以下の論文の内容について考えてみたい。
NVFP4データの変換
NVFP4は値のelementはE2M1で示される。
ここでE2M1の定義は
$(-1)^s*(0.0+0.5*m)*2^{e}, when (e=0)$
$(-1)^s*(1.0+0.5*m)*2^{e-1}, when (e>0)$
で作られる数字は±0, ±0.5, ±1, ±1.5, ±2, ±3, ±4, ±6である。
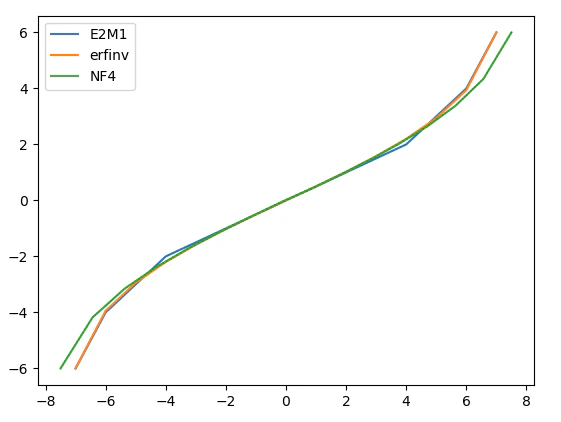
正規分布の逆累積分布関数
正規分布の逆累積分布関数erfinvとE2M1の値を比較してみたい。
正規分布の逆累積分布関数はゼロ付近に密で最大値付近では疎であるデータを割り当てを当分に配分するためのパラメータである。要するに一様分布にerfinvを掛けると正規分布になる。
plotしてみると分布が近いことが示される。
もっとも単なる偶然によるものかもしれないが。
import matplotlib.pyplot as plt
import numpy as np
from scipy.special import erfinv
x = np.arange(-7,8)
y = [-6.0, -4.0, -3.0, -2.0, -1.5, -1.0, -0.5, 0.0, 0.5, 1.0, 1.5, 2.0, 3.0, 4.0, 6.0]
y2 = erfinv(x/7.0*0.96)
y2 *= 6.0 / np.max(y2)
x2 = (np.arange(-7,9) - np.abs(np.linspace(-0.5, 0.5, 16)))
y3 = 6.0 * np.array([-1.0, -0.6961928, -0.525073, -0.394917488, -0.284441381693, -0.18477343,
-0.09105003625, 0.0, 0.079580299556, 0.1609302014, 0.2461123019456,
0.33791524171829, 0.44070982933044434, 0.562617003917, 0.722956836223,1.0])
plt.plot(x, y, label='E2M1')
plt.plot(x, y2, label='erfinv')
plt.plot(x2, y3, label='NF4')
plt.legend()
plt.show()
これはQLoRAの論文にもNF4という非等間隔のデータ型があった。
E2M1はこのNF4のデータ間隔とある程度近いのではないだろうか。

Blockwise
BlockwiseはBlock_sizeごとに細かく最大値スケールを取る方法である。外れ値による量子化性能低下を低減する効果がある。
例えばQLoRAの論文ではblock_size=64個毎に32bitのスケールパラメータを持った。
NVFP4においては入力ではblock_size=16個毎に8bitのスケールパラメータを持つようである。


