形態素解析とは
- 文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。(※Wikipediaより)
実行環境
- Windows環境(Windows10, 64bit)で以下の処理を実行しました。
下準備
以下の通り、2019/02/25時点で最新版のソフトウェアを利用しました。
- Rのインストール
- R-3.5.2を利用しました。
- MeCabのインストール
- 「Binary package for MS-Windows」のmecab-0.996.exeを使ってインストールしました。
- このWindows版にはコンパイル済みのIPA辞書が含まれているため、この辞書をそのまま活用して解析に使いました。
- RMeCabパッケージのインストール。
- Rを起動した後、以下のコマンドを実行してインストールしました。
- パッケージの読み込み
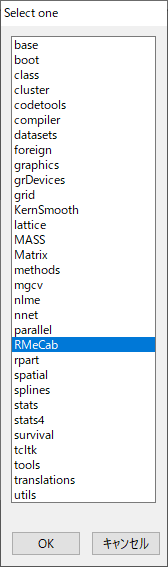
- ツールバーの[パッケージ]から[パッケージの読み込み]へ進み、開いたウィンドウ(※ウィンドウ名は"Select one")からRMeCabを選択します。
Rのコンソール
# RMeCabのインストール
> install.packages("RMeCab", repos = "http://rmecab.jp/R", dependencies = TRUE)
解析するテキスト
- Qiitaとはのページから、以下の文言を拝借しました。
qiita.txt
Qiitaは、プログラミングに関する知識を記録・共有するためのサービスです。
絵文字やシンタックスハイライトなど、豊富な機能を備えたMarkdown記法を使って、簡単に記事を投稿できます。
記事に付けたタグや、投稿したユーザ、ストック数、投稿日時の指定など、強力な検索機能で記事を探し出せます。
プログラミングに関する様々な分野のユーザ達と、知識を共有し、意見を交わすことで、より多くの知識を生み出しましょう。
解析処理
- RMeCabFreq関数を使って、qiita.txtを形態素解析した上で、形態素ごとの出現回数をカウントします。
- こちらのサイトによると、RMeCabFreqは「関数 RMeCabFreq( ) は指定されたテキストファイルを形態素解析して、その活用形を原形に変換した上で、その頻度を数えて、結果をデータフレームとして返す関数である。」と定義されています。
- 次にRMeCabFreq関数の結果として得られたデータフレームを、「品詞が名詞」に絞り込んだ上で、出現回数の降順にしています。
Rのコンソール
# 解析処理
> res <- RMeCabFreq("D:/qiita.txt")
> res <- res[res$Info1=="名詞",]
> res <- res[order(res$Freq, decreasing=T),]
解析結果
- 「投稿」「記事」「プログラミング」「共有」など、Qiitaらしい語句が並んでいます。
Rのコンソール
# 解析結果
> res
Term Info1 Info2 Freq
38 投稿 名詞 サ変接続 3
45 記事 名詞 一般 3
47 知識 名詞 一般 3
31 プログラミング 名詞 サ変接続 2
33 機能 名詞 サ変接続 2
35 共有 名詞 サ変接続 2
43 ユーザ 名詞 一般 2
29 サービス 名詞 サ変接続 1
30 ストック 名詞 サ変接続 1
32 意見 名詞 サ変接続 1
34 記録 名詞 サ変接続 1
36 検索 名詞 サ変接続 1
37 指定 名詞 サ変接続 1
39 Markdown 名詞 一般 1
40 シンタックス 名詞 一般 1
41 タグ 名詞 一般 1
42 ハイライト 名詞 一般 1
44 絵文字 名詞 一般 1
46 記法 名詞 一般 1
48 日時 名詞 一般 1
49 分野 名詞 一般 1
50 簡単 名詞 形容動詞語幹 1
51 強力 名詞 形容動詞語幹 1
52 豊富 名詞 形容動詞語幹 1
53 様々 名詞 形容動詞語幹 1
54 Qiita 名詞 固有名詞 1
55 数 名詞 接尾 1
56 達 名詞 接尾 1
57 こと 名詞 非自立 1
58 ため 名詞 非自立 1
59 多く 名詞 副詞可能 1
おわりに
- ずっと書きかけのままストックしていた記事だったので、記事の投稿時点では環境などがやや古くなっていると思います。