Wan2.1は2025/02/28に発表された。
Wan2.2は2025/07/28に発表された。
Wan2.5-Previewは2025/09/24に発表された。
しかし、Wan2.5は今のところオープンモデルではないし、技術レポートもないため、Wan2.2からどのような変更があるのかは不明である。Wan2.5の改善箇所に関してどのような変更余地があるか想像(妄想)してみる。
Captionの改善
Qwen2.5VLが発表されたのが今年の1~3月、Qwen3-VLが発表されたのが今年の9~10月あたりである。
Video理解のVideoMMEの結果は以下の通り。これを用いればおそらく学習データの静止画や動画に付与するCaptionに改善がみられるはずだと思う。Wan2.1の論文にはVideoMMEの精度は69.1とある。既にWan2.2がQwen2.5-VLのCaptionの改善を受けた可能性はあるが、Wan2.5でもQwen3-VLを用いればCaptionが良くなるだろう。
VideoMME:
Wan2.1 caption model(2025/02/28):69.1(Wan2.1論文より)
Qwen2.5-VL 7B(2025/01/28):65.1
Qwen2.5-VL 32B(2025/03/25):70.5
Qwen2.5-VL 72B(2025/01/28):73.3
Qwen3-VL 8B(2025/10/15):71.4
Qwen3-VL 32B(2025/10/21):76.6
Qwen3-30B-A3B(2025/10/04):74.5
Qwen3-235B-A22B(2025/09/23):79.2
Wan2.2(2025/07/28)、Wan2.5(2025/09/24)。
また、他のVLMのVideoMMEのスコアと比較してもそれほど遜色ない。
GPT-4o:71.9
GPT5(2025/08/07):77.3
Gemini 1.5-Pro:75.0
Gemini 2.5-Pro(2025/06/17):80.6


TextEncoderの改善
Wan2.1、Wan2.2で使われるTextEncoderはumt5-xxlであり、モデルサイズは13Bである。
以下、umt5-xxl(Wan)とllava_llama3(HunyuanVideo)、qwen2.5、qwen3の潜在次元とレイヤー深さを示す。
| model名 | hidden_size | intermediate_size | layer_num | vocab |
|---|---|---|---|---|
| umt5-xxl 13B | 4096 | 10240 | 48 | 256384 |
| llava_llama3 8B | 4096 | 14336 | 32 | 128256 |
| qwen2.5-vl 3B | 1280 | 3420 | 32 | 151936 |
| qwen2.5-vl 7B | 3584 | 18944 | 28 | 152064 |
| qwen2.5-vl 32B | 5120 | 27648 | 64 | 152064 |
| qwen2.5-vl 72B | 8192 | 29568 | 80 | 152064 |
| qwen3-vl 2B | 2048 | 6144 | 28 | 151936 |
| qwen3-vl 4B | 2560 | 9728 | 36 | 151936 |
| qwen3-vl 8B | 4096 | 12288 | 36 | 151936 |
| qwen3-vl 32B | 5120 | 25600 | 64 | 151936 |
| qwen3-vl 30B-A3B | 2048 | 6144 | 48 | 151936 |
| qwen3-vl 235B-A22B | 4096 | 12288 | 94 | 151936 |
画像生成モデルのqwen-imageはTextEncoderに(qwen2.5-VL 7B)を使用しているため、Wanにおいてもqwen2.5やqwen3をText-Encoderに使っても問題ないのではないか。

ここでWan2.1の論文にTextEncoderの学習曲線の結果があるがQwen2.5-7B-InstructはおそらくVLMモデルではない可能性もある。何故ならQwen2.5 VLを世に出したのは2025年1月28日であり、Wan2.1が公開されたのは2025年2月25日で間は一か月もない。
同じAlibabaグループとはいえ、通常の開発プロセス上、未公開モデル利用は考えにくい。


