1.はじめに
Dataiku DSSチュートリアルのMachine Learningをやりました。Dataikuに興味がある方は、操作方法のイメージが掴めるためおススメです。公式ホームページは英語のため備忘録を兼ねて、日本語版を公開します。
公式ホームページでは、今回実施する概要を説明するビデオが公開されているため、最初に視聴すると、どんなことをするかイメージできます(プログラムせずとも機械学習できることがわかります)。
※私は、Dataiku DSSのバージョン6.0.2を使用しました。
なお、以下の記事も参考になります。
+ Dataiku DSSをVirtual Boxを使って利用する方法
+ Tutorial: Basicの日本語記事
+ Tutorial: From Lab to Flowの日本語記事
+ Tutorial: Scoringの日本語記事
2.準備
このチュートリアルでは、Haiku Tシャツの過去の顧客レコードと注文ログを分析して、最初の機械学習モデルを作成します。最初の購入時に収集した情報に基づいて、新しい顧客が価値の高い顧客になるかどうかを予測することが目的です。
作成した機械学習モデルを新しい顧客へ適用する方法は、Tutorial: Scoring(12/24投稿予定)で明らかになります。
※前提条件
Tutorial: From Lab to Flowを実施しているのを前提とした内容になっているため、未実施な場合は、まずTutorial: From Lab to Flowを実施します。
3.プロジェクトの作成
Dataiku DSSのホーム画面を起動し、+新規プロジェクト > DSS tutorials > 103: Machine Learning(Tutorial)を選択します。

新しく作成されたプロジェクトを選択し、GO TO FLOWを選択します。Flow画面では、顧客と注文のデータセットを作成、準備、および結合するために、1つ前のチュートリアルで使用した手順を見ることができます。

