TensorFlow 2.0 の@tf.function でどのくらい実行速度が変わるか検証してみました。
(TensorFlow 2.0 の安定版はまだリリースされていません。この記事ではv2.0.0rc1 を用いています。)
はじめに
どこかで見聞きしている方も多いかと思いますが、TensorFlow 2.0 ではこれまでのTensorFlow から大きく変わって、Define-by-Run スタイル(1.x でのEager モード)がデフォルトになります。
Define-by-Run スタイルは、書きやすかったりデバッグしやすかったり、といい所もいっぱいあるのですが、やっぱり気になるのが「遅くなるんじゃないの?」って所です。
幸い、TensorFlow 2.0 にはtf.function というプログラムの一部をコンパイルしてグラフに変換する機能が追加されています。次のように、対象の関数を@tf.function でデコレートすることでこの機能を使うことができます:
@tf.function
def add(a, b):
return a + b
また、クラスのメソッドにも適用可能です。
注意: ただし、このデコレータには色々と制約があり、適当につけると意図しない挙動を示します。特に、グラフに変換したい関数が副作用を伴う場合には注意が必要です。この記事の最後にいくつか例を示します。
さて、「で、@tf.function で自分が書いた処理をどのくらい速くできるんや?」と思い、具体的な学習例で実行時間を計測してみました。
検証に使った実行環境はGoogle Colaboratory のPython 3 ランタイムで、GPUを有効にしたものです。
現在、TensorFlow 2.0 はrc1 が最新版です。pip install tensorflow-gpu==2.0.0-rc1 でColaboratory の環境にインストールしてから検証を行いました。
この記事の検証に用いたノートブックはGistにアップしてあります:
また、tf.function の公式ドキュメントはこちらです:
- https://www.tensorflow.org/beta/tutorials/eager/tf_function?hl=ja
- https://www.tensorflow.org/beta/guide/autograph?hl=ja
実行時間の計測方法
今回は、「fashion-MNISTデータでニューラルネットの学習を行う」という設定で学習にかかる時間を計測・比較してみました。
具体的には、
- ロスの計算
- 勾配の計算と重みの更新
- 学習中の訓練データにおけるロスとAccuracy の集計
- 各エポック終了後にテストデータにおけるロスとAccuracy の集計
といった処理を行う学習用クラスを実装し、@tf.functionの有無で学習にかかる時間がどれくらい変わるかを調べました。
まあ、こんなのは自分で書く必要なんてなくて、Keras を使えば簡単にできちゃいます。笑
というわけで、tf.keras.Sequential を使った場合の学習時間も合わせて計測して比較を行いました。
以下、次のようにimport しているとします:
import tensorflow as tf
from tensorflow import keras
学習用クラスの実装
次のような学習用クラスを実装しました:
class Trainer(object):
"""学習用のクラス
Args:
model: 学習したいモデル
optimizer: 使用するオプティマイザ
"""
def __init__(self, model, optimizer):
self.model = model
self.optimizer = optimizer
self.loss_fn = keras.losses.SparseCategoricalCrossentropy()
# 学習中のロス・Accuracy の集計用metric
self.train_metric_loss = keras.metrics.Mean()
self.train_metric_accuracy = keras.metrics.SparseCategoricalAccuracy()
self.validation_metric_loss = keras.metrics.Mean()
self.validation_metric_accuracy = keras.metrics.SparseCategoricalAccuracy()
self.history = {"loss": [], "val_loss": [], "accuracy": [], "val_accuracy": []}
def train_step(self, x_batch, y_batch):
"""ミニバッチ単位での学習ステップ"""
with tf.GradientTape() as tape:
y_pred = self.model(x_batch, training=True)
loss = self.loss_fn(y_batch, y_pred)
grads = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_variables))
self.train_metric_loss(loss)
self.train_metric_accuracy(y_batch, y_pred)
def eval_step(self, x_batch, y_batch):
"""ミニバッチ単位での評価"""
y_pred = self.model(x_batch, training=False)
loss = self.loss_fn(y_batch, y_pred)
self.validation_metric_loss(loss)
self.validation_metric_accuracy(y_batch, y_pred)
def train(self, epochs, train_dataset, validation_dataset, verbose=True):
"""学習ループを行う
Args:
epochs: 学習エポック数
train_dataset: 学習用のデータセット
validation_dataset: 評価用のデータセット
verbose: 学習ログをプリントするか
"""
for epoch in range(epochs):
for x_batch, y_batch in train_dataset:
self.train_step(x_batch, y_batch)
