Cloud Pak for Data(CP4D) は IBMの統合データプラットフォームです。Openshift上に導入するSW版とIBM Cloud上のSaaS版があります。
それぞれの機能はSW阪の方が若干機能が豊富で、SaaS版の方が後から追いつく感じです。
今回はOpenShift上に構築したCP4D v3.5を使ってGoogle Big Query上のテーブルを仮想化してアクセスする方法について説明します。
仮想化(Data Virtulization)は2021年7月7日現在SaaS版にも実装されていますが、残念ながら無料のLiteプランはなく、有料プランのみで使用できます。
1. データ仮想化?
データ仮想化とは、CP4Dの代表的な機能で、データをコピーすることなく、データを提供できる機能です。たくさんのDBにあるいろいろテーブルを使って分析処理や機械学習をしたい場合、CP4Dでデータ仮想化すれば、CP4Dで仮想化サービスにアクセス可能なユーザーであれば、それぞれのDBへの接続設定を知らなくともデータにアクセスすることが可能です。
従来の方法であれば、データアクセス権をそれぞれのDB管理者に申請して接続情報をもらってデータを取得、あるいは抽出したCSVをもらう等の手間が必要でしたが、CP4Dの仮想化のデータソース管理者がまとめてデータソースを設定しておけば、CP4D内でアクセス管理が完結してしまいます。
またCP4Dで仮想化サービスにアクセス可能なユーザーであれば、外部のBIツールなどからでも、DB2のJDBC接続で仮想化データにアクセスが可能です。
仮想化できるDB(v3.5): (2021/05/19現在)
また、ここでは説明しませんがCP4D内のWatson Knowledge Catalogと連携することで、カタログ登録した情報を簡単にデータ仮想化機能でも利用したり、データマスキングなどのプライバシー設定を引き継いだりすることが可能です。
2. Google BigQueryでのサービスアカウントの作成
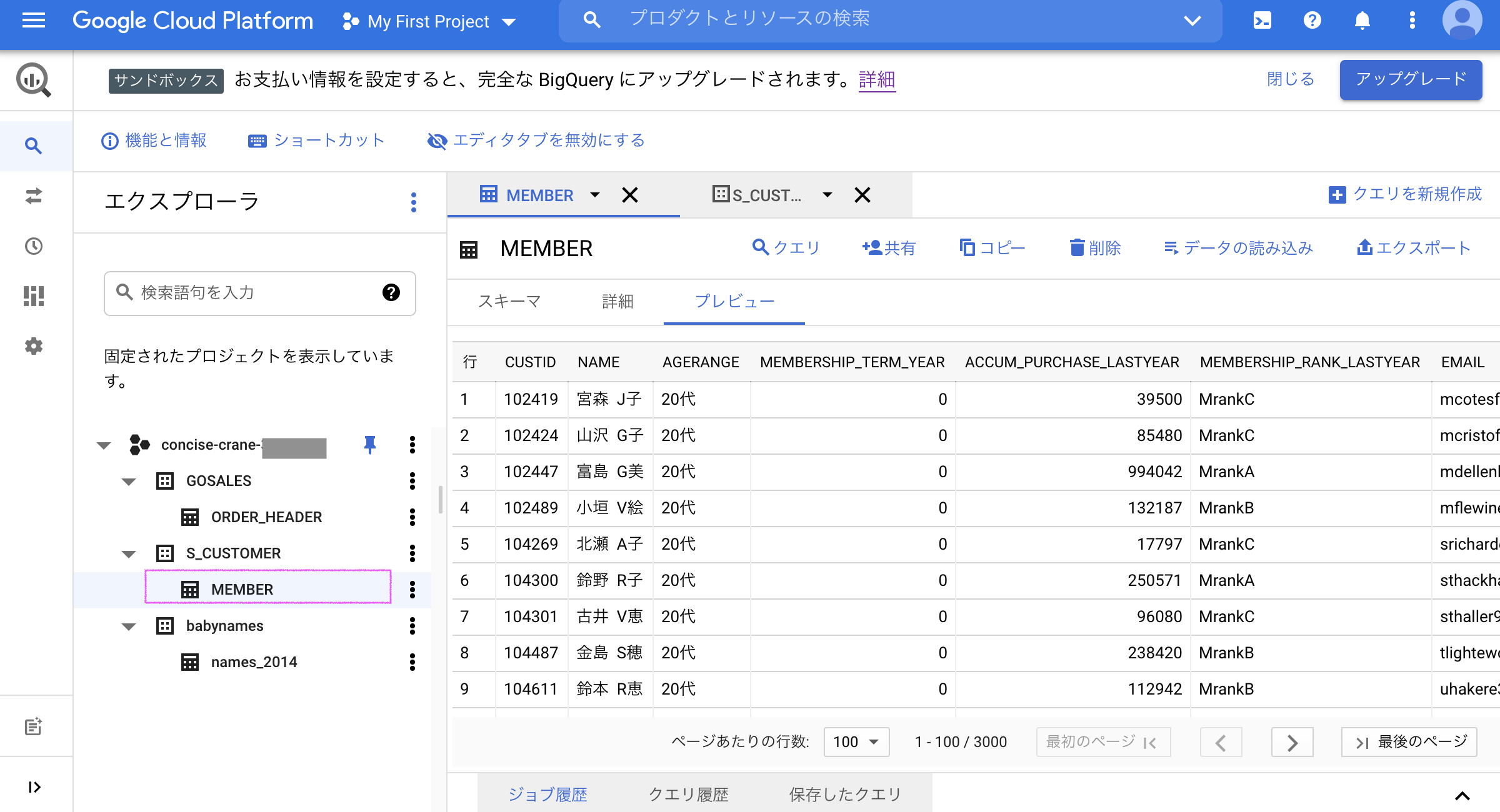
今回はサンドボックスを使って、以下のようなMEMBERというテーブルをデータセットS_CUSTOMERに作成してあります。このテーブルを仮想化します。
