ユースケース概要
-
ビジネス内容
国際通信事業者の調査および分析チームとして、公開されている米国運輸省(USDOT)の空港交通データを使用してレポートを作成するためのデータパイプラインを作成する必要があります。航空会社の幹部は、USDOTレポートおよびビジネスアナリストが作成した追加資産を通じて、この情報を間接的に消費しています。
私たちの使命は、国際便のレポートシステムを駆動するデータパイプラインを作成することです。データパイプラインへの変更を含むレポートシステムは、分析チームの支援を受けてビジネスアナリストによって維持されます。多くの場合、アナリストは、より大きなデータセットを使用してそれらをより小さな次元に縮小するようなパイプラインを動かします。私たちのチームの目標は、より速く、より効率的に、再現可能な方法で彼らを支援することです。 -
使用するデータ
データは、米国国際航空旅客および貨物統計レポートから取得します。T-100プログラムの一環として、USDOTは、米国の空港との間で運行している米国および国際航空会社の交通レポートを受け取ります。チームのデータエンジニアは、この公開データを取り込み、次のデータセットを提供します。
- 出発:出発地と目的地に関係なく、米国のゲートウェイと米国以外のゲートウェイ間のすべてのフライトのデータ。
- 各観測では、空港のペア(1つは米国、もう1つは外国)と特定の航空会社に関する情報が提供されます。3つの主要な列は、フライトの数を記録します(スケジュール済み、チャーター、合計)。
- 乗客:特定の航空会社がサービスを提供する、空港のペア間の月および年ごとの乗客総数に関するデータ。
- 番号は、定期便の便数とチャーター便の便数によっても分類されます。
それでは、2017年のデータから操作を始めていきましょう!
3. 今回作成するワークフロー
最終的に作成するパイプラインは以下の通りで、次ような比較的高度な内容を含みます。
1. データセットをダウンロードして入力データを取得する。
2. 乗客データセットをクリーンアップし、空港IDでグループ化し、その年の乗客数で最も混雑している空港を見つける。
3. 出発データセットをクリーンアップし、空港ペアの毎月の情報を市場シェアデータに変換する。
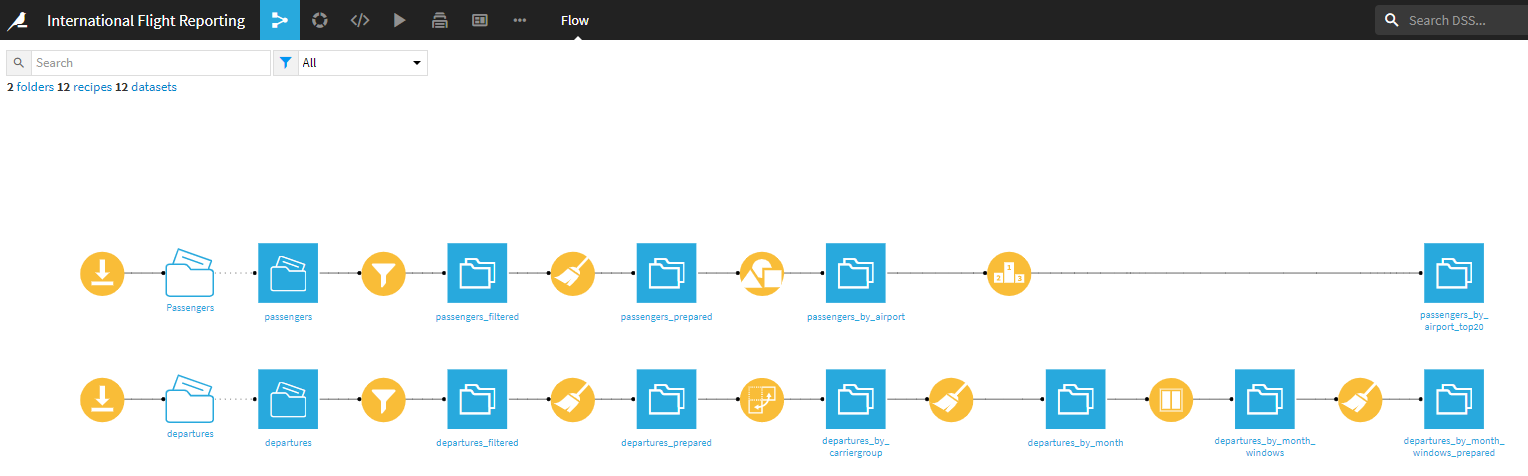
Dataiku galleryで、完成したプロジェクトを確認できるので、そちらも参考にできます。
4. 前提条件
Basics Tutorialに加えて、Data Pipelines tutorialの実施が推奨されています。このユースケースでは、Pivot、Windowレシピも扱います。
ユースケース内容
1. 国際線旅客機で最も混雑する空港を見つける。
