
🏆優勝しました!
縁あって、松尾研LLM開発コンペ2025に、チームRAMENのデータ班として予選立ち上げから参加し、決勝優勝しました。
そこでの活動について、論文ではなく物語形式で、由なし事を書き綴っておこうと思います。
この記事で得られるであろう知見
評価結果を個別視点で観察することにより得られる気付き
- データ作成視点での、2025年のLLM開発の実際と課題
- モデル開発におけるデータ作成と評価の立ち位置
はじめに
松尾研LLM開発コンペ2025とは
松尾研LLM開発コンペ20251とは、
最難関のベンチマークとされる Humanity’s Last Exam (HLE)2 において、
オープンモデルのLLMとして最高性能(SOTA)の達成を目指すコンペティションです。
予選を突破した我々チームRAMENを含む3チームは、既存の大規模言語モデル(LLM)に対して事後学習を行い、高次の推論能力を備えた reasoningモデル の開発に取り組みました。
チームRAMENの開発体制と担当領域
決勝戦におけるチームRAMENは、データ班 → モデル班 → 評価班 → データ班 というPDCAループで開発を進めました。
私はその中で、データ班目線で評価結果の分析を行いました。
モデルとデータ
まずは予選に使ったモデルを改めて評価しました。
以下の内容で学習したモデルです。
| ベースモデル | Qwen3-235B-A22B3 |
|---|---|
| 学習手法 | Chain-of-Thought Supervised Fine-Tuning (CoT-SFT) |
| 学習データ1 SFT_004_origin_1 | 理論的整合性検証・修正済みSFT用データ完全版(13,554件) |
| 学習データ2 SFT_004_origin_4 | SFT_004_origin_1 から高品質データを抜き出し、さらに理論的整合性が保証されたデータを抽出(1,780件) |
| 評価方法 | Humanity’s Last Exam(HLE)4 |
分析
Viewerの作成
評価結果はjson形式で取得します。
それにHLEの評価コードを元に問題のカテゴリーや問題の考え方などを付加、さらに1問ずつ見やすいよう閲覧用html(Viewer)にpythonプログラムで変換しました。
ここでは、左から ①ベースモデル ②学習データ1で学習したモデル ③学習データ2で学習したモデル の評価結果を横並びで閲覧できるようにしました。
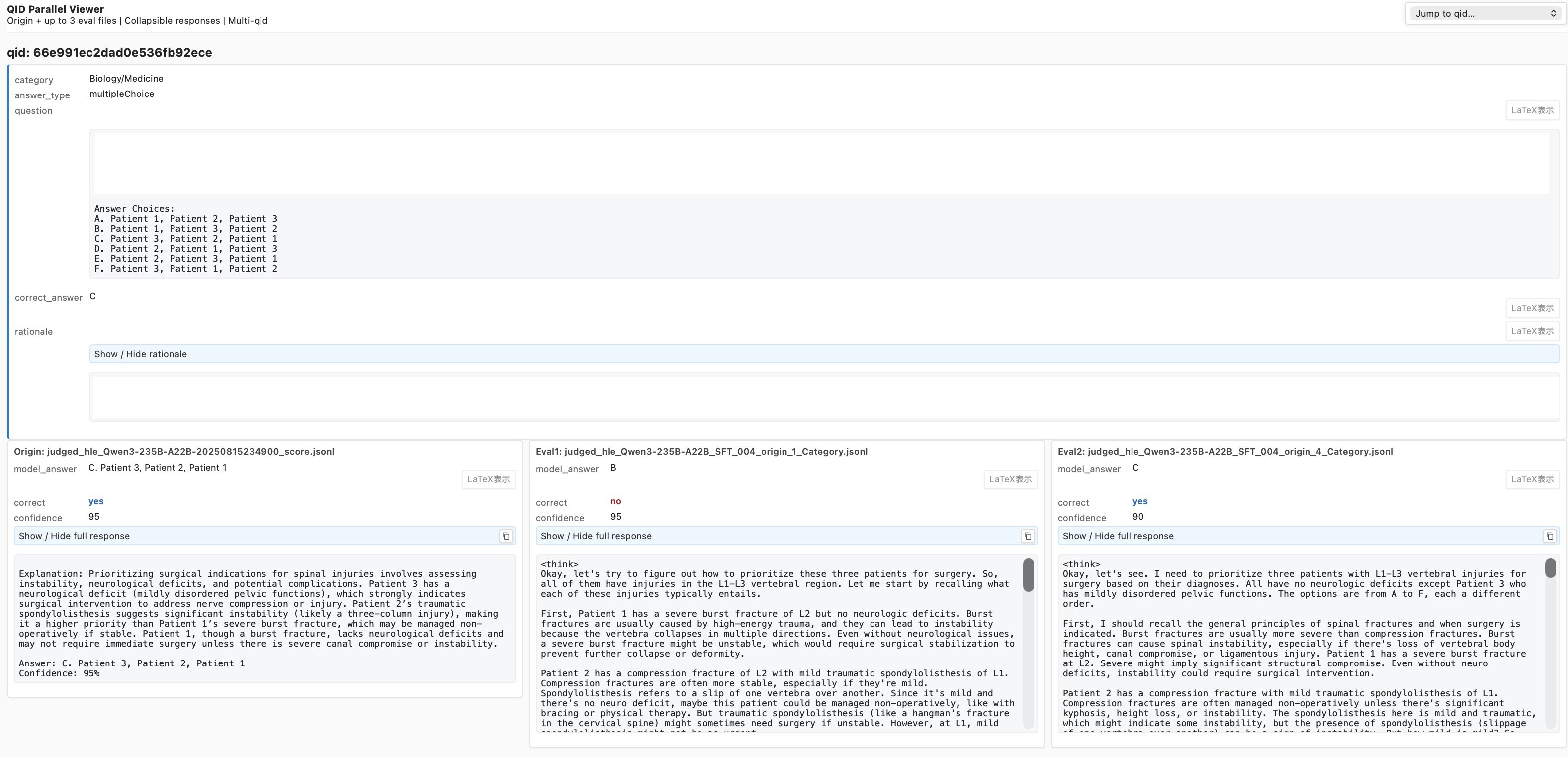
カラーの「yes/no」の文字がHLEによる評価結果で、そのすぐ上に各モデルのanswerが表示されています。
ベースモデルでは選択肢の文字以外に余計な記述が見られるのに対して、SFT後のモデルは選択肢の文字だけを出力している、つまりより好ましい回答形式になっていることが確認できます。
また、モデルによっては答えがベースモデルよりも悪くなっている事象も観察できます。
下段の文字列は、それぞれのモデルの思考過程です。
今回の分析は、①モデル間の正解/不正解の変化、そして②この思考過程を個別に観察することで、学習したモデルで具体的に何が起こっているのか、つぶさに観察することが目的です。
分析対象
分析にはHLEによる評価結果が不一致となった問題を抽出しました。今回は小さなサブセット(120問)での評価結果を使用しています。不一致となった分析対象は27問でした。
