はじめに
BigQueryは分析ツールとして非常に便利なものではありますが、クエリの実行はオンデマンド利用の場合各クエリで処理されたバイト数に比例するため、クエリ実行で気をつけないと高額な請求に繋がるデメリットがあります。
また定期実行や他者によるクエリ実行がある場合、定期的に料金を監視しないとより高額な請求につながりやすく、また実際の請求を見てもどのクエリ実行が原因か分かりづらいという課題を感じていました。
そこで、今回は高額な請求に繋がっているクエリ実行を洗い出し見直しのきっかけとするために、クエリごとに実行回数や利用料金を集計しSlackに通知する仕組みを考えました。
今回の構成
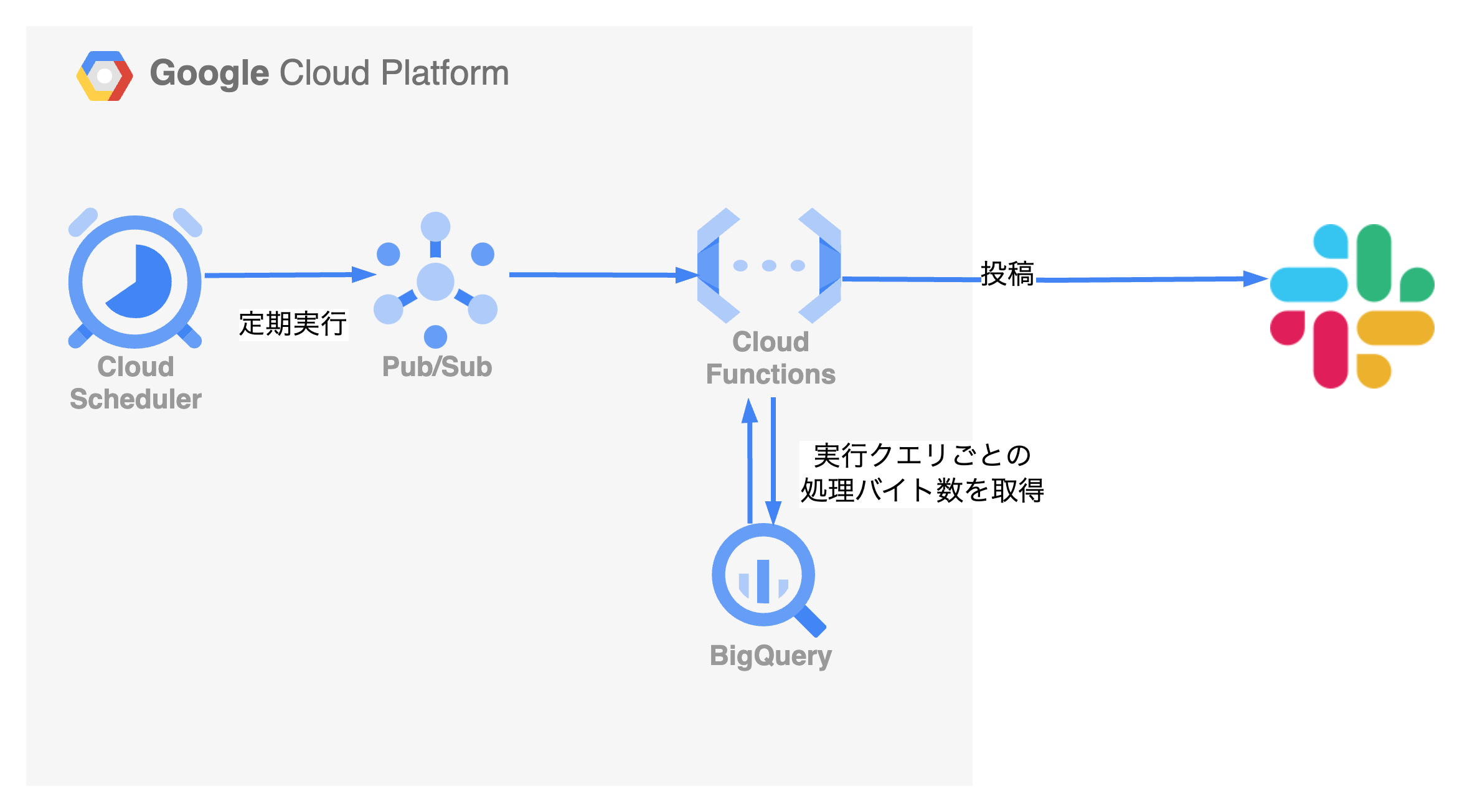
Cloud Scheduler を利用して定期的に Pub/Sub トピックを呼び出し、そこから Cloud Function にて一定期間中でコストが上位と推測されるクエリを洗い出すスクリプトを実行して、Slack に通知する流れとしております。
アウトプットイメージ
■BigQuery実行コスト集計結果■
total cost: $100.000
total query: 200
2times,$10.0(10.0%),{job_id1},SELECT XXX, YYY, ZZZ FROM table_a...
