TurboQuantの論文を読んでどんな風に量子化しているのか、コードを書きつつ考える。
論文にあること
アルゴリズム①とアルゴリズム②がある。
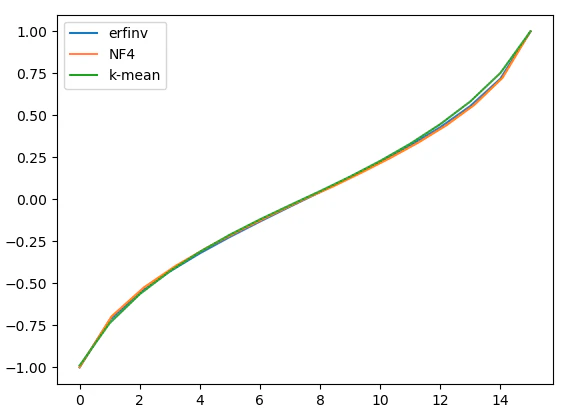
アルゴリズム①ではkmeansで最適なcodebookを求め、mseを最小化する。
アルゴリズム②では全体を$n$bitで量子化する時、アルゴリズム①で全体を$n-1$bitで量子化を行い、残差をqjlで1bit量子化する。
アルゴリズム①
この理解が難しく結構迷走した。最初、ベクトル量子化を考えているのかと勘違いし、その手法を検討した。その勘違いによるコードは参考として記事の最後に残す。

ランダム回転行列とQR分解
ランダム回転行列をQR分解から求めるとある。
$\boldsymbol{\rm{A}}=\boldsymbol{\rm{Q}}\boldsymbol{\rm{R}}$
$\boldsymbol{\rm{Q}}^T\cdot \boldsymbol{\rm{Q}}=\boldsymbol{\rm{I}}$

Aはd×dの適当なガウス分布の正方行列でこれをQR分解して、Qを回転行列として利用する。Rは使用しない。
codebookとQLoRAのNF4
ここでcodebookが何を意味するかを考える。
$c_1,c_2,...,c_{2^{b}}$の-1~1の値である。
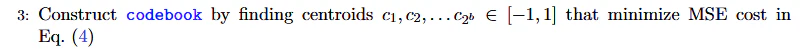
これはQLoRAのNF4におけるqの配列を思い出す。

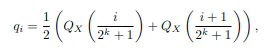
これは分布がガウス分布であれば以下の様なerfinv関数で大体作れる。
重みが統計的にずれていればその重みの分布に従い調整する。例えばマイナスの値がプラスの値より多ければマイナスの分割間隔を狭くし、プラスの分割の間隔を広げる。これによって各量子化bitの出現頻度が同じになるような間隔を作ればいい。
import scipy
import numpy as np
import matplotlib.pyplot as plt
b = 4
n = 2**b
# 1. erfinv
x = np.arange(16)
u = np.linspace(-1.0, 1.0, n+1)
Qx = scipy.special.erfinv(u*0.96)
q = np.zeros(n)
for i in range(n):
q[i] = (Qx[i]+Qx[i+1])/2
q /= np.max(q)
# 2. NF4
q2 = np.array([-1.0, -0.6961928009986877, -0.5250730514526367,
-0.39491748809814453, -0.28444138169288635, -0.18477343022823334,
-0.09105003625154495, 0.0, 0.07958029955625534, 0.16093020141124725,
0.24611230194568634, 0.33791524171829224, 0.44070982933044434,
0.5626170039176941, 0.7229568362236023, 1.0])
x2 = np.abs(np.linspace(-0.5, 0.5, 16)) - 0.5
# 3. kmeans(codebook)
from sklearn.cluster import KMeans
samples = np.random.randn(500000, 1)
kmeans = KMeans(n_clusters=n).fit(samples)
codebook = np.sort(kmeans.cluster_centers_.flatten())
codebook /= np.max(np.abs(codebook))
plt.plot(x, q, label='erfinv')
plt.plot(x-x2, q2, label='NF4')
plt.plot(x, codebook, label='k-mean')
plt.legend()
plt.show()
なお、KMeanでLOKY_MAX_CPU_COUNTの何かが警告が出る場合は以下を設定してると良い。
import os
os.environ['LOKY_MAX_CPU_COUNT'] = "4"
erfinv(逆誤差関数)やNF4は重みの分布に正規分布を仮定しているがkmeanは他の分布、例えば元の分布がロジスティック分布や一様分布であってもちょうどいいcodebookを生成できる。