さらに、予測したい新しい顧客を表す「ラベルのない」顧客のデータセットがあります。これらの顧客は注文ログと結合され、顧客の履歴データとほぼ同じ方法で準備されています。
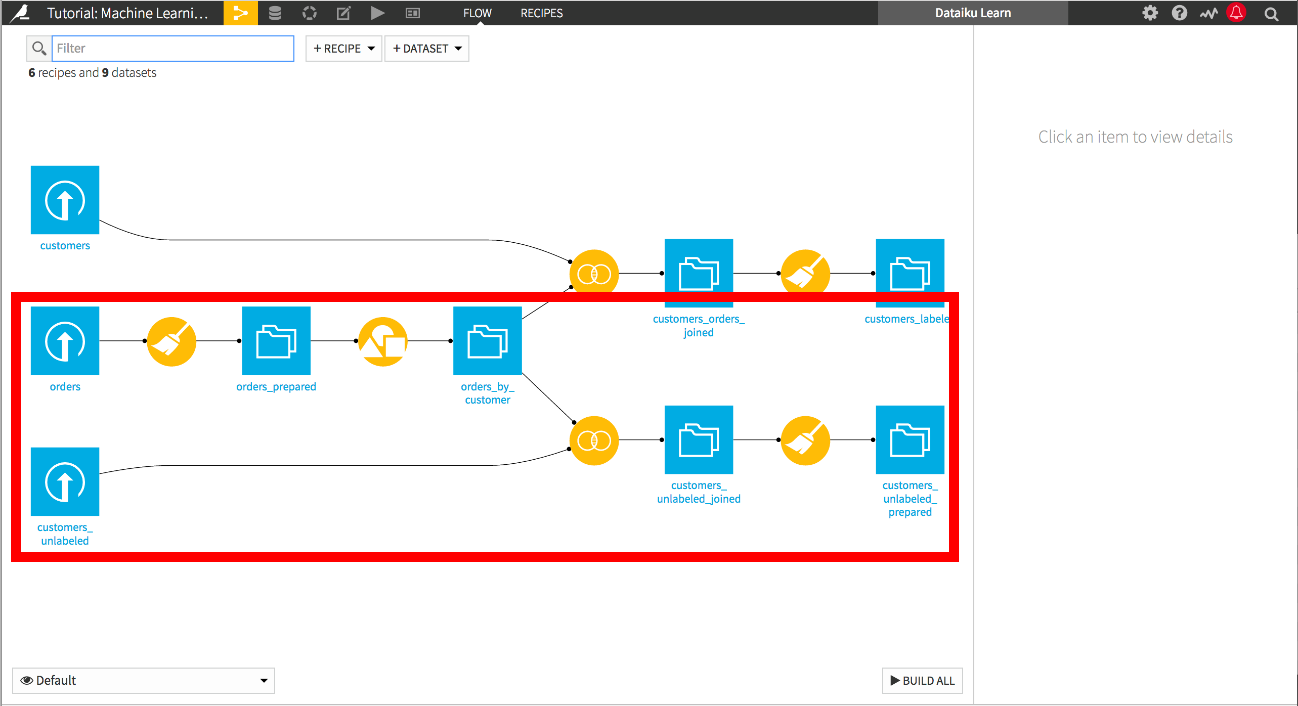
別の方法として、1つ前のチュートリアルから実施することもできます。
1. customers_labeledデータセットからtotal_sumおよびcount列を削除する
2. customers_unlabeled.csvファイルのコピーをダウンロードして、プロジェクトにアップロードします。
4.予測モデルの作成
機械学習モデルを作成する目的は、既存の顧客と注文データに基づいて、新規顧客が優良な(高収益をもたらす)顧客になるかどうかを予測(推測)することです。これを正しく予測できれば、より効果的なキャンペーンや関係構築につなげられる可能性あります。
Flow画面で、ラベル付き(customers_labeled)データセットを選択し、LABボタンをクリックします。そして、ダイアログ画面のVisual analysisのNEWを選択し、わかりやすい名前(例:High revenue analysis)を付けて、CREATEボタンを選択します。

ラベル付きデータセットには、顧客、デバイス、場所に関する個人情報が含まれています。最後の列high_revenueは、購入履歴に基づいて多くの収益を上げている顧客向けのフラグです。これは、機械学習モデルの目標変数として使用します。
では、モデルを作成してみます。先程作成したVisual analysis画面のModelタブを選択し、CREATE FIRST MODELボタンを選択します。

すると、Create a modeling taskダイアログが開きます。
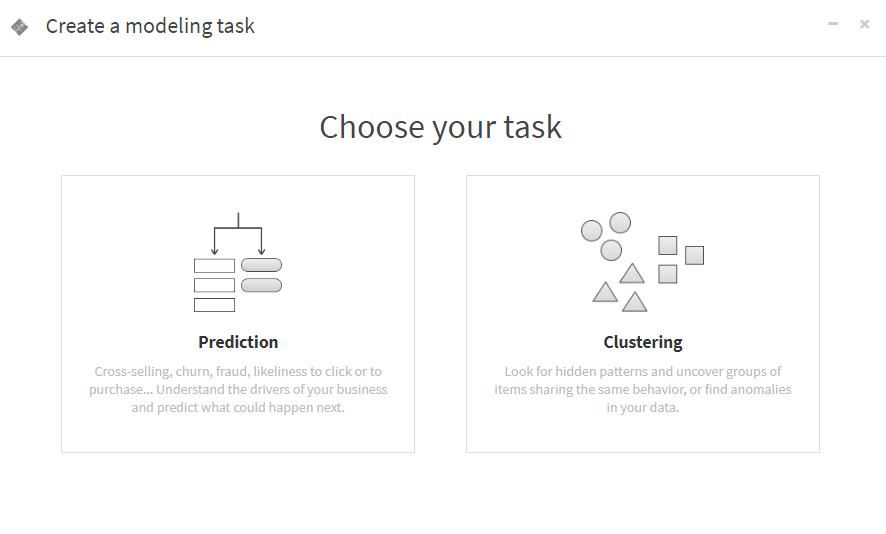
作業を進める前に、上記ダイアログのPrediction、Clusteringについて解説します。