TextEncoder(LLM)のクオリア
もう一個、TextEncoder関連で話題にしたいのはクオリアの話である。
メアリーの部屋という寓話では以下のような物語が語られる。
要するに人生で一度も「赤」を見た経験がない人物が「赤」という概念を理解しているといえるのか?
メアリーは聡明な科学者であるが、なんらかの事情により、白黒の部屋から白黒のテレビ画面を通してのみ世界を調査させられている。彼女の専門は視覚に関する神経生理学である。次のように想定してみよう。彼女は我々が熟したトマトや空を見るときに生じる物理的過程に関して得られる全ての物理情報を手にしており、また「赤い」や「青い」という言葉の使い方も知っている。例えば、空からの特定の波長の光の集合が網膜を刺激するということを知っており、またそれによって神経中枢を通じて声帯が収縮し、肺から空気が押し出されることで「空は青い」という文が発声される、ということをすでに知っているのである。(中略)さて、彼女が白黒の部屋から解放されたり、テレビがカラーになったとき、何が起こるだろうか。彼女はなにかを学ぶだろうか?
ここにおいて通常のLLMでは「赤い」という単語を知っており、それがリンゴや血の色だと知っていて、赤に関する知識もある。しかし、LLMは自分の目で直接見て「赤」という色を知っているわけではない。また「左」という概念も単語としての理解をしていても空間的な概念として理解しているか分からない。
CLIP Text EncoderはCLIP Image Encoderと一致するように学習されており、「画像の犬」と「テキストの犬」のEncoderを通過した潜在ベクトルが一致するようにされている。しかしながら、CLIP Text Encoderは100件の犬の画像が入った時のCLIP Image Encoderの出力潜在ベクトルの集合をぼんやりと知るに過ぎない。
VLM(Vision LLM)ではCLIP(またはSigLIP) Image Encoderを通じたImage TokenをText Tokenとして取り込んでおり、ある程度は画像における「赤」や「左」という概念を理解している。従って未知の赤い果物の画像を与えたとき、その「赤」という色は認識可能である。
しかしながら、DiT(Diffusion Transformer)の潜在空間ではVAE Encoderによって画像をtokenとして取り込んでおり、前述のCLIP Image Encoderの潜在空間とVAE Encoderの潜在空間は一致しない。
そもそも解像度時点でCLIP Image Encoderは1/14x1/14でVAEは1/8x1/8や1/16x1/16である。3D VAEでは時間軸のフレーム方向の圧縮もある。このためVAE EncoderとCLIP Image Encoderは入力画像が同じでもEncoderが違うと色付き眼鏡と魚眼レンズで見た景色ぐらいの違いが存在する可能性がある。
VAE潜在空間を知るTextEncoder
前述したとおり単純なTextEncoder(LLM)は画像のクオリアを持ってない。
VLM(Vision LLM)の場合、画像のクオリアを得るがそれはCLIP潜在空間の写像の変形であり、それはDiTにて用いられるVAE潜在空間ではない。
VAE潜在空間を知るTextEncoderについて実はこれは存在する。
最近の画像生成AIのHunyuanImage3.0のモデル図においてはTextEncoderとDiTをそもそも一個の大型のTransformerにしており、画像理解(VLM学習)においてはUnd.Encoder(CLIP Image Encoderと思われる)とGen.Encoder(VAE Encoderと思われる)の両方を与えてテキストと画像の相関をVLMで学習している。
これはVLMがCLIP Encoderを通した画像とTextの相関を知れるが、一方でVLMは拡散モデルに使われるVAE Encoderを通した画像とTextの相関を知ることができない点の改善になる。

(論文内の文章):条件付き画像入力に対しては、VAEからの潜在特徴とビジョンエンコーダからの潜在特徴を連結するデュアルエンコーダ戦略を導入する。このアプローチにより、単一のシーケンス内で生成と理解の両方をサポートする統一されたマルチモーダル表現が可能となる。これは、タスクごとに視覚特徴を分離することが多かった従来の統一モデル[33、34、35、36](例:理解にはビジョンエンコーダの特徴を、生成にはVAEの特徴を使用)との重要な違いである。我々の手法は、連続的な文脈内で、交互に挿入されるテキスト対話、画像生成、画像理解、画像編集といった複雑なマルチモーダル相互作用を容易にし、それによって、理解と生成の別々のパイプラインを切り替える必要性を排除します。
ただ、個人的にはTextの理解には深い(数十層)Transformerが必要で、画像の理解には浅い(10層程度)Transformerでよいと思っている。このため浅い層において両者のAttentionを計算しても、画像担当は入力を理解してもText担当はまだ入力を理解してないから浅い層で画像とテキストの相関を学ぶことは出来ず、あまり効率的とは言えない。
例えば宇宙の真理とはつまり42です、とLLMが導き出すのがTransformerの最終層の一個手前の深い場所で導き出したとして、これを画像生成担当に渡して残り一層で42を書かせるには遅すぎる。これを解決するにはもっと浅い層で宇宙の真理=42と気付くか、画像生成タスクの分通常のLLMよりTransformerの層がもっと深くないといけない。
TextEncoderとDiTを混合させるよりも、Text EncoderとDiTが事前に分かれていた方がText理解と画像理解にかかるTransformer層の深さを合わせることができ、よりTransformerの浅い層で両者の関係を知れるのではないか。また、拡散モデルは推論を何回も繰り返すため宇宙の真理=42であると何度もTransformerに計算させるのは効率が悪い。
それともMoEにおいては画像担当15Experts、Text担当49Expertsのように担当Experts数を自動で適切に割り振ることでText理解と画像理解にかかるTransformer深さを合わせられるのだろうか?
VAEの改善
Wan2.1でのVAEは幅と高さをそれぞれ1/8にして、時間方向は1/4にする。Token一個当たりの潜在次元は16でpatchfyでこれを4つ合わせて64とする。
SeaweedのVAEにおいては幅と高さを最初から1/16にしてこの次元を48にするのが見える。
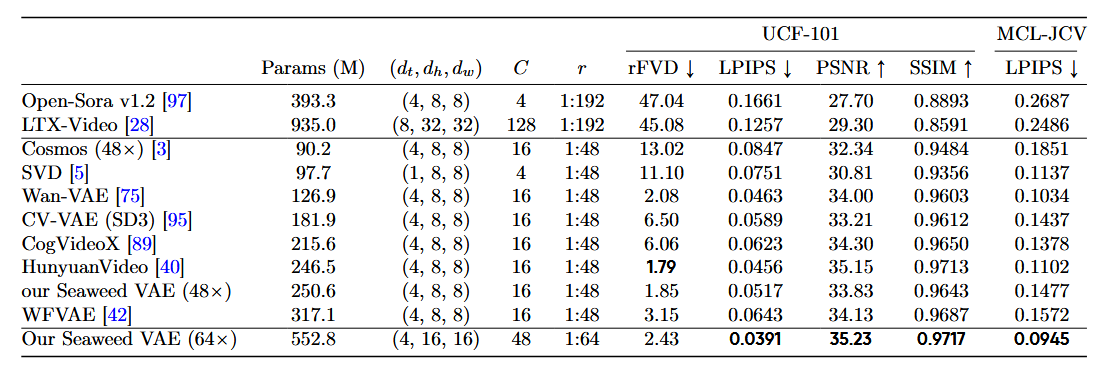
Wan2.2 5BのVAEの圧縮比率はこのSeaweedと等しい。
・(Wan2.1 VAE)1/8x1/8x1/4,z=16、(patchfy)縦横4個集めてz=16→64
・(Wan2.2 VAE)1/16x1/16x1/4, z=48
ただし、patchfyを含めるとlatent解像度が1/16x1/16なのは実は前からであるので潜在空間の次元が64→48に削減されたと考えるのが良いか。
一方でWan2.2 VAEが作られたがこれの使用は5Bモデルのみで、14Bモデルではhigh/low noiseモデルの分割が行われてこれをfinetuneしたため、Wan2.2 14BではWan2.2 VAEは使われずWan2.1 VAEのままである。何故ならVAEを更新するとモデルの互換性がまったくなくなり、いちから学習をしなくてはならない。
このためWan2.2 14BモデルではVAEの改善はなく、改良の余地はある。
もう一つWan2.1 VAEの課題を挙げておくと、Qwen-Imageの論文にWan2.1 VAEが出ており、Wan2.1 VAEは細かいテキストがつぶれてしまう現象が起きている。なおWan2.1は時間方向のフレームを1/4に圧縮するため厳密には画像系のVAEと単純比較はできないが、細かいテキストのレンダリングにおいて教師学習データを渡す際に画像生成AI系よりも文字の再現において不利なことが想像される。

