Pythonの勉強中にスクレイピングに興味が沸いたので、Pythonによるスクレイピング&機械学習 開発テクニック(増版改訂版)で勉強してますが、スクレイピング本当に楽しいです。
上記書籍ではスクレイピング用のPythonライブラリとして、BeautifulSoup、Scrapy、Seleniumがで使い方が紹介されています。
今回はSeleniumを用いて、指定したTwitterユーザのメディアツイートに貼られている画像を全部DLするプログラムを作りましたのでその説明をします。
※一部BeautifulSoupを使用しています。
なぜSeleniumを選んだか?
Seleniumを選んだ理由は、「Webブラウザープログラム上で操作することでスクレイピングを行う」からです。
詳しい話は後述しますが、Twitterで特定ユーザのメディアツイートを見たい場合、https://twitter.com/ユーザID/mediaにアクセスすれば見れます。
ただ、このページには20件しかメディアツイートは表示されず、ページ下部までスクロールしないと新たなメディアツイートを表示してくれません。
従って、「ページ下部までスクロールする」というブラウザ操作が出来るSeleniumを採用しました。
動作環境
動作環境は以下の通りです。
- Windows 10
- Python 3.x
- Google Chrome
- Chrome Web Driver※
Chrome Web Driverは直接バイナリをダウンロードして環境変数PATHを通すか、pipからインストールする2種類の方法がありますが、今回はpipからインストールする方法で説明します。
Pythonライブラリは、以下の3つが必要になりますのでpipでインストールしてください。
- beautifulsoup
- selenium
- chromedriver_binary
pip install beautifulsoup4, selenium, chromedriver_binary
ソースコードの解説
本ソースは、GitHubにて公開しております。
まず、全内容を記載しますが、以降でいくつか要点を絞って解説します。
# coding:utf-8
from selenium.webdriver import Chrome, ChromeOptions
from bs4 import BeautifulSoup
from urllib import request, robotparser, error
from os import makedirs
import os.path, re, sys, time, chromedriver_binary
if __name__ == "__main__":
args = sys.argv
user_id = ''
# 引数をチェック
if len(args) <= 1:
# 引数が存在しない(user_idが指定されていない)場合は終了
sys.exit("Please type 'python ./dl_mediatweets.py 'user_id''!")
else:
if len(args) == 2:
user_id = args[1]
else:
# 引数が多すぎる(user_idが特定出来ない)場合は終了
sys.exit("Please type 'python ./dl_mediatweets.py 'user_id''!")
print("user_id='%s'" % user_id)
target_url = "https://twitter.com/" + user_id + "/media"
# Twitterのrobots.txtをチェックする
print("Checking 'robots.txt'...")
rp = robotparser.RobotFileParser()
rp.set_url("https://twitter.com/robots.txt")
rp.read()
# クローラがURLを見れるかチェックする。
if not rp.can_fetch("*", target_url):
# 見れない場合は終了
print("It is forbidden to crawl Twitter page.")
sys.exit(2)
# クローラの遅延時間指定パラメータの取得
# デフォルトは1秒とし、robots.txtで1秒以上が定められていた場合はその設定に従う
delay_sec = 1
if rp.crawl_delay("*"):
delay_sec = rp.crawl_delay("*")
if rp.request_rate("*"):
rpquest_rate = rp.request_rate("*").seconds / rp.request_rate("*").requests
if rpquest_rate > delay_sec:
delay_sec = rpquest_rate
# TwitterページのHTTPヘッダーのX-Robots-Tag内に、
# "nofollow"または"noarchive"が有るかチェック。
print("Checking 'X-Robots-Tag'...")
r = request.urlopen(target_url)
if "nofollow" in str(r.headers.get("X-Robots-Tag")) \
or "noarchive" in str(r.headers.get("X-Robots-Tag")):
# 存在する場合はクローリングが禁止されているので終了
print("It is forbidden to crawl Twitter page.")
sys.exit(2)
# Twitterページのmetaタグに、
# "nofollow"または"noarchive"が有るかチェックする。
print("Checking 'Meta Tag'...")