Lloyd–Max(1次元k-means)はデータ点の重心を更新していく。
適当な$c_i$から開始し、区間境界$bound=\frac{c_i+c_{i+1}}{2}$で区切った各領域で重心$c_i$を更新する。その結果量子化におけるmse誤差が最小となるように$c_i$が収束する。
k平均法の収束の図とかを見るとより理解しやすいかもしれない。
クラスター分けしたデータからそのクラスターの重心を求め、その重心座標と各データの距離から再度クラスター分けを行い、これを何度か繰り返す。
アルゴリズム①の量子化コード
from sklearn.cluster import KMeans
import numpy as np
def quant_mse(x, Q, bit):
hidden_dim = x.shape[0]
batch_num = x.shape[1]
y = Q @ x
y_scale = np.max(np.abs(y))
y /= y_scale
kmeans = KMeans(n_clusters=2**bit).fit(y.reshape(hidden_dim*batch_num,1))
codebook = np.sort(kmeans.cluster_centers_.flatten())
if bit==4:
print('bit=', bit, 'codebook=', codebook)
y = np.tile(y.reshape(hidden_dim, batch_num,1),(1,1,2**bit))
c = np.tile(codebook.reshape(1,1,2**bit),(hidden_dim, batch_num,1))
idx = np.argmin(np.abs(y - c), axis=2)
qy = codebook[idx]
qy *= y_scale
qx = Q.T @ qy
return qx
hidden_dim = 1024
batch_num = 256
x = np.random.randn(hidden_dim, batch_num)/np.sqrt(hidden_dim)
x[0] += 5.0
x[10] *= 20
A = np.random.randn(hidden_dim, hidden_dim)
Q, R = np.linalg.qr(A)
for bit in range(1,8):
qx = quant_mse(x, Q, bit)
mse = np.sum((x - qx)**2)/np.sum(x**2)
print('bit=', bit,'mse=',mse)
-------------------------------------------
bit= 1 mse= 0.3661765036671557
bit= 2 mse= 0.11894296675099901
bit= 3 mse= 0.035322523848233194
bit= 4 codebook= [-0.77069511 -0.5866832 -0.46034606 -0.37232645 -0.30281123 -0.23913453
-0.17808743 -0.11816987 -0.05904284 0.00246032 0.06465763 0.13153272
0.20693523 0.29710566 0.4056128 0.57392675]
bit= 4 mse= 0.010432209230735982
bit= 5 mse= 0.002465568531398306
bit= 6 mse= 0.000627501149591063
bit= 7 mse= 0.00016062157398235205
論文には以下のように書かれていてmseが$0.36,0.117,0.03,0.009$が上述のコードで求められているのが確認できる。またbit=4のcodebookは長さ16で左右非対称で元のデータ分布に依存する。
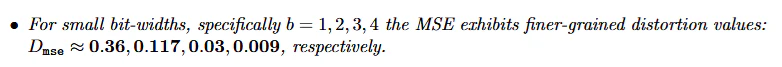
idx値復元の効率性
最初where関数を用いてindex値を一個づつ変換していた。
qy = np.zeros((hidden_dim, batch_num))
for k in range(2**bit):
qy = np.where(idx==k, codebook[k], qy)
index値をone-hotベクトルに変換し、codebookを掛ける場合は以下のように書ける。
ただし行列はほとんど疎なので効率がいいかは分からない。
qy = np.eye(2**bit)[idx] @ codebook.T