プロジェクト作成
新しい空のDataikuプロジェクト(プロジェクト名:International Flight Reporting)を作成します。
データインポート
次に、以下のようにDownloadレシピを使って、今回使用するデータをインポートします。
1. フロー画面の+RecipeからDownloadレシピを開く。
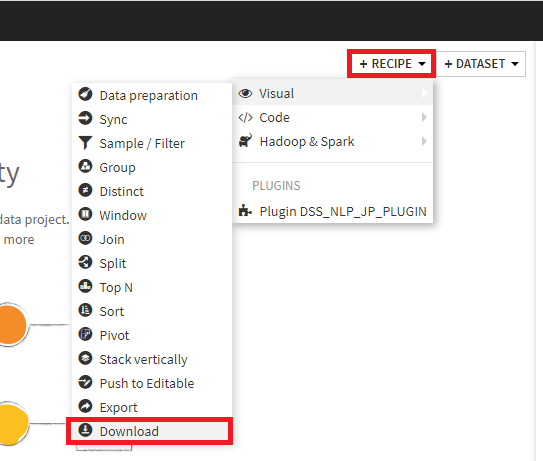
2. 出力フォルダ名をPassengersとし、Createボタンを押下。
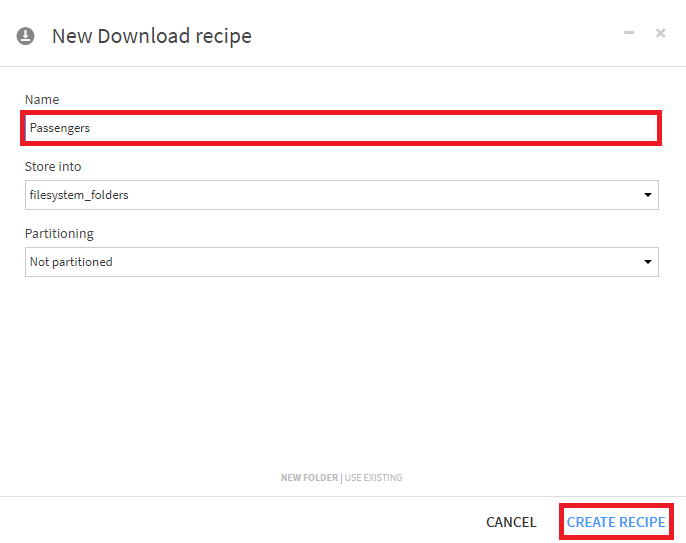
3. + Add a First Sourceを選択。
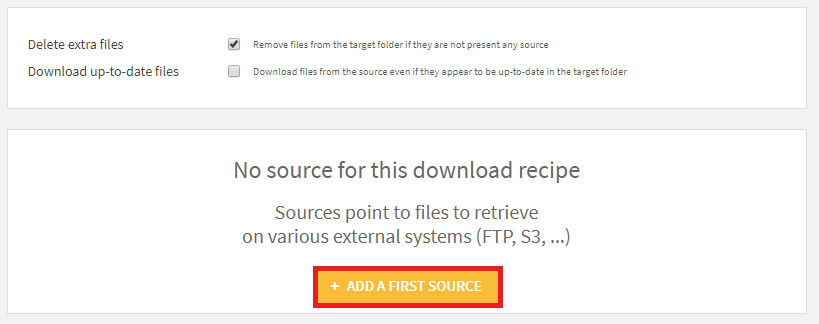
4. URLに https://data.transportation.gov/api/views/xgub-n9bw/rows.csv?accessType=DOWNLOAD を指定し、RUNボタンを押下。
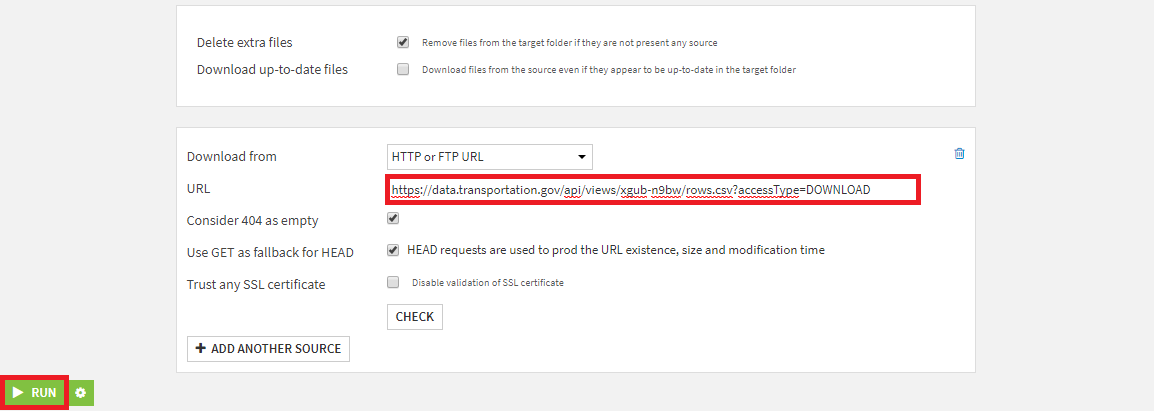
データ読み込み
生データをダウンロードしたら、Dataiku DSSに読み込みます。
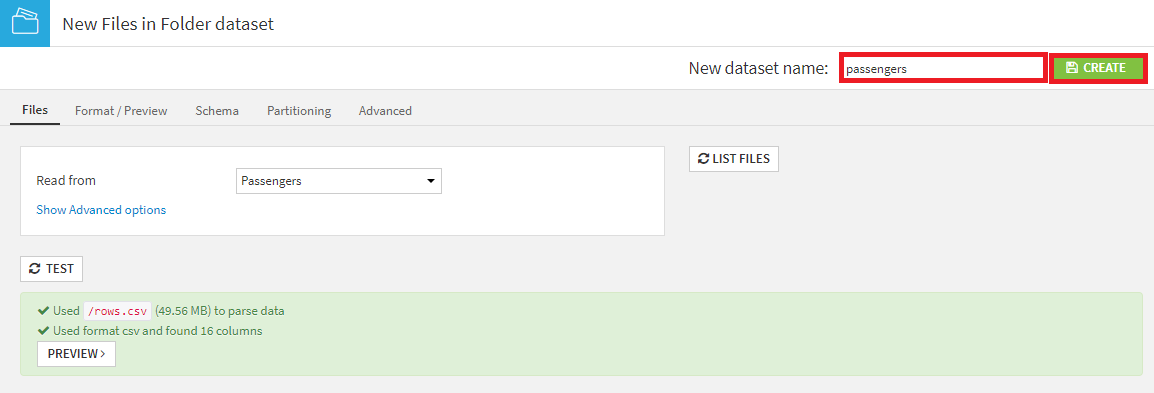
1. Passengersフォルダを選択。
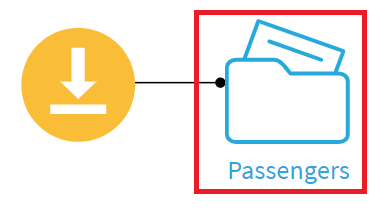
2. ACTIONSメニューのCreate a datasetを選択。
3. TESTを押下し、ファイルフォーマットを検出し、データを解析。
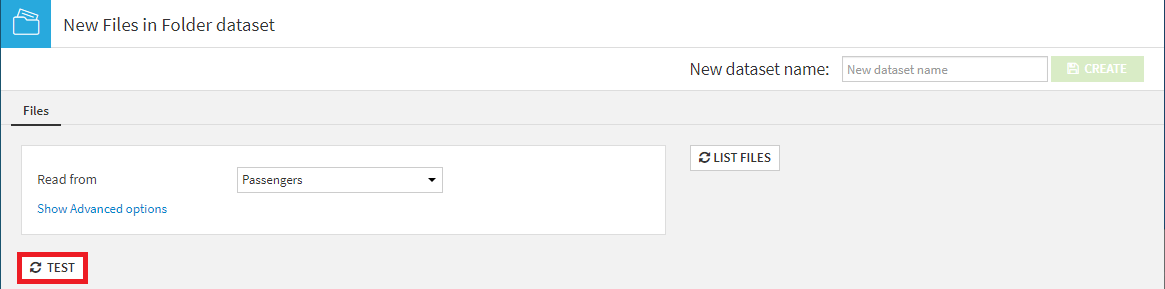

4. New dataset nameをpassengersへ修正し、CREATEを押下。
データ加工(1)
次に、目的に合わせてデータをフィルタリングします。
- 新しいデータセットを入力として、新しいSample/Filterレシピを作成。
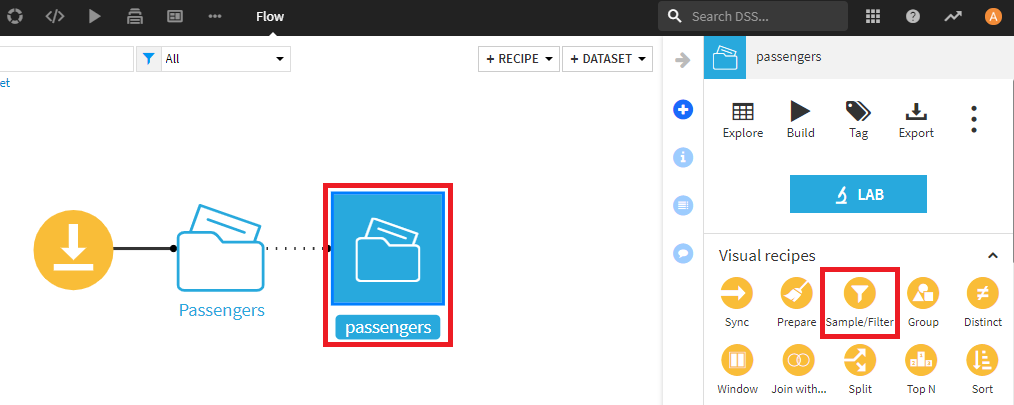
- Filterをオンにして、Year=2017の行のみを保持するよう設定。
- Sampling methodでNo sampling(whole data)を選択し、RUNを押下。
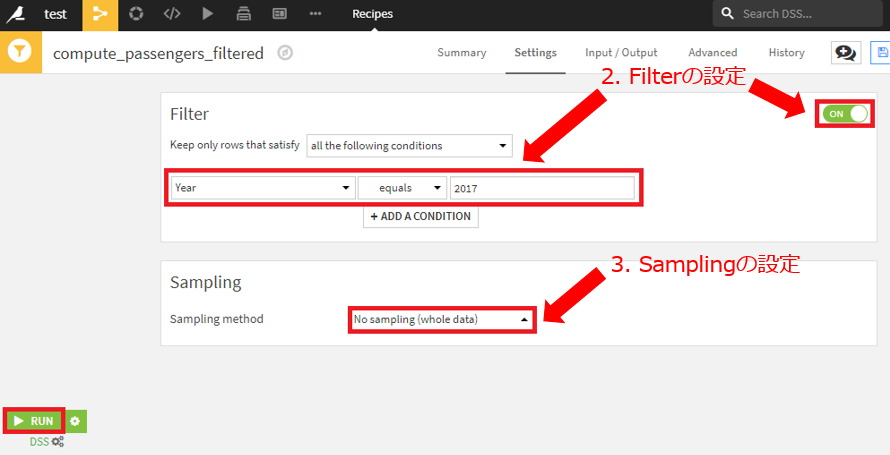
新規作成したデータセットに対して、データクレンジングを行います。Prepareレシピで以下の操作を行います。
-
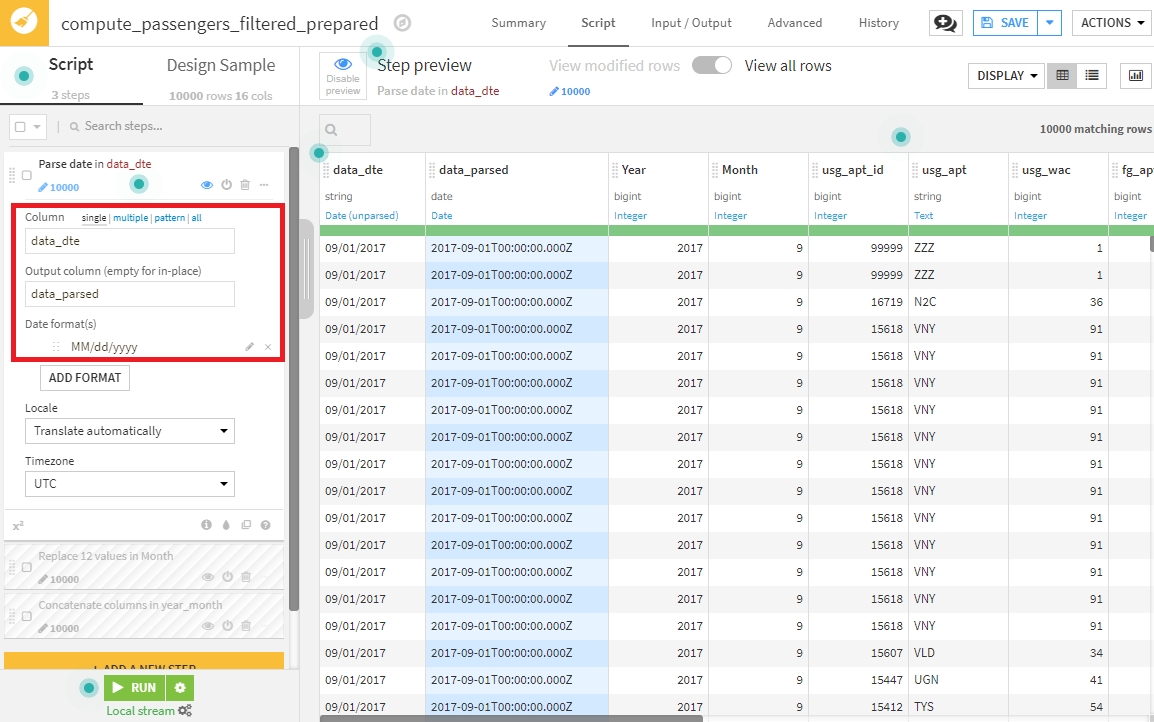
date_dte列の変換。