誤差逆伝播と転置
誤差逆伝播を計算する際に転置(Transpose)が発生することを簡単に示したい。
例えば
$x=(512,77), W_{1}=(2048,512), W_2=(10,2048)$
$z=(2048,77), y_{pred}=(10,77), y_{true}=(10,77)$となる入出力がある時、
z=W_1 x
y_{pred}=W_2z
Loss=\frac{1}{2}(y_{pred}-y_{true})^2
ここで各種式の偏微分は以下の様に示されるため
$\frac{\partial L}{\partial y_{pred}}=(y_{pred}-y_{true}), \frac{\partial y_{pred}}{\partial W_{2}}=z, \frac{\partial y_{pred}}{\partial z}=W_2, \frac{\partial z}{\partial W_{1}}=x$
連鎖律を使って
$\frac{\partial L}{\partial W_{2}}=\frac{\partial L}{\partial y_{pred}}\frac{\partial y_{pred}}{\partial W_{2}}=(y_{pred}-y_{true})z$
$\frac{\partial L}{\partial W_{1}}=\frac{\partial L}{\partial y_{pred}}\frac{\partial y_{pred}}{\partial z}\frac{\partial z}{\partial W_1}=(y_{pred}-y_{true})W_2x$
ここで各種次元を思い出すと
$\frac{\partial L}{\partial W_{2}}=(10,2048)=(y_{pred}-y_{true})z=(10,77)(2048, 77)^T$
$\frac{\partial L}{\partial W_{1}}=(2048,512)=(y_{pred}-y_{true})W_2 x=((10,77)^T(10,2048))^T(512, 77)^T$
のように損失Lの重み$W_1,W_2$に対する偏微分を計算するとき入出力の転置が計算されることが示される。
NVFP4フロー図
以下のような図が示される。ここで前述の$y_{pred}=W_2z$の誤差逆伝播を例にとると
左上にあるBF16 Activationが入力$z$、
中央にあるFP32 Weightが重み$W_2$、
右下にあるBF16 Activation Gradientが勾配$(y_{pred}-y_{true})$である。
緑色の計算は
$F_{prop}=W_{2}z$
$W_{grad}=(y_{pred}-y_{true})z^T$
$D_{grad}=W_2^T(y_{pred}-y_{true})$
である。

しかし、厳密には2D Block量子化、Hadamard変換、確率丸め(SR)などの各種工夫が見られるのでNVFP4に変換して単に計算すればいいというような単純な構成ではない。
Mixed precision
学習層によって要求精度が異なるらしい。
特にTransformersの最後の4層はNVFP4にするのではなくBF16のままにするのが良い。

2D scaling(Block scaling)
ここで量子化関数q(x)を与えた時、転置があるのとないのではBlockwise scalingの方向が異なるのでforwardとbackwardで値が一致しない。$q(W)\neq q(W^T)^T$
2D scalingではモデル重みWに対しては16×16の正方形Blockでscalingするとある。これによって重みの量子化ではスケーリングの方向が元の行列の量子化でも転置後の量子化でも等しくなる。一方の入力や勾配は1x16でscaleするらしい。

ランダムアダマール変換(Random Hadamard transforms)
$H\cdot H^T=I$となるアダマール行列を与えた時
$\frac{\partial L}{\partial W}=(y_{pred}-y_{true})x$で量子化関数q(x)を与えると
$W_{grad}'=q((y_{pred}-y_{true})H)\cdot q(H^T x)$となる。
ただしこれは$W_{grad}$を計算する際のみ有効で$F_{prop}$や$D_{grad}$計算においては逆に精度の悪化が見られる。

これによって量子化の妨げになる外れ値を取り除ける(分散する)という議論がある。

アダマール行列のサイズは1.2Bモデルでは何でも良かったが、12Bモデルにおいては4x4より128x128の方が良好であったのが述べられてます。

ここでアダマール行列は以下で示され

ランダムとつくのはアダマール行列Hに対角行列$S_d$が掛けられる。
S_d=
\begin{pmatrix}
\{1,-1\} & 0&0&0
\\
0&\{1,-1\} & 0&0\\0&0&\{1,-1\} & 0
\\0&0&0&\{1,-1\}
\\
\end{pmatrix}
これは対角項に{-1,1}の値をランダムにとる。-1の二乗も1の二乗も1であるから$S_d S_d^T=I$であるのは容易に示される。ランダムアダマール行列はランダム対角行列とアダマール行列の積であろう。

