日英翻訳の作り方
日英翻訳をtensorflowとkerasで実装していきます。
この記事の目次です。
- 環境やデータセットの詳細
- [基本的な流れ](#basic flow)
- データの前処理
- [モデル構築](#construct model)
- 学習
- 評価
コードの詳細はgithubで公開していますので、参考にしてください。
Japanese-English_Translation
.pyinbで保存しているので、google colabで気軽に動かせるようになっています。
大昔に自然言語処理の勉強した際のコードを公開します。(少し整理したものを公開)
お役に立てれば、幸いです。
環境やデータセットの詳細
ハードウェアの環境
gooble colab
ソフトウェアの環境
python3
tensorflow (version2.3.1)
データセット
small_parallel_enja
small_parallel_enjaは、田中コーパスからいくつかの文章を抽出した小さなデータセットです。
前処理がなされており、すごく使いやすいものになっています。
データセットを学習データと検証データ、テストデータの3つに分割しているので、分割する必要もありません。
リソースに余裕があるのでしたら、学習データと検証データを混ぜたものを学習データとして、交差検証を行っても良いのかもです。(GPUを複数台所持の方)
基本的な流れ
以下の流れで進んでいきます。1. データの前処理
2. モデル構築
3. 学習
4. 評価
まあ、普通ですねww
データの前処理
データの前処理は済んでるものを使用するので、結構楽です。トークナイズは、tensorflowに組み込まれているkerasのAPIを使用します。
tf.keras.preprocessing.text.Tokenizer
使い方は、結構簡単で、以下に例を示します。
tokenizer = tf.keras.preprocessing.text.Tokenizer(oov="<unk>")
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
tf.keras.preprocessing.text.Tokenizerのインスタンスを生成して、
そのインスタンスに使用する単語をfit_on_texts(texts)で教えてあげます。
これを行うことにより、ユニークな単語を内部で管理します。
その後、tokenizer.texts_to_sequences(texts)でそれぞれの文章を数値化すれば良いだけです。textsとは、テキストデータセットのことを指します。textsのフォーマットは、文字列のリストになっている必要があります。
texts = ["I am Niwaka", "Hello !", .., "Wow !"]
上のコードは、tf.keras.preprocessing.text.Tokenizerインスタンスに渡すtextsのフォーマット例です。
使い方は、
tf.keras.preprocessing.text.Tokenizer
上のリンクへ飛べば分かります。
ミニバッチ化による学習を行うために、ミニバッチ内でのデータの形状が一致しないといけません。
しかし、自然言語データは一般的に可変長です。
そのため、他のデータセットと違い工夫しなければなりません。
可変データを扱うには以下の2通りの方法が考えられます。
1.padding
2.バッチサイズを1にする(時系列長が数百レベルなら、こっちを使用するのかな?)
ここでは、1のpaddingを使用します。
paddingとは、ミニバッチ内での最大時系列長がLだとすると、それに満たさないデータに対しては特殊な値を埋めることで長さをLにする手法のことです。tensorflowとkerasでは0が特殊な値として、設定されるようです。
例えば、以下のような長さが統一されていないデータセットがあったとしましょう。
sequences = [
[12, 45],
[3, 4, 7],
[4],
]
上のデータセットの最大長は3です。paddingを行うと以下のようになります。
padded_sequences = [
[12, 45, 0],
[3, 4, 7],
[4, 0, 0],
]
tensorflowでは、textデータに対するpadding処理をtf.keras.preprocessing.sequence.pad_sequencesというAPIで提供しています。
使い方は、tf.keras.preprocessing.sequence.pad_sequencesに長さを統一したいデータセットを入力として与えるだけです。
padding引数は、後に0を埋めるか前に0を埋めるかの指定を行います。"post"を指定することで、あと埋めで0を埋めます。お好みで良いと思います。
padded_sequences = tf.keras.preprocessing.sequence.pad_sequences(sequences, padding="post")
これで、ミニバッチ化による学習を行うことができるようになりました。しかし、ここで問題があります。それは0をモデルがどう解釈するかという問題です。
