はじめに
4月ということで、新卒が入ってきたりRを使ったことないメンバーがJOINしたりしたので、
超便利なdplyrの使い方を何回かに分けてまとめて行きます。
Rは知らないけど、SQLとか他のプログラミング言語はある程度やったことあるみたいな人向けです。
dplyrを使いこなす!シリーズ
基礎編以外も書きましたので、↓からどうぞ。
dplyrとは
データフレームの操作に特化したパッケージです。
Rは基本的に処理速度はあまり早くないですが、dplyrはC++で書かれているのでかなり高速に動作します。
ソースの可読性もよくなるので、宗教上の理由で禁止されている人以外は使うメリットは大きいです。
処理可能なデータサイズの目安
あくまでも個人の環境に強く依存した感覚値ですが、1000万行、100MBぐらいのデータサイズであれば、
dplyrでそれ程ストレスなく処理可能です。
それ以上のデータサイズになると、サンプリングするか、Mコマンド等の別の処理方法も検討の土台に乗ってくると思います。
バッチ処理で時間がかかっても問題がない場合であれば、もちろんそれ以上のデータサイズの処理も可能だが、使える物理メモリ次第かも。
例として使っているデータについて
相模原市オープンデータライブラリで公開されている駅別乗降人員の推移を使用しています。
(よく例として使われるirisのデータは、個人的にイメージしづらいので。。。)
列名は、適当に変更しています。
SQLとの対比
処理対象のデータフレームをRDBのテーブルとしてイメージして、SQLと比較するとわかりやすいです。
主要なdplyrの機能とSQLの対比は、下図となります。
| SQL | dplyr | R | 説明 |
|---|---|---|---|
| where | filter | subset | 行の絞り込み |
| count , max ,min等 | summarise | aggregate | 集計する |
| group by | group_by | - | グルーピングする |
| order by | arrange | sort , order | 行を並べ替える |
| select | select | data[,c("a","b")] | データフレームから指定した列のみ抽出する |
| (select句) | mutate | transform | 列の追加 |
dplyrを使った書き方
具体的なdplyrの使い方を見る前に、dplyrを使った処理のお作法的な話を先にしておきます。
dplyrを使う場合、%>%演算子を使って複数の処理を連結し、一連の処理として扱うのが一般的です。
%>%演算子は、演算子の左の値を、演算子の右の値の第1引数として渡します。
linux系のOSをよく使う人は、shellの|(パイプ)をイメージするとわかりやすいかと思います。
# col1が1のデータのみを抽出し、col2で昇順にソートしたdataを返却
data.result <- data %>%
dplyr::filter(col1 == "1") %>%
dplyr::arrange(col2)
# %>%演算子を使わない書き方
## 中間結果を格納する変数が必要だったり、可読性が落ちる。
data.tmp <- dplyr::filter(data , col1 == "1")
data.result <- dplyr::arrange(data.tmp , col2)
それでは、具体的な使い方を見ていきましょう。
行の絞り込み
filter
filter(.data, 条件式)
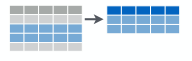
まずは、条件式にマッチした行のみに絞り込むfilter関数です。
SQLではWHERE句、Rではsubset関数が同様の機能を持っています。
イメージは↓な感じです。(チートシートから拝借)
# 町田駅のデータを選択
> sagamihara.station.user %>%
+ dplyr::filter(station == "町田駅(参考)")
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 横浜線 町田駅(参考) 211864 216428 215598 218154 218084 221086 221880
2 小田急線 町田駅(参考) 282772 291952 289622 290621 288884 291678 292779
条件式は複数の条件を指定でき、AND条件(&または,で連結)、OR条件(|で連結)も使用可能です。
# 横浜線の矢部駅のデータを選択( , で連結)
> sagamihara.station.user %>%
+ dplyr::filter(trainline == "横浜線" , station == "矢部駅")
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 横浜線 矢部駅 21220 22648 22348 22356 22646 22960 23594
# 横浜線の矢部駅のデータを選択( & で連結)
> sagamihara.station.user %>%
+ dplyr::filter(trainline == "横浜線" & station == "矢部駅")
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 横浜線 矢部駅 21220 22648 22348 22356 22646 22960 23594
# 横浜線と小田急線のデータを選択( | で連結)
> sagamihara.station.user %>%