RHTは特異値分解(SVD)やLoRA学習と関係あるか?
SVDQuant量子化においては特異値分解における$U,Σ,V^T$に対してU,Vは直行行列なため$UU^T=I,VV^T=I$が成り立つ。行列重みに対して特異値分解を実行すると外れ値を取り出せる。また、二個のモデル間の差分重みを特異値分解した場合これはlora重みになる。ランダムアダマール変換が消極的な特異値分解と見なせたり、あるいはLoRA学習と等価と見なせたりするのだろうか。
無論、これらが全く別の概念であることは知っていますが、RHTやSVDQuantは両方外れ値を取り除くという概念の元運用されています。LoRA学習においては初期LoRA重みは異なるガウス分布の内積なので期待値はゼロですが、重みの特異値分解の値を初期LoRA重みとすればメインの重みから外れ値を取り除けるのでメイン重みの量子化がより容易になるかもしれません。参考までにmusubi-tunerでは--network_weights path/to/lora.safetensorsで任意の初期LoRA重みを指定できます。
SVDQuantについて
話は脱線するがSVDQuantについて簡単に整理したい。
Smoothingでは入力Xの外れ値を取り除く。例えば入力Xの特定列が10倍大きいとする。この時、入力Xの特定列を1/10倍にして、重みWの特定行のみ10倍にするようなsを定義した場合、入力Xの外れ値を重みWの外れ値に移し替えることができる。
この移し替えた重みに対して特異値分解を行うと重みの外れ値を取り出すことができ、移し替えた入力Xと移し替えた重みWからLoRA成分を引いた行列は外れ値がなく容易に(低bitでも)量子化が可能である。
これによってSVDQuantではINT W4A4(+fp16 LoRA)の推論が可能である。


import numpy as np
def qint8(W_input):
scale = 127.0/np.max(np.abs(W_input))
qW = np.round(scale*W_input)/scale
return qW
np.random.seed(42)
d_in = 64
d_out = 128
batch = 32
# ガウス分布
x = np.random.randn(batch, d_in)
W = np.random.randn(d_out, d_in)
# 外れ値を注入
outlier_cols_x = [10, 25, 38] # 特定列
x[:, outlier_cols_x] *= 50.0
outlier_cols_W = [5, 14, 20]
W[:, outlier_cols_W] *= 100.0 # 列外れ値
x_max = np.max(np.abs(x), axis=0) + 1e-6
W_max = np.max(np.abs(W), axis=0) + 1e-6
s = x_max / W_max
s = np.clip(s, 1.0, 100.0)
x_smooth = x / s
W_smooth = W * s
print('Before smoothing:')
print('mean |x|:', np.mean(np.abs(x)))
print('mean |W|:', np.mean(np.abs(W)))
print('\nAfter smoothing:')
print('mean |x_smooth|:', np.mean(np.abs(x_smooth)))
print('mean |W_smooth|:', np.mean(np.abs(W_smooth)))
U, S, Vt = np.linalg.svd(W_smooth, full_matrices=False)
rank = 8
W_svd = U[:,:rank] @ np.diag(S[:rank]) @ Vt[:rank]
W_R = W_smooth - W_svd
print('\nAfter SVD:')
print('mean |W_svd|:', np.mean(np.abs(W_svd)))
print('mean |W_R|:', np.mean(np.abs(W_R)))
print('\nWx-Q(W)Q(x)=', np.mean(np.abs(W @ x.T - qint8(W) @ qint8(x).T)))
print('Wx-Q(W_smooth)Q(x_smooth)=', np.mean(np.abs(W @ x.T - qint8(W_smooth) @ qint8(x_smooth).T)))
print('Wx-(Q(W_R)+W_svd)Q(x_smooth)=', np.mean(np.abs(W @ x.T - (qint8(W_R) + W_svd) @ qint8(x_smooth).T)))
print('Wx-(Q(W_R)Q(x_smooth)+W_svd*x_smooth)=', np.mean(np.abs(W @ x.T - (qint8(W_R) @ qint8(x_smooth).T + (W_svd @ x_smooth.T)))))
print('Wx-(Q(W_R)Q(x_smooth)+(W_svd/s)*x)=', np.mean(np.abs(W @ x.T - (qint8(W_R) @ qint8(x_smooth).T + ((W_svd/s) @ x.T)))))
-----------------------------------------
Before smoothing:
mean |x|: 2.6440600137667536
mean |W|: 4.612151927679625
After smoothing:
mean |x_smooth|: 0.7830344184308307
mean |W_smooth|: 6.049435741204974
After SVD:
mean |W_svd|: 5.558826400091201
mean |W_R|: 0.6941292381398545
Wx-Q(W)Q(x)= 64.08620524481681
Wx-Q(W_smooth)Q(x_smooth)= 4.537900856818993
Wx-(Q(W_R)+W_svd)Q(x_smooth)= 1.0755791446412237
Wx-(Q(W_R)Q(x_smooth)+W_svd*x_smooth)= 0.06767648655536677
Wx-(Q(W_R)Q(x_smooth)+(W_svd/s)*x)= 0.06767648655536668
xもWも外れ値を持っている状態からsmoothとSVDによって外れ値を除いたx_smoothとW_Rを用意できる。正規分布の$mean(abs(x))=\sqrt{2/\pi}=0.798...$なのでsmoothによってこれに大体近い。ただし、smoothingを行うにはある程度の小型のデータセットの入力x集合が必要である。smoothのsの計算はデータセットのサンプリングを行うので多分複雑である。
LSGQuant
SVDQuantと似るがいくつか異なる点がある。
一方でこれらは学習済みの重みの量子化であって、量子化した重みの学習ではない。
・レイヤーごとの異なる量子化戦略。
・ランダムアダマール行列のHの採用。
・Quantization-Aware Training(量子化適応学習)の実施。