MoEのExpert数の増大
・TimestepによるMoE
Wan2.2のモデルではhigh noise/low noiseで2個のモデルを使用する。
これを3個や4個に分割し、それぞれのTimestep範囲においてfinetuneする。
block_swapを使えばモデル容量とRAM使用量が増えるデメリットだけで、推論速度は少し下がるだけで実行できる。ただし、block_swapを用いる場合、2個のMoEでは64GBのメモリが要るので、3個や4個の場合はメモリ96GBや128GB必要となる。
一方、timestepの切り替え条件が複雑になるし、Wan2.2でのtimestep切り替え値(0.875)も公式が十分に周知したとは言えないと感じるため、Timestep分割でモデルを公開するのはリスクになる。
正しい切り替え条件でモデルを切り替えないとおそらく精度がちゃんと出ないであろう。
また類似の構成ではeDiff-IにおいてはBaseModelと二個のエキスパート(高ノイズ特化、低ノイズ特化)で計3個のモデルのMoEがあった。
・TokenごとのMoE
通常のMMDiTやDualStreamBlockという部分は二個のMoEとみなせる。
これはSingleStreamBlockの二倍のパラメータ数を持つ。これはText TokenとVideo Tokenによって適用されるTransformer重みが異なる。
OminiHuman-1.5ではDiTモデルがTextとAudioとVideoで分かれており、MMDiT(Triple)である。処理するTokenの種類ごとに重みを分割(複製)するこの方法も広義のMoEといえる。
・本格的なMoE
一方最近では画像生成AIにおいてHunyuanImage3.0(モデルパラメータは80B-A13B)のモデルサイズ160GB(推奨VRAM240GB以上)もある大型モデルであり、モデルのindexを確認すると64個のExperts重みがあるのが確認できる。ただしExpertに分かれてるのは二層のprojの全結合層であり、SelfAttentionのqkvoの重みはExpertsに分かれていない。(MM-DiT(Dual)であるQwen-Imageはqkvo重みは二個ある)
一見、HunyuanImage3.0をローカルで動かすのは難しそうに思えるがDiT層は32層なのでRAMが64GBメモリ×4枚とblock_swap=30くらいの設定(RAMに乗るの30層、VRAMに乗るの2層)であればRAMが足りればVRAM12GBでもこれを動かすのは可能なのだろうか?ただし、Windows11 homeだとメモリ上限128GB、Windows11 Proだとメモリ上限2TBなのでWindows11 homeだと256GBのメモリを乗せるのはOS的に無理である。また、最近のメモリ高騰によって64GBメモリ×4枚の価格は半年前は20万を切るくらいだったが、今は30万円くらいする(らしい)。256GB分のメモリ価格がGPUの5080よりも高い。
HunyuanImage3.0は画像生成AIであって動画生成AIにおいてこの手法はまだ知らないが(Veo3.1とかSora2のクローズモデルが採用している可能性はあるが)、この本当のMoEが今後の主流になる可能性はある。
ただし、このHunyuanImage3.0の発表(2025/09/28)はWan2.5の発表(2025/09/24)よりもあとなのでWan2.5にてこの本当のMoEが採用されている可能性は低いだろう。