できれば、0という特殊な値は無視できるようにしたいところですよね。でないと、可変長に対応できるRNNを使用する意味が薄れます。
tensorflowでは、Maskingと呼ばれる機能が用意されています。
Maskingとは、指定したステップ時の値を無視する機能のことです。これにより、可変長のデータをまとめて取り扱うことができます。(Maskingを使わずとも、可変長のデータを取り扱えますが、0という特殊な値もモデルに取り込まれることになります。そういうのは気持ち悪いので、避けたいです。)
詳しくは以下のリンクへ飛んでください。リンク先では、tensorflowとkerasにおけるMakingとPaddingの使い方についての解説が詳細に書かれております。
Masking and padding with Keras
tensorflowでは、Maskingは以下の方法で有効になります。
1.tf.keras.layers.Maskingを加える
2.tf.keras.layers.Embeddingの引数mask_zeroをTrueにする。
3.maskを利用するLayerに直接渡す。(これは愚直なやり方、動画などにはこれを使用するのかも)
ここでは、2を使用します。
今回使用するモデルでは、Embeddingによって自動でmaskが生成され、そのmaskが次のレイヤーに自動的に伝搬していきます。
カスタムトレーニングでは、3の「maskを利用するLayerに直接渡す。」を行ってください。
ここでは、kerasで用意されているtf.keras.Modelのfitメソッドを用いて、学習を行います。
そのため、maskが勝手に伝搬されていくので、手動でやる必要はありません。
モデル構築
モデルには、Seq2Seqモデルを使用します。 Seq2Seqとは、 Sequenceデータを別の何かしらのSequenceデータに変換するモデルのことです。 ここでいうSequenceデータとは、時系列データのことです。Seq2Seqのインターフェースは、
変換後のsequence = Seq2Seq(変換前のsequence)
です。
例えば、"私は学生です。"をSeq2Seqモデルに入力したとします。
"I am student ." = Seq2Seq("私は学生です。")
Seq2Seqは、2つのモジュールで構成されています。
1つがEncoder、2つめがDecoderです。
EncoderによってSequenceデータをエンコードし、人間には理解できない特徴量を出力します。
Decoderにそれとstartトークンを入力し、別の何かしらのSequenceデータを得ます。
ここで、startトークンとはsequenceの始まりを意味する特別な単語です。
以下にEncoderとDecoderのインターフェースを疑似言語で記述しました。
人間には理解できない特徴量 = Encoder(変換前のsequence)
変換後のsequence = Decoder(人間には理解できない特徴量、<start>トークン)
それぞれのモジュールでは、RNNを使用しております。具体的な仕組みは
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
の最初の方を読めば分かるはずです。この記事は、attentionに関する記事なのですが、Seq2Seqの説明も書かれています。
Seq2SeqではRNNを利用します。
RNNは、可変長データを取り扱うことができるので、自然言語を処理するのが得意です。加えて、各ステップで使用する重みは共有するので、パラメータの増加を抑えることができます。
ただし、あまりにも時系列長が長いデータは誤差逆伝播時に、勾配消失や勾配爆発につながるので注意ですね。
時系列長がたったの10でも、時間軸上に10層のレイヤーが展開されるのと同じことになります。
RNNにはGRUを採用しました。GRUは勾配消失を起こしづらいRNN系のモデルです。
今回使用するdecoderとencoderのモデル図は以下です。
図1 encoder
図2 decoder
EncoderとDecoderそれぞれでRNNを1つしか使用していないです。
データセットが小さいので、小さめのモデルにしました。
tensorflowとkerasを用いたコードが以下になります。
The Functional APIを利用しています。
可変長データを表したい時は、tf.keras.InputのshapeにNoneと指定すると良いです。
The Functional APIの使い方は、以下のリンクへ飛んでください。
The Functional API
以下は、モデル実装コードになります。modelとencoderとdecoderそれぞれ用意しています。
modelは、学習用に用意しました。model.fitで学習を行い得られたパラメータをencoderとdecoderに読み込んでいきます。学習時と推論時では、処理が異なります。
def CreateEncoderModel(vocab_size):
units = 128
emb_layer = tf.keras.layers.Embedding(vocab_size, units, mask_zero=True)#padding有効にするために、mask_zero=True