その後、以下でも普通に問題ないのを知った。
qy = codebook[idx]
アルゴリズム②
アルゴリズム②のqjl

qjl量子化におけるsign関数は1bit bitNetでも現れており、1bit量子化(2値)において現れるのは普通であり、1.58bit量子化(3値)や2bit量子化(4値)を考える上だとsign関数の代わりにround関数が現れてくる。


量子化残差rにSを掛けてsign関数で1bit量子化する。
また量子化残差rのL2ノルムであるγを求める。$\gamma=||r||_2$

戻すときはqjlにSの転置行列を掛け係数をかけ、アルゴリズム①の量子化に足す。
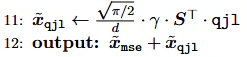
ここで$\sqrt{\frac{2}{\pi}}=0.798...$はガウス分布のabsmean関数がそうなる。
x = np.random.randn(4096*4096)
b = np.mean(np.abs(x))
print(b)
------------------------------------
0.7978108731432086
Sはガウス分布で作られるd×dの行列で量子化生成時と量子化解除時に同じ行列を用意しないといけない。
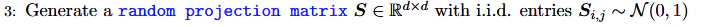
アルゴリズム②の量子化コード
アルゴリズム②において以下のy,qy,qy2を計算してみてcos類似度を計算してみる。
$y=W\cdot x$
$qy=qW\cdot qx$
$qy2=(qW+W_{qjl})\cdot (qx+x_{qjl})$
$cos\_sim1=cos\_sim(y,qy)$
$cos\_sim2=cos\_sim(y,qy2)$
def quant_prod(r, S):
hidden_dim = r.shape[0]
batch_num = r.shape[1]
qjl = np.sign(S @ r)
l2_norm = np.linalg.norm(r,ord=2,axis=0,keepdims=True)
l2_norm = np.tile(l2_norm, (hidden_dim,1))
xqjl = np.sqrt(2/np.pi)/hidden_dim*l2_norm*(S.T @ qjl)
#print('meanabs_r=', np.mean(np.abs(r)),', meanabs_xqjl=', np.mean(np.abs(xqjl)))
#print('meanabs(S.T@S)=',np.mean(np.abs(S.T@S)),', sqrt(d*2/pi)=', np.sqrt(hidden_dim*2/np.pi))
#print('r/xqjl=', np.mean(np.abs(r))/np.mean(np.abs(xqjl)))
return xqjl
hidden_dim = 1024
batch_num = 1
output_dim = 256
x = np.random.randn(hidden_dim, batch_num)/np.sqrt(hidden_dim)
W = np.random.randn(hidden_dim, output_dim)/np.sqrt(hidden_dim)
x[0] += 5.0
x[10] *= 20
A = np.random.randn(hidden_dim, hidden_dim)
Q, R = np.linalg.qr(A)
S = np.random.randn(hidden_dim, hidden_dim)
for bit in range(1,8):
qx = quant_mse(x, Q, bit)
qW = quant_mse(W, Q, bit)
rx = x - qx
rW = W - qW
xqjl = quant_prod(rx, S)
Wqjl = quant_prod(rW, S)
qx2 = qx + xqjl
qW2 = qW + Wqjl
y = (W.T @ x).reshape(output_dim)
qy = (qW.T @ qx).reshape(output_dim)
qy2 = (qW2.T @ qx2).reshape(output_dim)
cos_sim1 = np.sum(y * qy)/(np.linalg.norm(y,ord=2)*np.linalg.norm(qy,ord=2))
cos_sim2 = np.sum(y * qy2)/(np.linalg.norm(y,ord=2)*np.linalg.norm(qy2,ord=2))