train_loss = self.train_metric_loss.result().numpy()
train_accuracy = self.train_metric_accuracy.result().numpy()
self.train_metric_loss.reset_states()
self.train_metric_accuracy.reset_states()
for x_batch, y_batch in validation_dataset:
self.eval_step(x_batch, y_batch)
validation_loss = self.validation_metric_loss.result().numpy()
validation_accuracy = self.validation_metric_accuracy.result().numpy()
self.validation_metric_loss.reset_states()
self.validation_metric_accuracy.reset_states()
if verbose:
train_log = "epoch={}: train loss={:.3f}, val_loss={:.3f}, train_acc={:.3f}, val_acc={:.3f}".format(
epoch + 1,
train_loss,
validation_loss,
train_accuracy,
validation_accuracy)
print(train_log)
self.history["loss"].append(train_loss)
self.history["val_loss"].append(validation_loss)
self.history["accuracy"].append(train_accuracy)
self.history["val_accuracy"].append(validation_accuracy)
気持ち程度のコメントしか書いてませんが、モデルとオプティマイザで初期化して、train メソッドにデータセット(tf.data.Dataset)を渡すことで学習するというシンプルなやつです。
(tf.keras.metrics にあるクラスを使っていますが、ここでは使い方などは説明しません。興味のある方は公式ドキュメントなどをあたってください。)
追記: train_step とeval_step メソッドは単独で外から呼ばれることを想定していないので、_train_step のような名前にするべきでしたね... まあ、今回は時間を計るだけだし...(言い訳)。
この実装が@tf.function によるデコレートなしのもので、デコレートありの方ではtrain_step とeval_step メソッドに@tf.function を付けてあげました。
(Gist にあげているノートブックでは、二つクラスを用意するのがめんどくさかったので、
trainer = Trainer(model, optimizer)
# tf.function をTrainer.train_step とTrainer.eval_step に適用
trainer.train_step = tf.function(trainer.train_step)
trainer.eval_step = tf.function(trainer.eval_step)
とすることで動的にメソッドをラップしています。)
使用するネットワーク
全結合層だけのニューラルネットワークと畳み込みニューラルネットワークの2種類で検証しました。
それぞれ、以下のようなモデルです(構成は適当です):
# 全結合層だけのニューラルネットワークの方
keras.Sequential([
keras.layers.Dense(20, activation="relu", input_shape=(28 * 28,)),
keras.layers.Dense(20, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
# 畳み込みニューラルネットワークの方
keras.Sequential([
keras.layers.Conv2D(32, (3, 3), activation="relu", input_shape=(28, 28, 1)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(64, (3, 3), activation="relu"),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.SpatialDropout2D(0.3),
keras.layers.Conv2D(64, (3, 3), activation="relu"),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
その他の条件
エポック数は10、バッチサイズは128、計測回数はそれぞれ5回ずつです。
オプティマイザはAdam をデフォルトパラメータで利用しました。
データセットの作り方等はGist にあげてるノートブックを見てください。
計測方法
実行時間は次のようにして計っています:
import time
trainer = Trainer(model, optimizer)
start = time.time()
trainer.train(num_epochs, train_dataset, test_dataset, verbose=False)
end = time.time()
elapsed_time = end - start
keras.Sequential の方は、対応するロスとmetric を指定して次のように実行時間を計測しています:
model.compile(optimizer=optimizer, loss="sparse_categorical_crossentropy", metrics=["accuracy"])
start = time.time()
model.fit(X_train, y_train, epochs=num_epochs, batch_size=batch_size, validation_data=(X_test, y_test), verbose=0)
end = time.time()
elapsed_time = end - start
(Keras 使うとめっちゃ簡単。笑)
計測結果
計測結果はこちらです!