Dataikuでは、MM/dd/yyyyという形式を日付として検知します(それ以外の形式の場合は、Data format(s)を手動で設定してください)。出力するカラム名は、date_parsedとします。
-
月を名前へ変換。
1つのやり方は、Find and replaceプロセッサを使用して、Monthカラムの数値を、新しいmonth_nameカラムで名前に変換することです(例:1をJanへ変換)。
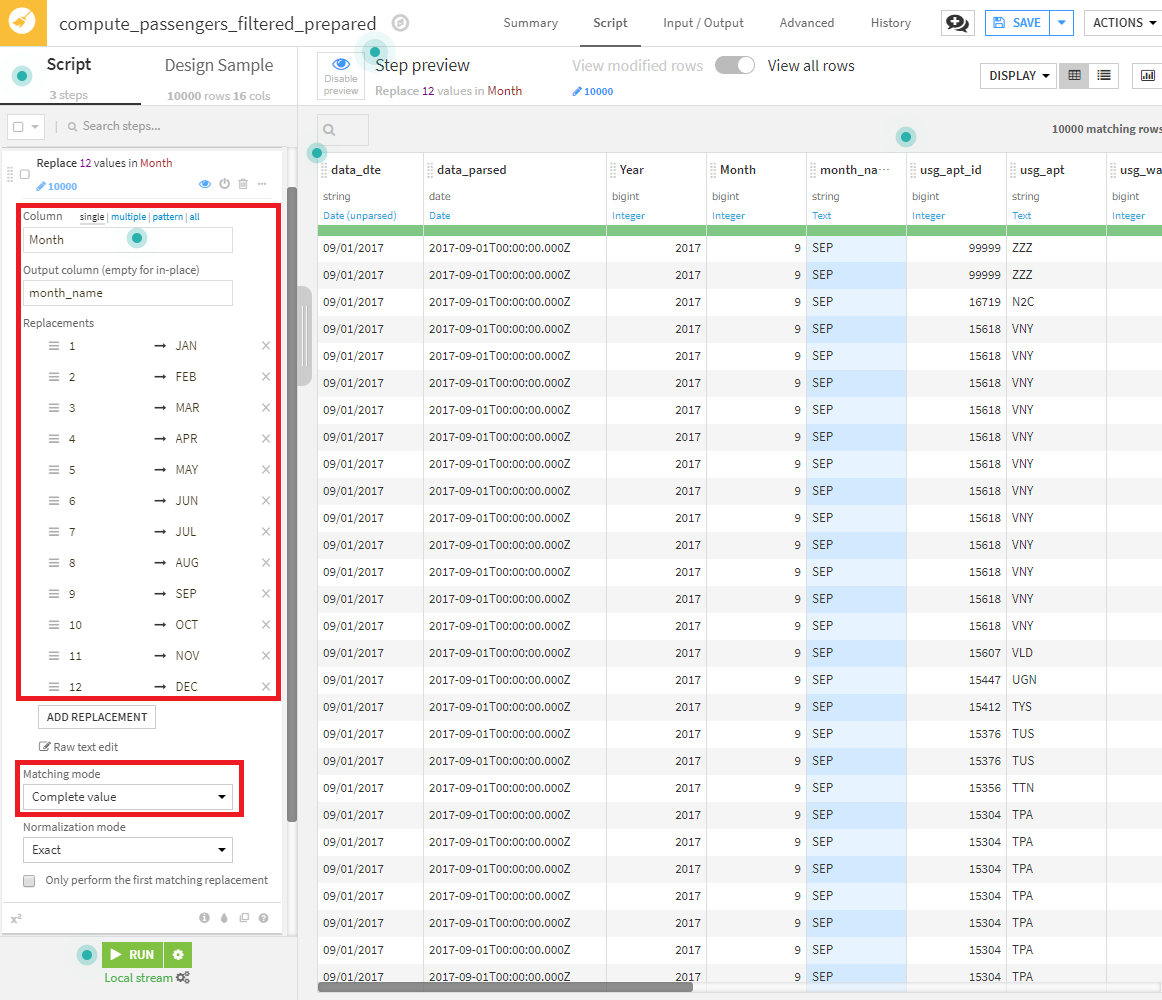
※Matching modeは、Complete value(完全一致)を指定してください。Substring(部分一致)を指定すると、12は、JanFebと誤変換される可能性があります。
3.Concatenate columnsプロセッターを使って、Year、Month、month_nameをハイフン(-)で連結した新しいカラムを作成する設定を行います。
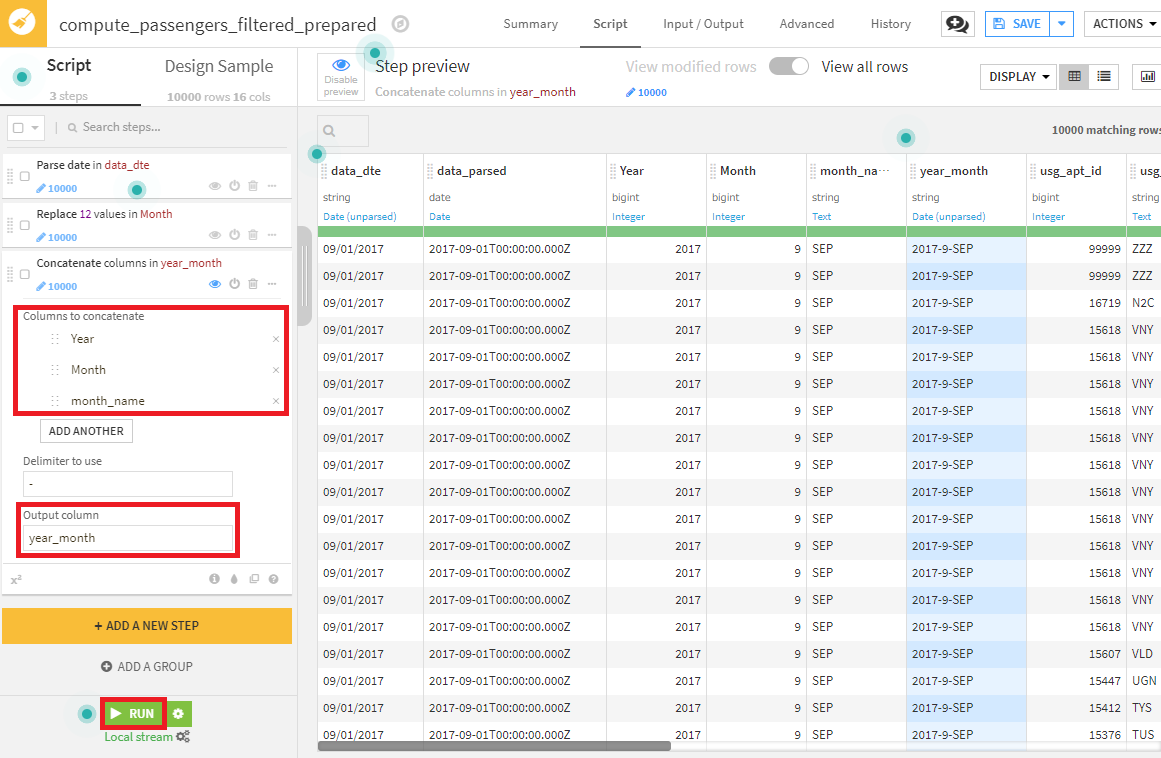
- RUNを押下すると、19カラムからなるデータセットが出力されるはずです。
データ加工(2)
次に、空港ごとに情報を集計して、国際的な旅行者向けに最も忙しい20の空港のリストを作成します。 これには、Groupレシピを使用します。
- Preparedレシピ適用後に作成されたデータセットを選択し、Groupレシピを選択。
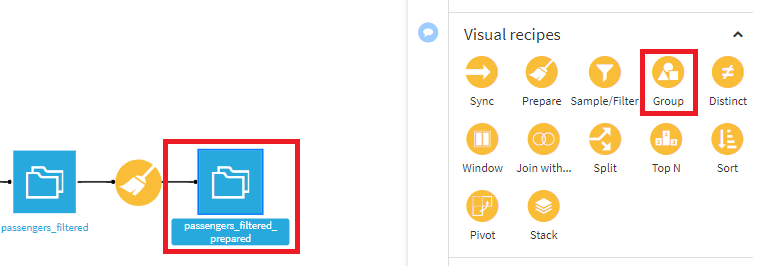
- usg_aptでグループ化するためにGroup Byでusg_aptを指定し、出力データセット名をpassengers_by_airportと変更して、CREATE RECIPEを押下します。
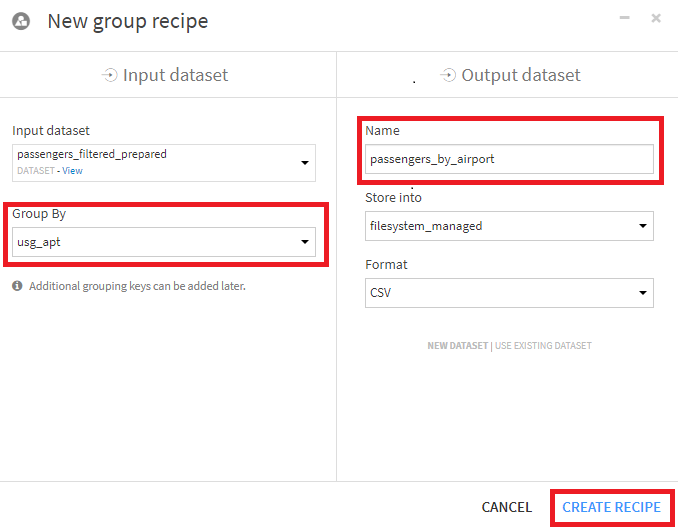
- Gropステップで以下のように設定します。
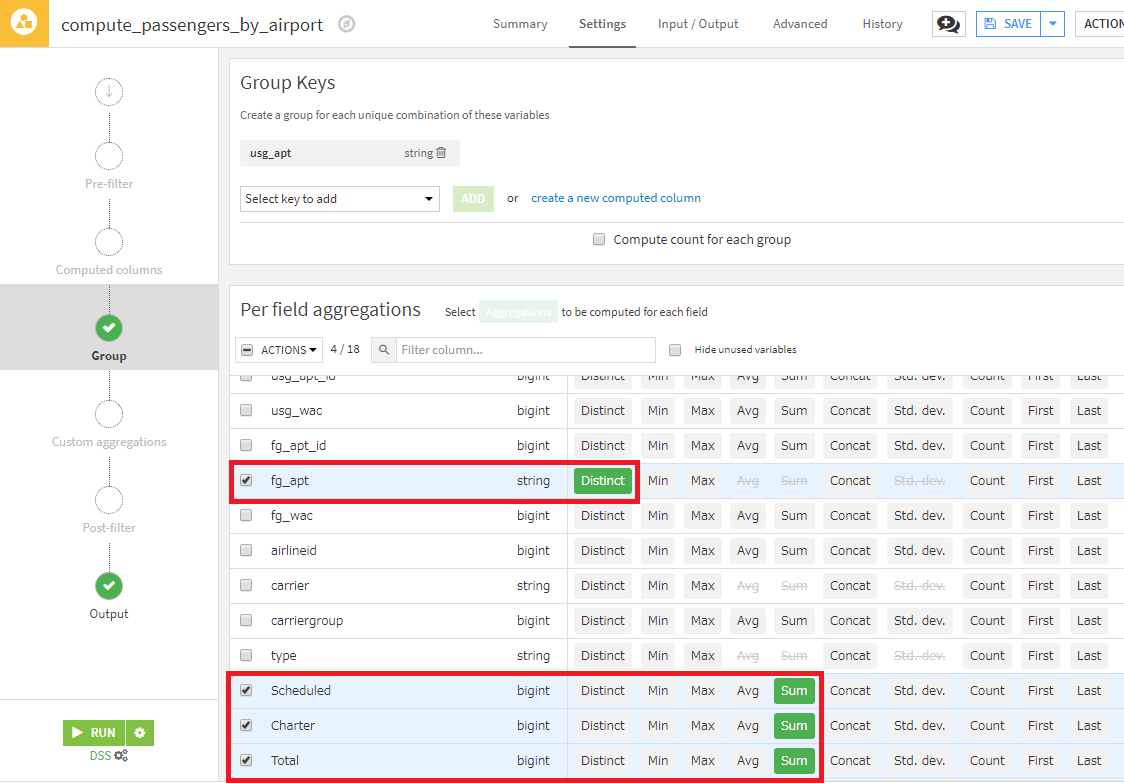
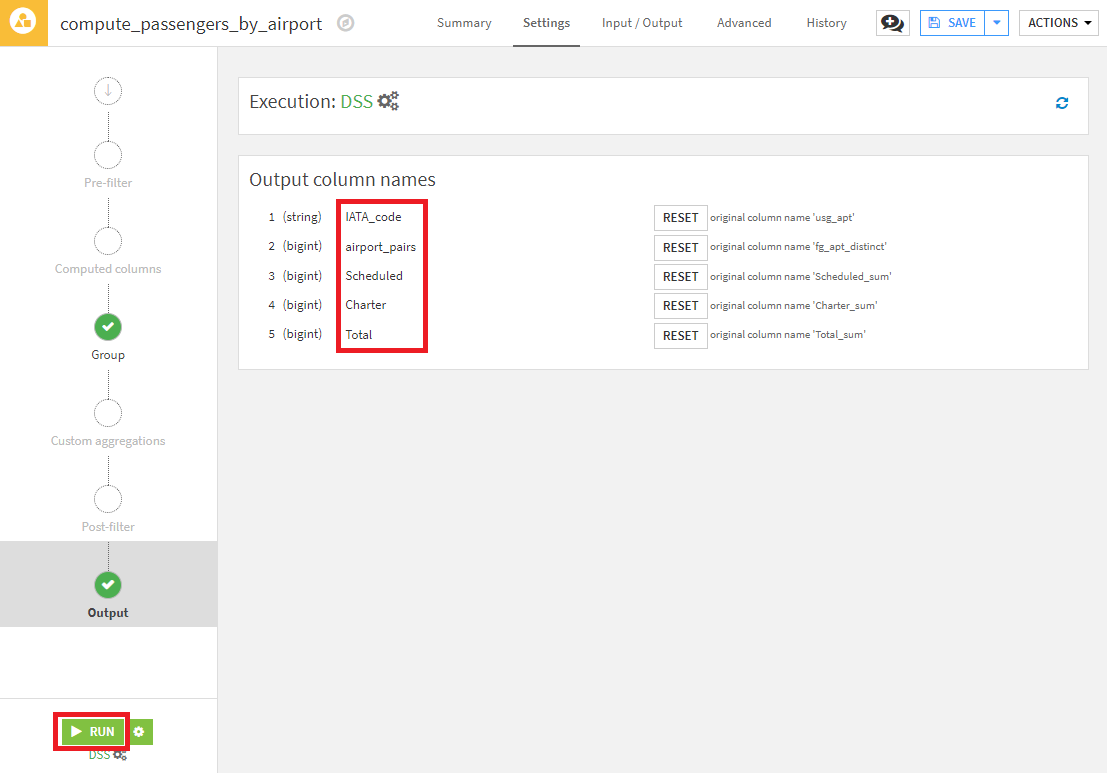
- Outputステップで、列の名前を以下のように変更し、RUNを押下し、レシピを実行します。
| 変更前 | 変更語 |
|---|---|
| usg_apt | IATA_code |
| fg_apt_distinct | airport_pairs |
| Scheduled_sum | Scheduled |
| Charter_sum | Charter |
| Charter_sum | Total |
 |
最後に、TopNレシピを使用して、国際線の乗客数に応じて上位20の空港を絞り込みます。
- Groupレシピ適用後に作成されたデータセットを選択し、TopNレシピを選択して作成します(出力データセット名は、passengers_by_airport_top20とします)。
