WatsonStudioのNotebookでプロジェクトのデータ資産としてアップロード済みのExcelファイルまたはCSVファイルを pandasのDataFrameに読み込むのは、WatsonStudioのNotebookがコードを生成してくれるので非常に簡単にできます。
参考(製品ドキュメント):
https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/data-load-support.html?context=cpdaas&audience=wdp&locale=en
0. (前準備)Notebookを開いた状態ででプロジェクトのデータ資産としてファイルをアップロード
既にアップロード済みの場合はここは飛ばしてください。
まだファイルをプロジェクトのデータ資産としてアップロードしていない場合は、以下の方法でアップロードできます。
0-1. notebookを編集状態で開き、右上の01/00のアイコン「データの検索と追加」をクリックします。
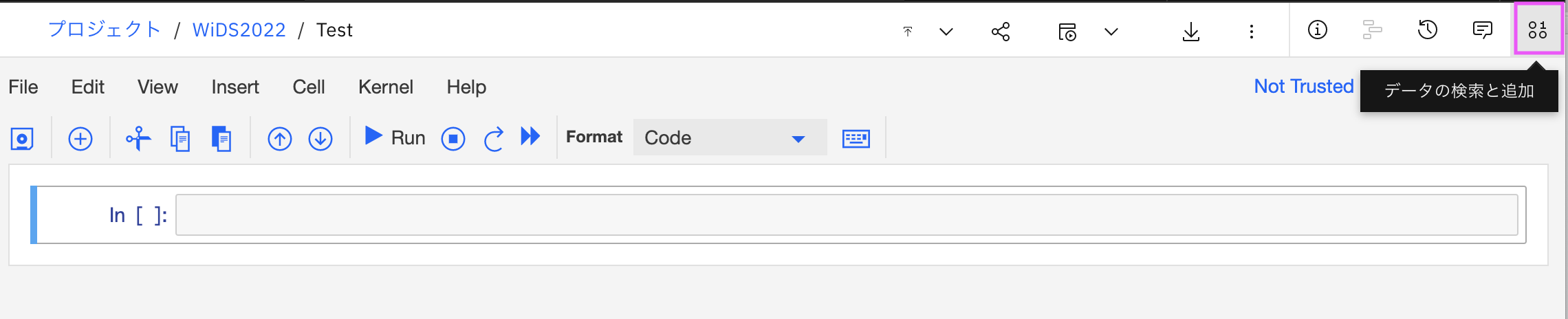
データの画面が右側に開きます。
0-2. 「ここにファイルをドラッグ・アンド・ドロップするか、アップロードしてください。」と書かれた四角のエリアにアップロードしたいファイルをドラッグ・アンド・ドロップするか、そのエリアをクリックしてファイルダイアログからファイルを選択してアップロードを実行します。
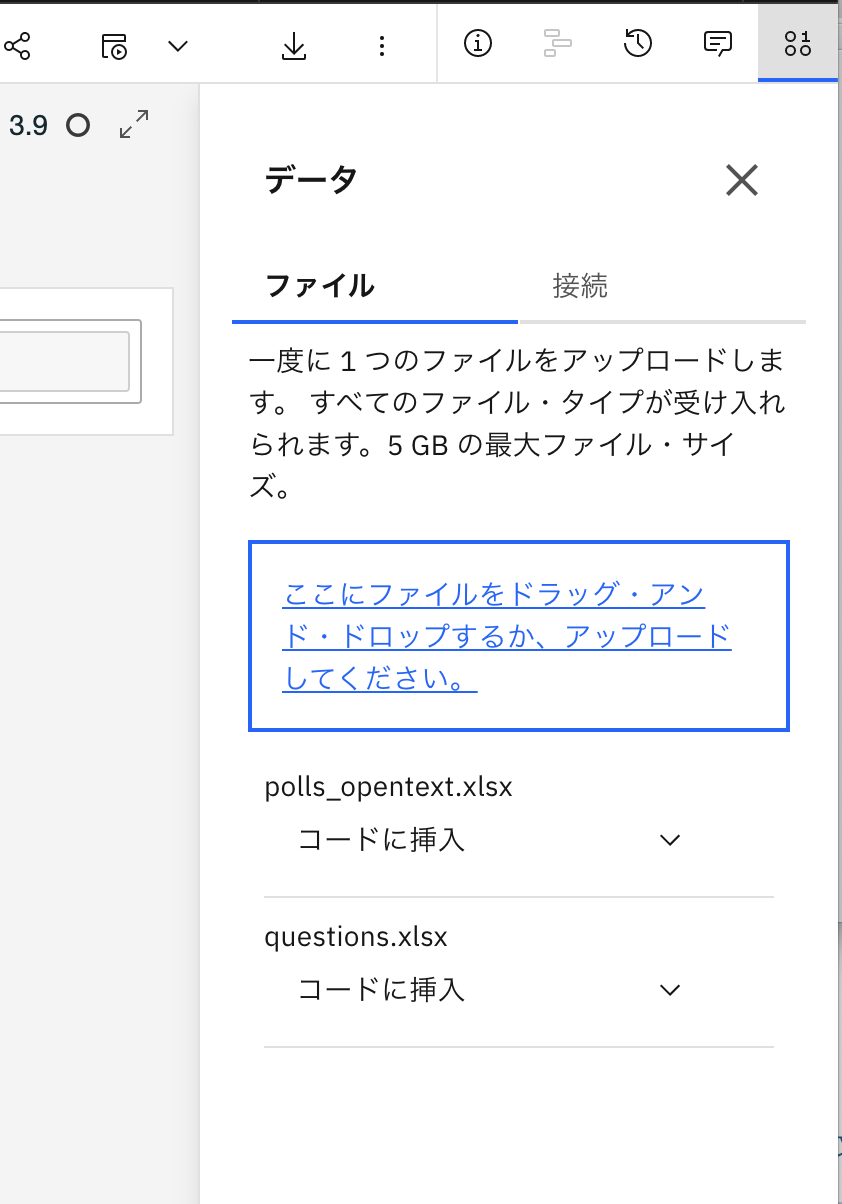
アップロードが完了すると 「ここにファイルをドラッグ・アンド・ドロップするか、アップロードしてください。」の四角の下に、ファイル名と「コードに挿入」のメニューが表示されます。