soup = BeautifulSoup(r, "html.parser")
meta = soup.find_all('meta',
attrs={"name":"robots"},
content=lambda x: "nofollow" in str(x).lower() or "noarchive" in str(x).lower())
if len(meta) > 0:
# 存在する場合はクローリングが禁止されているので終了
print("It is forbidden to crawl Twitter page.")
sys.exit(2)
# GoogleChromeのヘッドレスモードを有効化する
options = ChromeOptions()
options.add_argument("--headless")
# GoogleChromeを起動
driver = Chrome(options=options)
# 指定したユーザIDのTwitterページを開く
driver.get(target_url)
# TwitterページのタイトルにユーザIDが存在しない場合、
# 該当ユーザが存在しないと判断し終了
if not re.match(r".*@" + user_id + ".*$", driver.title):
sys.exit("Error! Not Found Twitter User Page!")
# 非公開ユーザかどうかチェックするため、非公開ユーザのみ存在する要素を取得する
# 非公開ユーザの場合、ツイートを取得できないため、終了
protect_check_elems = driver.find_elements_by_css_selector("#page-container > div.AppContainer > div > div > div.Grid-cell.u-size1of3.u-lg-size1of4 > div > div > div > div.ProfileHeaderCard > h1 > span > a")
if len(protect_check_elems) > 0:
if re.match(r".*protected.*",protect_check_elems[0].get_attribute('href')):
sys.exit("Error! This User is Protected User!")
# メディアツイートを全て表示し、ツイート数をカウントする
print("Checking media tweets...")
media_tweets = driver.find_elements_by_css_selector("#stream-items-id > li")
# メディアツイートが無い場合は終了
if len(media_tweets) == 0:
print( "'%s' not found media tweets." % user_id)
sys.exit(1)
# メディアツイートを全て表示するまでSelenium上のTwitterページを下にスクロールする
while True:
media_end_elem = driver.find_element_by_css_selector("#timeline > div > div.stream > div.stream-footer > div > div.stream-end")
if media_end_elem is None or media_end_elem.is_displayed():
break
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(delay_sec)
# メディアツイートを取得する
media_tweets = driver.find_elements_by_css_selector("#stream-items-id > li")
media_tweet_count = len(media_tweets)
print("Media tweets count:", media_tweet_count)
# カレントディレクトリ/ユーザID/を保存ディレクトリとする
savedir = os.path.dirname("./" + user_id + "/")
if not os.path.exists(savedir):
# ディレクトリが無い場合は作成
makedirs(savedir)
# メディアツイートに存在する画像をすべて保存する
for media_tweet in media_tweets:
tweet_id = media_tweet.get_attribute("data-item-id")
print("Checking ID:%s '%s'" % (tweet_id, "https://twitter.com/" + user_id + "/status/" + tweet_id))
media_elem = media_tweet.find_elements_by_css_selector("div > div.content > div.AdaptiveMediaOuterContainer > div > div > div")
if len(media_elem) == 0:
print("ID:%s is not image tweet." % tweet_id)
continue
img_elems = media_elem[0].find_elements_by_tag_name("img")
for i, img_elem in enumerate(img_elems):
img_url = img_elem.get_attribute("src")
img_ext = re.search(r"^.*(\.[0-9|a-z|A-Z]+)$", img_url).group(1)
if len(img_elems) == 1:
# 1ツイートに対して、画像が1つの場合は、
# [ツイートID].[基画像の拡張子]をファイル名とする
savepath = savedir + "/" + tweet_id + img_ext
else:
# 1ツイートに対して、画像が複数存在する場合は、
# [ツイートID_連番].[基画像の拡張子]をファイル名とする
savepath = savedir + "/" + tweet_id + "_" + str(i+1) + img_ext
if os.path.exists(savepath):
# 既に保存している場合はスキップ
print("ID:%s is Already Download.(url:'%s')" % (tweet_id, img_url))
continue
# 画像を保存する
print("Download: from '%s' to '%s'" % (img_url,savepath))
try:
# 画像のダウンロードは失敗する可能性があるのでエラーをキャッチする
request.urlretrieve(img_url, savepath)
except error.HTTPError as e:
# HTTP Errorとなった場合はエラーコードを表示
print("Failed download:'%s' (Error Code:%s)" % (img_url, e.code))
except error.URLError as e:
# URL Errorとなった場合はエラーメッセージを表示
print("Failed download:'%s' (Error Message:%s)" % (img_url, e.reason))
# robots.txtに従ってウェイト
time.sleep(delay_sec)
print("Complete.")
