前提・背景
この記事はLIFULL Advent Calendar 2021の4日目の記事です。
社内での告知をサボってたら投稿が集まらずに困ってるので、これを見ている社員は登録お願いしますw
有料集客チームでは効果測定の問題がずっとつきまとっていました。というのも、WEBサイトの開発ではA/Bテスト(ランダム化比較試験)で検証できるものが多いのですが、有料集客施策ではそれが広告媒体や運用上の制限でできないことが多いからです。
そのため適切な実験・分析を行う必要があるのですが、それには以下のような問題がありました。
- 正しい手順で行うのが難しい
- 工数がかかる
- 専門性を持ったアナリストに属人化してしまう
そのためのプロダクトを実装した…という話なのですが、現状ではほとんど使われなくなってしまい、反省点の多いプロジェクトだったと感じています。また、この記事では因果推論モデル自体の説明はほぼしないため、モデル部分で一緒に実装したアナリスト @neuman71 さんの記事「因果推論におけるCausal Impactの立ち位置を俯瞰する」などを見てください。
実装したプロダクト
各媒体から収集したレポートファイル(Excel)に加工し、Webの画面からアップロードすると統計(因果推論)モデルを実行できる環境を整備しました。以下のようなシンプルなUIで、マーケッターは以下の手順で効果検証を行えるように自動化しました。
- 利用したいモデルを決める
- 決められた手順で実験を実施して必要なデータを集める
- データを決められた形式のExcelレポートに加工する
- Excelレポートを選択してアップロードする
- ファイルをUI上からダウンロードできる
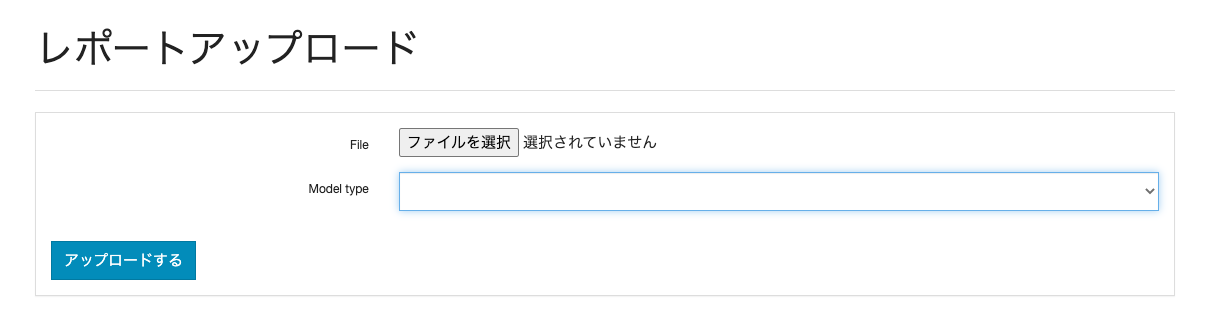
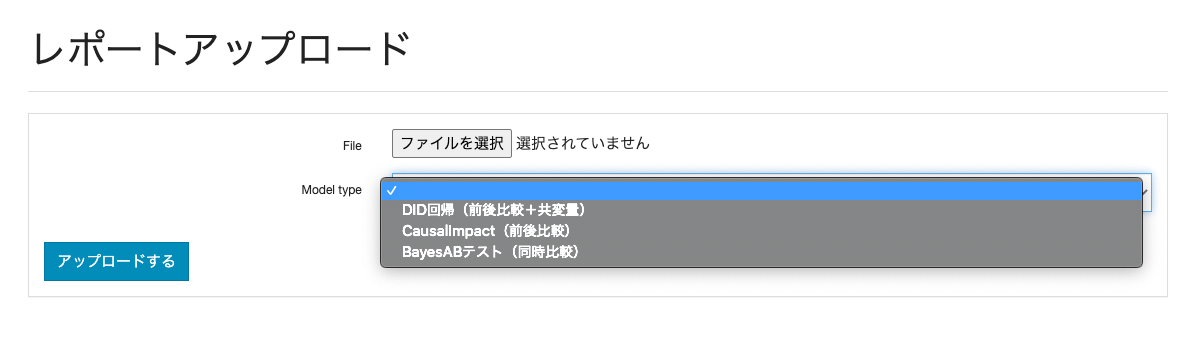
モデルは以下の3つが選択できるようになっています。
- Bayes ABテスト
- DID回帰
- CausalImpact
システム面では、S3にファイルがアップロードされたときに、AWS Lambda上の統計コードを起動するようなシンプルな設計です。統計ライブラリは容量がかかるものが多いので、ストレージとしてEFSを利用しています。
結果と展望
当時社内での発表資料には次のように書いていました。
当初挙がっていた問題点は以下のように解消した。
- かつては施策の効果検証を各マーケターが独自の観点でまとめることが多く、人によりばらつきが生じていたが、共通の方法で実施できるようになった
- 効果検証に多くの時間がかかっていたが、データいれればでてくる状態になり、工数が削減された
- プロダクトの検証と同時に、過去の検証の正当性も検証できた
- グラフによる可視化も行われるので分かりやすい
以下のような課題が残っている。
- マーケッター側の運用に入れるために、仕組み化と啓蒙活動が必要
- モデルの使い分けなどで知識が必要で、マニュアル整備をしたい
- 目的変数がCTVR回帰なので、より成果指標に近いROAS回帰できるようにしたい