Cross DiT vs MM-DiT(DualStream) vs HybridStream
・Wan2.1、2.2はCross DiT
Video TokenとText TokenはCross-Attentionで相関を計算される。
(Wan2.1)
・Qwen-ImageはMM-DiT
Video TokenとText TokenはSelf-Attentionで相関を計算される。
全てのレイヤーでVideo TokenとText Tokenはそれぞれ異なる重みを掛けられる。
Token毎に使用重みを決定するのでいわゆるMoEの一種と考えられる。
(Qwen-Image)
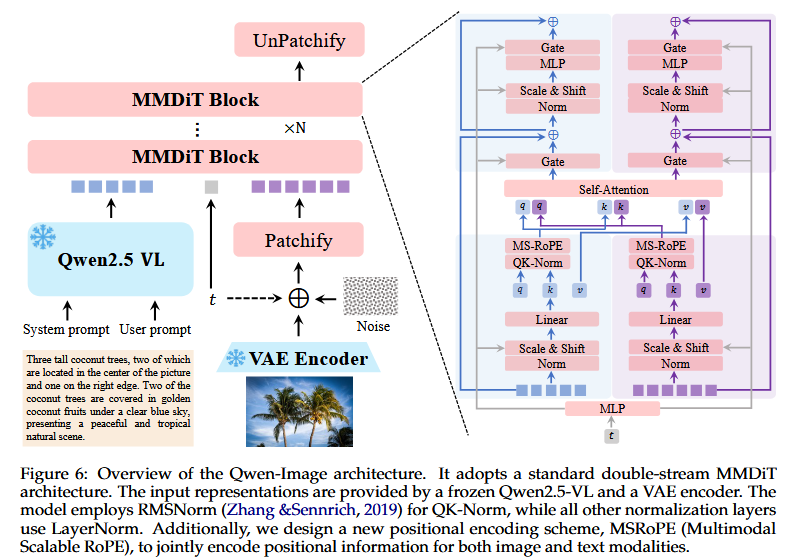
(StableDiffusion3)

・HunyuanVideoはDoubleStreamBlockとSingleStreamBlockの混合(HybridStream)
DoubleStreamBlockではVideo TokenとText Tokenはそれぞれ異なる重みを掛けられる。
SingleStreamBlockでは単純な一個のDiTとして計算される。
(HunyuanVideo)

・Flux、WaverでもDoubleStreamとSingleStreamの混合(Hybrid Stream)
(Flux)

(Waver)

・UViT
UViTはUnetライクなDiTである。
SD3の論文においてこれは初期の学習速度は優秀であるが最終性能は高くない。
(EasyAnimate)
モデル構造とloss推移
(StableDiffusion3)
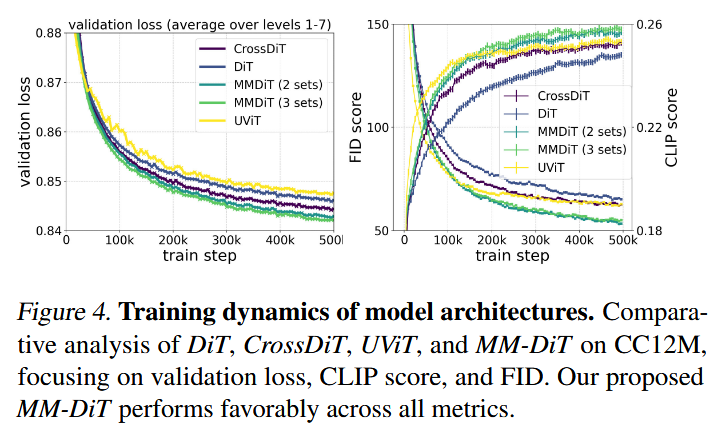
Waverの論文の以下はDualStreamはMMDiT(2step)、SingleStreamはDiTに相当する。
(Waver)

つまり論文に出てくる単一モデルのloss低減でいえば
・DualとSingleの混合(Hybrid)>MMDiT(2step)(DualStream)>CrossDiT>DiT(SingleStream)
である。ただし、MMDiT(DualStream)はVideoTokenとTextTokenのそれぞれの処理で二倍重みを持つ必要があるためVRAM制限下においてはモデルサイズを大きくしにくいというデメリットもある。またhigh/low noiseでモデルで重みを二個持つのとMMDiTで重みを二個持つのとではどちらが有利なのだろうか?
(Wan2.2)

論文の図からDiTの形式を調べた結果は以下である。(論文の中身は確認していない)
Wan2.5のDiTモデルはこれらいずれの様相を取っているだろうか?
| 形式 | 動画生成、画像生成モデル |
|---|---|
| Unet | StableDiffusion、Stable Video Diffusion、DynamiCrafter |
| UViT | SimpleDiffusion、EasyAnimate |
| DiT(Single) | Pyramid Flow? |
| CrossDiT | Wan2.1、Mochi 1、LTX-Video、Lumina Video、Step-Video、MovieGen、Cosmos、Allegro、Open Sora v1.0 |
| CrossDiT(MoE) | Wan2.2 |
| MMDiT(Dual) | StableDiffusion3、CogVideoX、Qwen-Image、Seedream 2.0&3.0 |
| MMDiT(Triple) | OmniHuman? |
| MMDiT(MoE) | HunyuanImage3.0、Seedream 4.0? |
| Hybrid(Dual&Single) | Flux.、HunyuanImage-2.1、HunyuanVideo、Waver、Seaweed、Open Sora v2.0 |
ただ、Wan2.2→Wan2.5の名称変化で大幅なモデル構成の変更は考えにくいかもしれない。
既存モデルを捨て、新規モデルを最初から学習しているならWan3.0と名付けるだろう。
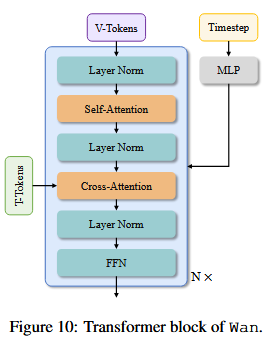
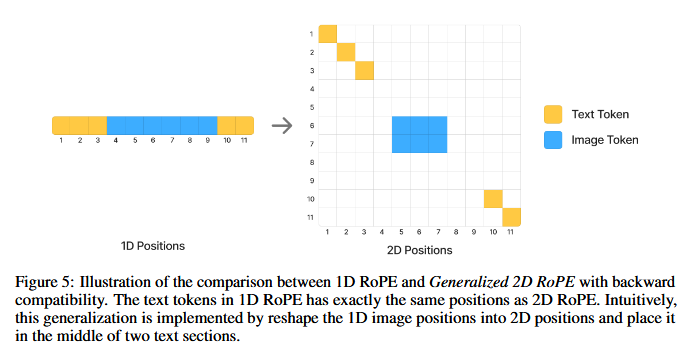
RoPE
Wan2.1はCrossDiTでありTextTokenとVideoTokenはCross-Attentionで計算される。TextTokenとVideoTokenを混合してSelf-Attentionを計算しないからこのVideoTokenポジション配置は3D RoPEだけでよくてあまりどうでもいい。もしMM-DiTのようなSelf-Attention構造を取るDiTを考えるならHunyuanImageやQwenImageの論文の図のようなVideo TokenとText Tokenの空間配置に留意したRoPEを取る必要があるのかもしれない。
(Hunyuan Image)
(Qwen Image)