Prediction
教師あり学習アルゴリズムを適用します。例えば、実際の値(目的変数)がわかっている過去のデータを基にモデルを学習します。目的変数の性質により、使用するアルゴリズムが変わります。
- 回帰:実際の数量(つまり、期間、数量、消費額など)を予測します。
- 2クラス分類:2値(存在/不在、はい/いいえなど)を予測します。
- マルチクラス分類:有限な値(赤/青/緑、小/中/大など)を持つ変数を予測します。
Clustering
「ラベル付けされていない」データから隠された傾向を把握するために、クラスタリングを適用します。これらの教師なし学習アルゴリズムは、類似している行をグループ化することができます。
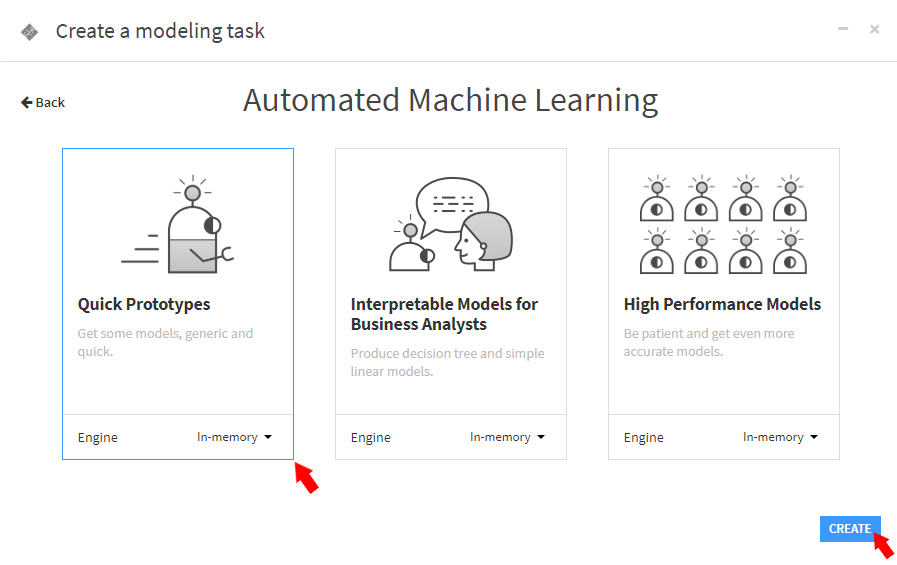
今回は、high_revenueを予測したいので、Predictionを選択します。そして、目的変数としてhigh_revenueを指定し、Automated Machine Learning選択します。

Automated Machine Learningは、目的に応じたモデルを作成するためのテンプレートを提供します。例えば、機械学習を使用してデータに関する洞察を得る、パフォーマンスの高いモデルを作成するといったテンプレートを選択できます。今回は、Quick Prototypesをデフォルトの設定(In-memory)のまま、CREATEボタンを選択し、次の画面でTRAINボタンを選択します。
TRAINボタンを選択すると、Dataiku DSSは、機械学習アルゴリズムを適用する前に、データセットの機能に適用する最適な前処理を推測します。そして、数秒後、今回学習したモデルを含むSESSION 1の結果の概要が表示されます。デフォルトでは、データに対して2クラス分類のアルゴリズムが使用されます。
- 単純な一般化線形モデル(ロジスティック回帰)
- より複雑なアンサンブルモデル(ランダムフォレスト)