| in1 | in2 | in3 |
|---|---|---|
| モデル1 | モデル2 | モデル3 |
| ベースモデル | データ1(SFT_004_origin_1)でSFTしたモデル | データ2(SFT_004_origin_4)でSFTしたモデル |
評価結果の比較
こちらは、ベースモデルに対してSFT後のモデル(モデル2)の正解数の変化をカウントしたグラフです。
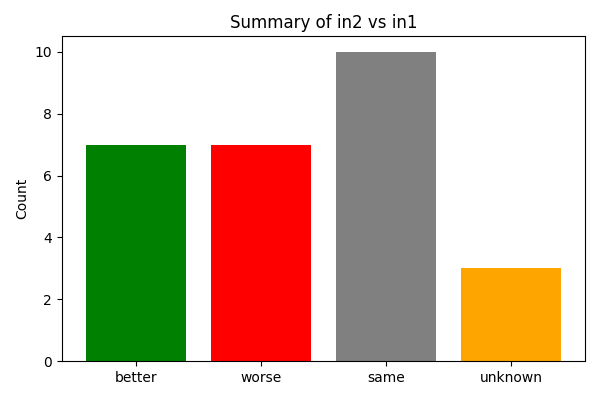
unknownはどちらかの評価結果に欠損があるデータです。sameはこの比較では評価結果が変わらないが他の比較で差が出た問題です。
集計すると改善も改悪もしていないことになります。
こちらも、ベースモデルに対してSFT後のモデルの正解数の変化をカウントしたグラフですが、モデル3の場合です。
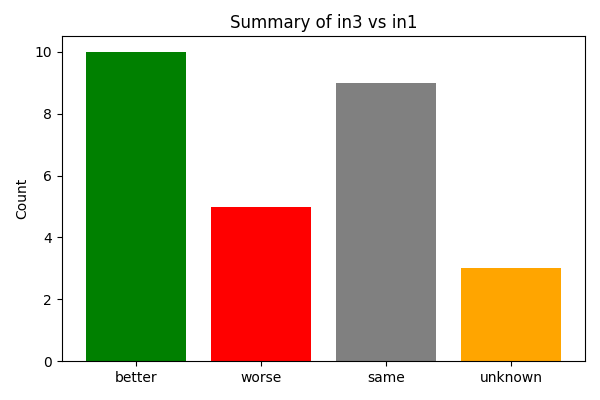
モデル3ではbetter(正解数の増加)が、worse(不正解の増加)を上回っており、集計するとSFTの効果が出ていると読み取れます。
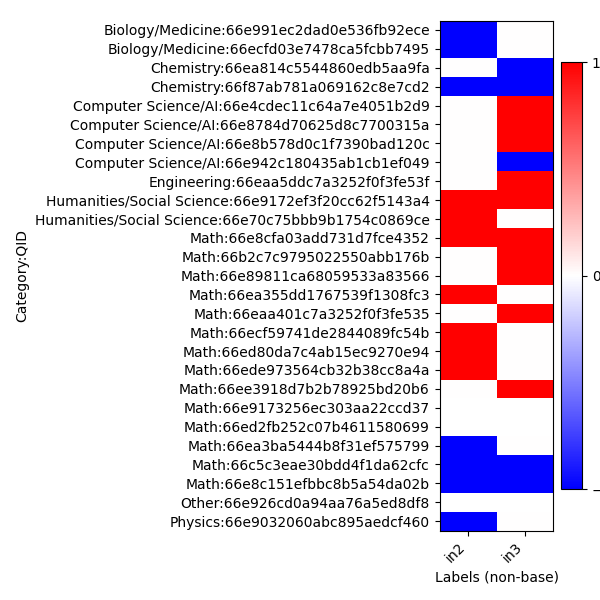
こちらは、どのようなカテゴリーの問題で、正解・不正解の変化があったのかをヒートマップで示しています。赤がbetter、青がworseです。
ちなみに120問のカテゴリーの分布は以下の通りです。
半分近くが数学です。
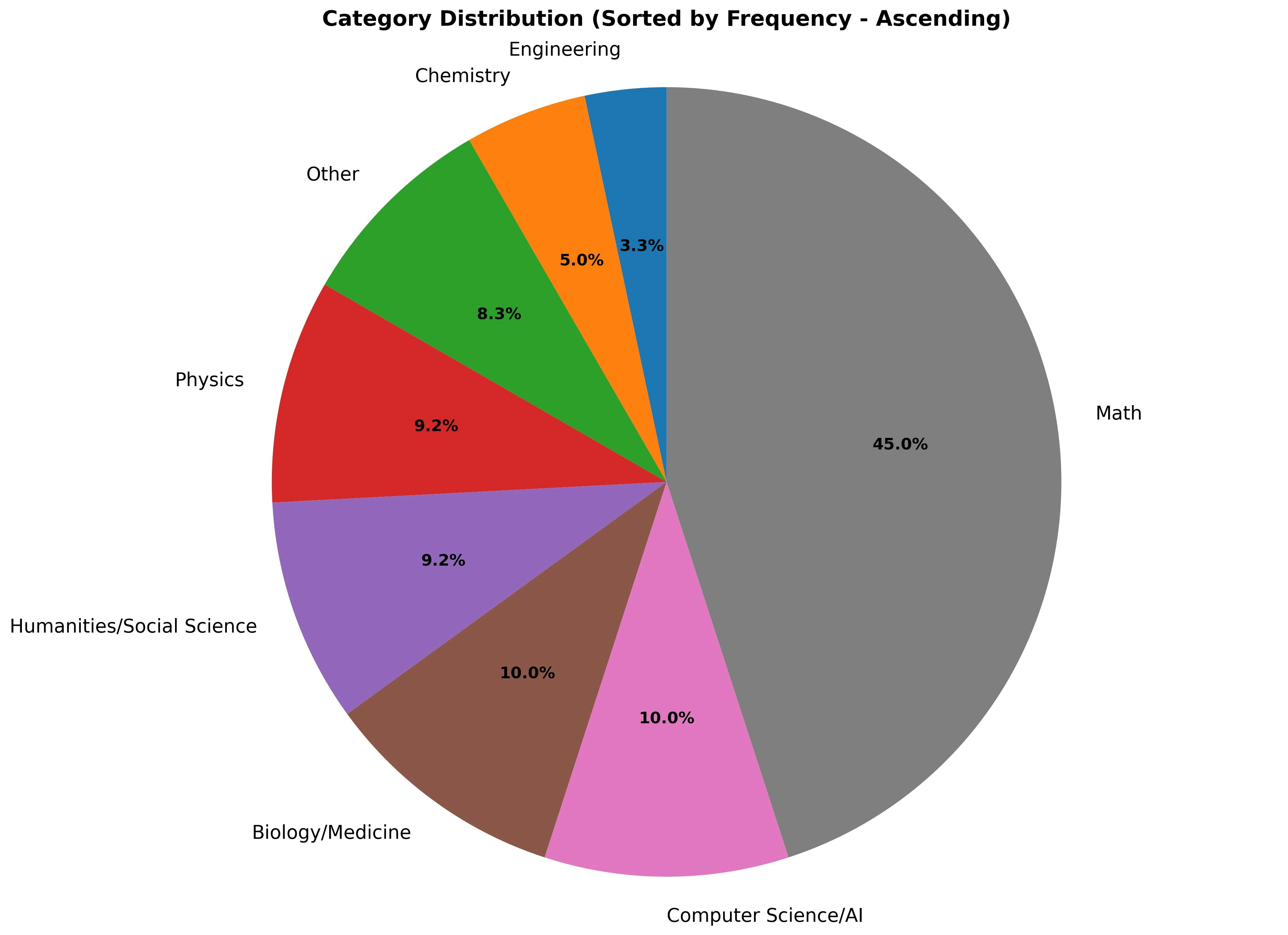
ヒートマップとカテゴリーの分布から、以下のような特徴が読み取れます。
- Mathは問題数が多い割には正解総数の変化が少ない。
- Mathは改善できた問題がモデル2とモデル3で違う。
- モデル3では Computer Science/Al が改善している
詳細分析
以上の基本事項を踏まえ、さらに先ほどのViewerで思考過程を中心に観察しました。
1)モデル3がComputer Science/Alで改善効果を上げている理由〜数学の強化
改善した問題を見ると、内容として数学分野での改善が見られる。
- ディープ・ニューラル・ネットワークで使用するsigmoid関数への式変型 = 数学
- ランゲージ・モデルの計算コスト算出 = 数学
- ディープ・ラーニングにおけるロス関数の類似性 = 数式の比較
2)モデル3だけComputer Science/Alの知識問題で間違えた理由〜考えすぎ
qid:66e942c180435ab1cb1ef049の問題は知識問題で、数学分野での改善が見られるモデル3だけ不正解でした。思考過程を確認すると以下のことがわかりました。
- 元のモデルには正解の知識があり一旦は答えにたどり着いたが、さらに思考を続けることで間違った答えに至っていました。
3)モデル3だけ正解したEngineeringの問題とは〜まぐれ当たり
qid:66eaa5ddc7a3252f0f3fe53fの問題はフェライトの問題で、特性グラフまたはグラフを記憶している関数電卓を使用しなければ解けない問題でした。しかし、思考に特性グラフを使用した形跡が無く、適当な概算がたまたま当たった模様。(概数によるまぐれ当たり)
4)モデル2の幅広さ
モデル2は、ネガティブな効果ではあるが、医学や物理学など、モデル3よりも幅広い分野に学習の影響を与えていました。