量子化適応学習でSVD結果を初期LoRA重みとしてLoRAを学習する。
なお、量子化に使われるround関数は一般に微分不可能であるが、Straight-Through Estimator(STE)というy=x+(round(x)−x).detach()を採用するとforwardではround(x)となり、backwardではx(勾配は1)扱いとなる。なので量子化適応学習においてはround関数が微分できないという事情は無視できる。
確率的丸め(stochastic rounding:SR)
よく四捨五入を考えた時に2.49は2なのに0.01だけ増えた2.50でいきなり3になるのを奇妙に思ったことはないですか?
確率的丸めによれば2と3の中間にある2.5は50%の確率で2になり、50%の確率で3に丸められることになります。
仮にInt8型の量子化を考えた際に整数値への丸めとみなすなら勾配のBF16の値に-0.5~0.5の一様分布乱数を足してからRoundを使えばいいのでしょうか。例えば値が2.1では乱数が0.4~0.5(10%)では3に繰り上がるが-0.5~0.4(90%)では2に切り捨てられる。
$Round(BF16/scale+uniform(-0.5,0.5))$
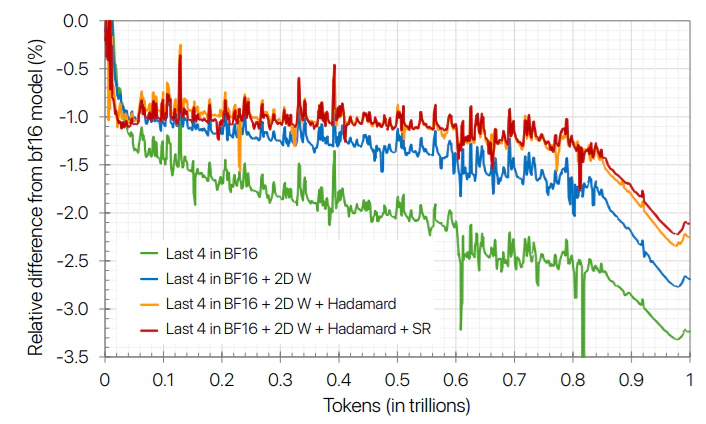
以下の図によれば確率的丸めは「勾配の量子化」(緑線)において効果がありますが、「入力やモデル重みの量子化」(青線、赤線)においては効果がありません。

