はじめに
この記事は、社内の勉強会「R言語を使った統計入門」の発表資料です
株式会社ネクストにはネクスト大学という制度があり、職種や部門を越えてお互いに教え合う文化を醸成しています(社外への宣伝)
自己紹介
二宮健
-
デジタルマーケティングUのエンジニア
- MAM(有料集客の管理ツール)の開発
- 具体的にはデータ集計バッチとか広告のAPIとか
-
Rを使って×専門的な分析 ○データの検証や集計
参考書籍
- この発表は1章の内容に対応しますが、Rに特有の詰まりどころや便利な機能も紹介します
- 特に「この本を使って統計・データ解析を勉強する際に、スムーズに始めるためのプログラミングの前提知識」を共有するつもりです
今回覚えて帰ってほしいこと
- 他のデータ分析ツールと比較したRの特徴
- Rによるプログラミングの基礎
今回話をしないこと
- 統計学やデータ分析について(次回やります)
- 最低限の話しかしないので、もし実際にRを使って分析したい場合、その都度勉強が必要です
数値計算用ツールのRの紹介
はじめまして、R
Rとは,オープンソースの言語処理系である。対話形式で使われることが多い。
特に統計・データ解析,統計グラフ作成に強い。
(『Rで楽しむ統計』P.1より)
※オープンソースとは「誰でもソースコードを見られるソフトウェア」のことだと考えてください
R以外のツールやプログラミング言語
数値計算
- Python + pydataのライブラリ: Rとほぼ同等の機能、実運用までOK
- Matlab: 大学や研究機関でよく使われる(ただし高額)
- Julia: RやPythonのいいとこ取りした新興勢力
データ分析
Rの良いところ・悪いところ
良いところ
- 慣れれば、データ分析中に高速で試行錯誤できる
- 最新の統計手法のパッケージが揃っている
- データ処理・集計のベストプラクティスがまとまっている(例: 整然データ)
悪いところ
- 落とし穴が多い(古い仕様が残っている)
- 他のプログラミング言語に比べると、実行が遅い
こんなあなたにはR
○ユーザー行動を可視化したい
Excelでもがんばればできるけど、Rのほうができることの幅が広くなる
(より専門的な作業が早くできる)
△新しい機械学習の機能を実装したい
エンジニアのあなたにはPython!
ただし、このゼミで学ぶことはpandasで活かせます
Rを使った例
社内用の資料で説明します
インストール方法
※今回はサーバーにあるRStudioを利用するのでインストール不要です
普段のPCで利用したい方は、三重大学の奥村研のページにある手順でインストールしてください
Excelと比較したデータ集計
ハンズオンの前に、Excelと比較しながらRでのデータ集計(のイメージ)を軽く説明します
Excelで分析しているとき、「表形式のデータ」をよく扱いますよね?
※ アヤメ(花)のサンプルデータのirisデータを使って説明します

Rには「表形式のデータ」を扱うための「データフレーム」というデータ構造があります
> #データフレームであることを確認
> class(iris)
[1] "data.frame"
>
> # 中身を確認(headは冒頭6行を取り出す関数)
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
列の合計値を計算したい
Excelなら

Rなら
> # "$"で列を取り出す
> iris$Sepal.Length
[1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1 5.7 5.1 5.4 5.1 4.6 5.1 4.8
(以下略)
>
> # 合計値を出す
> sum(iris$Sepal.Length)
[1] 876.5
分布を知りたい
がく片の長さ(Sepal.Length)の分布を知りたい(どれくらいの長さが多いのか調べたい)
Excelなら平均値を計算する
Rならグラフ(ヒストグラム)を描く
> # Sepal.Lengthのヒストグラムを描く
> hist(iris$Sepal.Length)
こんなグラフが描けます

