こんにちは!株式会社データミックスでエンジニアをしている丹羽です。
この度、社内用のRAGを開発する機会がありまして、Google CloudのDialogflow CXというチャットボットが簡単に作れるサービスと、RAG用のファイル保存先としてCloud Storageを組み合わせる形で、最終的にはSlack用のRAGのチャットボットが完成しました!!
RAGとは?
RAG(Retrieval-Augmented Generation)は、例えば今話題のChatGPTのようなテキスト生成技術に、特定の情報源への検索を組み合わせる技術のことです。(特定の場所に格納したファイルの情報からテキストを生成するなど)
実際に使ってみると下図のような感じで、Slackで作成したbotに対してDMで質問を投げると、Cloud Storageに保存したファイルの情報からテキストを生成して出力してくれます。
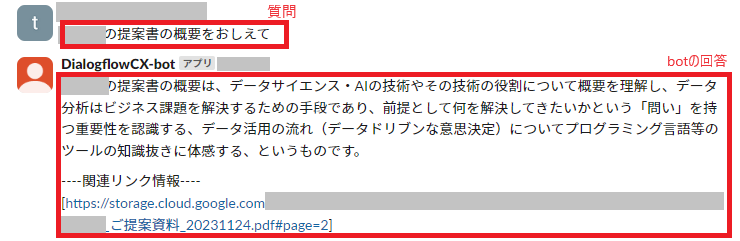
こ、これは便利!!
実際に使うと少し課題があることがわかりましたが、比較的簡単にRAGのチャットボットを作ることができたので、その点は非常によかったです。
これを使うと例えば営業系のドキュメント検索などがしやすくなり、業務改善に繋げられそうです。
ということで、今回利用したDialogflow CXの使い方などについては下記にまとめておくので、興味がある方はぜひ参考にしてみてください!
Dialogflow CXとCloud StorageでRAGを作る方法
下記で説明しているDialogflow CXとCloud Storageを利用する際にはそれぞれ利用料がかかりますのでご注意下さい。利用料に関しては事前にGoogle Cloudの公式サイトにあるドキュメント等をご確認下さい。
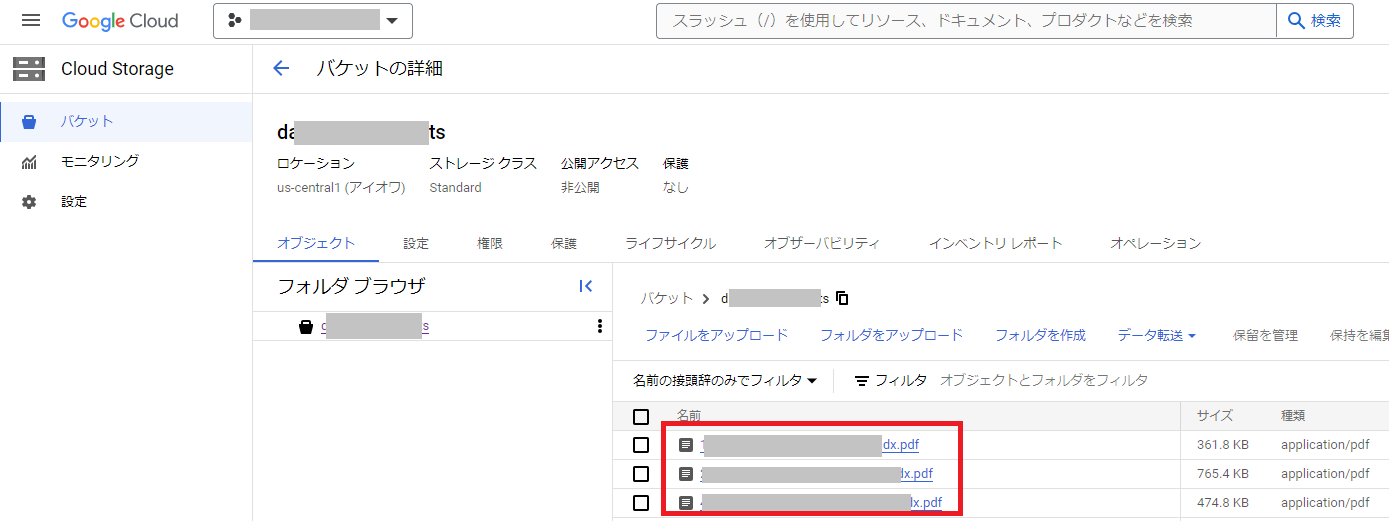
1. 事前にCloud Storageでバケットを作成してRAG用に使用するファイルを格納
Google Cloudのプロジェクト作成方法やCloud Storageの基本的な使い方についてはここでは割愛させていただきますが、事前にCloud Storageでバケットを作成し、RAG用に使用するファイルを格納して下さい。
対応しているファイル形式については、非構造化データの場合はHTML、PDF、TXTの3種類になります。
2. プロダクトメニュー「検索と会話」からアプリの作成
次にGoogle Cloudでプロダクトメニュー「検索と会話」を検索して開きます。

次に画面上の「新しいアプリ」をクリックします。
次にアプリの種類選択でチャットの「選択」をクリックします。
次に会社名、タイムゾーン、エージェント名を入力し、「続行」をクリックします。
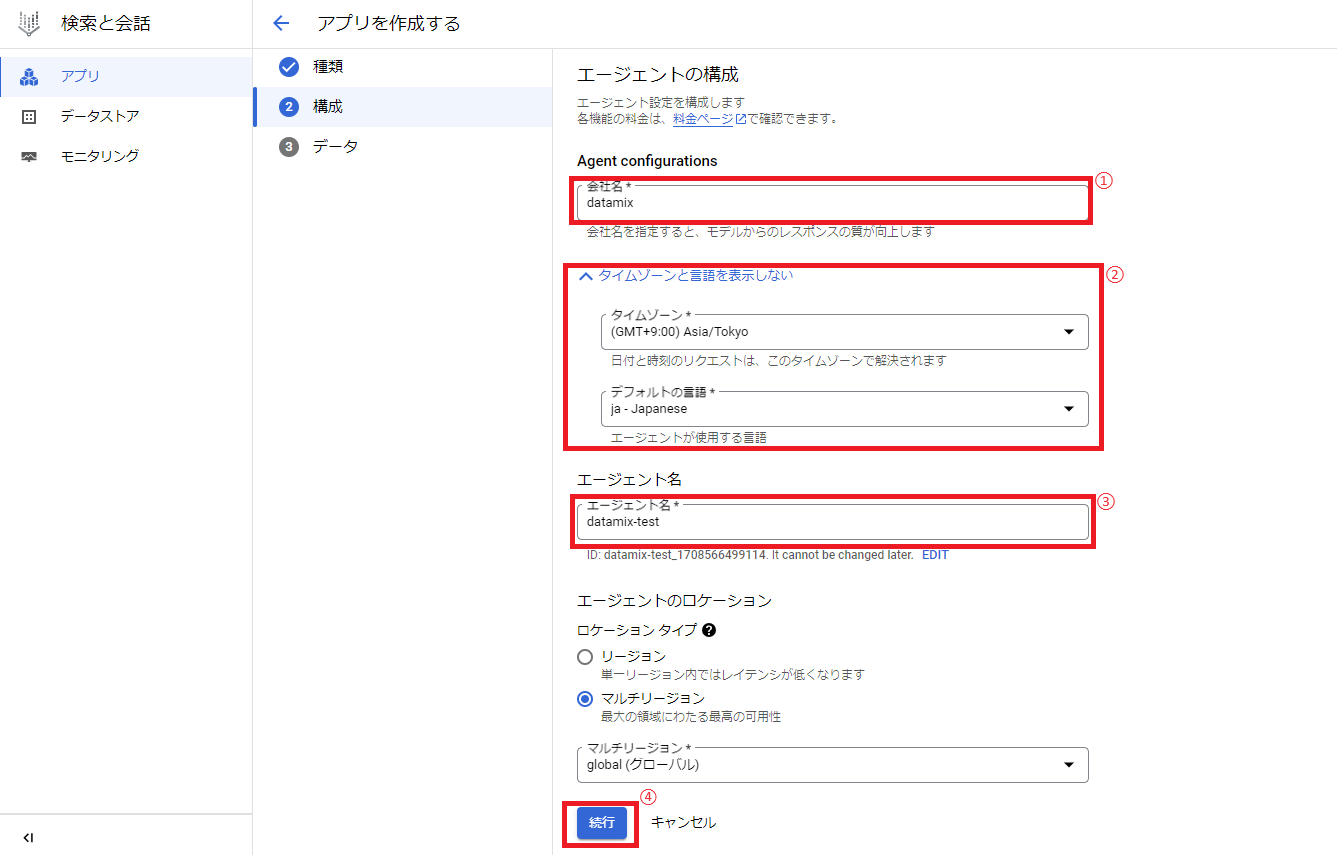
次にRAG用のデータストア(検索に使うデータを貯めておく場所)を作成するため、「新しいデータストアを作成」をクリックします。
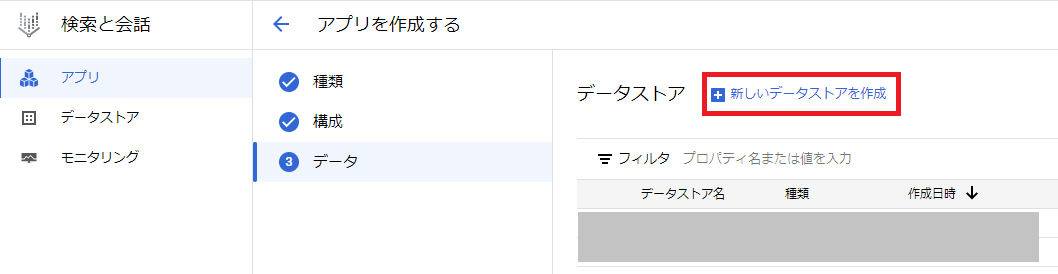
次にCloud Storageの「SELECT」をクリックします。
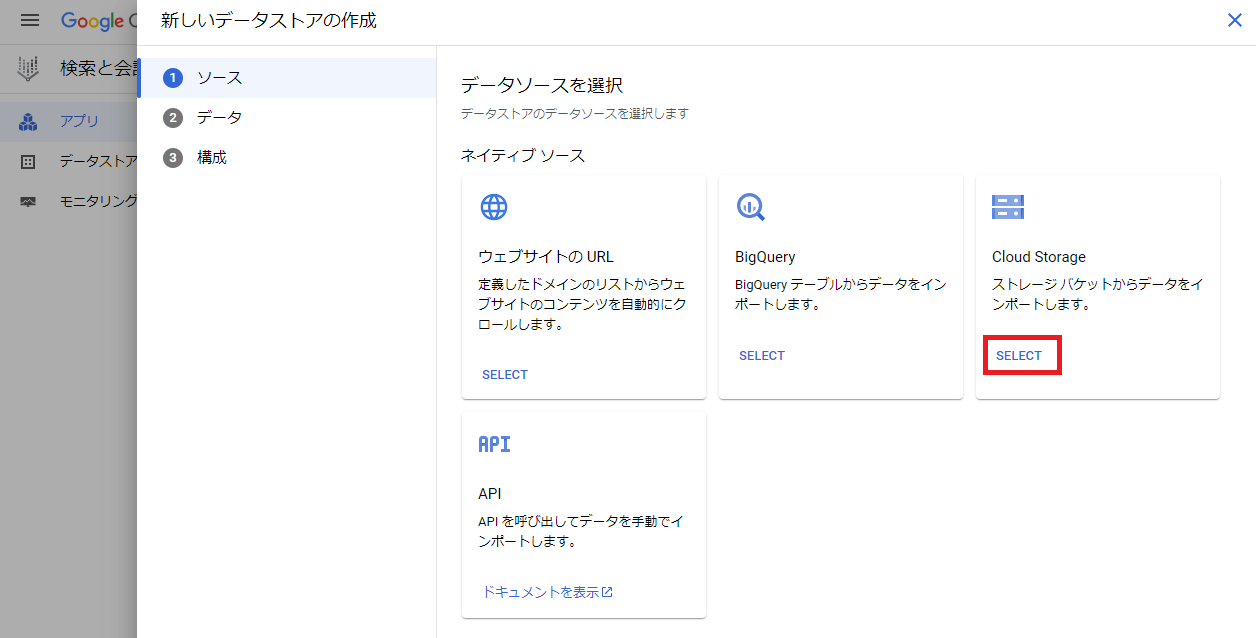
次にインポートするフォルダの選択で事前に作成しておいたCloud Storageのバケットを選択後、デフォルトで非構造化ドキュメントが選択されていることを確認し、「続行」をクリックします。
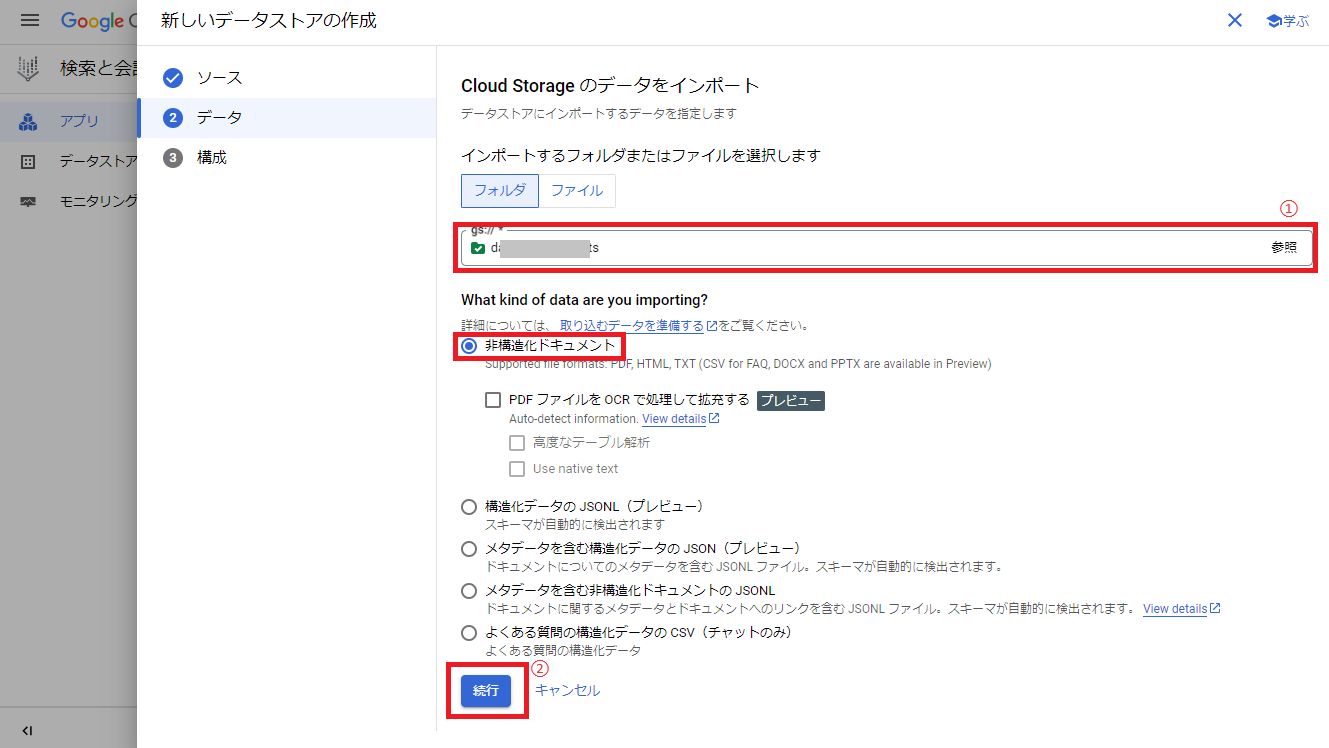
次にデータストア名を入力し、「作成」をクリックします。
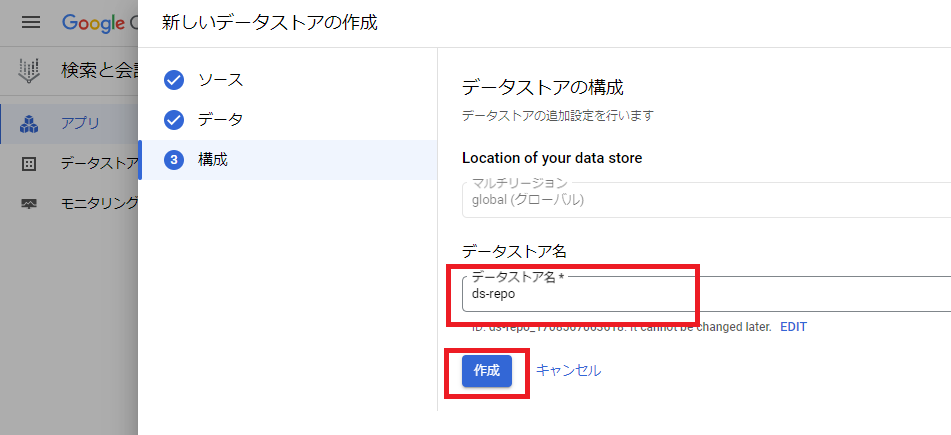
次に先程のアプリ作成画面に戻り、作成したデータストアを選択した状態で「作成」をクリックします。
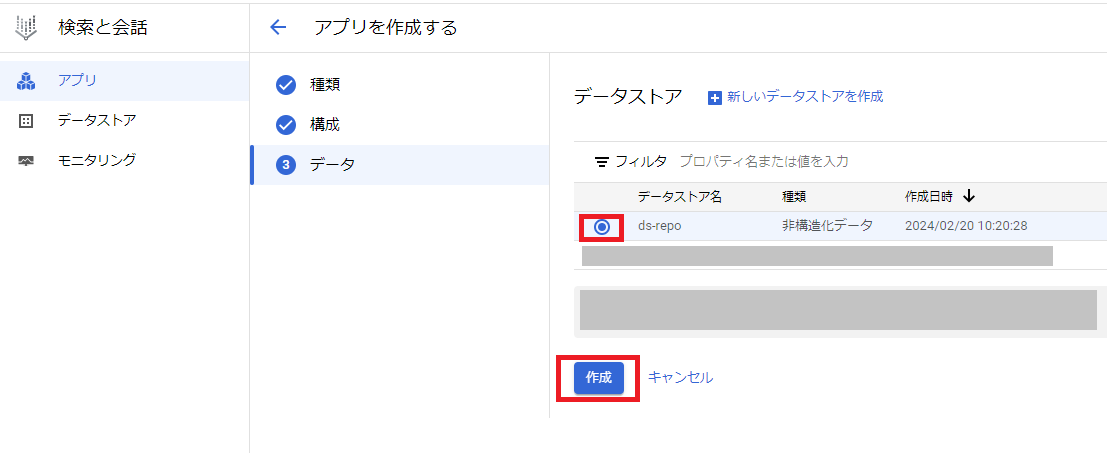
これでDialogflow CXのアプリが作成されたので、画面左の「プレビュー」をクリックして確認します。
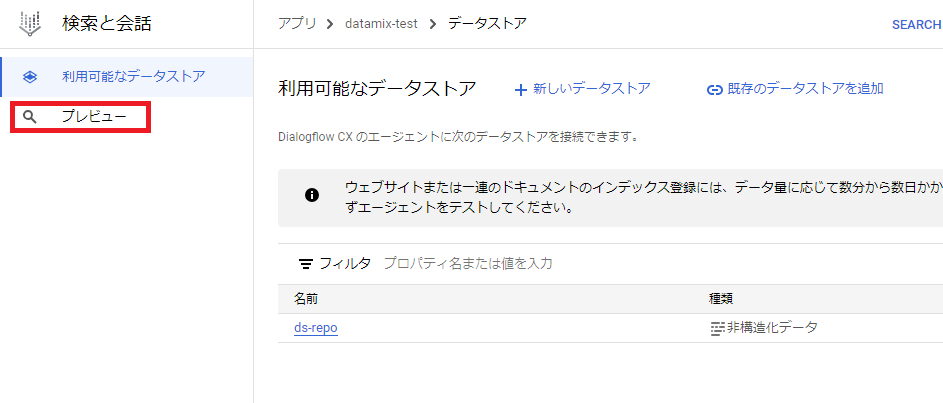
Dialogflow CXのアプリが起動して編集画面が表示されればOKです。この時点でDialogflow CXで作るRAGとしてほぼほぼ完成です!