美的評価と貴賤
簡単にいうと品質の等しい「白馬に乗った王子様」と「豚に乗った農奴」の画像はどちらが美的評価が高いとされるかという疑問。
一般には機械学習では雑多なデータで事前学習(Pre-training)を行った後、選別された学習データでファインチューニング(SFT)を行う。
美的評価モデルは、人間が学習データの一部をスコア付けした評価データを使って学習し、これを使ってすべての学習データの美的スコアを評価させる。同様にモーション評価モデルがある。
一応、美的フィルタリングにおいてクラスタリングという概念があり、これが学習データを分割して、各クラスターから等しくデータを除くことで学習データの多様性を維持してくれるとは期待できるが同じクラスター内で「白馬に乗った王子様」と「豚に乗った農奴」がいる場合、前者のみ抽出される可能性がある。
「豚に乗った農奴」を事前学習では学習しており、SFTでのみ除くというのなら問題ないが、段階的美的フィルタによって事前学習からすらも除かれる可能性がある。
他にも同じクラスタリング内で人間的価値の貴賤によって優先的に選ばれる動画(子供や子犬、スポーツカー)があるなら、逆に選ばれにくい動画対象(老人や虫、中古車)があるはずである。
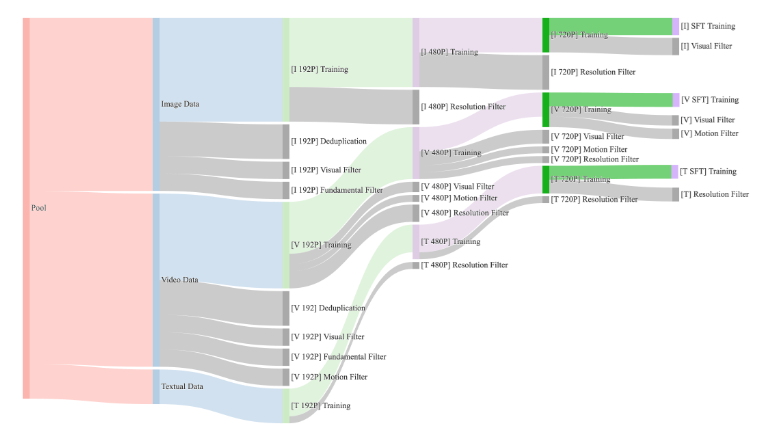
美的評価やモーション評価によって192P学習データは動画全体の1/2ほどであり、480P学習データは1/4、720P学習データは1/8、最後のSFTでは1/16くらいである。720Pの学習データ上位12%の選ばれたデータである。人間の価値基準で早めに削除された人気のない学習データの概念を生成するのは困難となるのではないだろうか。
また、品質の段階選別をしながら学習を行う場合、低い品質の概念自体を学ぶ事が困難となる。この場合、NegativePromptに「low quality」とか入れても学習データから低品質の動画が除かれている(評価ラベルも付与されない)ので低品質の概念が学習出来ないのでNegtivePromptに意味がない。
知識蒸留(生成画像の学習)
拡散モデルでは推論に20stepかかるのを4~8stepで達成できるモデルを蒸留モデルということがある。(Distilled Diffusion)
しかし、ここで話したいのはLLMにおいては小型LLMモデルを学習する際、小型LLMモデルと学習データだけで学習するよりも大型LLMモデルの出力を混ぜて学習する蒸留モデルである。(Knowledge Distillation)
これはひとつには学習データの質が雑多で分野や質が保証されないという問題がある。大型LLMの出力データは平均的な人間の回答より品質がよい。
そしてもうひとつに小型LLMにとって大型LLMの出力はLLM的な思考が似ているのでLLMにとって理解しやすい出力である可能性がある。(もしかしたら人間には理解できない機械にしか理解できない符号を含んでいるかもしれない)
画像生成AIでも実物写真よりも同じ画像生成AIの出力のほうがDiTは理解しやすいのではないか。
このように大型画像生成AIの生成画像を使って小型画像生成AIの学習を行ったり、大型動画生成AIの出力を使った学習を考える。利点として生成promptをCaptionとして使いまわせるので、Captionのない動画にVLMでCaptionを付与するよりも正確なCaptionを与えられる可能性がある。
また画像生成AIの投稿画像は大量の生成画像の一部であり、投稿者によって人の目による選別が既に行われて、明確に違和感を覚える画像は投稿されない。
このようにMidjourneyやNovelAI v4などの投稿画像を収集して学習データに加えれば、実際の雑多な質の画像にVLMでつけた不確かなCaptionをつけた学習データよりも良い品質や正確なCaptionを得られるかもしれない。
また、人物、服装、小道具、動作、背景がランダムに組み合わせた生成promptを用いることでバイアスのないよくばらついた学習データを用意できる。
また、画像生成AIは漢字やひらがなのレンダリングなどでも動画生成AIよりも高い位置にある。
ただし、これらは大型モデルの出力によって後塵を拝する小型モデルの性能を引き上げられることは可能であっても、トップを走る大型モデルの出力をさらに引き上げることは困難である。
版権キャラクター
Sora2とかで版権キャラの生成がなぜか出来ている。(問題にもなってはいるが…)
Captionの行うQwen3-VLの実行例で「鬼滅の刃」のキャラクターのラベル付けが可能になっている例を見かけたので、学習データに版権キャラを含み、このキャラクターのキャプションが正常に行われるなら、意図的にこれを消さない限りはWanでも版権キャラクターを学習するかもしれない。ただし、Wanでは版権キャラクターを学習データに含んでいるかどうか自体に疑問がある。
(個人的にはWan2.1よりHunyuanVideoのほうが出た気はする。というかLoRAなしのバニラのWan2.1はそれほど良くない)
無論、T2Vで版権キャラを生成できなくても、他の版権キャラクター生成の得意な画像生成AIで作った画像からI2Vをしたり、画像を集めてLoRA学習でも版権キャラクターを生成できる。
LongVideo生成技術
一般にAttention計算はシーケンス長の二乗に比例するため、解像度の高い動画や長い動画の学習は困難である。例えばシーケンス長が2倍になればAttention計算量は4倍、シーケンス長が4倍ならAttention計算量は16倍になる。
バニラのHunyuanVideoは学習が129frameまであり、これ以上の動画はメモリの問題もあるが学習自体が実行されていないため、一般にこれ以上のフレーム数では生成品質も低下する。
Causvid、Self-Forcing、PUSA、lightx2v、FramePackなどの技術を使えばこれらのAttention計算をある程度制限でき、長い動画も学習できる。(ただし、これらの推論のAttention計算の減るコードはあまり公開されてなく蒸留モデルの作成結果しかない)
これらのLongVideo生成技術をWan2.5で実装されていてほしい。(願望)
特にWan2.1の開発時ではLongVideo技術はあまりなく公式でA100での720 T2Vに3300[s]と書かれる効率の悪さだった。
HunyuanVideoでもAttention計算が720P 129frameにおいて計算量86.2%を占める。しかし、長距離VideoToken間のAttention計算を無視しても(STA:Sliding Tile Attention)性能劣化はほとんどないのでこれらは実際には意味のない計算である。シーケンス長115kの場合のAttention計算量を1/10に出来るという事は86.2%のAttention計算量を8.6%に出来るという事で合計計算量は9.2+4.6+8.6=22.4%であるからこのAttention計算の推論のシーケンス長を減らせば生成が4倍効率化できる。