各種効果
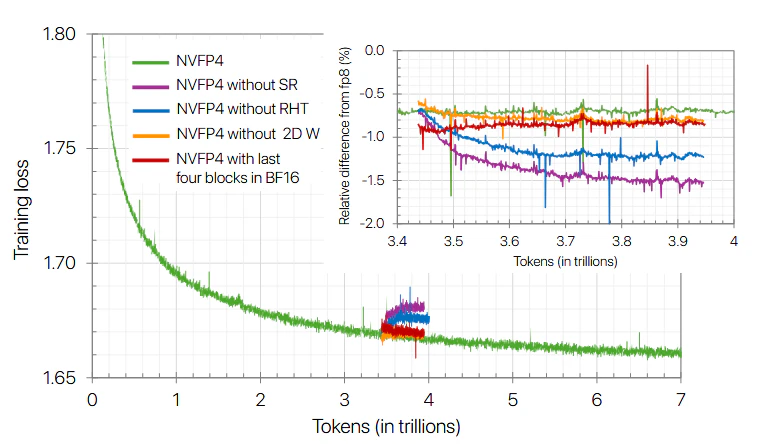
Mixed precision(最終4層のみBF16)、確率的丸め(SR)、ランダムアダマール変換(RHT)、2D scalingの影響は以下の通りである。
上の図ではSRの影響が最も大きく見えるが、下の図ではSRの影響は最も小さく見える。
各種テクニックは単独で使用しても取り立ててよくなく、組み合わせによって改善される。
基本の量子化は「32bitの全体スケール」と「1x16ごとの8bitスケール」で4bitの量子化が行われる。この基本の量子化のみではいずれ発散が起こる。次に行われたのが最終4層のBF16化であり、SR、RHT、2D scalingの三つはどの順に実装されたのか良く分からない。
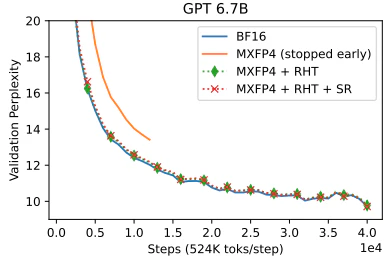
SR、RHT、2D scalingなどは他の論文でも見られ以下ではMXFP4におけるRHTとSRの実施が見られる。
NVFP4の表現できる最大値
elementのE2M1が最大値6、scaleのE4M3が表現できる最大値が448なのでNVFP4の最大値は2688となる。