- Top Nストップで、Retrieve the 20 top rowsと変更し、Totalの降順でソートする設定を行います(下記画像参照)。
- 最後にRUNボタンを押下し、レシピを実行します。
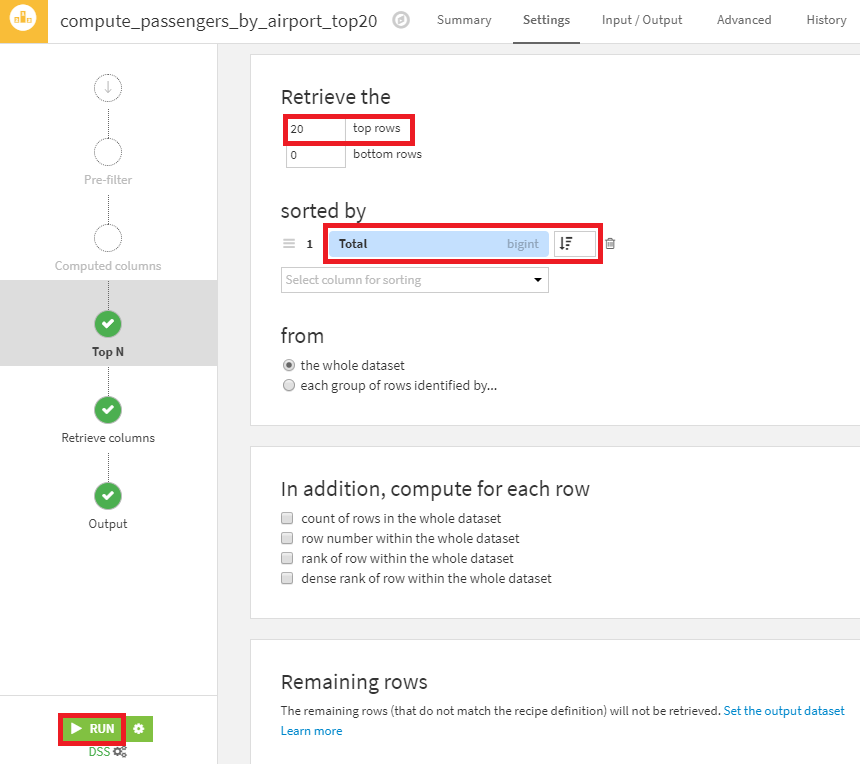
以上が、国際線旅客機で最も混雑する空港を見つけためのデータ加工操作になります。このウィキペディアの表に記載されている乗客の総数を簡単な操作で取得することができました。なお、作成した乗客の多いトップ20の空港リストは、データセットをCSVとしてエクスポートしたり、インスタンス内の他のプロジェクトと共有したり、Chartタブで可視化したりできます。
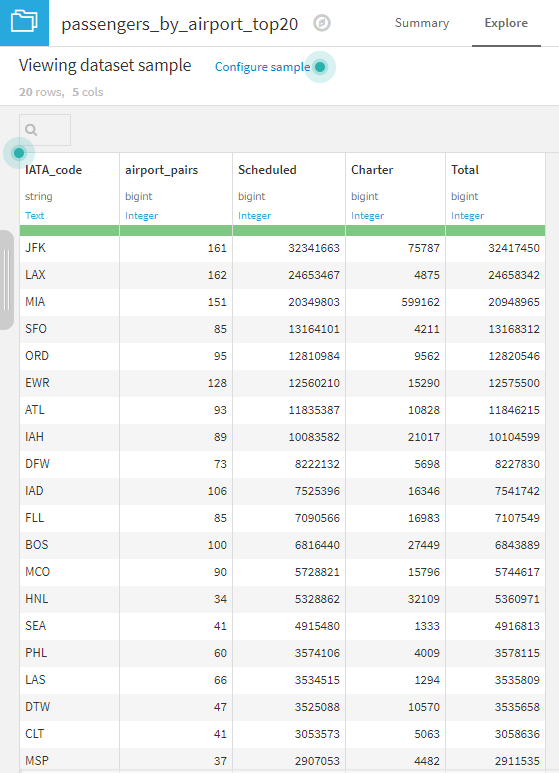
2. 運送業者グループの市場シェアの計算
データインポート
1章のデータインポートと同様の手順でデータをインポートします。
異なる点は以下の通りです。
- 手順2で、出力フォルダ名をdeparturesとする。
- 手順4で、URLをhttps://data.transportation.gov/api/views/innc-gbgc/rows.csv?accessType=DOWNLOADとする。
データ読み込み
1章のデータ読み込みと同様の手順でデータを読み込みます。
異なる点は以下の通りです。
生データをダウンロードしたら、Dataiku DSSに読み込みます。
- 手順1で、departuresフォルダを選択。
- 手順4で、New dataset nameをdepartures_filteredへ修正。
データ加工(1)
passengersデータと同様に、2017年のdeparturesデータを取得します。
- フロー画面上のSample/Filterレシピを選択し、コピーします。入力は、departuresデータセットを選択します。
- 出力データセット名は、departures_filteredとして、Create Recipeを押します。
- 上記以外は変更せず、Runを押します。
departments_filteredデータセットの列を確認すると、passengersデータセットと非常によく似ていることがわかります。そこで、passengersに対するPrepareレシピの処理をコピーして再利用します。
- passengersに対するPrepareレシピを開きます。

2.スクリプト上部にあるチェックボックスをチェックし、全てのステップを選択した後、Actions > Copy 3 stepsを選択します。
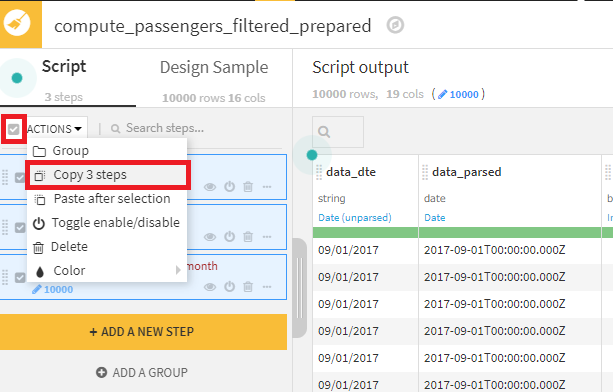
