まずはサンプルテーブルを作ってデータを投入する。
ERDはこんな感じ。
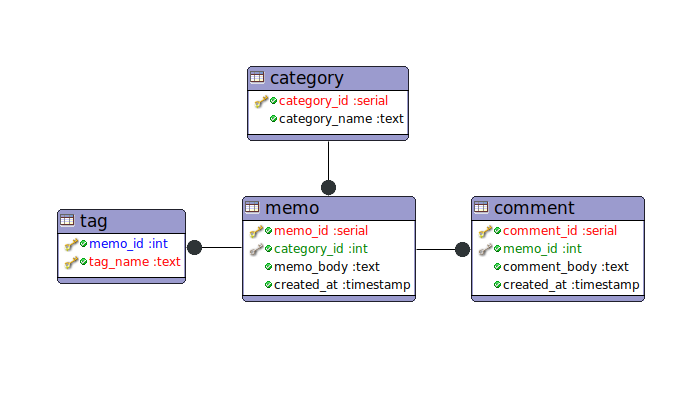
create table category(
category_id int primary key,
category_name text not null
);
insert into category values(1, '生活');
insert into category values(2, '役立ち');
insert into category values(3, '備忘録');
insert into category values(4, '宣伝');
create table memo(
memo_id int primary key,
category_id int not null references category(category_id) on delete cascade,
memo_body text not null,
created_at timestamp not null default CURRENT_TIMESTAMP
);
insert into memo
select i, i % 4 + 1, i || ' text' from generate_series(1,100000) as g(i);
create index memo_created_at_btree on memo(created_at desc, memo_id);
create index memo_category_id_btree on memo(category_id, created_at desc);
create table tag(
memo_id int not null references memo(memo_id) on delete cascade,
tag_name text not null,
unique (memo_id, tag_name)
);
insert into tag
select i, 'tag' || n
from generate_series(1,100000) as g(i)
, generate_series(1,5) as t(n);
create index tag_memo_id_btree on tag(memo_id);
create index tag_tag_name_btree on tag(tag_name);
create table comment(
comment_id int primary key,
memo_id int not null references memo(memo_id) on delete cascade,
comment_body text not null,
created_at timestamp not null default CURRENT_TIMESTAMP
);
insert into comment
select i * 10 + n, i, 'comment ' || n
from generate_series(1,100000) as g(i)
, generate_series(1,3) as t(n);
create index comment_memo_id_btree on comment(memo_id);
create index comment_memo_id_created_at_btree on comment(memo_id, created_at);
よくある関連のパターンのシンプルなやつ。
上記generate_seriesで自動生成したデータは次のようになっている。
user# select * from category;
category_id | category_name
-------------+---------------
1 | 生活
2 | 役立ち
3 | 備忘録
4 | 宣伝
(4 行)
user#
user#
user# select * from memo limit 5;
memo_id | category_id | memo_body | created_at
---------+-------------+-----------+----------------------------
1 | 2 | 1 text | 2019-01-23 16:11:56.282086
2 | 3 | 2 text | 2019-01-23 16:11:56.282086
3 | 4 | 3 text | 2019-01-23 16:11:56.282086
4 | 1 | 4 text | 2019-01-23 16:11:56.282086
5 | 2 | 5 text | 2019-01-23 16:11:56.282086
(5 行)
user# select count(*) from memo;
count
--------
100000
(1 行)
user# select count(*) from tag;
count
--------
500000
(1 行)
user# select count(*) from comment;
count
--------
300000
(1 行)
ここで、memoを基準に全てのデータを取ってきたい場合。単純に書くと
explain analyze
select *
from memo
join category using(category_id)
join tag using(memo_id)
join comment using(memo_id)
where memo_id = 12345
order by tag_name, comment.created_at;
--------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=33.99..34.03 rows=15 width=93) (actual time=0.076..0.077 rows=15 loops=1)
Sort Key: tag.tag_name, comment.created_at
Sort Method: quicksort Memory: 27kB
-> Nested Loop (cost=1.29..33.70 rows=15 width=93) (actual time=0.040..0.054 rows=15 loops=1)
-> Index Scan using tag_memo_id_btree on tag (cost=0.42..8.51 rows=5 width=9) (actual time=0.016..0.018 rows=5 loops=1)
Index Cond: (memo_id = 12345)
-> Materialize (cost=0.87..25.01 rows=3 width=80) (actual time=0.005..0.006 rows=3 loops=5)
-> Nested Loop (cost=0.87..25.00 rows=3 width=80) (actual time=0.020..0.022 rows=3 loops=1)
-> Nested Loop (cost=0.44..16.49 rows=1 width=58) (actual time=0.012..0.013 rows=1 loops=1)
-> Index Scan using memo_pkey on memo (cost=0.29..8.31 rows=1 width=26) (actual time=0.007..0.007 rows=1 loops=1)
Index Cond: (memo_id = 12345)
-> Index Scan using category_pkey on category (cost=0.15..8.17 rows=1 width=36) (actual time=0.003..0.004 rows=1 loops=1)
Index Cond: (category_id = memo.category_id)
-> Index Scan using comment_memo_id_btree on comment (cost=0.42..8.47 rows=3 width=26) (actual time=0.007..0.008 rows=3 loops=1)
Index Cond: (memo_id = 12345)
Planning time: 0.264 ms
Execution time: 0.145 ms