一点思うことはscaleのE4M3は絶対値最大値を取るため常に正なので、スケールの符号bitが有効に活用されてない。
元のelementの平均値がゼロでないときに、ランダムにscaleとelementの符号を同時に反転させれば、elementの期待値をゼロにすることはできるが、再構成値は不変なので多分意味はない。
scaleの導出
一次元配列で確認する。
NVFP4で表現できる最大値である2688を超える場合でも最大値が2688となるような係数をかけて、16個毎に最大値を調べ、最大値を6.0とする係数を調べればそれの最大値は448となるfloat8(e4m3)となるscaleが確認できる。
import torch
x = torch.randn(64).to(torch.float32) * 100.0
x[0] = 10000
block_size = 16
global_scale = 6.0*448/torch.max(torch.abs(x))
x2 = x * global_scale
local_scale = []
for i in range(len(x2)//block_size):
local_scale.append(torch.max(torch.abs(x2[block_size*i:block_size*(i+1)])))
local_scale = torch.stack(local_scale, dim=0)
local_scale = local_scale.repeat_interleave(block_size)/6.0
print('local_scale=',local_scale.to(torch.float8_e4m3fn))
-----------------------------------
local_scale= tensor([448.0000, 448.0000, 448.0000, 448.0000, 448.0000, 448.0000, 448.0000,
448.0000, 448.0000, 448.0000, 448.0000, 448.0000, 448.0000, 448.0000,
448.0000, 448.0000, 6.5000, 6.5000, 6.5000, 6.5000, 6.5000,
6.5000, 6.5000, 6.5000, 6.5000, 6.5000, 6.5000, 6.5000,
6.5000, 6.5000, 6.5000, 6.5000, 16.0000, 16.0000, 16.0000,
16.0000, 16.0000, 16.0000, 16.0000, 16.0000, 16.0000, 16.0000,
16.0000, 16.0000, 16.0000, 16.0000, 16.0000, 16.0000, 13.0000,
13.0000, 13.0000, 13.0000, 13.0000, 13.0000, 13.0000, 13.0000,
13.0000, 13.0000, 13.0000, 13.0000, 13.0000, 13.0000, 13.0000,
13.0000], dtype=torch.float8_e4m3fn)
MicrosoftのFP4学習(MXFP4)
MXFP4と呼ばれNVFP4より先にあったらしい。MXFP4は読んでないがNVFP4との比較が論文にある。bf16比ではNVFP4のほうがMXFP4より僅かにいいらしい。
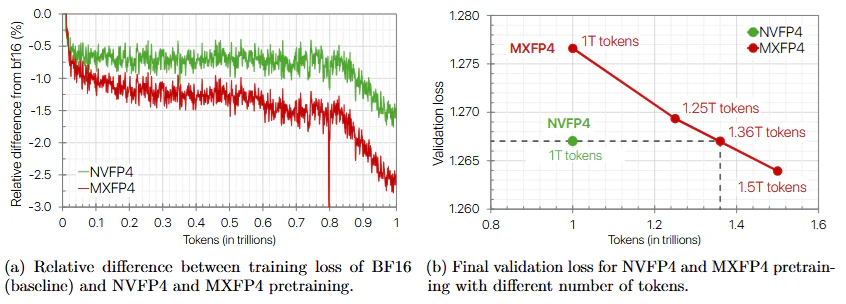
終端トレーニング
以下の図はNVFP4の学習とfp8の学習とBF16の学習が混在してて少し理解が難しい。
要するに最初から最後までfp8で学習するのと、NVFP4で学習した後に終端トレーニングのみBF16で学習すれば同等の精度が得られることが示されている。
結局、BF16の精度>FP8の精度>NVFP4の精度であるからFP8→NVFP4の精度低下を、FP8→BF16の終端学習の精度向上でFP8レベルまでは回復してるというだけなのだろうか。