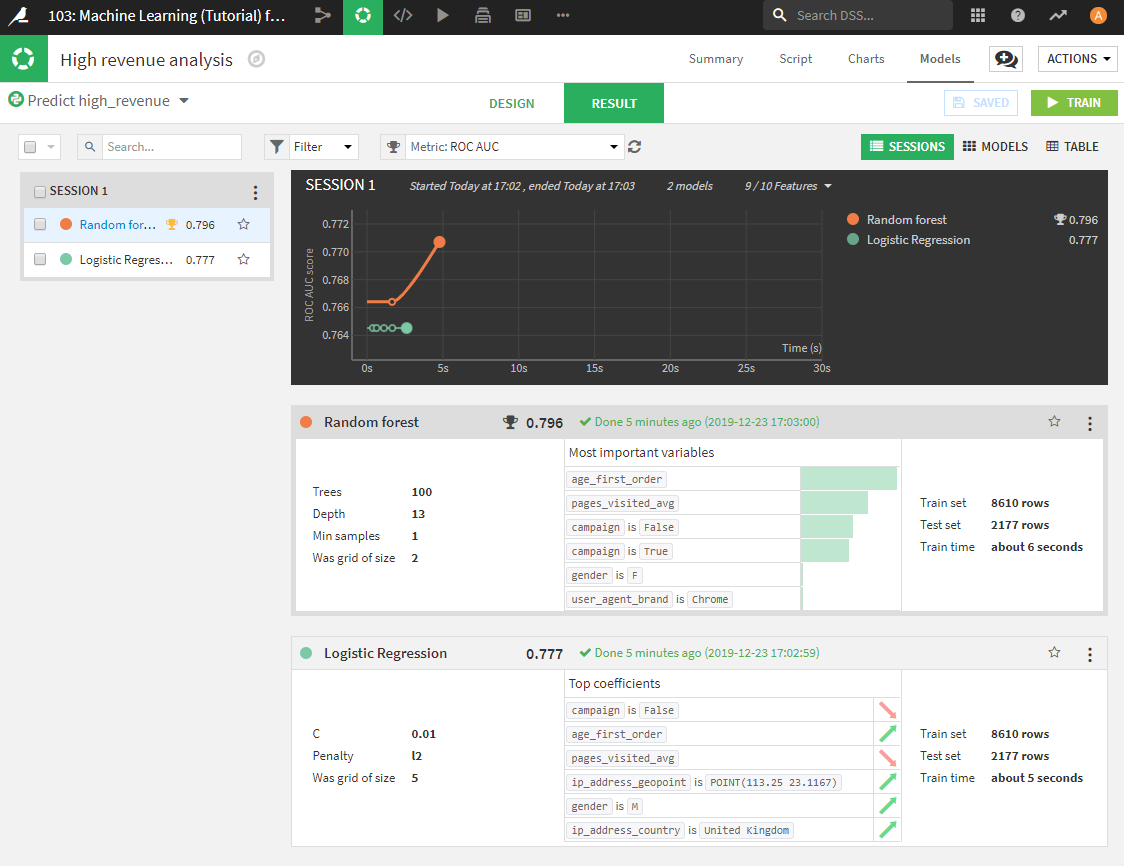
各モデルの結果サマリには、次のような重要な情報が含まれています。
- 学習アルゴリズム
- パフォーマンス(デフォルトでは、AUCが表示されます)
- 予測する上で最も重要な変数
AUC尺度は便利です。1に近いほど、モデルは優れています。今回は、ランダムフォレストモデルが最も高い性能を示しています。Random forestを選択すると、このモデルのメイン結果画面に遷移します。

5.モデル性能&結果理解
Summaryタブ画面では、AUCなどが表示されます。今回はAUC=0.769と表示されていますが、学習データ、テストデータはランダムに選択されるため、若干異なる場合があります。
作成されたモデルの理解を深めるために、Dataiku DSSはいくつか異なる情報を提供します。
左側のリストにINTERPRETATIONというセクションがあり、モデルに対する説明変数の寄与(影響力)に関する情報が表示されます。
このセクションに表示される情報は、アルゴリズムに依存して変わります(線形モデルの場合はモデルの係数が表示され、ツリーベースな手法の場合は各変数について、分割の深さで重み付けされた分割数を表示します)が、このセクションで提供される情報は、モデルをよりよく理解するために非常に役立ちます。

一部の変数は、優良顧客であることと強い関係があるようです。特に、age_first_order(初回購入時年齢)は良い指標だと解釈できます。
INTERPRETATIONの下にPERFORMANCEセクションがあります。Confusion matrix(混合行列)は、目的変数の真の値と予測値を比較した値(flase positives、false negativesなど)で、Presicion、Recall、F1-scoreに関連する。機械学習モデルは、一般的に2グループの1つに属する確率を出力し、予測値は、この確率に対して私達が設定した閾値に依存して決まります(例:優良顧客と見なす確率の閾値を決める。)。