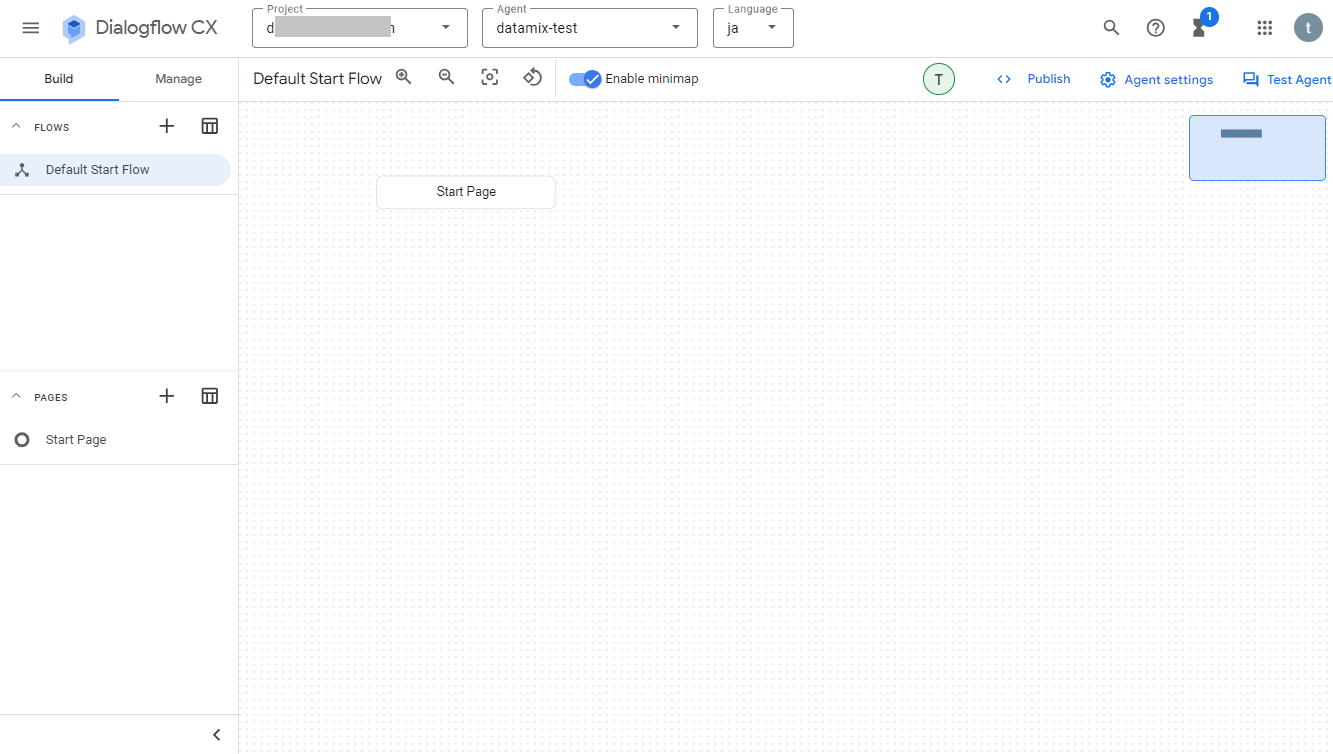
3. Dialogflow CXでテキスト生成モデルの変更
Dialogflow CXのデフォルトのテキスト生成モデルは「text-bison」系ですが、「gemini-pro」系などに変更することも可能です。
変更したい場合は、Dialogflow CXの画面右上の「Agent settings」をクリックします。
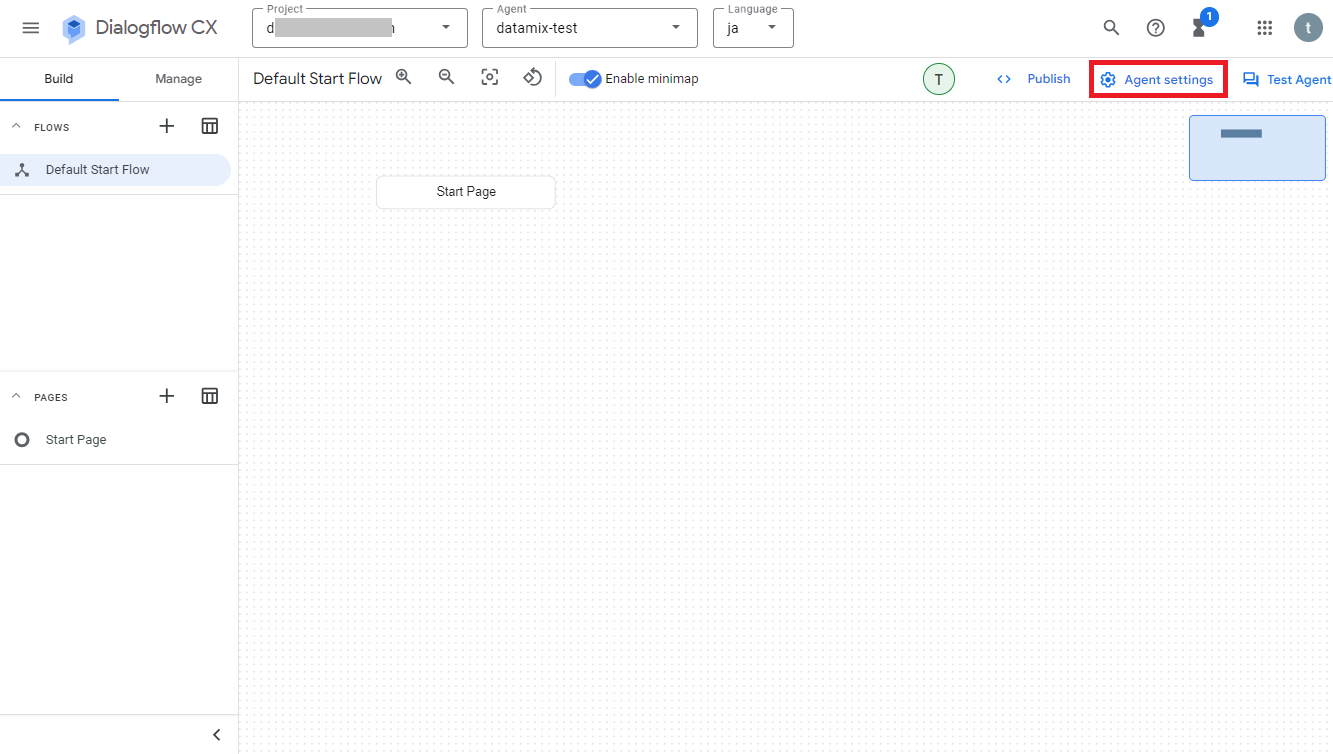
次にメニュー「Generative AI>Generative Agent」をクリックし、select generative modelのリストから使用したい生成モデルを選択します。
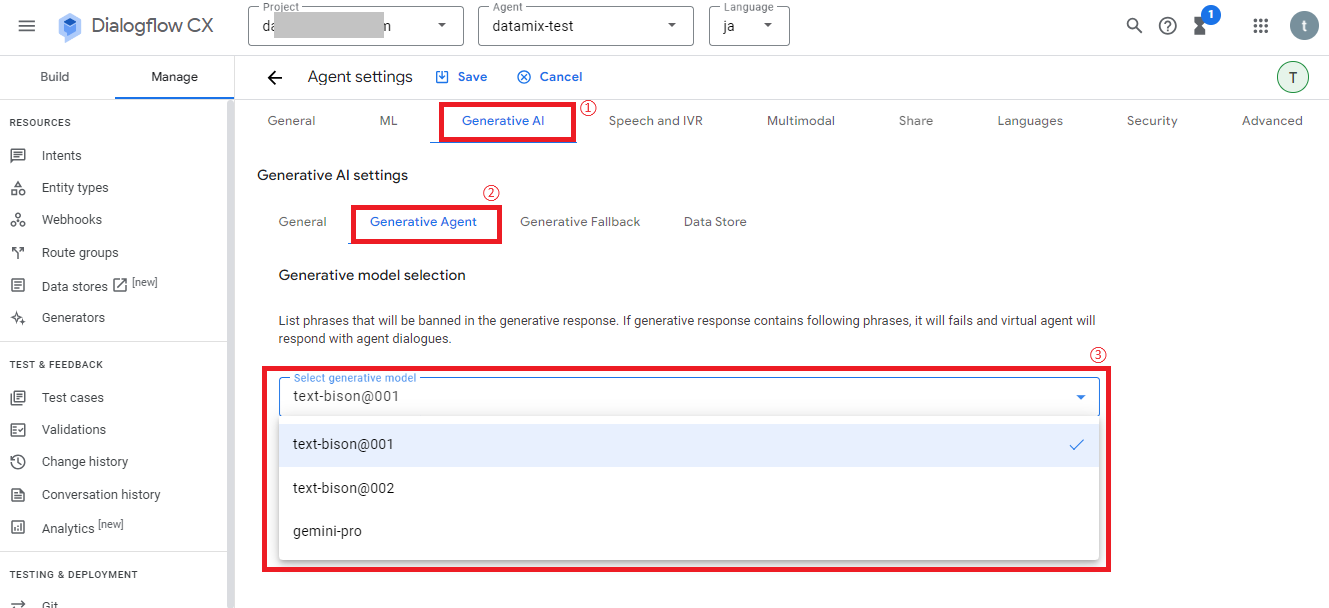
※2024年2月時点では上図の通り3種類から選択可能でした。4月時点では「gemini-pro」が「gemini-1.0-pro-001」に名称変更されたようです。
リストから選択後、設定を反映するには画面上の「Save」をクリックして保存して下さい。
4. Dialogflow CXの基本的な使い方について
ここからはDialogflow CXの基本的な使い方について解説しておきます。
デフォルトでは「Default Start Flow」のフローが設定されており、そのフローには「Start Page」というページが付いています。画面にある「Start Page」をクリックすると、ページの設定画面が開きます。
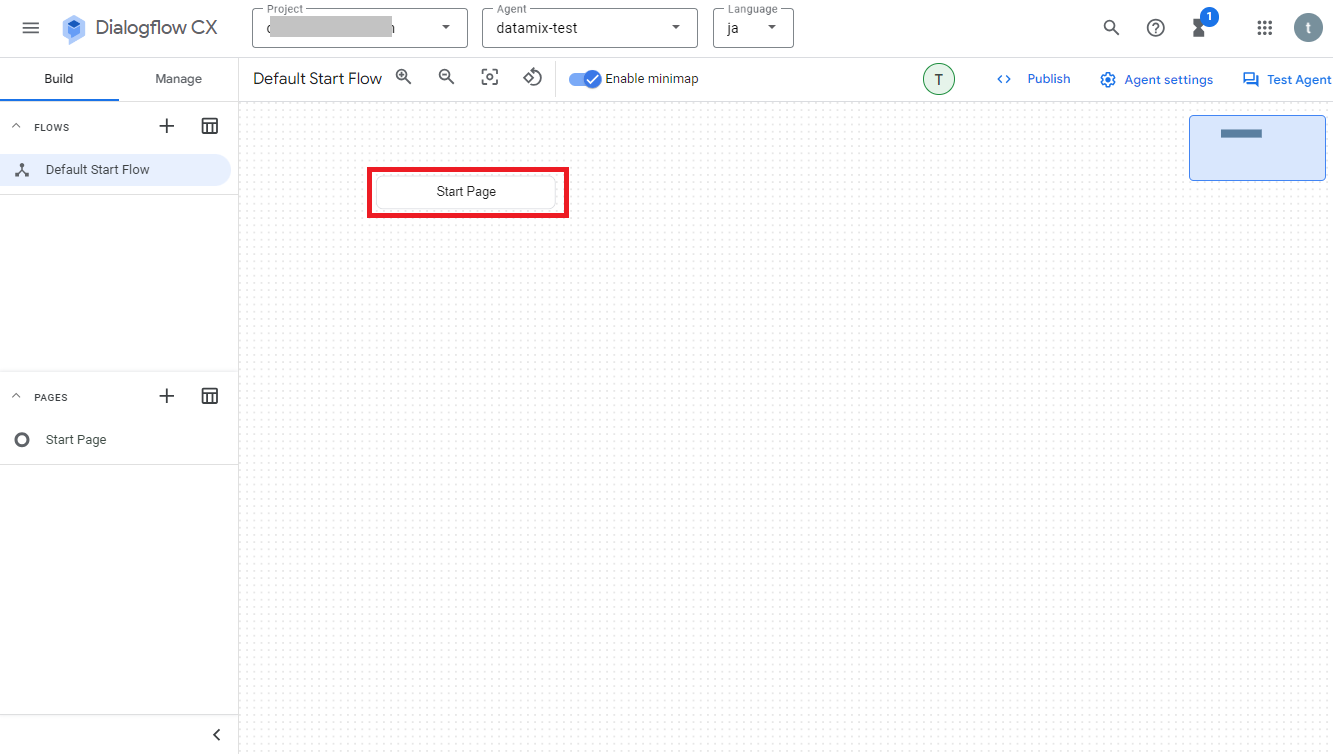
設定画面には主に3つの項目「Routes」、「Event handlers」、「Data stores」がありますが、それぞれの設定についての簡単な説明は次の通りです。
- Routes:基本的な分岐に関する応答の設定
- Event handlers:イベントを検知した場合に関する応答の設定
- Data stores:データストアを使用した場合に関する応答の設定
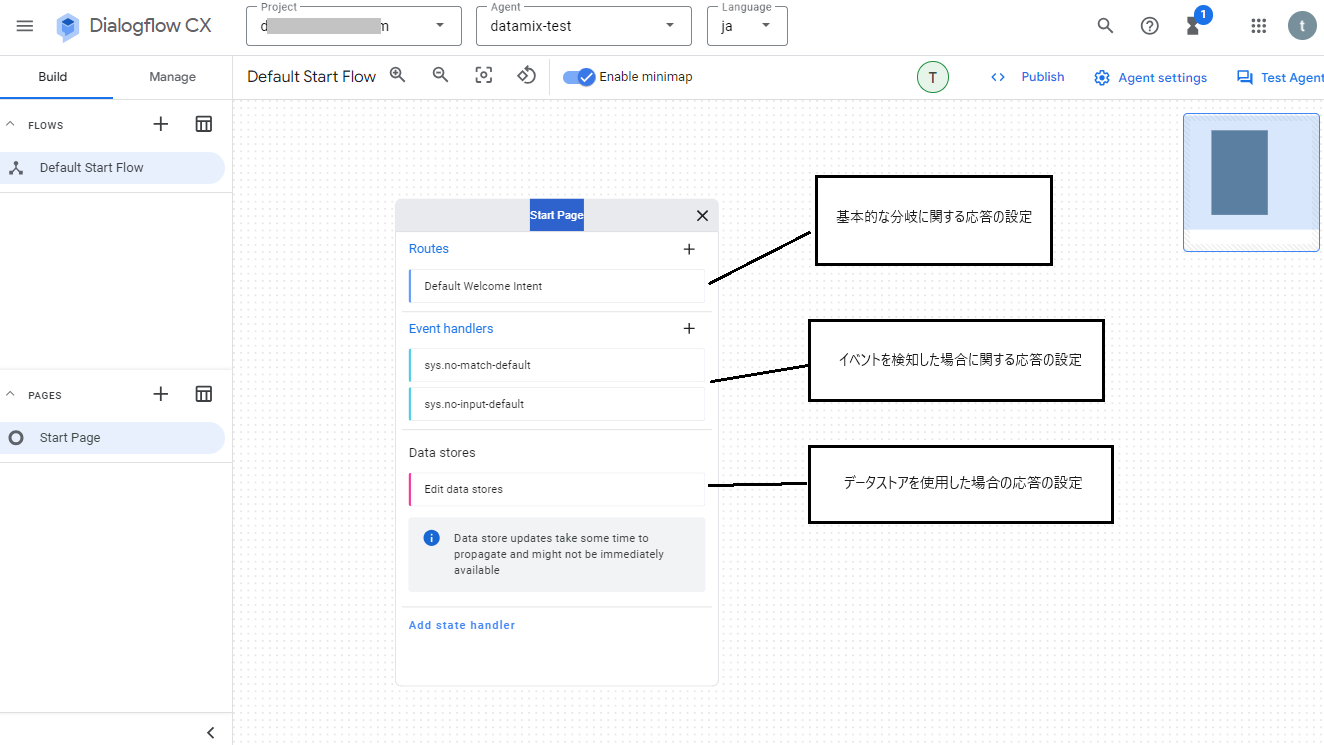
例えばRoutesにある「Default Welcome Intent」をクリックすると、画面右側に設定画面が表示されます。
設定画面のIntentの項目にはデフォルトで「Default Welcome Intent」が設定されていますが、この設定が入力されたテキストに対して、対象の単語等であるかを検知する設定になっています。