- departures_filteredを選択して、Prepareレシピを選択します。出力データセット名は、departures_preparedとします
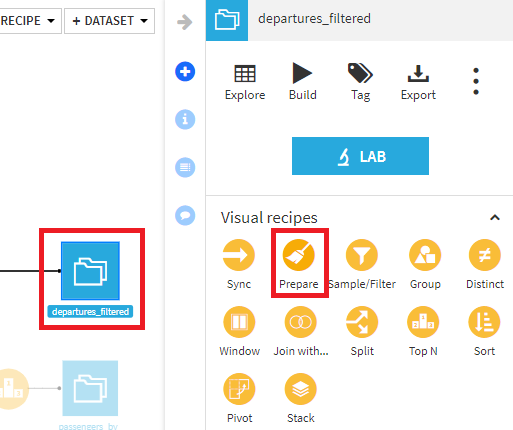
- コピーしたステップを貼り付け、RUNを押します。
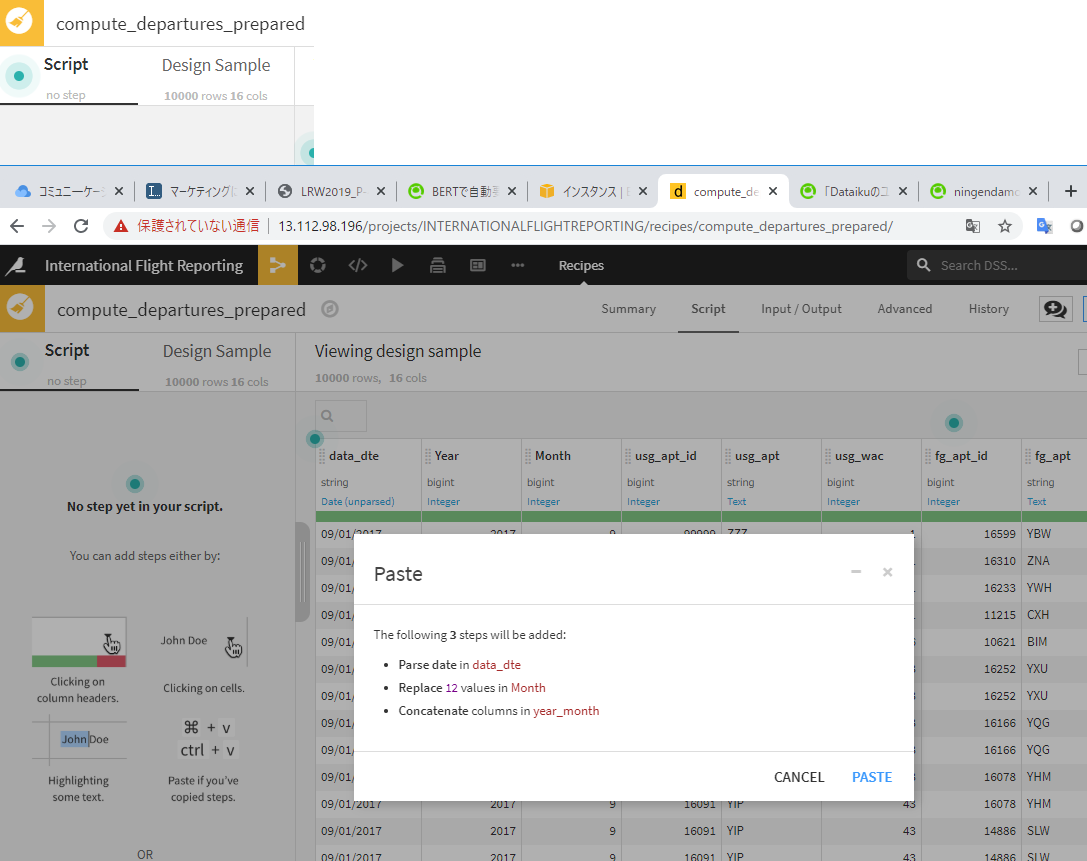
データ加工(2)
Pivotレシピを使って、キャリアグループの合計した列を作成します。
departures_preparedデータセットの各行は、月あたり空港間の交通量を表します。米国と国際航空会社を比較するために、各月について、carriergroupカラム(0=米国航空会社)で集計します。集計するのは、Scheduled、Charter、Total flightです。
- departures_preparedを選択し、Pivotを選択。
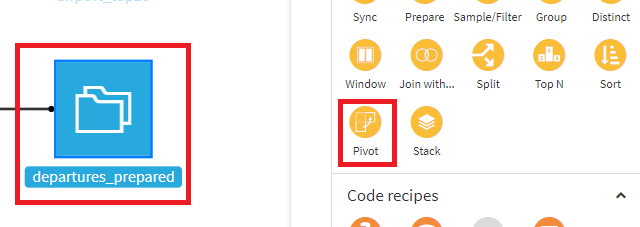
- Pivotにcarriergroup、出力データセット名にdepartures_by_carriergroupを指定し、CREATE RECIPEを選択します。
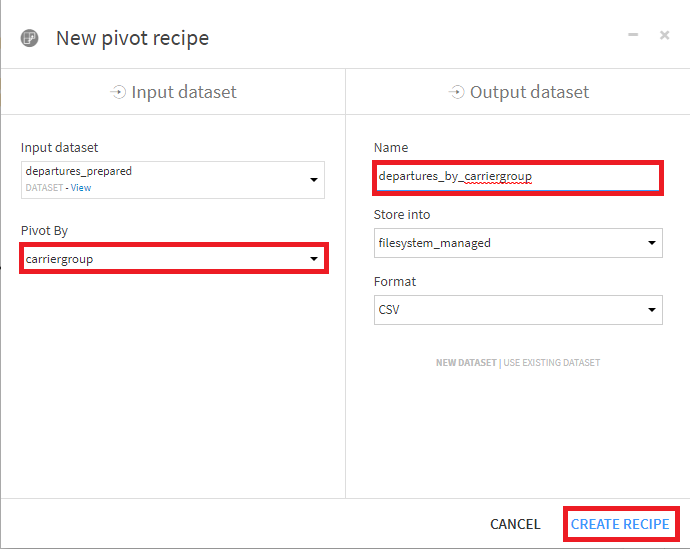
- Row identifiersにYear、Monthを指定。Count of recordsのチェックを外し、代わりにScheduled、Charter、Totalを選択し、ドロップダウンメニューからsumを選択し、RUNを押下。
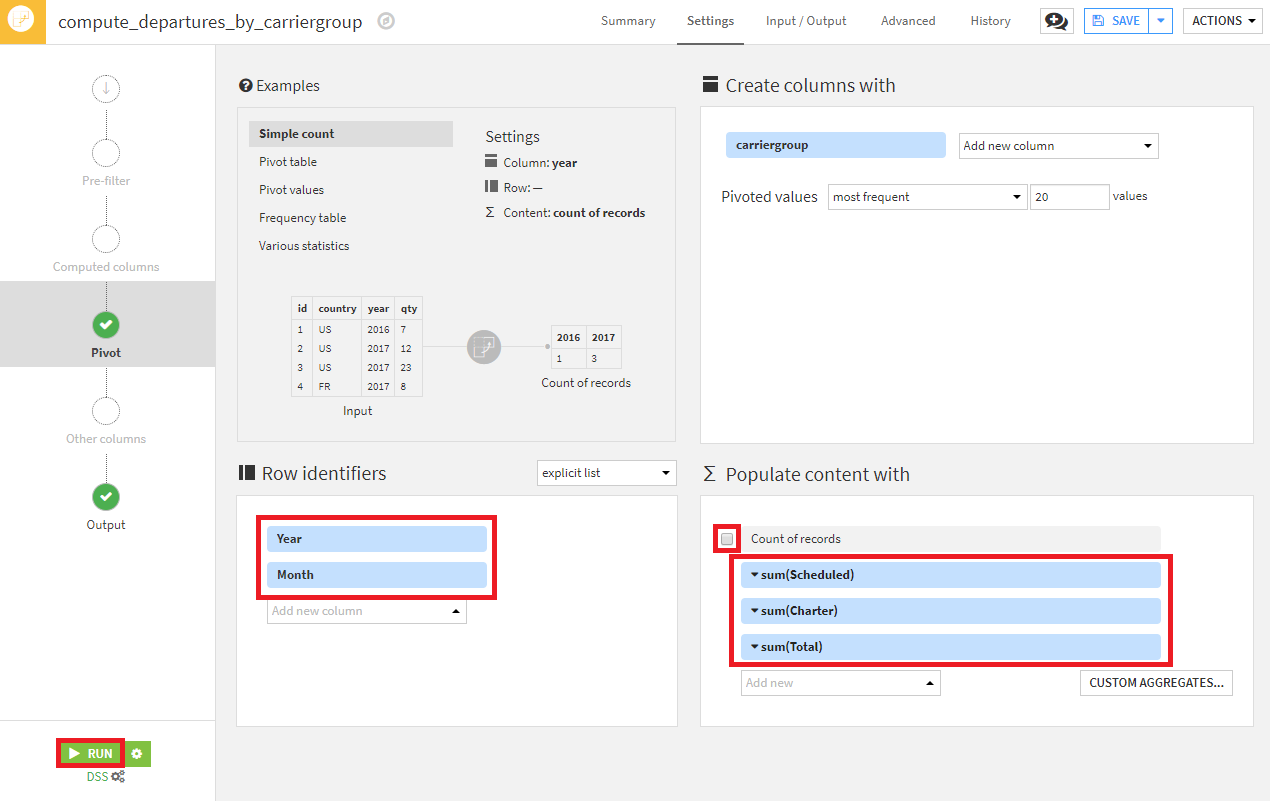
※Pivotレシピの詳細については、リファレンスドキュメントやチュートリアルを参照してください。
次に、ピボットされたデータをクリーンアップし、いくつかの新しい列を作成するためのPrepareレシピを追加します。ステップをグループ化して、コピーし易くします。
- departures_by_carriergroupデータセットを選択し、Prepareレシピを選択。出力データセット名は、departures_by_monthを指定。
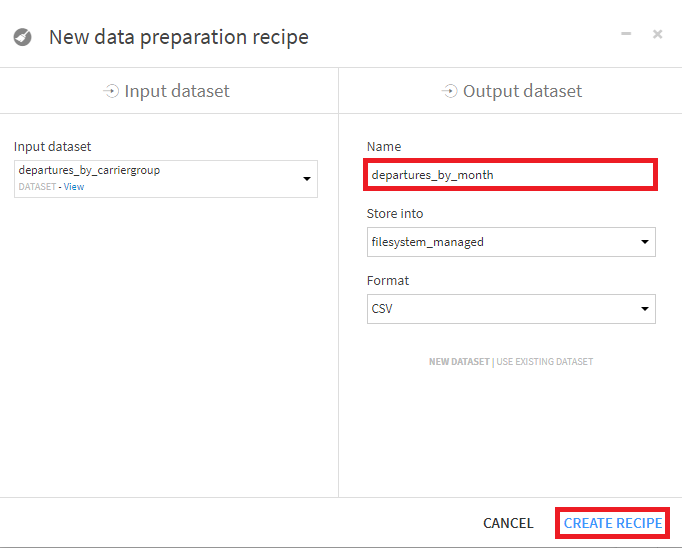
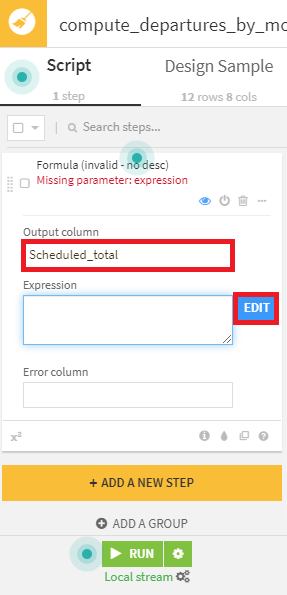
- まずは、スケジュールされたフライト数を表すScheduled_totalカラムを作成。Formulaプロセッサを選択。出力カラム名にScheduled_totalを指定し、EDITボタンを押下。
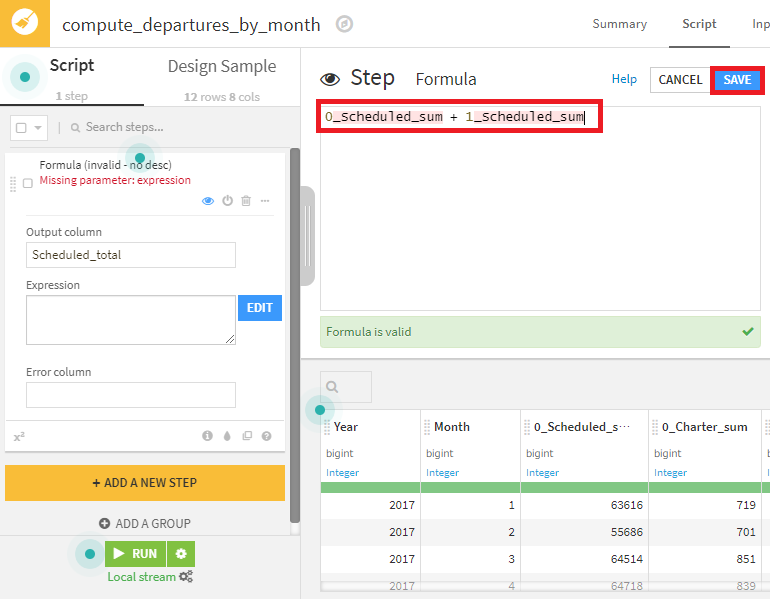
- 0_Scheduled_sum + 1_Scheduled_sumと入力し、SAVEボタンを押下。
