はじめに
dplyrの使い方にちょっと慣れてくると、「あー、これもうちょっと簡単にできないの?」みたいな事が出てきたりします。
今回は、そんな悩みをほんのちょっと解決できるかもしれない、Window関数について解説したいと思います。
SQLに詳しい人はすぐイメージできると思いますが、私の周りにもWindow関数の存在自体を知らない人が結構居たのでいい機会なので、ざっくりまとめます。
dplyrってなんぞやという方は、基礎編の記事を見ていただければと。
Window関数を使うと簡単にできることの例
とは言っても、具体的に何ができるのか、分からなかったら読むのもメンドクサイので、まずは簡単にできることを紹介します。
- ランキング(タイ順位考慮あり、なし等含む)
- 前日比、前週比(前後のレコードとの比較等)
- 累積(累積和等)
- 移動平均(Windowサイズの指定、Windowの位置、重み等)
どれも自分でやれなくはないけど、結構メンドクサイですよね。。
でも、Window関数を使えるようになると、dplyrの一連の処理の流れの中に数行で組み込めるので、簡単だし、コードも見やすくなり、そして、何より、仕事が捗ってる感を得ることができます。(初回限定)
集約関数とWindow関数の違い
まずは、いつも使っている集約関数とWindow関数の違いについて、整理します。
集約関数
集約関数は、複数の入力レコードに対し、1つのレコードを出力します。
count、sum、mean、max、min等がその代表です。
Window関数
対して、Window関数は、複数の入力レコードに対し、レコード毎に1つのレコードを出力します。
ランキングや累積和をイメージすると、分かりやすいかと思います。
という感じなので、集約関数の場合は、group_byして、summarise内で使う場合がほとんどだと思いますが、
Window関数は、新しい列を追加するケースが多いので、mutate内で使用することになります。
(慣れてくれば、filter内で使うことも増えてくるかもしれません。)
それでは、具体的に見ていきましょう。
ランキング関数
最初は、比較的イメージしやすいランキング関数から。
ランキング系の関数には、以下の6つの関数があります。
主なランキング関数
| 関数 | 説明 |
|---|---|
| row_number | 昇順にランキングを付ける。同じ値がある場合は、最初に来た方を優先 |
| min_rank | 昇順にランキングを付ける。同じ値がある場合は、同じ順位を付ける。gapあり |
| dense_rank | 昇順にランキングを付ける。同じ値がある場合は、同じ順位を付ける。gapなし |
| percent_rank | min_rankを0~1にリスケールしたもの |
| cume_dist | 累積割合。percent_rankの累積和ではない。 |
| ntile | n個の群に分割する |
ランキング関数構文
> row_number
function (x)
> min_rank
function (x)
> dense_rank
function (x)
> percent_rank
function (x)
> cume_dist
function (x)
> ntile
function (x, n)
例1:ランキング関数(昇順)
data.frame(x = c(5 , 1 , 3 , 2 , 2 , NA)) %>%
dplyr::mutate(row_number=row_number(x)) %>%
dplyr::mutate(min_rank=min_rank(x)) %>%
dplyr::mutate(dense_rank=dense_rank(x)) %>%
dplyr::mutate(percent_rank=percent_rank(x)) %>%
dplyr::mutate(cume_dist=cume_dist(x)) %>%
dplyr::mutate(ntile=ntile(x , 3))
x row_number min_rank dense_rank percent_rank cume_dist ntile
1 5 5 5 4 1.00 1.0 3
