前書き
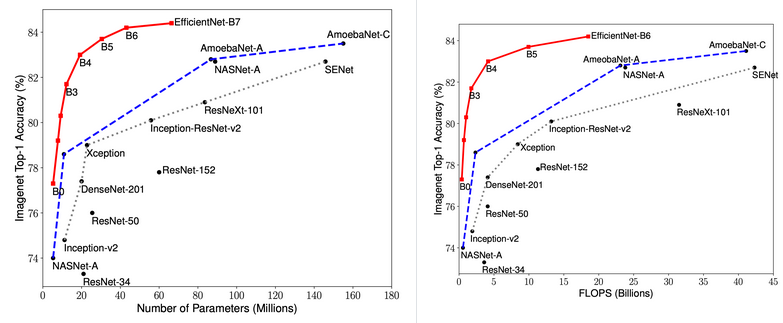
有名なEfficientNetは精度当たりのFLOPSやParamsではかなり優秀な部類に入り、実際これを更新するのは困難である。実際、最近のSOTAの更新もモデル自体はEfficientNetという新鮮味のない更新が多い。
一方でGPUの実効速度という観点ではFLOPSは実効速度と乖離しており、必ずしも同精度でEfficientNetが最速なわけではない。これらの論文群は以下の様な共通点がある。
・**GPU(Nvidia V100)でEfficientNetの数倍の実効速度を持つ。
・FLOPS、ParamsではなくThroughput([img/s])やLatency([ms/img])**で評価を行う。
・**inference latency(推論速度)とtraining latency(学習速度)**がある。
・ResNetからの進化であることが多い。
Assemble-ResNet
https://arxiv.org/pdf/2001.06268v2.pdf
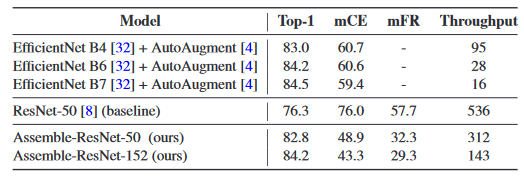
B4:x3.3、B6:x5.1
Throughputはinference(推論)。GPUは 8 P40 GPUs。
企業:NAVER
RegNet
https://arxiv.org/pdf/2003.13678.pdf
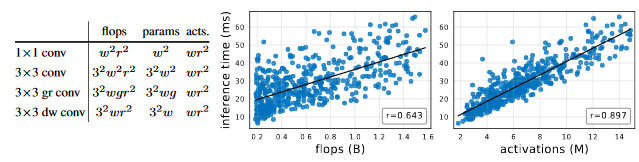
activationsという指数で比較が行われている。この指数の方がFLOPSよりも実効速度を反映しているかのように見えるが、これは他の論文に使われていない。
この指数では1x1Convと3x3DWConvと3x3Convの速度が等しい。
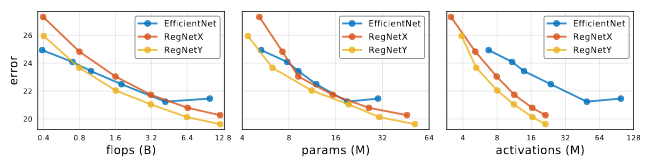
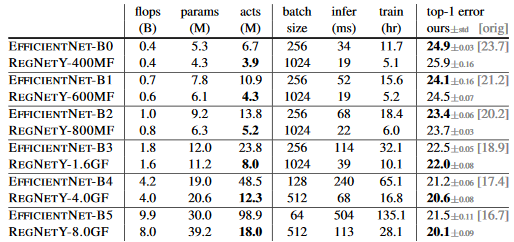
B0:x1.8、B1:x2.7、B2:x3.1、B3:x2.9、B4:x3.5、B5:x4.5
inference(推論)とtraining(学習)。GPUは8 V100 GPUs。
企業:Facebook
TResNet
https://arxiv.org/pdf/2003.13630v3.pdf
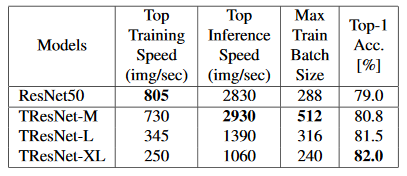
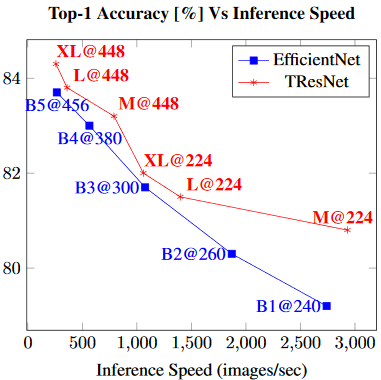
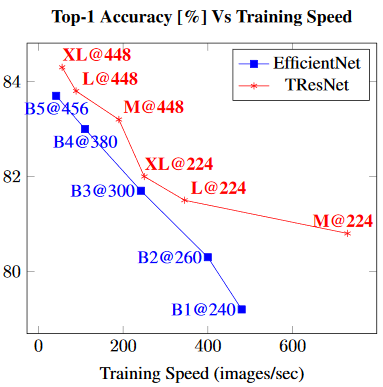
B1~B5:x1.5~x2.0
Throughputはinference(推論)とtraining(学習)。GPUは8xV100 GPU。
