BigQueryに前処理関数があるのを発見。
テキスト分析で使えそうなNGRAM関数があるのでメモ。
ML.NGRAMS
ML.NGRAMS(array_input, range[, separator])
使い方
リンク先のページにあるが、seapatorやrange()を指定できるのがうれしい。
※rangeは、普通2gramしか使わないけど(参考書でもnを3以上にしても精度(パープレキシティ)は
あまり上がらないとのことだ)。
あと、日本語でもngram作成してくれるといいなと思ったのだけど、たぶんない。
分割対象の列をスペースやカンマ区切りなどとして入れておけば、下記のように
SPLIT()をかませてarray_inputに変えてから使える。
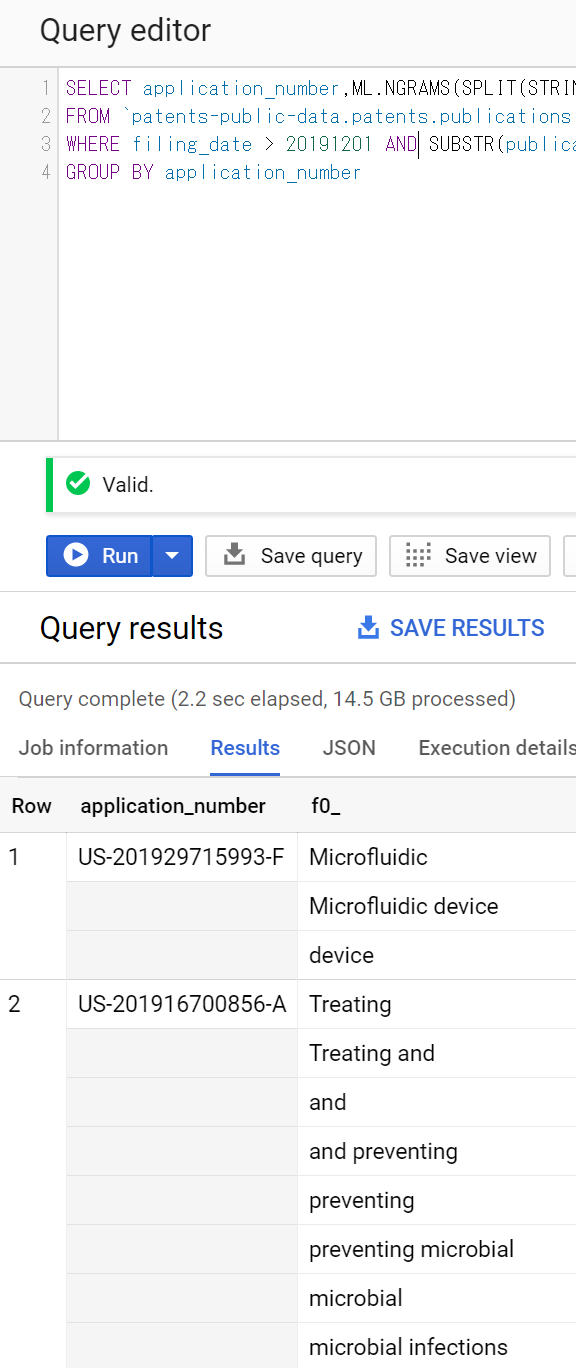
SELECT application_number,ML.NGRAMS(SPLIT(STRING_AGG(titles.text),' '), [1,2])
FROM `patents-public-data.patents.publications`,UNNEST(title_localized) as titles
WHERE filing_date > 20191201 AND SUBSTR(publication_number,0,2) = 'US'
GROUP BY application_number
ちゃんと2-gramを作って出力してくれている。
その他
作ったn-gramはそのままAutoML Tablesに突っ込めば、n-gramを利用したモデルが作成できるし、
BigQuery MLでも特徴量として使ってもらえる。
BigQueryのオンライン授業を受けたところ、GCP上で機械学習をする際の選択肢が以下3つあるとのこと。
- BigQueryMLで完結させる方法(LOGISTIC_REG)
- Auto ML
- 自分で作る(tensorflowなど)
3通り並列で今度やってみよう。
他にもML.POLYNOMIAL_EXPAND、ML.QUANTILE_BUCKETIZE、MIN_MAX_SCALERなど欲しい機能が
存在している!
今pythonやpipelineで行っていることを、BigQueryがどんどん飲み込んでいくような気がする。
tensorflowのモデルもBQMLの中で処理してくれるみたいですし。。