こんな感じ。
ただ、この場合のデータは
memo_id | category_id | memo_body | created_at | category_name | tag_name | comment_id | comment_body | created_at
---------+-------------+------------+----------------------------+---------------+----------+------------+--------------+----------------------------
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag1 | 123451 | comment 1 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag1 | 123452 | comment 2 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag1 | 123453 | comment 3 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag2 | 123451 | comment 1 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag2 | 123452 | comment 2 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag2 | 123453 | comment 3 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag3 | 123451 | comment 1 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag3 | 123452 | comment 2 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag3 | 123453 | comment 3 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag4 | 123451 | comment 1 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag4 | 123452 | comment 2 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag4 | 123453 | comment 3 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag5 | 123451 | comment 1 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag5 | 123452 | comment 2 | 2019-01-23 16:30:56.038017
12345 | 2 | 12345 text | 2019-01-23 16:11:56.282086 | 役立ち | tag5 | 123453 | comment 3 | 2019-01-23 16:30:56.038017
(15 行)
このようになっていて、何のツールも使わずに分解していくのはつらい。
かと言って、何度もSQLを発行してアプリ側で繋げるのも無駄な感じがする。
そういうときに、PostgreSQLではlateralとjson_aggが使える。
lateralはfromで絞り込んだ後のjoinのような感じ。
json_aggはデータをjson形式にまとめる。
explain analyze
select memo_id, category, tag, comment
from memo
, lateral (
select json_agg(category) as category
from category
where category_id = memo.category_id
) as category
, lateral (
select json_agg(tag order by tag_name) as tag
from tag
where memo_id = memo.memo_id
) as tag
, lateral (
select json_agg(comment_inner order by created_at) as comment
from (
select comment_body, created_at
from comment
where memo_id = memo.memo_id
) as comment_inner
) as comment
where memo_id = 12345
;
-------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=25.48..33.59 rows=1 width=100) (actual time=0.079..0.080 rows=1 loops=1)
-> Nested Loop (cost=16.99..25.07 rows=1 width=68) (actual time=0.056..0.057 rows=1 loops=1)
-> Nested Loop (cost=8.47..16.52 rows=1 width=36) (actual time=0.029..0.030 rows=1 loops=1)
-> Index Scan using memo_pkey on memo (cost=0.29..8.31 rows=1 width=8) (actual time=0.013..0.013 rows=1 loops=1)
Index Cond: (memo_id = 12345)
-> Aggregate (cost=8.17..8.18 rows=1 width=32) (actual time=0.015..0.015 rows=1 loops=1)
-> Index Scan using category_pkey on category (cost=0.15..8.17 rows=1 width=60) (actual time=0.004..0.005 rows=1 loops=1)
Index Cond: (category_id = memo.category_id)
-> Aggregate (cost=8.52..8.53 rows=1 width=32) (actual time=0.026..0.026 rows=1 loops=1)
-> Index Scan using tag_memo_id_btree on tag (cost=0.42..8.51 rows=5 width=38) (actual time=0.008..0.011 rows=5 loops=1)
Index Cond: (memo_id = memo.memo_id)
-> Aggregate (cost=8.48..8.49 rows=1 width=32) (actual time=0.020..0.020 rows=1 loops=1)
-> Index Scan using comment_memo_id_btree on comment (cost=0.42..8.47 rows=3 width=18) (actual time=0.007..0.008 rows=3 loops=1)
Index Cond: (memo_id = memo.memo_id)
Planning time: 0.189 ms
Execution time: 0.127 ms
SQLは複雑になっても遅くはならない。
データは
memo_id | category | tag | comment
---------+----------------------------------------------+----------------------------------------+---------------------------------------------------------------------------
