1.はじめに
- この記事は知財系もっと Advent Calendar 2022の記事です。
- 特許は自分(自社)で生み出すだけでなくて、他者(他社)から獲得することも多いです。有名なのはGoogleの事例など。特許の譲渡(assignment)事例はその企業の知財での戦い方も伺うことができるので調べると結構面白い。USPTOは使いやすく特許譲渡データを提供してくれているので、これで遊んでみました。
2.方法(2パターン)
とりあえずデータを入手しようとということで、USPTO関連のサイトを放浪して、以下の2つの方法(API使う、自前でデータベース作成)を検討。
2-1.APIを使う
USPTOのデータ活用のプロジェクトの1つ。各種データをwebAPI経由で取得可能にしてくれています。
詳しくはリンク参照ですが、
- USPTO Office Action Weekly Zips API
- USPTO Enriched Citation API v2
- IP Marketplace Platform API
- USPTO Office Action Text Retrieval API
- Bulk search and download
- OCE - Patent Litigation Cases
などassignmnt以外でも使ってみたいAPIがたくさん。USPTOは太っ腹!
可視化のページもあり見てても楽しい。
その中の「API Services for Patent Assignment Search」
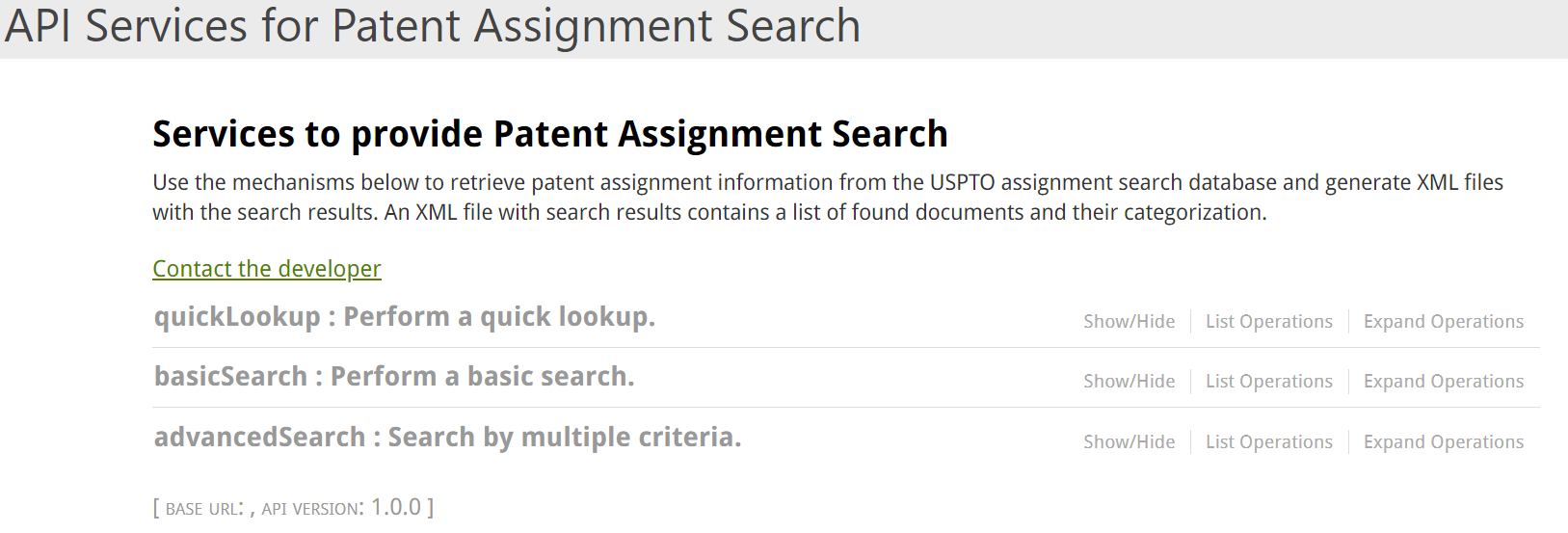
みたところ3種類あるみたい。
-
Simple -Search by query term.とのことで、必須(required)のパラメータはtermとfilter
-
basic -termはsimple番と同じだが、filterできる項目が番号系、譲渡前後の権利者名などある。
-
Advance -Search by multiple criteria.とのことでもっと複雑な条件検索が行える。出願人単位の指定(termが必須項目でない)が可能なので、これを採用。
-
パラメータ指定例
https://assignment-api.uspto.gov/patent/advancedSearch?filter_conveyanceType=ASSIGNMENT%20OF%20ASSIGNORS%20INTEREST&rows=100&priorOwnerName=google
とか
"https://assignment-api.uspto.gov/patent/advancedSearch?&ownerName=tesla&rows=1000"
レスポンス例
<doc>~</doc>が1譲渡の単位。
<doc>
<str name="id">60730-42</str>
<str name="displayId">060730-0042</str>
<str name="reelNo">60730</str>
<str name="frameNo">42</str>
<date name="lastUpdateDate">2022-09-09T12:52:13Z</date>
<str name="purgeIndicator">N</str>
<date name="recordedDate">2022-08-05T04:00:00Z</date>
<str name="pageCount">3</str>
<str name="conveyanceText">ASSIGNMENT OF ASSIGNORS INTEREST (SEE DOCUMENT FOR DETAILS).</str>
<str name="assignmentRecordHasImages">Y</str>
<str name="corrName">MAXVAL GROUP, INC.</str>
<str name="corrAddress1">2251 GRANT ROAD</str>
<str name="corrAddress2">LOS ALTOS, CA 94024</str>
<date name="patAssignorEarliestExDate">2022-08-04T04:00:00Z</date>
<arr name="patAssignorName">
<str>GOOGLE TECHNOLOGY HOLDINGS LLC</str>
</arr>
<arr name="patAssignorExDate">
<date>2022-08-04T04:00:00Z</date>
</arr>
<arr name="patAssignorDateAck">
<str>0001-01-01T00:00:00Z</str>
</arr>
<arr name="patAssigneeName">
<str>GOOGLE LLC</str>
</arr>
<arr name="patAssigneeAddress1">
<str>1600 AMPHITHEATRE PARKWAY</str>
</arr>
<arr name="patAssigneeAddress2">
<str>NULL</str>
</arr>
<arr name="patAssigneeCity">
<str>MOUNTAIN VIEW</str>
</arr>
<arr name="patAssigneeState">
<str>CALIFORNIA</str>
</arr>
<arr name="patAssigneeCountryName">
<str>NULL</str>
</arr>
<arr name="patAssigneePostcode">
<str>94043</str>
</arr>
<arr name="inventionTitle">
<str>METHOD AND SYSTEM FOR WIRELESS CHARGING</str>
</arr>
<arr name="inventionTitleLang">
<str>en</str>
</arr>
<arr name="applNum">
<str>10750593</str>
</arr>
<arr name="filingDate">
<date>2003-12-31T04:00:00Z</date>
</arr>
<arr name="intlPublDate">
<date>0001-01-01T00:00:00Z</date>
</arr>
<arr name="intlRegNum">
<str>NULL</str>
</arr>
<arr name="inventors">
<str>Joseph Patino, Ronald S. Coapstick</str>
</arr>
<arr name="issueDate">
<date>2010-04-27T04:00:00Z</date>
</arr>
<arr name="patNum">
<str>7705565</str>
</arr>
<arr name="pctNum">
<str>NULL</str>
</arr>
<arr name="publDate">
<date>2005-07-21T04:00:00Z</date>
</arr>
<arr name="publNum">
<str>20050156569</str>
</arr>
<int name="patAssignorNameSize">1</int>
<int name="patAssignorNameTypeSize">1</int>
<int name="patAssignorExDateSize">1</int>
<int name="patAssignorDateAckSize">1</int>
<int name="patAssigneeNameSize">2</int>
<int name="patAssigneeNameTypeSize">0</int>