1times,$9.0(9.0%),{job_id2},SELECT SUM(YYY), ZZZ FROM table_b...
10times,$8.4(8.4%),{job_id3},SELECT AAA, BBB, CCC FROM table_c...
4times,$7.3(7.3%),{job_id4},SELECT DDD FROM table_d where EEE...
2times,$5.1(5.1%),{job_id5},SELECT FFF, GGG, HHH FROM table_e...
3times,$4.5(4.5%),{job_id6},SELECT AAA, BBB, CCC, SUM(DDD), E...
1times,$3.8(3.8%),{job_id7},WITH AAA AS (SELECT BBB, CCC FROM...
1times,$2.2(2.2%),{job_id8},SELECT AVG(XXX) AS YYY, ZZZ FROM ...
2times,$1.5(1.5%),{job_id9},SELECT XXX.YY, XXX.ZZZ FROM table...
3times,$1.3(1.3%),{job_id10},SELECT XXX, COUNT(DISTINCT YYY) ...
ソースコード
Terraform
# BigQueryの閲覧権限を実行スクリプト側が得るためのサービスアカウント設定
resource "google_service_account" "bq-history" {
account_id = "bq-history"
display_name = "bq-history"
}
resource "google_project_iam_member" "bq-history-bigquery-data-editor" {
project = # GCP のproject ID を指定
role = "roles/bigquery.resourceViewer"
member = "serviceAccount:${google_service_account.bq-history.email}"
}
resource "google_pubsub_topic" "bq-history-topic" {
name = "bq-history"
}
data "archive_file" "bq-history-func-archive" {
type = "zip"
source_dir = "path/to/bq_history" #ファイルを置きたいパスを指定する
output_path = "path/to/bq_history.zip"
}
# 実行関数を保存するためのバケット
resource "google_storage_bucket_object" "bq-history-func" {
name = "terraform/cloudfunctions/bq-history-func-${data.archive_file.bq-history-func-archive.output_md5}.zip"
bucket = # 保存先のバケット名を指定する
source = data.archive_file.bq-history-func-archive.output_path
}
resource "google_cloudfunctions_function" "bq-history-func" {
name = "bq-history"
description = "show and notify bq query history"
runtime = "python39"
service_account_email = google_service_account.bq-history.email
available_memory_mb = 256
source_archive_bucket = # 保存先のバケット名を指定する
source_archive_object = google_storage_bucket_object.bq-history-func.name
timeout = 300
entry_point = "handler"
event_trigger {
event_type = "google.pubsub.topic.publish"
resource = google_pubsub_topic.bq-history-topic.name
failure_policy {
retry = false
}
}
# SLACK_HOOK_URL, SLACK_MONITOR_CHANNEL を適宜指定する
environment_variables = {
SLACK_HOOK_URL =
SLACK_MONITOR_CHANNEL =
}
}
# 定期実行を行うための Cloud Scheduler ジョブ
resource "google_cloud_scheduler_job" "bq-history-scheduler" {
name = "bq-history-scheduler"
description = "show and notify bq query history"
schedule = "0 0 * * 1" // 月曜0時の場合
time_zone = "Asia/Tokyo"
pubsub_target {
topic_name = google_pubsub_topic.bq-history-topic.id
data = base64encode("{}")
}
}
Pythonスクリプト
今回の実装としては、以下が特に肝となると感じました。
どのようにコストを算出するか
直接クエリごとにかかったコストを取得する方法はなかったので、処理バイト数('totalBytesBilled' キーもしくは 'totalBytesProcessed' キー)と、ドキュメントに書いてある処理バイト数あたりの料金をもとに計算しました。なお 2024年4月 現在、USリージョンでは 1TB あたり 6.25USD = 1USD あたり 160GB です
少しだけ中身の違うクエリの集計