企業:Alibaba
ReXNet
https://github.com/clovaai/rexnet
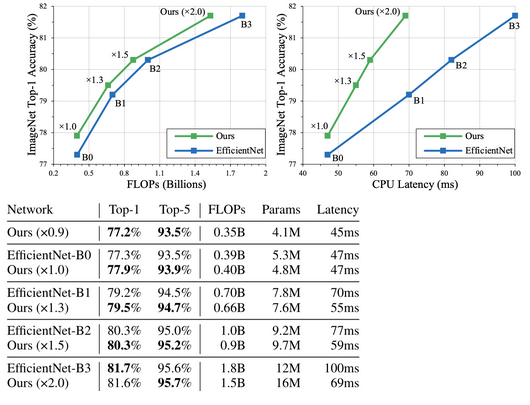
GPU速度ではなくCPU速度でだがEfficientNetを上回る。
また、FLOPSもEfficientNetを改善している。
企業:NAVER
ResNeSt
https://arxiv.org/pdf/2004.08955.pdf
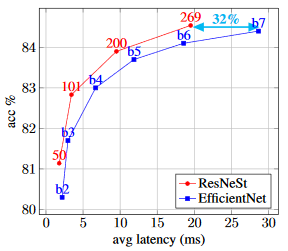
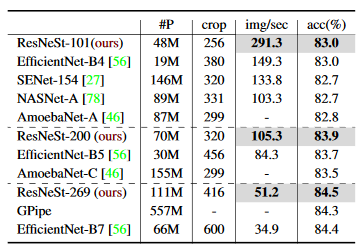
B4:x2.0、B5:x1.2、B7:x1.5
Throughputはinference(推論)。GPUはsingle V100 GPU。
企業:Facebook
GENet
https://arxiv.org/pdf/2006.14090.pdf
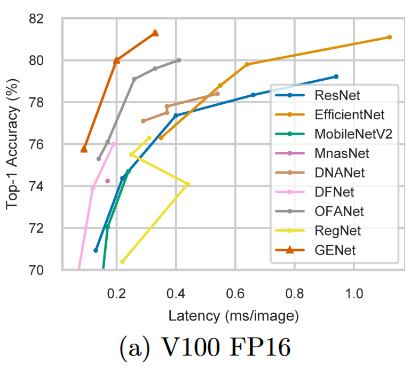
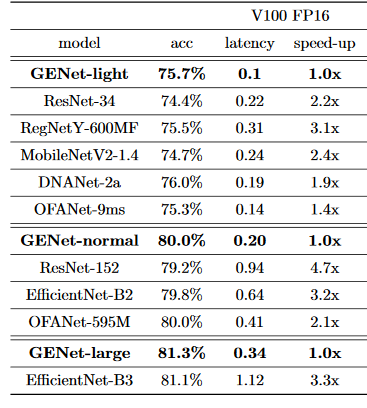
B2:x3.2、B5:x3.3
Throughputはinference(推論)。GPUは24 V100 GPUs。
このグラフではFacebookのRegNetは大した性能は出ていない。
企業:Alibaba
LambdaResNet
https://openreview.net/pdf?id=xTJEN-ggl1b
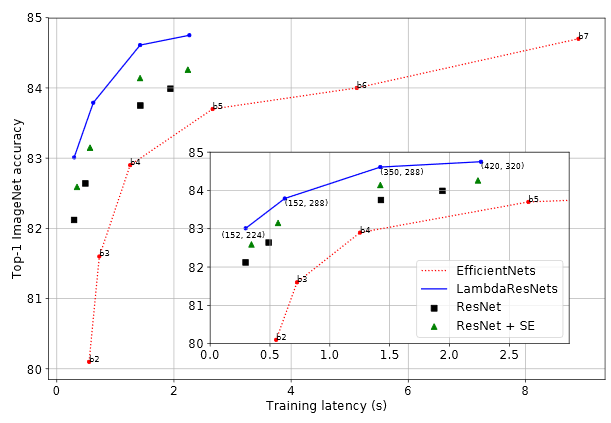
B4:x4.3、B5:x4.4
Throughputはtraining(学習)。32 TPUv3で4096個の画像のlatency。
DeiT
https://arxiv.org/pdf/2012.12877v1.pdf
ViT由来のようである。
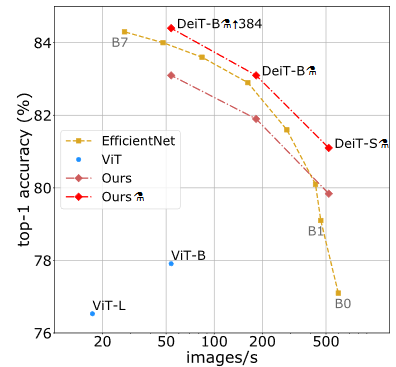
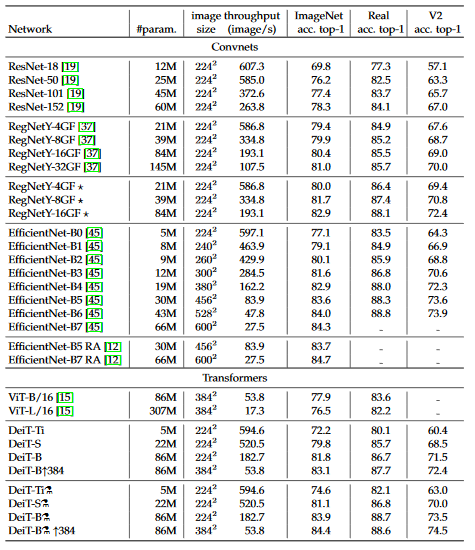
B3:x1.8、B6:x3.8、B7:x2.0
GPUはone V100 GPU。
企業:Facebook
まとめ:
EfficientNetよりも速いモデルを整理してどれが一番速いのか見積もろうとしたのだが、GPUの設定がバラバラでThroughputを並べて比較することが出来ませんでした。EfficientNet比で見ると3~5倍になっているモデルが多いです。
将来的にTensorコアの性能進化(A100)やTPUの発展を考えると、V100 GPUという固有GPUの最適化自体に意味があるかはちょっと疑問に思いました。
参考: