はじめに
今回やりたいこと
Webスクレイピングによって、Jリーグのデータサイトの情報を収集&分析したいと思いました。
その第1段階としてまずはデータを収集し、それを表にまとめてみました。
結果
以下がJリーグの川崎フロンターレというチームの選手一覧の情報を表にまとめた結果です。
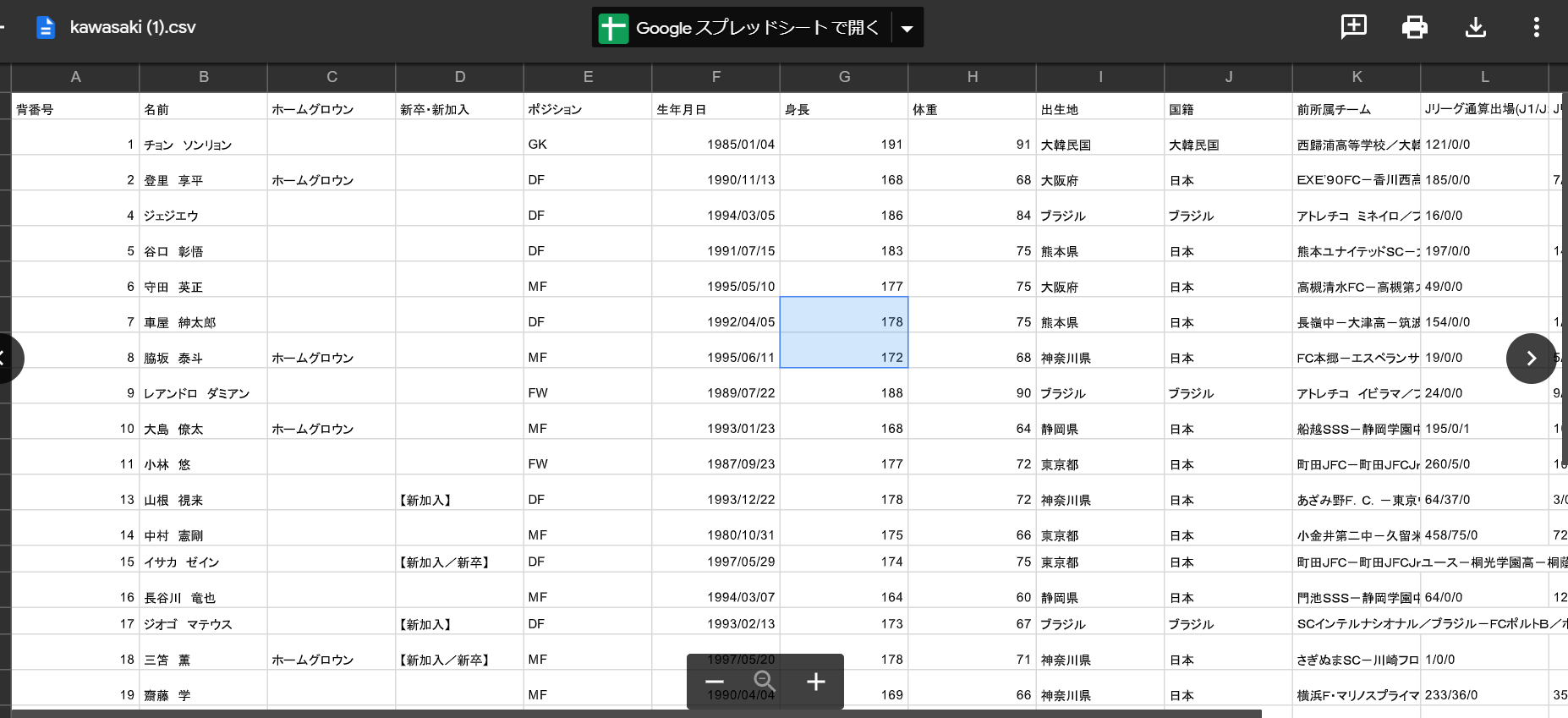
※CSVファイルとして出力したものを、Googleのスプレッドシートで開いています
きっかけ
元々サッカー観戦が好きで、その流れでスポーツのデータ分析にも興味を持っていました。
そしてプログラミングを学ぶうちに自分でもできるのではないかということでプログラムを作り始めました。
コードと解説
前提
- 現在のスキル
- Progate終了
- Ruby on Rails で少しアプリ作成の経験あり
- Python初心者
- 開発環境
- AWS cloud9
- Python3
流れ
1.Jリーグデータサイトの川崎フロンターレのサイトをチェック
2.スクレイピングのためのライブラリを取得
3.欲しいデータを辞書に入れていく
4.辞書をCSVファイルに出力
5.CSVファイルを表示
コード
まずrequestsとBeautifulSoupというライブラリをインポート
player-kawasaki.py
import requests
from bs4 import BeautifulSoup
import csv
対象のURLを指定し欲しい情報を抽出します。
player-kawasaki.py
url = "https://data.j-league.or.jp/SFIX02/search?displayId=SFIX02&selectValue=1&displayId=SFIX02&selectValueTeam=21&displayName=%EF%BC%AA%EF%BC%91%E3%83%AA%E3%83%BC%E3%82%B0&displayNameTeam=%E5%B7%9D%E5%B4%8E%E3%83%95%E3%83%AD%E3%83%B3%E3%82%BF%E3%83%BC%E3%83%AC"
html = requests.get(url)
soup = BeautifulSoup(html.text, "html.parser")
base = soup.find("div",class_="pd10-box") #検索結果一覧
データを入れるCSVファイルを作ります。
また、ヘッダー部分を作ります。
player-kawasaki.py
f = open('python-soccer/kawasaki.csv', 'w')
writer = csv.DictWriter(f, ['背番号','名前','ホームグロウン','新卒・新加入',' ポジション','生年月日','身長','体重','出生地','国籍','前所属チーム','Jリーグ通算出場(J1/J2/J3)','Jリーグ通算得点(J1/J2/J3)','Jリーグ初出場','Jリーグ初得点'])
writer.writeheader()
各選手の情報を辞書に入れていきます。
選手によって情報に抜けがあるので、tryを使うなど試行錯誤しました。
player-kawasaki.py
for div_player in base.find_all('div',class_='box-info register-list'):
# 背番号・名前 取得
p_name_tags =div_player.find('p',class_='name')
p_name_tags_tx = p_name_tags.text
p_name_tags_array = p_name_tags_tx.split('\n') #改行ごとに配列に入れる
player_number = p_name_tags_array[1].strip()
player_name = p_name_tags_array[2].strip()
if '新加入' in p_name_tags_array[4]: #'ホームグロウン'ありなしで配列の位置がずれるため
player_new = p_name_tags_array[4]
player_homegrown = ''
else:
player_homegrown = p_name_tags_array[4]