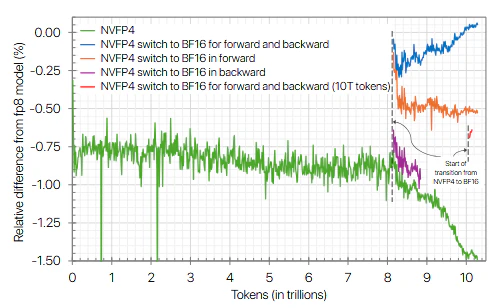
QLoRAとGGUFとBlockswapとの関連
・W8A16とW8A8
W8A16はモデル重み(Weight)のみ量子化するが入力(Activations)は16bitのままである。
W8A8はモデル重みも入力も量子化される。
W8A16はモデル読み込み時間やVRAMは削減されるが、推論速度は増加しない。
W8A8は推論速度は2倍速くなる。
FP8量子化においてW8A16とW8A8の区別が存在する。
・QLoRAはforwardはW4A16でTransformerの重みに4bitを使用し、backwardは16bit LoRAを学習対象とすることで精度を維持しつつ記憶する重みの量をBase modelから減らし、OptimizerはいわゆるAdamとかで2回分の過去勾配を記憶するがこれはせいぜい定数倍と足し算程度なのでVRAM上にもって計算する意味がないためCPUとRAMで処理する。QLoRA当時(2023年05月)においてはVRAM至上主義であり、何とか限られたVRAMに量子化したモデル重みを詰め込んで学習における使用VRAMを減らそうとしていた。
・GGUFは静的量子化によって低い量子化モデルを使用することでVRAM使用量を抑える。基本的にはblockwiseと可変量子化レートによって削減されており、QLoRAにみられた非等間隔量子化はなされているのか良く分からない。GGUFはQLoRA(block_size=64)よりもBlock sizeが小さい(block_size=32~8)なので不要なのだろうか。
まあ、大部分の人は量子化の仕様なんか興味ないし、最初のQ3,Q4,Q5,Q6の最初の量子化bit以外は知る必要もない。
LLMモデルのような100Bクラスのサイズがごろごろしてるような環境では何より量子化を採用しないとローカルの使用が話にならないことも多い。一方、画像生成モデルでは量子化モデルの精度劣化は可視化が容易だが、LLMにおいては量子化の精度劣化は可視化しづらい。
・Kijai氏のWanVideoWrapperとかkohya氏のmusubi-tunerではGGUFは採用されずにBlockswapによって使用VRAMの削減が見られる。Blockswapは去年あたりからみられ、これ自体は量子化とは直接関係はない。RAMが十分に余っているならばVRAMのモデル重みをRAMに配置して、RAMとVRAMの中身をスワップさせながら推論する。
一般に推論時間>スワップ時間であるからRAM十分多いならば、少ないVRAMでも少しの速度低下で推論が可能である。あるいはWindowsでは「共有GPUメモリ」というRAMをVRAMとして使う機能があるらしいのでWindowsならBlockswapの明示的設定は不要だという話もある。
ともかく生成モデルではBlockswapによって現在は精度低下してまでモデルの静的量子化によってVRAM使用量を切り詰めようという考えはある程度緩和されたのではないかと思われる。(GGUF愛好家の方はそうでもないかもしれませんが、自分はあまり生成AIにおいてはGGUFは使ってません…)
最近のハードウェア事情
最近のメモリ高騰のせいで64GBメモリすら10万円くらいする。128GB積もうとすれば20万円。その上、Windows11 HomeではOS上でメモリ128GB上限があるので今後のメモリの高容量化には制限があると思われる。
また、GeForece50XX superやGeForece60XXも延期され、GPUのVRAM向上の目途もしばらくは断たれた。5090(VRAM 32GB)は相変わらず50万以上して高いので、値段だけなら2枚の16GB VRAMのmulti GPUの方が安い。
まあ、2026年中には改善要素は特にないだろう。
SageAttention
SageAttention2ではAttention計算においてint4型の量子化が実行される。しかしながら、SageAttention2はbackwardを持たず学習には使えない。