- qid:66e991ec2dad0e536fb92ece:医療(外科)
- qid:66ecfd03e7478ca5fcbb7495:医療(遺伝子)
- qid:66e9032060abc895aedcf460:物理(気象学)
5)Humanities/Social での改善〜因果関係の学び
いずれのモデルも人文社会学(qid:66e9172ef3f20cc62f5143a4)での改善が見られました。
- 年号から金融恐慌を連想し、サブプライムローンの問題を関連づけ、因果関係の方向を適切に判断する必要がある問題でモデル2とモデル3が正解
- 幅広いデータで学習したモデル2が正解するのは想像がつくが、なぜより数学と推論に特化したモデル3も正解できたのか?
- 因果関係の概念を学んだ?
【モデル3の思考過程】
この期間にノンエージェンシーRMBSの価値下落をもたらした根本原因は、主として借り手の信用力の低さである。平均FICOスコア(C)は借り手の信用品質の主要な指標であり、FICOが低いほどデフォルト確率は高く、RMBSの価値を直接押し下げる。調整金利型(B)や実際のデフォルト率(E)は重要ではあるものの、いずれも初期の低品質ローンに根差した「結果/触媒」に過ぎない。FICOスコアは発行時点の潜在的リスクを反映するため、RMBS価値の根本的な決定要因となる。
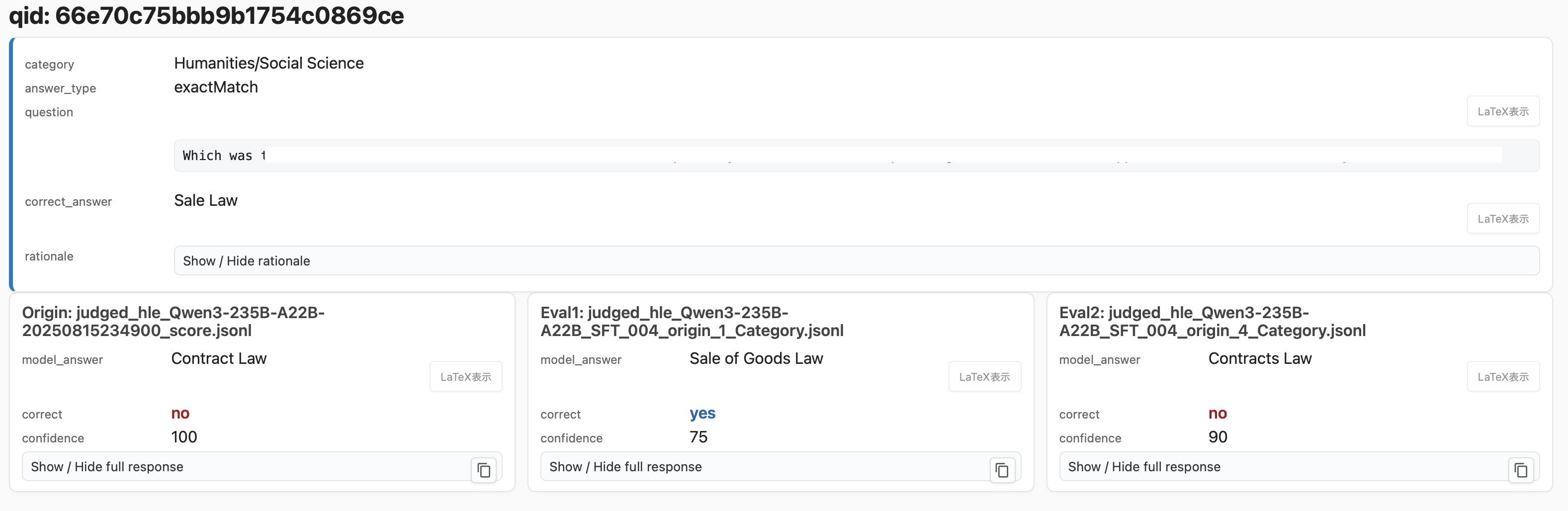
6)人文社会学での採点ミス
モデル2が「Sale Law」(=イスラエルの法律5)と「Sale of Goods Law」(=イギリスの法律)を混同して回答しているのに対して、誤って正解が与えられていました。
HLEの評価プログラムは、主にexactMatch(答えが完全一致)の問題形式における表記揺れを吸収するためにLLMを使用しており、このLLMが過大に解釈を広げすぎたことが原因と考えられます。
7)検算の重要性
Chemistry(qid:66ea814c5544860edb5aa9fa)では、モデル3だけが誤答しています。
溶解度と電荷収支の問題で、モデル1が539単語で推論しているの対して、モデル2は5973単語、モデル3は4148単語と約10倍前後の思考過程を費やしています。
また、最初に平衡式が提示されており、回答候補を算出後に元の式に代入すれば検算ができるような問題でしたが、検算せずに最終回答をしています。これが人間の子供だったら「テスト中に時間が余ったら検算しましょう」って言われると思います。
8)ドメインの暗黙値の重要性
Physics(qid:66e9032060abc895aedcf460)では、モデル2だけが不正解になっていました。この問題は竜巻が発生しにくいパラメーターを計測結果から抜き出す問題で、各パラメータの正常値がわかっていれば即答できる問題でした。
モデル1がたった82単語で正解を出しているのに対して、モデル2は3918単語、モデル3は2810単語を思考過程に費やしていました。モデル3は熟考の末に正解しましたが、それでもあまりに非効率ではないでしょうか。
振り返り
SFT後のモデルはいずれもベースモデルと比べて思考過程が長くなっていますが、8)の例のように推論過多の兆候が見られました。
- 思考手順を詳しく書く(推論)訓練により、ドメインの暗黙値が軽視されたのではないか → ドメインの暗黙値は恐らく学習済みなので、それを壊さずに推論を強化する方法が必要か?