+ dplyr::filter(trainline == "横浜線" | trainline == "小田急線")
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 横浜線 橋本駅 104522 118162 118098 120244 120482 122254 125510
2 横浜線 相模原駅 53448 56370 55774 56158 55716 56566 57552
3 横浜線 矢部駅 21220 22648 22348 22356 22646 22960 23594
4 横浜線 淵野辺駅 72368 77154 78518 79600 78700 80870 74276
5 横浜線 古淵駅 39480 42410 42404 42796 42626 43370 44614
6 横浜線 相原駅(参考) 21334 20330 20194 20422 20198 20392 20842
7 横浜線 町田駅(参考) 211864 216428 215598 218154 218084 221086 221880
8 小田急線 相模大野駅 108602 121338 119240 119166 120113 122453 128006
9 小田急線 小田急相模原駅 55944 55754 55392 55034 54366 55530 56767
10 小田急線 東林間駅 22883 22176 21796 21422 21152 21420 21584
11 小田急線 町田駅(参考) 282772 291952 289622 290621 288884 291678 292779
12 小田急線 相武台前駅(参考) 41987 39977 39301 39160 37931 38110 38869
13 小田急線 唐木田(参考) 16037 19994 20539 21228 21096 21330 21719
集計
summarise
summarise(.data, ...)
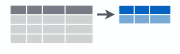
次は、summarise関数です。
主に集計関数と共に使用されて、min、max、mean等の集計を行う際に使用します。
> sagamihara.station.user %>%
+ dplyr::summarise(max=max(year_2013) , min=min(year_2013) , mean=mean(year_2013))
max min mean
1 292779 2252 60886.12
複数の列に別々の集計関数を適用することも出来ます。
> sagamihara.station.user %>%
+ dplyr::summarise(max_2013=max(year_2013) , min_2013=min(year_2013) , mean_2013=mean(year_2013),
+ max_2012=max(year_2012) , min_2012=min(year_2012) , mean_2012=mean(year_2012))
max_2013 min_2013 mean_2013 max_2012 min_2012 mean_2012
1 292779 2252 60886.12 291678 2128 60028.72
summarise_each
summarise_each(tbl, funs, ...)
summarise_eachは、指定した列に複数の関数を適用できます。適用する関数はfuns内で指定します。
summariseの例2のように複数列指定に対し複数関数適用する場合、冗長になるため、summarise_eachを使えば簡潔に書くことが出来ます。
# 2012年、2013年のmax , min , meanを集計
# 列名が元の列名+function名になるところが注意
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min ,mean) , year_2013 , year_2012)
year_2013_max year_2012_max year_2013_min year_2012_min year_2013_mean year_2012_mean
1 292779 291678 2252 2128 60886.12 60028.72
# 2012年のmax , min , meanを集計
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min ,mean) , year_2012)
max min mean
1 291678 2128 60028.72
列の選択する関数
列を選択する必要があるselectやsummarise_each等には、簡単に列を選択できるような関数が用意されています。
列が少ない場合は問題ありませんが、クロス集計した場合等に列名をすべてを正確に把握できない場合や、
列名が非常に多い場合に効果を発揮します。
(使わないで済むうちが幸せかもしれませんね。。。)
| 関数 | 構文 | 説明 |
|---|---|---|
| starts_with | starts_with(x, ignore.case = TRUE) | 列名がxで始まる列を取得。 |
| ends_with | ends_with(x, ignore.case = TRUE) | 列名がxで終わる列を取得 |
| contains | contains(x, ignore.case = TRUE) | 列名にxが含まれる列を取得 |