接続情報設定のため、サービスアカウントを作成します。すでにあるサービスアカウントを使用する場合は、この手順はスキップしてください。
2-1. Google Cloud Consoleにログインし、画面左上にあるメニューより、「IAMと管理」→「サービスアカウント」クリックします。

2-2. 上部の「+サービスアカウントを作成」 をクリック

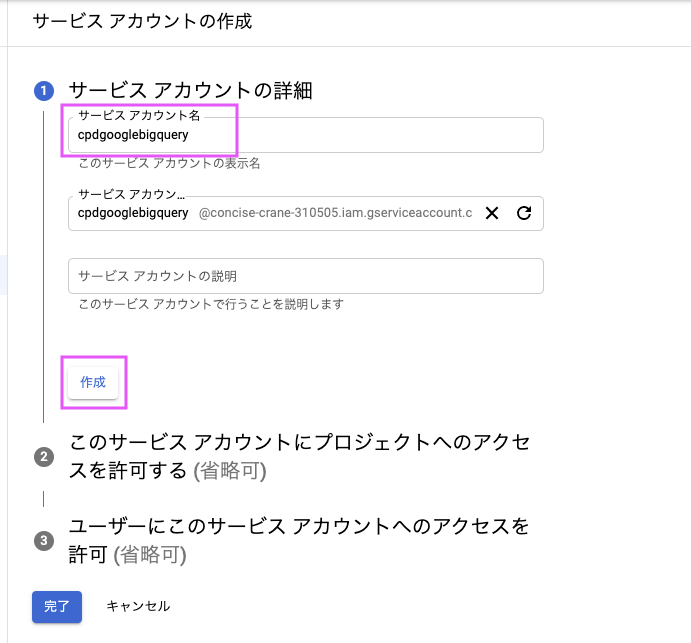
2-3. サービスアカウントの詳細を記入
サービス アカウント名を入れ、「作成」をクリック
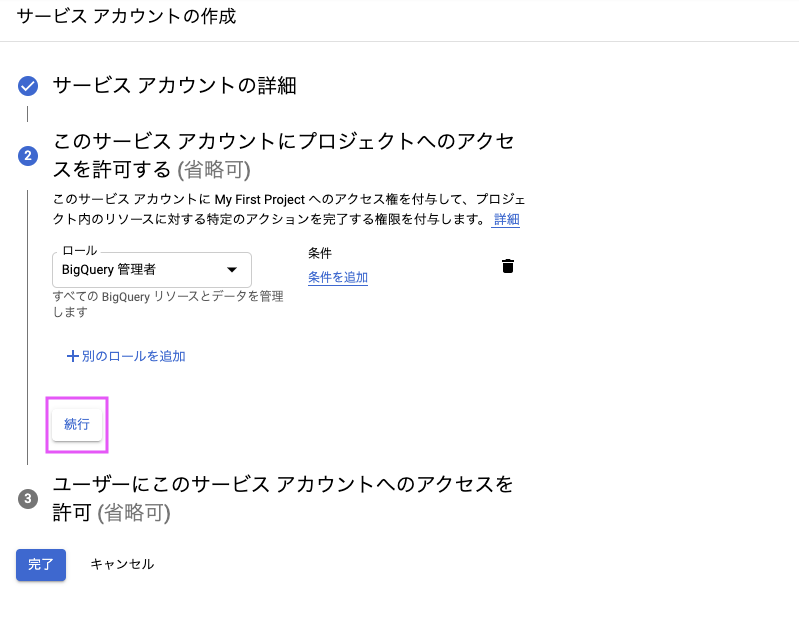
2-4. ロールを設定
「ロールの選択」から、BigQuery 管理者を選択し、「続行」をクリックします。

2-4. 「完了」をクリック
作成したサービスアカウントが表示されます。
2-5. 作成したサービスアカウントの操作をクリック、「鍵を管理」をクリック
2-6. 表示された画面で「鍵を追加」→「新しい鍵を作成」をクリック
2-7. キーのタイプ「JSON」のままで「作成」をクリック
その後、ファイル保存のダイアログが表示されるので、後から分かる場所に保存してください。