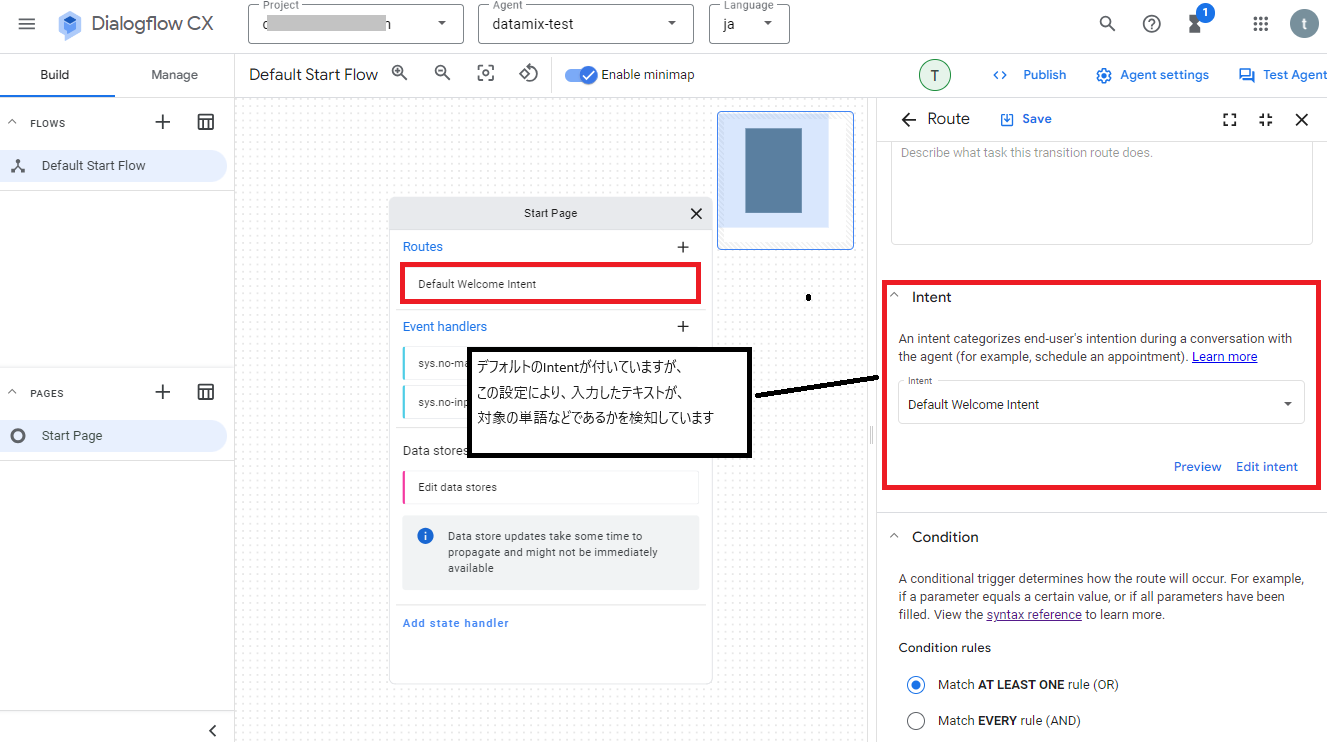
そして対象の単語等を検知した場合は、Fulfillment項目にあるAgent responsesに設定した値を返すようになっています。
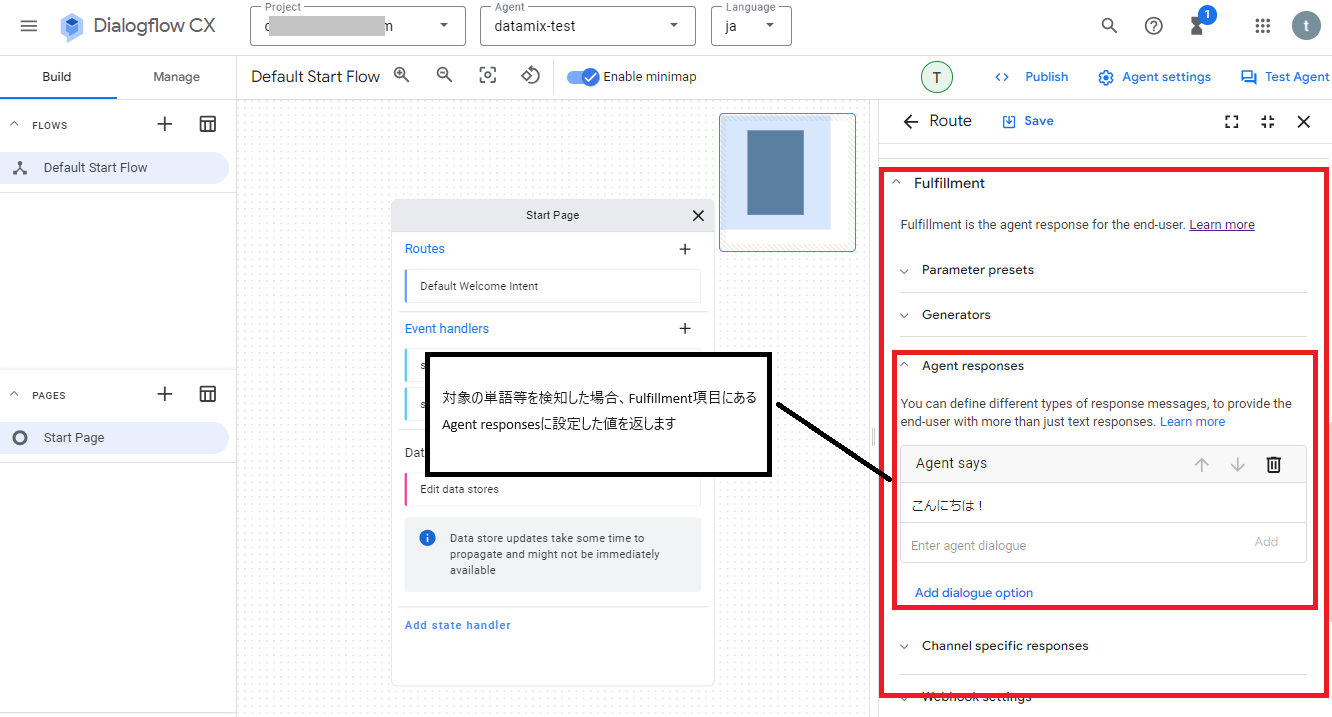
さらに処理後に別の処理を実行させたい場合は、Transition項目から遷移させたいフローやページの設定が可能になってます。
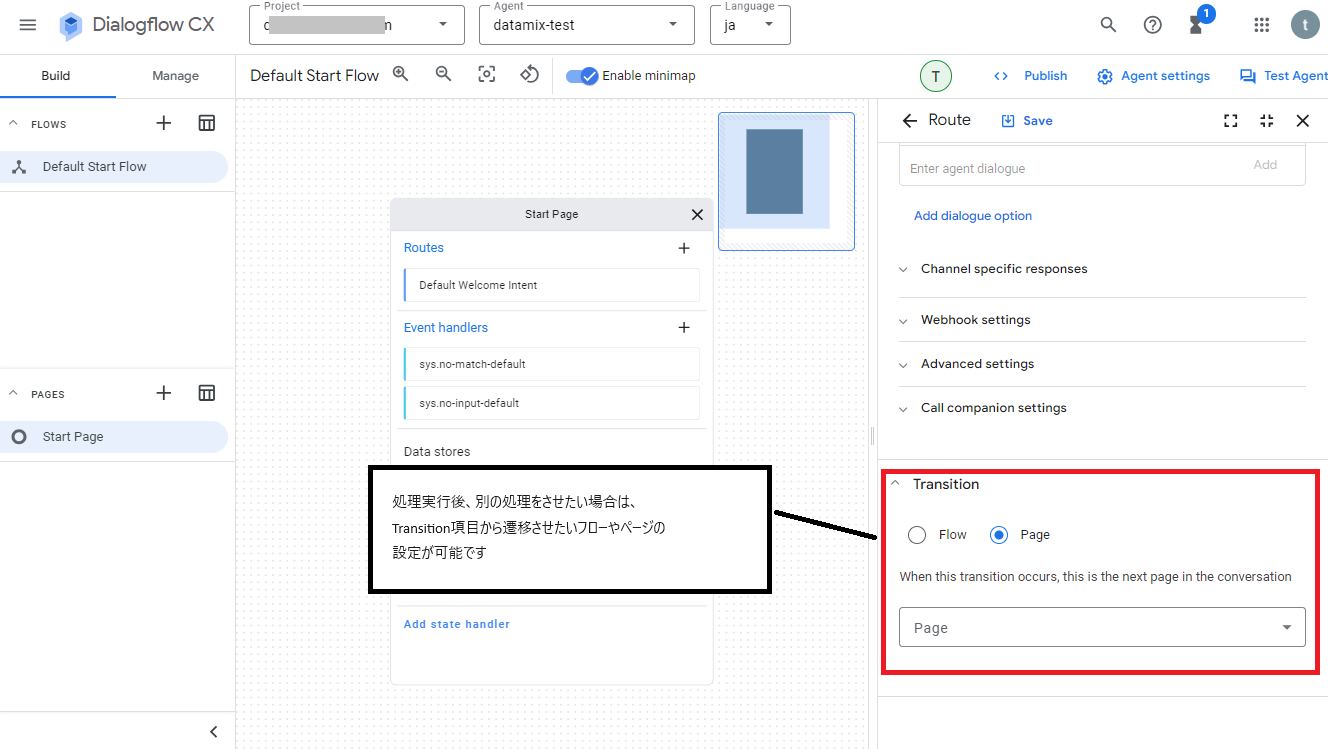
次にRAGに関係があるデータストアの設定については「Edit data stores」をクリックすると確認できますが、アプリ作成時にデータストアの設定をしたため、その内容が反映されて使えるようになっています。
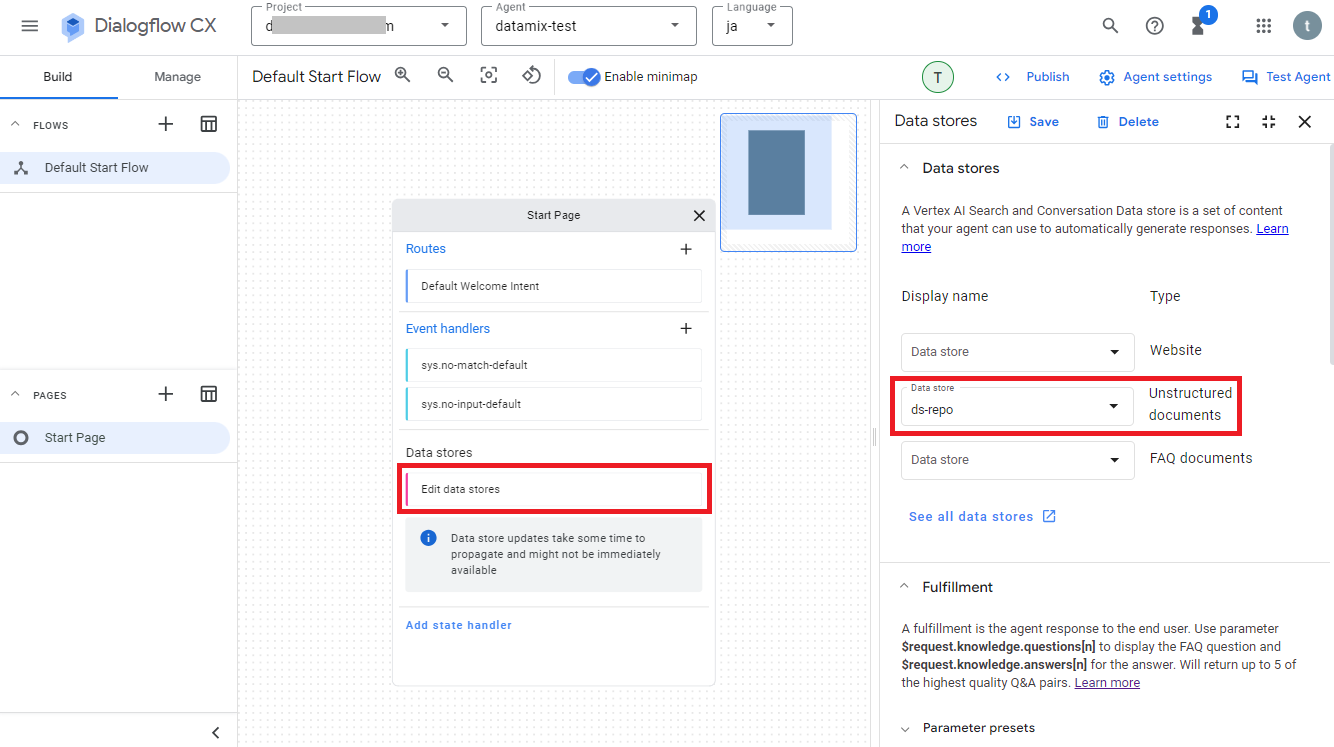
データストアの設定画面にあるAgent responsesにはデフォルトで"$request.knowledge.answers[0]"が設定されていますが、データストアの情報を元に生成したテキスト内容は、この変数に格納されるようになっています。
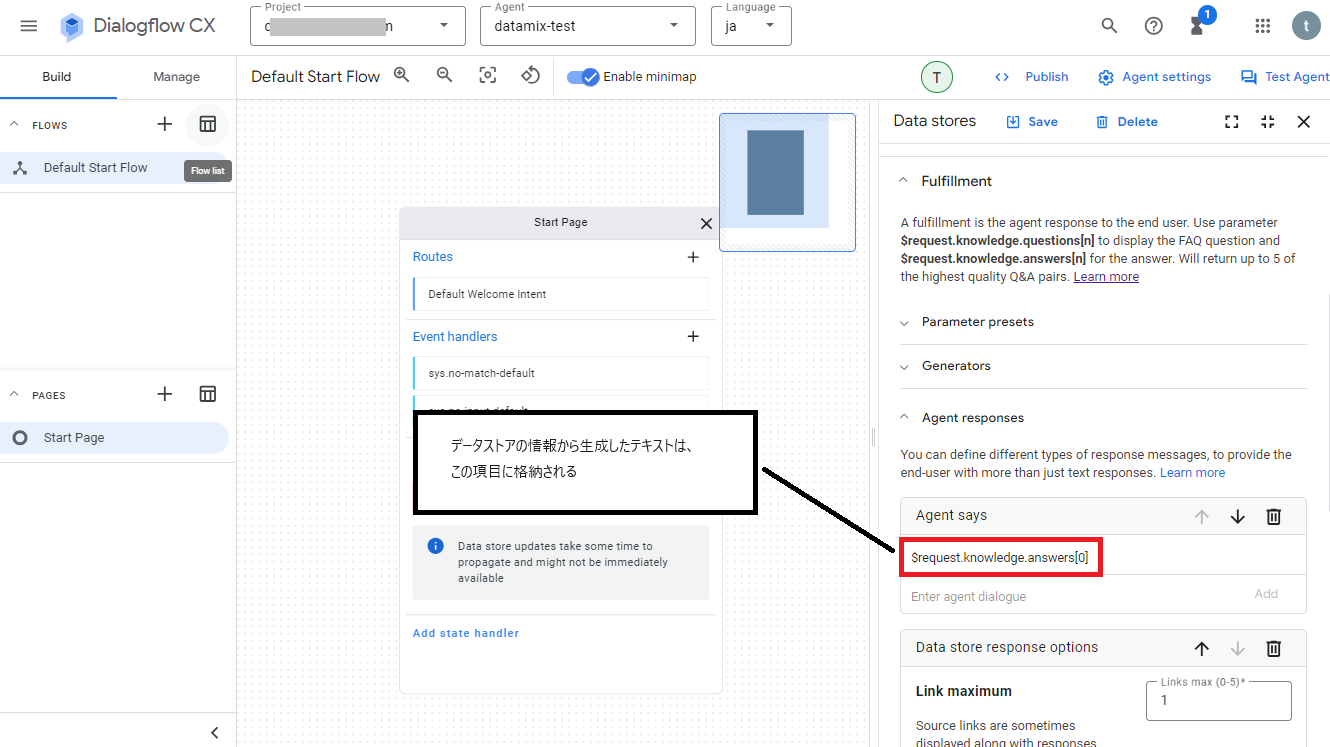
では、デフォルト設定のままでも十分使える状態なので、試しにテストを実行してみます。
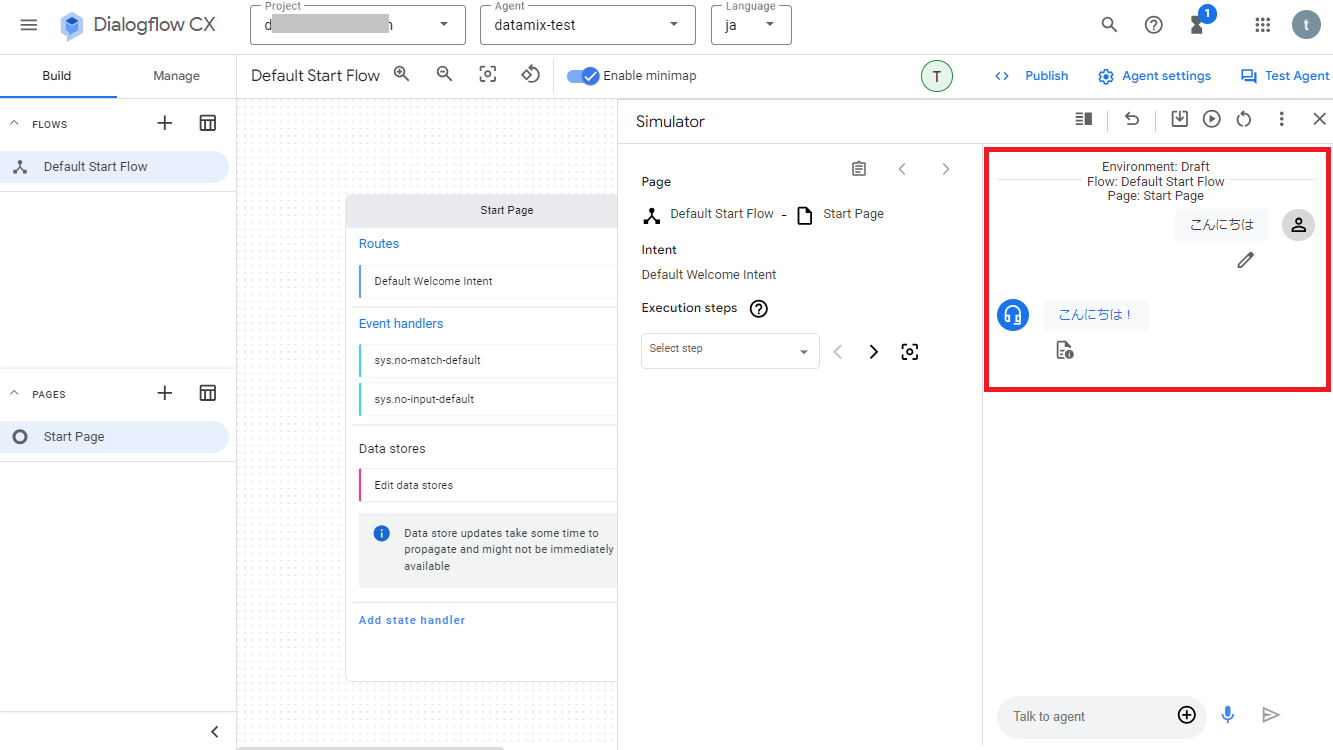
テストをするには、画面右上の「Test Agent」をクリックします。
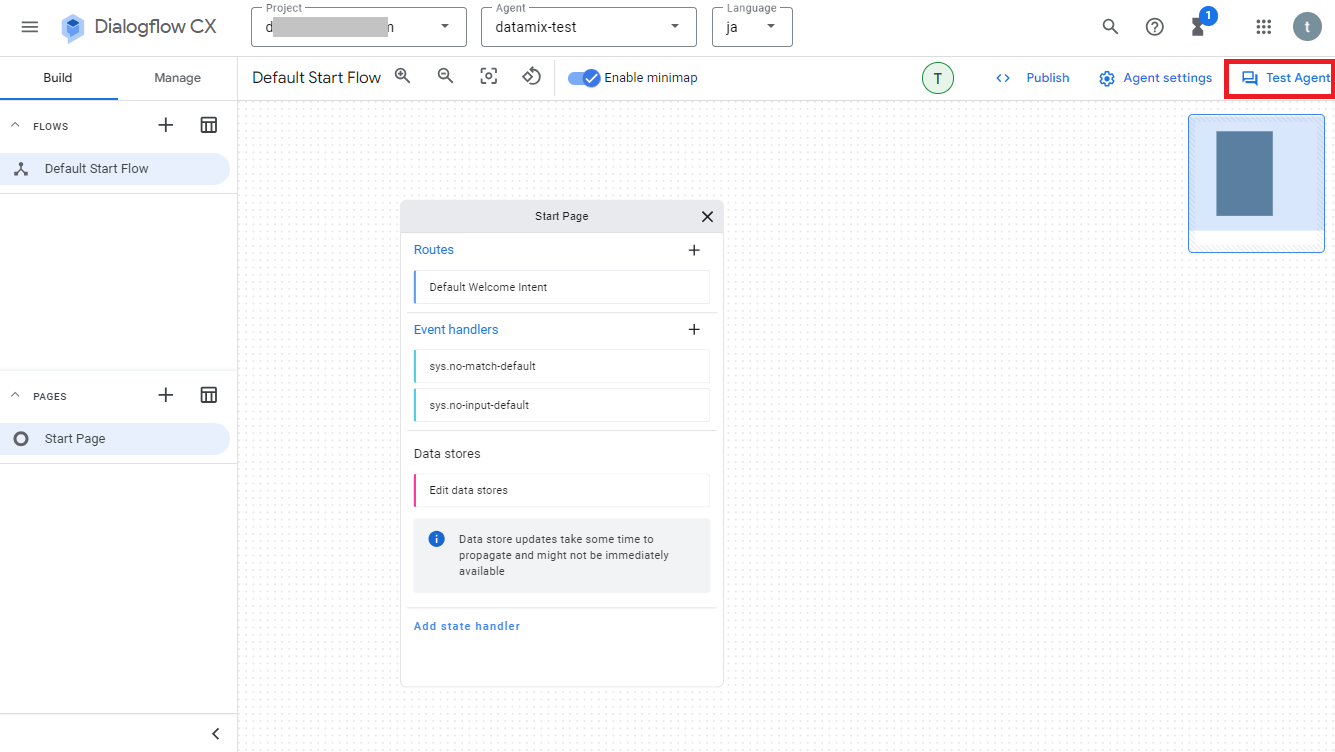
右側にテスト用の画面が表示されるので、画面下の入力フィールドにテキストを入力して実行すれば動かせます。
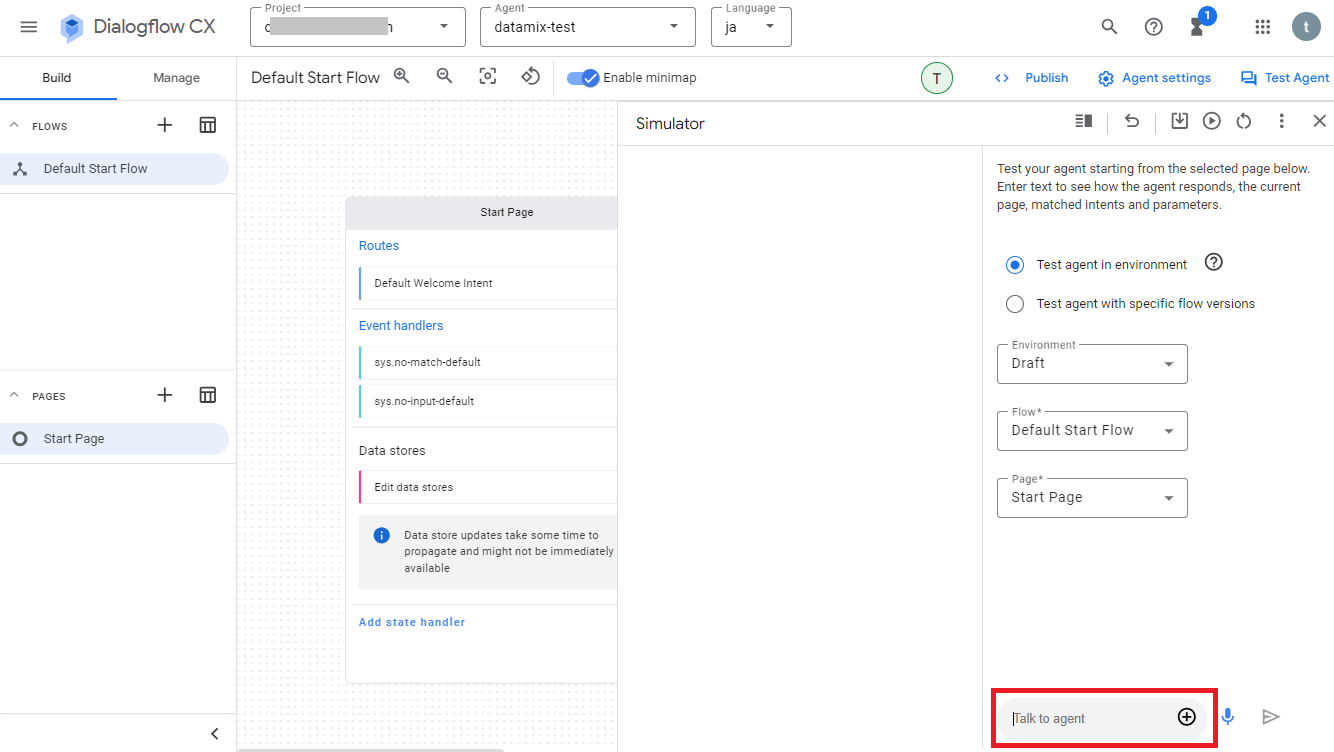
例えば「こんにちは」と入力すると、RoutesのDefault Welcome Intentの設定により検知され、そのIntentのAgent responsesに設定されているテキスト「こんにちは!」が出力されます。
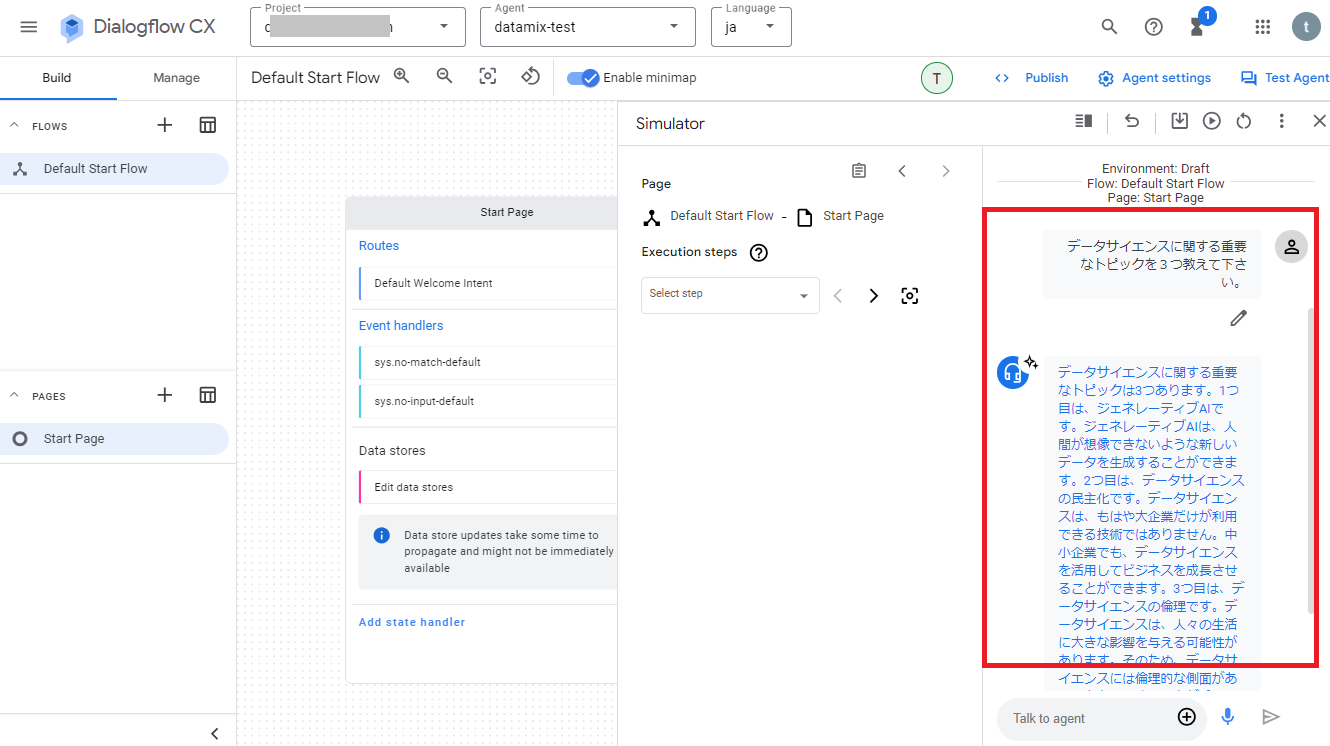
同じように今度はCloud Storageに格納しておいたファイルの内容に関する質問を入力して実行してみて下さい。上手くいくとファイルの内容から生成されたテキストが出力されます!