print('bit=', bit,'+0, cos_sim1=',cos_sim1)
print('bit=', bit,'+1, cos_sim2=',cos_sim2)
------------------------------------------
bit= 1 +0, cos_sim1= 0.6955806277796326
bit= 1 +1, cos_sim2= 0.7476469454126211
bit= 2 +0, cos_sim1= 0.8981193296306056
bit= 2 +1, cos_sim2= 0.9228969850916453
bit= 3 +0, cos_sim1= 0.9716313783691025
bit= 3 +1, cos_sim2= 0.9725752195440108
bit= 4 +0, cos_sim1= 0.9921447664621731
bit= 4 +1, cos_sim2= 0.9939368198427676
bit= 5 +0, cos_sim1= 0.9975446903216397
bit= 5 +1, cos_sim2= 0.9982842393961945
bit= 6 +0, cos_sim1= 0.999528293942991
bit= 6 +1, cos_sim2= 0.9996369315530476
bit= 7 +0, cos_sim1= 0.9999005834313949
bit= 7 +1, cos_sim2= 0.999916941082096
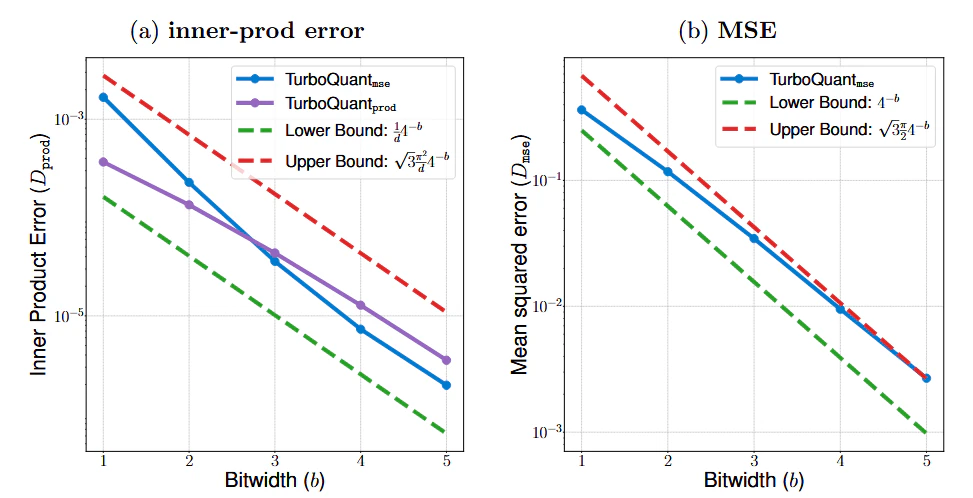
cos_sim1とcos_sim2を比べると若干cos_sim2の方が良いが、それはqjl量子化に1bit費やすからであり、同じbit換算なら大体アルゴリズム①の量子化の方がいい。
cos類似度の代わりに以下の様な異なるy[0]とy[1]の内積誤差を計算する。
その時の量子化誤差は同じ量子化bitでは多くの場合でqjl量子化のほうが良かった。
batch_num = 2
...
y = (W.T @ x).reshape(output_dim, batch_num)
qy = (qW.T @ qx).reshape(output_dim, batch_num)
qy2 = (qW2.T @ qx2).reshape(output_dim, batch_num)
error1 = np.abs(y[:,0] @ y[:,1] - qy[:,0] @ qy[:,1]) / np.abs(y[:,0] @ y[:,1])
error2 = np.abs(y[:,0] @ y[:,1] - qy2[:,0] @ qy2[:,1]) / np.abs(y[:,0] @ y[:,1])
print('bit=', bit,'+0, inner_prod_error1=',error1)
print('bit=', bit,'+1, inner_prod_error2=',error2)
-------------------------------
bit= 1 +0, inner_prod_error1= 0.5706519281419506
bit= 1 +1, inner_prod_error2= 0.19702186697768523
bit= 2 +0, inner_prod_error1= 0.273129436489087
bit= 2 +1, inner_prod_error2= 0.028909195685932188
bit= 3 +0, inner_prod_error1= 0.05961029171891594
bit= 3 +1, inner_prod_error2= 0.005962663019162352
bit= 4 +0, inner_prod_error1= 0.03983044642435016
bit= 4 +1, inner_prod_error2= 0.008174320169467304
bit= 5 +0, inner_prod_error1= 0.017539322224659152
bit= 5 +1, inner_prod_error2= 0.009748250031909402
bit= 6 +0, inner_prod_error1= 0.002348321531005058
bit= 6 +1, inner_prod_error2= 0.001561047239420965
bit= 7 +0, inner_prod_error1= 0.0010004222370677276