12345 | [{"category_id":2,"category_name":"役立ち"}] | [{"memo_id":12345,"tag_name":"tag1"}, +| [{"comment_body":"comment 1","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":12345,"tag_name":"tag2"}, +| {"comment_body":"comment 2","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":12345,"tag_name":"tag3"}, +| {"comment_body":"comment 3","created_at":"2019-01-23T16:30:56.038017"}]
| | {"memo_id":12345,"tag_name":"tag4"}, +|
| | {"memo_id":12345,"tag_name":"tag5"}] |
(1 行)
1行になったところがポイント。あとはアプリ側でjsonをハッシュや配列に変えればOK。
一覧表示も、単純にやると
explain analyze
select memo_id, category, tag, comment
from memo
join category using(category_id)
join tag using(memo_id)
join comment using(memo_id)
where category_id = 4
order by memo.created_at desc
limit 100 offset 20000
;
----------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=4043.92..4064.13 rows=100 width=155) (actual time=18.307..18.391 rows=100 loops=1)
-> Nested Loop (cost=1.42..75577.03 rows=373905 width=155) (actual time=0.031..17.729 rows=20100 loops=1)
Join Filter: (memo.memo_id = tag.memo_id)
-> Nested Loop (cost=0.99..28699.81 rows=74781 width=126) (actual time=0.026..4.528 rows=4020 loops=1)
-> Nested Loop (cost=0.57..3987.67 rows=24927 width=72) (actual time=0.019..0.837 rows=1340 loops=1)
-> Index Scan using memo_category_id_btree on memo (cost=0.42..3667.91 rows=24927 width=16) (actual time=0.011..0.360 rows=1340 loops=1)
Index Cond: (category_id = 4)
-> Materialize (cost=0.15..8.18 rows=1 width=64) (actual time=0.000..0.000 rows=1 loops=1340)
-> Index Scan using category_pkey on category (cost=0.15..8.17 rows=1 width=64) (actual time=0.005..0.006 rows=1 loops=1)
Index Cond: (category_id = 4)
-> Index Scan using comment_memo_id_btree on comment (cost=0.42..0.96 rows=3 width=54) (actual time=0.002..0.002 rows=3 loops=1340)
Index Cond: (memo_id = memo.memo_id)
-> Index Scan using tag_memo_id_btree on tag (cost=0.42..0.56 rows=5 width=37) (actual time=0.002..0.002 rows=5 loops=4020)
Index Cond: (memo_id = comment.memo_id)
Planning time: 0.814 ms
Execution time: 18.437 ms
こんな感じでSQLは非常にシンプルで良いのだが、この後にアプリ側で展開するのがつらい。
あと、このSQLはmemoを100件表示するつもりが出来ていないので、SQLを何度か発行するかlimitを内側に書く必要がある。orderやlimit、offsetを考えると結局シンプルにはならない。
lateralを使ってSQLをがっつり書いた場合は
explain analyze
select memo_id, memo_body, category, tag, comment
from (
select *
from memo
where category_id = 4
order by created_at desc
limit 100 offset 20000
) as memo
, lateral (
select json_agg(category) as category
from category
where category_id = memo.category_id
) as category
, lateral (
select json_agg(tag order by tag_name) as tag
from tag
where memo_id = memo.memo_id
) as tag
, lateral (
select json_agg(comment_inner order by created_at) as comment
from (
select comment_body, created_at
from comment
where memo_id = memo.memo_id
) as comment_inner
) as comment
;
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=2968.19..5486.22 rows=100 width=100) (actual time=6.005..8.660 rows=100 loops=1)
-> Nested Loop (cost=2959.71..4634.72 rows=100 width=68) (actual time=5.975..7.644 rows=100 loops=1)
-> Nested Loop (cost=2951.18..3779.22 rows=100 width=36) (actual time=5.923..6.344 rows=100 loops=1)
-> Limit (cost=2943.01..2957.72 rows=100 width=48) (actual time=5.863..5.924 rows=100 loops=1)
-> Index Scan using memo_category_id_btree on memo (cost=0.42..3667.91 rows=24927 width=48) (actual time=0.020..5.253 rows=20100 loops=1)
Index Cond: (category_id = 4)
-> Aggregate (cost=8.17..8.18 rows=1 width=32) (actual time=0.004..0.004 rows=1 loops=100)
-> Index Scan using category_pkey on category (cost=0.15..8.17 rows=1 width=60) (actual time=0.001..0.001 rows=1 loops=100)
Index Cond: (category_id = memo.category_id)
-> Aggregate (cost=8.52..8.53 rows=1 width=32) (actual time=0.012..0.012 rows=1 loops=100)
-> Index Scan using tag_memo_id_btree on tag (cost=0.42..8.51 rows=5 width=38) (actual time=0.002..0.003 rows=5 loops=100)