定期実行の場合は時刻を変えたり、作業者がクエリテンプレート等を持っている場合は一部の数値だけを適宜書き換えて繰り返しクエリを実行したり…などと微妙にクエリの内容を変えながら実行されているケースが多いです。この「書き換わった部分」を共通の文字に変換してうまく同一のクエリとみなすことで、大量に実行されかつコストが高額なクエリテンプレートや定期実行バッチ等が浮かび上がりやすくなります。
import http.client
import json
import logging
import os
import re
import sys
import urllib
from datetime import datetime, date, time, timedelta
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
import pytz
import google.auth
import google.auth.transport.requests
# 1 ドルあたりに処理可能なバイト数。 2024年4月 現在のUSリージョンでは 160 GB
# 詳細は(https://cloud.google.com/bigquery/pricing?hl=ja#bigquery-pricing)参照
PROCESSED_BYTES_PER_DOLLAR = 160_000_000_000
# 集計結果を出す数
SHOW_HEAVY_QUERY_COUNT = 10
# 表示するクエリの文字数(最初の何文字目までか)
QUERY_STRING_SLICE_LENGTH = 50
# 集計期間
PERIOD_DAYS = 7
# SLACKのWEBHOOKで利用するURL
SLACK_HOOK_URL = os.environ['SLACK_HOOK_URL']
# SLACKに流したいチャンネル
SLACK_MONITOR_CHANNEL = os.environ['SLACK_MONITOR_CHANNEL']
# GCPのプロジェクト名
GCP_PROJECT =
# BigQueryのリージョン
BIGQUERT_REGION =
# 時刻や空白、コメントやIDの差異を取り除き、同一クエリとして扱うための変換。ケースバイケースで要編集
NORMARIZE_PATTERNS = [
["\u00A0", ' '],
[r'[0-9]+\-[0-9]+\-[0-9]+', 'date'],
[r'[0-9]+:[0-9]+:[0-9]+', 'time'],
[r'\/\*.+\*\/', ''],
[r'--.*(--|\n)', ''],
[r'[0-9]{3,16}', 'num'],
[r'[\n\t\s]+', ' '],
[r'^[\n\t\s]+/', ''],
[r'[\n\t\s]+$', '']
]
def slack_message(color, message):
slack_message = {
'channel': SLACK_MONITOR_CHANNEL,
'username': 'BigQuery cost notifier',
'attachments': [
{
'text': message,
'fallback': message,
'color': color,
'mrkdwn_in': ['text'],
}
]
}
return slack_message
def post_slack(message):
logging.error("Slack: " + str(message))
req = Request(SLACK_HOOK_URL, json.dumps(message).encode("UTF-8"))
try:
response = urlopen(req)
response.read()
logging.error(f'Message posted to {message["channel"]}')
except HTTPError as e:
logging.error(f'Request failed: {e.code} {e.reason}')
except URLError as e:
logging.error(f'Server connection failed: {e.reason}')
def handler(_event, _context):
credentials, _project_id = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
auth_req = google.auth.transport.requests.Request()
credentials.refresh(auth_req)
today = date.today()
max_time = pytz.timezone('Asia/Tokyo').localize(datetime.combine(today, time()))
min_time = max_time - timedelta(days=PERIOD_DAYS)
token = credentials.token
next_pointer = "0"
query_result = []
while next_pointer is not None:
print(next_pointer)
parameters = {
'allUsers': 'true',
'maxResults': '10000',
'projection': 'FULL',
'min_creation_time': int(min_time.timestamp() * 1000),
'max_creatiton_time': int(max_time.timestamp() * 1000)
}
if next_pointer != "0":
parameters['pageToken'] = next_pointer
params_query = urllib.parse.urlencode(parameters)
conn = http.client.HTTPSConnection("www.googleapis.com")
conn.request(
"GET",
f'/bigquery/v2/projects/{GCP_PROJECT}/jobs?{params_query}',
headers={'Authorization': f'Bearer {token}'}