bit= 7 +1, inner_prod_error2= 0.0028945521561829506
論文の図では内積誤差においてbit1,2だと②(TuboQuant_prod)のほうがエラーが小さく、bit3以降だとアルゴリズム①(TuboQuant_mse)のほうが良くなるらしい。
qjl量子化スケールのずれ
以下をコメントアウトを外して見てみると、入力rの絶対値平均と出力xqjlの絶対値平均が僅かにずれている。そのずれの大きさは元の$x,W$が変わらなくても、異なる量子化bitに依存する。またSとSの転置行列の絶対値平均も$\sqrt{d\cdot 2/\pi}$からもずれている。
print('meanabs_r=', np.mean(np.abs(r)),', meanabs_xqjl=', np.mean(np.abs(xqjl)))
print('meanabs(S.T@S)=',np.mean(np.abs(S.T@S)),', sqrt(d*2/pi)=', np.sqrt(hidden_dim*2/np.pi))
print('r/xqjl=', np.mean(np.abs(r))/np.mean(np.abs(xqjl)))
-------------------------------------------------
meanabs_r= 0.06425918481414755 , meanabs_xqjl= 0.07342348133188356
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.8751857532291037
meanabs_r= 0.015081178176801395 , meanabs_xqjl= 0.01535412866933625
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9822229904143005
bit= 1 +0, cos_sim1= 0.6481698296506542
bit= 1 +1, cos_sim2= 0.7408383469961393
meanabs_r= 0.04185685936058811 , meanabs_xqjl= 0.04380718347094675
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9554793539362759
meanabs_r= 0.008592674292158698 , meanabs_xqjl= 0.008741790303310286
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9829421656230851
bit= 2 +0, cos_sim1= 0.8913572372168914
bit= 2 +1, cos_sim2= 0.9124989041274659
meanabs_r= 0.02311015238105768 , meanabs_xqjl= 0.024092475225773728
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9592269853757004
meanabs_r= 0.004678378355026681 , meanabs_xqjl= 0.004762222424130497
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9823939199733779
bit= 3 +0, cos_sim1= 0.9691436989865007
bit= 3 +1, cos_sim2= 0.9738214095024289
meanabs_r= 0.01228041394299275 , meanabs_xqjl= 0.01250983450722538
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9816607834340156
meanabs_r= 0.002460269907428172 , meanabs_xqjl= 0.0025147556734170574
meanabs(S.T@S)= 26.458078196366245 , sqrt(d*2/pi)= 25.532305945691693
r/xqjl= 0.9783335746828835
bit= 4 +0, cos_sim1= 0.9909570832604432
bit= 4 +1, cos_sim2= 0.992740192302105
...