1. NotebookにpandasのDataFrameに読み込むためのセルを準備
ここでは新たにセルを追加してそこにカーソルを置いて、コードを入れるようにします。
既存のセルでも問題ありませんが、その場合カーソルのある部分からpandasのDataFrameに読み込むコードが生成されます。
上のメニューアイコンからプラスのアイコンをクリックしてセルを追加します。

2. 追加したセルをクリック
追加したセルをクリックしてカーソルをセルにおきます。
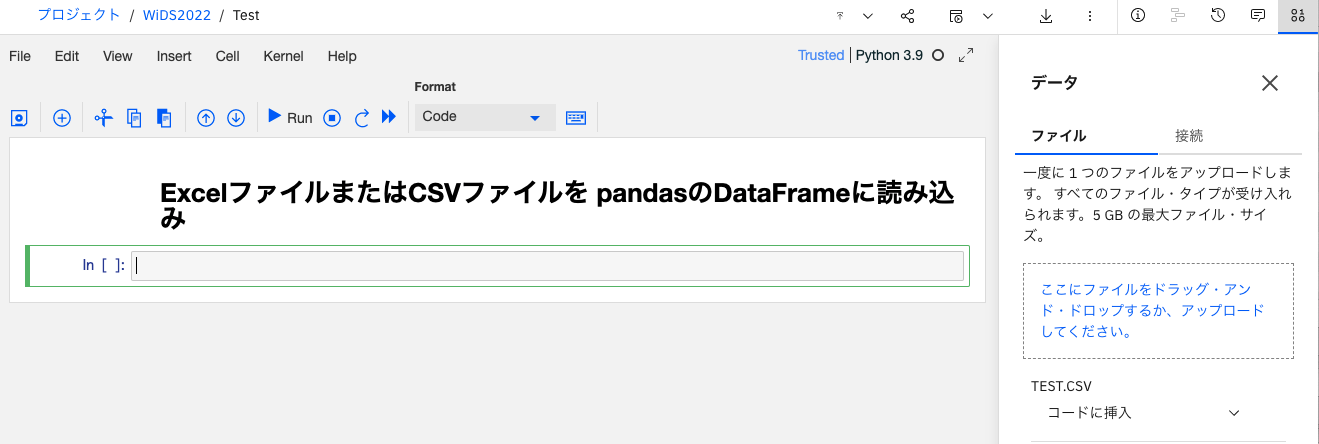
3. 右側のデータのエリアからpandasのDataFrameに読み込みたいファイルの下にある、「コードに挿入」のメニューをクリック。表示されたドロップダウンメニューから「pandas DataFrame」をクリック。

セルにpandasのDataFrameであるdf_data_X (Xは数字)に指定したファイルを読み込むコードが挿入されます。df_data_の後のXの数字は1だったり、0だったりします。
どこにも書いてはないですが、CSVは1でExcelは0のような気がしています(あくまでも個人の考えです)。
下のイメージでは、df_data_Xはdf_data_1となっています。

4. セルの実行
セルを実行してdf_data_X (Xは数字)にデータを読み込ませます。
最後にdf_data_X.head()のコードが入っているので、読み込んだ最初の5行が表示されます。

最初の1行目はデフォルトでヘッダー項目行とみなされます。
もし最初の1行目はヘッダー項目行ではなくデータ行の場合は、
df_data_1 = pd.read_csv(body)
の行をpandas.read_csvのオプションを付けて変更します。header=Noneを引数に付けます。
デフォルトで数字の列名がつきます。
df_data_1 = pd.read_csv(body, header=None)

数字の列名ではなく、列名を指定したい場合は
names=['<列名1>', '<列名2>']
のようにnamesを引数に加えます。
df_data_1 = pd.read_csv(body, header=None, names=['item', 'number'])

Excel(read_excel)の場合も同様のオプションです。
これでpandasのDataFrameにデータが入りました!
次に別のファイルを読み込む場合、同じ種類のファイルの場合は同じdf_data_X (Xは数字)という変数名が使用され、上書きされてしまうので、データを取っておきたい場合はコピーしておきます。
df_my_data1 = df_data_1.copy()
ちなみにCSV, ExcelファイルだけでなくJSONなど他のファイルタイプも同じ感じで読み込めますので、他のファイルタイプも読み込みたい場合はドキュメントを参考にしてみてください。
以上です。