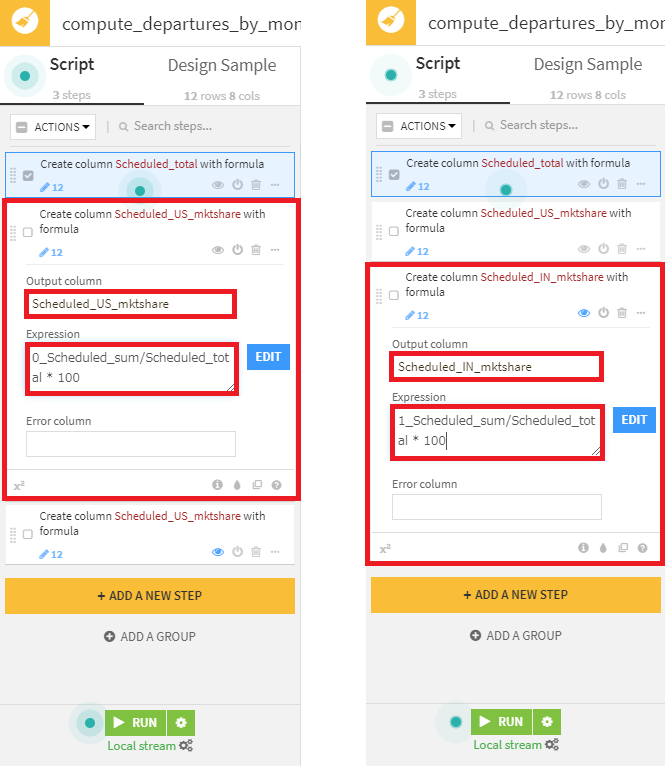
- 米国/国際航空会社のシェアを表す2カラム(Scheduled_US_mktshare/Scheduled_IN_mktshare)を作成。Expressionに0/1_Scheduled_sum/Scheduled_total * 100を設定。
- これら3つのステップをまとめるScheduledグループを作成。まず、3ステップ全て選択し、上部のAction>Groupを選択し、Scheduledという名前を付けます。
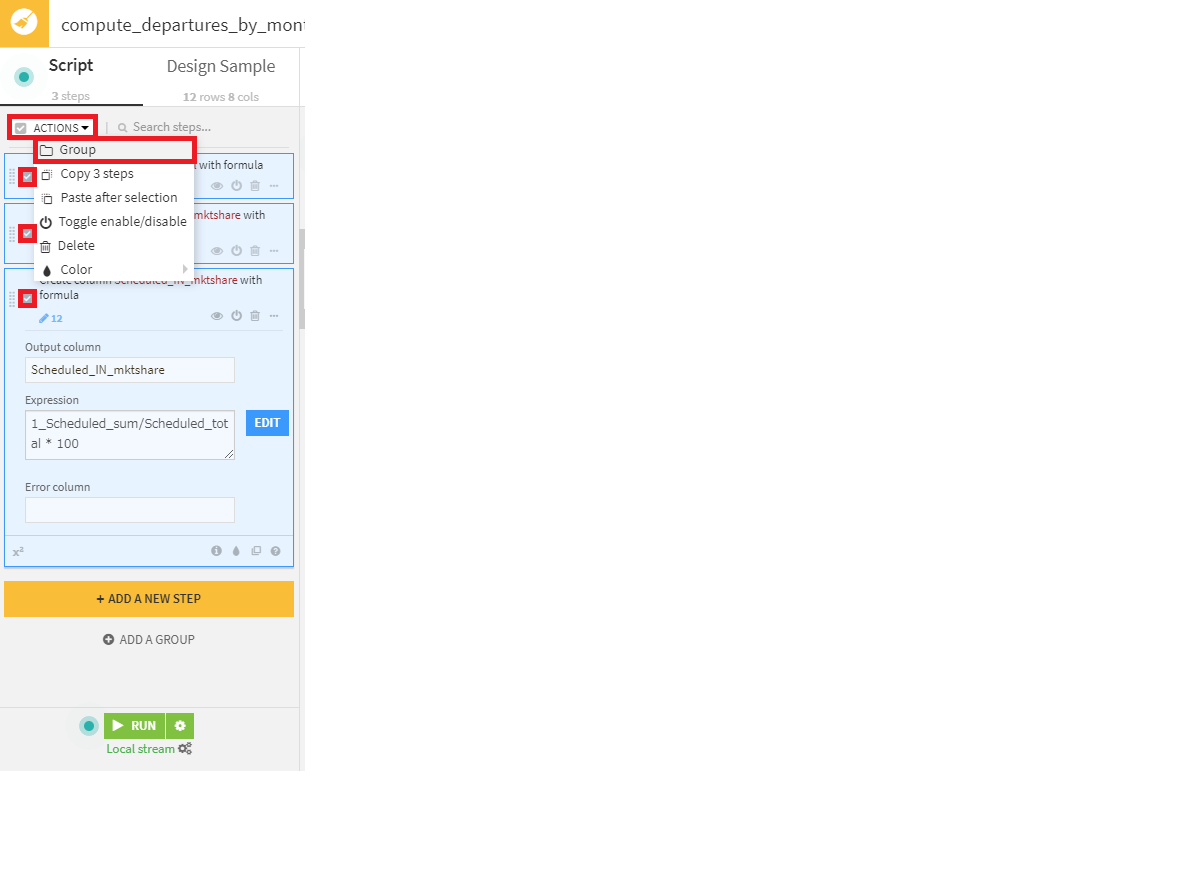
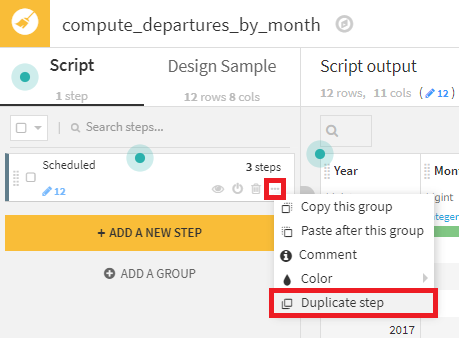
- グループをコピーして、2つの新しいグループ(Charter、Total)を作成し、それぞれ適切に集計するため修正を加えます。
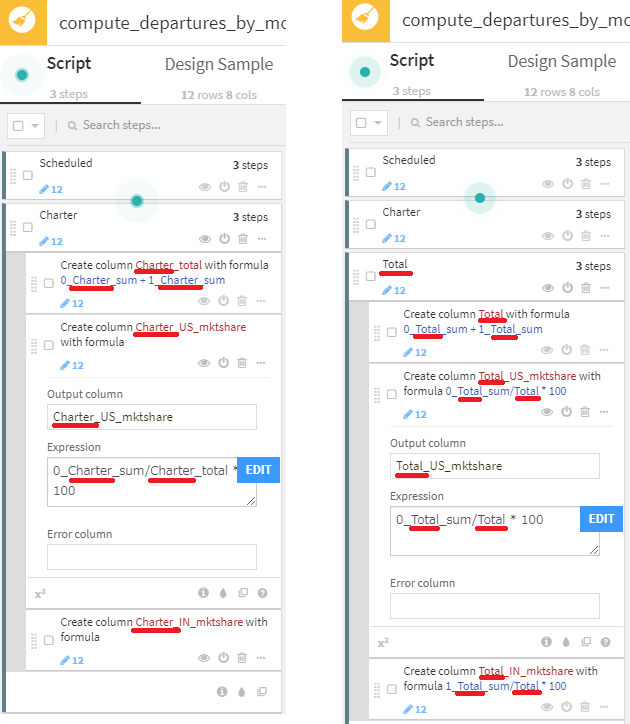
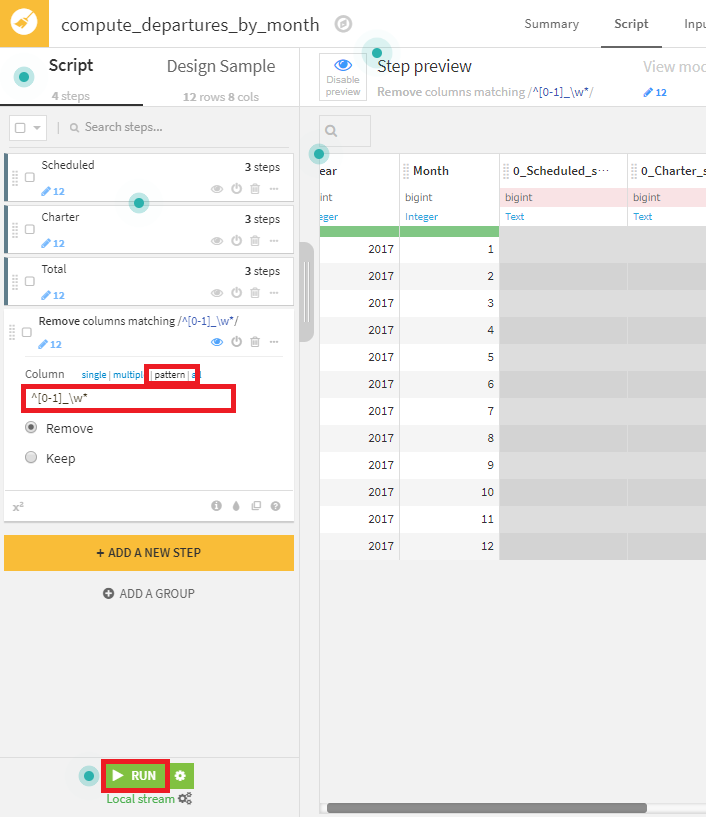
- 最後に、Delete/Keep columns by nameプロセッサで、0または1から始まるカラムを削除します。patternを選択し、正規表現^[0-1]_\w*により、0/1で始まり、長さが不定のカラムを指定しているのがポイントです。
※正規表現(regex)は、一連の文字を使用して検索パターンを定義するために使用でき、Dataiku DSSの様々なレシピで対応しています。Python for Informatics course slidesで正規表現の優れた紹介を見つけることができ、作成した正規表現をオンラインでテストすることもできます。
可視化
最初のデータパイプラインでは、最も混雑している上位20の空港を算出し、次のデータパイプラインでは、2017年度のフライトの月間合計と2つのカテゴリ(米国/国際)の航空会社の市場シェアを計算しました。
最も混雑している上位20の空港の算出結果をChartタブで視覚化してみましょう。
- データセットを選択。
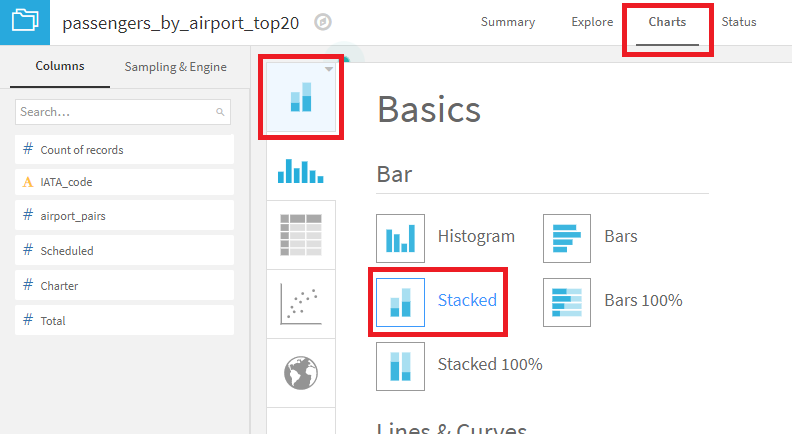
- Chartタブを選択し、積み上げ棒グラフを選択。
- Y軸にScheduled、Charterをドラッグして設定。X軸にIATA_Codeをドラッグして設定。
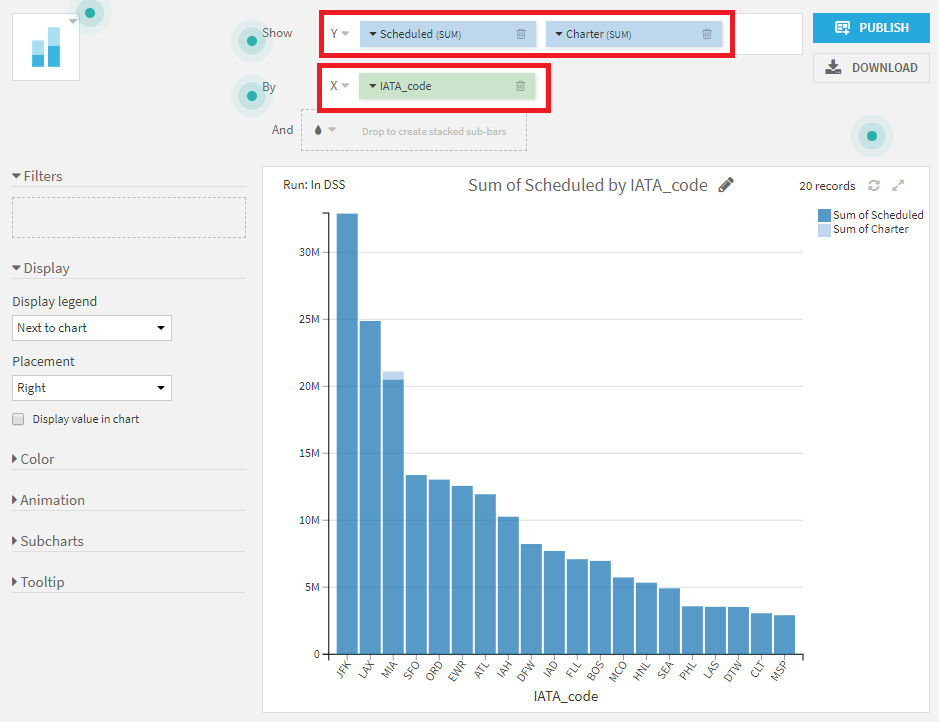
全体的な傾向に加えて、マイアミ(MIA)はチャーター便が突出して多い唯一の空港であることが見て取れます。
3. 経年変化を計算する時間差ウィンドウの追加(前年度データとの比較)
既存レシピ拡張