○○ごとの平均値を計算したい
がく片の長さ(Sepal.Length)の平均値をアヤメの種類(Species)ごとに計算したい

Excelなら、ピボットテーブルを使います

Rならこう書けます
> # 集計用のパッケージ
> library(dplyr)
>
> # SpeciesごとにSepal.Lengthの平均(mean)を集計する
> iris %>%
+ group_by(Species) %>%
+ summarise(mean = mean(Sepal.Length))
# A tibble: 3 × 2
Species mean
<fctr> <dbl>
1 setosa 5.006
2 versicolor 5.936
3 virginica 6.588
※ 「これくらい簡単に集計できる」という例のため、暗記する必要はありません
データフレームを集計するためのdplyrパッケージの詳しい使い方が気になる方は@matsuou1さんの『dplyrを使いこなす!基礎編』を見てください
ここまででイメージを持ってもらいたいこと
Rには次の2つの強みがあります
- Rでは「データフレーム」を操作してデータを集計する
- 他のプログラミング言語よりも簡単
- Excelでは「表形式のデータ」以外でも入力できてしまうので、手順化(≒プログラム化)しづらいこともある
- 簡単にグラフが描ける
- グラフを見ながら仮説検証できる
- 高速なPDCAが可能!
Rによるプログラミングの基礎
ここから実際にプログラムを実行しながら学んでいきましょう
簡単な計算
四則演算(+-÷×)ができます
> 123 + 456
[1] 579
>
> # 円周率のπ
> pi
[1] 3.141593
>
> 2 * pi
[1] 6.283185
変数の代入
何度も使う変数には、名前を付けましょう
> # C言語のようにこう書けますが、
> x = 12345
>
> # デジタルマーケティングUではこう書くよう決めています
> #(コーディング規約)
> x <- 12345
> x
[1] 12345
>
> x + 1
[1] 12346
>
> # 大文字と小文字は区別されるので大文字のXに代入しても
> X <- 10
> # 小文字のxの値は元のままです
> x
[1] 12346
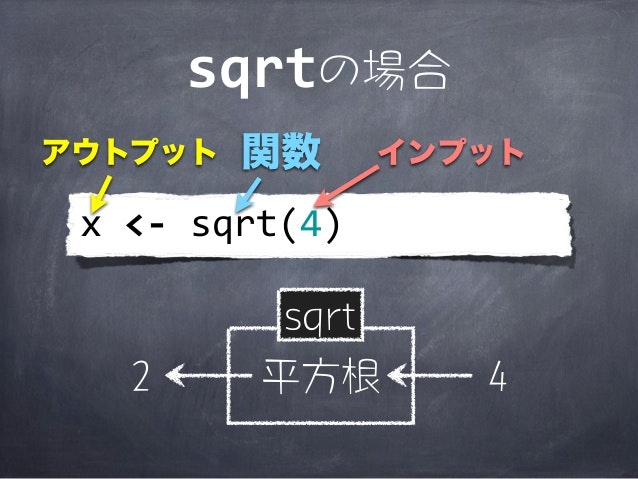
関数
関数とは「何らかのインプットに対して処理を加えアウトプットを返すもの」です
> # 値を丸める
> floor(1.9)
[1] 1
>
> # 平方根√2
> x <- sqrt(2)
> x
[1] 1.414214
出典: はじめての「R」
出典: はじめての「R」
関数は自分で定義することもできます
> # xとyを足し算する
> plus <- function(x, y) {
+ return (x + y)
+ }
>
> plus(1, 2)
[1] 3
> plus(3, 4)
[1] 7
ベクトル
他のプログラミング言語での「配列」に似たものです
ベクトルはcという関数を使って定義します
> c(1, 2, 3, 4, 5)
[1] 1 2 3 4 5
> # 整数の順列はこうも書けます
> 1:5
[1] 1 2 3 4 5
ベクトルに対する四則演算は、全体に作用します
> x <- c(3.14, 2.718, 0.577)
> x + 10
[1] 13.140 12.718 10.577
関数も多くの場合はベクトル全体に作用します
これにより、他の多くのプログラミング言語よりも計算をシンプルに書けます
> # √2 平方根
> sqrt(2)
[1] 1.414214
> sqrt(1:5)
[1] 1.000000 1.414214 1.732051 2.000000 2.236068
そのため、Rでは繰り返し文(for)はあまり使いません
> # こんな風にはふつうは書きません
> x <- c(3.14, 2.718, 0.577)
> result <- c()
> for(i in x) {
+ result <- c(result, i + 10)
+ }
> result
[1] 13.140 12.718 10.577
>
> # こう書きます
> result <- x + 10
[1] 13.140 12.718 10.577
リスト
Rには、ベクトルの他に「複数の値を持つ」ための仕組みがもう一つあります
リストでは他の種類の型(整数、文字列)が混ぜられます
> list(1, "a", 3.14)
[[1]]
[1] 1
[[2]]
[1] "a"
[[3]]
[1] 3.14
>
> # ベクトルでは他のデータ型は混ぜられません
> # (文字列と数値を混ぜると、全部文字列型に変換されます)
> c(1, "a", 3.14)
[1] "1" "a" "3.14"
リストは次のように使います
> # リストを代入する
> x <- list(1, 2, 3)
