Pythonを使った基本的な機械学習のステップを解説します。
データサイエンティストのサイトKaggleで提供されているタイタニックのデータを使って、複数の説明変数から目的変数を予測する「教師あり学習」による予測モデルを構築してみます。
以下のKaggleのサイトを参考にしています。
Titanic Data Science Solutions
統計分析のステップ
統計分析の手順は、データマイニングの標準的な方法論であるCRISP-DM(Cross-Industry Standard Process for Data Mining)に沿って行います。
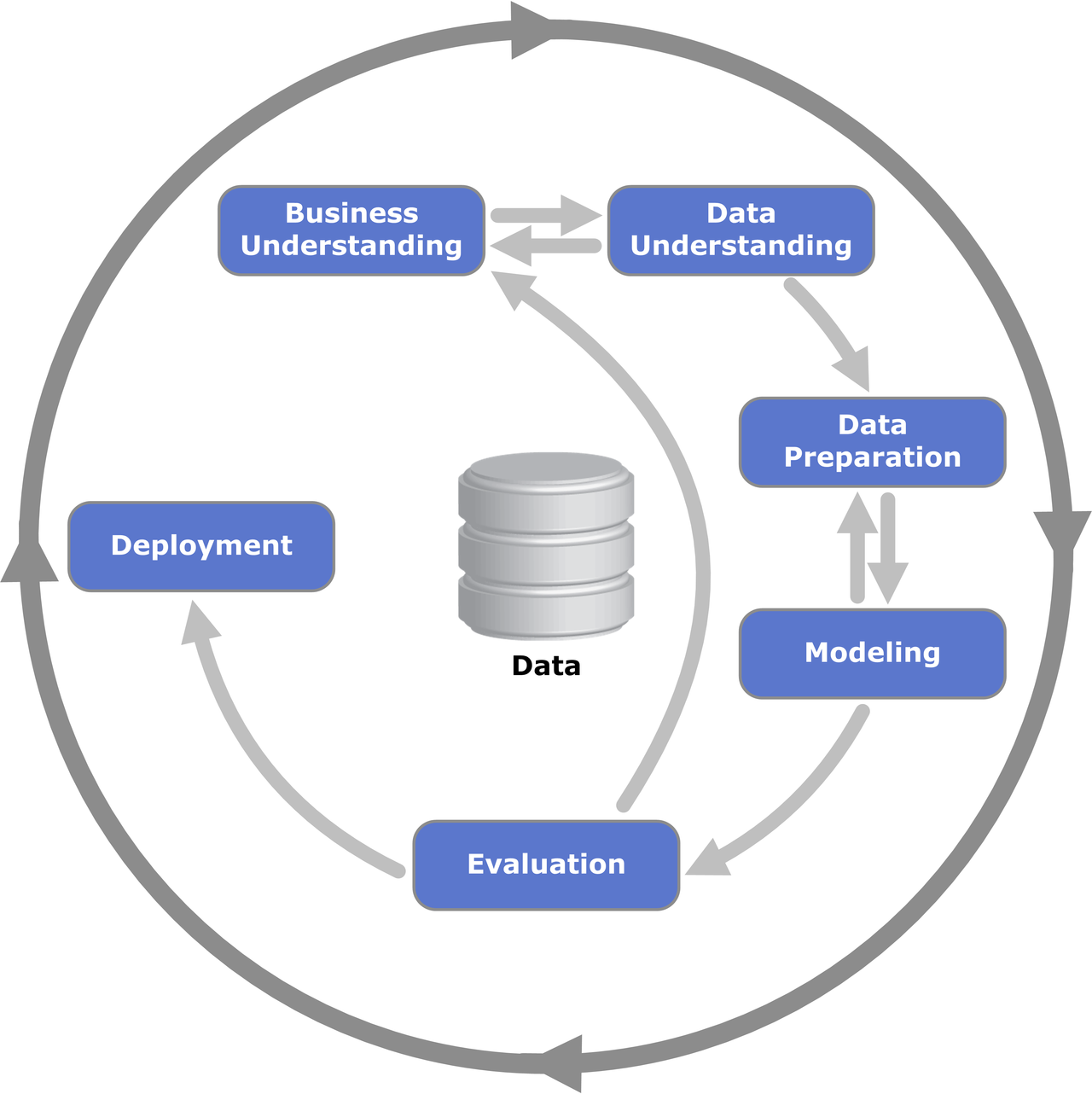
(Wikipediaより引用)
- Business Understanding (ビジネスの理解)
- Data Understanding (データの理解)
- Data Preparation (データ準備)
- Modeling (モデル構築)
- Evaluation (モデル評価)
- Deployment (適用)
Business Understanding
今回は、タイタニックの乗客の生死の実績データを使って予測・分析を行います。1912年4月15日に、その処女航海で沈没したタイタニックは、2224名の乗客・乗組員のうち1502名が死亡しました。
いま、手元には891名の乗客の属性および生存・死亡に関するデータと、生死が不明な418名分のデータがあります。
これらのデータを使って、どのような乗客が生存したのかを分析し、その結果にもとづいて、生死が未知である乗客の生死を推定します。

(Wikipediaより引用)
Data Understanding
以下のような観点で、データを理解します。
- データ項目
- データの意味
- データ件数
- データ型
- 値の範囲
- 値の分布
- ユニークな値のリスト
- カーディナリティ
- 欠損値・不正値