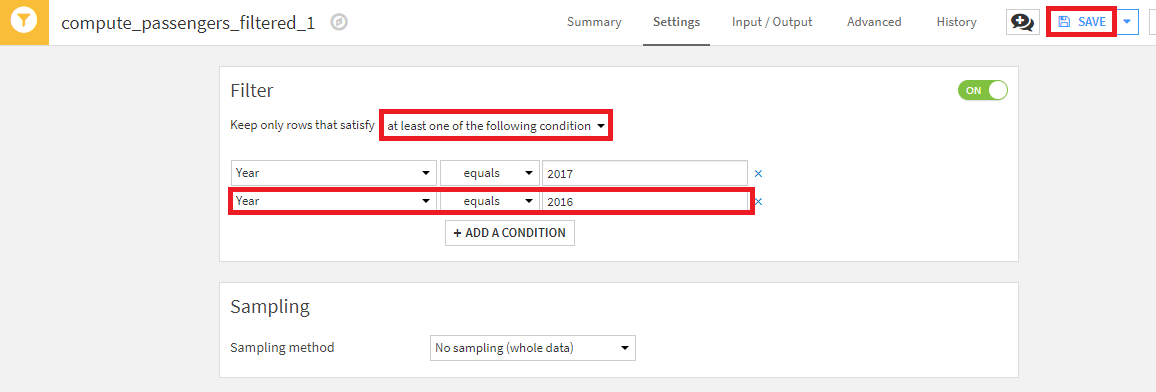
これまで、2017年のデータのみを保持するFilterレシピを作成しました。departureデータを前年と比較できるよう、このフィルターに2016年を含むように拡張してみましょう。既存のレシピに修正を加えると、それより下流にあるデータセットは修正前のレシピで作成されたデータセットになるため、再構築する必要があることに注意してください。
- departures_filteredを作成したFilterレシピを選択。
- keep rows that satisfyでat least one of the following conditionsを指定し、+ Add a ConditionでYear = 2016の設定を追加し、SAVEを押下。
- フロー画面を開き、当該Filterレシピを右クリックし、Build Flow outputs reachable from hereを選択。
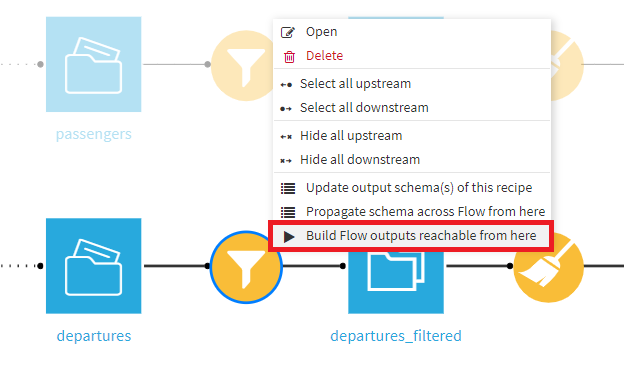
※Dataiku DSSでデータセットを再構築するための様々なオプションの詳細は、リファレンスドキュメントを参照してください。
データ加工
departures_by_monthのデータセットは現在、2年間(2016、2017年)の出発の合計を持っています。そこで、Windowレシピを使用して、前年度と比較した各月の交通量を算出してみましょう。各月について、12か月前の値を特定する必要があり、Windowレシピ的に言うと12か月のlagを指定する必要があります。
- departures_by_monthデータセットを選択し、Windowレシピを選択し、デフォルトの設定のままCREATE RECIPEを押下。
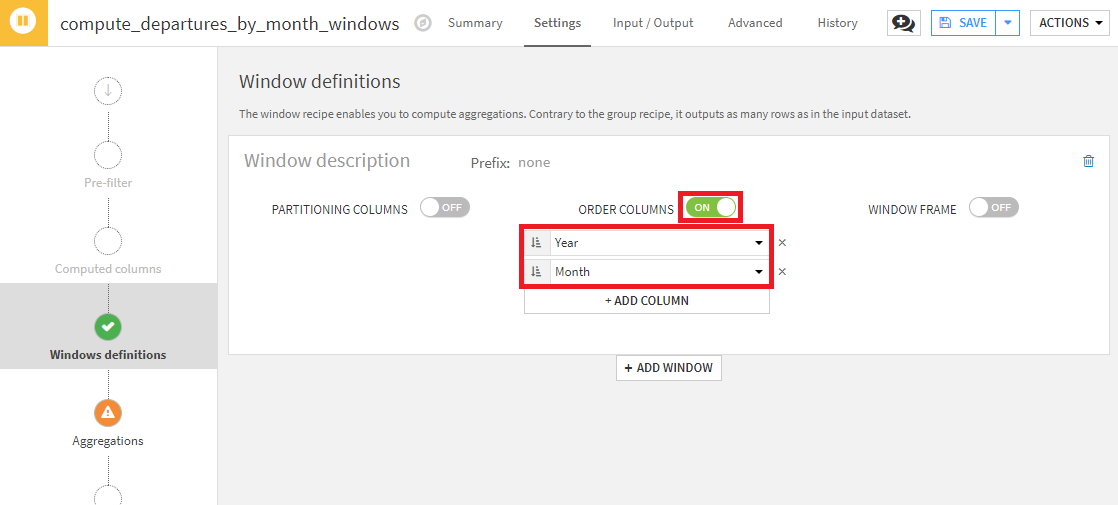
- Windows definitionsステップで、ORDER COLUMNSをONにし、YearとMonthの昇順に並ぶよう設定。これで、lagを計算するためのデータセットの順序の定義は完了です。
- Aggrigationステップで全てのカラムの値は維持した上で、TotalのLagを選択し、12ヵ月のlagとするため12を入力し、RUNを押下。
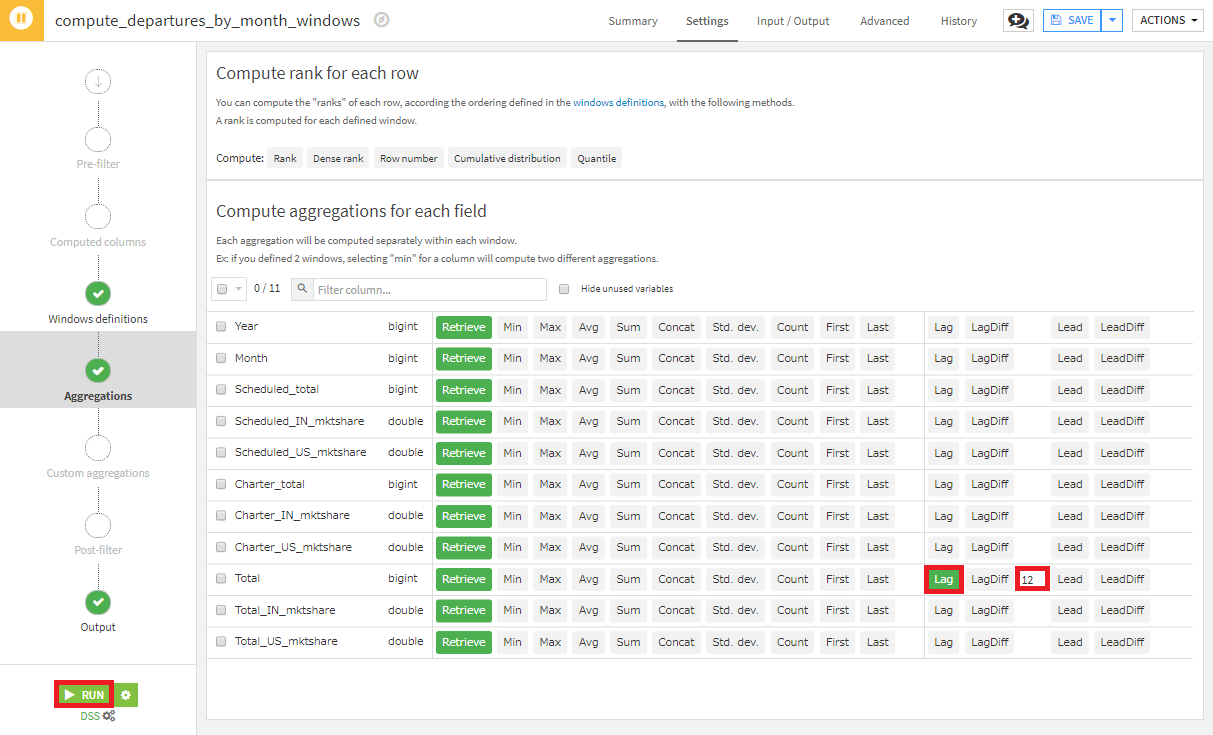
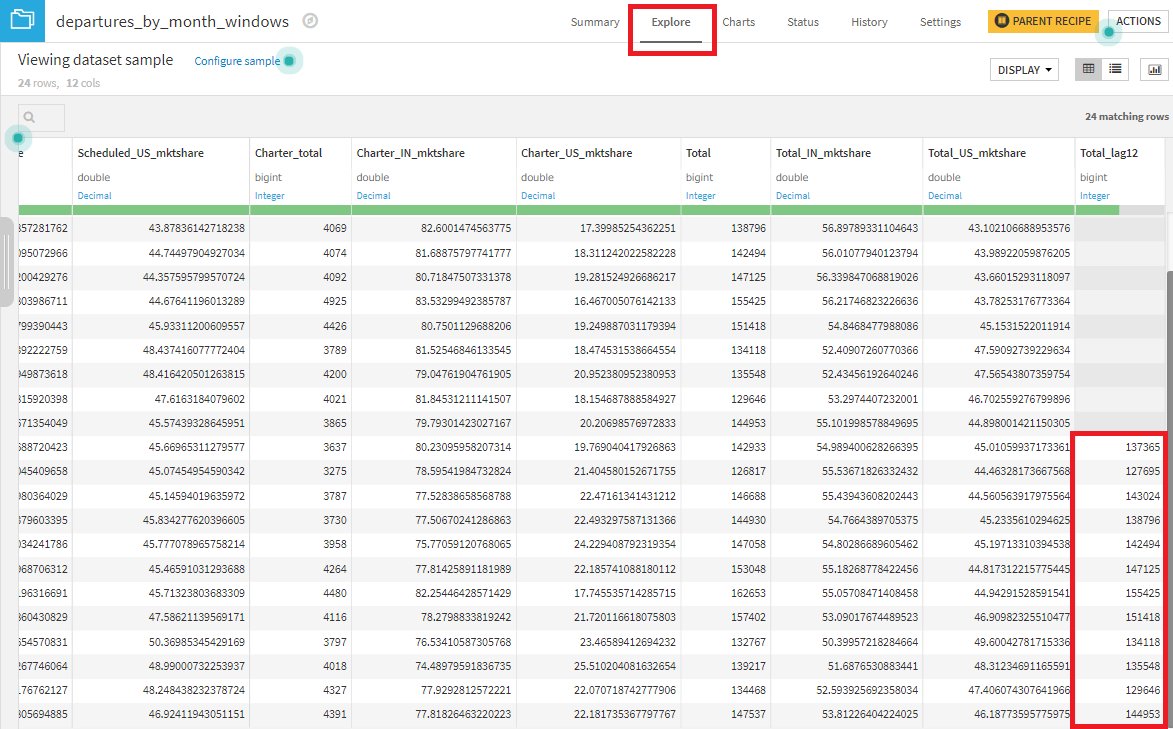
出力データセットの2017年の全ての月のレコードにおいて、Total_lag12カラムに値が入力されているはずです。そして、この値は、1年前の同月のフライト合計と一致していなければなりません。この確認はExploreタブ画面で簡単に確認できます。