以上でGoogle Big Query側の操作は完了です。
3. CP4D: 仮想化のデータソース設定
ここからはCP4Dで作業します。
3.1. メニューから、「データ仮想化」を選びます。
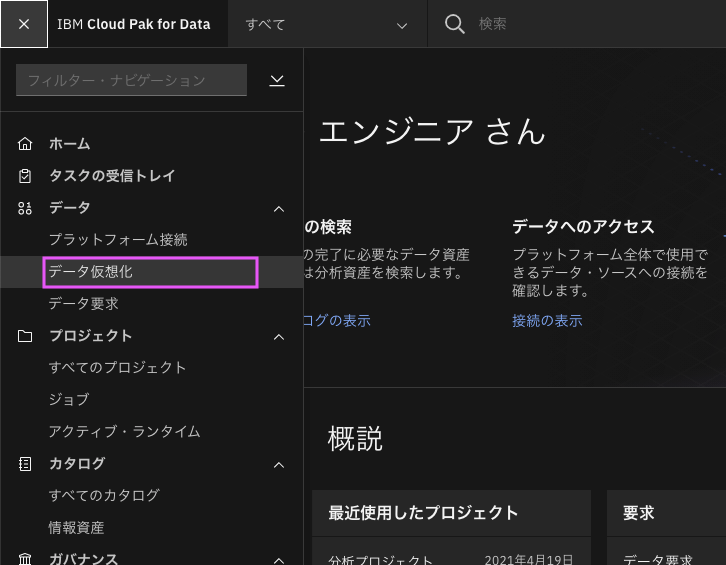
3-2. 「データソース」の画面で「データ・ソースの追加」→「新規接続の作成」をクリックします。
プラットフォーム接続で定義済みの場合は「既存の接続を選択」でも定義可能ですが、ここでは説明しません。

もし、「データソース」の画面が表示されなかったら、タイトルの横の∨マークをクリックして、メニューを出して、「データソース」を選択します。
このメニューに「データソース」の表示がなければ、権限がありませんので、管理者に相談してください。
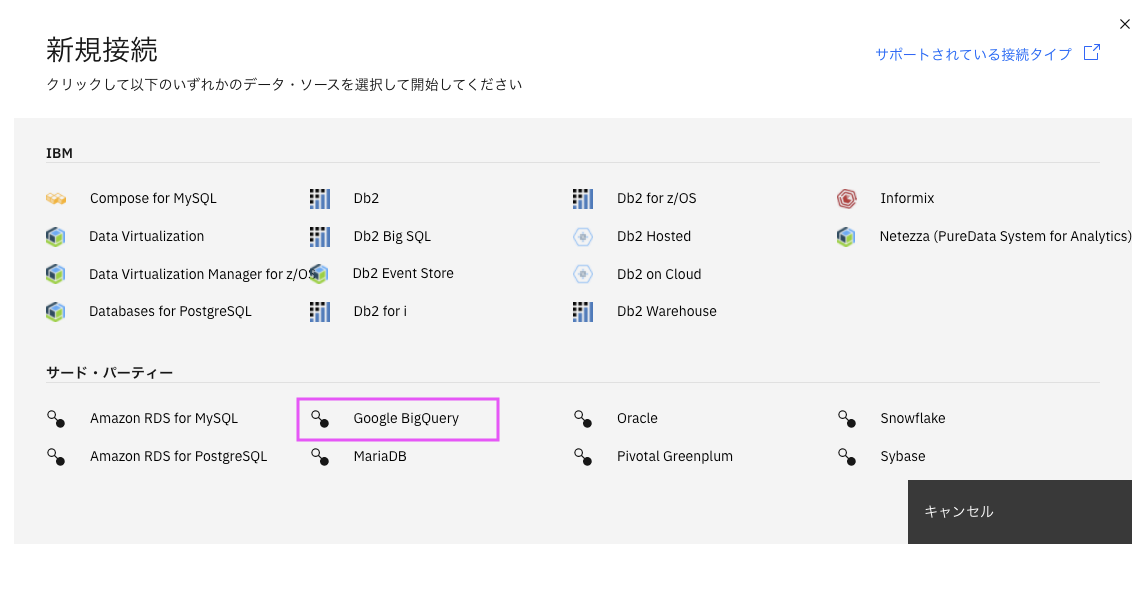
3-3. 「新規接続」の画面で「Google BigQuery」をクリックします。
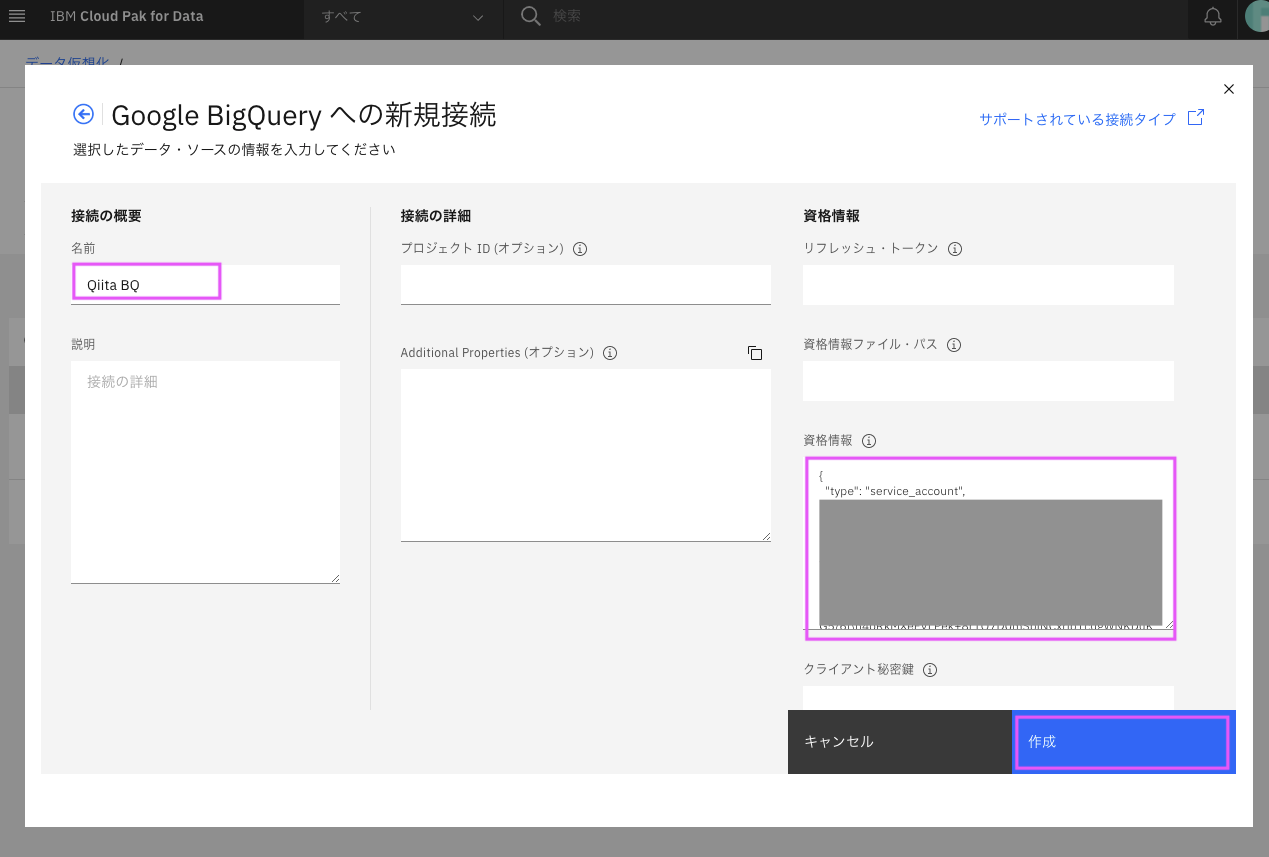