そもそもスケール部分が論文と僅かに違っているのに気付いたろうか。
論文だと$\sqrt{\pi/2}$の部分がコードだと$\sqrt{2/\pi}$にしている。
こちらの方が$x_{qjl}$スケールの再現に良かったからなのだが、自分が何かを勘違いしている可能性は高い。
xqjl = np.sqrt(2/np.pi)/hidden_dim*l2_norm*(S.T @ qjl)
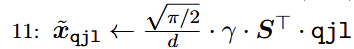
$\gamma=L2\_norm(r)$
QJLの式(参考):
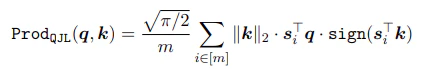
あるいはJL行列(Johnson-Lindenstraus:S)は以下のように正規分布乱数$N(0,1)$から適当に作成したがもっと何らかの規格化が必要なのかもしれない。
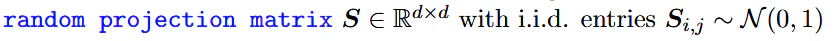
ベクトル量子化(勘違い)
最初の方に書いたベクトル量子化の検討結果を残しておく。
一応、このやり方でも量子化が出来なくはないが、topkのkを増やした場合に上がる再現量がわずかであり、量子化は非効率的である。
ベクトル量子化の式(勘違い)
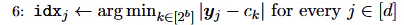
数式的に近いと思ったのはVQVAEにおけるベクトル量子化の式である。
あるいはLLMにおけるtoken_indexのような離散化indexへの変換や、MoEにおけるgate重みである。
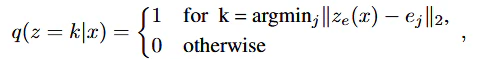
古典的なgate関数においては以下で示される。
$G(x)=softmax(TopK(x\cdot W_{gate}, k))$
VQVAEやLLMにおけるtoken_indexは最も一致するベクトルを採用するからindexがone-hotであるのに対して、MoEのgate関数ではtopk関数を使用するのでk個のindexが1である。
$|e^T \cdot x - 1|$に$e\cdot e^T=I$となる$e$を掛けると$|e\cdot e^Tx - e|=|x - e|$である。
つまり、xにembedベクトルを掛けて内積が1に近くなるベクトルを探さなくても、xとembedベクトルの差分の絶対値を見ればいい。
以下のようにxの値がembedの二個の基底ベクトルの足し合わせで示せるとした時、xとembedの次元を合わせればこの引き算の絶対総和の最小を探せば、xとembedの掛け算は不要である。
$y=x \cdot embed$
$index=arg\max(|y|)$
$z=|tile(x)-embed|$
$index=arg\min(z)$
import numpy as np
hidden_dim = 128
vocab_num = 5
embed = np.random.randn(hidden_dim, vocab_num)/np.sqrt(hidden_dim)
x = -0.4*embed[:,0] + 0.8*embed[:,3]
y = x @ embed
print('x.shape=', x.shape)
print('embed.shape=', embed.shape)
print('y=', y)
x = np.tile(x.reshape(hidden_dim, 1),(1,vocab_num))
z = np.sum(np.abs(x - embed),axis=0)
print('z=', z)
--------------------------------------
x.shape= (128,)
embed.shape= (128, 5)
y= [-0.54750005 0.02114625 -0.08258768 0.83018206 0.17872929]
z= [16.4223792 11.71405178 12.89683446 3.97263522 9.95282443]
ベクトル量子化のコード(勘違い)
以下の時、$z=|y-embed|$を求めzが小さい値から順に量子化する。これはtopk関数を使うのに等しく、この処理でvalue, indicesを得る。idxとvalueの両方の値を使用しないと量子化は上手くいかなかった。
また、zの大きさと√dの大きさが微妙にずれていて規格化のスケールが√dからずれてしまっていた。適当なbiasをdに足して量子化するほうがよく見えた。
import numpy as np
import torch
hidden_dim = 128
vocab_num = 2**16
x = np.random.randn(hidden_dim)/np.sqrt(hidden_dim)
x[0] += 5.0
x[10] *= 20
embed = np.random.randn(hidden_dim, vocab_num)/np.sqrt(hidden_dim)
embed_scale = np.mean(np.abs(embed))
#print('embed_scale=', embed_scale)
A = np.random.randn(hidden_dim, hidden_dim)
Q, R = np.linalg.qr(A)
y = Q @ x
y_scale = np.mean(np.abs(y))/embed_scale
y /= y_scale
y = np.tile(y.reshape(hidden_dim, 1),(1,vocab_num))
z = np.sum(np.abs(y - embed),axis=0)
print(z)
#print('y_scale=', y_scale)
#print('sqrt(d)=', np.sqrt(hidden_dim))
#print('sqrt(d)/0.798=', np.sqrt(hidden_dim)/np.sqrt(2/np.pi))