| matches | matches(x, ignore.case = TRUE) | 正規表現xにマッチする列を取得 |
| num_range | num_range("x", 1:5, width = 2) | 文字列xに連番を組み合わせた列を取得 |
| one_of | one_of("x", "y", "z") | x , y , zに含まれる変数を選択 |
| everything | everything() | すべての列を取得 |
※ ignore.caseは大文字、小文字を区別するかどうか
# 200X年のmaxとminを集計する
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min) , starts_with("year_200"))
year_2003_max year_2008_max year_2009_max year_2003_min year_2008_min year_2009_min
1 282772 291952 289622 1694 2002 1994
# 末尾が3のmaxとminを集計する
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min) , ends_with("3"))
year_2003_max year_2013_max year_2003_min year_2013_min
1 282772 292779 1694 2252
# year_200を含む列を集計する
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min) , contains("year_200"))
year_2003_max year_2008_max year_2009_max year_2003_min year_2008_min year_2009_min
1 282772 291952 289622 1694 2002 1994
# 末尾が010~012で終わる列を集計
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min) , matches("01[0-2]$"))
year_2010_max year_2011_max year_2012_max year_2010_min year_2011_min year_2012_min
1 290621 288884 291678 1968 2016 2128
# year_2010~2012までの列を集計
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max) , num_range("year_" , 2010:2012))
year_2010 year_2011 year_2012
1 290621 288884 291678
# year_2009~year_2011までの列を集計。widthで指定した桁数に足りない場合は、0でpaddingされる。
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max) , num_range("year_20" , 9:11 , width=2))
year_2009 year_2010 year_2011
1 289622 290621 288884
# 2003年と2008年のmaxとminを集計する
> sagamihara.station.user %>%
+ dplyr::summarise_each(funs(max , min) , one_of("year_2003" , "year_2008"))
year_2003_max year_2008_max year_2003_min year_2008_min
1 282772 291952 1694 2002
グループ化
group_by
group_by(.data, ..., add = FALSE)
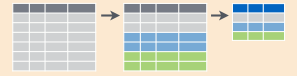
先ほどのsummariseでは、対象のデータフレーム全体に対しminやmax等の関数を適用していましたが、group_byを使用することで、SQLのgroup by句と同様に指定した列のユニークな組み合わせごとに集計することが可能です。
add=Tを指定すると、grouped_dfのグループ情報に新しく追加することができます。
add=Fもしくは、指定しない場合は、grouped_dfのグループ情報が上書きされます。
# 沿線別に集計
> sagamihara.station.user %>%
+ dplyr::group_by(trainline) %>%
+ dplyr::summarise(max=max(year_2013) , min=min(year_2013) , mean=mean(year_2013))
Source: local data frame [5 x 4]
trainline max min mean
1 横浜線 221880 20842 81181.143
2 京王線 91060 18471 54765.500
3 小田急線 292779 21584 93287.333
4 相模線 11600 2252 7197.333
5 中央本線 170382 5144 60361.500
ungroup
データフレームのグループ情報を削除します。と言われても、殆どの人が良くわからないと思います。
グループ情報とか意識していない、もしくは動作が怪しいときにungroupしている人が多いのでは?