3-4. 「Google BigQuery への新規接続」の画面でデータ・ソースの情報を入力し後、「作成」をクリック。
- 名前: 任意の名前。 下の例では
Qiita BQ - 資格情報: 2-6でダウンロードしたファイルをエディタ等開いて表示し、その内容をコピペする。
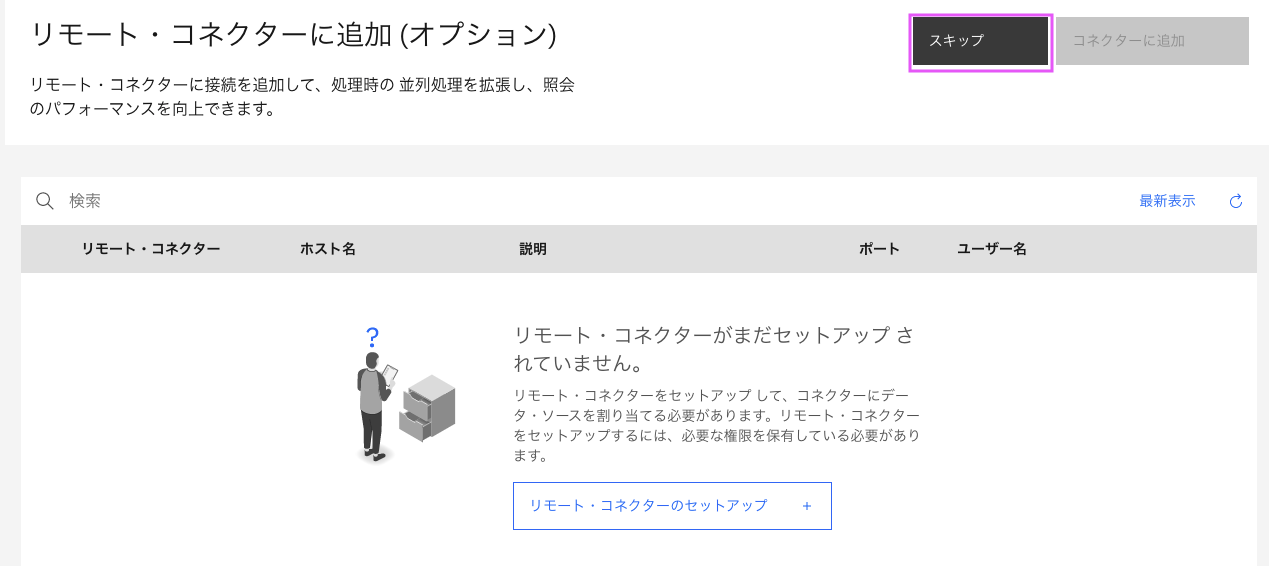
3-5. 「リモート・コネクターに追加 (オプション)」の画面では「スキップ」をクリック。
接続が成功すれば、無事データソース一覧に表示されます。

4.CP4D: Google Big Query上のテーブルを仮想化
ではいよいよCP4Dから Google Big Query上のテーブルを仮想化してアクセスしてみましょう!
「データ仮想化」の画面になっていない場合は、「3-1. メニューからデータ仮想化を選びます」の手順で「データ仮想化」の画面にします。
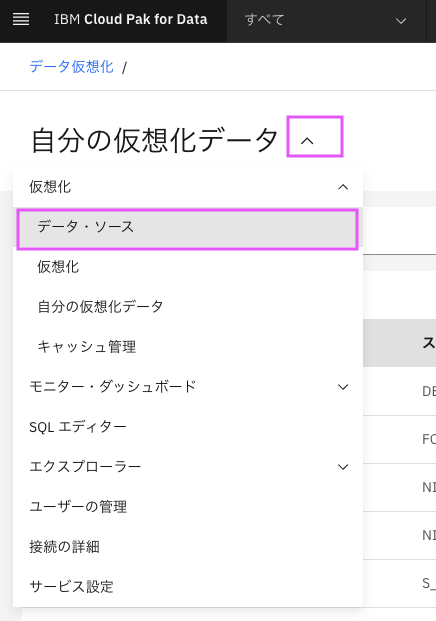
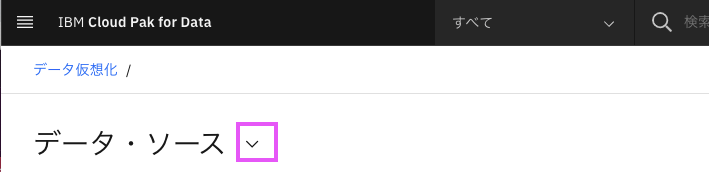
4-1. データ仮想化のメニューから、「仮想化」をクリック