<int name="patAssigneeAddress1Size">1</int>
<int name="patAssigneeAddress2Size">1</int>
<int name="patAssigneeCitySize">1</int>
<int name="patAssigneeStateSize">1</int>
<int name="patAssigneeCountryNameSize">1</int>
<int name="patAssigneePostcodeSize">1</int>
<int name="inventionTitleSize">1</int>
<int name="inventionTitleIdSize">1</int>
<int name="inventionTitleLangSize">1</int>
<int name="applNumSize">1</int>
<int name="filingDateSize">1</int>
<int name="intlPublDateSize">1</int>
<int name="intlRegNumSize">1</int>
<int name="inventorsSize">1</int>
<int name="issueDateSize">1</int>
<int name="patNumSize">1</int>
<int name="pctNumSize">1</int>
<int name="publDateSize">1</int>
<int name="publNumSize">1</int>
<str name="inventionTitleFirst">METHOD AND SYSTEM FOR WIRELESS CHARGING</str>
<str name="inventionTitleLangFirst">en</str>
<str name="applNumFirst">10750593</str>
<date name="filingDateFirst">2003-12-31T04:00:00Z</date>
<date name="intlPublDateFirst">0001-01-01T00:00:00Z</date>
<str name="intlRegNumFirst">NULL</str>
<str name="inventorsFirst">Joseph Patino, Ronald S. Coapstick</str>
<date name="issueDateFirst">2010-04-27T04:00:00Z</date>
<str name="patNumFirst">7705565</str>
<str name="pctNumFirst">NULL</str>
<date name="publDateFirst">2005-07-21T04:00:00Z</date>
<str name="publNumFirst">20050156569</str>
<str name="patAssignorNameFirst">GOOGLE TECHNOLOGY HOLDINGS LLC</str>
<str name="patAssigneeNameFirst">GOOGLE LLC</str>
<arr name="patAssigneePostcodeFacet">
<str>94043</str>
</arr>
<arr name="patAssignorNameFacet">
<str>GOOGLE TECHNOLOGY HOLDINGS LLC</str>
</arr>
<str name="corrNameFacet">MAXVAL GROUP, INC.</str>
<long name="_version_">1743496739211444224</long>
<arr name="patAssigneeNameFacet">
<str>GOOGLE LLC</str>
</arr>
<arr name="patAssigneeCityFacet">
<str>MOUNTAIN VIEW</str>
</arr>
<arr name="patAssigneeCountryNameFacet">
<str>NULL</str>
</arr>
<arr name="patAssigneeStateFacet">
<str>CALIFORNIA</str>
</arr>
<str name="corrNameString">MAXVAL GROUP, INC.</str>
</doc>
- エクセルならWEBSERVICE関数でとれるけどレスポンスがxmlなので苦労しそう、ということでpythonで取得&加工して可視化まで。
1.データ取得:
- 認証とか不要でした。xmltodictとBeautifulSoupと迷ったけど、取得しやすさで後者でやることに
データ取得
import requests
#url = 'https://assignment-api.uspto.gov/patent/advancedSearch?filter_conveyanceType=ASSIGNMENT%20OF%20ASSIGNORS%20INTEREST&rows=100&priorOwnerName=google'
#url = "https://assignment-api.uspto.gov/patent/basicSearch?query=google&rows=500"
#url = "https://assignment-api.uspto.gov/patent/basicSearch?query=battery&filter_ownerName=tesla&facet=false&highlight=false&rows=500"
url = "https://assignment-api.uspto.gov/patent/advancedSearch?priorOwnerName=tesla&rows=500"
res = requests.get(url=url)
####BeautifulSoupで格納
#pip install beautifulsoup#
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,"xml")
#ヒット件数(≠取得件数に注意)
hitcount = soup.response.result["numFound"] #.doc#'result']
hitcount

2.データ加工:
- 全部辞書にしてpandasにつっこむ。他取得したい項目は適宜doc.find_all("arr",attrs={"name":"patAssignorName"}) の部分を追加すればOK
データ処理
assigndic = {}
for doc in soup.find_all("doc"):
for ary in doc.find_all("str",attrs={"name":"id"}):
id = ary.string
#assigndic["id"] = id
assigndic[id] = {}
#print(doc)
for ary in doc.find_all("arr",attrs={"name":"patAssignorName"}):
#print([x.string for x in ary.find_all("str")])
assigndic[id]["patAssignorName"] = "|".join([x.string for x in ary.find_all("str")])
for ary in doc.find_all("arr",attrs={"name":"patAssigneeName"}):
#print([x.string for x in ary.find_all("str")])