player_new = p_name_tags_array[5]
#1~10の要素取得
dl_base_tags = div_player.find('dl',class_='dl-base')
dl_base_tags_tx = dl_base_tags.text
dl_base_tags_array = dl_base_tags_tx.split('\n') #改行ごとに配列に入れる
player_position = dl_base_tags_array[2]
player_birthday = dl_base_tags_array[4]
player_h_w = dl_base_tags_array[6].split('/') #身長と体重を分割
player_height = player_h_w[0]
player_weight = player_h_w[1]
player_place_birth = dl_base_tags_array[8]
#以降、要素が抜けている場合があるのでtry文で条件分け
try:
i = dl_base_tags_array.index('5')
except:
player_nation = '日本'
else:
player_nation = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('6')
except:
player_before_team = ''
else:
player_before_team = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('7')
except:
player_participation = ''
else:
player_participation = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('8')
except:
player_goals = ''
else:
player_goals = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('9')
except:
player_f_p_day = ''
else:
player_f_p_day = dl_base_tags_array[i+1]
try:
i = dl_base_tags_array.index('10')
except:
player_f_g_day = ''
else:
player_f_g_day = dl_base_tags_array[i+1]
player_info = {
'名前': player_name,
'背番号': player_number,
'ホームグロウン':player_homegrown,
'新卒・新加入':player_new,
' ポジション':player_position,
'生年月日':player_birthday,
'身長':player_height,
'体重':player_weight,
'出生地':player_place_birth,
'国籍':player_nation,
'前所属チーム':player_before_team,
'Jリーグ通算出場(J1/J2/J3)':player_participation,
'Jリーグ通算得点(J1/J2/J3)':player_goals,
'Jリーグ初出場':player_f_p_day,
'Jリーグ初得点':player_f_g_day,
}
writer.writerow(player_info) #for文終了
f.close()
感想・反省
かなり試行錯誤しましたが目標のデータを作成することができて満足ですね。
今回は辞書に入れていきましたが、それが最適だったかは疑問です。
またデータに抜けがあったので条件分岐が増えてしまい、冗長なコードになってしまいました。もっと簡素に書ける方法を模索したいです。
今後、スクレイピングする人の少しでも参考になれば幸いです。
参考
- 同じようにJリーグデータサイトからスクレイピングしている方の記事
- 【Python】Beautiful Soupを使ってJリーグ選手の情報をスクレイピングしてみる
- [Python]2018年Jリーグの得点データをスクレイピングして描画してみる[ジョー編]