driver.quit()
引数チェック
本ソースは、以下の通りにコマンドを入力することで実行できます。
python ./dl_mediatweets.py ユーザID
なのでsys.argvでコマンドライン引数からユーザIDを取得しています。
※if文の分岐がおかしいのは、コマンドを増やそうとして結局増やさなかった名残です。。。
if __name__ == "__main__":
args = sys.argv
user_id = ''
# 引数をチェック
if len(args) <= 1:
# 引数が存在しない(user_idが指定されていない)場合は終了
sys.exit("Please type 'python ./dl_mediatweets.py 'user_id''!")
else:
if len(args) == 2:
user_id = args[1]
else:
# 引数が多すぎる(user_idが特定出来ない)場合は終了
sys.exit("Please type 'python ./dl_mediatweets.py 'user_id''!")
print("user_id='%s'" % user_id)
robots.txt、Metaタグ、HTTPヘッダーのX-Robots-Tagチェック
クローリングやスクレイピングはとても便利ですが使い方を誤ると、取得先のサーバに大きな負荷を与えたり、クローラによる取得が許可されていないページも取得してしまう可能性があります。
そういったことを避けるために、ドメイン直下に配置されているrobots.txt、Metaタグなどを必ず確認しましょう。
スクレイピングのマナーについては以下の記事がとても参考になります。
今回のソースで使用した上記内容をチェックする場合のPythonソースコードも記載されていますので是非。
Webスクレイピングする際のルールとPythonによる規約の読み込み - Stimulator
robots.txtの確認
まず、robots.txtの確認ですが、こちらはurllib.robotparserを使うことで簡単に内容を解読できます。
※urllibはbeautifulsoupをインストールすると自動でインストールされます。
自身がクローリングしたいページがrobots.txtで許可されているかを確認する方法は、以下の通りです。
重要なのはrp.can_fetch("*",target_url)のところで、これはUser-Agentが"*"となっている設定、つまり全てのクローラに対する設定となっており、その設定では指定したURLがクローリング可能かを調べています。
target_url = "https://twitter.com/" + user_id + "/media"
# Twitterのrobots.txtをチェックする
print("Checking 'robots.txt'...")
rp = robotparser.RobotFileParser()
rp.set_url("https://twitter.com/robots.txt")
rp.read()
# クローラがURLを見れるかチェックする。
if not rp.can_fetch("*", target_url):
# 見れない場合は終了
print("It is forbidden to crawl Twitter page.")
sys.exit(2)
また、robots.txtでは1ページ当たりのウェイト秒数、何秒当たり何リクエスト可能かも指定されていますので、この情報も確認する必要があります。
上記値は設定されていない場合もありますが、必ず1ページ当たり1秒のウェイトをかけるようにしましょう。
# クローラの遅延時間指定パラメータの取得
# デフォルトは1秒とし、robots.txtで1秒以上が定められていた場合はその設定に従う
delay_sec = 1
if rp.crawl_delay("*"):
delay_sec = rp.crawl_delay("*")
if rp.request_rate("*"):
rpquest_rate = rp.request_rate("*").seconds / rp.request_rate("*").requests
if rpquest_rate > delay_sec:
delay_sec = rpquest_rate
Metaタグ、HTTPヘッダーのX-Robots-Tagの確認
Metaタグ、HTTPヘッダーのX-Robots-Tagにはnoindex、nofollow、noarchiveが指定されていることがあります。
3つの簡単な説明は以下の通りです。
- noindex:該当ページを検索エンジンの検索結果に表示しないようにする
- nofollow:該当ページに記載されているURLリンクをクローラで走査しないようにする
- noarchive:該当ページをキャッシュしないようにする
今回はメディアツイートの一覧から画像を全てダウンロードするプログラムを作成するので、nofollowとnoarchiveが付いていないかを確認します。
※個人利用だとあんまり関係ないかもしれませんが、念のため。
HTTPヘッダーの確認はurllib.request.urlopenを使います。
Metaタグの確認はBeautifulSoupを使います。
# TwitterページのHTTPヘッダーのX-Robots-Tag内に、
# "nofollow"または"noarchive"が有るかチェック。
print("Checking 'X-Robots-Tag'...")