2 1 1 1 1 0.00 0.2 1
3 3 4 4 3 0.75 0.8 2
4 2 2 2 2 0.25 0.6 1
5 2 3 2 2 0.25 0.6 2
6 NA NA NA NA NA NA NA
min_rank(gapあり)、denserank(gapなし)は、タイ順位があった場合にその次の順位を飛ばすか、飛ばさないかの差です。
上記例で言えば、1,2,2,4となるか、1,2,2,3となるかの違いですね。
cume_distは、上位5%とか出したいときや、全体の90%を占めるラインは何処かを求める際に使うイメージです。
percent_rankの累積ではないので、勘違いしないようにしましょう。
入力値がNAの場合は、どの関数もランキングせずに、NAを返します。
例2:ランキング関数(降順)
# 降順
# スコアの高い順でランキングしたい場合等は、desc関数を使用すればよい
> data.frame(x = c(5 , 1 , 3 , 2 , 2 , NA)) %>%
dplyr::mutate(row_number=row_number(desc(x))) %>%
dplyr::mutate(min_rank=min_rank(desc(x))) %>%
dplyr::mutate(dense_rank=dense_rank(desc(x))) %>%
dplyr::mutate(percent_rank=percent_rank(desc(x))) %>%
dplyr::mutate(cume_dist=cume_dist(desc(x))) %>%
dplyr::mutate(ntile=ntile(desc(x) , 3))
x row_number min_rank dense_rank percent_rank cume_dist ntile
1 5 1 1 1 0.00 0.2 1
2 1 5 5 4 1.00 1.0 3
3 3 2 2 2 0.25 0.4 1
4 2 3 3 3 0.50 0.8 2
5 2 4 3 3 0.50 0.8 2
6 NA NA NA NA NA NA NA
スコアの高い順にランキングしたい場合は、desc関数を使用します。
Offsets(lead , lag)
lead 、lag関数を使用すると、前後のレコードの値を取得でき、前日比、前週比等の値が簡単に出せるようになります。
lead、lagの説明
| 関数 | 説明 |
|---|---|
| lead | xを前方にnだけずらして、後方をdefaultで埋める |
| lag | xを後方にnだけずらして、前方をdefaultで埋める |
lead、lagの構文
> lead
function (x, n = 1L, default = NA, order_by = NULL, ...)
> lag
function (x, n = 1L, default = NA, order_by = NULL, ...)
例1:標準的な使い方
# 1つづつ前後にずらす
data.frame(x = c(1, 2, 3, 4, 5)) %>%
dplyr::mutate(lead=lead(x)) %>%
dplyr::mutate(lag=lag(x))
x lead lag
1 1 2 NA
2 2 3 1
3 3 4 2
4 4 5 3
5 5 NA 4
例2:nオプションを使用して、2つづつずらす
複数ずらすことも可能です。n=7にすると前週比とか簡単に出せるようになります。
# 前後に2つづつずらす
data.frame(x = c(1, 2, 3, 4, 5)) %>%
dplyr::mutate(lead=lead(x , n=2)) %>%
dplyr::mutate(lag=lag(x , n=2))
x lead lag
1 1 3 NA
2 2 4 NA
3 3 5 1
4 4 NA 2
5 5 NA 3
例3:defaultオプションを使用して、0で埋める
ずらして欠損値となる部分に埋める値を指定できます。
# 値がないところを、0埋め
data_frame(x = c(1:5)) %>%