Data Preparation
データ準備では、予測モデルのインプットとするために、データを整備します。データ整備は以下のような処理を含みます。
- 結合(JOIN、UNION)
- 集計(GROUP BY)
- ピボット、アンピボット
- 欠損値の補完
- 文字列変換
- 四則演算
- 名寄せ
- 値の置き換え
データ準備の手順
- 1つのデータ(ファイル、テーブル)で説明変数と目的変数の組み合わせになるように、結合、集計、ピボット、アンピボットで構造を変換します。
- 欠損値がある場合、そのままでは適切に予測ができないため、何らかの値に置き換えます。
- カテゴリカルなテキスト項目は、数値に置き換えます。
Modeling (モデル構築)
予測に適したアルゴリズムを選択し、予測モデルを構築します。主要なアルゴリズムは、「教師ありか、教師なしか」「予測する対象がカテゴリカルか、数値か」により以下のように分類できます。
教師あり、カテゴリカルを予測 - 判別(Classification)
| アルゴリズム | 概要 |
|---|---|
| 決定木(Decision Tree) | 属性値テストにより段階的にデータを分割していき構築する、木構造の分析モデル。 |
| ランダムフォレスト(Random Forrest) | ランダムサンプリングされたトレーニングデータによって学習した多数の決定木を使用するモデル。 |
| K近傍法(K Nearest Neighbors) | 特徴空間における最も近い訓練例に基づいた分類の手法。 |
| ロジスティック回帰(Logistic Regression) | ベルヌーイ分布に従う変数の統計的回帰モデルの一種。連結関数としてロジットを使用する一般化線形モデル (GLM) の一種。 |
| サポートベクターマシン(SVM) | 線形入力素子を利用して 2 クラスのパターン識別器を構成する手法。 |