r = request.urlopen(target_url)
if "nofollow" in str(r.headers.get("X-Robots-Tag")) \
or "noarchive" in str(r.headers.get("X-Robots-Tag")):
# 存在する場合はクローリングが禁止されているので終了
print("It is forbidden to crawl Twitter page.")
sys.exit(2)
# Twitterページのmetaタグに、
# "nofollow"または"noarchive"が有るかチェックする。
print("Checking 'Meta Tag'...")
soup = BeautifulSoup(r, "html.parser")
meta = soup.find_all('meta',
attrs={"name":"robots"},
content=lambda x: "nofollow" in str(x).lower() or "noarchive" in str(x).lower())
if len(meta) > 0:
# 存在する場合はクローリングが禁止されているので終了
print("It is forbidden to crawl Twitter page.")
sys.exit(2)
Google Chromeをヘッドレスモードで起動
Seleniumを用いてGoogle Chromeを起動し操作するわけですが、何も指定しないと新たにGoogleChromeのウィンドウが開いてしまいます。
それを避けるためにGoogle Chromeをヘッドレスモードで起動するようオプションに"--headress"を追加します。
# GoogleChromeのヘッドレスモードを有効化する
options = ChromeOptions()
options.add_argument("--headless")
# GoogleChromeを起動
driver = Chrome(options=options)
# 指定したユーザIDのTwitterページを開く
driver.get(target_url)
画面をスクロールして、メディアツイートを全て表示する
前書きでも述べましたが、ツイッターのメディアツイート一覧のページは最初から全てのツイートが表示されておらず、画面下部までスクロールしないと次のメディアツイート(20件分)が表示されません。
Seleniumでは表示しているページにに対してJavaScriptを実行するexec_scriptメソッドが存在しますので、以下のスクリプトを実行することで画面下部までスクロールが可能です。
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
続いて、メディアツイートを全て表示できたか判定する方法ですが、ツイッターのページは以降のツイートが無い場合のみ表示するDOM要素があります。
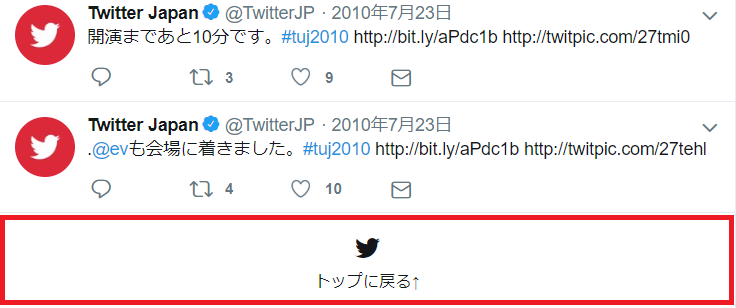
このDOM要素をSeleniumで取得し表示状態を確認することで、メディアツイートを全て表示できたか確認します。
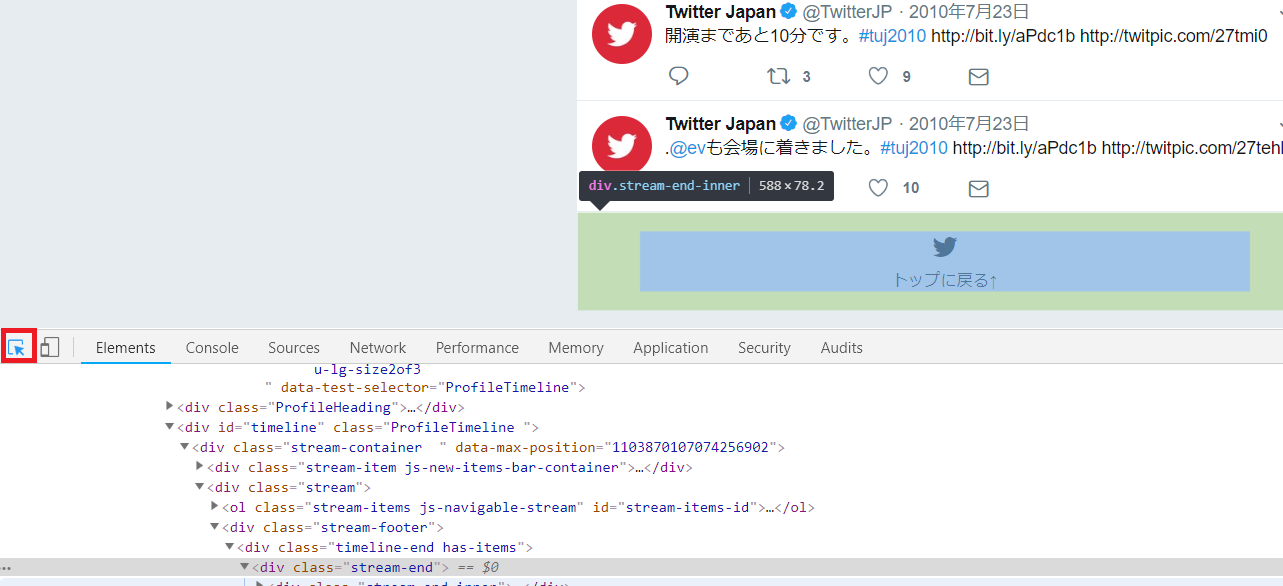
取得方法は色々ありますが、今回はGoogle Chromeのデベロッパー・ツールでDOM要素のSelectorを確認し、それを用いて取得します。
デベロッパー・ツールはF12キーで表示できます。
表示したら左下のアイコンをクリックすると、ブラウザ上のDOM要素のHTMLタグが分かります。
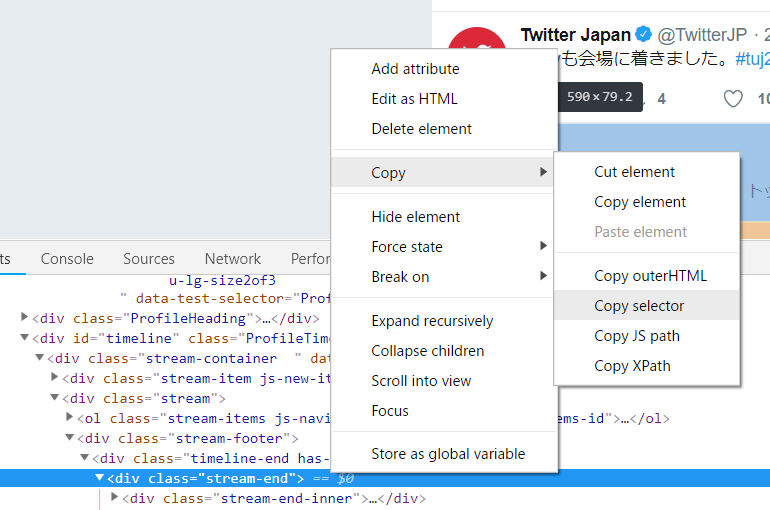