assigndic[id]["patAssigneeName"] = "|".join([x.string for x in ary.find_all("str")])
for ary in doc.find_all("arr",attrs={"name":"patAssignorExDate"}):
#print([x.string for x in ary.find_all("date")])
assigndic[id]["patAssignorExDate"] = "|".join([x.string[0:10] for x in ary.find_all("date")])
for ary in doc.find_all("str",attrs={"name":"conveyanceText"}):
#print([x.string for x in ary.find_all("str")])
assigndic[id]["conveyanceText"] = ary.string
for ary in doc.find_all("arr",attrs={"name":"applNum"}):
#print([x.string for x in ary.find_all("str")])
assigndic[id]["applNum"] = "|".join([x.string for x in ary.find_all("str")])
for ary in doc.find_all("arr",attrs={"name":"publNum"}):
#print([x.string for x in ary.find_all("str")])
assigndic[id]["publNum"] = "|".join([x.string for x in ary.find_all("str")])
for ary in doc.find_all("arr",attrs={"name":"patNum"}):
#print([x.string for x in ary.find_all("str")])
assigndic[id]["patNum"] = "|".join([x.string for x in ary.find_all("str")])
3. 集計、可視化
- とりあえず可視化前の状態まで持っていく
集計
assign_df = pd.DataFrame(assigndic).T
assignor = assign_df['patAssignorName'].str.split("|",expand=True).stack().reset_index().drop(columns=["level_1"])
assignee = assign_df['patAssigneeName'].str.split("|",expand=True).stack().reset_index().drop(columns=["level_1"])
assign_df2 = pd.merge(assignor,assignee,on="level_0").rename(columns={"0_x":"patAssignorName","0_y":"patAssigneeName"})
assign_df2 = pd.merge(assign_df.reset_index(),assignee,left_on="index",right_on="level_0")\
.rename(columns={"0_x":"patAssignorName","0_y":"patAssigneeName"})\
.drop(columns=["level_0",0])
中身
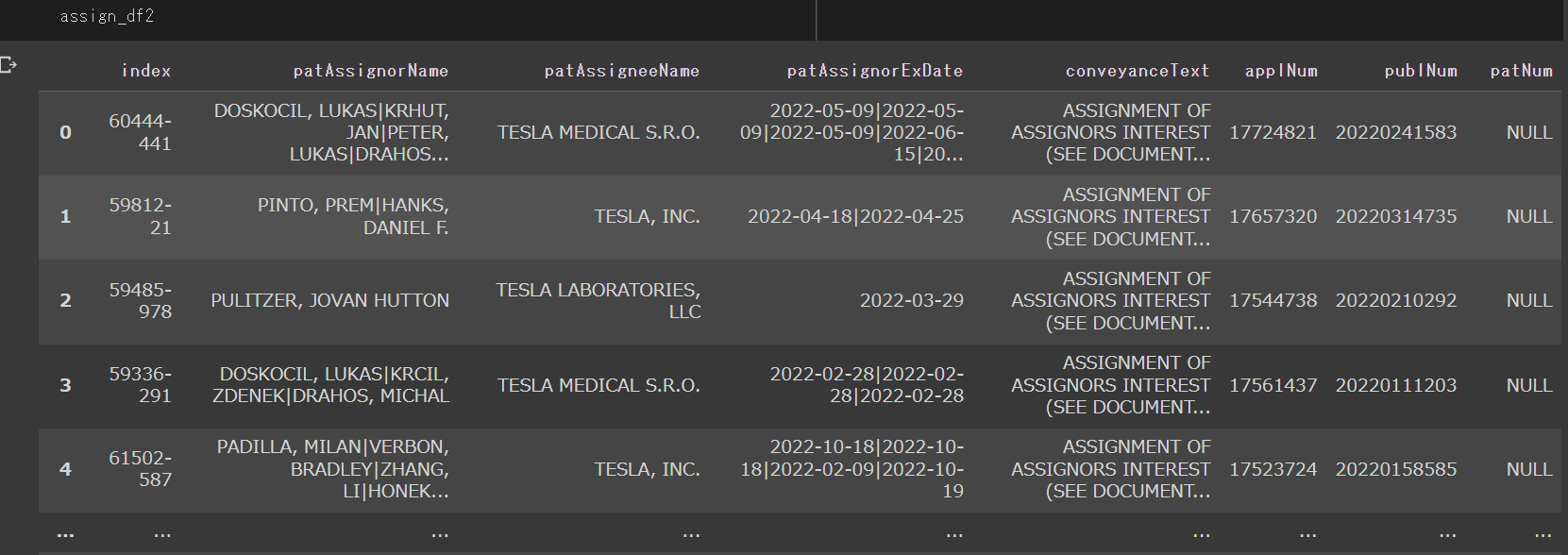
- 譲渡人ランキング
assign_df2[assign_df2["patAssignorName"].str.lower().str.contains(" inc| corp| ltd| llc| univ| limited")]\
[-assign_df2["conveyanceText"].str.contains("CHANGE OF NAME")]\
[-assign_df2["patAssignorName"].str.lower().str.contains("tesla")]\
["patAssignorName"].value_counts()

結構いい感じに取得できた。APIなので、こちらで管理しなくても最新情報をとってくれるのがありがたい。
2-2. 自分でDB作成
もっと自由度高く自分で色々見たい。大量のデータでやってみたい場合のアプローチ。
おなじみbulkdataから、assignment関連のデータを作成する。
- データに2種類あり
(1)普通のassignmentのデータ
Patent Assignment XML (Ownership)
(2)学術研究用に作成してくれたデータ
Patent Assignment Data for Academia and Researchers__
Contains detailed information on roughly 6 million patent assignments and other transactions recorded at the USPTO since 1970 and involving over 10 million patents and patent applications.詳細はここ。
- 今回は(1)を利用。1980年~2021年までのbackfileが20個
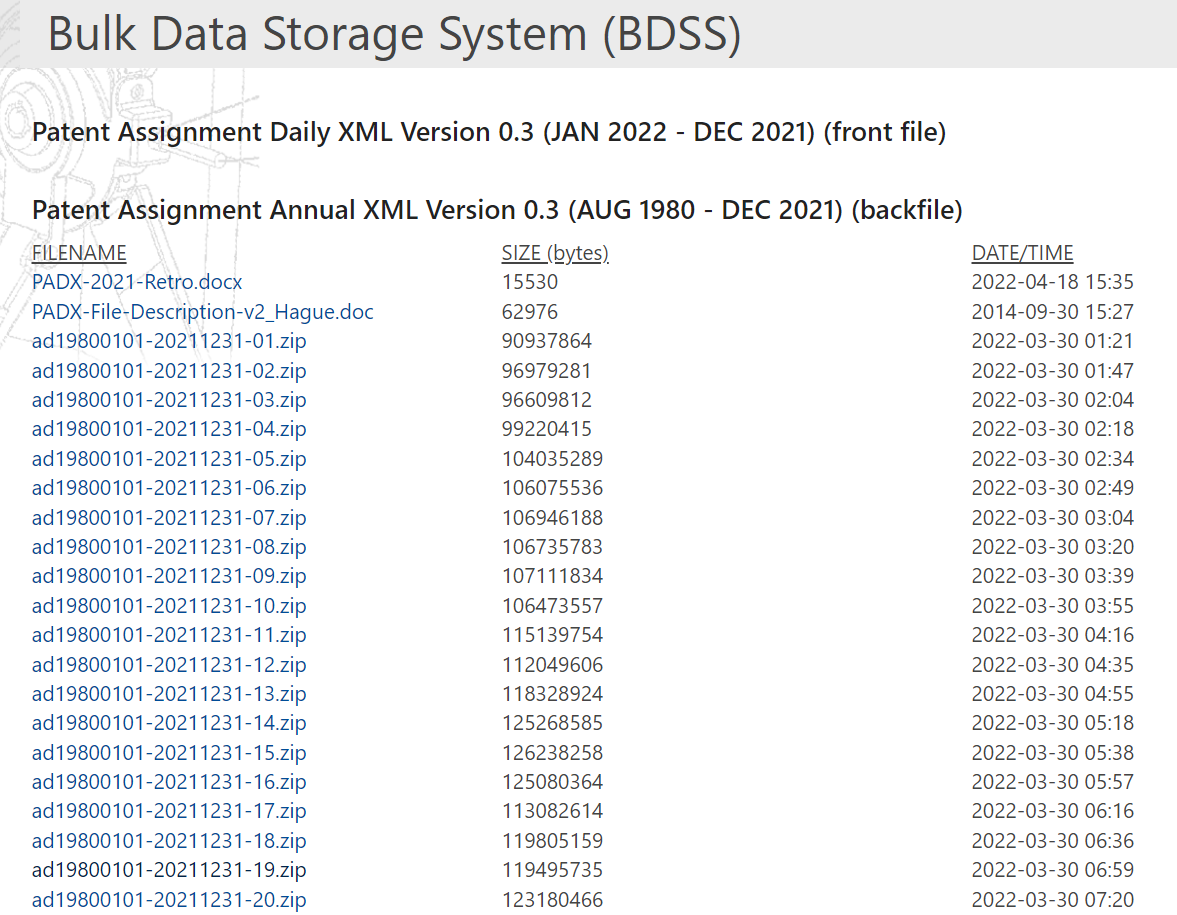
こんな感じで落としてきてunzip
!curl -o ad19800101-20211231-19.zip https://bulkdata.uspto.gov/data/patent/assignment/ad19800101-20211231-19.zip
!unzip ad19800101-20211231-19.zip
xmltodictをかませて辞書形式で必要な部分を抽出していく
※ちなみにBeautifulSoupだとクラッシュしてしまう。#@title exec_xmlfile(fname):
#!pip install xmltodict
import xmltodict
import json
import glob
def exec_xmlfile(fname):
with open(fname, encoding='utf-8') as fp:
# xml読み込み
xml_data = fp.read()
# xml → dict
dict_data = xmltodict.parse(xml_data)
return dict_data
len(dicd['us-patent-assignments']['patent-assignments']['patent-assignment'])
1ファイル50万行位

上記でとってきたデータをdataframeにしていく
#@title dicd関数 def get dicd(fname):
def get_dicd(fname):
dicd = exec_xmlfile(fname)
print(len(dicd['us-patent-assignments']['patent-assignments']['patent-assignment']))
return dicd
#@title 譲渡データ作成関数 get_assigndf(dicd):
def get_assigndf(dicd):
assignlist = []
for i,k in enumerate(dicd['us-patent-assignments']['patent-assignments']['patent-assignment']):
reelno = k['assignment-record']['reel-no']
try:
conveyanceText = k['assignment-record']['conveyance-text']
except:
conveyanceText = "unknown"
try:
patAssignorName = k['patent-assignors']['patent-assignor']['name']
except:
patAssignorName = "|".join([x['name'] for x in k['patent-assignors']['patent-assignor']])
try:
patAssigneeName = k['patent-assignees']['patent-assignee']['name']
except:
patAssigneeName = "|".join([x['name'] for x in k['patent-assignees']['patent-assignee']])
patAssignorRecDate = k['assignment-record']['recorded-date']['date']
try:
countryname = k['patent-assignees']['patent-assignee']['country-name']
except:
countryname = "US"
try:
patnum = "|".join(["{}{}{}".format(x['country'],x['doc-number'],x['kind']) for x in k['patent-properties']['patent-property']['document-id']])
except:
patnum = "-"
assignlist.append([reelno,patAssignorName,patAssigneeName,patAssignorRecDate,conveyanceText,countryname,patnum])
return assignlist
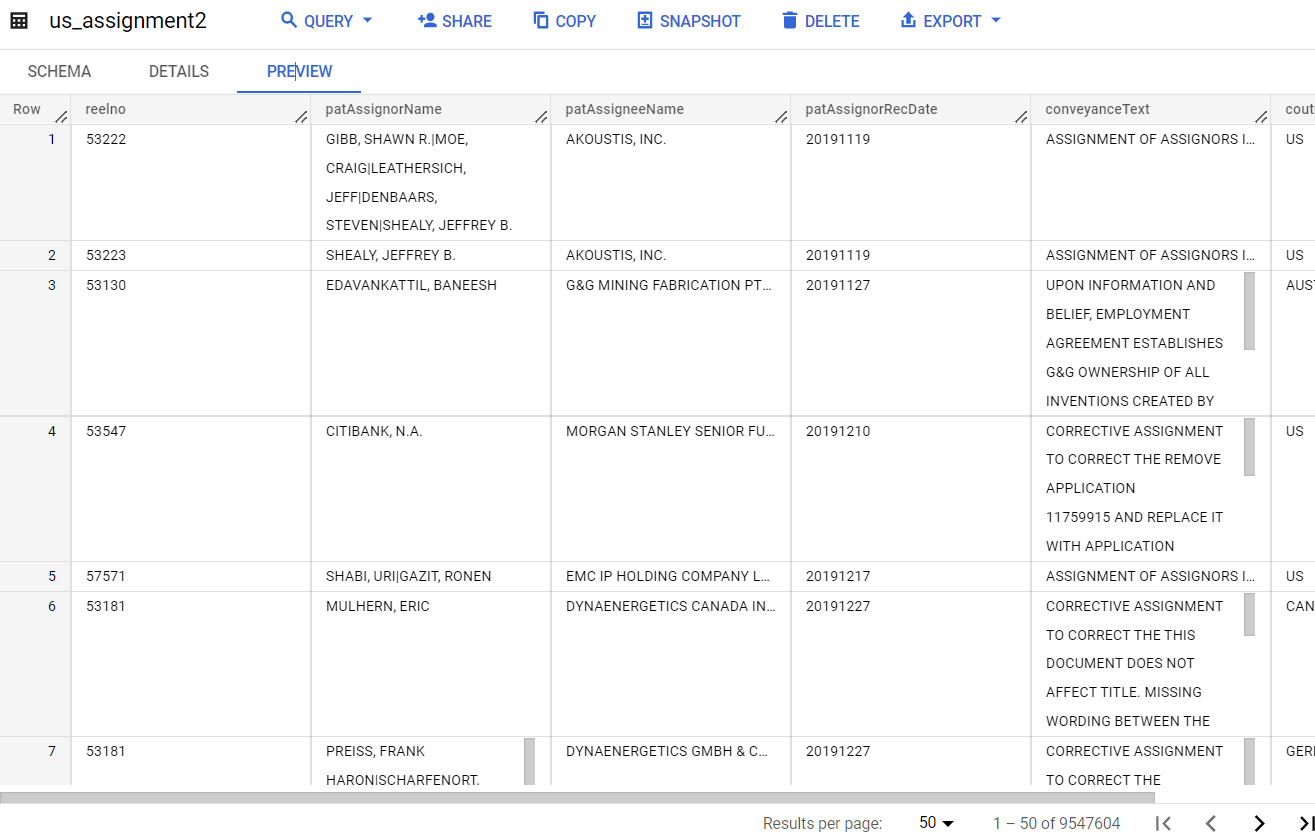
dataframeをBigQueryに投入
assign_df = pd.DataFrame(assignlist,columns=["reelno"
,"patAssignorName"
,"patAssigneeName"
,"patAssignorRecDate"
,"conveyanceText"
,"coutryname"
,'patnum'])
#@title 関数3:BigQuery投入関数(google-bq)
from google.cloud import bigquery
project_id = "{project-id}"
dataset = "{dataset}"
table = "us_assignment3"
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField("reelno", bigquery.enums.SqlTypeNames.STRING),
bigquery.SchemaField("patAssignorName", bigquery.enums.SqlTypeNames.STRING),
bigquery.SchemaField("patAssigneeName", bigquery.enums.SqlTypeNames.STRING),
bigquery.SchemaField("patAssignorRecDate", bigquery.enums.SqlTypeNames.STRING),
bigquery.SchemaField("conveyanceText", bigquery.enums.SqlTypeNames.STRING),
bigquery.SchemaField("coutryname", bigquery.enums.SqlTypeNames.STRING),
bigquery.SchemaField("patnum", bigquery.enums.SqlTypeNames.STRING),
],
# Optionally, set the write disposition. BigQuery appends loaded rows
# to an existing table by default, but with WRITE_TRUNCATE write
# disposition it replaces the table with the loaded data.
#write_disposition="WRITE_TRUNCATE",
write_disposition="WRITE_APPEND",
)
def insertbq(dataframe):
bigqueryClient = bigquery.Client(project_id)
tableRef = bigqueryClient.dataset(dataset).table(table)
bigqueryJob = bigqueryClient.load_table_from_dataframe(dataframe, tableRef,job_config=job_config)
return bigqueryJob.result()
この作業を20回繰り返してBigQuryのデータ完成!(約950万レコード)
for fname in fnames:
url = "https://bulkdata.uspto.gov/data/patent/assignment/" + fname
!curl -o $fname $url
!unzip $fname
for fname in xmlfnames:
dicd = get_dicd(fname)
assignlist = get_assigndf(dicd)
assign_df = pd.DataFrame(assignlist,columns=["reelno","patAssignorName","patAssigneeName","patAssignorRecDate","conveyanceText","coutryname","patnum"])
insertbq(assign_df)
3.遊んでみる
- Bigqueryへの投入が予想以上にいい感じに進んだのでこれで遊ぶことに。
以下、発明者→企業とか同じ企業間の名前変更のみとかをなるべく除くように処理して集計
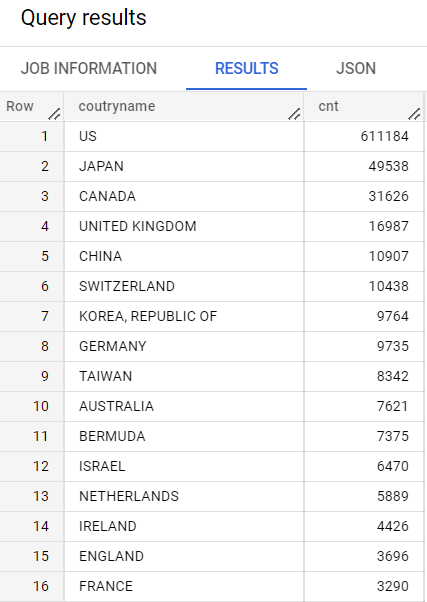
3.1 譲受人の国籍
SELECT coutryname,COUNT(*) as cnt
FROM `{project}.{dataset}.us_assignment3`
WHERE REGEXP_CONTAINS(lower(patAssignorName)," inc| corp| ltd| llc| univ| limited")
GROUP BY coutryname
ORDER BY cnt DESC
- USを除くと日本、カナダ、UKと多い。CNはまだですね。
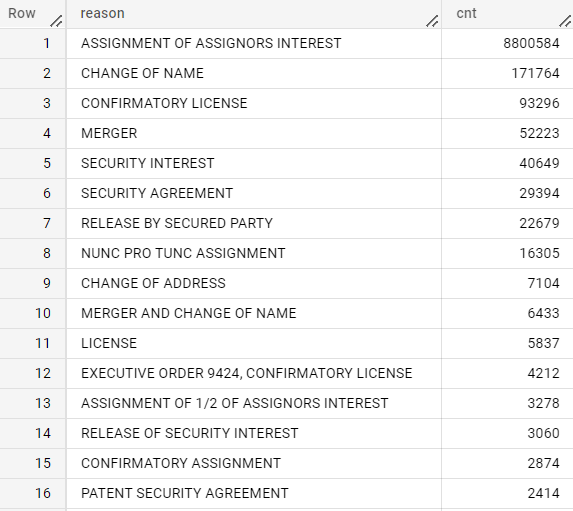
3.2 譲渡理由
どんな理由での譲渡が多いのか。
SELECT REGEXP_REPLACE(REGEXP_REPLACE(conveyanceText,r"\(.*\)|\.","")," $","") as reason,COUNT(*) as cnt
FROM `{project}.{dataset}.us_assignment3`
#WHERE REGEXP_CONTAINS(lower(patAssignorName)," inc| corp| ltd| llc| univ| limited")
GROUP BY reason
ORDER BY cnt DESC
- よくわからないのもあるけど、いろんな理由があるのね。SECURITY INTERESTとは担保か何か?