gru_layer = tf.keras.layers.GRU(units)
encoder_inputs = tf.keras.Input(shape=(None,))
outputs = emb_layer(encoder_inputs)
outputs = gru_layer(outputs)
encoder = tf.keras.Model(encoder_inputs, outputs)
return encoder
def CreateDecoderModel(vocab_size):
units = 128
emb_layer = tf.keras.layers.Embedding(vocab_size, units, mask_zero=True)#padding有効にするために、mask_zero=True
gru_layer = tf.keras.layers.GRU(units, return_sequences=True)
dense_layer = tf.keras.layers.Dense(vocab_size, activation="softmax")
decoder_inputs = tf.keras.Input(shape=(None,))
encoder_outputs = tf.keras.Input(shape=(None,))
outputs = emb_layer(decoder_inputs)
outputs = gru_layer(outputs, initial_state=encoder_outputs)
outputs = dense_layer(outputs)
decoder = tf.keras.Model([decoder_inputs, encoder_outputs], outputs)
return decoder
def CreateModel(seed, ja_vocab_size, en_vocab_size):
tf.random.set_seed(seed)
encoder = CreateEncoderModel(ja_vocab_size)
decoder = CreateDecoderModel(en_vocab_size)
encoder_inputs = tf.keras.Input(shape=(None,))
decoder_inputs = tf.keras.Input(shape=(None,))
encoder_outputs = encoder(encoder_inputs)
decoder_outputs = decoder([decoder_inputs, encoder_outputs])
model = tf.keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
return model, encoder, decoder
学習
バッチサイズ32, 64, 128で探索してみます。実験の設定を以下に示します。
1.RNNのunit数は128
2.重みの更新方法はAdam(学習率はデフォルトのまま)
3.epoch数は2
4.評価方法はBLEU
エポックを2回で止め、検証データに対する評価を行いました。
BLEUとは、翻訳の品質測定に使われる指標のことです。
以下は学習コードです。
bleu_scores = []
batch_size_list = [32, 64, 128]
for batch_size in batch_size_list:
model, encoder, decoder = CreateModel(seed, len(ja_tokenizer.word_index)+1, len(en_tokenizer.word_index)+1)
model.fit([train_ja_sequences, train_en_sequences[:, :-1]], train_en_sequences[:, 1:], batch_size=batch_size, epochs=2)
model.save(str(batch_size)+"model.h5")
encoder.load_weights(str(batch_size)+"model.h5", by_name=True)
decoder.load_weights(str(batch_size)+"model.h5", by_name=True)
bleu_score = Evaluate(valid_ja, valid_en, encoder, decoder)
bleu_scores.append(bleu_score)
Evaluate関数で、BLEUの測定を行なっています。(実装はgithubで公開しています。)
各バッチサイズを名前に用いて、モデル保存を行いました。
Decode方法は、各ステップの最大確率となる単語を出力としました。
貪欲に単語を決めていきました。(貪欲法)
本当は、Beam Searchを使ったほうが良いです。Beam Searchは、貪欲法の条件を少し緩めた探索アルゴリズムになります。
貪欲に各ステップの単語を決めても、それが最適解になるかどうかは分からないので、Beam Searchを使用したほうがいいです。