データ仮想化のメニューはわかりにくいのですが、下記のようにページタイトル(ここではデータ・ソース)の右の∨マークをクリックして表示します。

4-2. 仮想化したいテーブルをチェックし、カートに追加
追加したデータソースからアクセス可能なテーブルが表示されています。
今回は1つしかありませんが、複数表示され見つからない場合は、データベースでフィルタリングしたり、検索窓にテーブル名を入れたりして絞って表示させましょう。

またテーブル名の右端の目玉(?)マークをクリックすると表の内容がプレビューできます。

MEMBERというテーブルを仮想化したいので、チェックを入れ、「カートに追加」をクリックします。
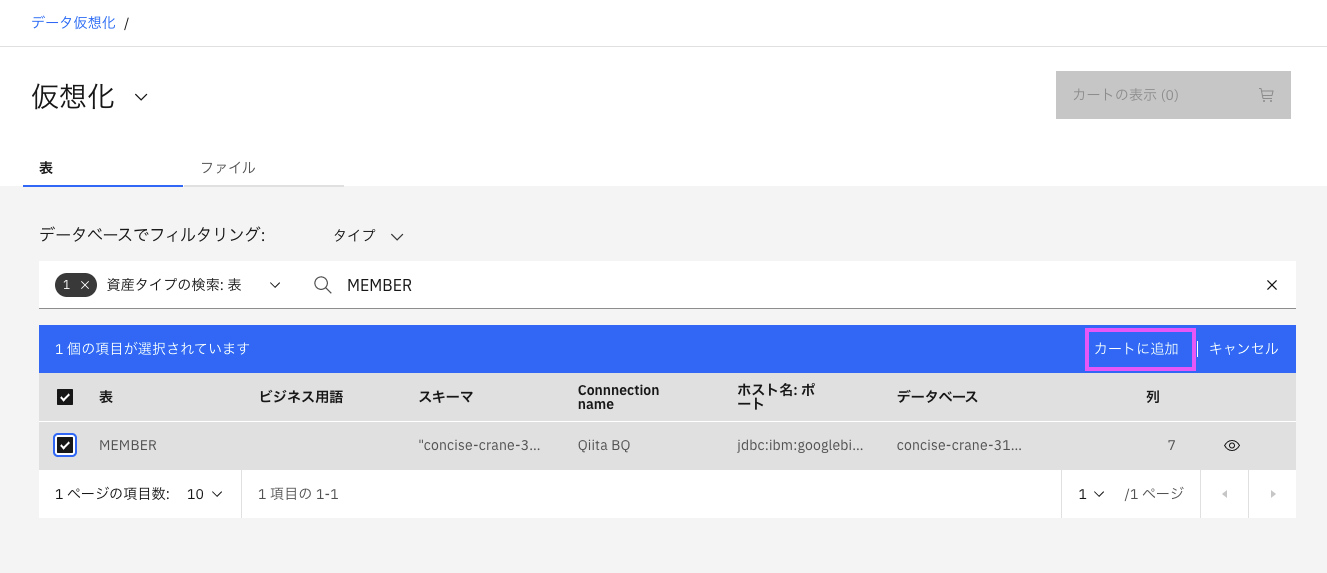
4-3. カートを表示
「カートの表示」をクリックし、カートを表示します。

仮想化する表の名前、スキーマは変更可能です(今回は変更しません)。また右側の縦の・・・メニューから、プレビューしたり、列名を編集したり、表をカートから削除することができます。
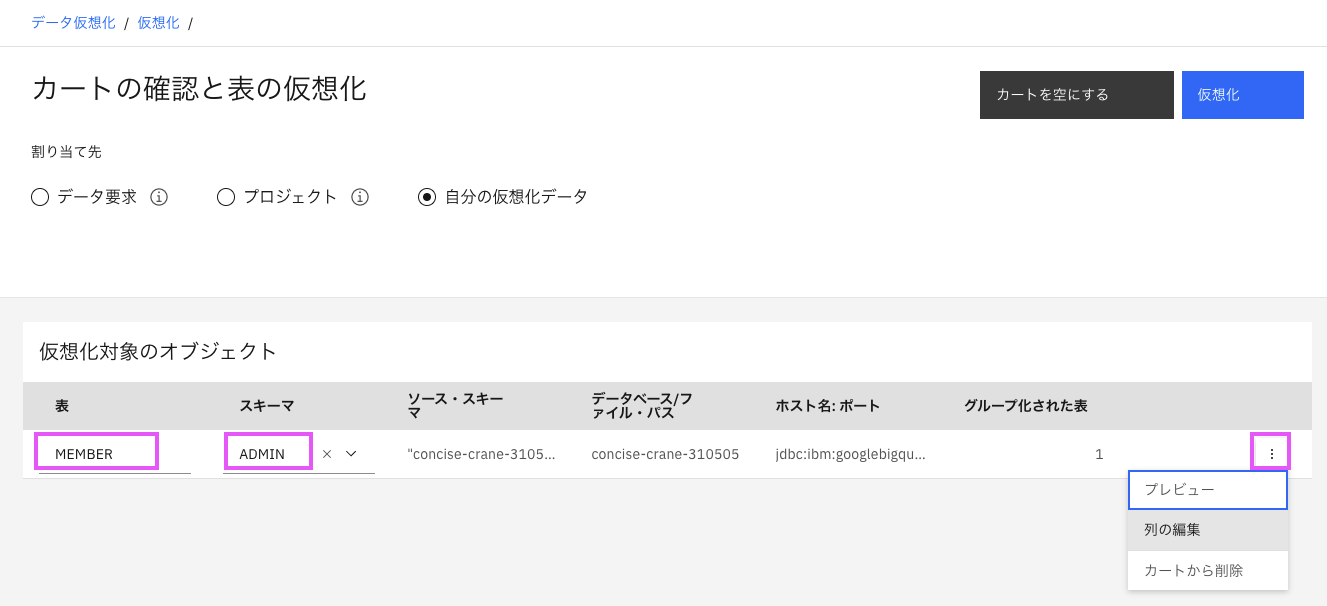