)
res = conn.getresponse()
status = res.status
if status != 200:
message = f'ERROR raised while getting bigquery jobs history. code: {status}'
post_slack(slack_message('danger', message))
sys.exit(1)
data = json.loads(res.read())
jobs = data['jobs']
for job in jobs:
estimate_billed_bytes = \
job['statistics'].get('totalBytesBilled') or job['statistics'].get('totalBytesProcessed')
if estimate_billed_bytes is None or job['configuration'] is None:
continue
estimate_cost = float(estimate_billed_bytes) / PROCESSED_BYTES_PER_DOLLAR
start_timestamp = datetime.fromtimestamp(float(job['statistics']['startTime']) / 1000)
query = job['configuration']['query']['query']
user = job['user_email']
job_id = job['id']
query_result.append({
'time': start_timestamp,
'user': user,
'estimate_cost': estimate_cost,
'query': query,
'job_id': job_id
})
next_pointer = data.get('nextPageToken')
query_result_group = {}
for result in query_result:
normalized_query = result['query']
for pattern in NORMARIZE_PATTERNS:
normalized_query = re.compile(pattern[0]).sub(pattern[1], normalized_query)
if query_result_group.get(normalized_query) is None:
query_result_group[normalized_query] = {'count': 0, 'total_cost': 0}
query_result_group[normalized_query]['count'] += 1
query_result_group[normalized_query]['total_cost'] += float(result['estimate_cost'])
query_result_group[normalized_query]['sample_job_id'] = result['job_id']
total_cost = sum(map(lambda v: v['total_cost'], query_result_group.values()))
total_query_count = sum(map(lambda v: v['count'], query_result_group.values()))
message = '■BigQuery実行コスト集計結果■\n'
message += (f'total cost: ${total_cost}\n')
message += (f'total query: {total_query_count}\n')
expensive_query_result_groups = sorted(query_result_group.items(), key=lambda stat: stat[1]['total_cost'], reverse=True)
for query, stat in expensive_query_result_groups[0:SHOW_HEAVY_QUERY_COUNT]:
times = stat['count']
cost = round(stat['total_cost'], 1)
rate = round(cost / total_cost * 100, 1)
job_id = stat['sample_job_id'].replace(f'{SLACK_MONITOR_CHANNEL}:{BIGQUERT_REGION}.", "")
message += (
f'{times}times,${cost}({rate}%),{job_id},{query[0:QUERY_STRING_SLICE_LENGTH]}...\n'
)
post_slack(slack_message('success', message))
クエリが長い場合の対処法
実際にこのようにしてクエリの実行集計結果を確認してみましたが、私の場合は実行されているクエリが数十行レベルと長く、結局クエリの最初の数十文字を見てもどこのことかアタリがつかないという問題が生じてしまいました。かといって長くしてしまうと、今度は表示が多すぎて読みにくい…というところで悩みました。
その場合は、実行された BigQuery ジョブの ID をもとに BigQuery に保存されている INFORMATION_SCHEMA.JOBS_BY_PROJECT テーブルへ以下のようにクエリを実行することで、クエリの全文と実行者のメールアドレスを確認できるようにするのが便利と思いました。
/* `region-us` の部分は適宜リージョンに合わせて書き換えてください */
SELECT user_email,
query,
job_id
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_id = '{job_idを入力}'
さらには Redash などでこのクエリを保存し、Slackのメッセージにてクエリへのリンクを貼れるとより便利でした。