Beam Searchは、以下の説明が参考になります。
C5W3L03 Beam Search
リンク先は動画になっているので、時間に余裕があるときに観ると良いです。
kerasでは、loss値を求める際にmaskを適用しているのかどうか気になります。
適用されているという話を聞いたことがあるのですが、そこんところどうなっているのか実装を知らないので、よく分かりません。
気持ち悪いと感じるならば、Neural machine translation with attentionのコスト関数の実装が参考になります。ただし、リンク先の実装はmodel.fitでしか学習を行なった経験しかない人にとっては結構難しいものになっていますので、注意してください。
リンク先のコスト関数の実装は、maskするステップ時のコストを最終的なコストに計上しないように実装しています。
実験結果をグラフにしました。
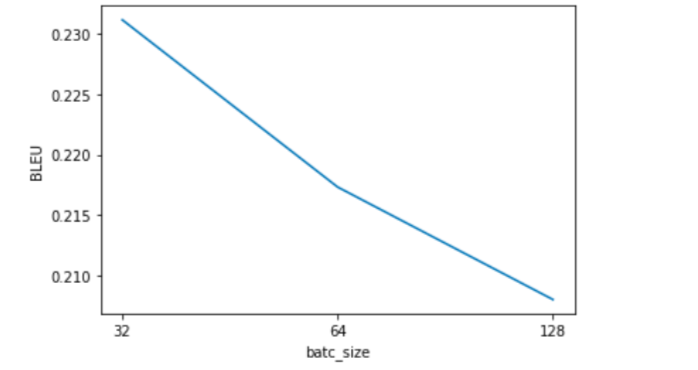
図3 実験結果
画像が荒いですが、ご了承ください。
検証データに対する最も良いBLEUを得られたバッチサイズは32なので、32を使用して、再学習を行います。
図3を見る限り、バッチサイズを更に小さくすると、より良い結果が得られるかもです。
評価に入る前に、学習データと検証データを混ぜて、再学習しておきます。
再学習では、epoch数を10にしました。それ以外は同じです。
本来は、混ぜない方が良いと思います。検証データに対するBLEUが最も高くなるepoch時で、モデル保存するようにし、test_dataに対して、評価を行うほうがいいです。
train_and_valid_ja_sequences = tf.concat([train_ja_sequences, valid_ja_sequences], 0)
train_and_valid_en_sequences = tf.concat([train_en_sequences, valid_en_sequences], 0)
best_model, best_encoder, best_decoder = CreateModel(seed, len(ja_tokenizer.word_index)+1, len(en_tokenizer.word_index)+1)
best_model.fit([train_and_valid_ja_sequences, train_and_valid_en_sequences[:, :-1]], train_and_valid_en_sequences[:, 1:], batch_size=32, epochs=10)
best_model.save("best_model.h5")
GPUを使用している場合、同じ結果が得られるとは限らないです。
評価
テストデータに対するBLEU0.19でした。(最大が1) 他と比較していないので分かりませんが、結構酷い結果だと思いますwwwテストデータに対する処理のコードは、以下になります。
best_encoder.load_weights("best_model.h5", by_name=True)
best_decoderbest_decoder.load_weights("best_model.h5", by_name=True)
bleu_score = Evaluate(test_ja, test_en, best_encoder, best_decoder)
print("bleu on test_dataset:")
print(bleu_score)
素朴な疑問なのですが、BLEU評価方法はいくつか存在するようです。(smoothing_functionはいくつか存在するようです。)
統一されていなそうなのですが、そこのところ詳しい方教えてください。
統一されていないのでしたら、最も上手くいくsmoothing_functionでBLEUを測定すれば良いことになります…これはアリなのでしょうか?…
最後に
次回はbeam_searchをスクラッチから実装してみる記事を上げます。
精度を上げる方法をいくつか紹介して、この記事の終わりとします。
1.入力データを反転する
2.attentionをモデルに組み込む
3.stop_wordを用いる。
4.アンサンブル
5.層を深くする(その際、skip connectionを使うことを忘れないように)
6.Embedding層と全結合層の重みを共有する
7.Transformerにモデル変更
8.ハイパーパラメータ(ユニット数や学習率やバッチサイズ)をいじる。
ネットで検索すればいくらでも見つかりそうなものを列挙しました。使ったからといって、BLEUが向上するとは限りません。
興味があれば、Google先生に聞いてみてください。
9番はお勧めしません。ハイパーパラメータ(ユニット数や学習率やバッチサイズ)の数が多すぎて、キリがないからです。9番は最後の手段に取っておいた方が良いです。時間が惜しいので‥
ちなみに、自分はいくつかのモデルを用意して、交差検証を行い、最も上手くいったモデルで細かくハイパーパラメータのチューニングを行なっています。
自然言語処理初心者なので、間違ったやり方などがありましたら、教えてくださると嬉しいです。