>
> # 1番目の要素を取り出す(※[[0]]でないことに注意!)
> x[[1]]
[1] 1
リストに対する四則演算は、ベクトルと違い全体に作用しません(エラーが出ます)
> x <- list(1, 2, 3)
> # 間違ったプログラム!
> x + 1
Error in x + 1 : non-numeric argument to binary operator
>
> # リスト全体に足し算したいときは、汎関数(高階関数)のlapplyを使う必要があります
> # 最初に覚える必要はないですし、この場合はベクトルを使ったほうが自然です
> plus10 <- function(x) { x + 10 }
> lapply(list(1, 2, 3), plus10)
[[1]]
[1] 11
[[2]]
[1] 12
[[3]]
[1] 13
リストには名前も付けられ、これを「名前付きリスト」と呼ぶこともあります
(むしろ、名前付きリストのほうがよく使われます)
PHPやRubyの「連想配列」や「ハッシュテーブル」のような使い方ができます
> ninomiya <- list(名字 = "二宮", 名前 = "健", ユニット = "デジタルマーケティングU")
> ninomiya
$名字
[1] "二宮"
$名前
[1] "健"
$ユニット
[1] "デジタルマーケティングU"
> # 名字を取り出す
> ninomiya$名字
[1] "二宮"
データフレーム
先ほども出ましたが「表形式のデータ」を表現するためのデータ構造です
データフレームの実体は「同じ長さのベクトル」が入った「リスト」です
> 身長 <- c(168.5, 172.8, 159.0)
> 体重 <- c(69.5, 75.0, 56.5)
> X <- data.frame(身長, 体重)
> X
身長 体重
1 168.5 69.5
2 172.8 75.0
3 159.0 56.5
>
> # リストと同様、$で値を取り出します
> X$身長
[1] 168.5 172.8 159.0
> # 取り出した値はベクトルなので、演算を要素全体に適用できます
> X$身長 / 100
[1] 1.685 1.728 1.590
後から行を追加することもできます
> # 行を追加する
> X$性別 <- c("M", "M", "F")
> X
身長 体重 性別
1 168.5 69.5 M
2 172.8 75.0 M
3 159.0 56.5 F
>
> X$BMI <- round(X$体重 / (X$身長 / 100) ^ 2)
> X
身長 体重 性別 BMI
1 168.5 69.5 M 24
2 172.8 75.0 M 25
3 159.0 56.5 F 22
ファイルを読み込む
大きなデータは画面からタイプするのは大変です
Rでは、csvやExcelファイルを読み込むこともできます
> # 参考(今回のハンズオン用のサーバーにはcsvを置いていないのでエラーが出ます)
> X <- read.csv("D:/work/X.csv", stringsAsFactors = FALSE)
より詳しくは、『Rで楽しむ統計』のP.7~を読んでください
図を描く
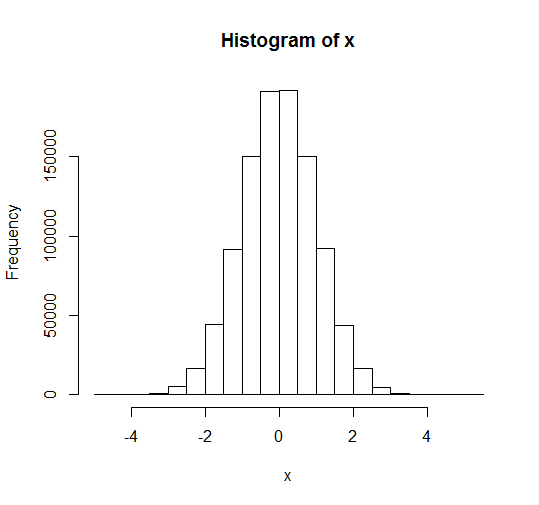
Rには「グラフを簡単に描ける」という特徴的な機能があります
ヒストグラム(度数分布表)を描いてみましょう
> # 正規分布の乱数を100万個作る
> x <- rnorm(1000000)
> # ヒストグラムを描く
> hist(x)
パッケージのインストール
Rは外部パッケージをインストールすることで機能を拡張することができます
「世界中の統計学者が作成した統計モデルを簡単に使える」ことが、Rを使う最大のメリットです
> # install.packageでインストールできます
> # ハンズオンでは元々インストールされています
> install.packages("readxl")
>
> # インストール後はlibrary関数でインポートできる
> library(readxl)
まとめ
ここまでできれば、『Rで楽しむ統計』でRを使いながらデータ分析を試せるようになっているはずです
今回覚えて帰ってほしいこと
- 他のデータ分析ツールと比較したRの特徴
- データ分析で試行錯誤するためのツール
- 世界中の統計学者が作ったモデルを利用できる
- Rによるプログラミングの基礎
- 変数や関数
- リストとベクトルの使い方
- 表形式のデータをデータフレームで表現する
参考資料
- Rで楽しむ統計 奥村晴彦 (著), 石田基広 (監修)
-
はじめての「R」
- 「Rを使いたい人」のタイプ別の丁寧な導入
-
ふつうのスクリプト言語プログラマーのためのR言語入門
- 他言語(Ruby)のプログラマーが違和感を持ちやすい部分や、Rでのプログラミングを楽にするパッケージの紹介
参加していただきありがとうございますm(_ _)m