- SFT後のモデルはどちらのモデルも「let's try to…」「so I need to…」で問題を解き始めているので、暗黙知を使う逃げ道がふさがれているのかも → 推論と暗黙値を両立すべき問題ではどのように思考を始めれば良いのか?
- 小学生は公式の証明ができなくても円の面積を答えられる → 完璧な推論ができなくても答えを優先できる逃げ道を適切に与える必要があるのでは?
…と、以上のようなことが浮かんできました。
いずれにしても、個々の思考過程を観察すると、様々なドラマがそこにありました。
時にそれは、まやかしのドラマであり、勘違いのドラマ、考え過ぎのドラマ、うっかりさんのドラマ、偶然のドラマであったりもしました。
次回予告
6)の採点ミスは、これで終わりませんでした。このあと、評価用LLMに翻弄されていたことが、だんだんとわかってくるのです。
評価結果の評価
モデルを評価していくにつれて、同じモデルを評価するたびに正解する問題が大きく入れ替わるという現象が表面化し始めました。予選でも、高評価だったモデルの成績が、運営側の評価で伸びないということもありました。また、データ班の中でも先のViewerを使用して、正解判定の甘すぎる評価事例を複数発見していました。
最初は「正解が入れ替わっても一定の割合をキープしているのであれば、問題ないのでは」とか、「評価が甘い方向であれば、嬉しい方向では」とか軽い気持ちで考えていたのですが、この評価結果のばらつきが、終盤になってモデルの選定に影響を与え始めました。
特に、予選で高評価だったモデルの成績が、運営側の評価で伸びなかったことについては、モデルの汎化性能の問題と捉えていましたが、評価結果のばらつきがそれを助長している可能性も考えられます。
ばらつきの原因としてはモデル側の安定性と評価側の安定性の両方が考えられます。
評価班でも早いうちからこの現象に注目し、評価時のtemperatureを低くしたり複数回評価するなど、精力的に解決を図って頂きました。
その一方で、評価ステップで何が起きているのか、別の視点で評価結果を検証してみることにしました。
検証方法
HLEの問題は記号を選択するmultipleChoice(選択問題)と値を記述するexactMatch(完全一致問題)に分けられます。ここで、multipleChoiceの答えが記号でなくても内容が合っていたり、exactMatchの答えに表記揺れがあっても正解とするために、評価にLLMが利用されており、回答には幅を持たせています。
これを、本来の完全マッチだけで回答の正誤を判定するように戻し、HLEの評価プログラムがLLMを使い正誤判定した結果(予測)と比較することで、評価プログラムの評価傾向を間接的に測定することとしました。
混同行列(Confusion Matrix)の定義
結果の整理には混同行列(Confusion Matrix)を使っています。
HLEの評価は予測とは厳密には違いますが、ここでは完全マッチの結果を正解(行方向)、HLEの評価結果を予測(列方向)として整理しています。
$$
\begin{array}{c|cc}
& \text{HLE(x)=1} & \text{HLE(x)=0} \\
\hline
\text{Truth(x)=1} & TP & FN \\
\text{Truth(x)=0} & FP & TN \\
\end{array}
$$
$完全マッチによる判定:Truth(x) =
\begin{cases}
1, & \text{完全マッチで正解の場合} \\
0, & \text{完全マッチで不正解の場合}
\end{cases}
$
$HLEの評価結果:HLE(x) =
\begin{cases}
1, & \text{HLE評価で正解と判定された場合} \\
0, & \text{HLE評価で不正解と判定された場合}
\end{cases}
$
$True Positive:TP = |{x \mid Truth(x)=1 \land HLE(x)=1}|$
$False Positive:FP = |{x \mid Truth(x)=0 \land HLE(x)=1}|$
$False Negative:FN = |{x \mid Truth(x)=1 \land HLE(x)=0}|$
$True Negative:TN = |{x \mid Truth(x)=0 \land HLE(x)=0}|$
モデルとデータ
| ベースモデル | Qwen3-235B-A22B-Thinking-25076 |
|---|---|
| 学習手法 | Direct Preference Optimization (DPO) + LoRA |
| 学習データ SFT_006_origin_1 | SFT_004_origin_1を元にした次期フルバージョン(11,004件) |
| 評価方法 | Humanity’s Last Exam(HLE)4 LLM vs 完全マッチ |
評価対象
| モデル1 | モデル2 |
|---|---|
| ベースモデル | SFT_006_origin_1 でDPO(2epoch)したモデル |
モデル1 評価結果
| 評価問題数 | 2122問(multipleChoice:512問 + exactMatch:1610問) |
|---|
multipleChoice問題のみを対象に測定
multipleChoice問題では次のようなことがわかりました。
- 5件がLLMで救済されている(FP)
- そのうち誤って救済されたのは4件
- 残りの1件は、選択肢ではなく選択肢の内容を回答しているため救済されているように見える

exactMatch問題のみを対象に測定
exactMatch問題の場合は、回答が数字や分数、数式、LaTeXなどで表現されるため、LLMによる救済(FP)が一定数必要になります。
問題は完全マッチしているにも関わらず、HLEの評価プログラムが不正解としている問題(FN)が4問あるということです。割合としては完全マッチの176問中4問、つまり3%にも満たない数字ですが、約0.2ポイント分モデルの評価が不当に下がっていることになります。
これは、検証時の完全マッチにおいて、文字列の両端のスペース文字や$の削除を行う簡単な正規化処理を行なったためだと考えられます。逆に言うとこの程度の違いこそLLMで救済して欲しいものです。
そして、気になるのが救済(FP)のサジ加減です。正解判定の4割近い数が救済による正解です。これが公平で安定していないと、評価の精度に疑問が残ることになります。
実際に、3回同じ評価をして1回だけ評価が低かったモデルを確認すると、TPは減っていないのにFPが急減していたということもありました。これが、モデルの問題なのか評価プログラムの問題なのかまでは、追いきれませんでした。

原因判明?