混同行列は、指定された閾値に依存します。これは、上部のスライダーを使用して変更できます。

Decision Chartは、閾値ごとのPrecision、Recall、F1 scoreを示します。
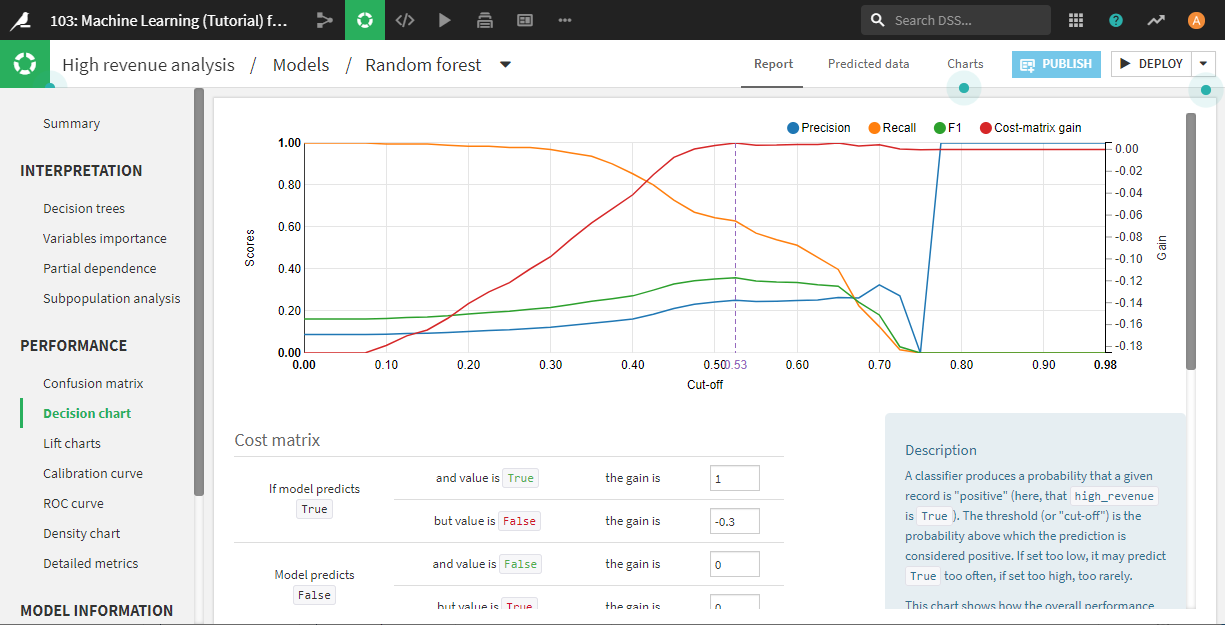
List charts(リフトチャート)とROC curve(ROC曲線)は、モデルの性能を評価するために、おそらく最も有効な可視化方法です。詳細な説明は割愛しますがポイントは、どちらの場合もグラフの始めからカーブが急な程、よりよいモデルとなります。
今回の場合も、かなり良く見えます。


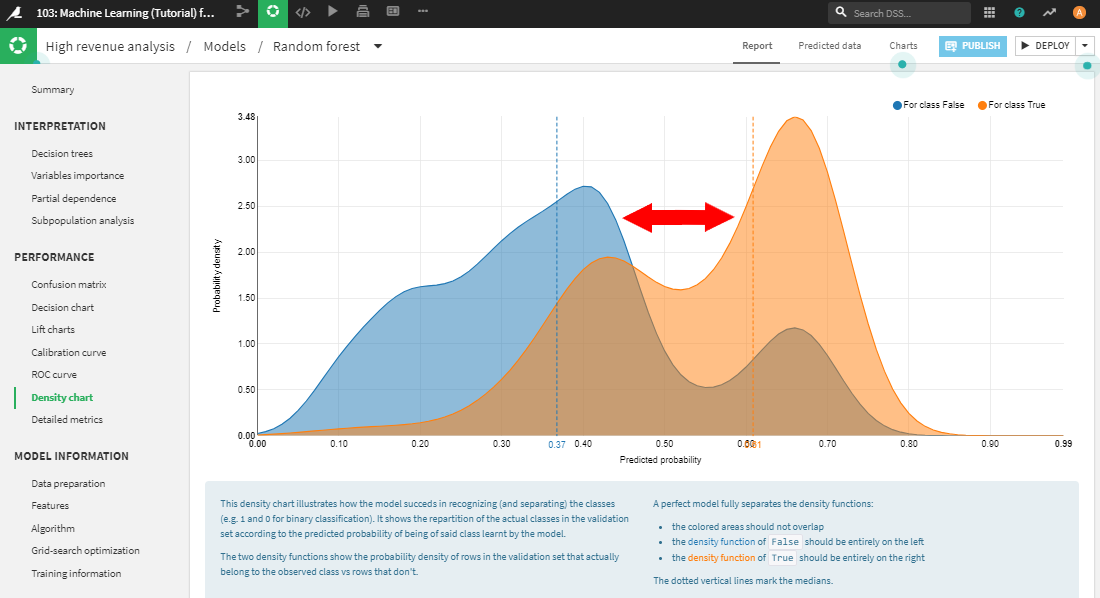
Density chart(密度グラフ)は、優良顧客の確率の分布を2つのグループ(実際に優良顧客/実際は非優良顧客)を重ねて表示します。優れたモデルは2つの曲線をより分割することができますが、それをこの密度グラフで確認することができます。
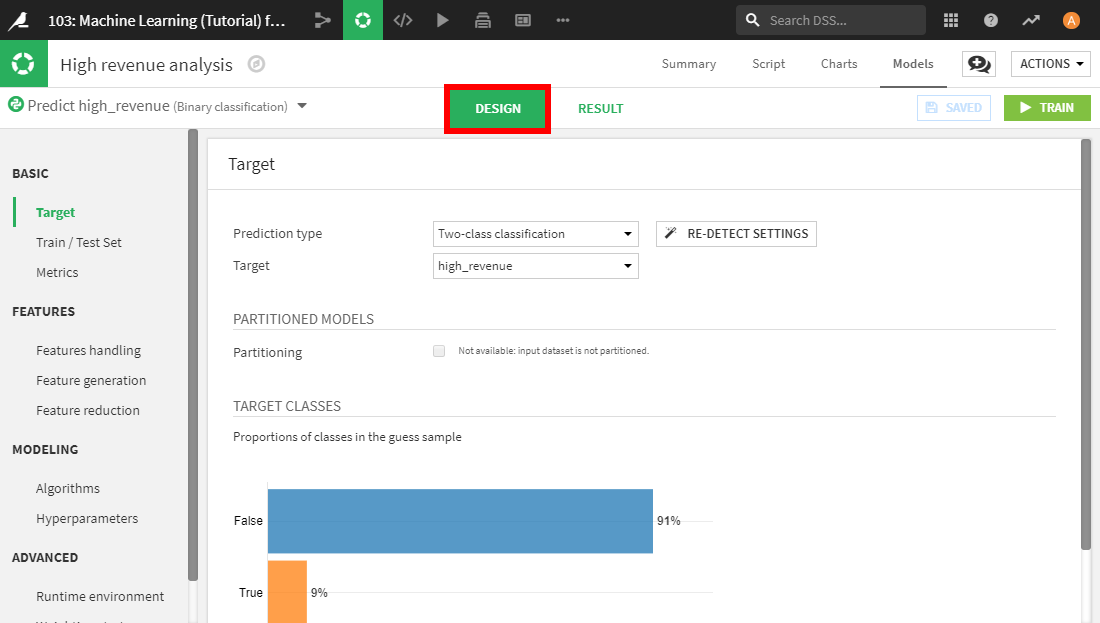
最後のModel Informationセクションは、モデルがどのように構築されたかの要約となります。Featuresタブを確認すると、いくつか興味深いことに気付きます。

デフォルトでは、customerIDを除く使用可能なすべての変数が、目的変数の予測に使われます。Dataiku DSSは、customerIDを一意の識別子として検出し、優良顧客を予測する助けにならないと判断し、Rejectedとしています。
さらに、geopoint(緯度経度情報)などは、未知のデータに対して一般的に扱えないと思われるため、予測モデルにおいてあまり有効でないと思われます。このように、モデルの設定を調整したくなる場合があり得ます。
6.モデル設定の調整
学習するモデルの設定を変更するには、Modelsリンクを選択し、Design画面を開きます。.