dplyr::mutate(lead=lead(x , default=0, n=2 )) %>%
dplyr::mutate(lag=lag(x , default=0 , n=2))
x lead lag
1 1 3 0
2 2 4 0
3 3 5 1
4 4 0 2
5 5 0 3
例4:order_byオプションを使用して、ソート列を指定する
order_byで、ソート列を指定できます。逆順にする場合は、descを使用します。
# yの値でランキング
data_frame(x = c(1 , 2, 3, 4, 5), y=c(5,4,2,1,3)) %>%
dplyr::mutate(lead=lead(x , default=0, order_by=y)) %>%
dplyr::mutate(lag=lag(x , default=0 , order_by=y))
x y lead lag
1 1 5 0 2
2 2 4 1 5
3 3 2 5 4
4 4 1 3 0
5 5 3 2 3
例5:group_by
group_byを使用すると、グループ内でのoffsetが可能です。
data_frame(x = c(1 , 2, 3, 4, 5) , y=c("aa" ,"aa" , "aa" , "bb" , "bb")) %>%
dplyr::group_by(y) %>%
dplyr::mutate(lead=lead(x , default=0)) %>%
dplyr::mutate(lag=lag(x , default=0))
x y lead lag
1 1 aa 2 0
2 2 aa 3 1
3 3 aa 0 2
4 4 bb 5 0
5 5 bb 0 4
累積関数
各項目の累積に対して、集約関数をかけます。
言葉で書くよりも、図で書いた方が分かりやすいので、例にイメージ図を書いてみました。
主な累積関数
| 関数 | 説明 |
|---|---|
| cumsum | 部分和 |
| cummin | 部分min |
| cummax | 部分max |
| cummean | 部分平均 |
| cumall | 部分all |
| cumany | 部分any |
累積関数の構文
> cumsum
function (x)
> cummin
function (x)
> cummax
function (x)
> cummean
function (x)
> cumall
function (x)
> cumany
function (x)
例1:cumsum、cummin、cummax、cummean
累積に対して、集約関数をかけるイメージ
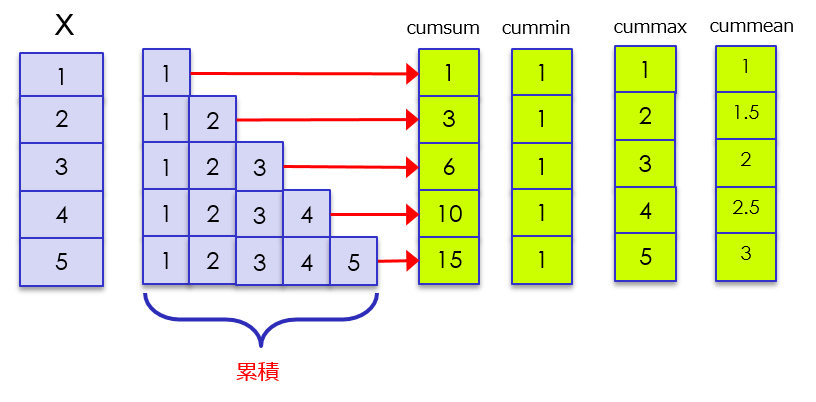
data_frame(x = c(1,2,3,4,5)) %>%
dplyr::mutate(cumsum=cumsum(x)) %>%
dplyr::mutate(cummin=cummin(x)) %>%
dplyr::mutate(cummax=cummax(x)) %>%
dplyr::mutate(cummean=cummean(x))
x cumsum cummin cummax cummean
1 1 1 1 1 1.0
2 2 3 1 2 1.5
3 3 6 1 3 2.0
4 4 10 1 4 2.5
5 5 15 1 5 3.0
例2:cumall、cumany
cumallは、累積のすべてがTRUEの場合にTRUE
cumanyは、累積のいずれか一つがTRUEの場合にTRUE
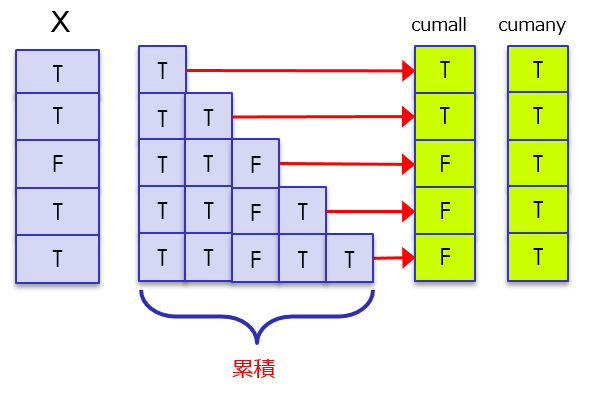
data_frame(x = c(TRUE , TRUE , FALSE ,TRUE , TRUE)) %>%
dplyr::mutate(cumall=cumall(x)) %>%
dplyr::mutate(cumany=cumany(x))
x cumall cumany
1 TRUE TRUE TRUE
2 TRUE TRUE TRUE
3 FALSE FALSE TRUE
4 TRUE FALSE TRUE
5 TRUE FALSE TRUE
ローリング関数