試しに「表の編集」をクリックしてみましょう。
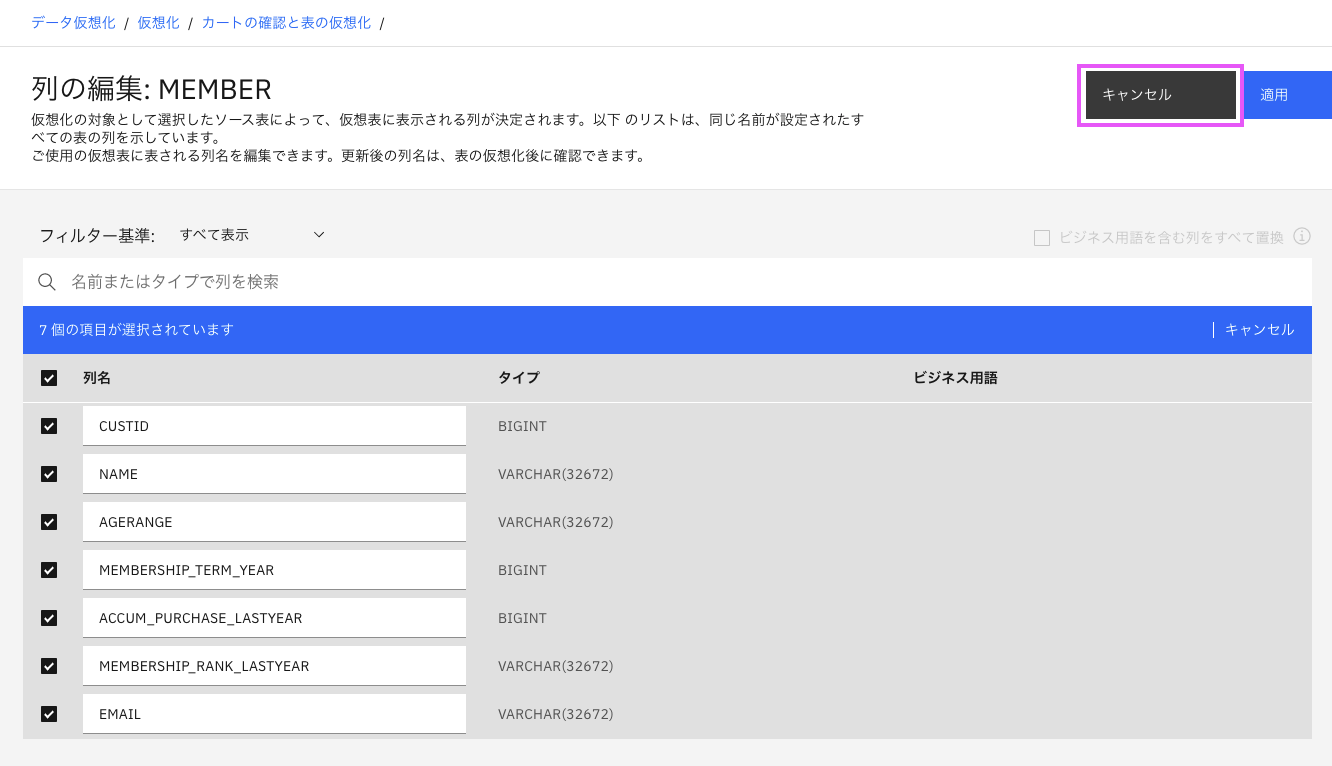
列名は編集可能で、日本語の列名にも変更できます。
また列も選択可能で、不要な列はチェックを外すことで、仮想化後のテーブルからはずずことができます。
変更した場合は「適用」クリックしてください。
ここでは変更せず、「キャンセル」で閉じます(上の黒い方のキャンセルをクリックしてください)。
4-4. 仮想化の実行
「仮想化」をクリックして仮想化を実行します。
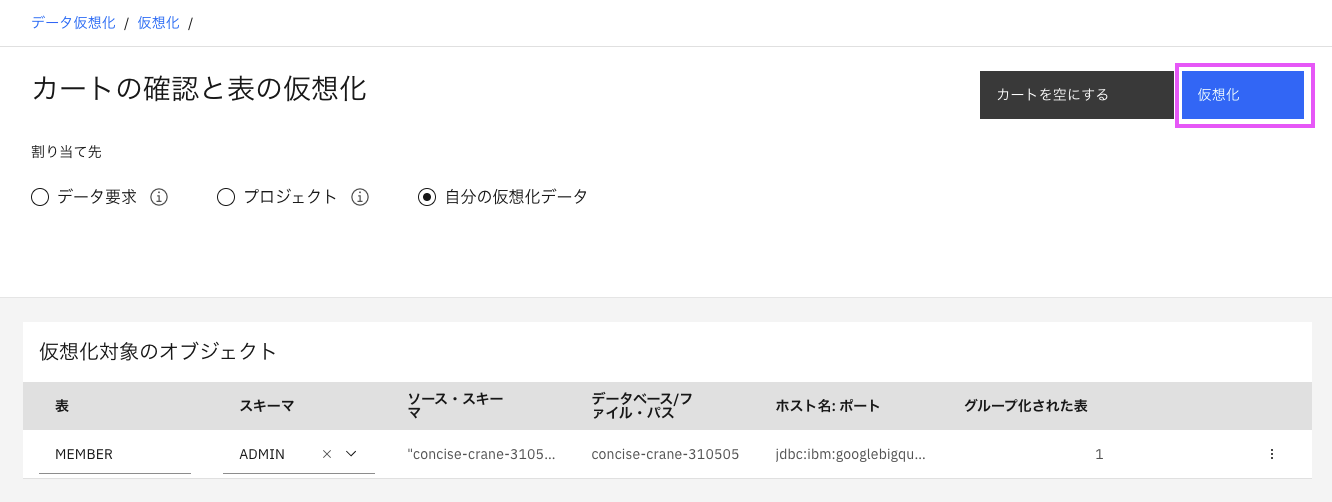
以下のような画面が表示され、成功しました! 「 自分の仮想化データを表示」をクリックして、確認してみましょう。
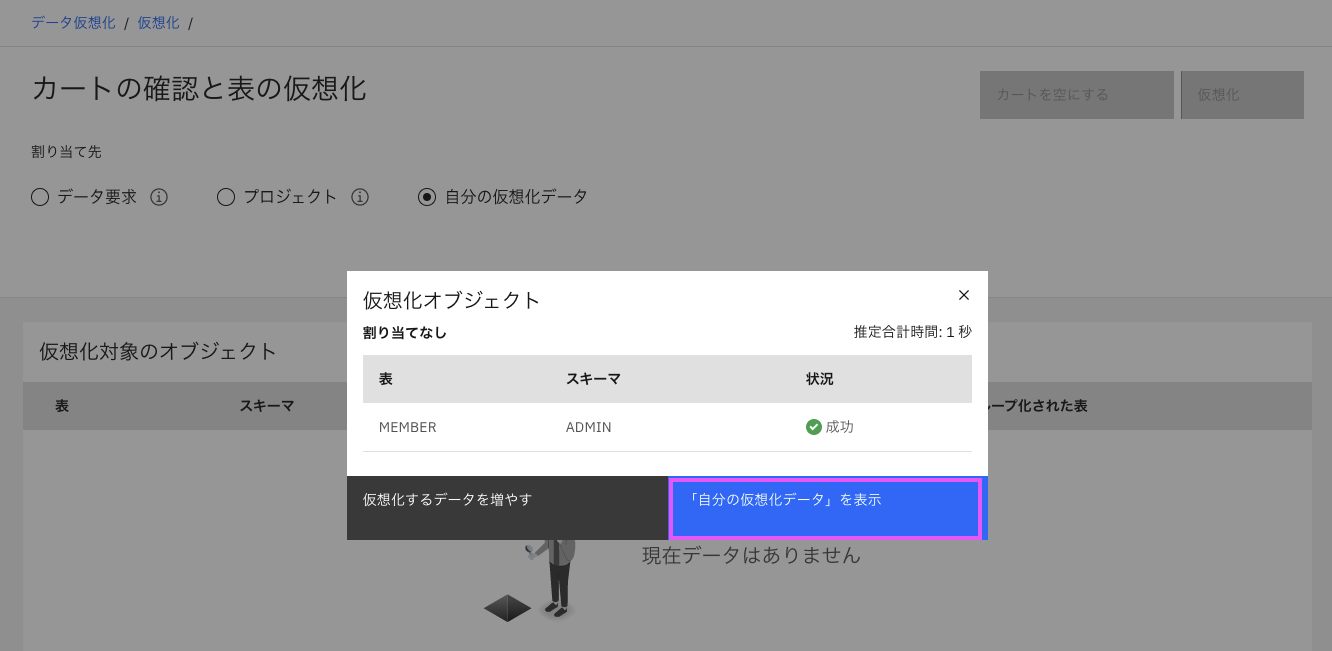
自分の仮想化データにテーブル名が表示されています。プレビューで見てみましょう。
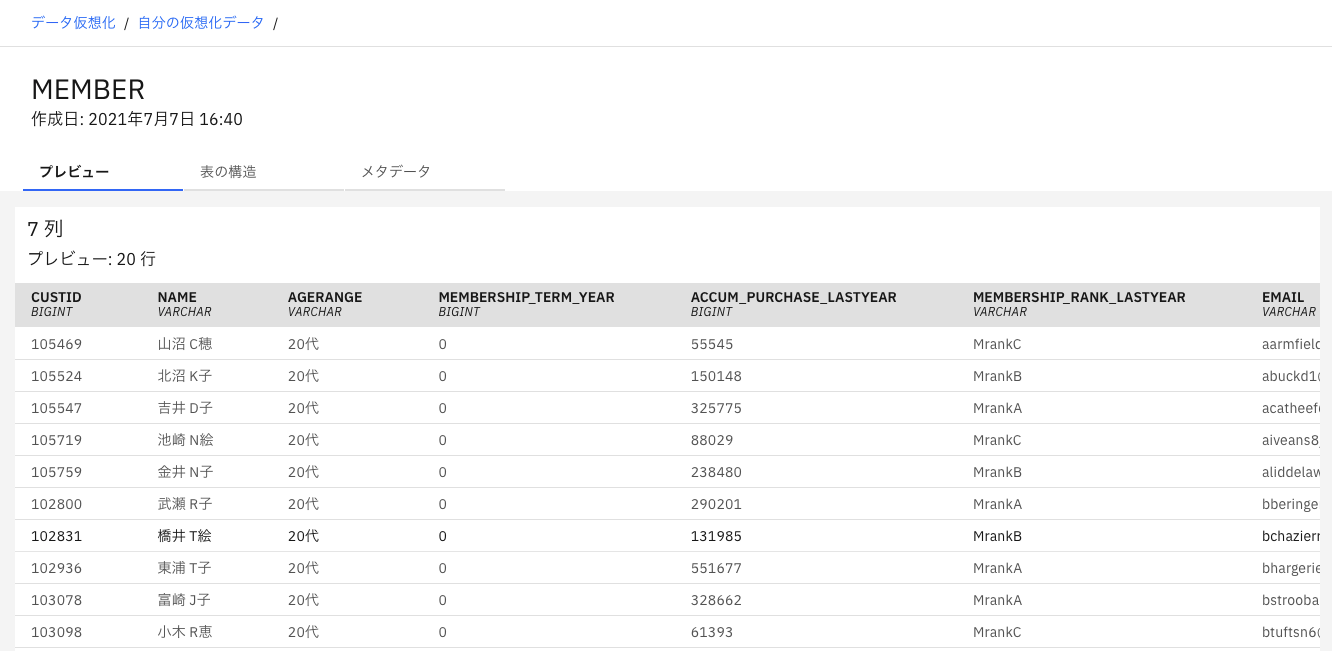
Google Big Query上のテーブルがCP4Dで仮想化されアクセスできました!