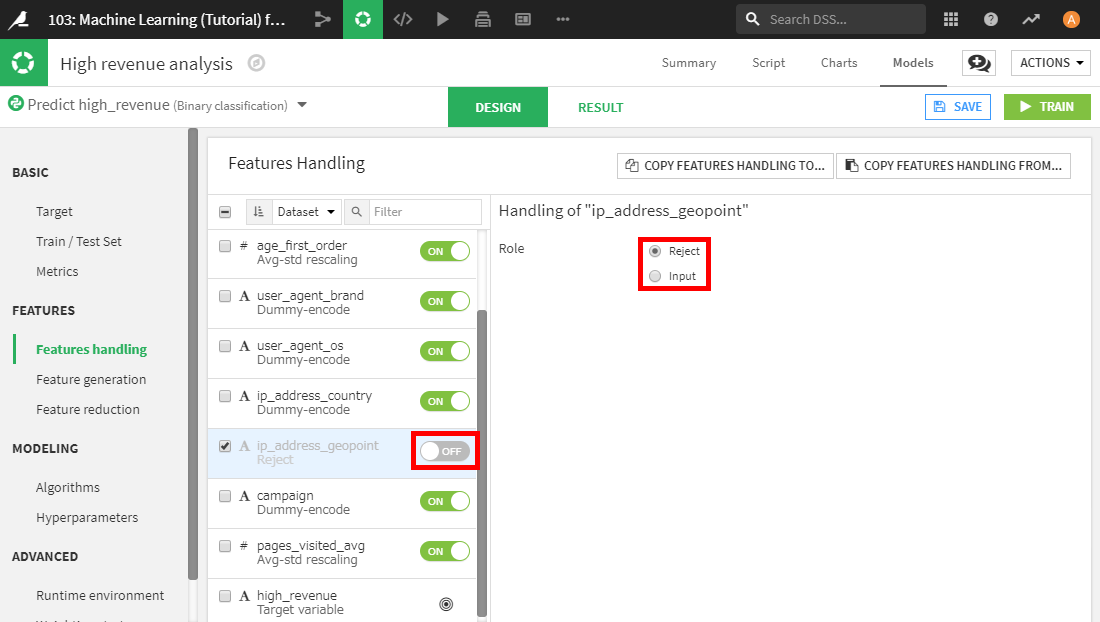
変数をどのように使用するか設定するには、Features handlingタブを選択します。ここでは、様々な設定をすることができます。
変数(または特徴量)のRoleは、モデルで使う(Input)/使わない(Reject)を示します。ip_address_geopointをモデルで使用したくないとします。その場合は、ip_address_geopointを選択し、Rejectボタンを選択します(または、ON/OFF切替ボタンを選択してOFFにします)。
変数のType(タイプ)は、機械学習アルゴリズムを適用する前の前処理の方法を定義するためとても重要です。
- Numericalは、実数値。整数または、小数を含む数値です。
- Categoricalは、赤/青/緑や郵便番号、性別などの名目上の値を持つ変数です。また、数値のように見える変数が、実はカテゴリ変数である場合がよくあります。例えば、実際の値の代わりに「id」が使用される場合です。
- Textは、ツイートや顧客レビューなどのテキストデータです。Dataiku DSSは、特定の前処理を使って処理することができます。
