はじめに
Wan2.2-FunControl、Wan2.2-VACE、Wan-Animateはいずれも参照画像と参照モーションを与えて参照画像を動かすことができる。例えば「家の中にいるキャラクターの画像」と「ビーチで踊る一般人の動画」があれば「家の中で踊るキャラクターの動画」を生成できる。反面、これらの違いは解説記事もなく正直良く分からない。
Wan-AnimateとWan-VACEの論文からこれらの違いを考えてみたい。
Wan-Animateのモード
Wan-Animateの論文では従来のアニメーションモード(Animation Mode)(前述した「家の中で踊るキャラクターの動画」を生成)以外に置換モード(Replacement Mode)というのがありこれは参照動画の背景を使う「ビーチで踊るキャラクターの動画」をつくる。
論文ではアニメーションモードはI2Vライクで置換モードはV2Vライクだという解説がある。おそらく出来上がる動画が、参照動画の背景と動きをコピーした動画が出来上がるという点でV2Vに近いと言っているのだと思う。
自分的には「ビーチで踊る一般人」の動画の人物部分をマスクで指定しノイズで塗りつぶして上からキャラクターを描き込むという原理なのならInpaintモデルのほうが近いように思った。
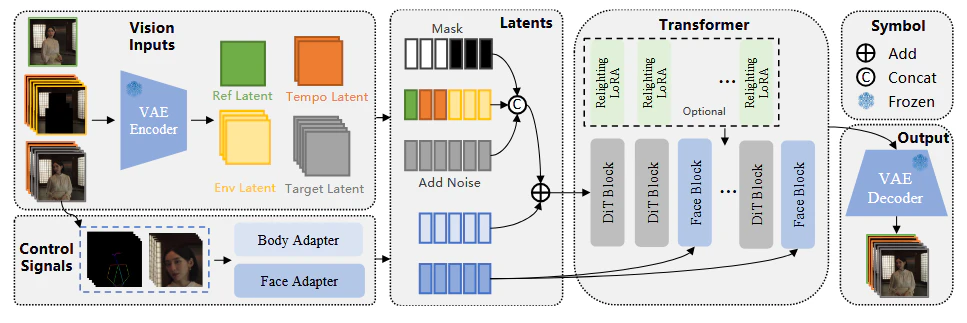
Wan-Animateの図
論文によれば以下の通りである。
Ref Latentは参照画像のVAEを通したImage Tokenである。
Temporal Latentは何をするためか不明。
Env Latentは置換モードにおいて動画のセグメントして人物部分のノイズで塗りつぶす。また人物領域のMASKを用意する。
Traget Latentは参照モーション動画をVAEに通したvideo tokenだろう。vid2vidのようにノイズを加えて開始latentとできる。
またControl信号は顔部分や動画のスケルトン情報を抽出し、これをNoise latentにそのまま足すものと条件信号となってるものが見える。
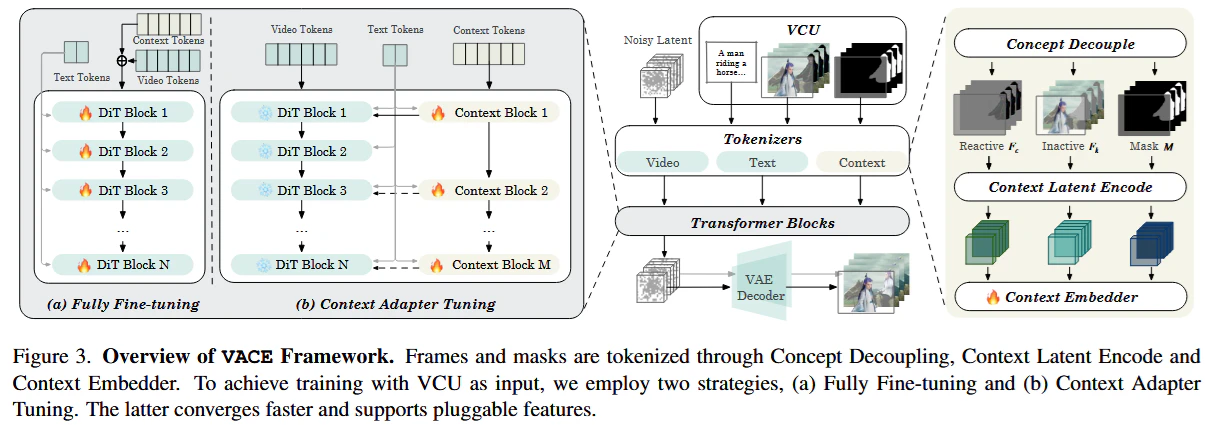
Wan-VACEのContext Adapter
VACEにおけるContext Adapterは従来のDiTブロックに並列にDiTブロックを挿入する。
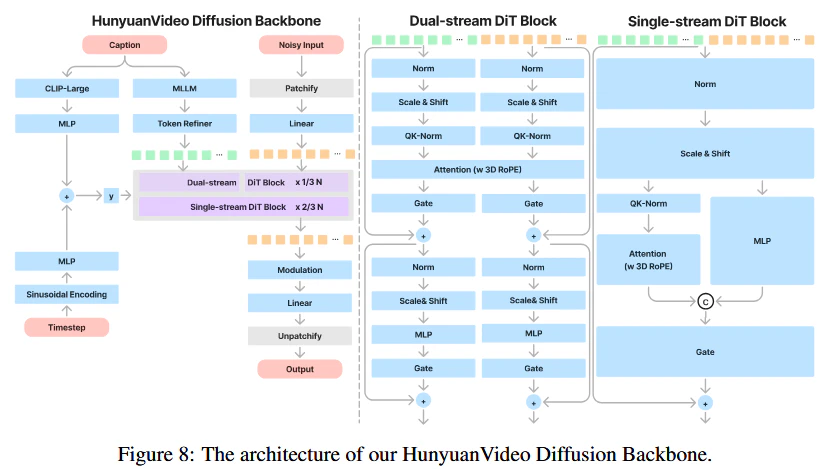
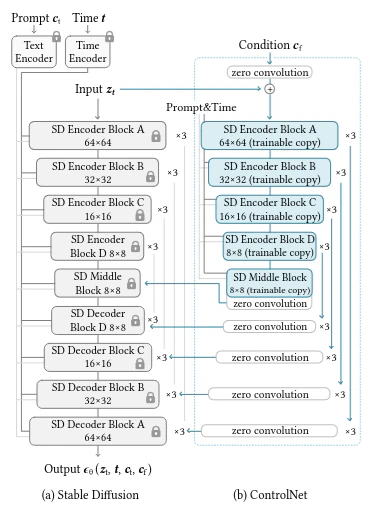
これはHunyuanVideoにおけるDualStreamDiTBlock(Text TokenとVideo Tokenを別のDiTで処理する)、もしくは古(いにしえ)のControlNetの実装を彷彿させる。
(参考)HunyuanVideoのDualStreamDiTBlock
(参考)StableDiffusionのControlNet
例えばWan2.2のVACEは6.1GBしかなく14Bのパラメータよりおそらく少ない。

さらにVACEモデルを使うときに以下のような感じでoriginalモデルにextra_modelとして追加しているのが分かる。

1. 参照画像をどのように渡すのか?
一般的な動画生成AIにおいて参照画像の渡し方について考えてみる。
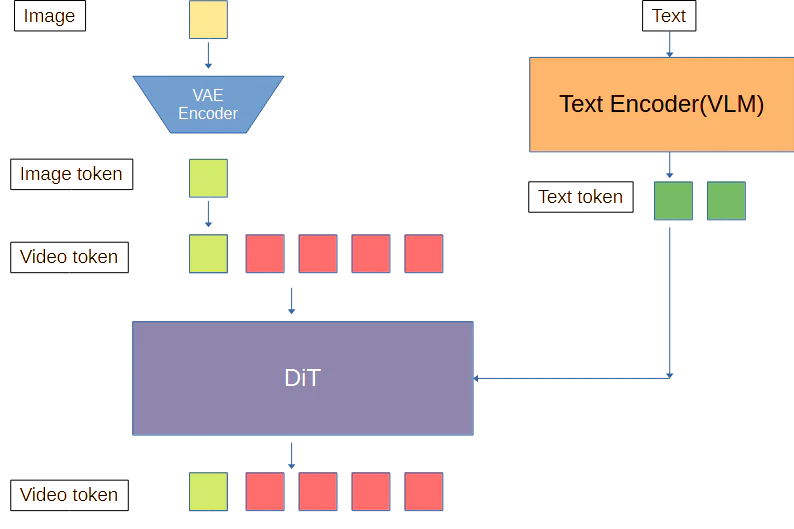
①VAEを通し、Video tokenの先頭フレームとして渡す
一般的なWan2.2のI2Vモデルはこのような方式にのっとっている。
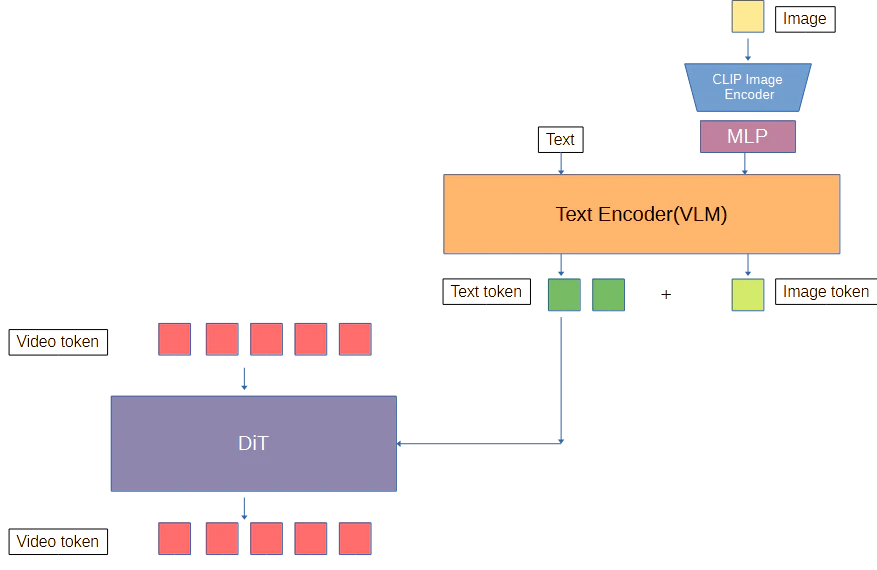
②CLIPを通し、Text tokenとして渡す。
一般にCLIPはImage Encoderを通した画像とText Encoderを通したテキストが同じペアである事を学習している。これを利用して画像をCLIPを通したテキストトークンとして渡す。
しかしながら、HunyuanVideoとは違い、デフォルトではWanはCLIPTextEncoder自体を使わない。だからCLIPtokenを得てもあまりうれしくない。

実際、Wan2.1 I2Vではこれが必要だったらしいが、Wan2.2ではI2Vでもclip_vision_hが要らなくなっている。

③VLMを通し、Text Tokenとして渡す。
この方式をImagePrompt2Video(IP2V)と呼び、以下の実装においてみられる。
この場合CLIP TokenではなくHunyuanVideoの場合はllava-llama-3-8bのVLM Tokenとみなせる。
とはいえこのような方針も実際にはWanでは採用されてはいないと思われる。
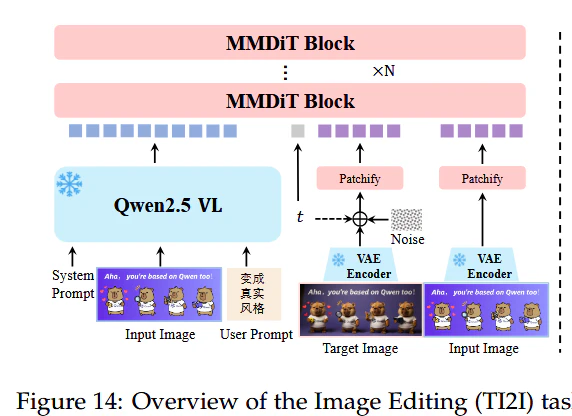
とはいえQwen ImageのTI2Iの画像編集タスクでVLMに画像を渡すのがあったから動画編集するタスクでも将来性はあるかもしれない。
④並列DiT(直列DiT)によって処理する
前述のContext Adapterに参照画像を渡した場合。
ここでImage Tokenとの相関はSelf-Attention層で計算される。
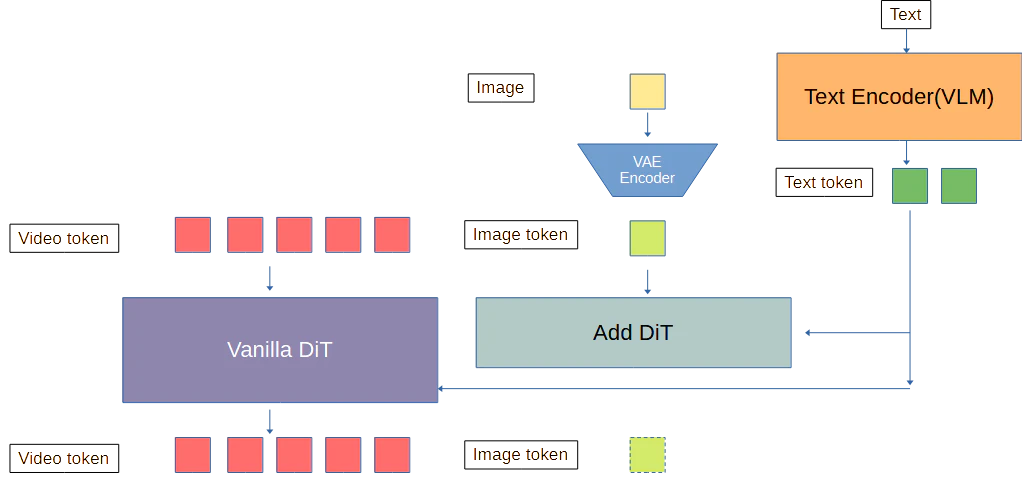
または追加DiTがCross-Attentionの計算を元とすると考えるなら以下の図のような直列にDiTがあるかもしれない。
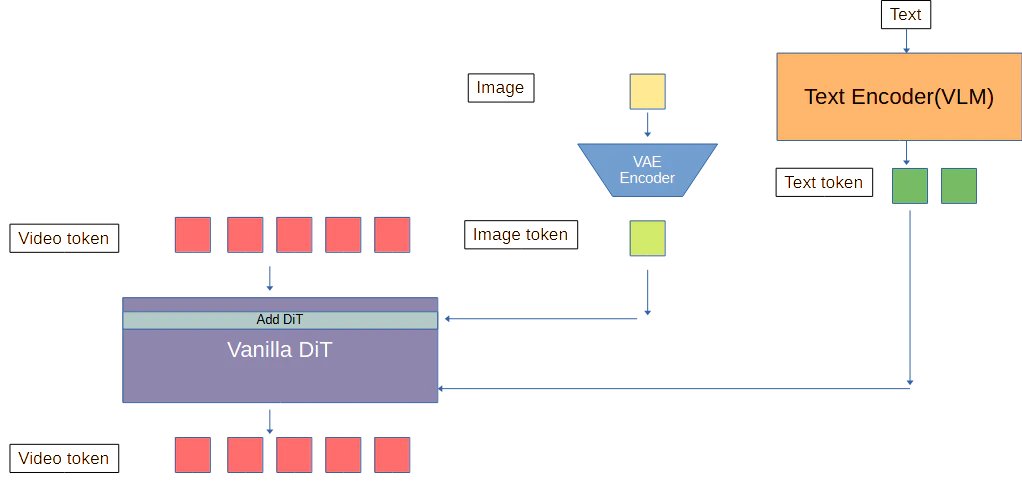
2. 参照モーションをどのように渡すのか?
参考画像と同様の渡し方を考えると以下の3通りの渡し方が考えられる。ただし、自分はMotionのデータ型を理解しているわけではない。
①モーションTokenをvideoトークンに渡す。
構成的にはvid2vidに近いイメージ。Context TokenをVideo Tokenに足す。
VACEのFully Fine-tuningの図に近いイメージ。
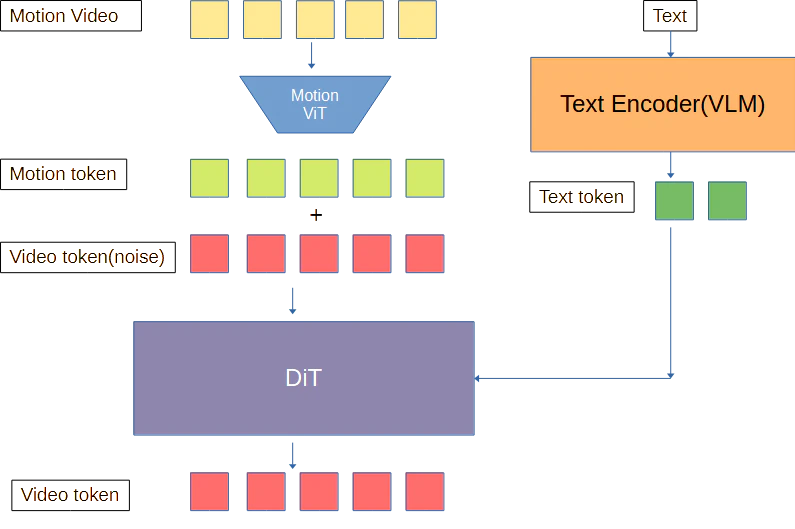
②スケルトンTokenをTextTokenに結合する。
スケルトンTokenのトークン数がVideoTokenより十分に少ないと考えられるならskeleton tokenはtext tokenと共にcondition tokenとして考えられるだろう。
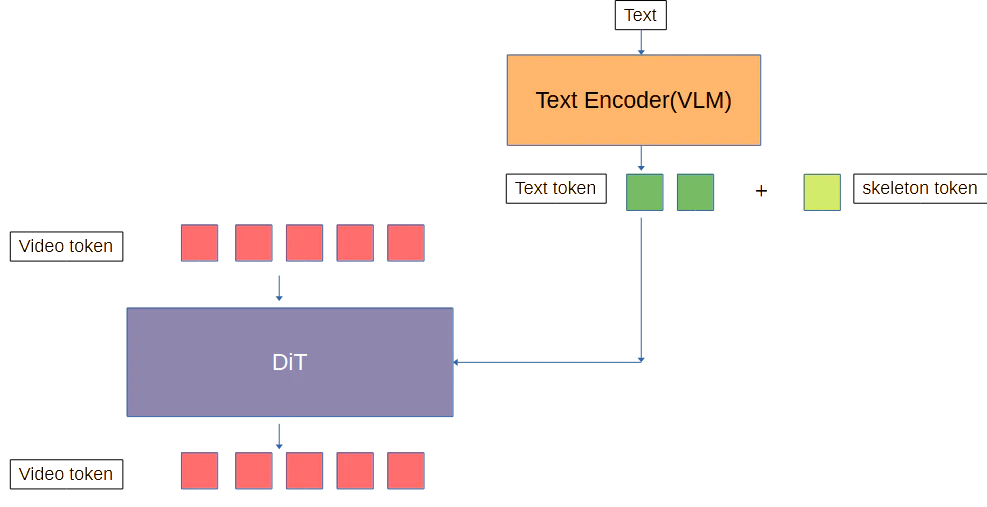
③並列DiTで処理する
VACEのContext Adapterの図である。
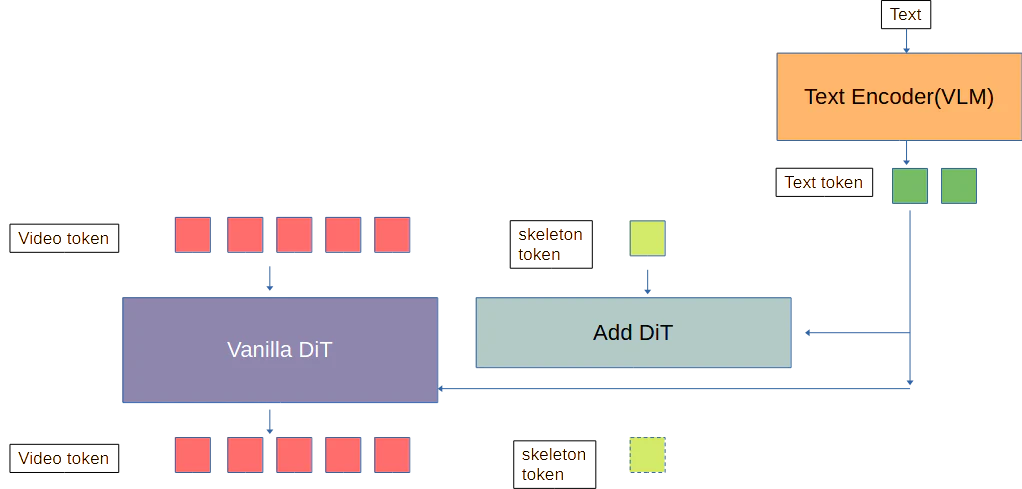
Wan-FunControl、VACE、Animateの違い
VACEはContext Adapterという並列にDiTを挿入するControlNetライクな実装方法である。
FunControlはVACEの図のFully FinetuningにあるContext TokenをVideo Tokenに足すI2Vモデルなのだろうか。
AnimateはContextTokenをVideo Tokenに足すのとContext Adapterで処理するものの両方のように見える。Animateは構成が非常に複雑であり、置換モードでは参照画像(キャラクター)、参照動画(背景)、人物セグメント(マスク)、スケルトン(モーション)、表情(フェイス)の5条件を使っており、その条件も参照画像(キャラクター)、参照動画(背景)、人物セグメント(マスク)は結合、スケルトン(モーション)は加算、表情(フェイス)はContext Adapterであり条件毎に処理が異なる。
また、VACEが並列DiTを追加しているように見えるのに対して、図からはAnimateは直列DiTを追加しているように見える。しかし、実際にはAnimateのモデルがどうなっているのかは分からない。
(Wan-VACE)
(Wan-Animate)
Temporal Latentは何のためにあるか?
以下はTemporal Latentの考察である。
Long Video理解のため
学習時に先頭フレームだけでなく、ランダムなフレームのクリーンlatentを残して学習した方がLongVideoの学習に有利という考え。
推論時はこの部分に意味のあるlatentを用意できず、推論中はこれを用意する意味はないのだが、学習においてはより長時間のVideoの理解が容易になるという考え。これで長時間動画を理解してれば、この部分がblank(学習時もランダムで与えない)でも動画作成に有利である。論文ではLong Video理解として導入されたと説明されている。
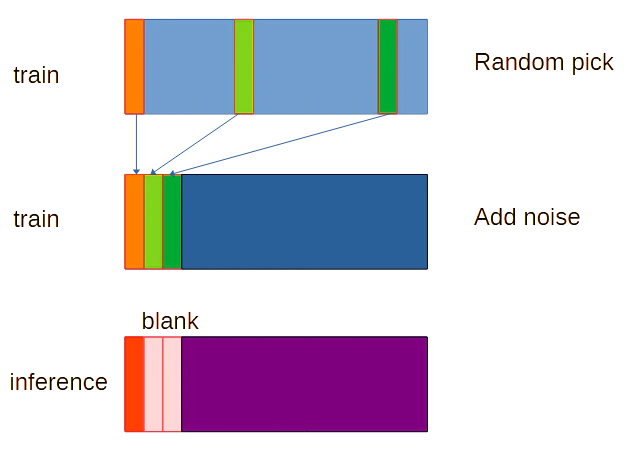
To accommodate the temporal guidance required for long video synthesis, we randomly select the first few latents from the target sequence to serve as temporal latents.
(長いビデオ合成に必要な時間的ガイダンスに対応するために、ターゲット シーケンスから最初のいくつかの潜在変数をランダムに選択し、時間的潜在変数として使用します。)
スケルトンボーンの推移の解消のためにある
FunControlの記事で下の方に参照画像のボーンと参照動画のボーンを合うように調整しないといけないとある。
参照画像と参照動画が被るときボーン位置が一致しない。
仮に空白latentを設ければキャラクターの参照画像のボーンから参照動画のボーンへの遷移が適当に空白latent中にいい感じで補完されて、調整する必要がなくなるのではと思った。

なお、論文の方ではPose Retargetingという項目があってVideo Boneの腕や足のボーン長さを参照画像に合わせて短く調整したり、動画のボーンを参照画像に合わせて平行移動するのを述べられているため、実際にはWan-Animateにおいてもまだ参照画像にあわせるボーン調整が必要であるようだ。
複数枚の画像参照
Qwen Imageの話だが、複数枚の画像参照がある。
Wan2.2 Animateもこれを参考にして、Temporal latent部分に複数枚の参照画像を入れられる余地を残したのではないかという考え。

FramePackの画像合成
参照画像の変化余地を持たせるための意図的なブランク。この領域では過去(前フレーム)からは人物が伝わり、未来(後フレーム)からは背景が伝わりこれらがこの空白領域で合成されるのだろうか。
この発想はWan-FLF2V(Fast-Last Frame to Video、フレーム間生成)やFun InP、FramPackとかの2フレーム以上指定できるモデルにおいて人物と背景の合成や、衣装の着せ替えなどがやられている。
ComfyUIのWan-Animateワークフロー
kijai氏のワークフローをのぞいてみる。
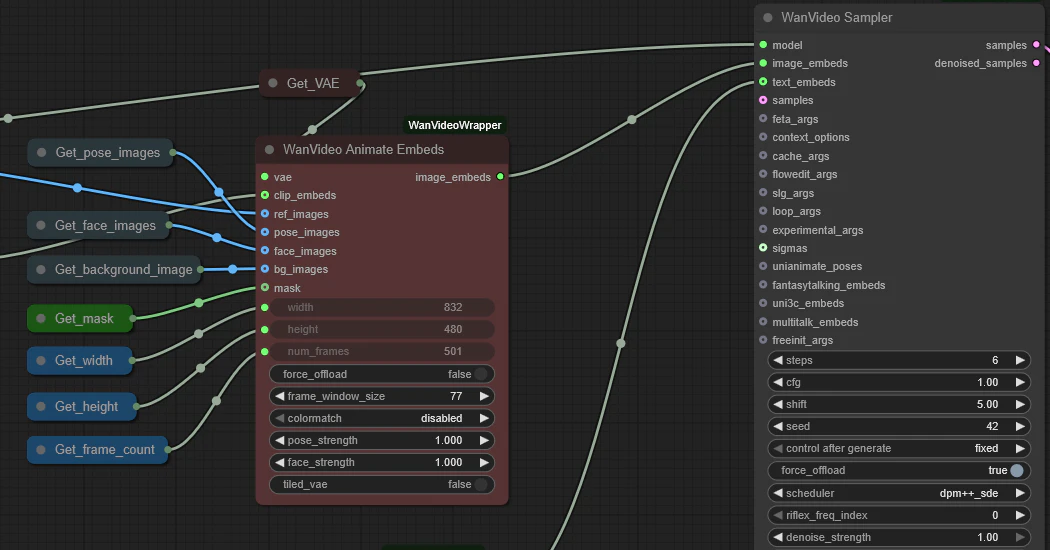
前述した5条件、参照画像(キャラクター)→ref_images、参照動画(背景)→bg_images、人物セグメント(マスク)→mask、スケルトン(モーション)→pose_images、表情(フェイス)→face_imagesとして入力されているのが分かる。
また、参照画像をCLIP Image Encoderを通したclip_embedsも入力されているがこれが必要なのかは良く分からない。Wan2.1のI2Vでは要るし、Wan2.2のI2Vでは要らないらしい。論文にはWan-AnimateがWan2.1 I2Vモデルをベースにしているとあるが…。
また、参照画像(キャラクター)のスケルトンや表情抽出も要るかと思ったのだが、要らないらしい。
まあ、それでも参照動画からモーション抽出して、これに参照画像を与えるだけのFunControlと比べてもだいぶ複雑に見える。
Wan-AnimateはWan2.1派生なのかWan2.2派生なのか?
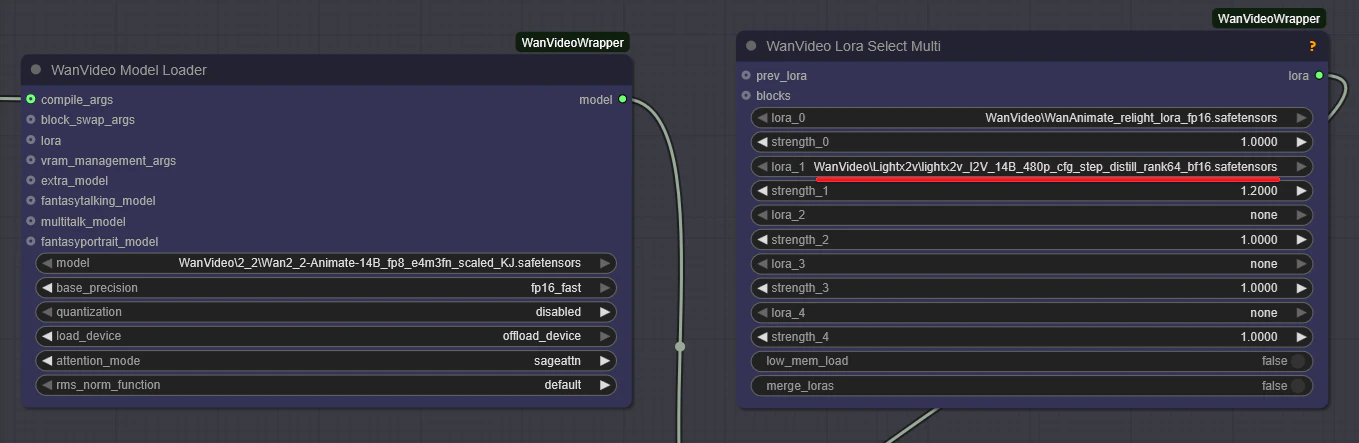
無論、Wan2.2-Animateというモデル名を信じるならWan2.2のI2V 14Bモデル派生なのだが、Wan2.1派生なのではと思う点がいくつかある。ひとつがhigh noise modelとlow noise modelとで分割されていない点。次に上記ワークフローで使われるloraもWan2.1 I2V用のloraに見える点。CLIP Image Encoderの出力が入力に必要な点。前述したがWan2.1 I2Vではclipが必要だが、Wan2.2 I2Vではclipは不要である。Wan2.2派生だとするならclipが不要なはずである。
これらを考えるとWan2.2-Animateは実際にはWan2.1派生である。
またWan-Animate論文にもWan2.1から学習したとある。
Correspondingly, our Wan-Animate is also built upon the open-source model Wan2.1, fully leveraging its robust pre-trained knowledge to ensure high-quality visual generation from the outset.(同様に、当社の Wan-Animate もオープンソース モデル Wan2.1 をベースに構築されており、その堅牢な事前トレーニング済みの知識を最大限に活用して、最初から高品質のビジュアル生成を保証します。)
Wanの開発者とFunシリーズの開発者は異なるのか?
WanのモデルとFun系列のモデルで投稿アカウントが違う。
Wan2.1のVACEにはFunの名は冠していないが
Wan2.2のVACEにはFunの名を冠している。
また、先頭フレームと終端フレームを与え、その間を生成するモデルを「FLF2V」(First-Last-Frame-to-Video)といっているのに、Fun系列では「InP」(start-end image prediction、多分Interpolation(補間)から。またはMaskで指定した黒塗りの中間フレームのみを生成するからInpaintから来ているかもしれない)と言ったりで名称にずれがある。
Wan-Animate、Wan2.1 VACEは前者で、
Wan2.2 VACE-Fun、Wan2.2 Fun-Controlは後者である。
DiT index
Wan2.1 I2V、Wan2.1 VACE、Wan2.2 Animate、Wan2.1 FunControlおよびWan2.2 I2VのDiTモデルのindexは以下の通りである。これらを比較してモデル差分の重みを確認したい。
Wan2.1 Fun Control - Wan2.1 I2V
Fun Controlにref_conv.bias ref_conv.weightがある以外は同じ。
img_embブロックはある。
Wan2.1 VACE - Wan2.1 I2V
Wan2.1 VACEにはimg_embブロックがない。
"img_emb.proj.0.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.0.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.1.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.1.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.3.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.3.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.4.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"img_emb.proj.4.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
代わりにVACEには以下のような8層分(0~7)のDiTブロックがある。
本来のWan DiTは40層だから8/40×14B×2byte=5.6GBとなる。Wan2.2のVACEファイルは6.1GBなので大体あっている。
"vace_blocks.0.after_proj.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.after_proj.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.before_proj.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.before_proj.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.k.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.k.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.norm_k.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.norm_q.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.o.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.o.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.q.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.q.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.v.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.cross_attn.v.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.ffn.0.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.ffn.0.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.ffn.2.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.ffn.2.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.modulation": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.norm3.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.norm3.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.k.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.k.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.norm_k.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.norm_q.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.o.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.o.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.q.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.q.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.v.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.0.self_attn.v.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.1.after_proj.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
...
"vace_blocks.7.self_attn.v.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_blocks.7.self_attn.v.weight": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_patch_embedding.bias": "diffusion_pytorch_model-00007-of-00007.safetensors",
"vace_patch_embedding.weight": "diffusion_pytorch_model-00007-of-00007.safetensors"
Wan2.2 Animate - Wan2.1 I2V
Wan2.2 Animateはimg_embブロックがある。これはWan2.1系列の特徴である。
また以下のようなブロックがある。face_adapter.fuser_blocksはTransformerっぽいがそれ以外はTransformerぽくない。またK重みとV重みがkv重みとして共通化されているようだ。
face_encoder, motion_encoderは畳み込みを行う単なるCNNモデルっぽい。
"face_adapter.fuser_blocks.0.k_norm.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.linear1_kv.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.linear1_kv.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.linear1_q.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.linear1_q.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.linear2.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.linear2.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.0.q_norm.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.k_norm.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.linear1_kv.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.linear1_kv.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.linear1_q.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.linear1_q.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.linear2.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.linear2.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.1.q_norm.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_adapter.fuser_blocks.2.k_norm.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
...
"face_adapter.fuser_blocks.7.q_norm.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.conv1_local.conv.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.conv1_local.conv.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.conv2.conv.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.conv2.conv.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.conv3.conv.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.conv3.conv.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.out_proj.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.out_proj.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"face_encoder.padding_tokens": "diffusion_pytorch_model-00004-of-00004.safetensors",
...
"motion_encoder.dec.direction.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.0.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.0.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.1.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.1.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.2.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.2.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.3.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.3.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.4.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.fc.4.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.net_app.convs.0.0.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.net_app.convs.0.1.bias": "diffusion_pytorch_model-00004-of-00004.safetensors",
...
"motion_encoder.enc.net_app.convs.7.skip.1.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"motion_encoder.enc.net_app.convs.8.weight": "diffusion_pytorch_model-00004-of-00004.safetensors",
"pose_patch_embedding.bias": "diffusion_pytorch_model-00001-of-00004.safetensors",
"pose_patch_embedding.weight": "diffusion_pytorch_model-00001-of-00004.safetensors",
Wan2.2 I2V - Wan2.1 I2V
Wan2.1にはimg_embブロックがある。
Wan2.2にはimg_embブロックがない。
これはclip embed入力を処理するレイヤーと思われる。
Wan2.2 S2V、InfiniteTalk
また、参考までにWan2.2-S2V-14BとInfiniteTalkは論文(内容未読)の図を見ると追加VACE Adapterは直列DiT的であるように見える。またAudio以外のDiTBlockの制御TokenはS2VはT5のText Token制御で、InfiniteTalkはCLIP Image Encoderを通したCLIP Image Token制御であるが、これはWan2.1 I2Vであるためである。
また、Wan2.2 S2Vは12層のDiTでInfiniteTalkは40層のDiTである。
 (Wan2.2 S2V)
(Wan2.2 S2V)
 (InfiniteTalk:base Wan2.1 I2V)
(InfiniteTalk:base Wan2.1 I2V)
Wan-Animateの学習手順
3.5 TRAININGによれば、Body Control Training.、Face Control Training.、Joint Control Training. 、Joint Mode Training. と手順が分かれている。
Body Control Training. はmotionのみの学習なのでFunControlっぽい。
Face Control Training. はFace条件のContext Adapter(追加DiT)を学習するのでVACEっぽい。
Joint Control Training. ではmotionのみ学習したFunControlのベースモデルにFace AdapterのVACEモジュールを追加してこの複合モデルを学習データで学習する。
Joint Mode Training. はMASKで人物部分のみ黒塗りして背景を残すか(置き換えモード)、MASKで人物も背景も黒塗りするか(アニメーションモード)の両方を実行する。
こう見るとWan-AnimateがFunControl+VACE Adapter追加モデルと解釈できる。
まとめ
参照画像(キャラクター+背景)を参照動画のモーションで動かすというのにWan-Fun Control、Wan-VACE、Wan-Animateがある。これらはいずれもI2V派生である。
Fun Controlはおそらくモーション条件をlatentに加算してI2Vモデル全体をフルファインチューニングされている。
VACEは並列DiTを考えることでControlNetのように元のDiTを破壊せずに学習されている。
Animateは多条件で生成するのを想定しており、置換モードでは背景とモーションを維持してキャラクターの置き換えが可能である。
とはいえWan2.5-previewが発表されたので、Wan2.2からモデルが大幅に変わってない限りは、Wan2.5 FunContorolやWan2.5-VACE FunやWan2.5-Animateが出るのも時間の問題なのかもしれない。(その気になればこれらをファインチューニングするのに一週間もかかるまい)