一方、SageAttention3においてはSageBwdという8bit backwardがあり、fine-tuningにおいて有効らしい。
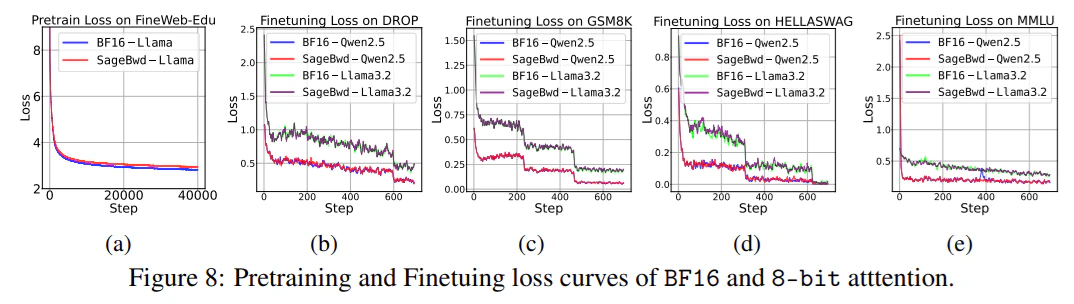
Attentionの量子化が先に行われているならFP8やFP4の量子化速度改善が相対的に小さくなるかもしれない。
NVFP4の4bit推論
論文ではNVFP4の学習(backward)に対する工夫は多いが、推論(forward)に限ると特段工夫は少ない。
入力(Activation)が「32bitの全体スケール」と「1x16ごとの8bitスケール」で「4bit(E2M1)の量子化」。
重み(Weight)が「32bitの全体スケール」と「16x16ごとの8bitスケール」で「4bit(E2M1)の量子化」。
であってQLoRAの重み量子化であるblockwise(Blockごとの最大値スケール)+NF4(erfinv状の非等間隔分割)からあまり差はない。 推論でのQLoRAとの量子化の違いは重みが16x16の2D scalingであることぐらいである。
SVDQuantやLSGQuantのほうが学習済み重みを「Smoothing+SVD」や「RHT+Quantization-Aware Training(QAT)」によって4bit推論に最適化されているように思う。
学習における実用性の課題
forwardのW8A16は既にメジャーになりつつある。これはGPUには依存しない。これはLoRA学習においてはDiTにfp8モデルを指定できる。一方で40GBや80GBのVRAMを持つA100を使用するなら14B前後のモデルなら特に量子化はなくても動作する。
backwardのW8A16についてはファインチューニングならともかくLoRA学習においては学習するLoRAモデル自体が小さいのでBF16から下げた場合のメリットがほとんどない。
forwardのW8A8についてはW8A16との混同が見られるがおそらく静かに広まっている。また対応するGPUがH100やRTX4000以上である必要があり、A100では使用できないと思われる。
backwardのW8A8については前述のGPU制限があるうえ、一般にbackwardのほうがforwardのW8A8よりも困難である。FP8-training(backwardのW8A8)が可能であるにはFP4推論が可能なほど量子化誤差が小さくないといけないと思われる。このため単に精度を切り捨てた単純な量子化では不可で、学習前や学習中の量子化に何らかの工夫が必要であると考えられる。
forwardのW4A4については対応するGPUがB100とかRTX5000とかに限られる。一例としてSVDQuant(Nunchaku)が知られるがこれは事前に重みをsmoothとSVDによって4bit重みと16bit LoRAへの変換が必要である。smoothには小規模の入力データセット、SVDにはそこそこの計算時間が必要なため、ユーザーが重みを変換することは出来ない。
backwardのW4A4についてはGPU制限に加え、この記事に取り上げた工夫を適用する必要があり、それでいて学習がちゃんと安定するかは保証されない。
A100を用いたLoRA学習においては意味があるのはforwardのW8A16のみである。forwardのW8A8はGPU(A100)の都合で使用できないし、backwardのW8A16はLoRA学習ではVRAM削減のメリットが少ない。
GPU制限とLoRA学習の特性を考慮するとA100では何ら改善点はない。
GoogleColabにおいてA100(40GB)が5.37cu/h、H100(80GB)が18.05cu/hでまだ割高感がある。まあ、GoogleColabにおいてH100が選べるようになったのは2025/12からであるからH100やB100での学習がもっと身近になればW8A8のFP8量子化への機運も高まるだろう。
もっともH100(VRAM80GB,RAM230GB)でしかLoRA学習出来ないというモデルは逆にローカルで動かすには絶望的なサイズでしかない。あるいはLoRA学習ではなくファインチューニング学習に流行が回帰すればH100の使用とFP8のW8A8が見られるようになるかもしれない。
その他参考記事
以下の記事ではNVFP4のモデル変換と推論がある。一方、NVFP4学習の記事はない。
またはlora学習を行うmusubi-tunerでは以下の議論の後半にW8A8への記述がある。一方、現行の学習におけるfp8_scaledは多分W8A16なのであろう。
また--fp8_fastがおそらくW8A8であると推定されるが、このオプションが有効なのは推論のみで、学習においてはこのオプションは有効ではない。

まとめ
以下、難しい順にならべてみた。
FP16の推論→FP16の学習→FP8の推論→FP8の学習→FP4の推論→FP4の学習
基本的にはbackwardはforwardよりも高い精度が必要である。
「FP8の学習」も「FP4の推論」も今のところメジャーとは言えない状況でさらに進んだ「FP4の学習」と聞いてそんなのが本当に可能なのか?と最初思った。
論文を見てみると学習に様々な工夫が実施されている。