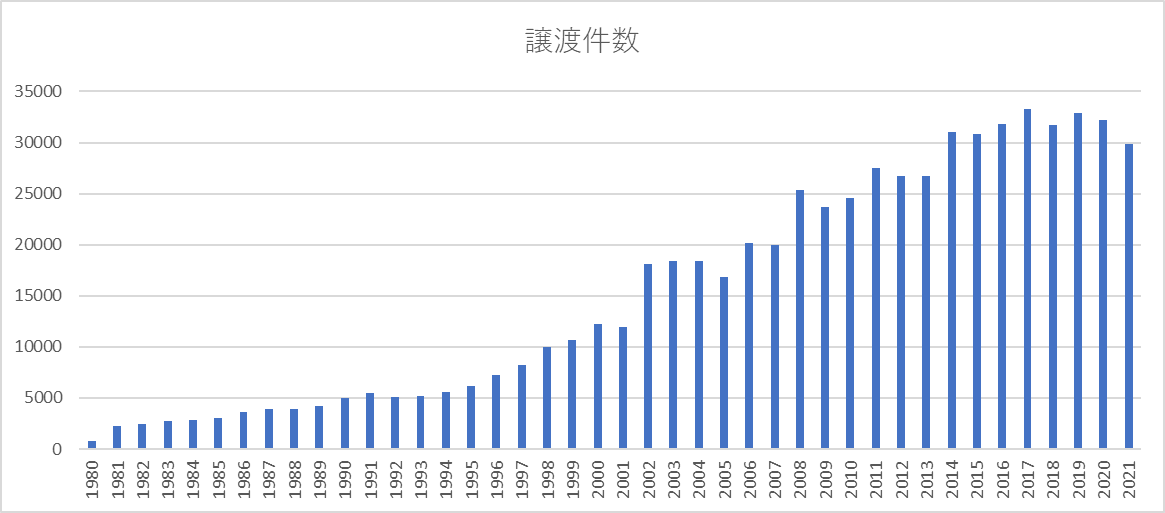
3.3 assignmentの時系列推移
2014年以降増加してますね。2000年くらいまではのどかな感じ。
SELECT SUBSTR(patAssignorRecDate,0,4) as assignyear,COUNT(*) as cnt
FROM `{project}.{dataset}.us_assignment3`
WHERE REGEXP_CONTAINS(lower(patAssignorName)," inc| corp| ltd| llc| univ| limited")
AND NOT REGEXP_CONTAINS(conveyanceText,"CHANGE|MERGE")
GROUP BY assignyear
ORDER BY assignyear ASC
3.4 一番長いassignmentの鎖は?
一番多くの人(企業)の手に渡ってきた特許はどれ?
SELECT patnum,STRING_AGG(DISTINCT patAssignorName) as unique_assigners,COUNT(DISTINCT patAssignorName) as cnt
FROM `{project}.{dataset}.us_assignment3`
WHERE REGEXP_CONTAINS(lower(patAssignorName)," inc| corp| ltd| llc| univ| limited")