続いて、モデル2についての評価結果を見てみましょう。
| 評価問題数 | 270/265問(multipleChoice:65問 + exactMatch:205/200問) |
|---|
モデル2のmultipleChoice問題の評価結果です。
SFT後のモデルではmultipleChoiceの回答記述が揺れることはほとんどないので、LLMによる救済(FP)はほとんど採点ミスと考えて問題ありませんでした。
それにしても、綺麗にFPとFNがなくなっています(=0)。
理由はHLEの評価に使用するLLMをchatGPT5-nanoからchatGPT5-miniに変更したためと考えられます。
ただ何もしないのと同じですが、評価精度が100%に上がりました。

サンプル数が1/10近くまで小さくなっているので、元がFP=5だと0になる可能性も高いという疑いがありますが、他の評価結果を確認してもほとんどがFP=0でした。
こちらはモデル2のexactMatch問題の評価結果です。
それほど変わったことはないように見えますが、3回の評価では、完全マッチ(TP)が19〜22の間でしか変化しないのにも関わらず、LLMによる救済(FP)は ( 7, 16, 19 ) と大きく変化しました。
サンプル数の問題もありますが、まだ安定した評価結果にはなっていないようです。
最近の話を聞くと、chatGPT5よりもchatGPT4oの安定感を評価する声もちらほらと聞きます。今更ですが、5-miniを通り越して4o-miniを提案しても良かったのかもしれません。



ここまでの全体を通しての印象としては、評価には2,000件程度の数が必要だということです。そして、全てが終わって今更思うのですが、評価では最初に負荷がかからない完全マッチ法で、学習データの吟味や、ハイパーパラメーターのテストを高速に何度も行ない、これぞというモデルについて、評価として安定した結果が得られるHLE2,000件を実施するのが勝ち筋だったのかもしれません。そうでなくても、300問程度であれば人手による採点という選択肢もあったかもしれません。
追加の興味〜Aha moment
Aha moment(アハ・モーメント)とは、難しい問題の解決策や、それまで分からなかったことの答えが突然ひらめく瞬間、つまり「あっ、そうか!」という洞察や発見の体験を指します。
LLMの推論過程でもAha momentが発生していることが知られており、DeepSeekの論文でも以下のような形で注目されています。7。
The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems,
paving the way for more autonomous and adaptive models in the future.
一方で例えば、初めに分析した2)モデル3だけComputer Science/Alの知識問題で間違えた理由〜考えすぎ の例では、不要なAha momentにより誤った回答に辿り着いてしまうという、ネガティブな側面も観察されました。
思考過程の日本語訳と原文です。答えである「TC⁰」を通り越しています。
二値アクティベーションとハードアテンションを持つトランスフォーマーは、しきい値回路(threshold circuit)と同等かもしれません。
多項式サイズ・定数深さのしきい値回路(TC⁰)は、AC⁰ではできないMAJORITYのようなことも計算できます。
したがって、もし各層がステップ関数のようなしきい値ゲートを使うなら、そのモデルはTC⁰に属する可能性があります。
でも、問題文にはfloat activationsとある。もしアクティベーションが実数値なら、もっと複雑な関数が計算できるかもしれない。
しかし、最終的な判定が閾値に基づくなら、回路複雑性は依然として同じはずだが……
いや、もしかしてもっと上、P/polyかもしれない。
If the activations are saturated (like binary), then the entire computation is digital.
A transformer with binary activations and hard attention might be equivalent to a threshold circuit.
Threshold circuits of polynomial size and constant depth (TC⁰) can compute things like MAJORITY, which AC⁰ cannot.
Therefore, if each transformer layer uses threshold gates (like step activations), then the model could be in TC⁰.