- マーケットごとに対応の余地あり(戸建は見学予約=10unitsとしての扱いだが現在はまるっとunits数として計算&結果がでてくるため、資料請求が多かった/見学予約が多かったなどの判断ができない)
- コードの作りが粗雑なままで、エラー内容(カラム名の間違いなど)の確認にエンジニアの手が必要
- CausalImpactのモデル改善で、処理がタイムアウトするようになってしまった
ところが、残念なことに、現状ではほとんど実運用者に使われていません。その原因は2点あるんじゃないかと思っています。
- そもそも、マーケターが各施策の振り返りを行うチェックポイントが無い。直近の運用に追われてしまっていることが多い
- 各モデルの前提条件や実験計画が難しく、工数よりそちらの設定のほうが難しい
①施策の振り返りのチェックポイントが無い
前者はまずは業務分析をしっかり行って負荷工数を削減する必要があります。マーケターも含めて整備しようと考えているのですが、マーケター間でも業務の標準化ができていないなどの課題がありそうです。
②各モデルの前提条件や実験計画が難しい
このアプリケーションのマニュアルの一部がこちらなのですが、端的に言って難しく、統計学(因果推論)に明るい人でないと使いこなせないものになってしまっていたと思います。例えば、3種類のモデルを選ぶ際の「平行トレンド仮説の確認」や「ベイズCI値」などの確認方法や意思決定方法が難しいです。
- ABテスト(ランダム化同時比較):
- 満たすべき前提条件が多い:共変量が全て等しい(例えば、ImpressionsやCost、ターゲティング設定などもABで全て等しい状況で使える実験、後工程は平均値の差分を見るだけ)
- 因果推論が信頼できない=ベイズCI値が小さかったとき:サンプルサイズを増やす
- 比較群あり前後比較(DID回帰モデル):
- 適切な比較群を見つけることがそもそもかなり難しい:平行トレンド仮説 を満たしているかを、ROAS_ts.png(Cost_ts.png)を確認する必要がある
- 因果推論が信頼できない=P値が大きかったとき:サンプルサイズを増やす
- 比較群なし前後比較(CausalImpact):
- 現状1年以上あるデータにしか対応できない:CIは比較対象ではなく、過去の自分(1年前1ヶ月前、曜日影響)からテスト期間の反実仮想値を予測(nseasons=7に変更すれば1年なくても使える)
- 因果推論が信頼できない=P値が大きかったとき:サンプルサイズ(データの期間)を増やす
そのため、これらのフローを自動化するアプリケーションを整備するより、実験計画まで突っ込んでコンサルティングしてくれるようアナリストに協力を体制を作るべきだろうと考えています。
最後に
今後はこの反省を活かして、業務フロー全体を見渡すことを優先し、ボトルネック工程から重点的に対処するようにしていきたいと考えています。
また、実は弊チームはボスを募集しているので、こういうMarketingOps的な内容に詳しいマネージャーがいたらぜひ応募していただけたら嬉しいです🙇