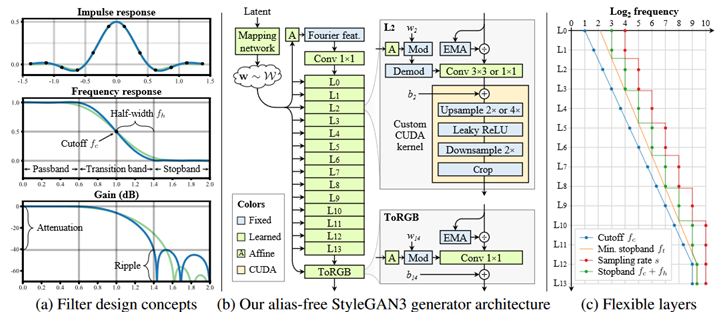
いつの間にかStyleGAN3が発表されていたので、少しだけ触ってみました。
自分は初代のStyleGANは少しだけ触ったことがありましたが、StyleGAN2やStyleGAN2-adaに関しては触ったことがありませんので微妙な変化は追えていないかもしれません。
論文:https://arxiv.org/abs/2106.12423
初代StyleGANとの違い(印象)
・実装はtensorflowではなくpytorchである。
・torch_extensionsの追加プラグインをビルドするのにninjaを使っている。
自分の初期環境ではこれがこけるので動作させるまでに手こずった。
・モデルの重みがGoogleDriveではなくnvidiaの公式のサイトに公開されている。
File Browser=>action=>Downloadで直接ローカルに保存もできる(Firefoxだと何故かダメ)。GoogleDriveの接続制限で時間をおいてダウンロードできるまで待つという事はなくなる。
https://ngc.nvidia.com/catalog/models/nvidia:research:stylegan3
・モデルのタイプが2パターンある
rとtの2パターン。違いはよく分かりません。論文にはこうあります。
柔軟なレイヤー仕様(config T)変更により、等分散品質が向上しました。
回転同変(config R)ネットワークの回転同変バージョンを取得します。
・生成画像のアフィン変換がある。
画像生成コード例(gen_images.py)ではアフィン変換でStyleGAN3画像の回転、平行移動に対応している。拡大縮小、反転に関して仕様から外されているが、アフィン変換の行列を自分で作れば出来るように見える。
・動画生成のコード例(gen_video.py)がある。触ってない。
・GUIツール(visualizer.py)がある。これを使うと論文などにある近未来的なカラフルな隈取り模様が見られるのだが、その視覚化が何のために存在するのか理解していない。
追加プラグインのビルドに失敗する
現象としては以下のリンク先の現象参考:
原因は詳しく分かっていないが、追加プラグインのビルドに失敗する事が起こりました。
C:\Users\<<username>>\AppData\Local\torch_extensions\torch_extensions\Cacheの場所にあるビルドに失敗する(Windows機)。結論としては自分の場合もリンク先に書かれているようにCUDAを一度アンインストールしてから、CUDAの再インストールが必要だった。
Setting up PyTorch plugin "bias_act_plugin"... ~(中略)
...
Failed!
https://github.com/NVlabs/stylegan2-ada-pytorch/issues/39
https://github.com/NVlabs/stylegan2-ada-pytorch/issues/67
https://teratail.com/questions/349906
自分の環境ではインストールしているVisual Studioが混在しており、ninja.buildに書かれるリンク用の環境変数が元はC:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\binだった。
この環境変数を削除してC:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\x64の環境変数を追加して(cl.exeのある場所)、CUDA関連をプログラムから全てアンインストールして、CUDAを再インストールして、cuDNN入れて、あと再起動すると動作した。
Anacondaからnvcc -Vと打った時のCUDAのversionを確認する時、CUDAは11.1以上である必要がある。
Anacondaからclと打った時のVisual Studioのversionを確認する。リンクに使われる。
Anacondaからgcc --versionと打った場合のgccのversionは関係ないようである。
実行例
ローカルに保存したpklのファイルを読み込んで簡単に試すコードは以下の通りである。
$G$はStyleGAN3の画像生成モデル。
変数$z$は$(1,512)$次元の潜在変数。
変数$w$は$(1,16,512)$次元の潜在変数。
変数$c$はラベルだが今回の場合は多分使用しない。
truncation_psiは潜在変数の超ガウス球の半径。
生成画像の次元はpytorchなので$(1, 3, 1024, 1024)$だが、PIL画像にするには次元を入れ替える必要がある。
import numpy as np
import PIL.Image
import torch
import pickle
path = './stylegan3-r-ffhq-1024x1024.pkl'
with open(path, 'rb') as f:
G = pickle.load(f)['G_ema'].cuda()
seed = 0
z = torch.from_numpy(np.random.RandomState(seed).randn(1, G.z_dim)).cuda()
c = None
w = G.mapping(z, c, truncation_psi=0.5, truncation_cutoff=8)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save('./out/test.png')
結果、以下の様な画像が保存される。

実行例2(アフィン変換)
潜在変数$w$を求めた後、G.synthesisで画像生成するまでにアフィン変換を挿入した場合の確認を行う。
m=\begin{pmatrix}
S_x cos \theta & S_x sin \theta & t_x\\
-S_y sin \theta & S_y cos \theta & t_y\\