But wait, the question says float activations. If the activations are real numbers, then perhaps the model can compute more complex functions.
Maybe the upper bound is even higher, like P/poly…
Thereforeというキーワードから始まる1文で一旦正解に辿り着いていますが、その直後にBut waitというAha momentのキーワードが続き、正解を通り越して思考を再開しているのがわかります。
そこで、今回の最終モデルとベースのモデルの間で、Aha momentと正解率の傾向を見てみたいと思います。
モデルとデータ
| ベースモデル: T06 | Qwen3-235B-A22B-Thinking-25076 |
|---|---|
| 学習済みモデル: DPO | RAMEN-SHIO-235B |
| 学習手法 | Direct Preference Optimization (DPO) + LoRA |
| 学習データ DPO_mashimashi_widerange_000 | SFT_006_origin_1を元に大幅増強した大学院レベル以上の数理・自然科学・人文社会系の公開/合成データ(4,910件) |
| ベースモデル: T06 | 学習済みモデル: DPO | 共通する問題 | |
|---|---|---|---|
| 評価問題数 | 2,122問 | 1,587問 | 1,570問 |
Aha momentのキーワード
まずAha momentを9つに分類し、それぞれのキーワードを挙げました。(Aha moment キーワード一覧)
ここでは、決め打ちでキーワードを決めましたが、今回のモデルが出力した思考過程そのものを使って重要なキーワードや頻出キーワード、要注意キーワードなどを抽出できるかもしれません。また、思考過程と正解/不正解のラベルから深層学習したモデルで、思考の確からしさを見ることもできるかもしれません。
正解率とAha momentの関係
両モデルとも、正解した問題の方が思考過程も長いので、Aha momentも比例して多くなる傾向が見られましたが、密度は変わりませんでした。
つまり、ahaとahaで挟まれる塊(Reasoning episode または Chunk of reasoning)を長くするのではなく、増やすことで正解にたどりついていることを示してします。
- DPOモデル:
- 正解時の平均Aha moment: 121.15回/問 (2.10 per 1000 chars)
- 不正解時の平均Aha moment: 100.93回/問 (2.09 per 1000 chars)
- 密度: 正解は1.01倍
- ベースモデル:
- 正解時の平均Aha moment: 116.82回/問 (2.08 per 1000 chars)
- 不正解時の平均Aha moment: 99.90回/問 (2.13 per 1000 chars)
- 密度: 正解は0.98倍
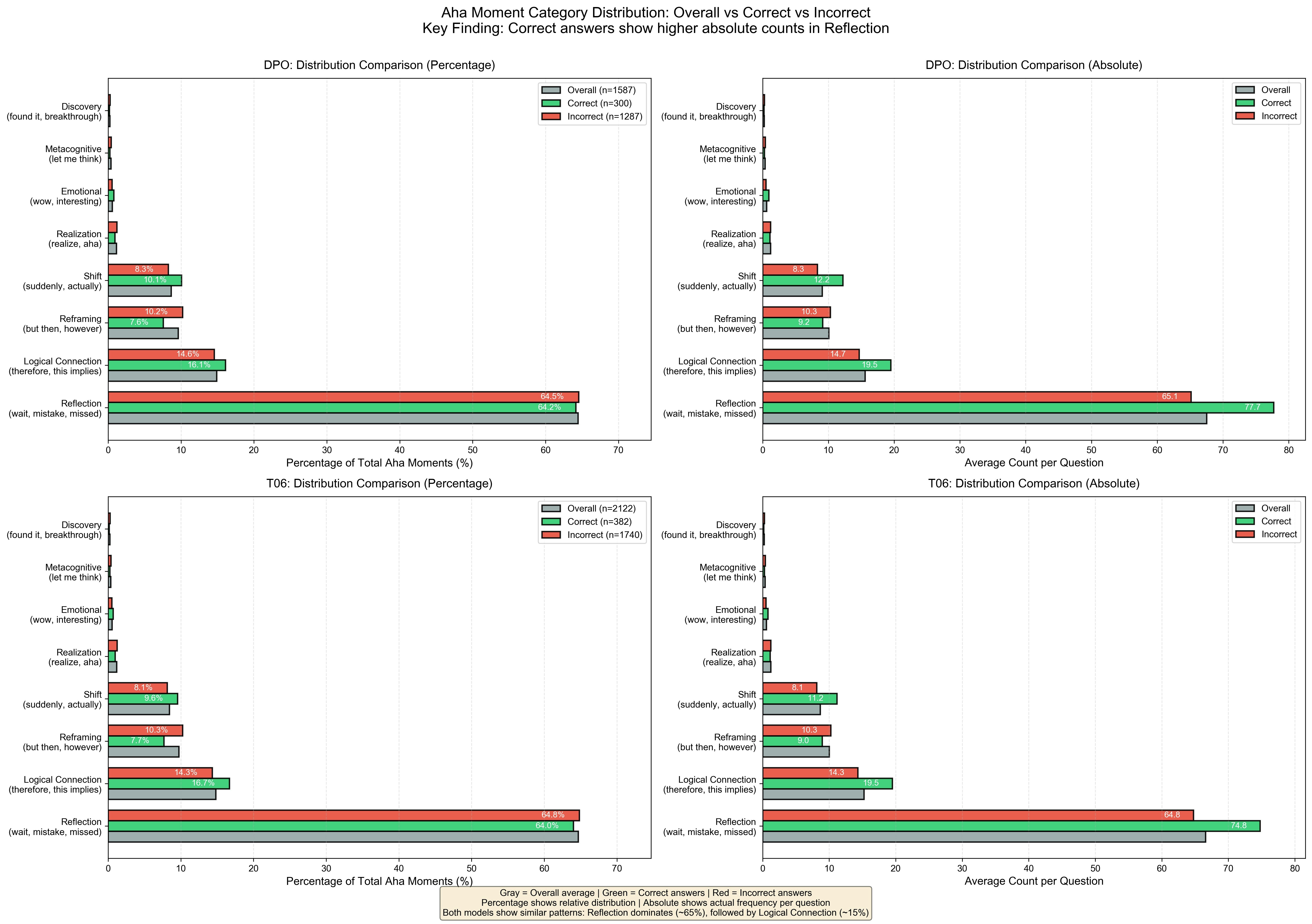
正解時のAha momentのカテゴリー分布
以下のグラフはAha momentのカテゴリー分布です。上段のDPOが最終モデル、下段のT06がベースモデルです。
両モデルともカテゴリの分布は似ており、Reflection (wait, I was wrong など)が最多、次いでLogical Connection (therefore, this implies など)が2番目に来ています。
これは、決め打ちしたキーワードの精度にも左右されるので、正解(緑)と不正解(赤)の間での相対的な変化に着目してください。
興味深いのは、第3位のReframing(however, instead など)が正解した問題では減っています。Reframingとは例えば「この問題は数学の式変形だ」と思って考えていたけど、「いや、これは図形の問題として考えたほうがいい」と気づくような、視点の変更をいいます。
これが減っているということはひょっとすると、「思い直しが少ない=思考が安定している」からなのかもしれません。
つまり、最初にどの枠組みで思考を進めるかという感のようなものが非常に重要で、できるだけ一筆書きでその枠組みの中で推論できた方が、結果的に正解に辿り着く確率が高いと言えるのではないでしょうか。
また、正解した問題では思考量が増えるため、それに比例して右の問題あたりの頻度グラフではAha momentの回数もそれぞれ増えています。
つまり、量(思考の深さ)が重要だが、質(思考のバランス)は一定を保っているといえます。
逆に考えると、推論が増えた時でも質(思考のバランス)を変えないことが、正解への道ではないかと考えられます。
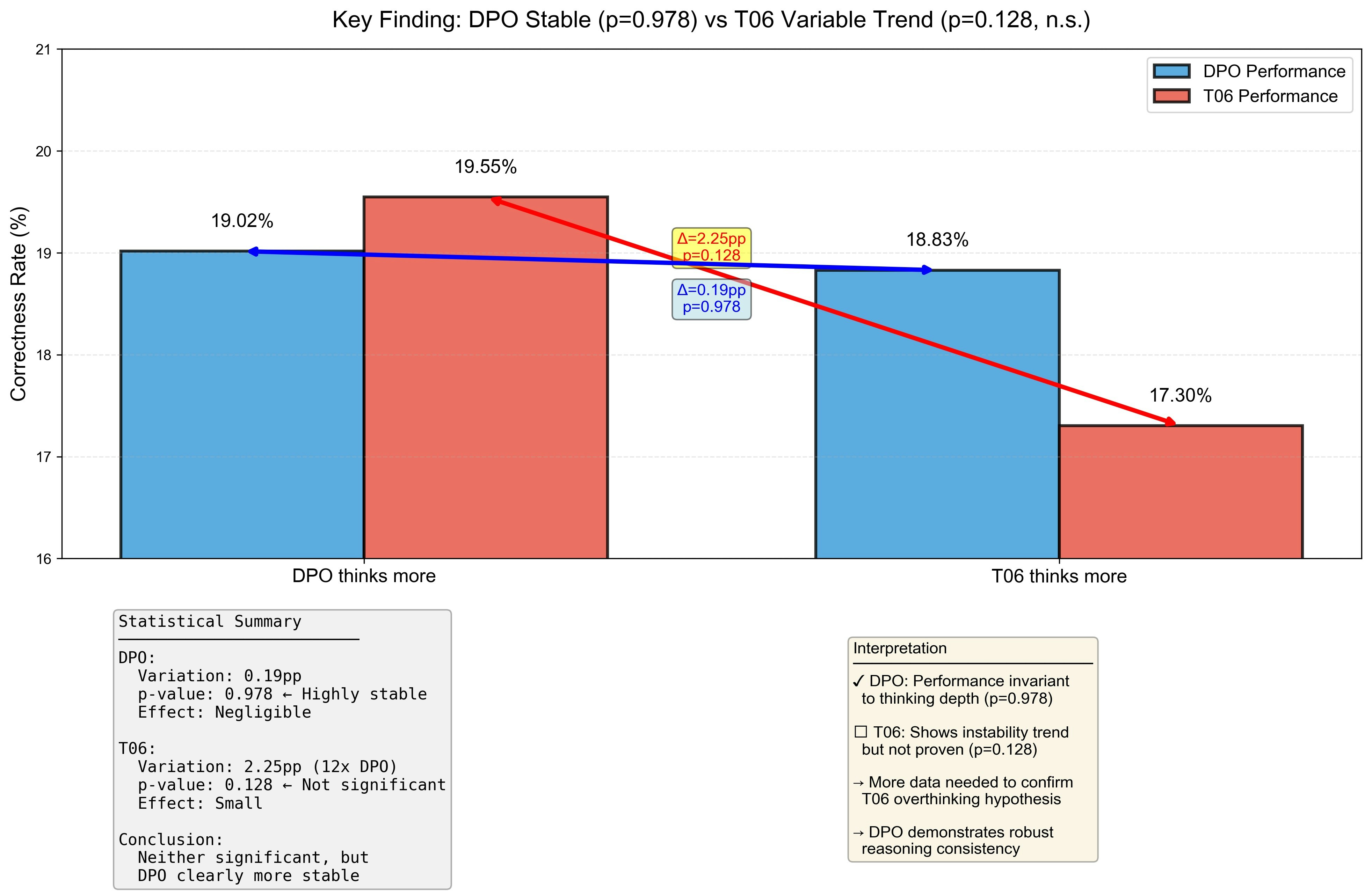
思考量と正解率の関係
最終モデルとベースモデルのAha momentの数は拮抗していますが、以下のグラフでは最終モデルの方がAha momentが多かった場合(左)とベースモデルがの方がAha momentが多かった場合(右)を比較しています。
ここで、差が出てきました。右の赤い部分、つまりベースモデルのAha momentが最終モデルのAha momentより多い問題においては、逆にベースモデルの正解率が2ポイント以上下がっているのです。
これは、最終モデルがベースモデルよりも推論過多になりにくいという特徴を示唆していると考えられます。統計的有意水準(p<0.05)には達しませんでしたが、p=0.128と一定の傾向が見られました。
DPO > T06: 752問 (48.0%) ← グラフの左側で使用
T06 > DPO: 786問 (50.1%) ← グラフの右側で使用
DPO = T06: 32問 (2.0%) ← 使用していない
合計 1,570問
推論の品質が上がれば正解率も上がる
ここでは、Aha momentのキーワードを、正解した思考に含まれるかどうかで、6段階(Positive3段階、Negative3段階)に分けました。
それに3段階ずつの重みをつけて、思考過程内での各キーワードの出現数として合計することで、推論の品質スコア(Quality Score)と定義し、最終モデルとベースモデルで比較を行ったのが次のグラフです。
時間の都合で、残念ながらクローズドのテストになっているところに注意してください(=相関が有意なのは当たり前)。
正のキーワード例(Positive)3段階:
- Tier 1: "hold on", "wait a minute/second/moment", "missed", "wow", "mistake"
- Tier 2: "wait", "in fact", "therefore"
- Tier 3: "instead", "interesting", "obviously"
負のキーワード例(Negative)3段階:
- Tier 1: "this suggests", "let me think"
- Tier 2: "figured out"
- Tier 3: "breakthrough"
quality_score = (positive_tier1 * 3 +
positive_tier2 * 2 +
positive_tier3 * 1 -
negative_tier1 * 3 -
negative_tier2 * 2 -
negative_tier3 * 1)
$
Q = \sum_{i=1}^{3} w_i p_i - \sum_{j=1}^{3} w_j n_j
$
- $Q$: Quality Score(品質スコア)
- $w_i$: 正のキーワードの重み
- $p_i$: 正のキーワードの出現回数
- $w_j$: 負のキーワードの重み
- $n_j$: 負のキーワードの出現回数
具体的な例:
$
Q = w_{\text{wait}} \cdot p_{\text{wait}} + w_{\text{mistake}} \cdot p_{\text{mistake}} + w_{\text{missed}} \cdot p_{\text{missed}} - (w_{n1}
\cdot n_1 + w_{n2} \cdot n_2 + w_{n3} \cdot n_3)
$
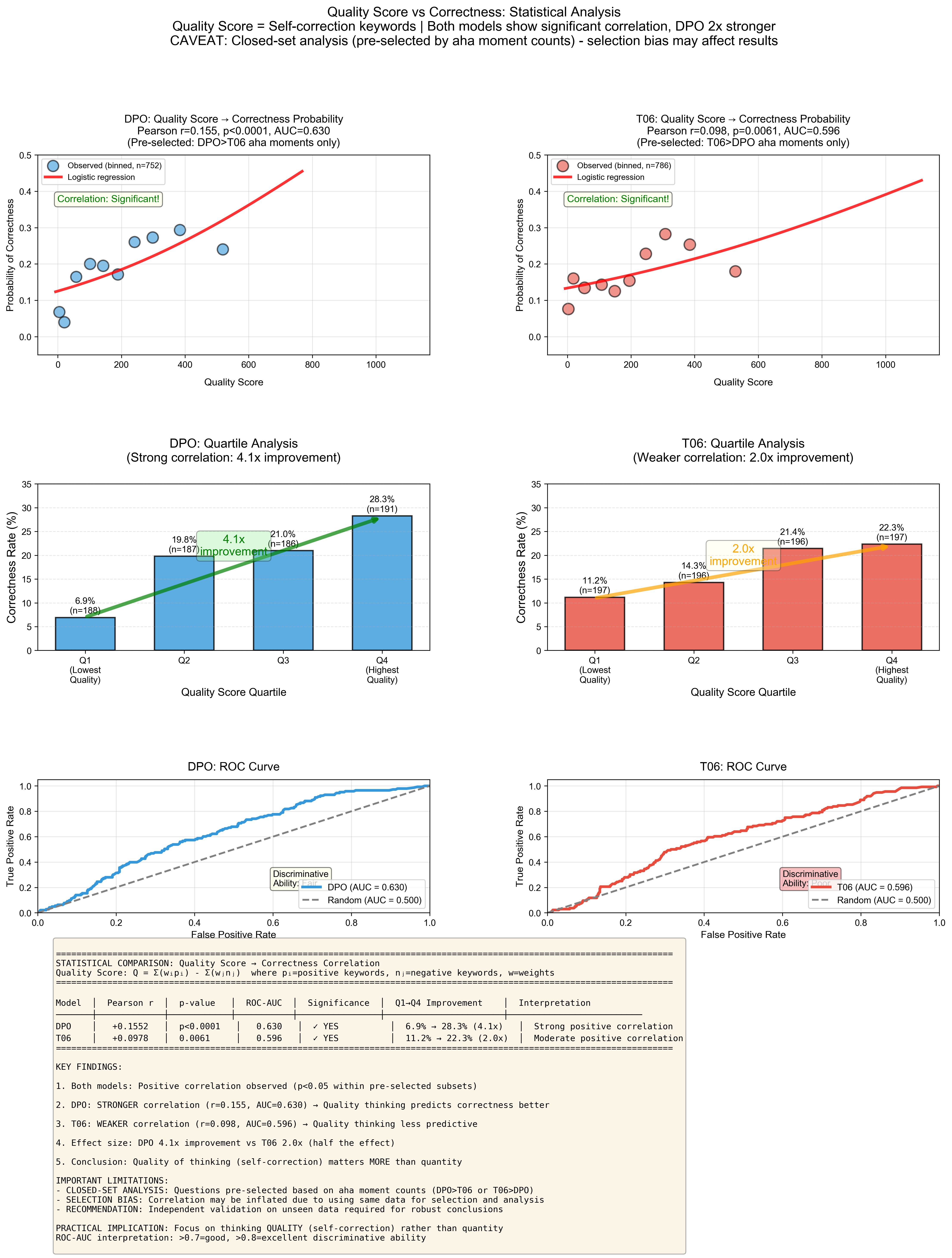
このグラフから、最終モデルはベースモデルと比べて、推論の品質が上がればより正解となる割合も高くなることが読み取れました。
ただし、薄いROC曲線からわかるように、その効果は比較的小さく、現状の品質スコアだけでは正解/不正解を十分に説明できません。また、DPOしたことにより、Aha momentの語彙が先鋭化した(狭くなった)という可能性も考えられます。Aha momentのキーワードを精緻化したり他の要因と合わせて用いる必要があるでしょう。
全体のまとめ
以上、評価結果の個別詳細な分析を基点に幾つかのことを深掘りしてみました。
最後に、我々の最終モデルRAMEN-SHIO-235Bは、安定した高い性能を期待できるという示唆を得ました。
今回のコンペで改めて身に沁みたことが2つあります。
・データ収集は難しい
・評価は大事
最後に、評価精度の検証と評価精度の向上に熱心に取り組み、最終的にチーム全体のPDCAを高速で回すことに貢献した評価班の皆様に、感謝を述べてこの稿をまとめたいと思います。
本プロジェクトは、国立研究開発法人新エネルギー・産業技術総合開発機構(以下「NEDO」)の「日本語版医療特化型LLMの社会実装に向けた安全性検証・実証」における基盤モデルの開発プロジェクトの一環として行われます。
Appendix
Aha moment キーワード一覧
# Anthropic Claude による自動生成
AHA_KEYWORDS = {
# 1 Realization
'realization': [
r'\baha+h?\b',
r'\breali[zs]e[ds]?\b',
r'\breali[zs]ation\b',