尚、この「自分の仮想化データ」の画面は、データ仮想化のメニューから、「自分の仮想化データ」をクリックすることで、表示可能です。
1つのテーブルのみを参照するなら直でGoogle Big Queryにアクセスすればよいのでは? と思うかもしれませんが、この仮想化したテーブルは、普通のDb2のテーブルと同じように、仮想化した他のテーブルとJOINしたビューを作成したり、そのJOINしたビューも含め、外部のBIツールからアクセス可能となります。
つまり、 仮想化すれば仮想化したテーブル同志、例えばGoogle Big Query上のテーブル、Db2のテーブル、Oracle DBのテーブルなどを3つJOINしたりして参照することができます。
またCP4D内のカタログに載せたり、プロジェクトと共有することが可能なので、CP4DのユーザーIDとCP4Dの適切な権限があれば、Google Big Query上に権限がなくとも簡単にデータアクセスが可能となります。
5.外部ツールからCP4D仮想化DBにアクセス
CP4D以外のツールからCP4D仮想化DBにアクセスしてみます。
5-1. 権限の確認
仮想化した本人のIDを使わない場合は、、データ仮想化のメニューから、「ユーザー管理」をクリックして、「ユーザーの追加」からIDを追加してください。
5-2. 接続情報の確認
CP4D仮想化DBへの接続情報は、データ仮想化のメニューから、「接続の詳細」をクリックして表示します。
右側にDb2としての接続情報が書いてありますので、Db2に接続可能なツールであれば接続してデータを参照することが可能です。(今回はSSLなしで接続します)
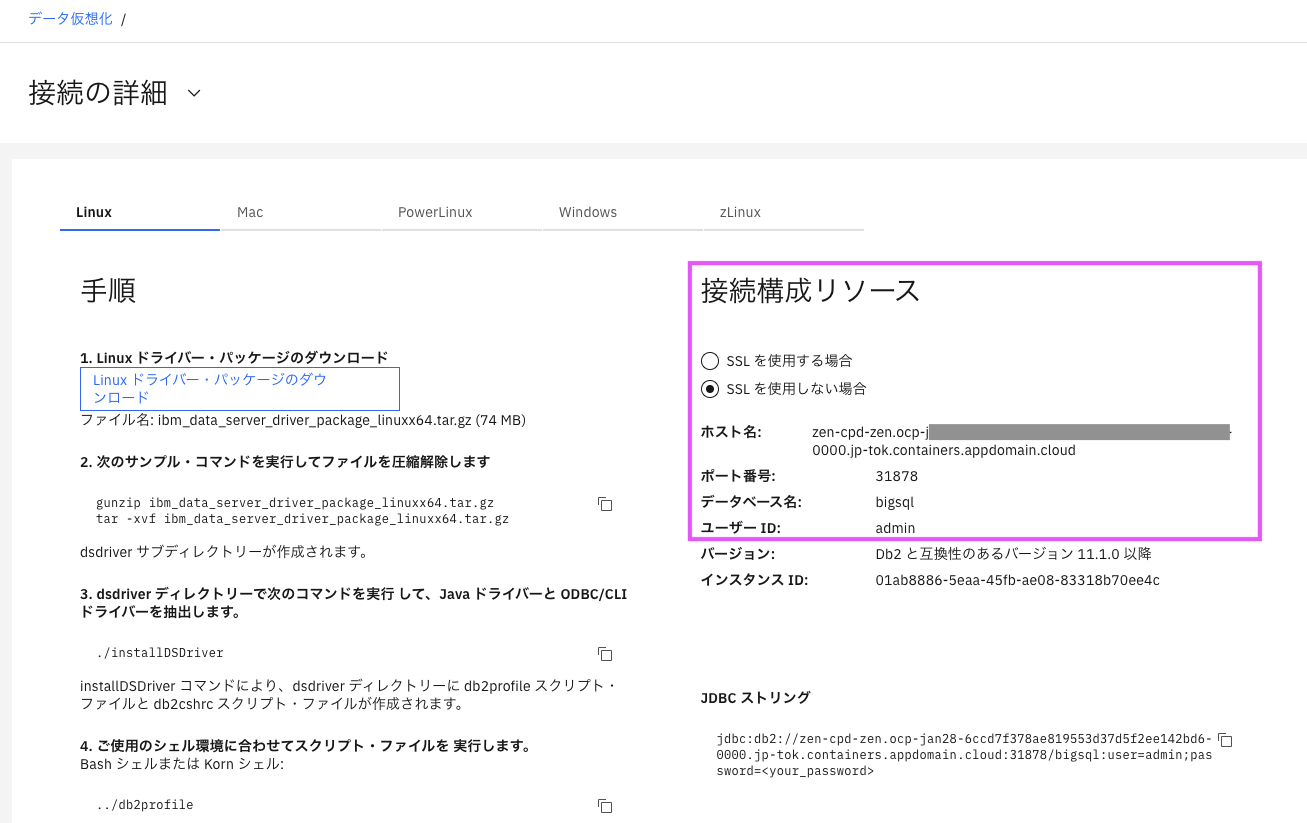
5-3. 接続してみる
OSSのDB Tool DBeaverから接続します。

なぜかテーブル一覧が表示できませんでしたが、SQL実行はOKでした!

以上です。