これを理解するには、groupとsummariseの関係を見れば、ちょっと見えてきます。
いままでのデータでは、ちょっと説明しづらいのでmtcarsのデータを使います。
# mtcarsのデータをgearとcylでグルーピング後、summariseを実行
> mtcars %>%
+ group_by(gear,cyl) %>%
+ summarise(newvar = sum(wt))
Source: local data frame [8 x 3]
Groups: gear
gear cyl newvar
1 3 4 2.465
2 3 6 6.675
3 3 8 49.249
4 4 4 19.025
5 4 6 12.375
6 5 4 3.653
7 5 6 2.770
8 5 8 6.740
ここで、Groupsの情報を見てみると、gearだけ残っています。
ポイントは、summariseを行うと最後のグループ情報が削除されます。
gearとcylを逆に指定した場合を見てみましょう。
> mtcars %>%
+ group_by(cyl , gear) %>%
+ summarise(newvar = sum(wt))
Source: local data frame [8 x 3]
Groups: cyl
cyl gear newvar
1 4 3 2.465
2 4 4 19.025
3 4 5 3.653
4 6 3 6.675
5 6 4 12.375
6 6 5 2.770
7 8 3 49.249
8 8 5 6.740
同じように最後に指定したグループ情報が削除されています。
意図した操作にならないケースは、複数のグループ情報を指定した場合にグループ情報が残ることを忘れている場合に発生します。
> mtcars %>%
+ group_by(gear , cyl) %>%
+ summarise(newvar = sum(wt)) %>%
+ arrange(cyl)
Source: local data frame [8 x 3]
Groups: gear
gear cyl newvar
1 3 4 2.465
2 3 6 6.675
3 3 8 49.249
4 4 4 19.025
5 4 6 12.375
6 5 4 3.653
7 5 6 2.770
8 5 8 6.740
> mtcars %>%
+ group_by(gear,cyl) %>%
+ summarise(newvar = sum(wt)) %>%
+ ungroup() %>%
+ arrange(cyl)
Source: local data frame [8 x 3]
gear cyl newvar
1 3 4 2.465
2 4 4 19.025
3 5 4 3.653
4 3 6 6.675
5 4 6 12.375
6 5 6 2.770
7 3 8 49.249
8 5 8 6.740
慣れてきたときにハマりやすいので、グループ情報についてはきちんと意識して使うようにしましょう。
(私も何度がよくわからずに、ungroup使ったりしてました。。。)
ソート
arrange
arrange(.data, ...)
データフレームを指定した列でソートする。 SQLでいうと、order by句。
デフォルトは昇順で、desc(column)の場合は、降順でソートします。
# 2013年の利用者数が少ない順
> sagamihara.station.user %>%
+ dplyr::arrange(year_2013) %>% head(5)
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 相模線 下溝駅 1694 2002 1994 1968 2016 2128 2252
2 相模線 相武台下駅 1856 2510 2404 2184 2070 2282 2406
3 中央本線 相模湖駅 6744 6914 6904 6746 6586 5118 5144
4 中央本線 藤野駅 5898 5892 5742 5550 5382 5310 5352
5 相模線 番田駅 5484 5980 6076 6388 6384 6630 7076
# 2013年の利用者数が多い順
> sagamihara.station.user %>%
+ dplyr::arrange(desc(year_2013)) %>% head(5)
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 小田急線 町田駅(参考) 282772 291952 289622 290621 288884 291678 292779
2 横浜線 町田駅(参考) 211864 216428 215598 218154 218084 221086 221880
3 中央本線 八王子駅(参考) 162546 164788 160546 160438 162948 165042 170382
4 小田急線 相模大野駅 108602 121338 119240 119166 120113 122453 128006
5 横浜線 橋本駅 104522 118162 118098 120244 120482 122254 125510
# 各沿線毎に利用者数が多い順
> sagamihara.station.user %>%
+ dplyr::arrange(trainline , desc(year_2013))
trainline station year_2003 year_2008 year_2009 year_2010 year_2011 year_2012 year_2013
1 横浜線 町田駅(参考) 211864 216428 215598 218154 218084 221086 221880
2 横浜線 橋本駅 104522 118162 118098 120244 120482 122254 125510
3 横浜線 淵野辺駅 72368 77154 78518 79600 78700 80870 74276
4 横浜線 相模原駅 53448 56370 55774 56158 55716 56566 57552
5 横浜線 古淵駅 39480 42410 42404 42796 42626 43370 44614
6 横浜線 矢部駅 21220 22648 22348 22356 22646 22960 23594
7 横浜線 相原駅(参考) 21334 20330 20194 20422 20198 20392 20842
8 京王線 橋本駅(京王) 78072 88320 88427 88065 87242 88377 91060
9 京王線 多摩境駅(参考) 10727 16526 16678 17183 17184 17582 18471
# 以下略
列操作
select
select(.data, ...)