タグが分かったらそのタグを右クリックし、「copy > copy selector」を選択することで対象のDOM要素のCSS selectorをコピーできます。
要素の取得はfind_element_by_css_selector()で行えますので、コピーしたCSS selecotrをメソッドの引数に指定します。
要素の表示状態の確認はis_displayed()で行います。
# メディアツイートを全て表示するまでSelenium上のTwitterページを下にスクロールする
while True:
media_end_elem = driver.find_element_by_css_selector("#timeline > div > div.stream > div.stream-footer > div > div.stream-end")
if media_end_elem is None or media_end_elem.is_displayed():
break
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(delay_sec)
メディアツイートを取得し、画像をDLする
メディアツイートを全て表示したら、先ほどと同様の手段でデベロッパー・ツールからツイートの連続要素となっているタグのCSS Selectorをコピーし、それを用いてメディアツイートを取得します。
先ほどは、find_element_by_css_selector()で要素を取得しましたが、今回は要素が複数個あるのでfind_elements_by_css_selector()で取得します。
# メディアツイートを取得する
media_tweets = driver.find_elements_by_css_selector("#stream-items-id > li")
media_tweet_count = len(media_tweets)
print("Media tweets count:", media_tweet_count)
あとは取得したメディアツイートの要素をループで1つずつ処理します。
先ほど取得したメディアツイートですが、以下のようなタグ構成となっています
階層は深いですが、画像は全てimgタグで表示しています。
<div id="stream-items-id">
<li><!-- この要素に対してリストで取得 -->
<div>
<div>ユーザアイコン</div>
<div>
<div>ツイートのヘッダー部(ユーザ名、日時)</div>
<div>ツイート内容</div>
<div><!-- ツイートに張り付いている画像、動画などのコンテンツ領域 -->
<div>
・・・
<div>
<div><!-- 1番目の画像領域 -->
<img />
</div>
<div><!-- 2番目以降の画像領域 -->
<img />
・・・
</div>
・・・
</div>
</div>
<div>ツイートのフッター部(返信、リツイート、いいねのアイコン)</div>
</div>
</div>
</li>
<li>
・・・
</div>
あとは、各要素の内部にあるimgタグから画像をDLします。
ちなみに、メディアツイートには動画も含まれていますが、その場合はimgタグは存在しないため、スキップします。
また、画像ツイートの画像が見つからない場合もありますので、その場合もスキップします。
# カレントディレクトリ/ユーザID/を保存ディレクトリとする
savedir = os.path.dirname("./" + user_id + "/")