RcppRollを用いることで、指定ウィンドウサイズ内で集約関数を使用することができます。
移動平均等も簡単に出せるので、便利です。
ローリング関数を使用するには、RcppRollパッケージのインストールが必要です。
install.packages("RcppRoll")
library(RcppRoll)
ローリング関数も、文字で説明してもなかなかイメージしづらいので、イメージ図を作成しました。
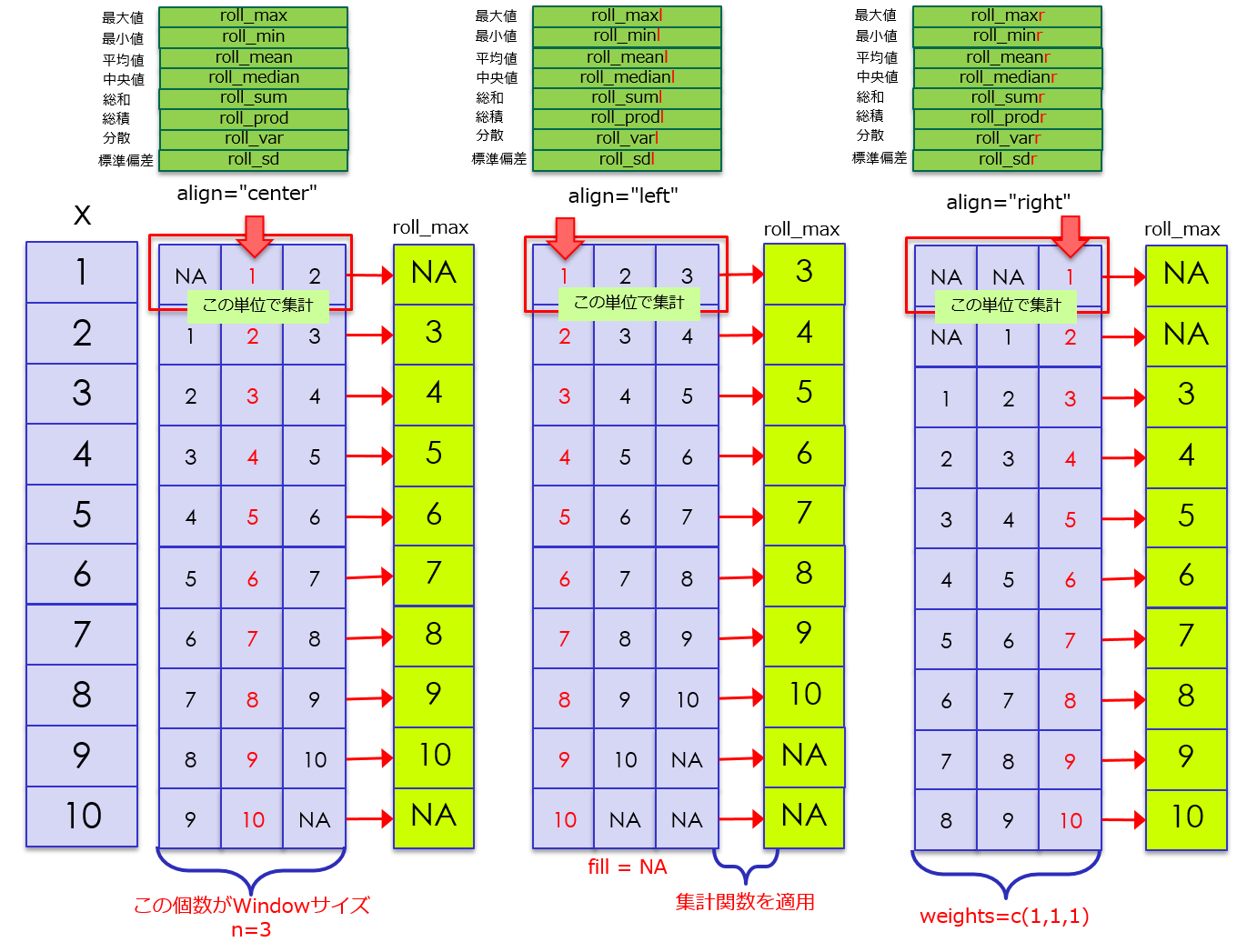
主なローリング関数
| 関数 | 説明 |
|---|---|
| roll_max | 指定ウィンドウサイズ内の最大値を取得 |
| roll_min | 指定ウィンドウサイズ内の最小値を取得 |
| roll_mean | 指定ウィンドウサイズ内の平均値を取得 |
| roll_median | 指定ウィンドウサイズ内の中央値を取得 |
| roll_sum | 指定ウィンドウサイズ内の合計を取得 |
| roll_prod | 指定ウィンドウサイズ内の総積を取得 |
| roll_var | 指定ウィンドウサイズ内の分散を取得 |
| roll_sd | 指定ウィンドウサイズ内の標準偏差を取得 |
主なローリング関数の構文
> roll_max
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_min
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_mean
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_median
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_sum
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_prod
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_var
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
> roll_sd
function (x, n = 1L, weights = NULL, by = 1L, fill = numeric(0),
partial = FALSE, align = c("center", "left", "right"), normalize = TRUE,
na.rm = FALSE)
主なオプションの説明
| オプション | 説明 |
|---|---|
| n | ウィンドウサイズ |
| weights | ウィンドサイズと同じ長さのベクトルで、各要素の重みを指定します。 |
| fill | 欠損値を何で埋めるかを指定します。 |
| align | ウインドウの位置を指定します。"left"、"center"、"right"が指定できます。 |
| normalize | 重みをNormalizeするかどうかを指定します。 |
| na.rm | NAを削除するかどうかを指定します。 |
例1:alignの違い
# Windowサイズn=3で、最大のものを取得する例
# nが1か全体でなければ、fillの指定が必要
# align="center" : n=3の場合、該当行、およびその前後の1行を使用し、最大値を出す
# align="left" : n=3の場合、該当行、およびその後ろ2行を使用し、最大値を出す
# roll_maxl関数は、roll_max(x , align="left")と同様
# align="right" : n=3の場合、該当行、およびその前2行を使用し、最大値を出す
# roll_maxr関数は、roll_max(x , align="right")と同様
data_frame(x = c(1:10) ) %>%
dplyr::mutate(roll_max_center= roll_max(x , n=3 ,align="center" , fill=NA)) %>%