#print('mean_z=', np.mean(z))
#print('mean_y=', 1/np.mean(np.abs(y)))
#print('mean_embed=', 1/np.mean(np.abs(embed)))
for k in [1,2,4,6,8,12,16,24,32,64,128]:
u = torch.from_numpy(z.astype(np.float32)).clone()
value, indices = torch.topk(u, k, largest=False)
value = value.to('cpu').detach().numpy().copy()
indices = indices.to('cpu').detach().numpy().copy()
if hidden_dim==64:
bias = -16
elif hidden_dim==128:
bias = -8
elif hidden_dim==256:
bias = 16
elif hidden_dim==512:
bias = 64
else:
bias = 0
c = np.zeros(vocab_num)
for i in range(k):
c[indices[i]] = 1.0 - value[i]/np.sqrt(hidden_dim+bias)
#print(value[i])
qy = embed @ c
qy *= y_scale
qx = Q.T @ qy
mse = np.sum((x - qx)**2)/np.sum(x**2)
print('k=', k,'mse=',mse)
-----------------------------------------
[12.37691447 12.67508379 12.78263717 ... 12.51082058 11.71509254
13.20684273]
k= 1 mse= 0.9659392698648385
k= 2 mse= 0.9213695284980896
k= 4 mse= 0.8533731958904824
k= 6 mse= 0.800309034367945
k= 8 mse= 0.757177004419557
k= 12 mse= 0.678821483753514
k= 16 mse= 0.6239314611128386
k= 24 mse= 0.5275251474687341
k= 32 mse= 0.46349443791665307
k= 64 mse= 0.2839979600725631
k= 128 mse= 0.155802559474205
cの値は0~1であるので一個あたりfp8(8bit)で表現できる。
indicesの値はvocab_numの大きさに依存し、vocab_num=65536の時、一個16bitである。
従ってtopkのk=1であれば8+16=24bit、topkのk=8であれば8x24bit=192bit。
hidden_dim=128ならtopk=8なら1変数当たり1.5bitである。
参考までに初歩的な最大値間の等間隔量子化のmseを示す。
ベクトル量子化はbitの量子化効率的によくない。
hidden_dim = 128
x = np.random.randn(hidden_dim)/np.sqrt(hidden_dim)
def quant(x, b):
x_scale = np.max(np.abs(x))/(2**(b-1))
split = (2**b-1.0)/2.0
qx = (np.clip(np.round(x/x_scale+split),0,split*2)-split) * x_scale
return qx
for b in range(1,8):
qx = quant(x, b)
mse = np.sum((x - qx)**2)/np.sum(x**2)
print('b=', b,'mse=',mse)
-------------------------------------------------------
b= 1 mse= 0.5678472133289747
b= 2 mse= 0.12002471319077919
b= 3 mse= 0.0351334223838419
b= 4 mse= 0.007757804866291579
b= 5 mse= 0.001896614861163555
b= 6 mse= 0.0005530022759338022
b= 7 mse= 0.00013082282052867726
考察まとめ:
TurboQuantの量子化についてコードを書いてみて考えた。
TurboQuant_mse(アルゴリズム①)で重要なのは、QR分解したQを掛けて特定の外れ値を分散させる方法と、kmeans法でcodebookを作成しNF4のような非等間隔をする方法であろう。
一方、TurboQuant_prod(アルゴリズム②)において量子化残差rを1bitで量子化するqjlを行う場合、異なるy[0]とy[1]の内積誤差が小さくなる。これは恐らく量子化したAttention計算においてtoken間内積がより正しく再現できるだろう。
とはいえ、$Q^TQ=I$であるランダム回転行列を掛けるという発想はNVFP4でもRandom Hadamard Transforms(RHT)であったし、非等間隔codebookを用意するというのもQLoRAにおけるNF4で既に非等間隔分割については定義されているので全く新しい概念ではない。
qjlは異なる入力の内積は改善するものの、同じ入力の内積(cos類似度)ではメリットが見えなかった。
まあggufはBlock内最大値の等間隔量子化が基本で、層によって量子化bitを変える可変量子化bitは見られるが、基本的にはランダム回転行列や非等間隔量子化はされてないと思われる。その理由は復元速度上の問題であろう。