0 & 0 & 1
\end{pmatrix}
def transform(G, angle, tx, ty, sx, sy):
m = np.eye(3)
s = np.sin(angle/360.0*np.pi*2)
c = np.cos(angle/360.0*np.pi*2)
m[0][0] = sx*c
m[0][1] = sx*s
m[0][2] = tx
m[1][0] = -sy*s
m[1][1] = sy*c
m[1][2] = ty
m = np.linalg.inv(m)
G.synthesis.input.transform.copy_(torch.from_numpy(m))
################################################################################
angle = 20
tx, ty = 0.0, 0.0
sx, sy = 1.0, 1.0
transform(G, angle, tx, ty, sx, sy)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save('./out/test2.png')
################################################################################
angle = 0
tx, ty = 0.0, 0.0
sx, sy = 1.1, 1.0
transform(G, angle, tx, ty, sx, sy)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save('./out/test3.png')
################################################################################
angle = 0
tx, ty = 0.0, 0.0
sx, sy = -1.0, 1.0
transform(G, angle, tx, ty, sx, sy)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save('./out/test4.png')
################################################################################
angle = 0
tx, ty = 0.2, 0.3
sx, sy = 1.0, 1.0
transform(G, angle, tx, ty, sx, sy)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save('./out/test5.png')
################################################################################
angle = 20
tx, ty = 0.1, -0.1
sx, sy = -0.9, 0.9
transform(G, angle, tx, ty, sx, sy)
img = G.synthesis(w, noise_mode='const', force_fp32=True)
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save('./out/test6.png')
以下のアフィン変換各種の実行結果は以下の様になります。
オリジナル、回転、拡大、
反転、平行移動、複合が確認できました。

※注意:
sx=1.0より小さくした場合、何故か生成画像の目と目の距離が相対的に縮まります。例えばsx=0.7にした場合は2個の目が繋がってしまいます。この画像は非常におぞましく、グロテスクなのでsxの値を0.85以下にするのは推奨しません。
ローパスフィルタ
論文にある以下の図の意味を考える。
離散的な点にsinc関数の畳み込みを考えると連続的なデータになる。
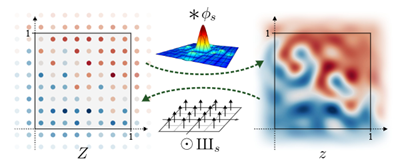
一般に関数$f(x)$(画像)と$g(x)$(フィルタ)の畳み込み演算(記号$*$)を行った結果を$h(x)$とする場合、関数$f(x),g(x),h(x)$をFFT(フーリエ変換)した関数をそれぞれ$F(u),G(u),H(u)$とするとFFT後の関係式は周波数領域では畳み込みではなく、単なる関数の乗算で計算できる。
h(x)=g(x)*f(x) \\
H(u)=G(u) \cdot F(u)
$g(x)$をガウスフィルタとした場合、FFTした関数もガウス関数$G(u)$である。
$g(x)$を平滑フィルタ(矩形関数、$rect$関数)とした場合、FFTした関数$G(u)$は$sinc$関数$(= \sin x/x)$となる。
$g(x)$をsincフィルタ($sinc$関数)とした場合、FFTした関数$G(u)$は$rect$関数(矩形関数)となる。
さて、周波数領域に$rect$関数(矩形関数)$G(u)$を掛けるというのは高周波数領域をカットオフする急峻なローパスフィルタを掛ける事に等しい。一般に高周波領域をカットオフすると画像がぼやけるのと同義だが、これはsincフィルタを畳み込んだ結果に等しい。
また、ガウスフィルタの畳み込みを行う事も画像をぼかす事と等しいが、こちらは周波数領域でガウス関数$G(u)$の積を掛ける事になるので緩やかなローパスフィルタを掛ける事と同義になる。
UpsamplingとDownsamplingとこの周波数上のローパスフィルタとの関連が何となく示唆されているように感じるが、詳しくは分からない。正直、理想的なUpsamplingしてからDownsamplingしても結果は何も変わらないのではと思う。しかしながら周波数上の補間が何かあるのではないか、そしてそれが潜在変数空間の連続性に何らかの寄与を与えるのかなぁ、と思いました(でも、よく分かりません)。