5. フローと環境設定のバージョン保存について
後述で記載しているように別サービスと連携させる際などには、作業中のフローや環境設定に名前を付けて保存し、バージョン管理をする必要がでてきます。
フローに対してバージョン管理をしたい場合は、画面左のメニューから「Manage > Versions」を選択し、対象のフローをクリックします。
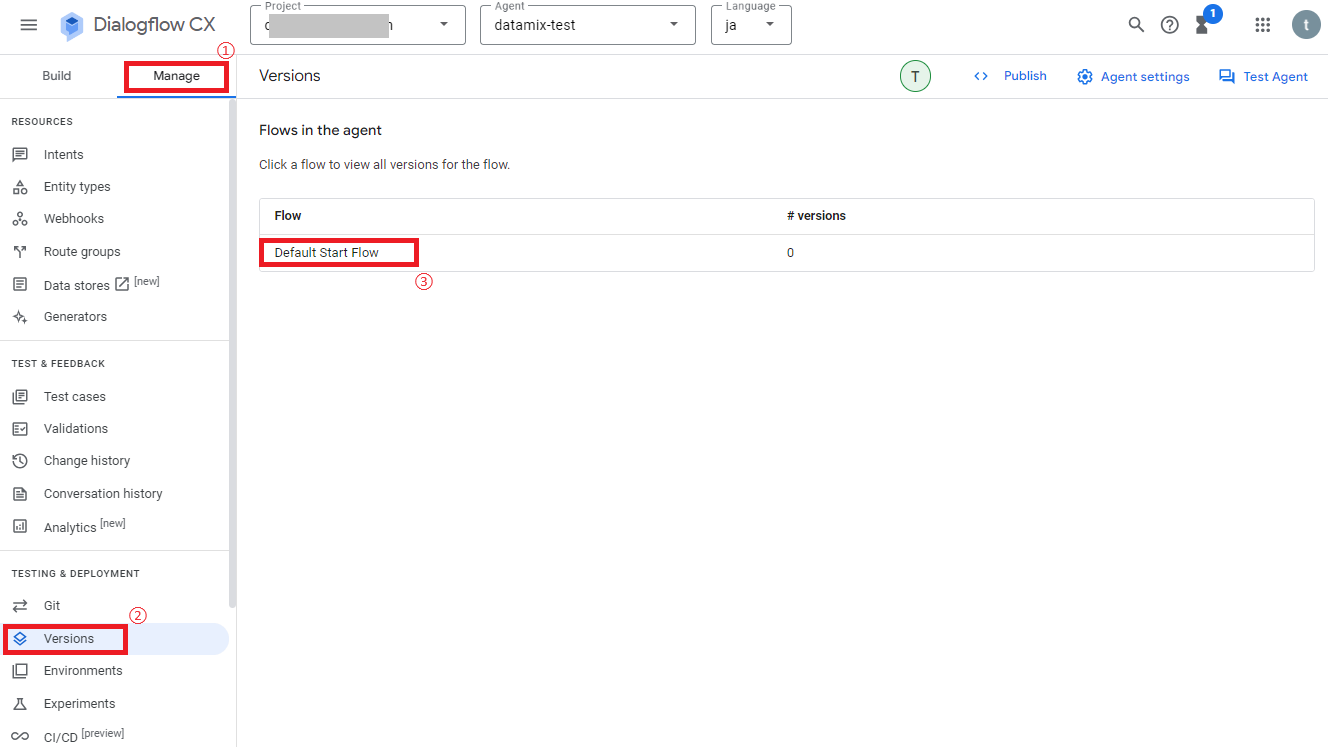
次に画面上の「+Create」をクリックします。
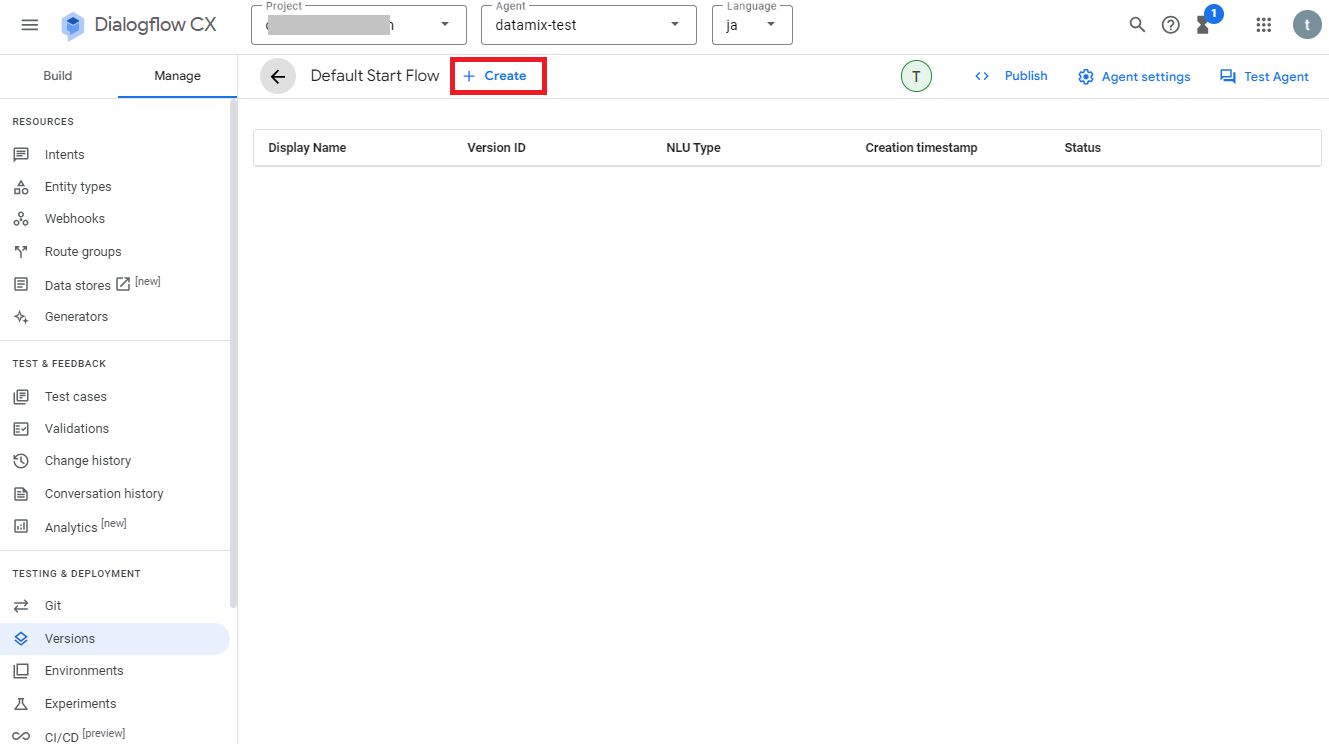
次に表示名と説明を入力し、画面上の「Save」をクリックします。
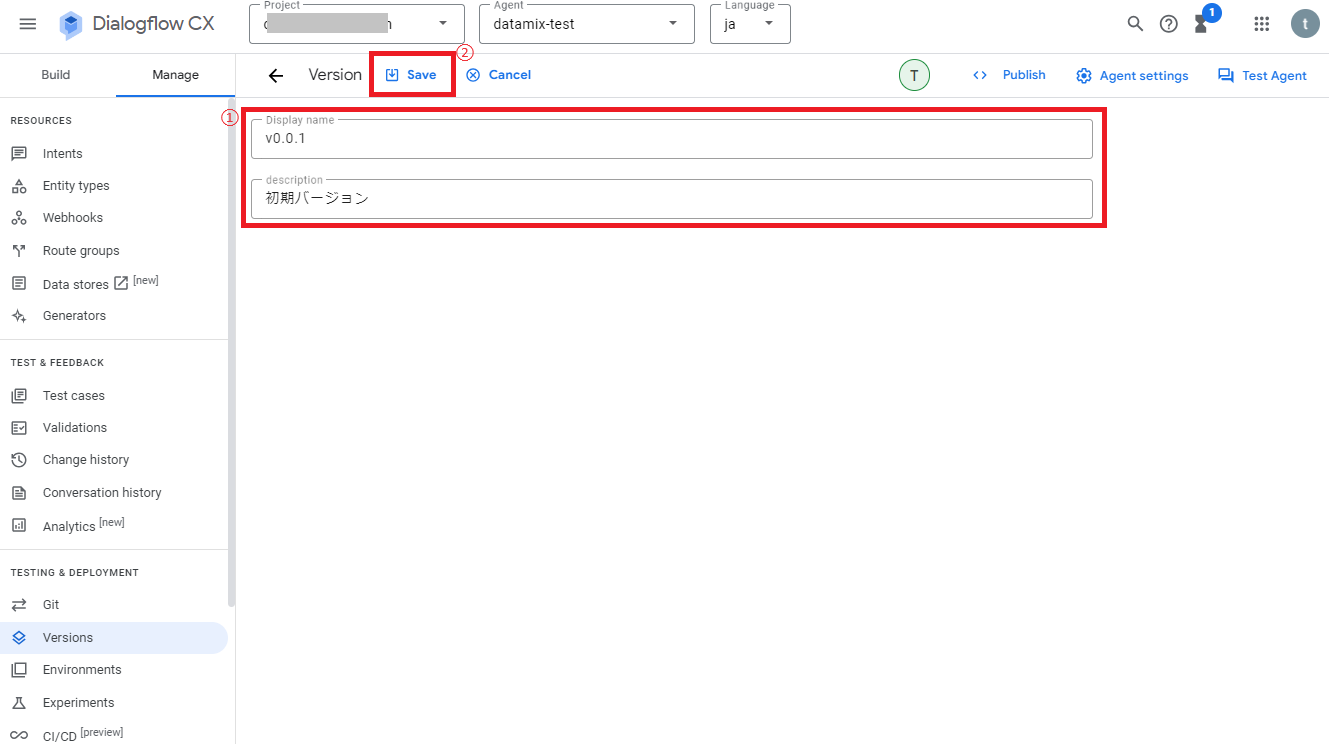
これでフローのバージョンが保存され、StatusがReadyになれば完了です。
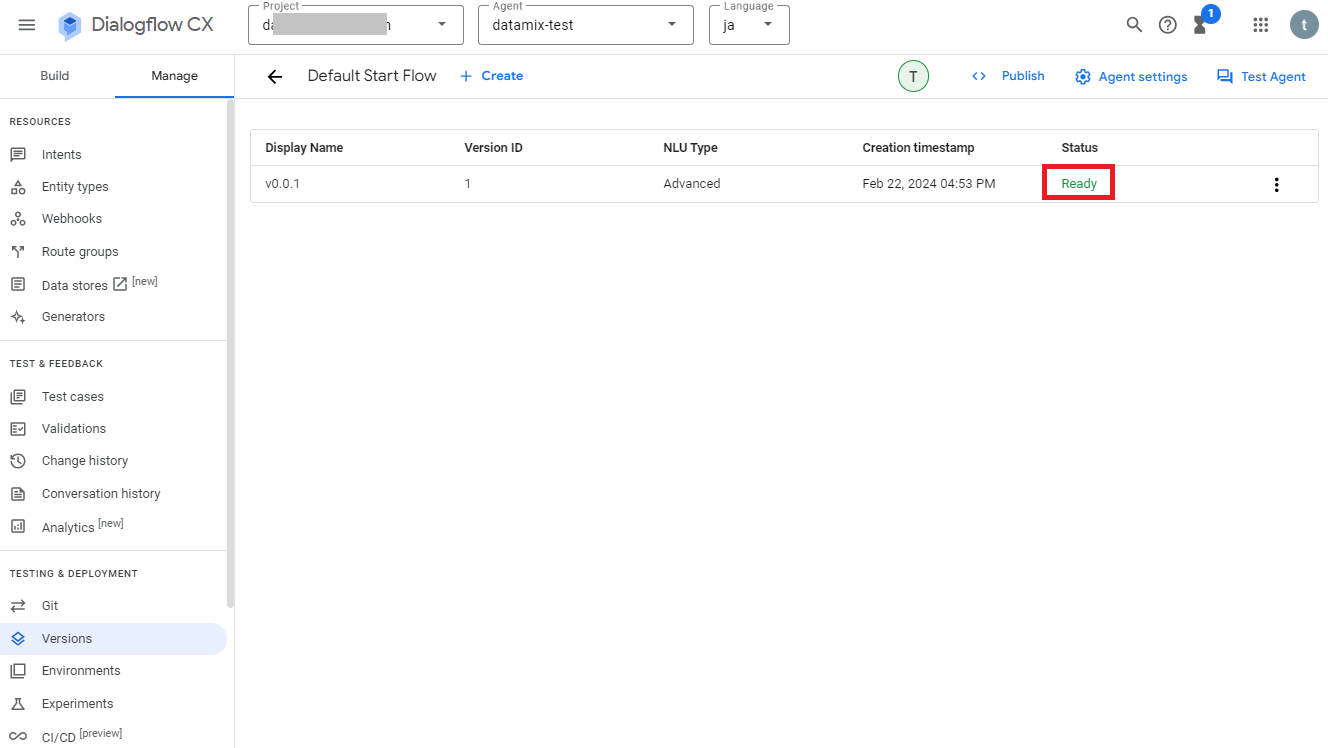
次は環境設定のバージョン管理について、作業中のデータはEnvironments「Draft」に保存されていますが、外部システムと連携させる際には新しくEnvironmentsを作成して使用します。
Environmentsを作成するには、画面左のメニューから「Environments」を選択し、画面上の「+Create」をクリックします。
次に表示名、説明、事前に保存しておいたフローのバージョンを選択し、画面上の「Save」をクリックします。
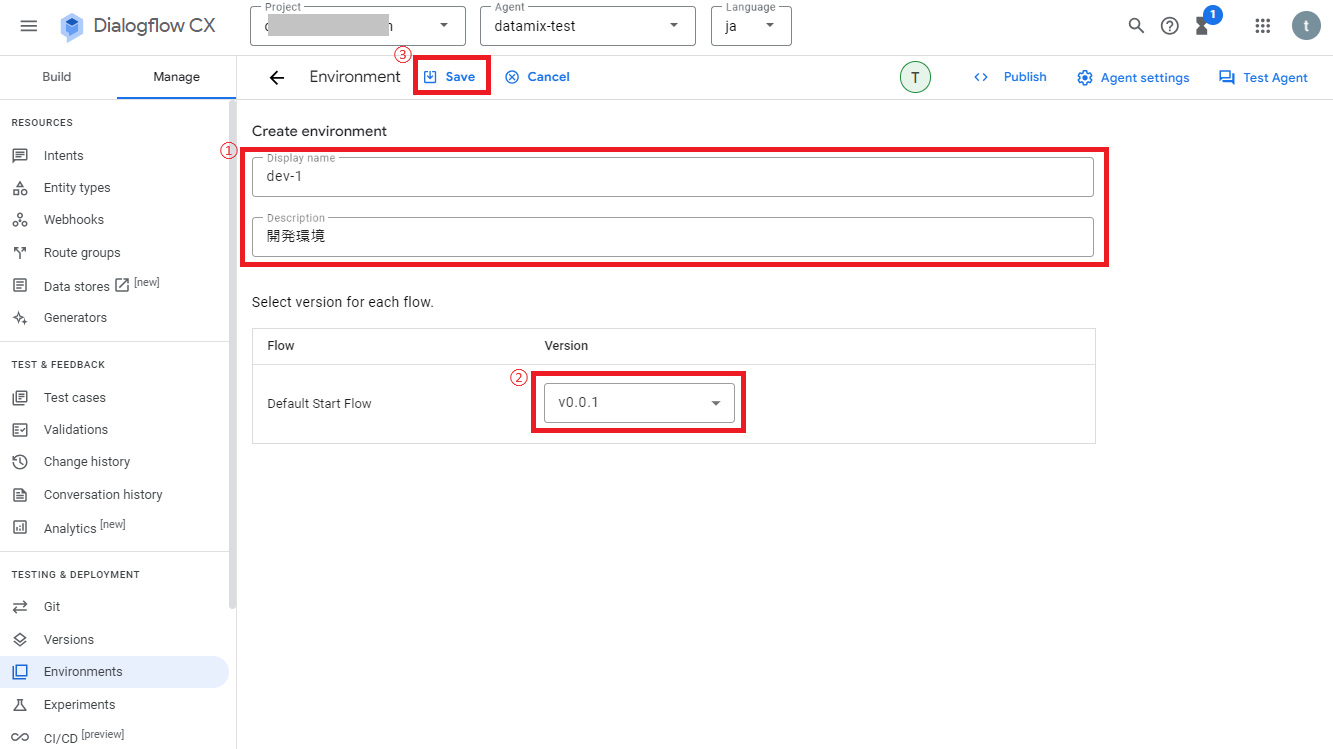
Environments一覧に新しい環境設定が追加されれば完了です。
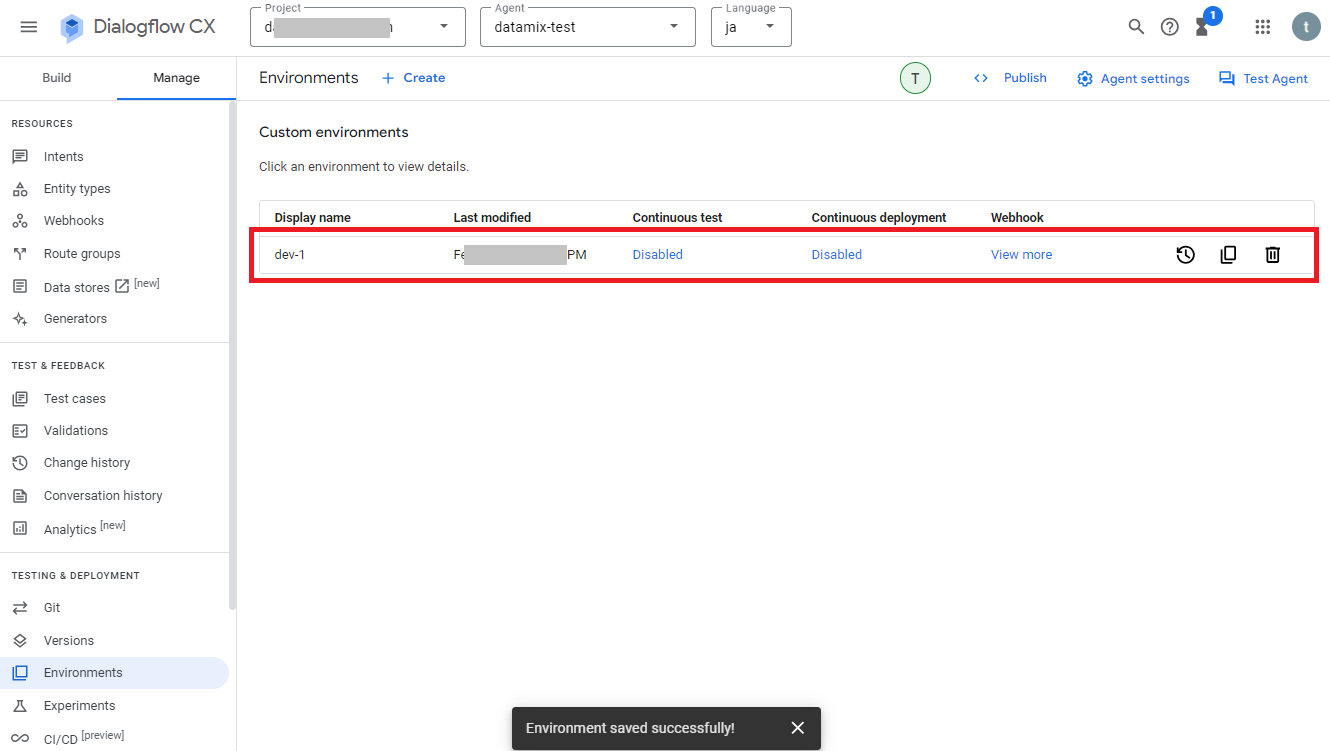
※外部システムとの連携後にDialogflow CXで変更した内容を反映させたい場合は、新しいEnvironmentsを作成してそれに切り替えることで変更内容を反映させることができます。
Dialogflow CXとSlackを連携する方法について
Dialogflow CXは様々な外部アプリケーションと連携させることが可能ですが、ここではSlackと連携させる方法について少し解説しておきます。
Slackとの連携方法については、記事「Dialogflow CX の統合に Slack と Google Chat が追加されました」を参考にさせていただいたらできたので、Slack用アプリの作成する部分などの詳細は割愛させていただきますが、事前に「https://api.slack.com/apps」でSlack用のアプリを作成後、まずはSlackアプリのメニュー「Settings>Install App」にある「Bot User OAuth Token」の値を確認してメモしておきます。
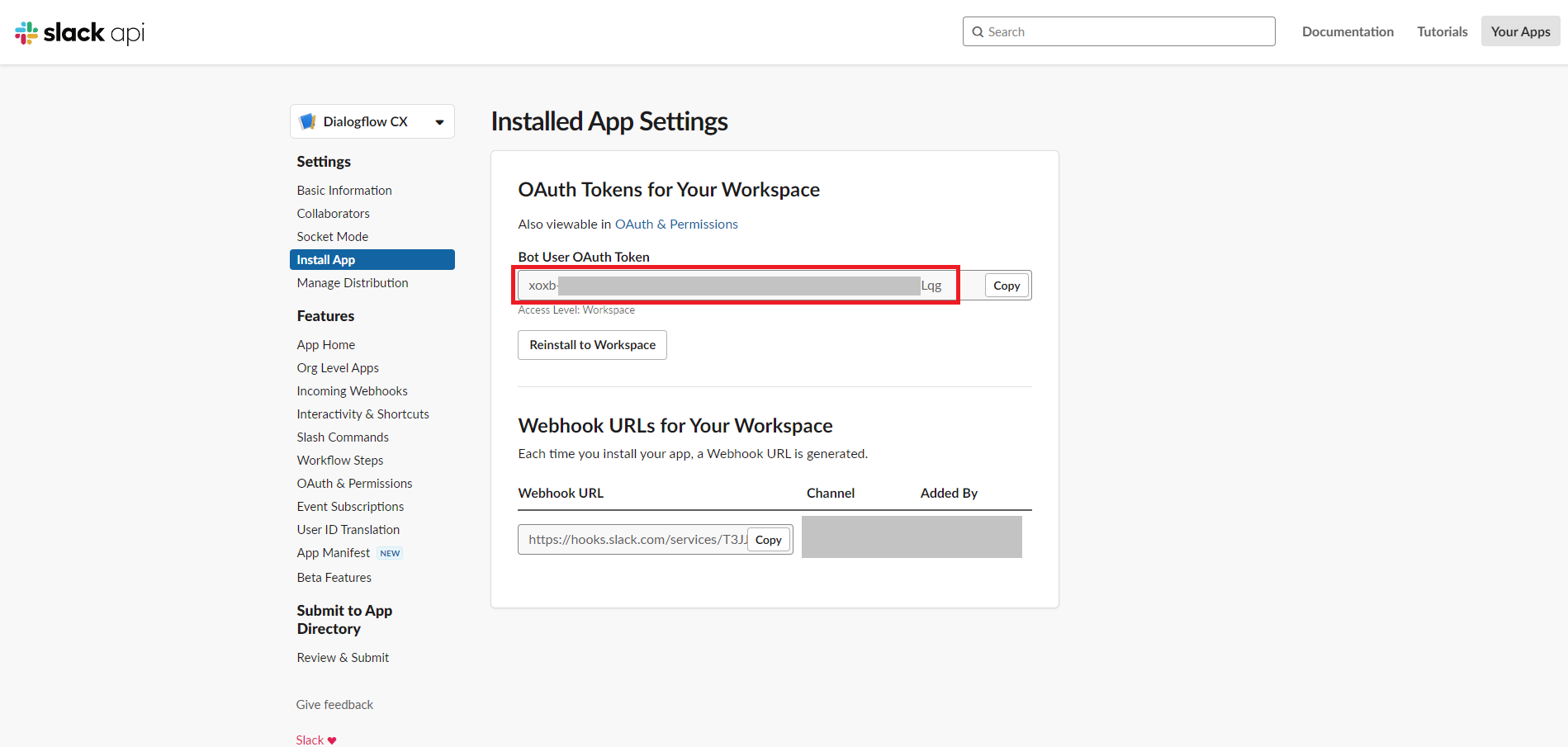
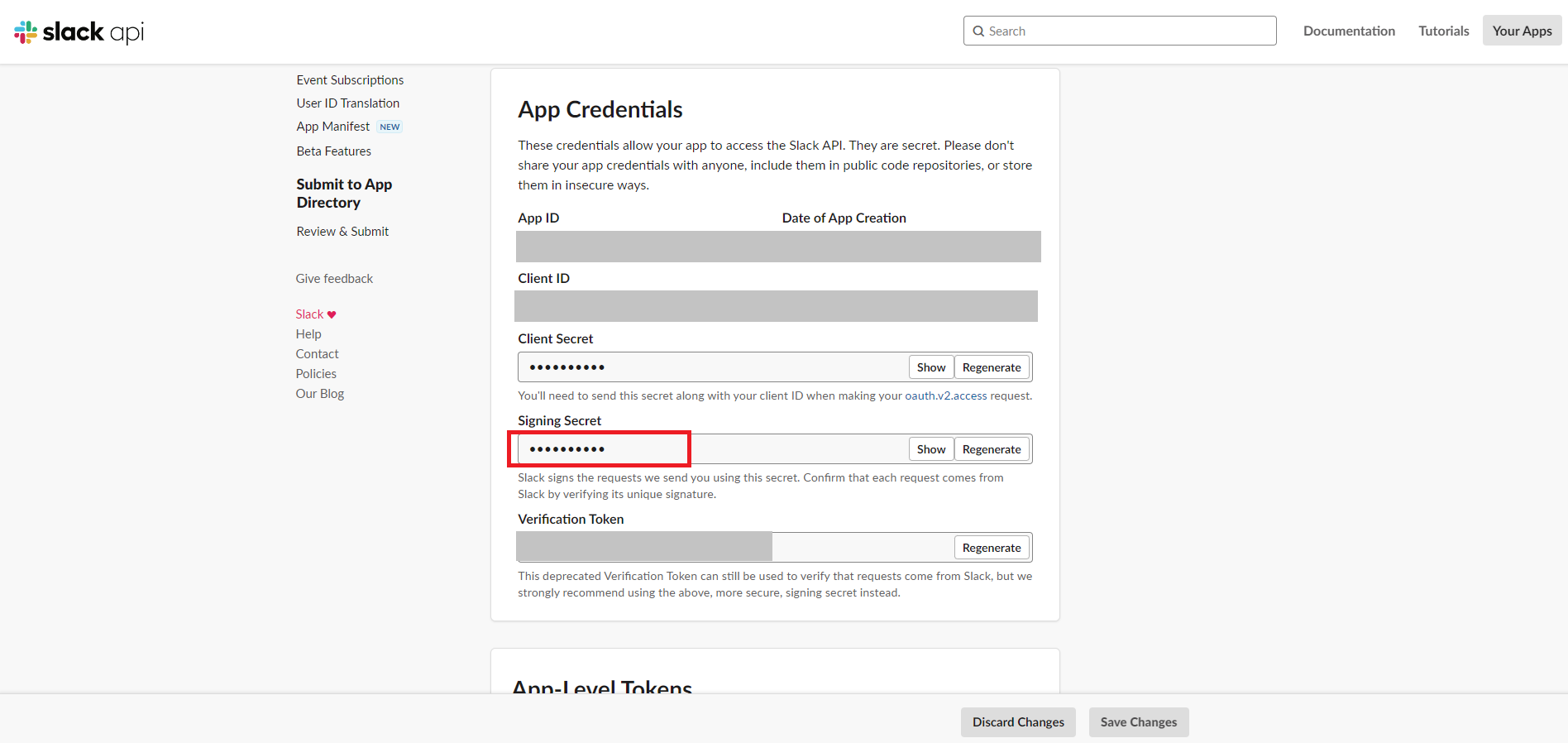
次に、Slackアプリのメニュー「Settings>Basic Information」にある「Signing Secret」の値を確認してメモしておきます。
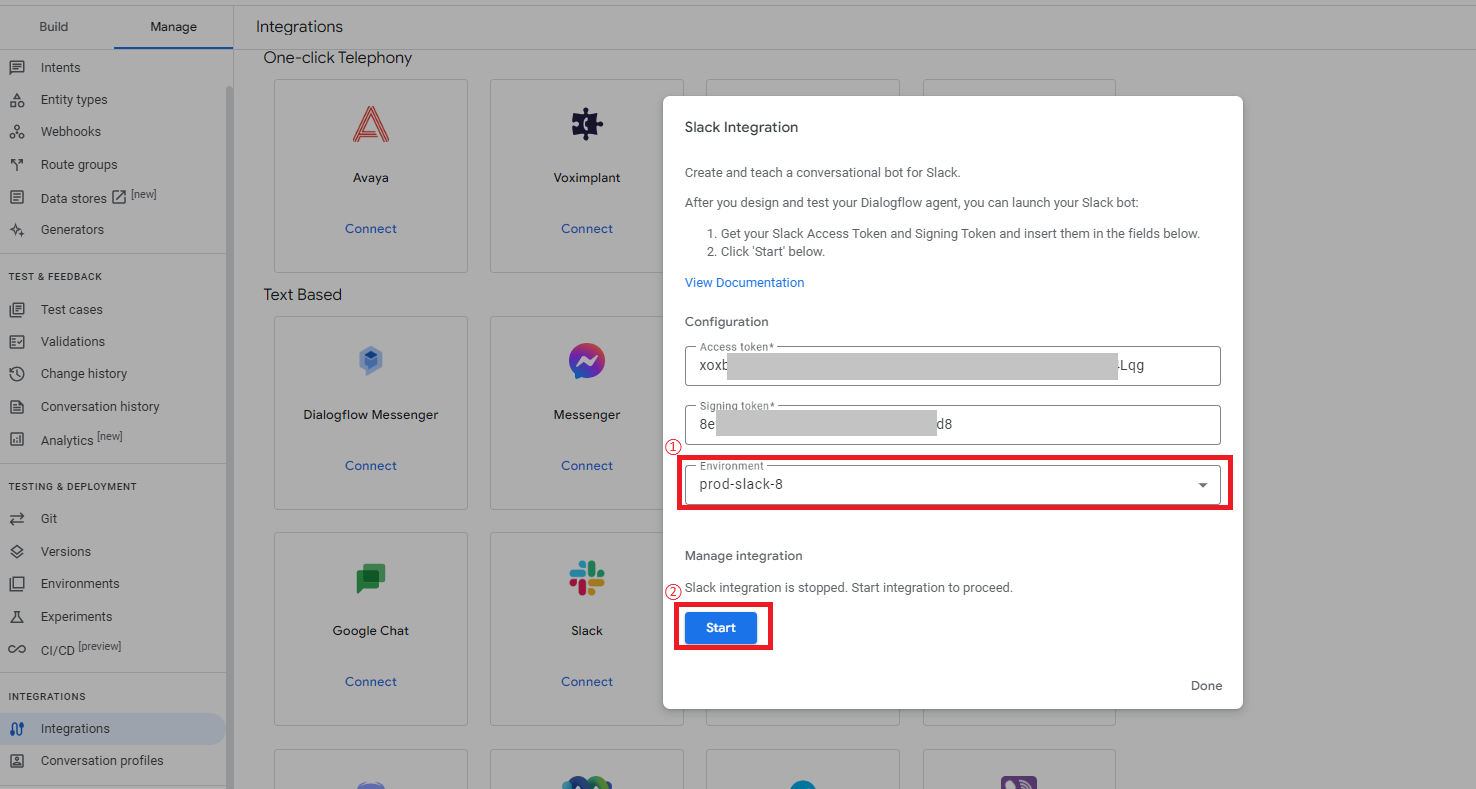
次にDialogflow CXに戻り、メニュー「Manage > Integrations」からSlackの「Connect」をクリックします。

次に設定画面が表示されるので、Slackアプリの方で確認した「Bot User OAuth Token」と「Signing Secret」の値を、「Access token」と「Signing token」にそれぞれ入力します。
そして、Environmentsは事前に作成しておいた設定をリストから選択し、最後に「Start」をクリックします。
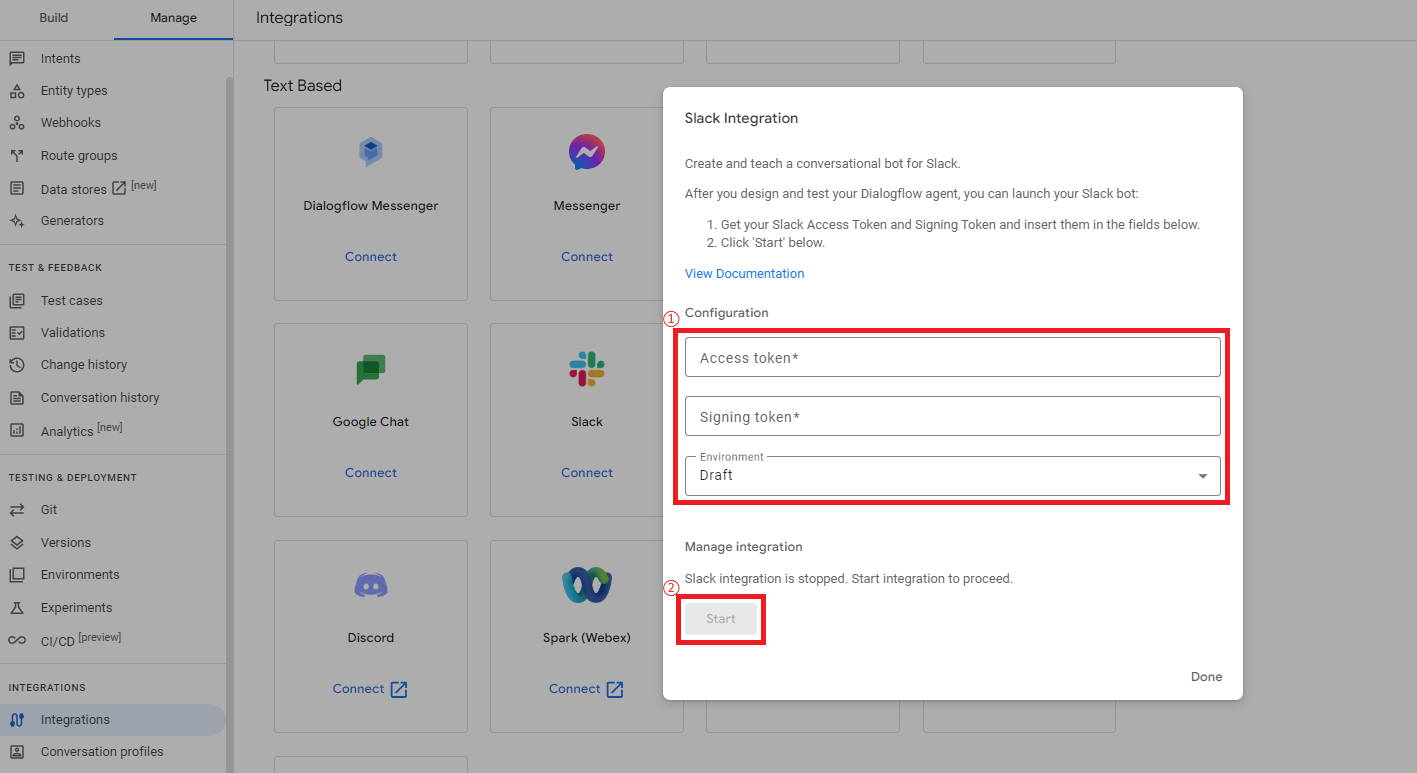
これでDialogflow CX側の接続設定が完了し、Webhook URLが表示されるのでメモします。
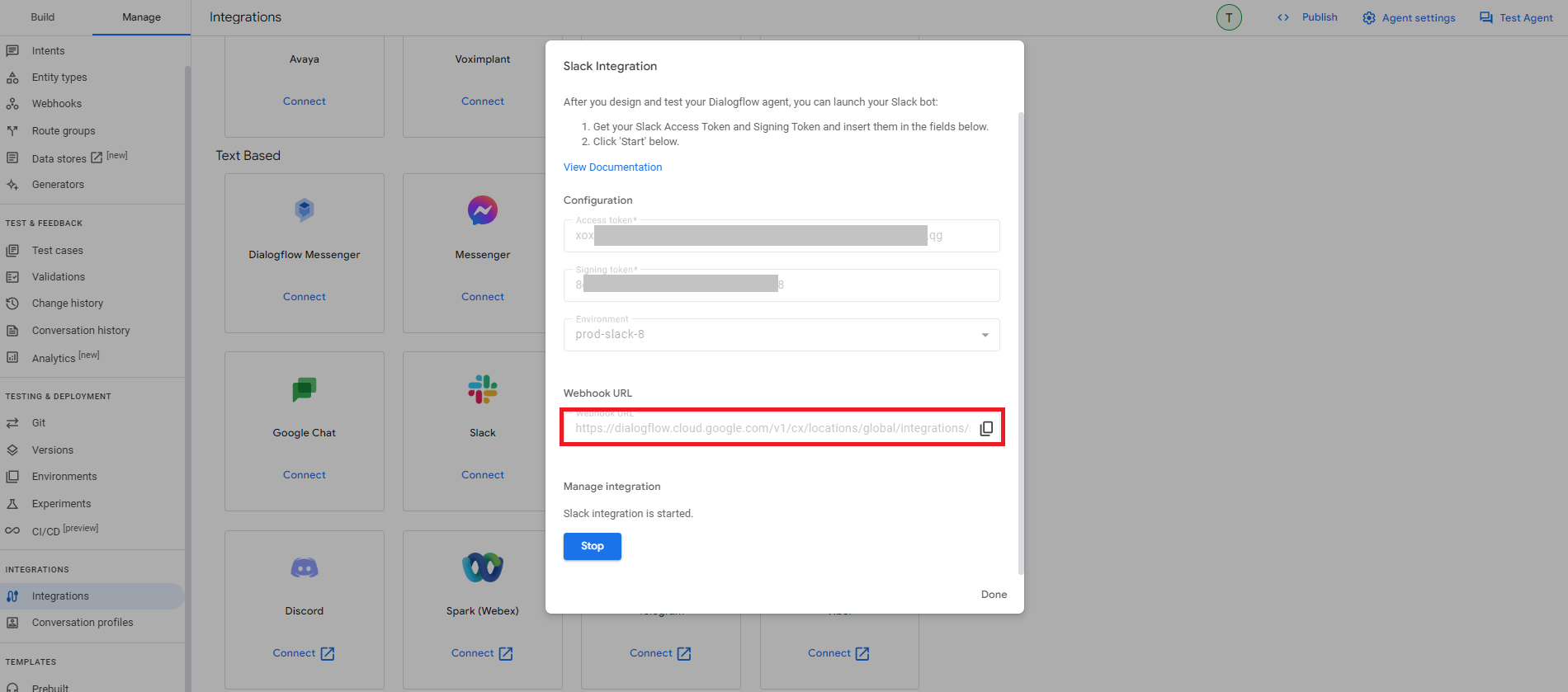
もう一度Slackアプリの設定画面に戻り、メニュー「Settings>Event Subscriptions」にあるRequest URLに上記でメモしたWebhook URLを入力後、ステータスがVerifiedになればOKなので、画面下の「Save Changes」をクリックして設定を保存します。
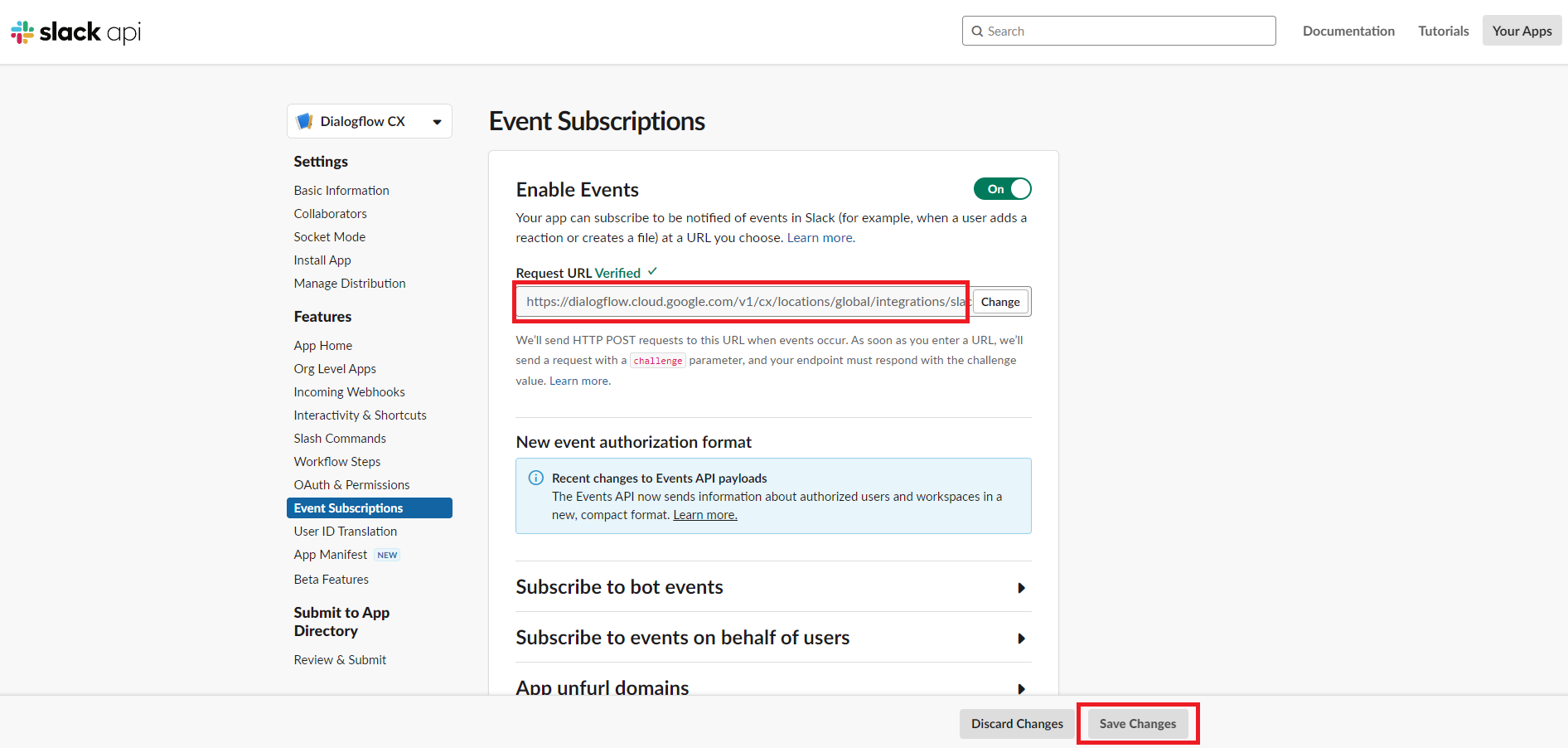
これでDialogflow CXとSlackとの連携が完了です。Slackのbotアプリに対してDMすれば動くと思うので試してみて下さい。
Slackで関連ファイルのリンク情報を出力させる方法について
Dialogflow CXでテストした際に関連ファイルのリンク情報が「Custom payload」として出力されることがありますが、これはSlackには出力されないため、Slackに関連ファイルのリンクを出力させたい場合は工夫が必要になります。
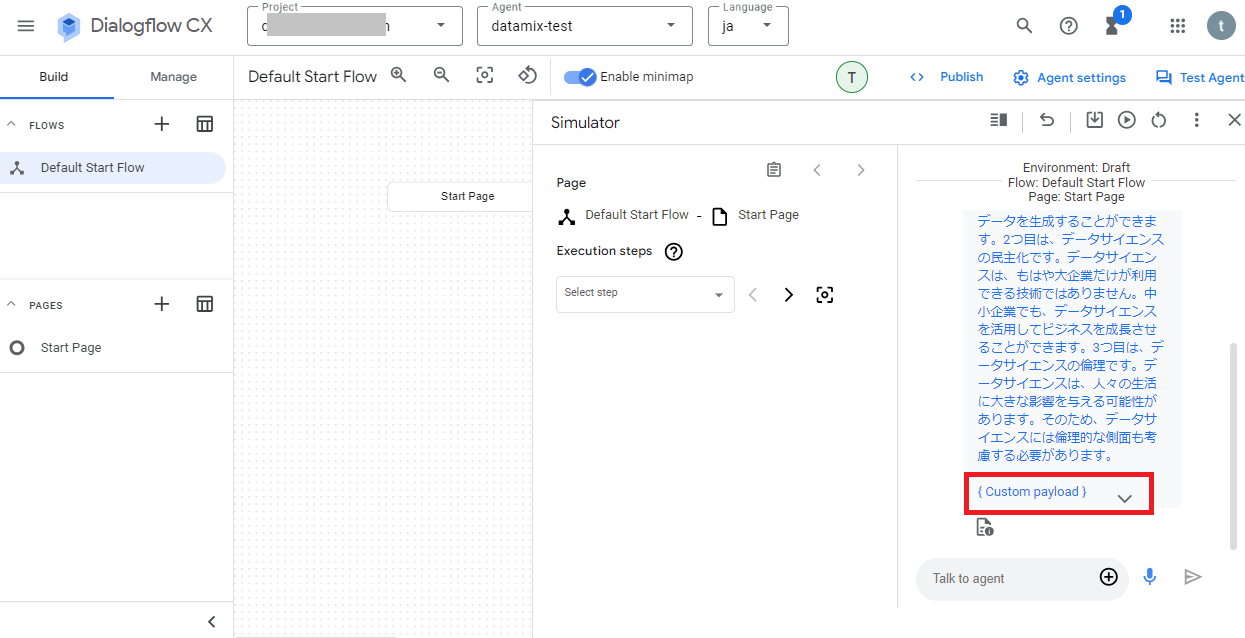
Dialogflow CXでデータストアの情報を元に生成したテキスト内容は"$request.knowledge.answers[0]"に格納されていますが、関連ファイルのリンク情報は$request.knowledge.sources[0]に格納されています。
そのため、ここからDialogflow CXのシステム関数を使ってリンク情報だけを抜き出し、データストアの出力設定でSlack用のCustom payloadを追加すれば、関連ファイルのリンク情報をSlackに送信することが可能です。
・システム関数の関連ドキュメント:System functions reference
Slack用のCustom payloadを追加方法については、データストアに関する設定の「Edit data stores」をクリックして設定画面を開き、Fulfillment項目のAgent responsesにある「Add dialogue option > Custom payload」をクリックします。
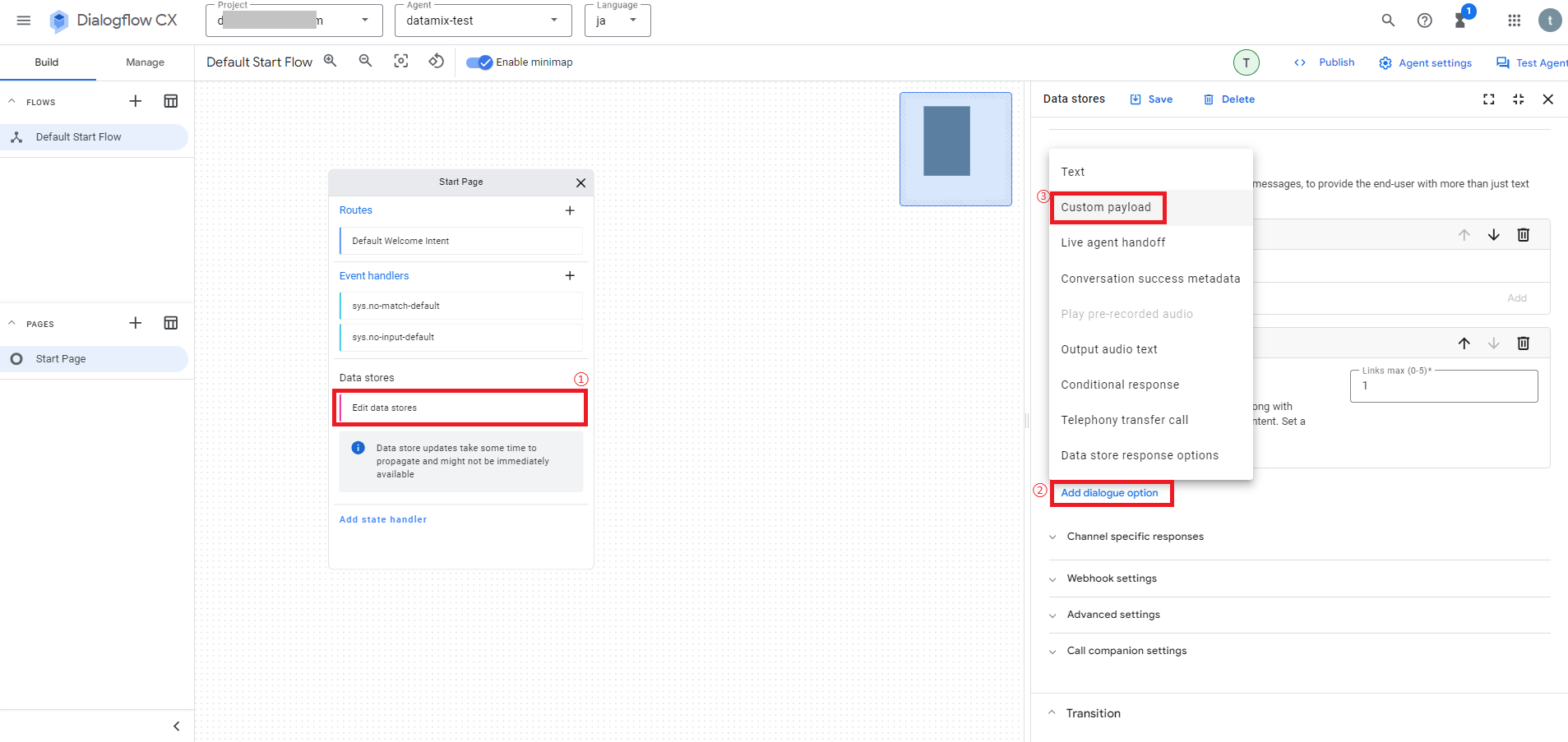
次にCustom payloadの設定画面が追加表示されるので、例えば以下のようなコードを追加し、画面上の「Save」をクリックして設定を保存して下さい。
{
"text": "----関連ファイルのリンク情報----\n$sys.func.FILTER(\"$request.knowledge.sources[0]\", \"$.[*].uri\")"
}
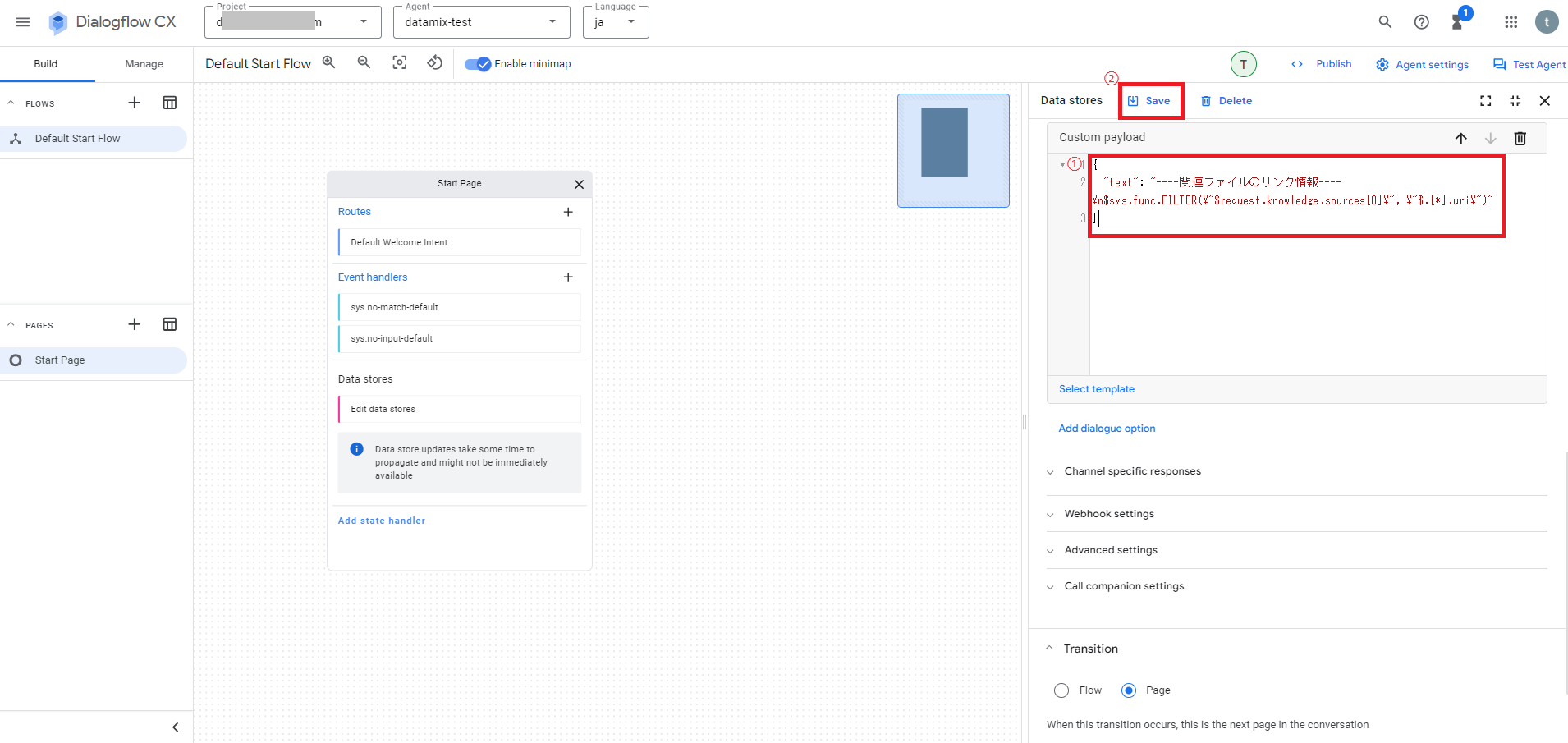
これでSlackに関連ファイルのリンク情報を出力させる設定は完了です。
既にSlackとの連携が済んでいて、Dialogflow CXの変更内容を反映させたい場合は、上記で記載した「フローと環境設定のバージョン保存について」を参考に、新しいEnvironment設定を作成して下さい。
そしてメニュー「Manage > Integrations」からSlackの「Connect」で設定画面を開き、「Stop」をクリックして一度停止させます。
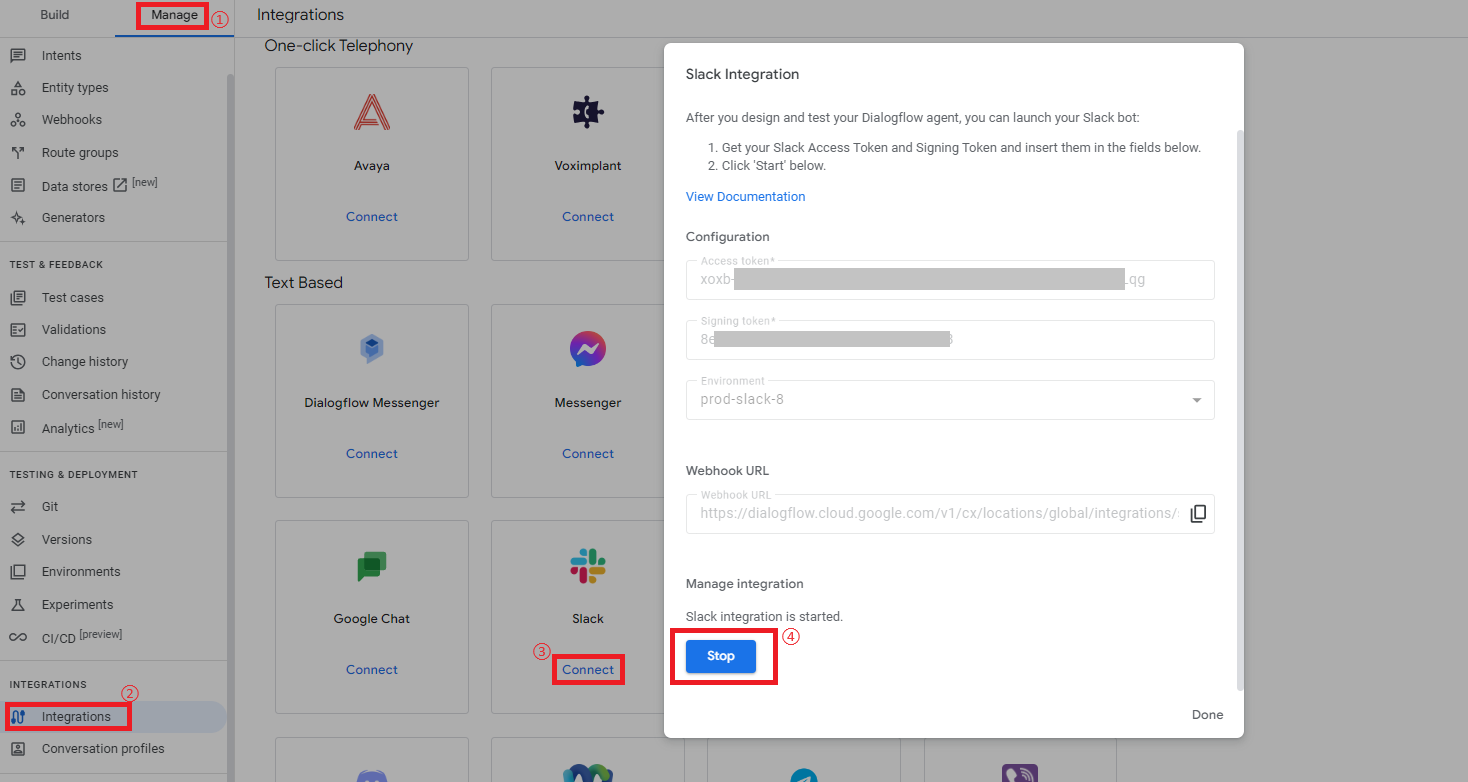
次にEnvironmentの設定部分を新しく作成した設定に変更し、「Start」をクリックして再起動させます。
これでDialogflow CXの変更内容を反映されるので、Slackで関連ファイルのリンク情報が出力されるか試してみて下さい。
データストアの更新について
今回はRAG用のファイル保存先としてCloud Storageを使いましたが、Cloud Storageに新しくファイルを追加した場合は、その後にデータストアの更新を行わないと変更内容が反映されないのでご注意下さい。
データストアの更新方法については、Google Cloudの「検索と会話」のメニュー「データストア」から、対象のデータストアをクリックします。
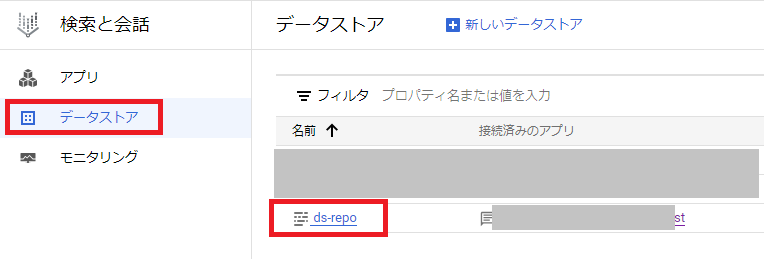
次に画面下にある「+データをインポート」をクリックします。
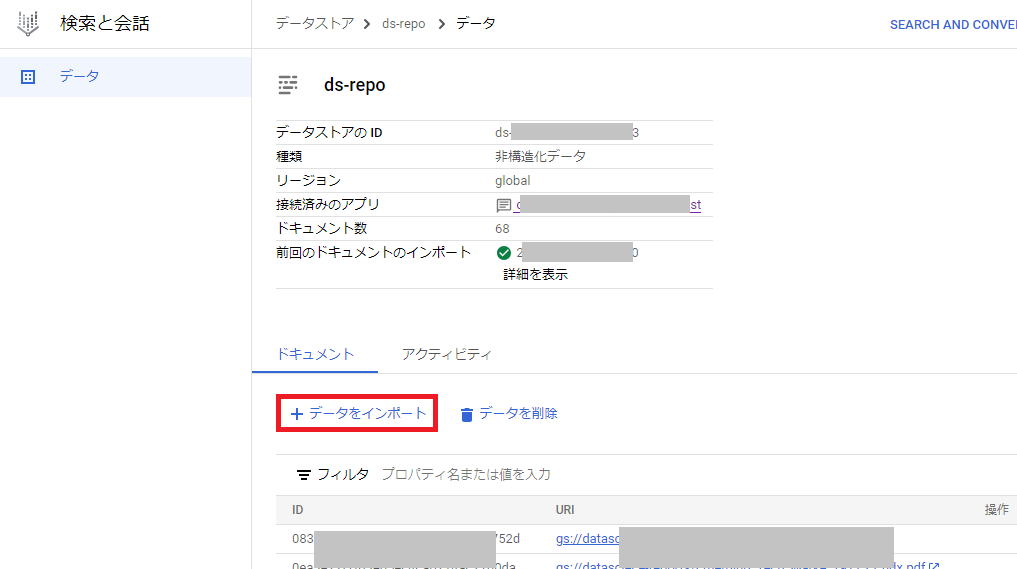
次にデータソースの選択画面が表示されるので、Cloud Storageの「SELECT」をクリックします。
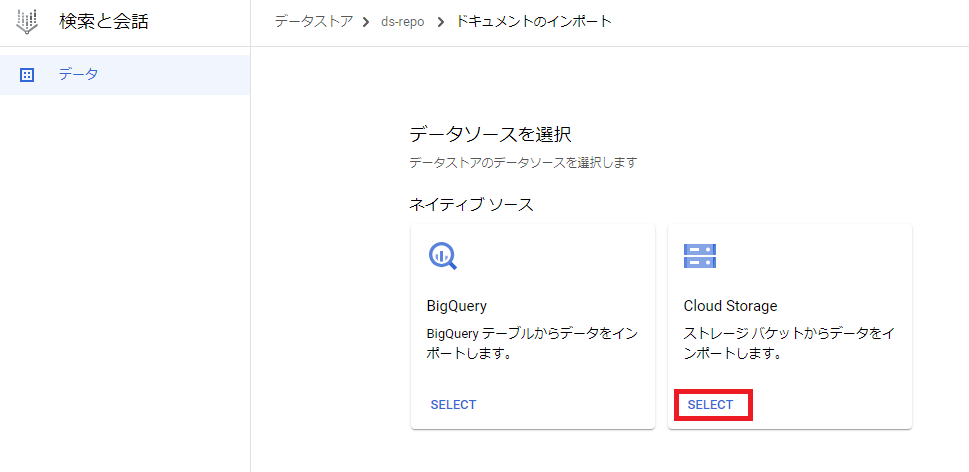
次にインポートするフォルダの選択で対象のCloud Storageのバケットを選択後、非構造化ドキュメントにチェックを付け、「インポート」をクリックします。
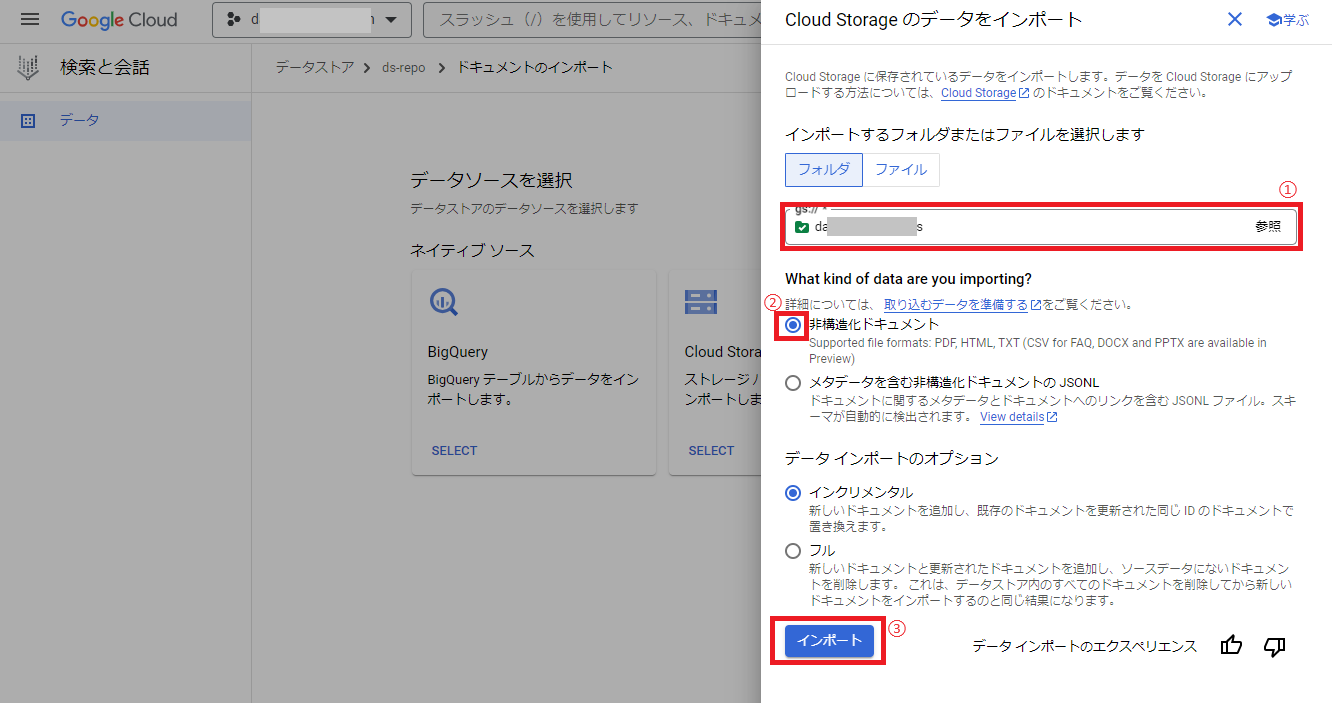
次にデータストアのデータ画面に戻り、アクティビティ項目に実行結果が表示されるので、ステータスが「インポートが完了しました」になれば正常に完了したのでOKです。
Cloud Functionsでデータストアを自動更新する方法
上記でデータストアを手動で更新する方法を解説しましたが、Cloud Functions(指定したイベントをきっかけに関数を実行できるサービス)を使うと、Cloud Storageにファイルを追加した際にデータストアを自動更新させることも可能です。
下記で説明しているCloud Functionsを利用する際にも利用料がかかりますので、事前にGoogle Cloudの公式サイトにあるドキュメント等をご確認下さい。
1. 事前に環境変数に設定するデータストアに関する接続情報を確認
Cloud Functionsで関数を作成する前に、データストアに関する接続情報を確認して下さい。
プロダクトメニュー「検索と会話」の「データストア」から対象のデータストアの詳細画面を表示し、プロジェクトID、データストアのID、リージョンの値をそれぞれ確認してメモしておきます。
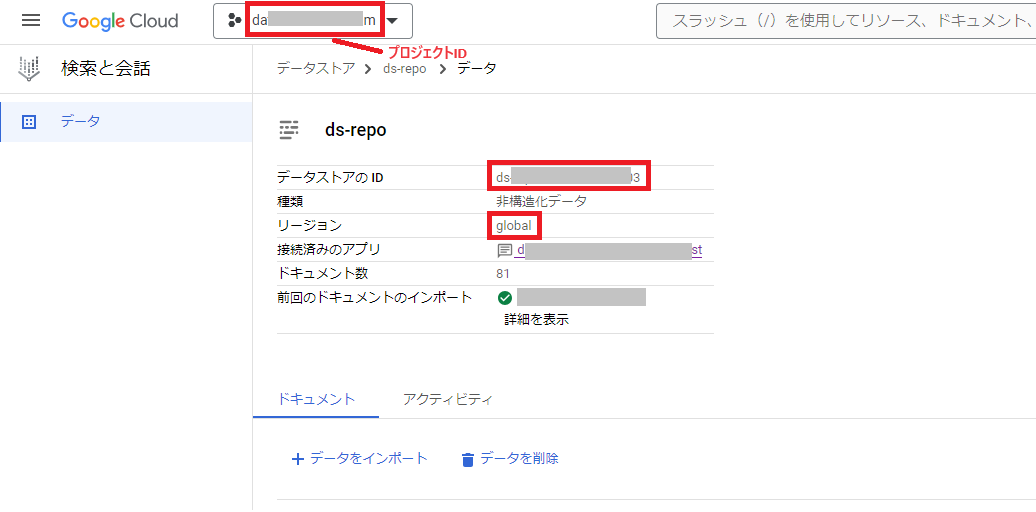
次にCloud Storageにある対象のバケット名を確認し、メモしておきます。
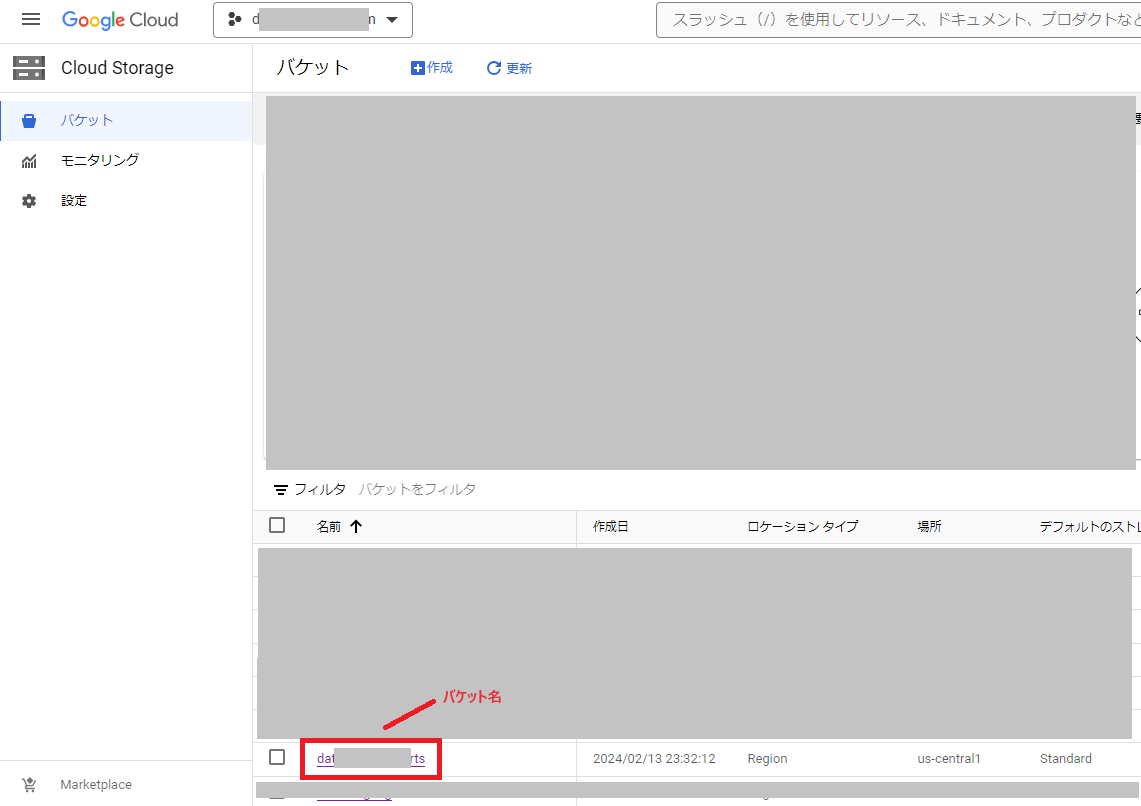
2. Cloud Functionsで関数を作成
次にCloud Functionsで関数を作成しますが、プロダクトメニュー「Cloud Functions」を開き、画面上の「+ファンクションを作成」をクリックします。
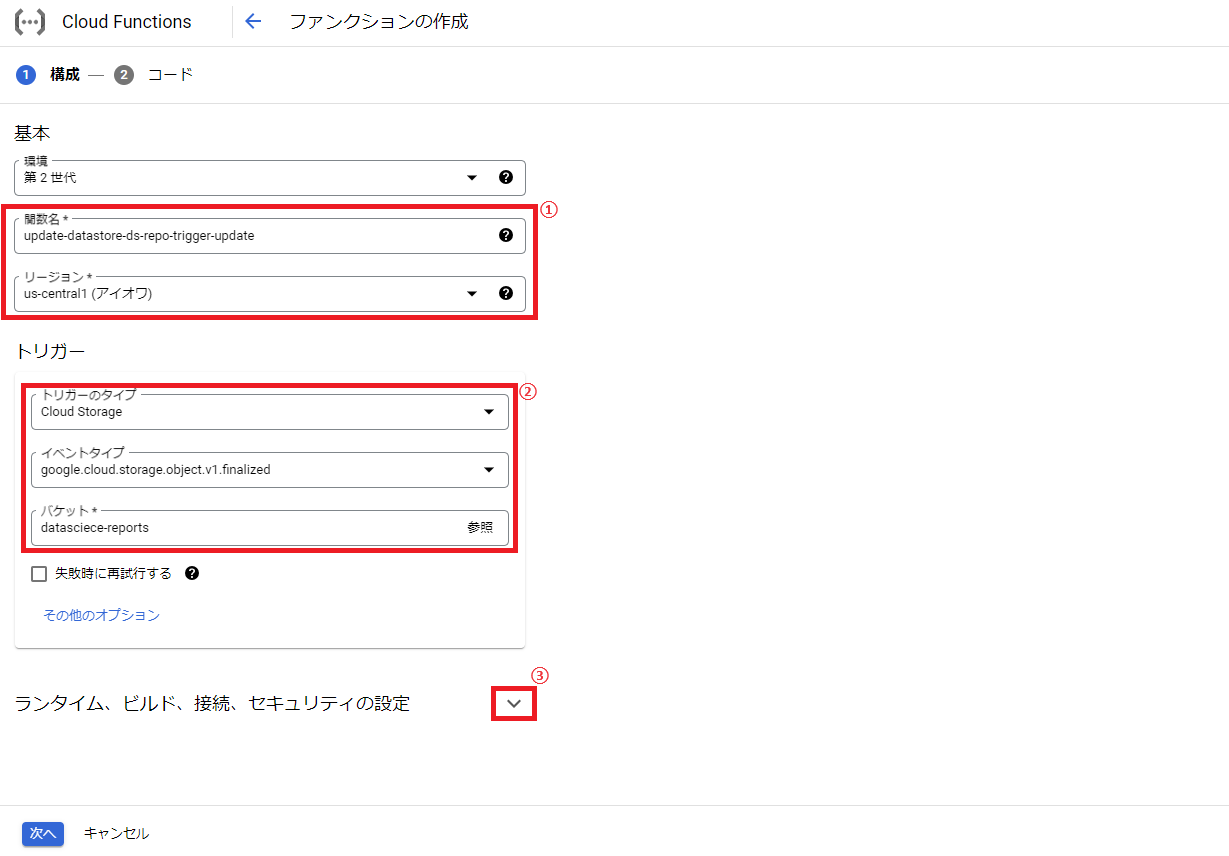
次に関数名の入力、リージョン(Cloud Storageのリージョンと同じにした方がいいみたいです)、トリガータイプ「Cloud Storage」、イベントタイプ「google.cloud.storage.object.v1.finalized」、対象のバケットを選択し、その下にある「ランタイム、ビルド、接続、セキュリティ設定」の詳細設定を開きます。
※イベントタイプ「google.cloud.storage.object.v1.finalized」は、Cloud Storageのファイル追加や更新を検知するイベントです。
次に画面下のランタイム環境変数の「+変数を追加」をクリックします。
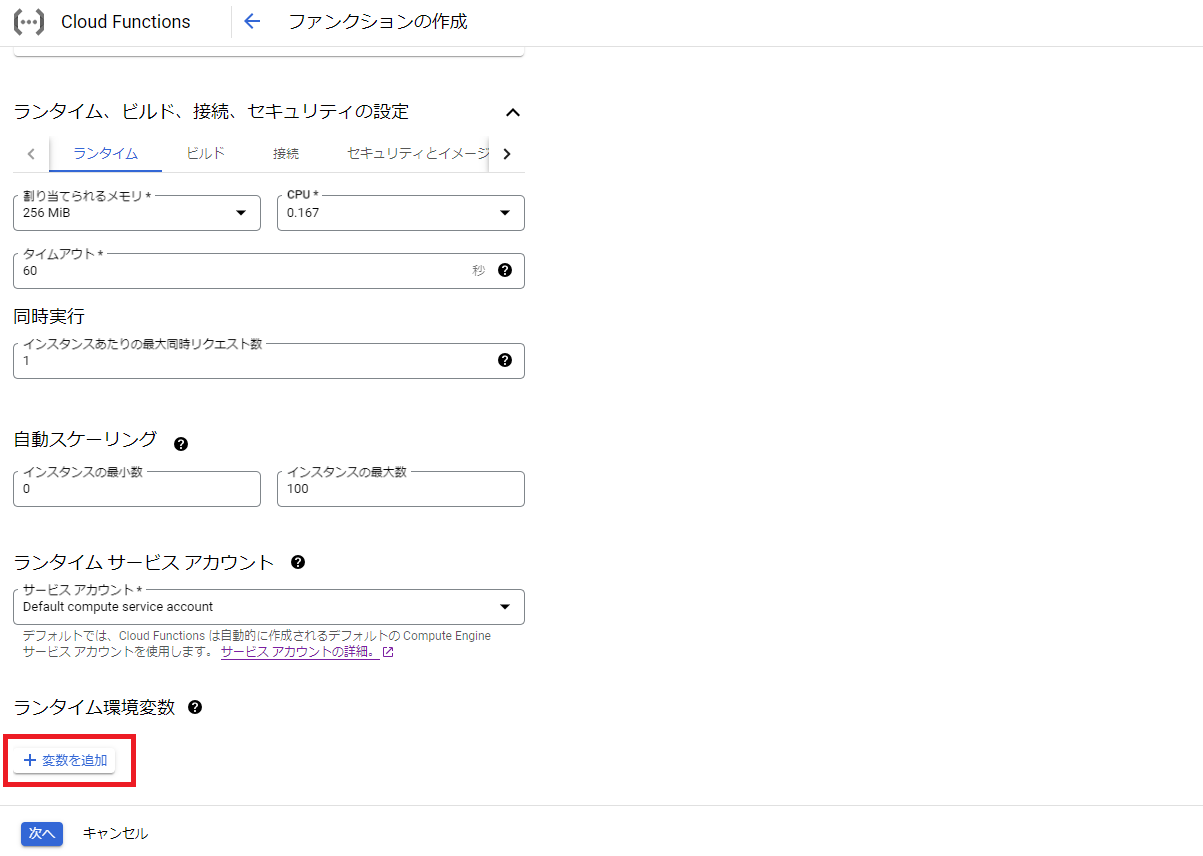
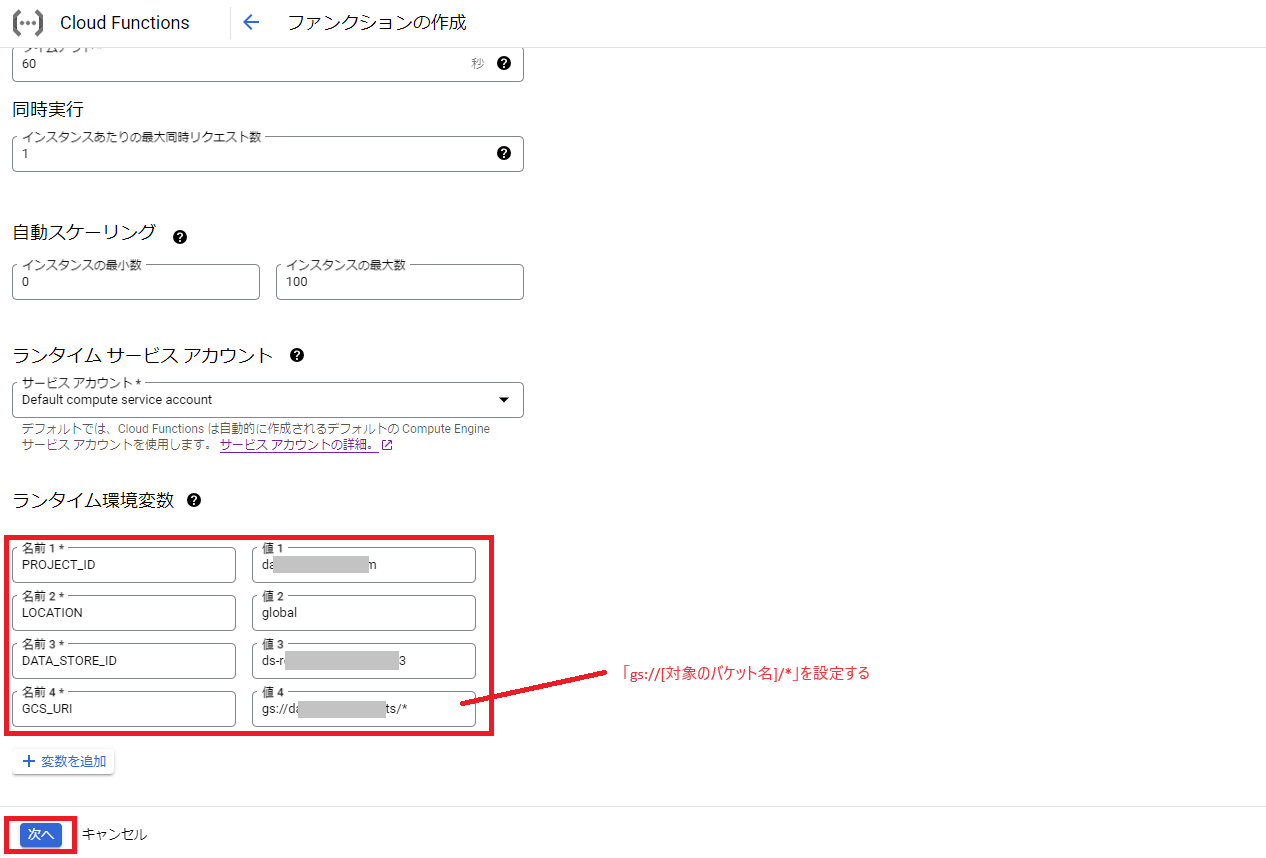
次に事前に確認しておいたデータストアへの接続情報を環境変数に設定するため、ランタイム環境変数に「PROJECT_ID」、「LOCATION」、「DATA_STORE_ID」、「GCS_URI」をそれぞれ設定し、「次へ」をクリックします。
※GCS_URIには「gs://バケット名/*」を設定します。
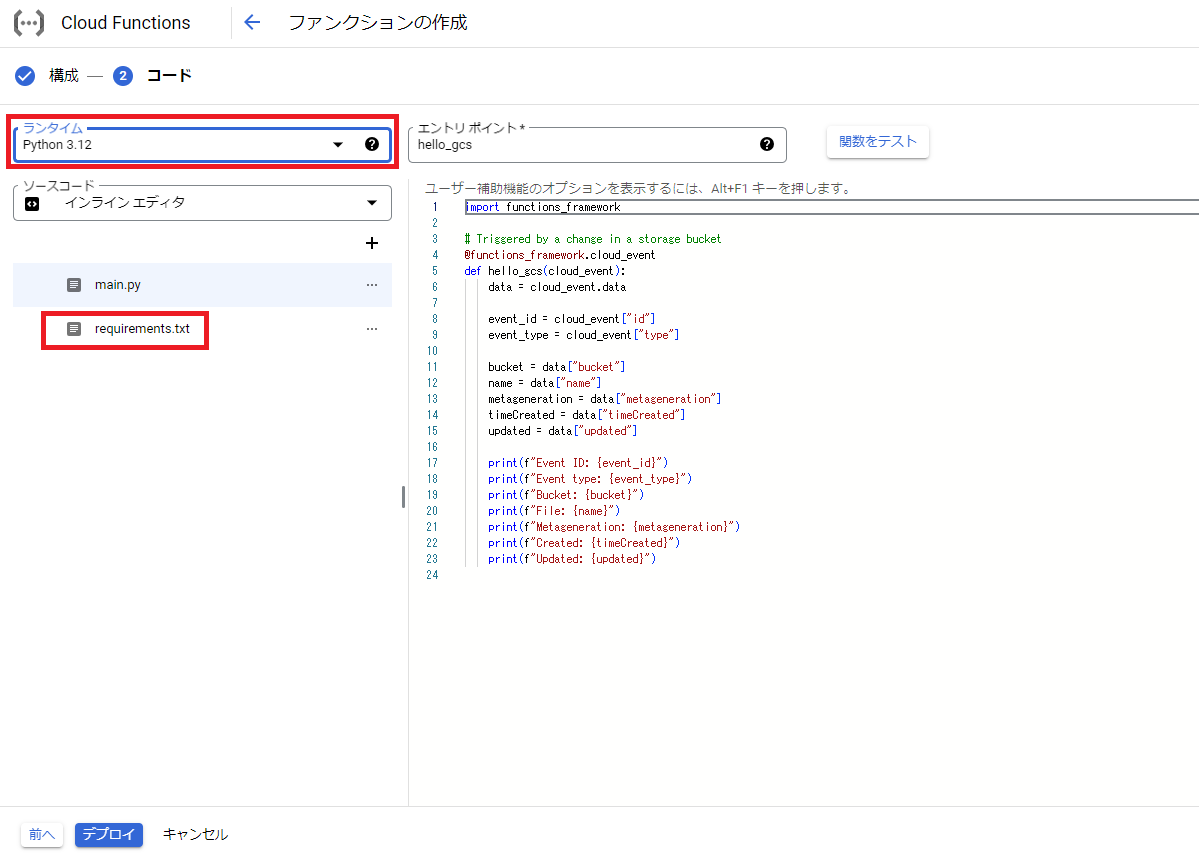
次にファンクションの作成画面が開くので、今回はランタイムにPythonの任意のバージョンを選択後、requirements.txtをクリックします。
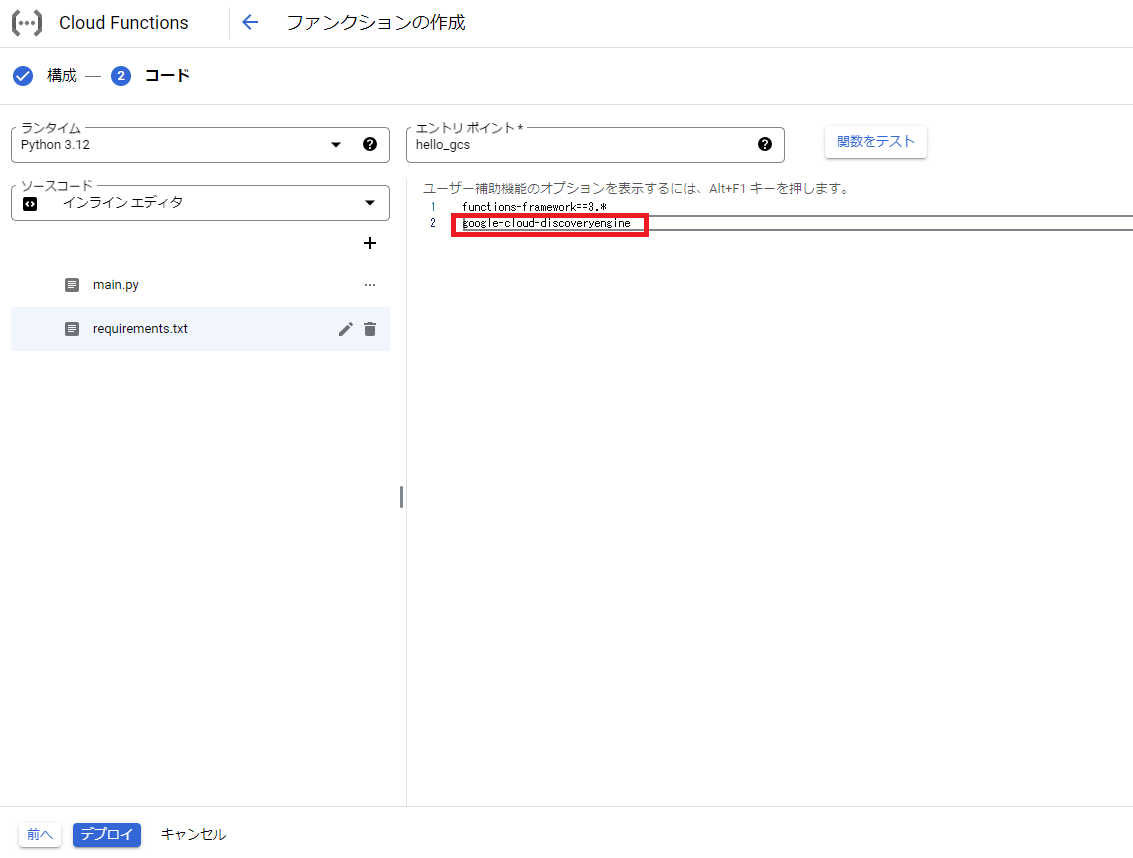
次に使用するライブラリとして「google-cloud-discoveryengine」を追加します。
次にもう一度main.pyの画面に戻り、エントリポイントを「update_datastore」、ファンクションのコード例として以下のように修正します。
※コード例はドキュメント「Create a search data store」を参考にしてカスタマイズしたものです。ランタイム環境変数から設定値の取得のところのデフォルト値の部分(os.getenvの右側のパラメータ)は自分の環境変数の値に修正して下さい。
import functions_framework
# ライブラリ
import os
from typing import Optional
from google.api_core.client_options import ClientOptions
from google.cloud import discoveryengine
# ランタイム環境変数から設定値の取得(デフォルト値はテスト実行用)
project_id = os.getenv("PROJECT_ID", "プロジェクトID")
location = os.getenv("LOCATION", "ロケーション")
data_store_id = os.getenv("DATA_STORE_ID", "データストアID")
gcs_uri = os.getenv("GCS_URI", "Cloud StorageのURL")
# Triggered by a change in a storage bucket
@functions_framework.cloud_event
def update_datastore(cloud_event):
# データストア更新用関数
def import_documents(
project_id: str,
location: str,
data_store_id: str,
gcs_uri: str,
) -> str:
client_options = (
ClientOptions(api_endpoint=f"{location}-discoveryengine.googleapis.com")
if location != "global"
else None
)
client = discoveryengine.DocumentServiceClient(client_options=client_options)
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch="default_branch",
)
request = discoveryengine.ImportDocumentsRequest(
parent=parent,
gcs_source=discoveryengine.GcsSource(
# 非構造化データが対象の場合はdata_schemaに「content」を設定
input_uris=[gcs_uri], data_schema="content"