各タイプは異なる方法で処理できます。例えば、数値のage_first_orderとpages_visited_avgは、標準的な方法(平均0および分散1を持つように縮尺を変更)で自動的に正規化されます。リストで両方の名前を選択し、No rescalingボタンを選択することで、この正規化を無効にできます。
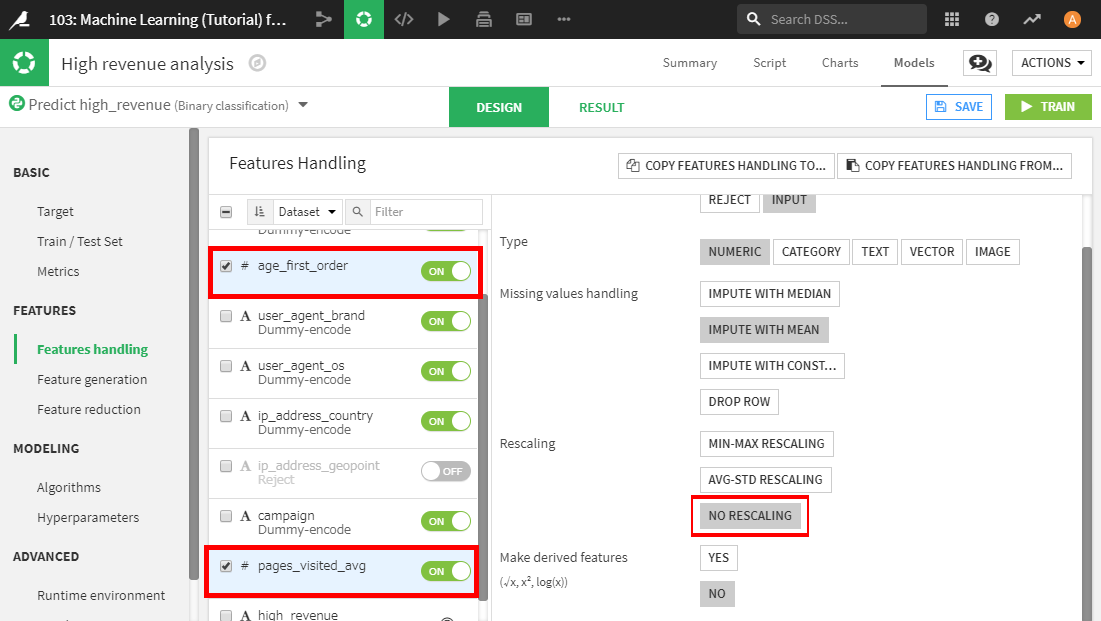
これら設定の変更後、Trainを選択すると新しいモデルが作成されます。
チュートリアルでは、ランダムフォレストモデルの性能がわずかに向上するとありましたが、今回はデフォルトの設定よりも性能はわずかに低下する結果でした。

7.新規特徴量の作成
Design画面を開き、Feature generationタブを選択します。既存の数値の特徴量のPairwise linear combinationsとPolynomial combinationsを使用して、新しい数値の特徴量を自動生成することができます。これらの特徴量生成方法を選択し、EnableをYesに設定します。しばしば、新しく生成された特徴量により、説明変数と目的変数の予期しない関係が明らかになる場合があります。
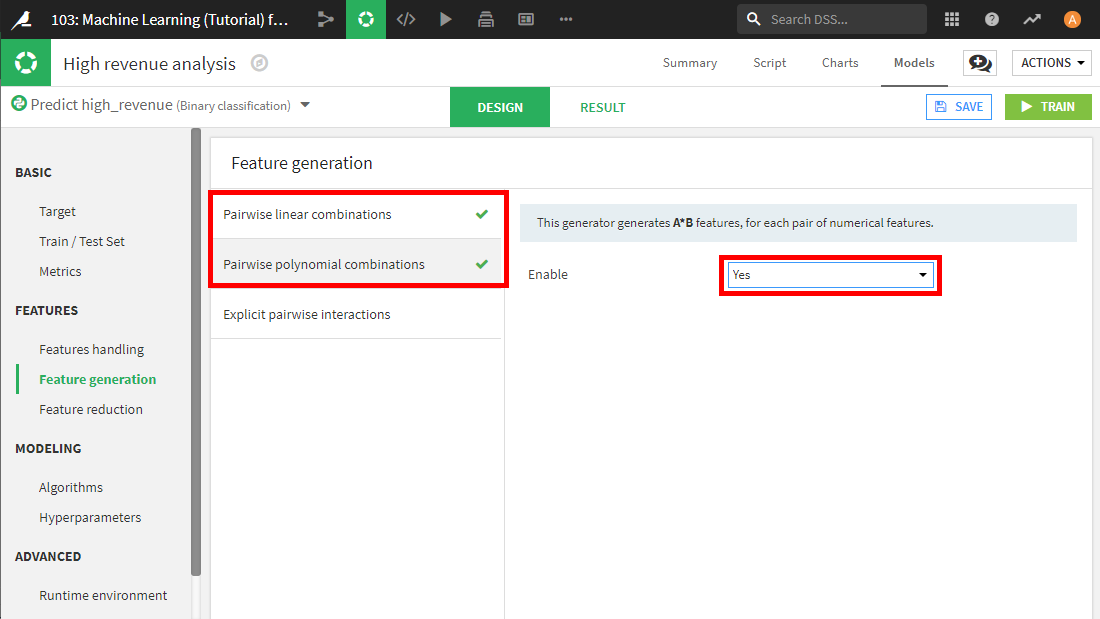