r'\bunderstand\b',
r'\bfigure[ds]? out\b',
r'\bnow I see\b',
r'\bI see\b',
r'\boh I see\b',
],
# 2 Shift in reasoning
'shift': [
r'\bsuddenly\b',
r'\bit clicked\b',
r'\bturns out\b',
r'\bactually\b',
r'\bin fact\b',
r'\bwait a (minute|second|moment)\b',
r'\bhold on\b',
],
# 3 Reframing
'reframing': [
r'\bbut then\b',
r'\bhowever\b',
r'\binstead\b',
r'\bon second thought\b',
r'\bon the other hand\b',
r'\brethinking\b',
r'\blet me reconsider\b',
],
# 4 Reflection and self-correction
'reflection': [
r'\bI was wrong\b',
r'\bwait[,\.]?\b',
r'\bwait\.\.\.\b',
r'\bno wait\b',
r'\bactually no\b',
r'\bthat\'s not right\b',
r'\bcorrecting\b',
r'\bmistake\b',
r'\bmissed\b',
],
# 6 Logical connection and insight
'logical_connection': [
r'\btherefore\b',
r'\bthis (implies|means)\b',
r'\bthe key is\b',
r'\bthe crucial (point|insight) is\b',
r'\bthis suggests\b',
r'\bthis explains\b',
r'\bnow it makes sense\b',
],
# 7 Emotional markers
'emotional': [
r'\bwow\b',
r'\bamazing\b',
r'\binteresting\b',
r'\bit makes sense\b',
r'\bof course\b',
r'\bobviously\b',
r'\bclearly\b',
],
# 8 Discovery and breakthrough
'discovery': [
r'\bI (got|found) it\b',
r'\bthat\'s it\b',
r'\beureka\b',
r'\bbingo\b',
r'\bbreakthrough\b',
r'\bdiscovered\b',
r'\bnoticed\b',
r'\bspotted\b',
],
# 9 Metacognitive markers
'metacognitive': [
r'\blet me think\b',
r'\bthinking about (this|it)\b',
r'\bupon reflection\b',
r'\blooking back\b',
r'\bin hindsight\b',
r'\bconsidering this\b',
]
}
-
松尾研LLM開発コンペ2025 https://weblab.t.u-tokyo.ac.jp/lm-compe-2025/ ↩
-
Humanity's Last Exam https://agi.safe.ai ↩
-
Qwen3-235B-A22B https://huggingface.co/Qwen/Qwen3-235B-A22B ↩
-
Humanity’s Last Exam (github) https://github.com/matsuolab/llm_bridge_prod/tree/master/eval_hle ↩ ↩2
-
The World Law Guide | LEGISLATION ISRAEL https://www.lexadin.nl/wlg/legis/nofr/oeur/lxweisr.htm ↩
-
Qwen3-235B-A22B-Thinking-2507 https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507 ↩ ↩2
-
DeepSeek-AI Team. (2025). DeepSeek-R1-Zero: Self-evolving reasoning capabilities emerging from reinforcement learning (Version 1). arXiv. “2.2.4 Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero” https://arxiv.org/abs/2501.12948 ↩