),
# Cloud Storageにファイル追加・更新の場合は「INCREMENTAL」で取り込む
reconciliation_mode=discoveryengine.ImportDocumentsRequest.ReconciliationMode.INCREMENTAL,
)
operation = client.import_documents(request=request)
print(f"Waiting for operation to complete: {operation.operation.name}")
response = operation.result()
metadata = discoveryengine.ImportDocumentsMetadata(operation.metadata)
print(response)
print(metadata)
return operation.operation.name
# イベント情報をログ出力
data = cloud_event.data
event_id = cloud_event["id"]
event_type = cloud_event["type"]
bucket = data["bucket"]
name = data["name"]
metageneration = data["metageneration"]
timeCreated = data["timeCreated"]
updated = data["updated"]
print("\n==== Event Info ====")
print(f"Event ID: {event_id}")
print(f"Event type: {event_type}")
print(f"Bucket: {bucket}")
print(f"File: {name}")
print(f"Metageneration: {metageneration}")
print(f"Created: {timeCreated}")
print(f"Updated: {updated}")
# データストアの更新処理実行
print("\n==== Exec import_documents ====")
import_documents(project_id, location, data_store_id, gcs_uri)
エントリポイントとファンクションのコードを修正後、テストを試すので画面右上の「関数をテスト」をクリックします。
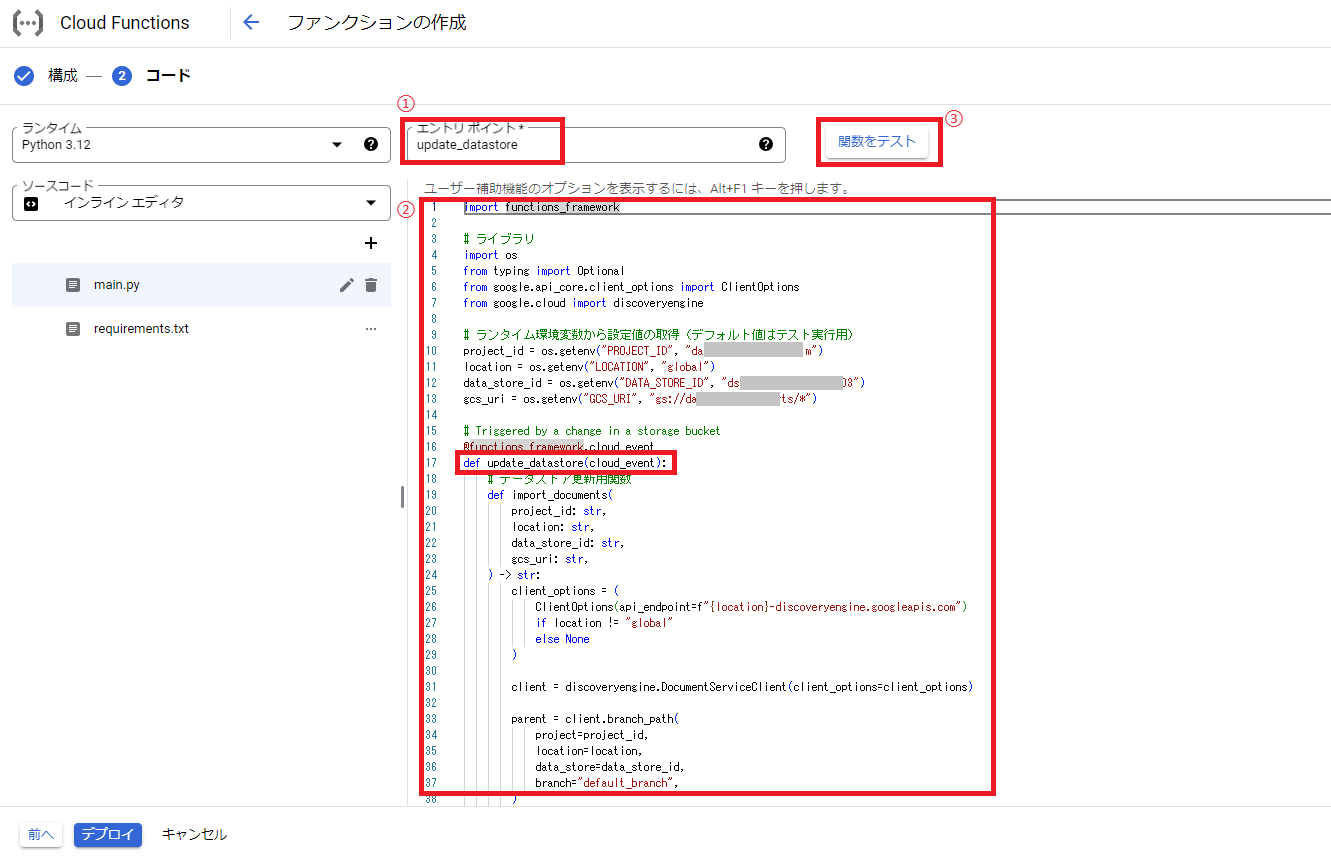
次にテストに関するポップアップが表示されるので、「テストを始める」をクリックします。
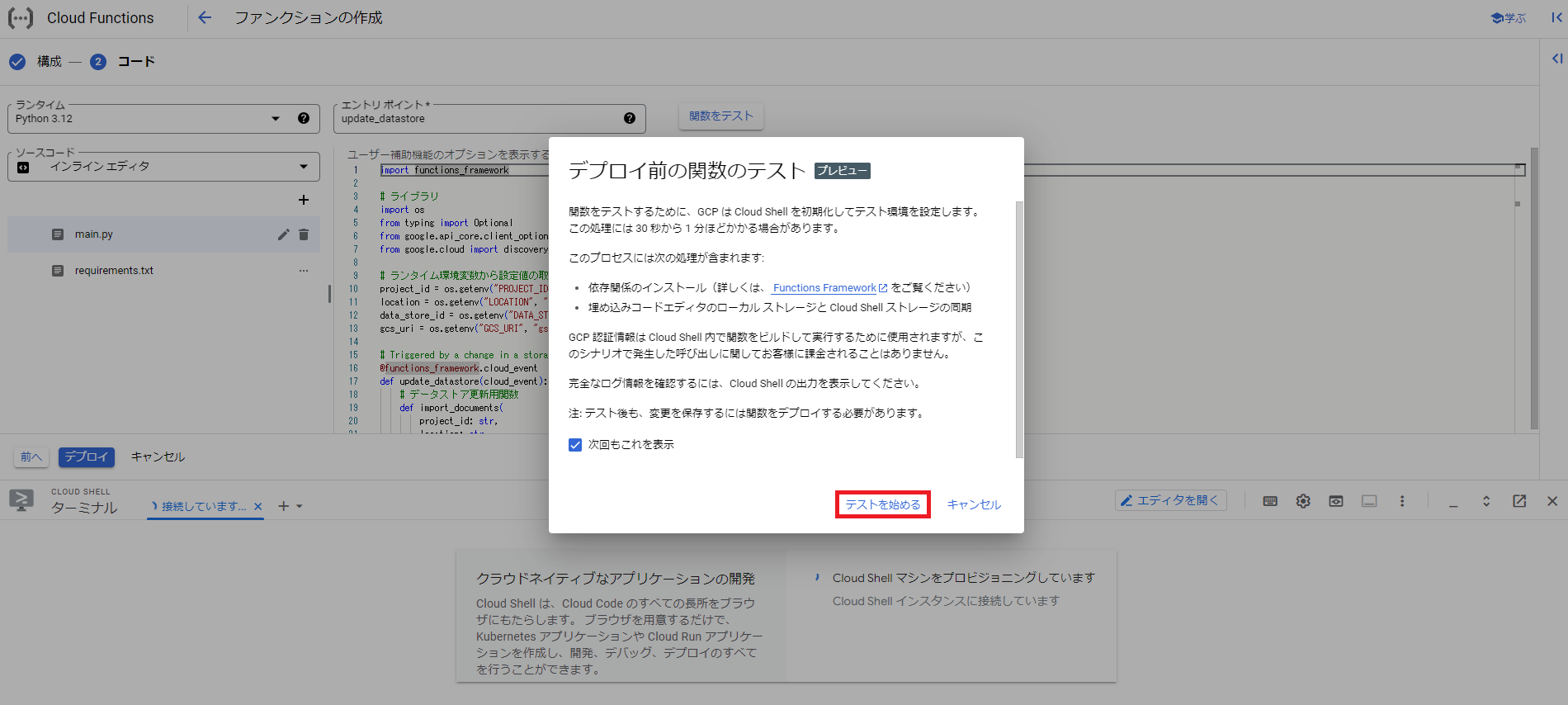
次に関数をテストする準備が完了後、画面右下の「テストを実行」をクリックします。
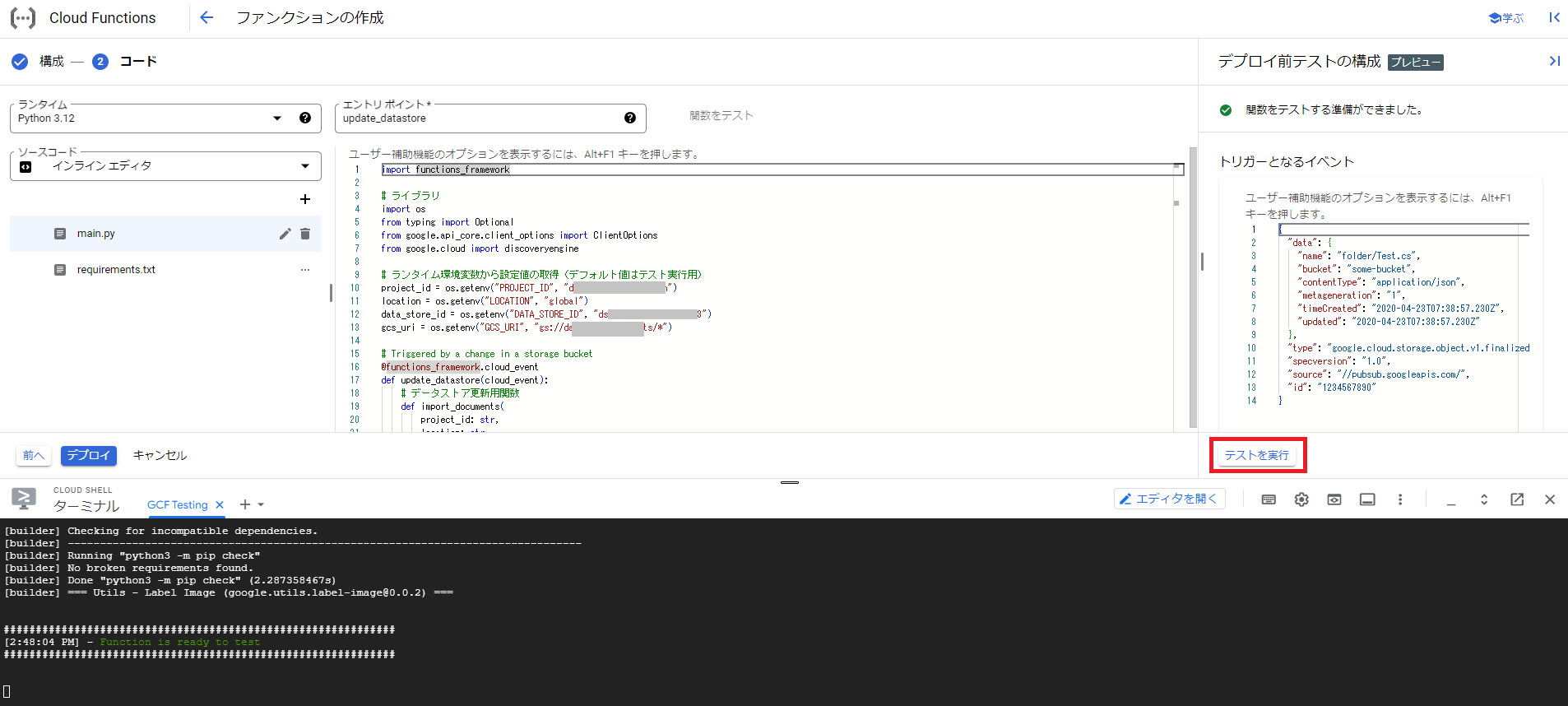
テストを実行して上手くいくとターミナル部分にエラーがでず、対象のデータストアの画面を確認するとインポート処理が実行されているのを確認できます。
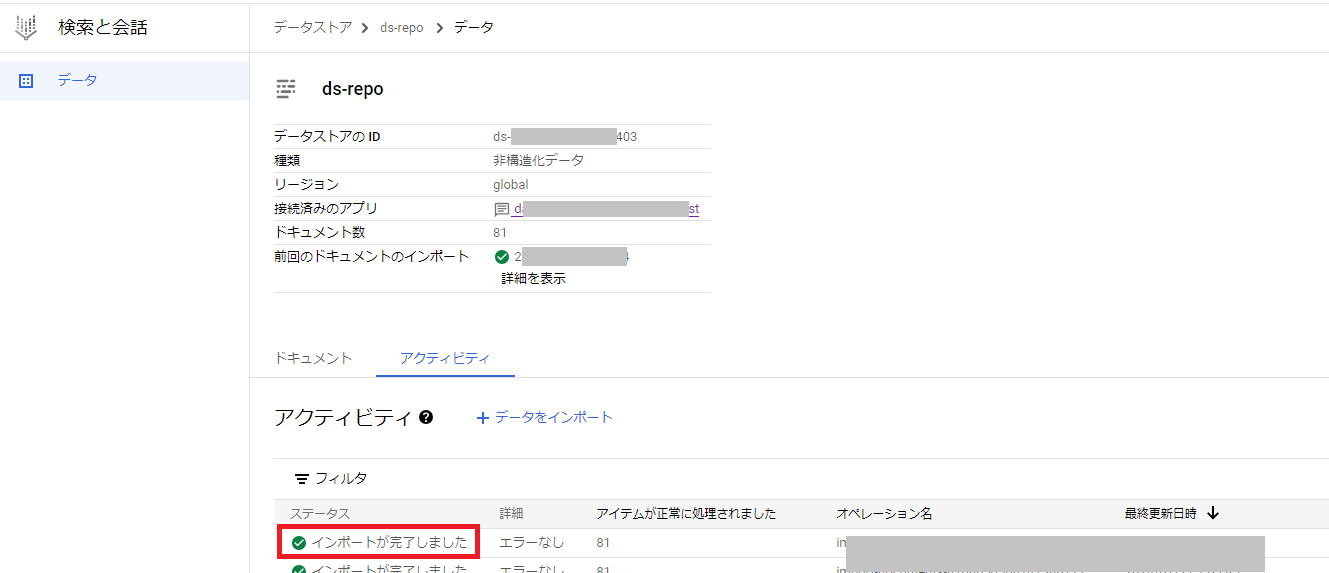
テストを試して問題がなければ、画面左下の「デプロイ」をクリックします。
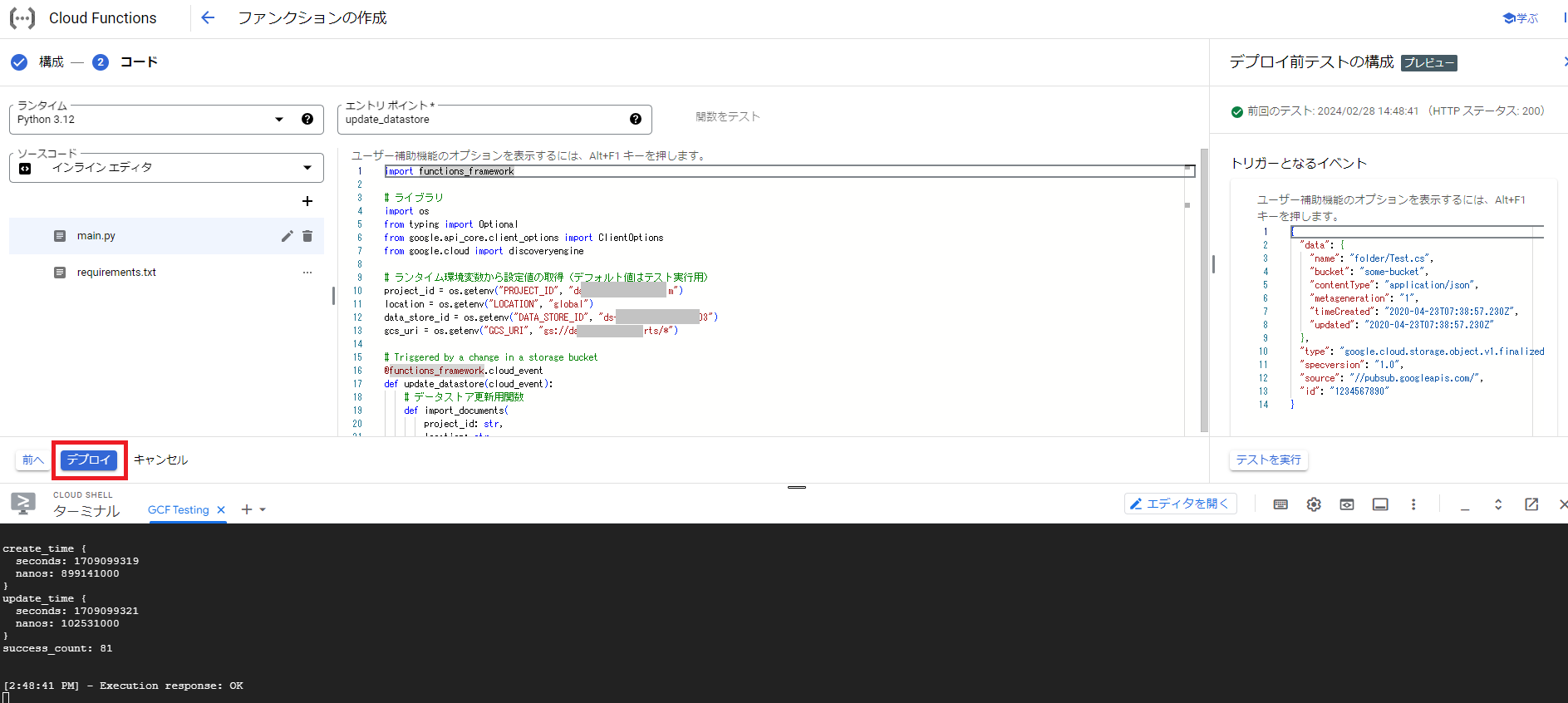
これでデプロイ処理が実行され、正常終了すれば完了です。実際にCloud Storageにファイルを追加し、データストアでインポート処理が実行されるのを試してみて下さい。
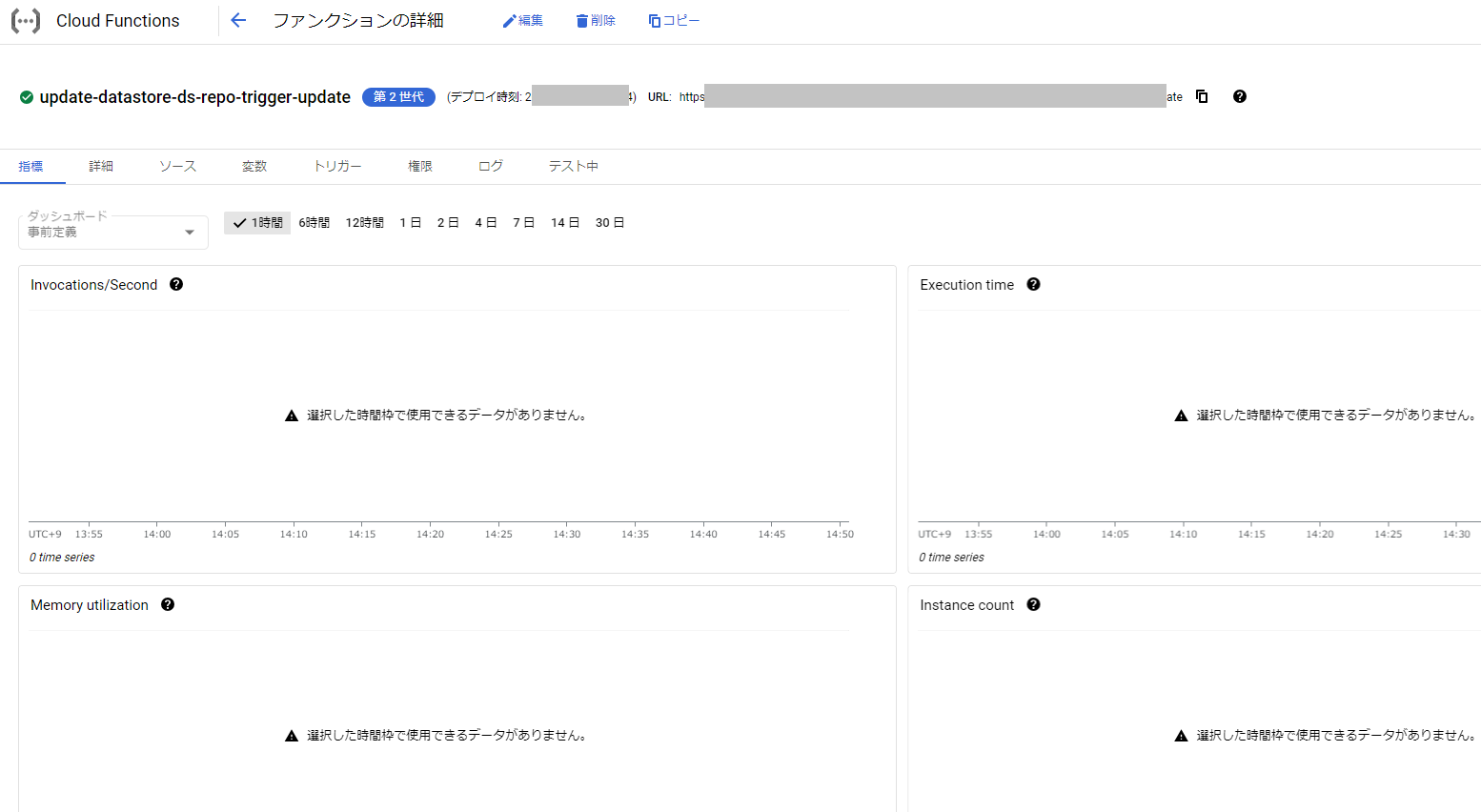
3. ファイル削除を検知したい場合について
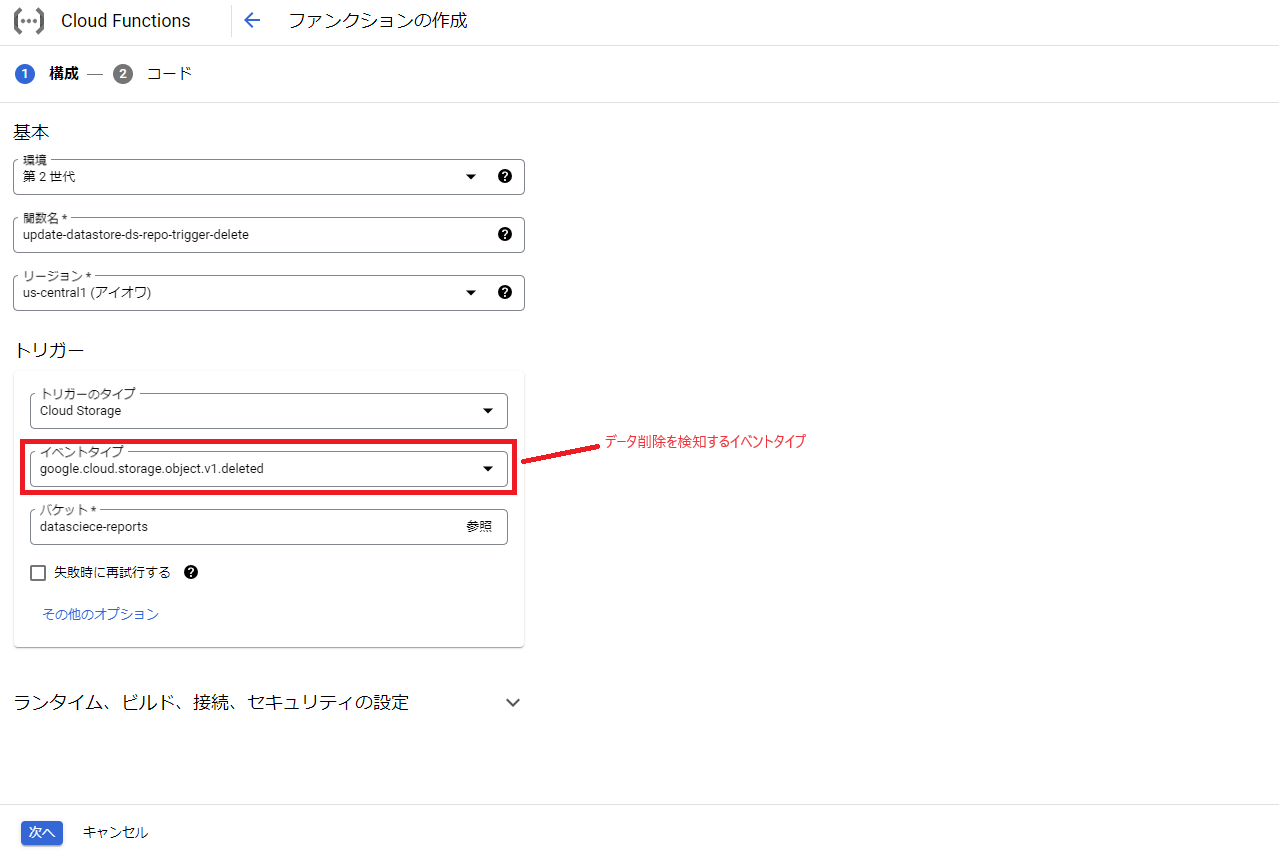
上記で作成したファンクションはCloud Storageのファイル追加や更新を検知して実行されますが、ファイル削除を検知して実行させたい場合は別途もう一つファンクションを作成する必要があります。
作成方法は先程とほぼ同様ですが、最初のトリガー設定で「google.cloud.storage.object.v1.deleted」を選択して下さい。
そしてファンクションのコード例としては、以下のようにドキュメントをインポートする際のモードを「FULL」に変更して下さい。
※ランタイム環境変数から設定値の取得のところのデフォルト値の部分(os.getenvの右側のパラメータ)は自分の環境変数の値に修正して下さい。
import functions_framework
# ライブラリ
import os
from typing import Optional
from google.api_core.client_options import ClientOptions
from google.cloud import discoveryengine
# ランタイム環境変数から設定値の取得(デフォルト値はテスト実行用)
project_id = os.getenv("PROJECT_ID", "プロジェクトID")