| リニアSVC(Linear SVC) | カーネルを使用しないSVM(サポートベクトル・マシン)に基づくクラス分類手法。 |
| パーセプトロン(Perceptron) | ニューラルネットワークの一種。S層(感覚層、入力層)、A層(連合層、中間層)、R層(反応層、出力層)の3つの部分からなる。 |
| 確率的勾配降下法(Stochastic Gradient Decent) | 連続最適化問題に対する勾配法の乱択アルゴリズム。 |
| ナイーブベイズ(Naive Bayes) | ベイズの定理にもとづく分類器。 |
教師あり、数値を予測 - 回帰(Regression)
- 回帰木
- ランダムフォレスト
- ロジスティック回帰
- リッジ回帰
教師なし、カテゴリカルを予測 - 分類(Clustering)
- K平均法(K-Means)
scikit-learnのアルゴリズムでは、下図のようなチートシートも提供されています。
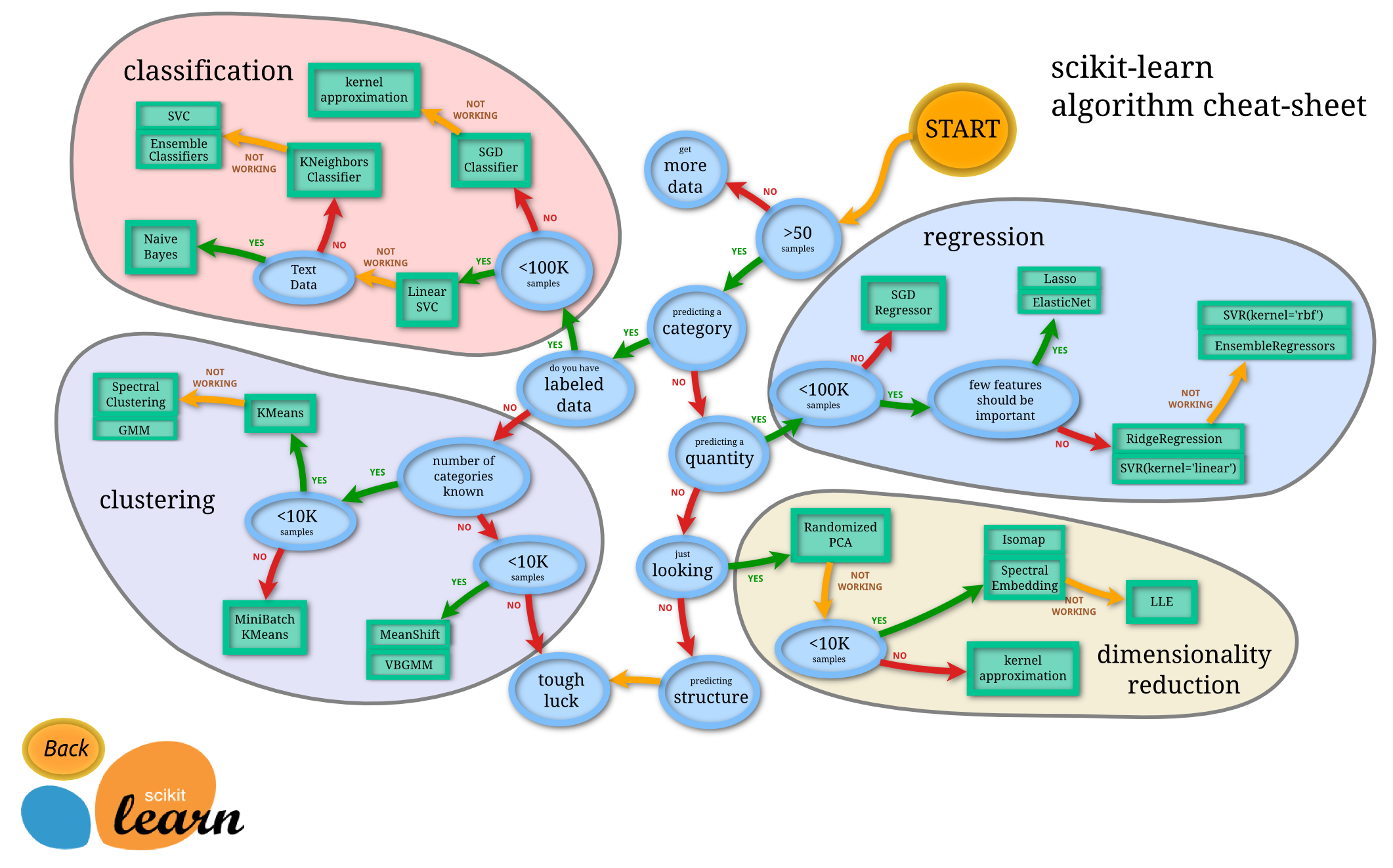
(scikit-learnサイトより引用)
今回は、既知の乗客の生死(「生存」か「死亡」か)の実績から未知の乗客の生死を予測するので、教師ありのカテゴリカルの予測になり、上記のClassificationのアルゴリズムから精度の良いものを選択して使用します。
Evaluation
モデル構築に用いるアルゴリズムがどの程度の精度であるかを評価し、最適なアルゴリズムを選択します。アルゴリズムの評価には交差検証(cross-validation)を用います。
交差検証のイメージ(出典:Wikipedia)
交差検証は、データを分割し、そのうち1つを検証データ、残りを学習データとして学習と検証を行う手順を、分割した回数分だけ繰り返して、精度の平均値などをとって評価する。
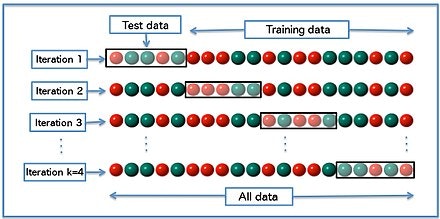
(Wikipediaより引用)
Deployment
モデルを運用環境で使えるようにデプロイします。