは遅くなりませんが,データが増えると指数的に実行速度は遅くなっていきます.
適切に外部キー制約を貼ること,INDEXを貼ること,PRIMARY KEYを設定することがいかに大切かということです.
問題
最高のINDEXの貼り方を考えてみよう!
table_nはテーブルを,columnAはカラムを,id_nはtable_nのPRIMARY KEYを表すよ!
例1)
SELECT id_1 FROM table_1 WHERE columnA = 'hoge';
答え (反転させてね!)
columnAにINDEXを貼る
問1)
SELECT id_1 FROM table_1 WHERE columnA = 'hoge' ORDER BY columnB ASC;
答え (反転させてね!)
(columnA, columnB)の順にINDEXを貼る.
実はINDEXは複数のカラムに対して同時に貼ることも可能です.
(columnA, columnB)の順に貼られたINDEXは,最初にcolumnAの値でソートされ,次にcolumnBの値でソートされたB+木を作成します.
SQLはWHERE → GROUP BY → HAVING → ORDER BYの順に実行されるので,この順序のINDEXが最適です.
問2)
SELECT columnB, columnC FROM table_1 WHERE columnA = 'hoge' ORDER BY columnB ASC;
答え (反転させてね!)
(columnA, columnB, columnC)の順にINDEXを貼る.
実を言うと最後のcolumnCは別にいらないです.しかし入れておくとINDEXのみでこのクエリを解決できます.
実行計画を見るとUsing Index(インデックスツリーのみを使用し,テーブルデータにアクセスしない)を出力します.
一般にCovering Indexと呼ばれる技術で,通常絞り込みのために使うINDEXを,ある種のキャッシュ的な使い方をします.
問3)
SELECT id_2
FROM table_1
INNER JOIN
table_2 ON table_1.columnA = table_2.columnB
WHERE table_1.columnC = 'hoge';
答え (反転させてね!)
(table_2.columnB)と(table_1.columnC)にINDEXを貼る.
外部表と内部表の結合カラムのどちらにINDEXが必要かを問う題です.外部表の持つ値を内部表から探してくるため,内部表のカラムであるcolumnBにINDEXを貼っておくと良いでしょう.UNIQUE INDEXを貼れるとなお良いです.
table_1は(table_1.columnC, table_1.columnA)も良い答えだと思います.
ざっくりした問題と解説でしたが実際にこのINDEXが最高かは実は分かりません.データ数や統計情報によってオプティマイザが想定とは違うINDEXを使用することもあります.
まとめ
データベースは色々あって楽しい!
クエリの最適化はなんか頭の体操みたい!
きちんと設計すればMySQLは割と速いよ!