設定が終わったら、Trainボタンを選択すると、モデルを作成できます。
チュートリアルでは、新規特徴量を加えたランダムフォレストモデルのAUCが最大になるとありましたが、今回は最大にはなりませんでした。

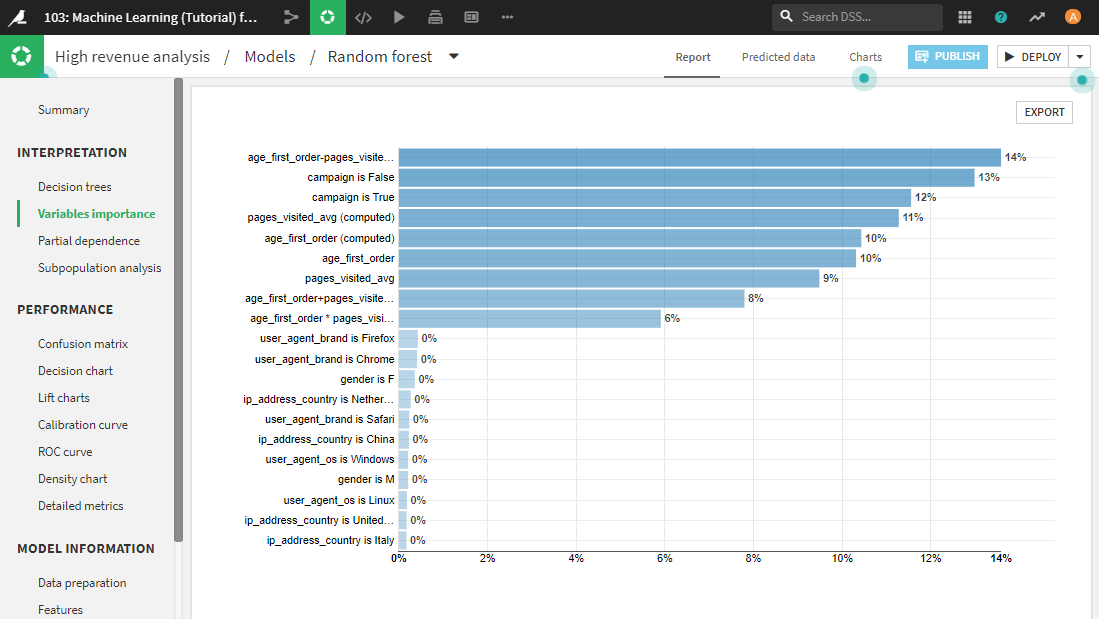
最新モデルのVariables importanceグラフを見ると、age_first_orderおよびpages_visited_avgから自動生成された特徴量の重要度が高いことがわかります。これは、隠れた関係を明らかにした可能性がありますが、AUCは改善していないので、深読みしなくてよいかもしれません。
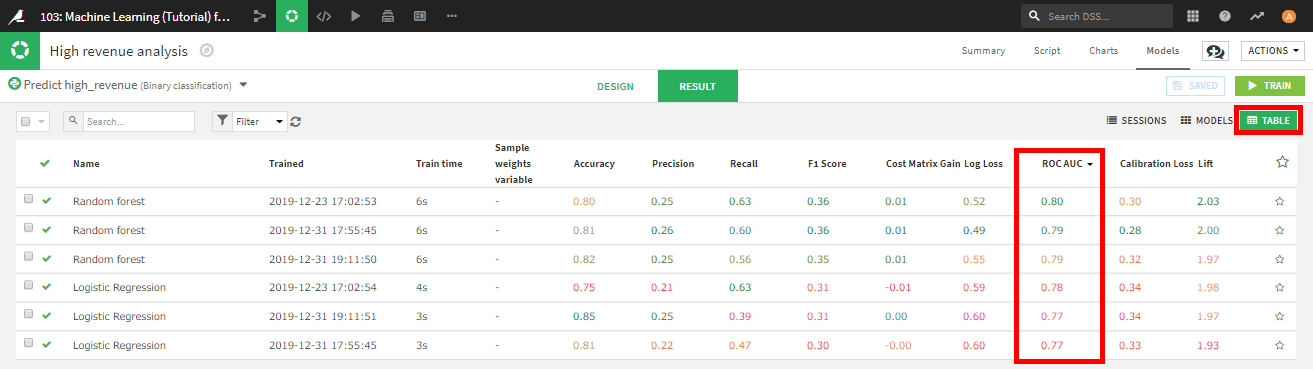
複数のモデルを作成したので、全ての結果が画面に収まらない可能性があります。全てのモデルを一目で確認するには、Tableビューに切り替えます。任意の列で並べ替えることができます。今回はROC AUCでソートしました。
8.さいごに
Dataiku DSSを使用して優良顧客予測モデルを作成しました。
作成したモデルのでデプロイや新しいデータにモデルを適用する方法については Model Scoring tutorialをご覧ください。