レシートをスキャンして,内容を読み取ります。今回はScanSnapを利用するのでJPEG画像ですが,PDFの場合はpdftoppmを使えば良い。
以下は,最新の機能を使っているので,プロデル1.8系では動作しません。1.9系をお使い下さい。
今回は以下の2つのレシートを読み取ります。日付と合計額を読み取ります。


方針
- レシート画像を1行ずつ切り分ける
- 切り分けた画像に対してOCR処理を行う
- 日付と合計額が書かれている部分を抜き出す
レシート画像を1行ずつ切り分けてOCR
プロデルのOCRは,レイアウト情報を保存しません。行毎に出力されるわけでもありません。したがって,先に画像を加工しておく必要があります。また,文字の周りに十分な余白がないと認識しません。
ファイル名は,「xxx.jpg」
’準備
レシート画像は,画像(ファイル名)を作ったもの。
画素配列は,レシート画像を配列化したもの。
横幅は,画素配列(1)の個数。
白い画像は,{}。
白い行は,{}。
横幅回繰り返せ
白い点は,色情報を作ったもの。
白い点の要素は,{255,255,255}。
白い行へ白い点を追加する。
繰り返し終わり
30回繰り返せ
白い画像へ白い行を追加する。
繰り返し終わり
’OCR開始
行区切りは,1。
読み取りテキストは,{}。
画素配列の個数回,行番号へカウントしながら繰り返せ
白い画素数は,0。
行画素は,画素配列(行番号)。
行画素を【画素:色情報】へそれぞれ繰り返せ
各色合計は,画素の赤+画素の緑+画素の青。
もし各色合計>600なら
白い画素数へ1を足す。
もし終わり
繰り返し終わり
もし白い画素数>横幅×0.98なら
もし行番号-行区切りが8以上なら
開始番号は,行区切り-1。
もし開始番号が0以下なら開始番号は,1。
切り出し画像は,{}。
切り出し画像へ白い画像を一括追加する。
切り出し画像へ画素配列の開始番号番目から(行番号-開始番号+1+1)個切り出したものを一括追加する。
切り出し画像へ白い画像を一括追加する。
切り出し画像を画像に変換して「temp.jpg」へ保存する。
一行テキストは,OCRで「temp.jpg」を読み取ったもの。
もし一行テキストが「」でないなら
一行テキストを読み取りテキストへ加える。
もし終わり
行区切りは,行番号。
もし終わり
もし終わり
繰り返し終わり
準備のところで作っている白い画像は,余白です。切り出した画像の上下に貼り付けます。
行の切れ目の判定は,白い画素が98%を超えているかどうかで行います。
白い画素かどうかは,RGBの値の合計が600/765より大きいかどうかで判定します。
レシートは傾いておらず,行の切れ目はきれいに白くなっていることを前提としています。
切り出した画像はtemp.jpgに保存し,そのファイル名をOCRに渡しています。
もし行番号-行区切りが8以上ならの部分は,文字の入っていない(最低でも縦8ピクセルはないと文字は入っていないと判断)部分にOCRをかけるのは時間の無駄であるために用意しています。
また,白くない部分の上下1ピクセルも切り出し画像に含めています。
読み取る文字がなかった場合,「」が返ってきますので,この場合の結果は捨てます。
日付と合計額の抽出
正規表現で抽出します。
’後処理
日付は,「」。
金額は,「」。
読み取りテキストを一行テキストへそれぞれ繰り返せ
一行テキストは,正規表現で一行テキストを「「[\s ,,]+」」から「」へ置換したもの。
’日付?
日付候補は,一行テキストから「「[0-90-9]+年[0-90-9]+月[0-90-9]+日」」という正規表現で取り出したもの。
もし日付候補の個数が1なら,日付は,日付候補(1)。
’金額
金額表現候補は,一行テキストから「「合計|合言十|合十」」という正規表現で取り出したもの。
金額候補は,一行テキストから「「\d+」」という正規表現で取り出したもの。
もし金額表現候補の個数が1かつ金額候補の個数が1なら
金額は,金額候補(1)。
もし終わり
繰り返し終わり
日付を報告する。
金額を報告する。
実行
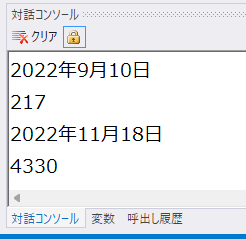
読めました!!