if not os.path.exists(savedir):
# ディレクトリが無い場合は作成
makedirs(savedir)
# メディアツイートに存在する画像をすべて保存する
for media_tweet in media_tweets:
tweet_id = media_tweet.get_attribute("data-item-id")
print("Checking ID:%s '%s'" % (tweet_id, "https://twitter.com/" + user_id + "/status/" + tweet_id))
media_elem = media_tweet.find_elements_by_css_selector("div > div.content > div.AdaptiveMediaOuterContainer > div > div > div")
if len(media_elem) == 0:
print("ID:%s is not image tweet." % tweet_id)
continue
img_elems = media_elem[0].find_elements_by_tag_name("img")
for i, img_elem in enumerate(img_elems):
img_url = img_elem.get_attribute("src")
img_ext = re.search(r"^.*(\.[0-9|a-z|A-Z]+)$", img_url).group(1)
if len(img_elems) == 1:
# 1ツイートに対して、画像が1つの場合は、
# [ツイートID].[基画像の拡張子]をファイル名とする
savepath = savedir + "/" + tweet_id + img_ext
else:
# 1ツイートに対して、画像が複数存在する場合は、
# [ツイートID_連番].[基画像の拡張子]をファイル名とする
savepath = savedir + "/" + tweet_id + "_" + str(i+1) + img_ext
if os.path.exists(savepath):
# 既に保存している場合はスキップ
print("ID:%s is Already Download.(url:'%s')" % (tweet_id, img_url))
continue
# 画像を保存する
print("Download: from '%s' to '%s'" % (img_url,savepath))
try:
# 画像のダウンロードは失敗する可能性があるのでエラーをキャッチする
request.urlretrieve(img_url, savepath)
except error.HTTPError as e:
# HTTP Errorとなった場合はエラーコードを表示
print("Failed download:'%s' (Error Code:%s)" % (img_url, e.code))
except error.URLError as e:
# URL Errorとなった場合はエラーメッセージを表示
print("Failed download:'%s' (Error Message:%s)" % (img_url, e.reason))
# robots.txtに従ってウェイト
time.sleep(delay_sec)
print("Complete.")
driver.quit()
最後に
Twitterの画像DLについてはtimg: Twitterや、Twitterメディアダウンローダとかあるので有用性は低いですが、スクレイピングのいい練習になりました。