やりたいこと
√2(1.41421356...)のような小数部を100桁までSQLだけを使って算出する。
動機
複雑なSQLを書いたり読んだりする際のスピードを上げたく、
いい感じのアルゴリズム問題を探していたら開平法の存在を知り、実装してみたくなった次第。
あと、SQLはプログラミング言語ではない(だって、順次・分岐・反復の処理ができないから)と主張する層に
このくらいまではできるぞと示せる記事があってもいいんじゃないかという気持ち。
※業務用ではないです。
動作環境
PostgreSQL(PostgreSQL 10.5, compiled by Visual C++ build 1800, 64-bit)を使用。
※基本的に標準SQLにある程度対応しているDBであれば多少記述の仕方が違うだけで実装は可能です。
※MySQL5.7以下だとWITH句がないですが、ユーザ定義変数を上手いこと使えば実装できると思います。
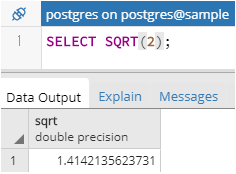
ちなみに、標準で用意されているSQRT関数だと結果がdouble precision型になるので、小数部は13桁までしか表示されないようです。
開平法について
√2を小数表現に変換する計算方法として開平法があるので、今回はそちらのアルゴリズムをそのままSQLに変換していきます。
開平法については 開平法のやり方と原理 | 高校数学の美しい物語 に既にわかりやすい説明があるのでそちらをご参照ください。
実装したクエリ
以下、実装したクエリです。
SQLですがテーブル作成はせずに1回のクエリ実行で算出できるようにしました。
※なお、√1.44などのパターンは気力の問題で対応してません。
※eosr.digit > -100 の部分を10000にすれば1万桁まで算出できました。自分の環境では30秒程度かかるようです。
SQLによる開平法の実装
WITH RECURSIVE
-- 引数関連 ----------------------------------------------
-- 開平対象となる数値を指定
args(input_val) AS (
VALUES (2),
(144),
(9801)
),
-- 以降の算出処理用に引数を変換
formatted_args(input_val, val_char, val_len) AS (
SELECT input_val,
input_val::VARCHAR,
CHAR_LENGTH(input_val::VARCHAR)
FROM args
),
-- 開平対象値を右から2桁区切りで分割
two_digits_unordered(input_val, splitted_args_val, digit, val_char, val_len) AS (
SELECT input_val,
SUBSTRING(val_char FROM val_len - 1 FOR 2),
2,
val_char,
val_len
FROM formatted_args
UNION ALL
SELECT input_val,
SUBSTRING(val_char FROM val_len - digit - 1 FOR 2),
digit + 2,
val_char,
val_len
FROM two_digits_unordered
WHERE digit < val_len
),
two_digits(input_val, splitted_args_val, digit) AS (
SELECT input_val, splitted_args_val, digit / 2
FROM two_digits_unordered
ORDER BY input_val, digit DESC
),
-- 定数テーブル ----------------------------------------------
-- 数値(0~9)を定義
numbers(val) AS (
VALUES (0), (1), (2), (3), (4), (5), (6), (7), (8), (9)
),
-- 1以上100未満の平方を定義
squares_lt_100(root, square) AS (
SELECT 1,
POWER(1, 2)::INTEGER
UNION ALL
SELECT root + 1,
POWER(root + 1, 2)::INTEGER
FROM squares_lt_100
WHERE POWER(root + 1, 2) < 100
),
-- 開平法ロジック --------------------------------------------
extraction_of_square_root(input_val, ans, digit, summation, difference) AS (
SELECT td.input_val,
s1.root::VARCHAR,
(CHAR_LENGTH(td.input_val::VARCHAR) - 1) / 2,
(s1.root + s1.root)::NUMERIC,
(
(td.splitted_args_val::INTEGER - POWER(s1.root, 2))::VARCHAR
|| COALESCE((
SELECT splitted_args_val
FROM two_digits AS td3
WHERE td.input_val = td3.input_val
AND td3.digit = td.digit - 1
), '00')
)::NUMERIC
FROM (
SELECT td1.input_val, td1.splitted_args_val::INTEGER, td1.digit