全結合層だけのニューラルネットワーク
| 学習方法 | 学習時間平均値 (s) |
|---|---|
@tf.function なし |
85.4 |
@tf.function あり |
13.5 |
keras.Sequential |
18.8 |

(プロットに単位を入れ忘れてしまいましたが、秒です。)
畳み込みニューラルネットワーク
| 学習方法 | 学習時間平均値 (s) |
|---|---|
@tf.function なし |
158.9 |
@tf.function あり |
34.7 |
keras.Sequential |
45.6 |
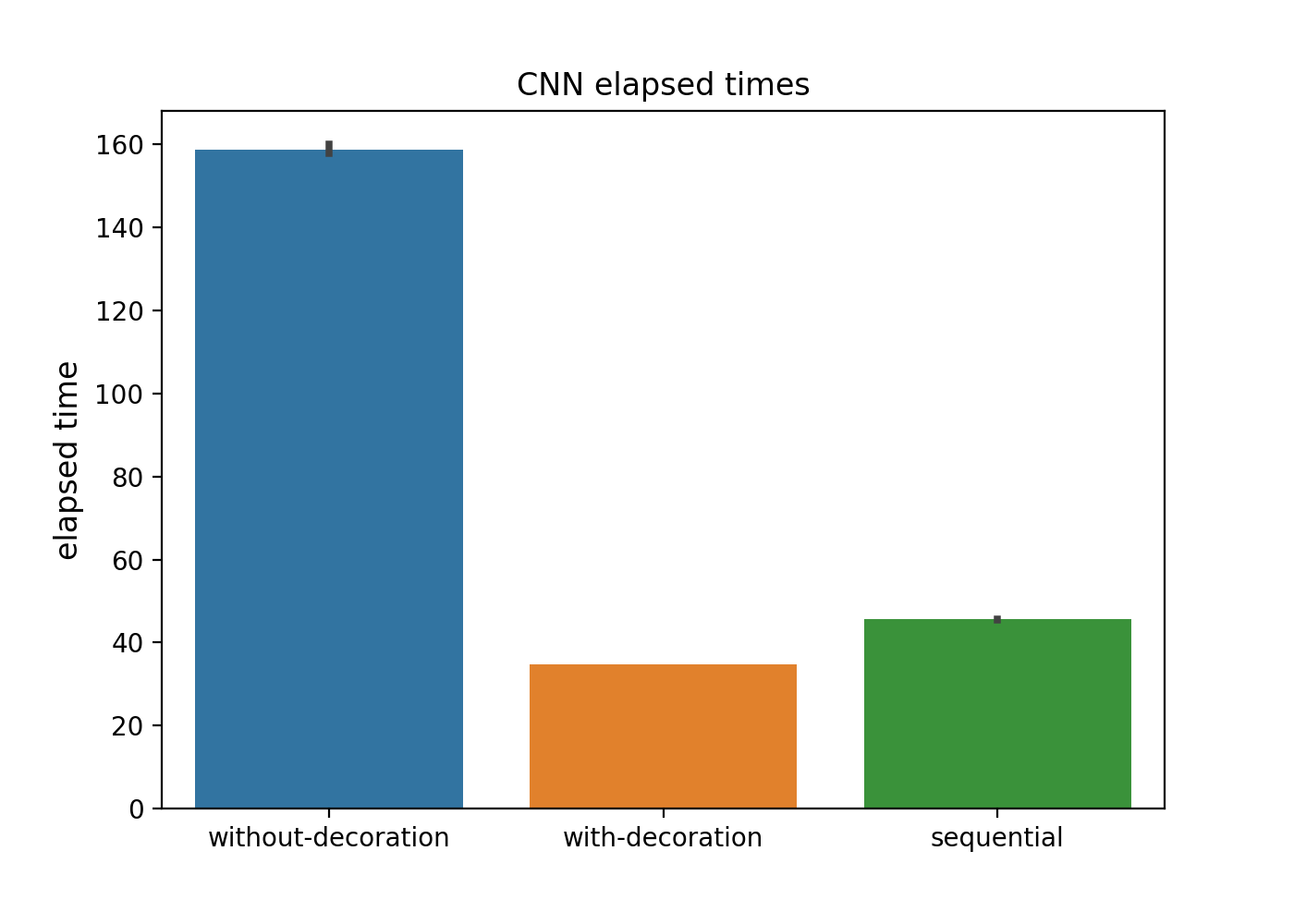
考察的な
上の数字を見ていただければ、そんなに言うこともありませんが...