列を選択します。
列の選択には、summarise_eachのところで解説した列選択の関数を使用できます。
> sagamihara.station.user %>%
+ dplyr::select(trainline , station , year_2003) %>% head(3)
trainline station year_2003
1 横浜線 橋本駅 104522
2 横浜線 相模原駅 53448
3 横浜線 矢部駅 21220
> sagamihara.station.user %>%
+ dplyr::select(starts_with("year_200")) %>% head(3)
year_2003 year_2008 year_2009
1 104522 118162 118098
2 53448 56370 55774
3 21220 22648 22348
rename
rename(.data, ...)
列名を変更します。
> sagamihara.station.user %>%
+ dplyr::select(trainline , station , year_2003) %>%
+ dplyr::rename(new_column=year_2003) %>% head(3)
trainline station new_column
1 横浜線 橋本駅 104522
2 横浜線 相模原駅 53448
3 横浜線 矢部駅 21220
# 複数列の名前変更や列名に日本語を使うことも可能
> sagamihara.station.user %>%
+ dplyr::select(trainline , station , year_2003 , year_2009) %>%
+ dplyr::rename(2003年=year_2003 , 2009年=year_2009) %>% head(3)
trainline station 2003年 2009年
1 横浜線 橋本駅 104522 118098
2 横浜線 相模原駅 53448 55774
3 横浜線 矢部駅 21220 22348
mutate
mutate(.data, ...)
新しく列を追加します。
> sagamihara.station.user %>%
+ dplyr::select(trainline , station , year_2008 , year_2009) %>%
+ dplyr::mutate(new_column=(year_2008 + year_2009) / 2 ) %>% head(3)
trainline station year_2008 year_2009 new_column
1 横浜線 橋本駅 118162 118098 118130
2 横浜線 相模原駅 56370 55774 56072
3 横浜線 矢部駅 22648 22348 22498
ifelseを使うことで、条件によって値を変更することも可能です。
# 2008年の乗降数が1万人以上の場合は1、それ以下の場合は0の列を追加
> sagamihara.station.user %>%
+ dplyr::select(trainline , station , year_2008 ) %>%
+ dplyr::mutate(new_column=ifelse(year_2008 > 10000 , 1 , 0) ) %>% head(15)
trainline station year_2008 new_column
1 横浜線 橋本駅 118162 1
2 横浜線 相模原駅 56370 1
3 横浜線 矢部駅 22648 1
4 横浜線 淵野辺駅 77154 1
5 横浜線 古淵駅 42410 1
6 横浜線 相原駅(参考) 20330 1
7 横浜線 町田駅(参考) 216428 1
8 相模線 南橋本駅 10886 1
9 相模線 上溝駅 11456 1
10 相模線 番田駅 5980 0
11 相模線 原当麻駅 8282 0
12 相模線 下溝駅 2002 0
13 相模線 相武台下駅 2510 0
14 中央本線 相模湖駅 6914 0
15 中央本線 藤野駅 5892 0
まとめ
基礎編は以上となります。ここで紹介した分だけでもきちんと使いこなせればdplyrを使う前よりも前処理や集計処理が格段に楽になると思います。
SQLがわかる人にとっては、イメージしやすいので使いこなすまでには、それ程時間はかからないので、まずは使ってみましょう!
ここで紹介した機能だけでも、豊富な機能がたくさんあるのですが、dplyrには、まだまだ紹介しきれていない機能がたくさんあるので、あと何回かに分けて紹介していきたいと思います。