AND NOT REGEXP_CONTAINS(conveyanceText,"CHANGE|MERGE|CONVERSION|ENTITY CONVEYANCE")
AND NOT patnum = "-"
GROUP BY patnum
ORDER BY cnt DESC
最大はUS5950168Aとこれ。UIとメインフレーム?

3.5 パテントトロールに流れ込む特許を可視化
パテントトロールと言う表現がいかがなものかとも思いますが。リストがあったので。
時系列、相手の広がり、・・・作成中
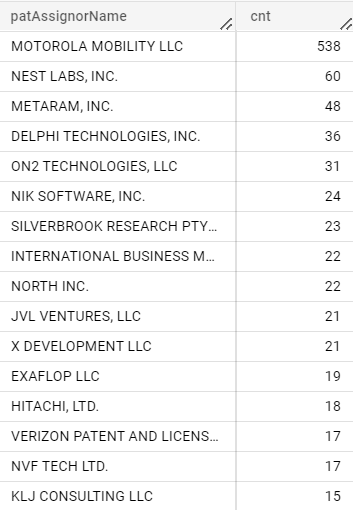
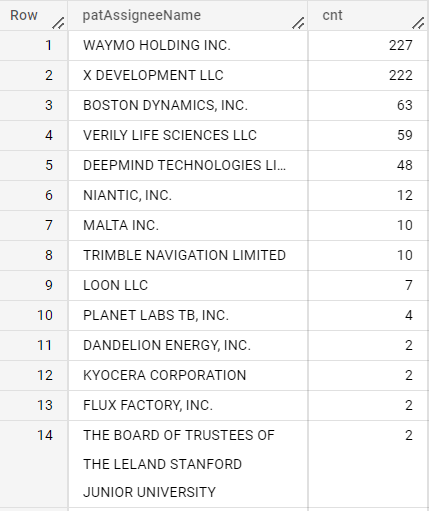
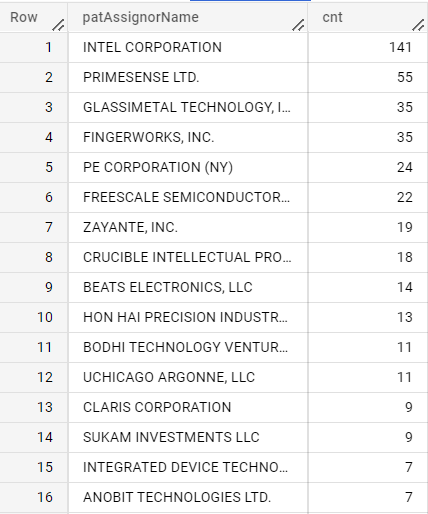
3.6各企業の譲受(IN)、譲渡(OUT)
- 以下、出願人名を変える以外は共通
IN
SELECT patAssignorName,COUNT(*) as cnt
FROM `{project}.{dataset}.us_assignment3`
WHERE REGEXP_CONTAINS(lower(patAssigneeName),"google")
AND NOT REGEXP_CONTAINS(lower(patAssignorName),"google")
AND REGEXP_CONTAINS(lower(patAssignorName)," inc| corp| ltd| llc| univ| limited")