これらLongVideo生成技術はいろんな技術を含む。
Self-ForcingやFramePackのような先頭フレームや直前フレームの推論済みのクリーンlatentを保持する1フレーム推論。

RadialAttentionやSliding Tile AttentionみたいにAttentionMask技術。
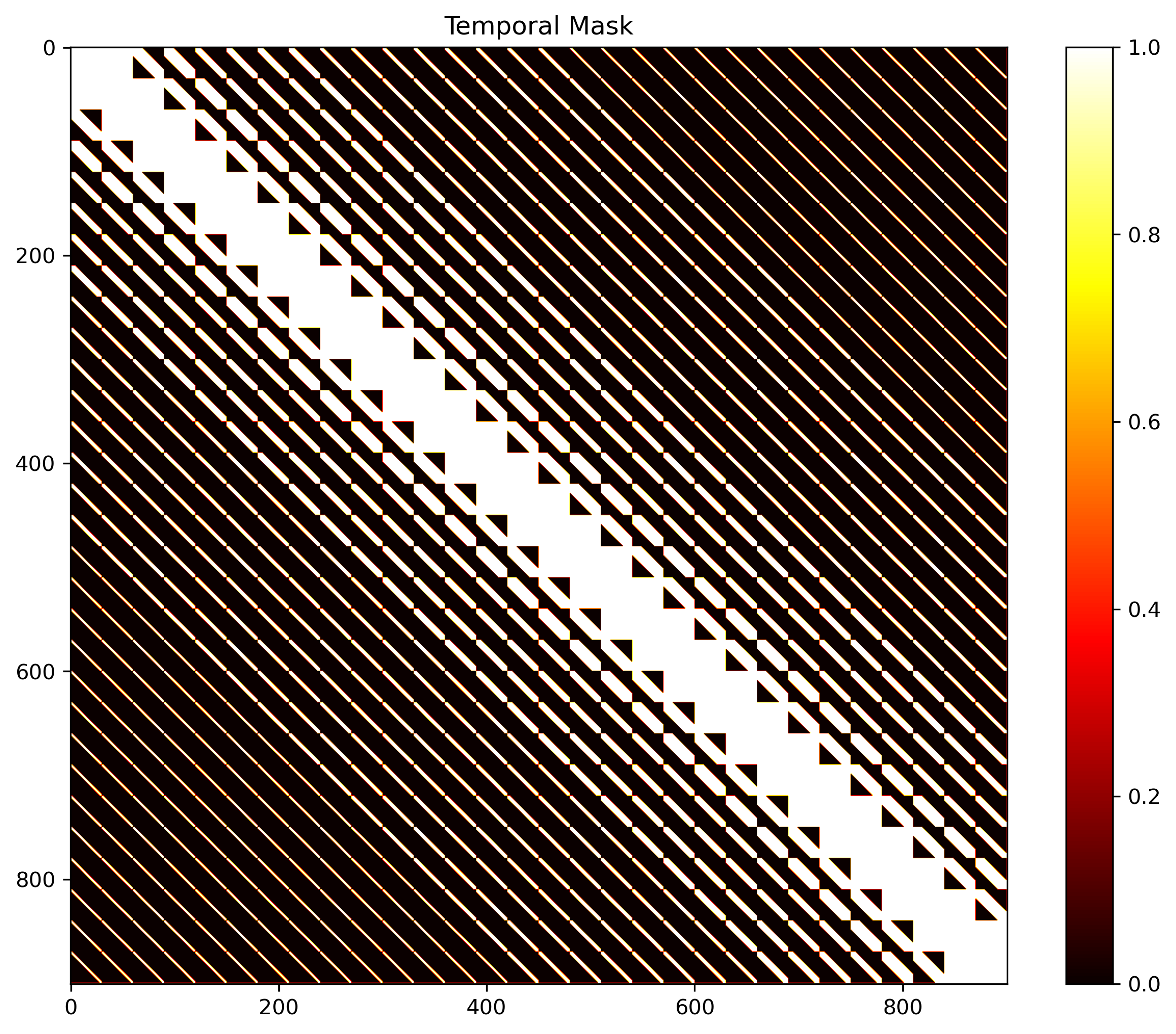
Vectorized timestep adaptation (VTA)では単一のTimestepではなくフレームごとに異なるTimestepを与える技術。など。