Index Cond: (memo_id = memo.memo_id)
-> Aggregate (cost=8.48..8.49 rows=1 width=32) (actual time=0.010..0.010 rows=1 loops=100)
-> Index Scan using comment_memo_id_btree on comment (cost=0.42..8.47 rows=3 width=18) (actual time=0.002..0.003 rows=3 loops=100)
Index Cond: (memo_id = memo.memo_id)
Planning time: 0.237 ms
Execution time: 8.740 ms
こんな感じ。
memo_id | category | tag | comment
---------+--------------------------------------------+----------------------------------------+---------------------------------------------------------------------------
80003 | [{"category_id":4,"category_name":"宣伝"}] | [{"memo_id":80003,"tag_name":"tag1"}, +| [{"comment_body":"comment 1","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":80003,"tag_name":"tag2"}, +| {"comment_body":"comment 2","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":80003,"tag_name":"tag3"}, +| {"comment_body":"comment 3","created_at":"2019-01-23T16:30:56.038017"}]
| | {"memo_id":80003,"tag_name":"tag4"}, +|
| | {"memo_id":80003,"tag_name":"tag5"}] |
80007 | [{"category_id":4,"category_name":"宣伝"}] | [{"memo_id":80007,"tag_name":"tag1"}, +| [{"comment_body":"comment 1","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":80007,"tag_name":"tag2"}, +| {"comment_body":"comment 2","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":80007,"tag_name":"tag3"}, +| {"comment_body":"comment 3","created_at":"2019-01-23T16:30:56.038017"}]
| | {"memo_id":80007,"tag_name":"tag4"}, +|
| | {"memo_id":80007,"tag_name":"tag5"}] |
80011 | [{"category_id":4,"category_name":"宣伝"}] | [{"memo_id":80011,"tag_name":"tag1"}, +| [{"comment_body":"comment 1","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":80011,"tag_name":"tag2"}, +| {"comment_body":"comment 2","created_at":"2019-01-23T16:30:56.038017"}, +
| | {"memo_id":80011,"tag_name":"tag3"}, +| {"comment_body":"comment 3","created_at":"2019-01-23T16:30:56.038017"}]
| | {"memo_id":80011,"tag_name":"tag4"}, +|
| | {"memo_id":80011,"tag_name":"tag5"}] |
結果がまとまっていて便利。しかも別に遅くなっているわけではなく、場合によっては速くなる。
これをPHPから使う場合、クラスで
class Memo
{
public $category;
public $comments;
public $tags;
private $category_json;
private $comments_json;
private $tags_json;
public function __construct()
{
$this->category = json_decode($this->category_json);
$this->comments = json_decode($this->comments_json);
$this->tags = json_decode($this->tags_json);
}
}
このようなクラスを作っておくと、上記SQLを少し変えて
select memo_id, memo_body, category_json, tags_json, comments_json
...
select json_agg(category) as category_json
...
_jsonなど分かりやすくなるように名前を付けて
$pdo = new PDO('pgsql:dbname=user;user=user');
$pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$pdo->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_OBJ);
$pdo->setAttribute(PDO::ATTR_EMULATE_PREPARES, false);
$stmt = $pdo->prepare($sql);
$stmt->execute();
$stmt->setFetchMode(PDO::FETCH_CLASS, Memo::class);
foreach ($stmt as $memo){
print_r([$memo->memo_id => $memo->memo_body]);
print_r(['category' => $memo->category]);
print_r(['tags' => $memo->tags]);
print_r(['comments' => $memo->comments]);
}
/*
Array
(
[80003] => 80003 text
[category] => Array
(
[0] => stdClass Object
(
[category_id] => 4
[category_name] => 宣伝
)
)
[tags] => Array
(
[0] => stdClass Object
(
[memo_id] => 80003
[tag_name] => tag1
)
[1] => stdClass Object
(
[memo_id] => 80003
[tag_name] => tag2
)
[2] => ...
)
[comments] => Array
(
[0] => stdClass Object
(
[comment_body] => comment 1
[created_at] => 2019-01-23T16:30:56.038017
)
[1] => stdClass Object
(
[comment_body] => comment 2
[created_at] => 2019-01-23T16:30:56.038017
)
[2] => stdClass Object
(
[comment_body] => comment 3
[created_at] => 2019-01-23T16:30:56.038017
)
)
)
*/
素のPDOを使ってSQL一発で簡易ORマッピングができる。
PDO::FETCH_CLASSでフェッチすると、クラスのプロパティに値が入ってからコンストラクタが呼ばれるので、初期化がスムーズにできる。