AND NOT REGEXP_CONTAINS(conveyanceText,"CHANGE|MERGE|CONVERSION|ENTITY CONVEYANCE")
GROUP BY patAssignorName
ORDER BY cnt DESC
OUT
SELECT patAssigneeName,COUNT(*) as cnt
FROM `{project}.{dataset}.us_assignment3`
WHERE REGEXP_CONTAINS(lower(patAssignorName),"google")
AND NOT REGEXP_CONTAINS(lower(patAssigneeName),"google")
GROUP BY patAssigneeName
ORDER BY cnt DESC
IN
OUT
Apple
IN
OUT
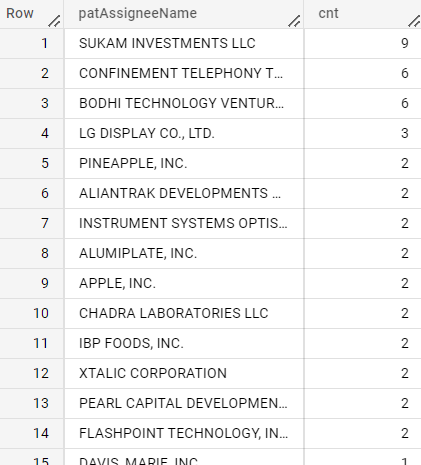
Tesla
IN
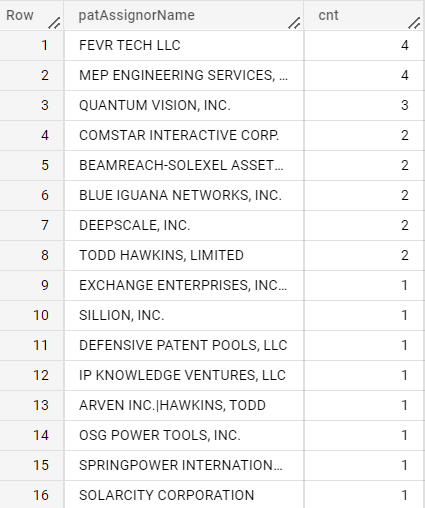
OUT
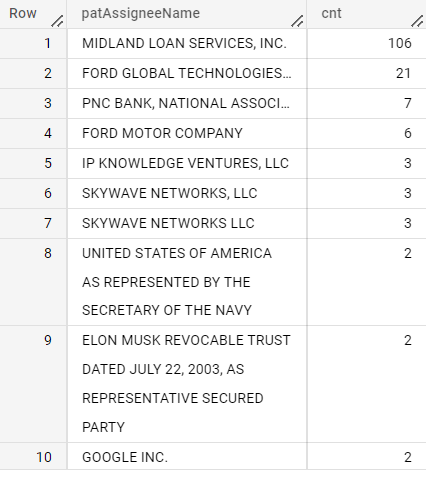
Microsoft
IN
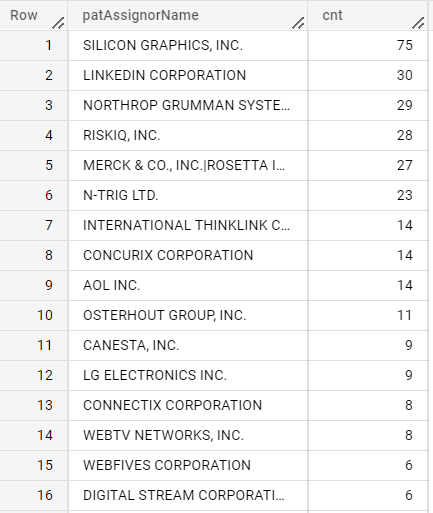
OUT
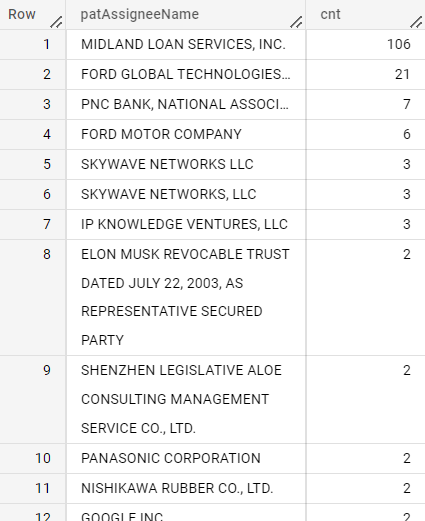
IBM
IN