音の生成(T2VS)
音声付きの動画を作成するタスク。
Sora2やVeo3.1などで音声付き動画が作れるようになったから、Wan2.5にも採用されている。
しかし、その場合はCrossDiTではVideo Tokenしか生成できないから、DoubleStreamBlockまたはTripleStreamBlockにして、video token、audio token、text tokenの三つをSelf-AttentionかCross-Attentionで混合しつつ入力のnoise tokenをデノイズするモデルが必要であろう。
一方でWan2.2 S2Vとの違いを述べておきたい。
音声付き動画が作れるという成果物で見ると差はないのだが、S2Vモデルはテキスト条件(Text Condition)のDiTブロック以外に音声条件(Sound Condition)のDiTブロックを追加する。
要するにテキストから音声を生成する機能はなく、音声は別のTTS(Text to Speech)モデルなどを使ってあらかじめ用意しないといけない。
またTTSモデルにはサンプル音声を与えて、このサンプル音声から埋め込みを生成することで読み上げる音声をサンプル音声の声色に近づけるタスクもある(voice cloning)。これはI2Vがキャラクターを学習してなくても参照画像があればキャラクターが動く動画を作れるのと同じである。
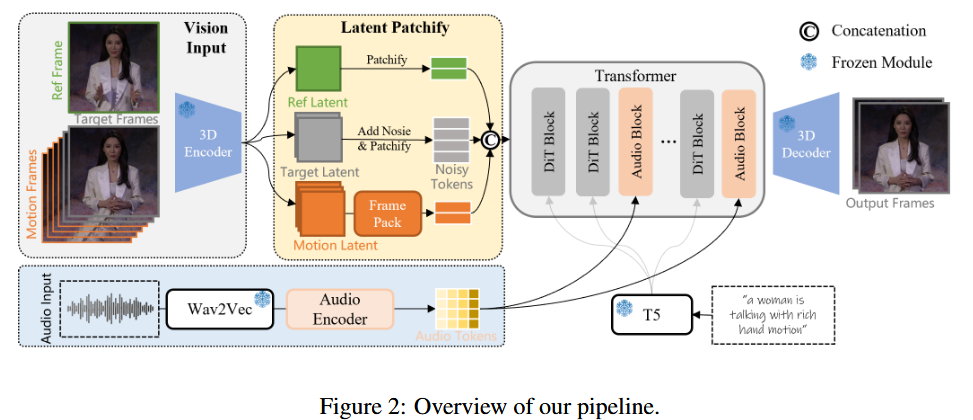
またS2Vのタスクは参照画像の必要なI2Vの派生であり、リップシンク(画像を音声に合わせて動かす)というタスクであるともいえる。
要するに音声付きの動画を生成するタスクにおいて三通りの可能性があり、
・テキスト→TTSモデル→音声、テキストと音声(と画像)→Wan2.5→音声付き動画
・テキスト(と画像)→Wan2.5→無音動画、無音動画→TTSモデル→音声付き動画
・テキスト(と画像)→Wan2.5→音声付き動画
のようにWan2.5自身が音声を作るのか、別途外部TTSモデルが存在するのかは不明である。
以下の記事を見るとWan2.5はリップシンク機能があるだけでTTS機能はないのかもしれない。
Qwenモデル
Wanの開発元であるAlibabaの出しているQwenモデルには通常のLLMやVLM以外にもいくつかある。これらについて考えてみたい。
Qwen2.5-Omini、Qwen3-Omini
これはテキスト、画像、音声のマルチモーダルLLMである。
DiTにて音声をAudio Encoderで変換して直接DiTに注入するのではなく、audioを理解するマルチモーダルLLMをTextEncoderと考えた方が事前にText TokenやImage TokenとSound Tokenの相関を得やすいのではないかという話。
古くはQwen-Audioというモデルが存在したが、現在は見られない。