※Windowレシピの詳細については、リファレンスドキュメントまたはチュートリアルを参照してください。
前年度のフライト合計を使用して、最終的なプレゼンテーションデータセットを作成できます。
- departures_by_month_windowsを選択し、Prepareレシピを選択し、CREATE RECIPEを押下。
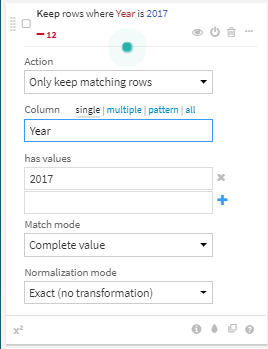
- Filter rows/cells on valueプロセッサを使用して、2017年のレコードだけ保持。
3. Formulaプロセッサを使用し、フライト合計の前年度比『(Total - Total_lag12)/Total_lag12 * 100』を算出.
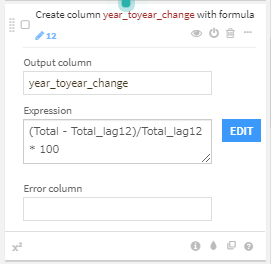
4. Delete/Keep columns by nameプロセッサを使用して、7カラム(Year, Month, Total_US_mktshare, Total_IN_mktshare, Total, Total_lag12, year_toyear_change)のみ保持し、RUNを押下。
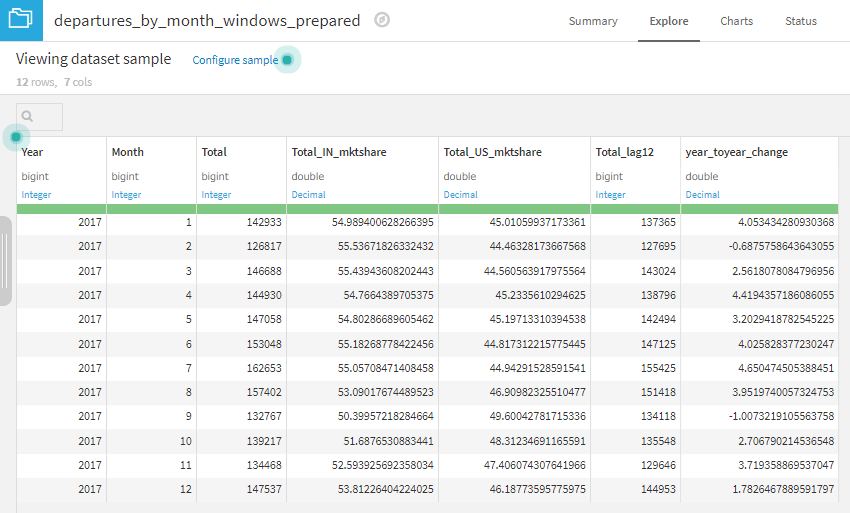
可視化
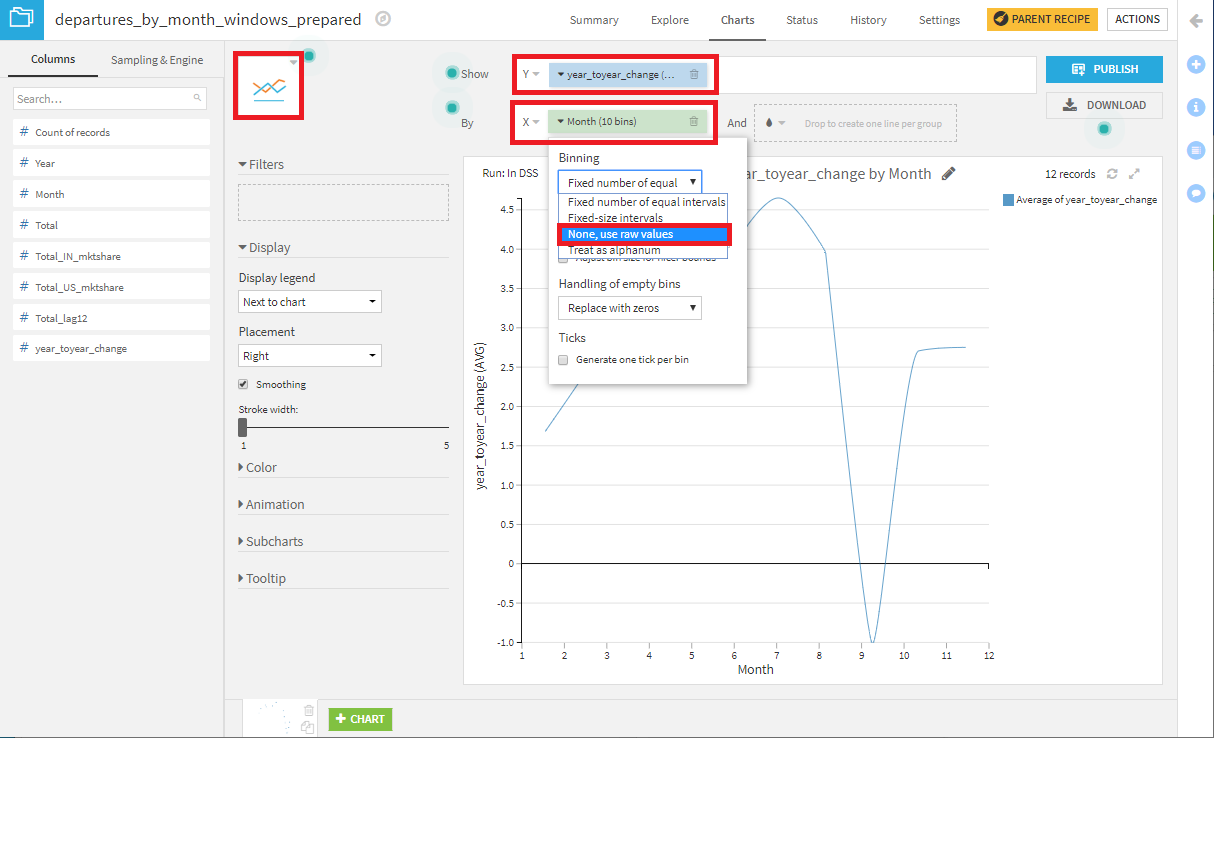
departures_by_month_windows_preparedのChartsタブで折れ線グラフを作成してみましょう。Y軸にyear_toyear_changeをドラッグし、X軸にMonthをドラッグし、binsにNone, use raw valueを指定すれば完成です。
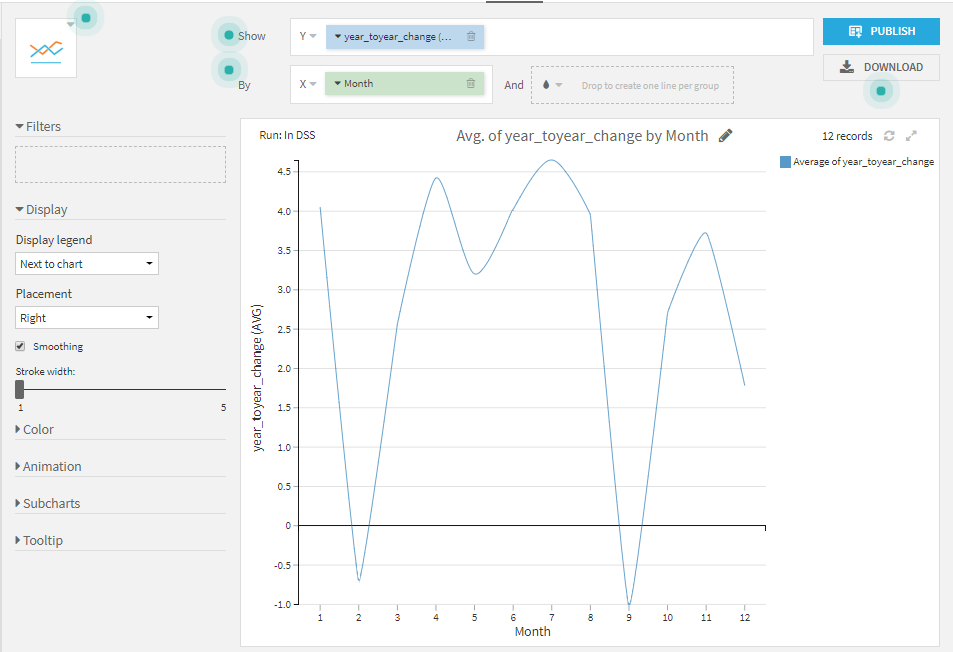
まとめ
継続的なデータ分析をする上で、データパイプラインの構築は、必要不可欠です。これは、データをさらに活用するための最初のステップです。シナリオ機能を使うことで、データパイプラインは自動化できます。
Dataiku DSSのさらなる理解のために、以下も参考になります。