まず、「@tf.function なしのやつ遅い!」ってのが最初の感想です。
そして、デコレートしてあげたやつがkeras.Sequential より速かったのはちょっと嬉しいですね。
ただ、このくらいのタスクならKeras を使ってしまう方が、色んな面で楽ができて良い気もします(評価指標の追加も簡単だし、元から用意されている多くのコールバックも魅力だし)。
GAN とか深層強化学習だったり、どうしても自分で学習ロジックを実装したい(Keras だと難しい)という時には、@tf.function の利用は必須かなと思いました。
(もちろん、実行環境によって差はあると思うので、その点はご留意ください。)
@tf.function を使う時の注意事項
さて、最初の方でもコメントした@tf.function を使う時の注意事項についてです。
公式ドキュメント からの引用ですが、この文章を念頭に置いておきましょう:
The main takeaways and recommendations are:
- Don't rely on Python side effects like object mutation or list appends.
- tf.function works best with TensorFlow ops, rather than NumPy ops or Python primitives.
- When in doubt, use the for x in y idiom.
まず、とても大事な点ですが、@tf.function はPython の副作用を伴うような処理に対してまともに振る舞ってくれません。
次のような例を見てみましょう:
l = []
def append_to_list(x):
print(x)
l.append(x)
append_to_list(1)
append_to_list(1)
append_to_list(2)
append_to_list(2)
print(l)
この結果はもちろん
1
1
2
2
[1, 1, 2, 2]
となります。
@tf.function を付けてみると...
# @tf.function をつけてみる
l = []
@tf.function
def append_to_list(x):
l.append(x)
append_to_list(1)
append_to_list(1)
append_to_list(2)
append_to_list(2)
print(l)
1
2
[1, 2]
最初は「え!?」ってなると思います。
もうちょっと例を見てみましょう:
# インプットをプリントして、足し算結果を返すだけの関数
def add(a, b):
print(a)
print(b)
return a + b
print(add(1, 2))
print("\n")
print(add(1, 2))
print("\n")
print(add(1, 3))
print("\n")
print(add(tf.constant(1), tf.constant(2)))
print("\n")
print(add(tf.constant(1), tf.constant(2)))
print("\n")
print(add(tf.constant(1), tf.constant(3)))
1
2
3
1
2
3
1
3
4
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(4, shape=(), dtype=int32)
@tf.function をつけてみると...
@tf.function
def add(a, b):
print(a)
print(b)
return a + b
print(add(1, 2))
print("\n")
print(add(1, 2))
print("\n")
print(add(1, 3))
print("\n")
print(add(tf.constant(1), tf.constant(2)))
print("\n")
print(add(tf.constant(1), tf.constant(2)))
print("\n")
print(add(tf.constant(1), tf.constant(3)))
1
2
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
1
3
tf.Tensor(4, shape=(), dtype=int32)
Tensor("a:0", shape=(), dtype=int32)
Tensor("b:0", shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
tf.Tensor(4, shape=(), dtype=int32)
公式ドキュメントによる説明をかみ砕くと、@tf.function を付けた関数の挙動は次のような感じということになるでしょうか:
- 関数の引数が「初めてのもの」だと、trace(グラフへの変換のこと?)された後に実行される。
- 例えば、上の例でa=1, b=2 とa=1, b=3 は異なる引数ということになって、それぞれ初回はtrace が発生する。
- 引数がPython のオブジェクトの場合、Primitiveは値、その他はid 単位でtrace が発生する。
- trace 時にだけprint 等が実行される。
- 関数の引数がTensorFlow のTensor 等の場合は、dtype とshape 単位でtrace が発生する。
(いい感じに要約できずすみません... 使う前にはドキュメント等を熟読することをおすすめします)
追記: 最初に書いたときには、上記の説明にいくつか勘違いがありました。また、表現の仕方も誤解を招きそうなものだったため修正しました。
というわけで、@tf.function を使うなら、
- 副作用を伴うような処理は避ける。
- ただし、TensorFlow 由来のものならうまく機能することがあります。
- 今回紹介した
Trainerクラスのtrain_stepメソッドは思いっきり副作用を伴っていますが、ちゃんと意図したように機能してくれます。 -
trainメソッドの方につけるのはまずいですね。
- デコレートする対象の関数にはTensorFlow 由来のものを渡すようにする。
といったことを意識する必要がありそうです。
まとめ
この記事では@tf.function によるパフォーマンス向上がどのくらいのものかを検証しました。自分で学習フローを書かないといけなくなった時には、@tf.function を使うメリットはかなりのものと思います。
ただし、@tf.function には色々と制約もあるので、あとからデコレートしやすいような実装を心掛ける必要がありそうです。