Qwen/Qwen3-Omni-30B-A3B-Captionerのパラメータ数とアクティブパラメータ数の割合を見るとこれはqwen3-vl 30B-A3Bと同じである。また、このモデルは音声Caption(音声書き起こし)も可能なので、音声Caption性能の改善も期待できる。
さらに、このモデルが前述のTTS(Text to Speech)モデルとして活用されている可能性もある。
このモデルで生成した音声をもとにWanで動画を生成するか、Wanで作った無音動画をもとにこのモデルで音声を生成するのかは分からないが。
ただし、Qwen3-Ominiの発表が2025/09/22なのでWan2.5(2025/09/24)とは何の関係もない可能性もある。(Qwen2.5-Ominiが2025の3~4月)
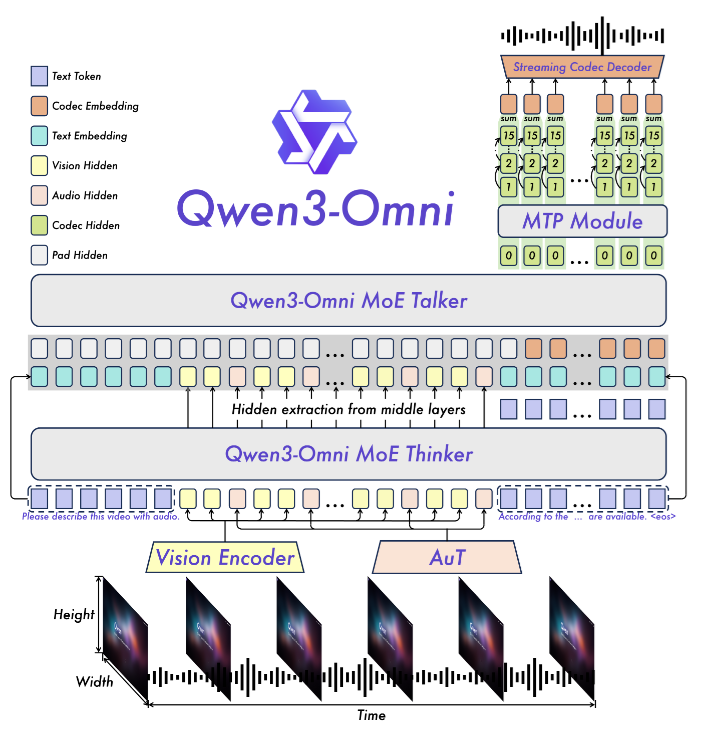
Qwen3-TTS-Flash
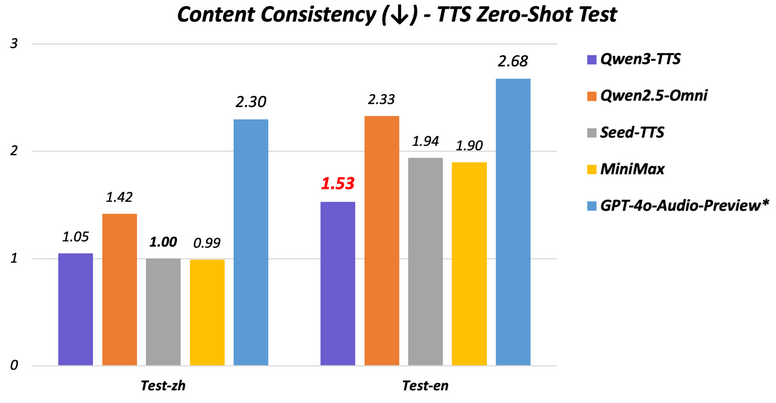
また、Qwen3の直接的なTTS(Text to Speech)モデルもある。
これらが拡散モデル(何回も推論する)か回帰モデル(一回で推論できる)かは分からない。
TTS能力はQwen2.5-Omniより上のようである。
(Qwen3-Omniとどちらが上かは不明、FlashとついているのでQwen3-Omniより軽量なのかもしれない)
Qwen2.5-Max
「Qwen2.5-Max 動画生成」で検索してみるとこのモデルが画像生成、動画生成出来るという話が見られる。本当だろうか?外部APIを利用できるだけで、単に動画生成の中身はWan2.1のAPIかもしれない。
これはChatGPT(4o Image Generation、Dalle3)やGemini(Nanobanana)やGrok(Flux.1、Aurora)がAPIを使用して画像生成できると言うのと同じであろう。
Qwen3-Max
1兆パラメータ越えという記載が見えるのでパラメータは1000B以上である。
いまのところ(2025/11現在)VLMモデルのQwen3-VL-Maxは見当たらない。
Qwen-VL-Maxは存在するが、Qwen2.5-VL-Maxは存在しないので、Qwen3-VL-Maxが出るかは怪しいと思われる。
このため、このQwen3-MaxがWanに出来ることはあまりないが、あえて挙げるならWan2.1におけるPrompt Extention(prompt拡張)であろうか。Wan2.1時代はT2Vのprompt拡張にqwen-plus、I2Vのprompt拡張にqwen-vl-maxの使用がみられるのでテキストを拡張して長いpromptに変換すると生成動画の質が改善する。
Wan2.1
Use the qwen-plus model for text-to-video tasks and qwen-vl-max for image-to-video tasks.
まとめ
Wan2.5の改善箇所に対してどのような可能性があり得るかというのを考えてみた。
この記事を書いている時点ではWan2.5のモデル重みは公開されておらず、技術報告もないため詳細は不明である。