location = os.getenv("LOCATION", "ロケーション")
data_store_id = os.getenv("DATA_STORE_ID", "データストアID")
gcs_uri = os.getenv("GCS_URI", "Cloud StorageのURL")
# Triggered by a change in a storage bucket
@functions_framework.cloud_event
def update_datastore(cloud_event):
# データストア更新用関数
def import_documents(
project_id: str,
location: str,
data_store_id: str,
gcs_uri: str,
) -> str:
client_options = (
ClientOptions(api_endpoint=f"{location}-discoveryengine.googleapis.com")
if location != "global"
else None
)
client = discoveryengine.DocumentServiceClient(client_options=client_options)
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch="default_branch",
)
request = discoveryengine.ImportDocumentsRequest(
parent=parent,
gcs_source=discoveryengine.GcsSource(
# 非構造化データが対象の場合はdata_schemaに「content」を設定
input_uris=[gcs_uri], data_schema="content"
),
# Cloud Storageのファイル削除の場合は「FULL」で取り込む
reconciliation_mode=discoveryengine.ImportDocumentsRequest.ReconciliationMode.FULL,
)
operation = client.import_documents(request=request)
print(f"Waiting for operation to complete: {operation.operation.name}")
response = operation.result()
metadata = discoveryengine.ImportDocumentsMetadata(operation.metadata)
print(response)
print(metadata)
return operation.operation.name
# イベント情報をログ出力
data = cloud_event.data
event_id = cloud_event["id"]
event_type = cloud_event["type"]
bucket = data["bucket"]
name = data["name"]
metageneration = data["metageneration"]
timeCreated = data["timeCreated"]
updated = data["updated"]
print("\n==== Event Info ====")
print(f"Event ID: {event_id}")
print(f"Event type: {event_type}")
print(f"Bucket: {bucket}")
print(f"File: {name}")
print(f"Metageneration: {metageneration}")
print(f"Created: {timeCreated}")
print(f"Updated: {updated}")
# データストアの更新処理実行
print("\n==== Exec import_documents ====")
import_documents(project_id, location, data_store_id, gcs_uri)
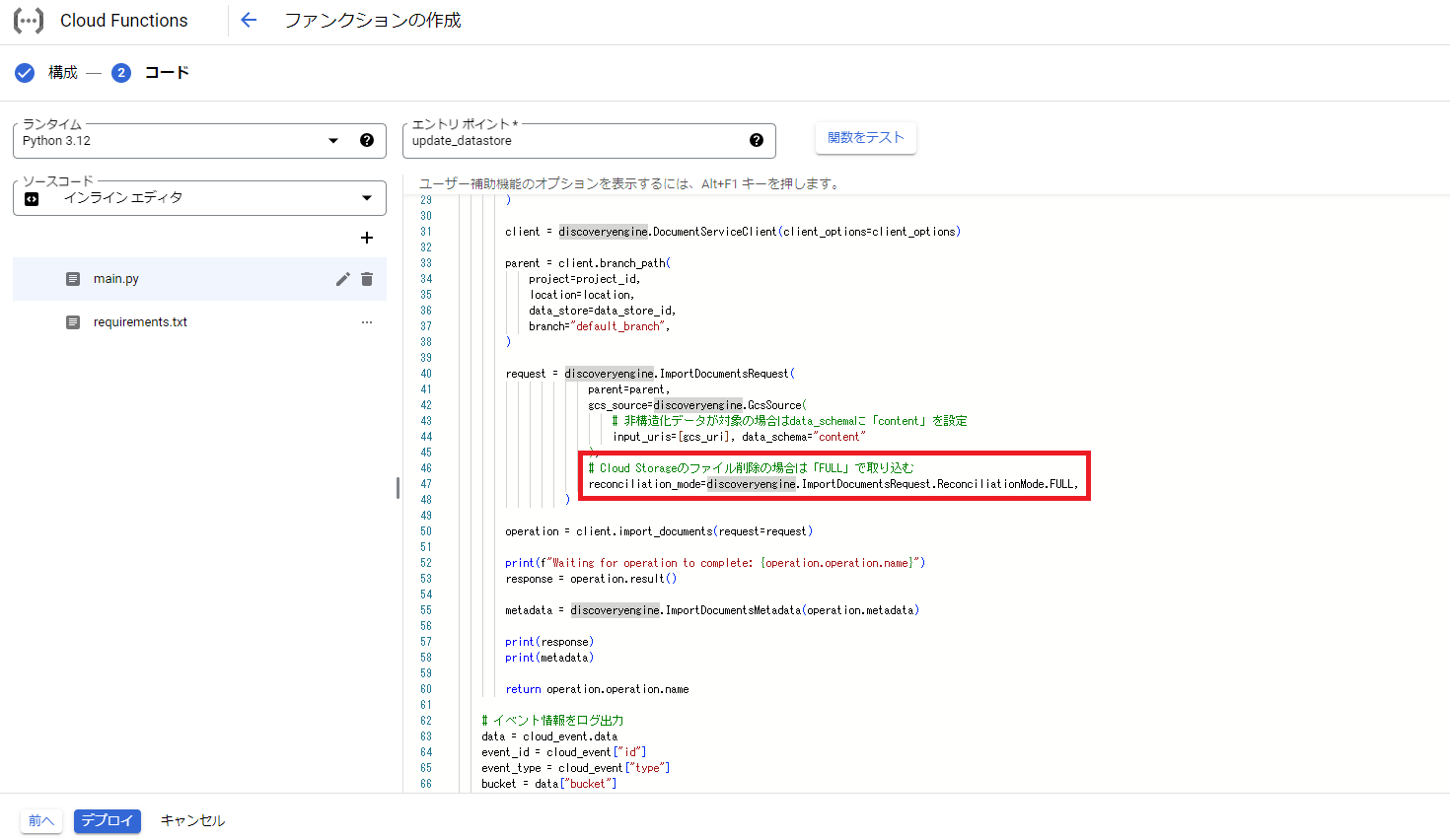
あとは上記と同様の方法で作成していただければOKです。
最後に
今回はDialogflow CXとCloud Storageで作成したRAGのチャットボットについてご紹介しました。
実際に使ってみるとテキスト生成が上手くいかないことがあったり、ChatGTPのような創発性が高いテキスト生成ができないというような課題があることがわかりましたが、ドキュメント検索を目的とするRAGとしての利用であれば、比較的簡単導入できて十分効果的だと思います。
これからRAGのチャットボットを導入して業務改善に繋げたいというような方がいたら、ぜひ参考にしてみて下さい!