dplyr::mutate(roll_max_left = roll_max(x , n=3 ,align="left" , fill=NA)) %>%
dplyr::mutate(roll_max_right = roll_max(x , n=3 ,align="right" , fill=NA))
x roll_max_center roll_max_left roll_max_right
1 1 NA 3 NA
2 2 3 4 NA
3 3 4 5 3
4 4 5 6 4
5 5 6 7 5
6 6 7 8 6
7 7 8 9 7
8 8 9 10 8
9 9 10 NA 9
10 10 NA NA 10
例2:重み付き移動平均
weightsオプションで重みを指定することができます。
# weightsには、ウィンドウサイズnを同じ長さのベクトルを指定します。
data_frame(x = c(1:10) ) %>%
dplyr::mutate(roll_mean=roll_mean(x , n=3 ,fill=NA)) %>%
dplyr::mutate(roll_mean112=roll_mean(x , n=3 , weights=c(1,1,2) ,fill=NA)) %>%
dplyr::mutate(roll_mean211=roll_mean(x , n=3 , weights=c(2,1,1) ,fill=NA)) %>%
dplyr::mutate(roll_mean121=roll_mean(x , n=3 , weights=c(1,2,1) ,fill=NA))
x roll_mean roll_mean112 roll_mean211 roll_mean121
1 1 NA NA NA NA
2 2 2 2.25 1.75 2
3 3 3 3.25 2.75 3
4 4 4 4.25 3.75 4
5 5 5 5.25 4.75 5
6 6 6 6.25 5.75 6
7 7 7 7.25 6.75 7
8 8 8 8.25 7.75 8
9 9 9 9.25 8.75 9
10 10 NA NA NA NA
例3:fillオプション指定
欠損値が出る場合、fillで指定した値が使用されます。
data_frame(x = c(1:10) ) %>%
dplyr::mutate(roll_mean1=roll_mean(x , n=3 , fill=0)) %>%
dplyr::mutate(roll_mean2=roll_mean(x , n=3 , fill=-1)) %>%
dplyr::mutate(roll_mean3=roll_mean(x , n=3 , fill=NA))
x roll_mean1 roll_mean2 roll_mean3
1 1 0 -1 NA
2 2 2 2 2
3 3 3 3 3
4 4 4 4 4
5 5 5 5 5
6 6 6 6 6
7 7 7 7 7
8 8 8 8 8
9 9 9 9 9
10 10 0 -1 NA
Window関数をfilterに使用する
これまでは、主に列を追加する際にWindow関数を使用していましたが、filter関数にも使用することができます。
例1:yでグルーピングしてmin_rankが1のもののみ抽出
data_frame(x = c(1 , 2, 3, 4, 5) , y=c("aa" ,"aa" , "aa" , "bb" , "bb")) %>%
dplyr::group_by(y) %>%
dplyr::filter(min_rank(x) == 1)
x y
1 1 aa
2 4 bb
例2:累積和が5を超えるもののみ抽出
data_frame(x = c(1,2,3,4,5)) %>%
dplyr::filter(cumsum(x)>5)
x
1 3
2 4
3 5
まとめ
Window関数編は以上になります。
分かりにくいところもあるので、今回は具体的なイメージ図を入れてみました。
使いこなせると、普段の集計には殆ど困ることは無くなると思いますので、是非、使いこなせるようになりましょう!
これだけ解説しても、まだまだ機能が残ってるdplyr、恐るべし・・・。
きっとあと1回か、2回ぐらい続きます。