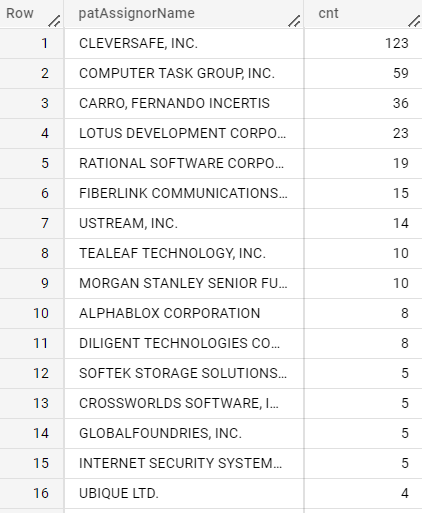
OUT
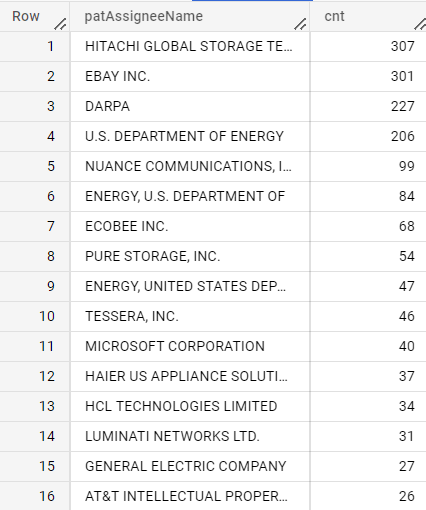
sony
IN
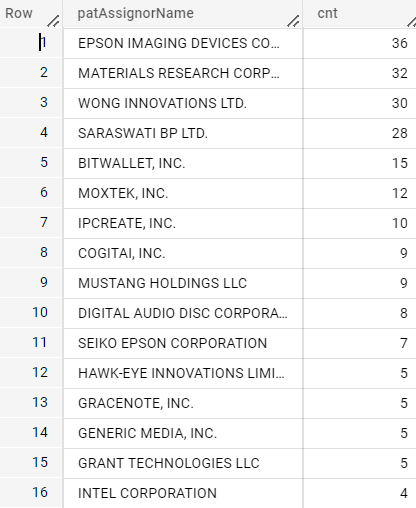
OUT
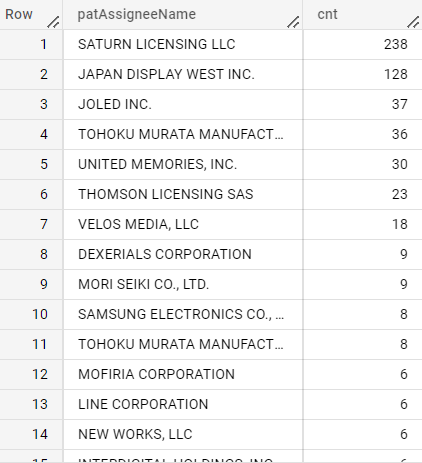
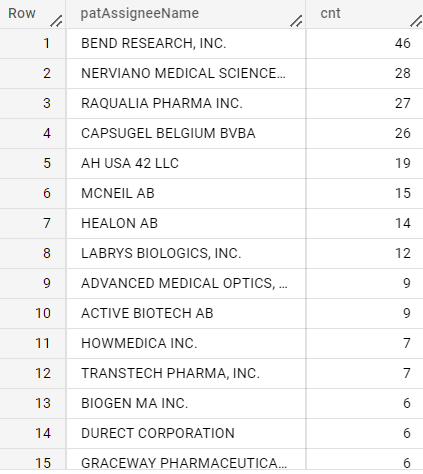
pfizer
IN
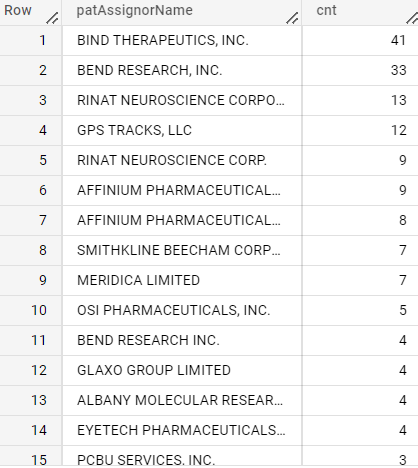
OUT
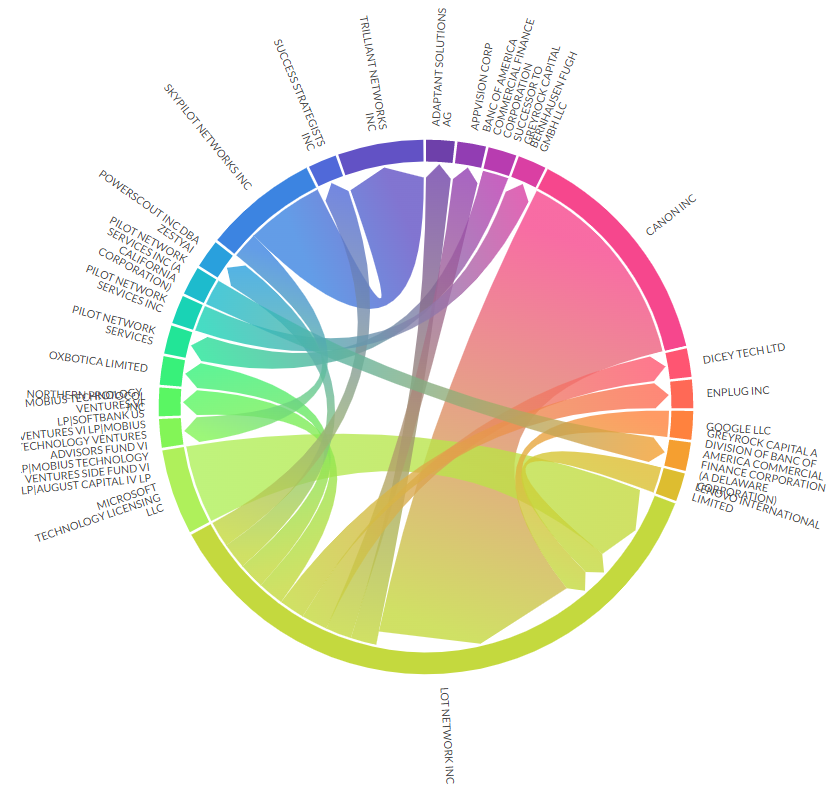
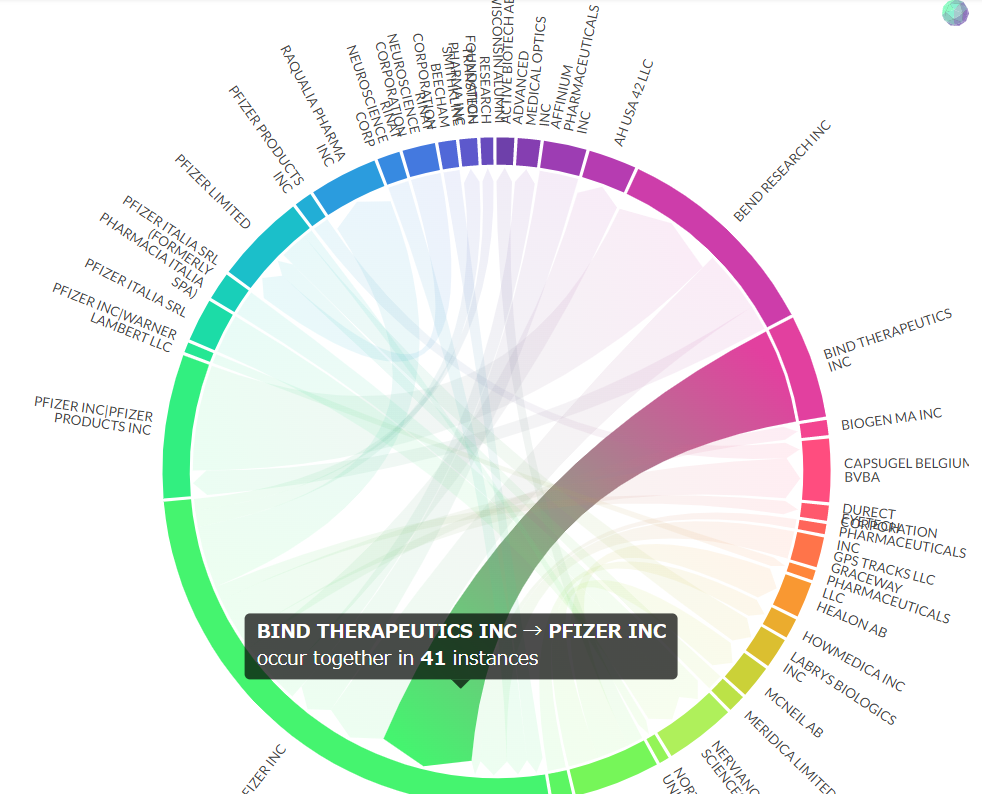
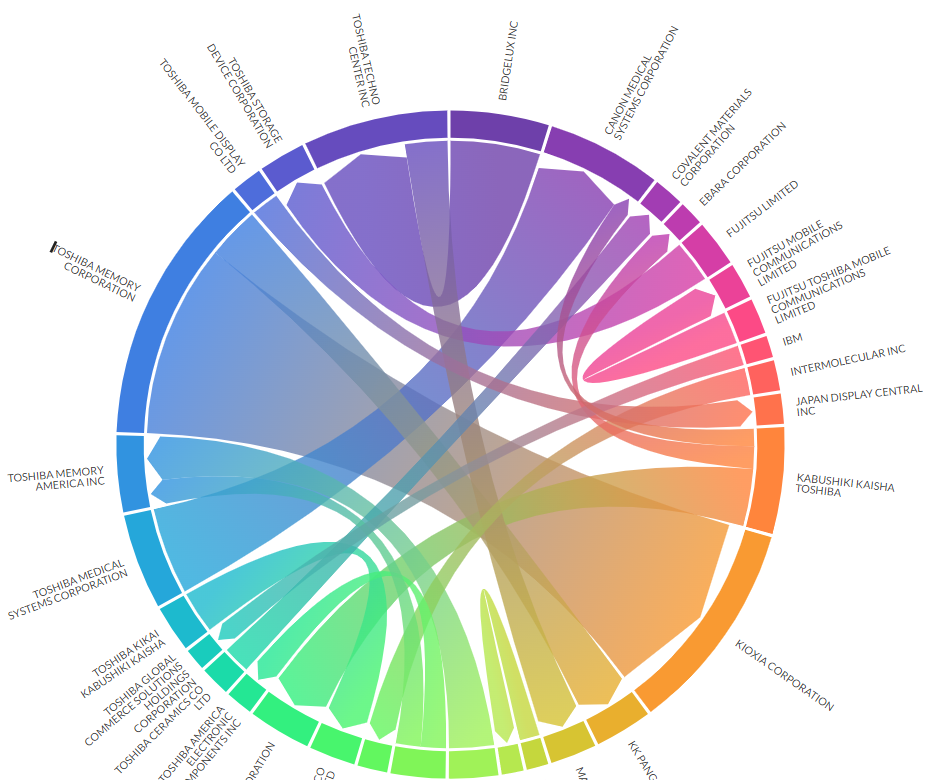
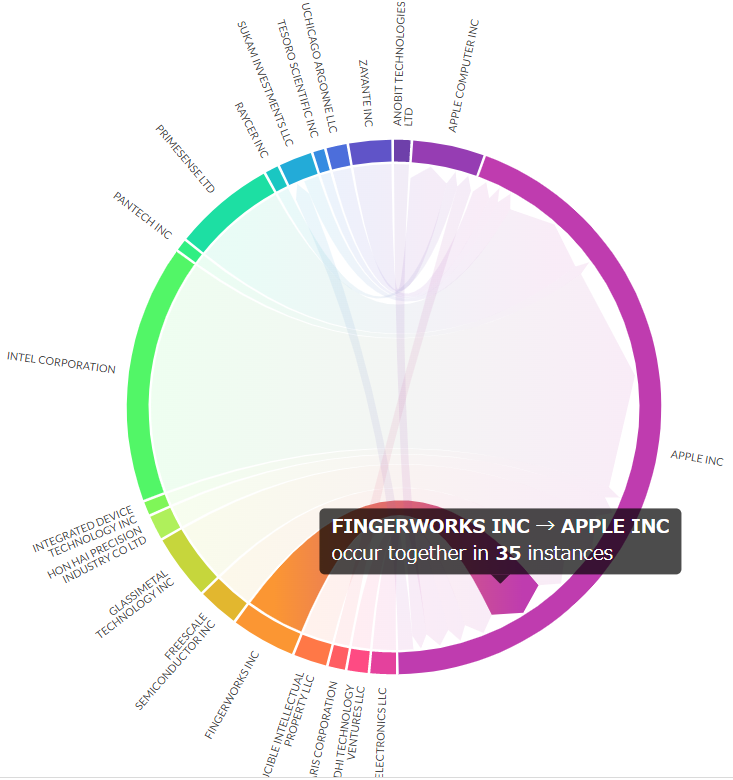
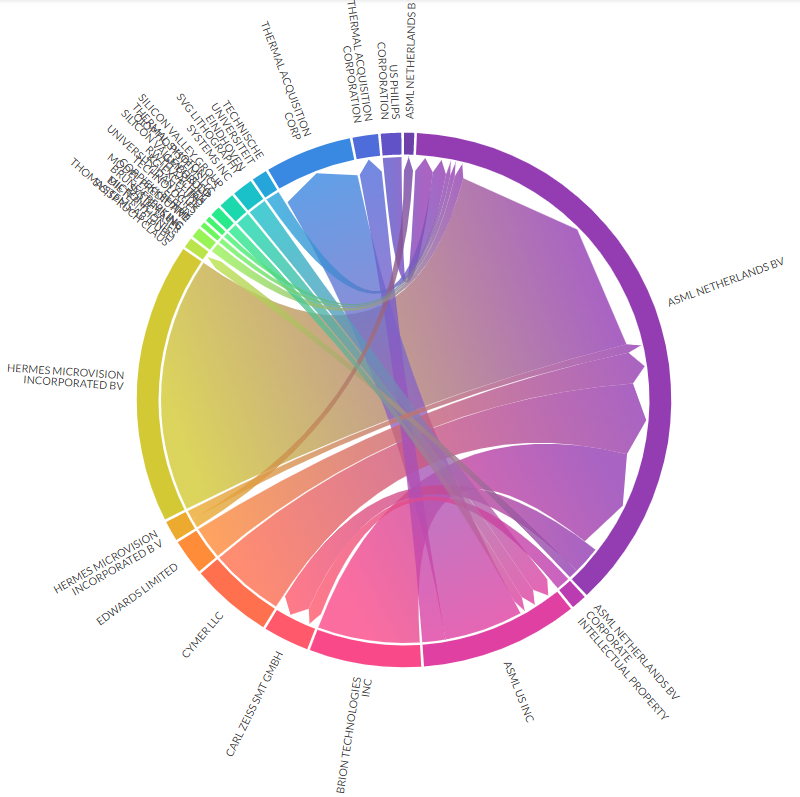
3.7 ネットワーク図
- 昨年に続きplotapiを利用。探したけど一番きれいにchord diagramを出してくれる。
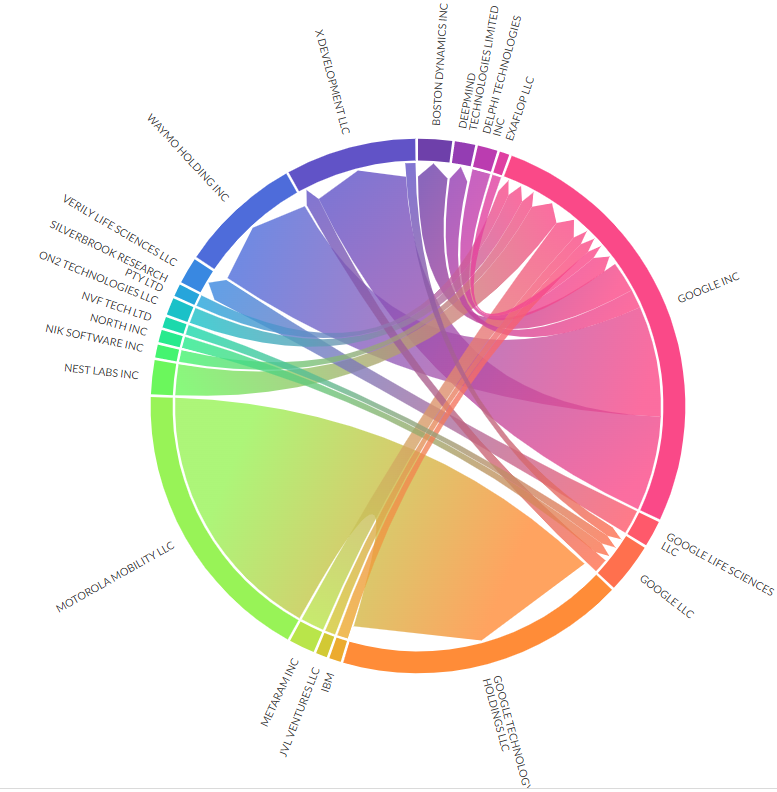
pfizer
toshiba
apple
ASML
おっCYMERだ
hitachi
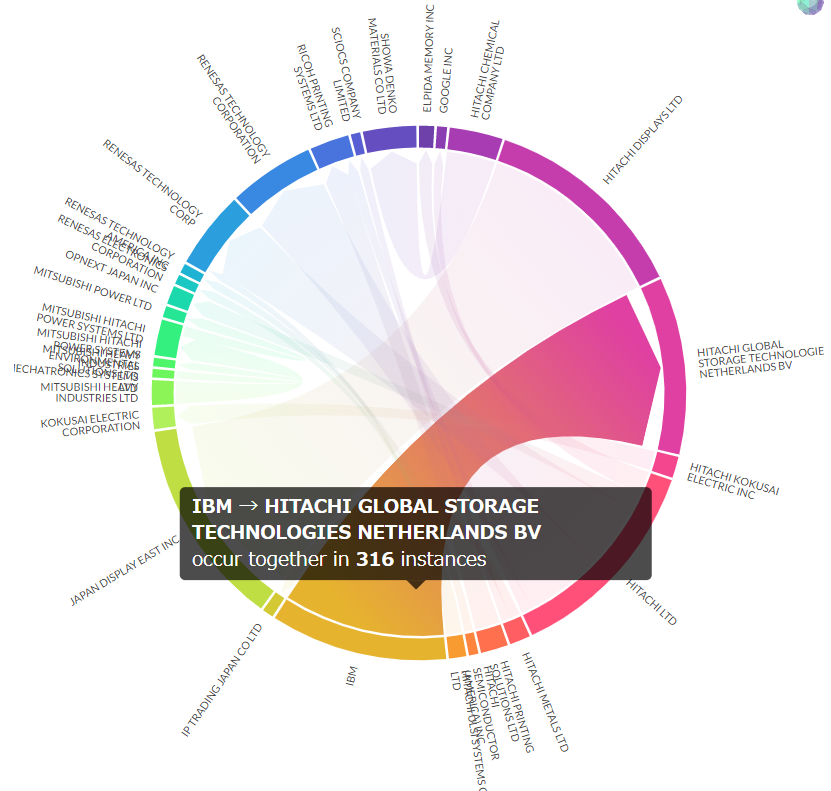
LOT NETWORK
数はそんなに多くない