FROM two_digits AS td1
WHERE td1.digit = (
SELECT MAX(td2.digit)
FROM two_digits AS td2
WHERE td1.input_val = td2.input_val
)
) AS td
JOIN squares_lt_100 AS s1
ON s1.square <= td.splitted_args_val
AND s1.root = (
SELECT MAX(root)
FROM squares_lt_100 AS s2
WHERE s2.square <= td.splitted_args_val
)
UNION ALL
SELECT eosr.input_val,
num1.val::VARCHAR,
eosr.digit - 1,
(eosr.summation::VARCHAR || num1.val::VARCHAR)::NUMERIC + num1.val,
(
(eosr.difference - (eosr.summation::VARCHAR || num1.val::VARCHAR)::NUMERIC * num1.val)::VARCHAR
|| COALESCE((
SELECT td.splitted_args_val
FROM two_digits AS td
WHERE eosr.input_val = td.input_val
AND td.digit = eosr.digit - 1
), '00')
)::NUMERIC
FROM extraction_of_square_root AS eosr
JOIN numbers AS num1
ON (eosr.summation::VARCHAR || num1.val::VARCHAR)::NUMERIC * num1.val <= eosr.difference
AND num1.val = (
SELECT MAX(num2.val)
FROM numbers AS num2
WHERE (eosr.summation::VARCHAR || num2.val::VARCHAR)::NUMERIC * num2.val <= eosr.difference
)
WHERE eosr.difference <> 0 AND eosr.digit > -100
),
-- 数字の整形処理 -------------------------------------------------------
plus_ans(input_val, val) AS (
SELECT input_val, ARRAY_TO_STRING(ARRAY_AGG(plus.ans ORDER BY plus.digit DESC), '')
FROM extraction_of_square_root AS plus
WHERE plus.digit >= 0
GROUP BY input_val
),
minus_ans(input_val, val) AS (
SELECT input_val, '.' || ARRAY_TO_STRING(ARRAY_AGG(minus.ans ORDER BY minus.digit DESC), '')
FROM extraction_of_square_root AS minus
WHERE minus.digit < 0
GROUP BY input_val
)
-- 開平値を出力 -------------------------------------------------------------
SELECT input_val AS square, plus.val || COALESCE(minus.val, '') AS square_root
FROM plus_ans AS plus
LEFT JOIN minus_ans AS minus
USING (input_val)
;
解説
以降、上記のクエリの解説を簡単に書いておきます。
WITH句の使い方について
今回のように一回のクエリ実行で値を算出したい場合、WITH句でLinuxのパイプのように処理を繋げて書いていくと
いい感じでクエリが分割できるため便利です。
WITH句で作成する一時的なテーブルの書き方を共通テーブル式といいますが、
今回、大きく2通りの使い方をしています。
WITH句の使い方1:再帰WITH句によるループ処理
再帰クエリあまり書く機会ないと最初は読みづらいですが、以下のように解釈すると入りやすいのではないかと思ってます。
WITH RECURSIVE
-- ループ処理を実装したい場合
`共通テーブル式名`('列名1', ...) AS (
['初期化処理'] -- 最初だけ実行
UNION ALL -- 他の集合演算子でも可能ですが、ループ処理したい場合はだいたいこれ
['ループ処理'] -- WHERE句の条件がFALSEになるまで実行。(FALSEになった最初の行は結果として含まれる点に注意!)
)
WITH句の使い方2:共通テーブル式で定数を定義
今回のよううに0~9の数値を単純に定数として持っておきたい場合、
共通テーブル式で定義しておくと以降のクエリがよりシンプルになりやすいです。
共通テーブル式で定義した値は定義した後で変更することができないので、文字通り定数扱いになります。
WITH
`共通テーブル式名`('列名1', ...) AS (
['定数テーブル']
)
各共通テーブル式の依存関係と処理の流れ
今回定義した共通テーブル式は全部で9つあるわけですが、
それぞれの依存関係は図にすると以下のようになっています。
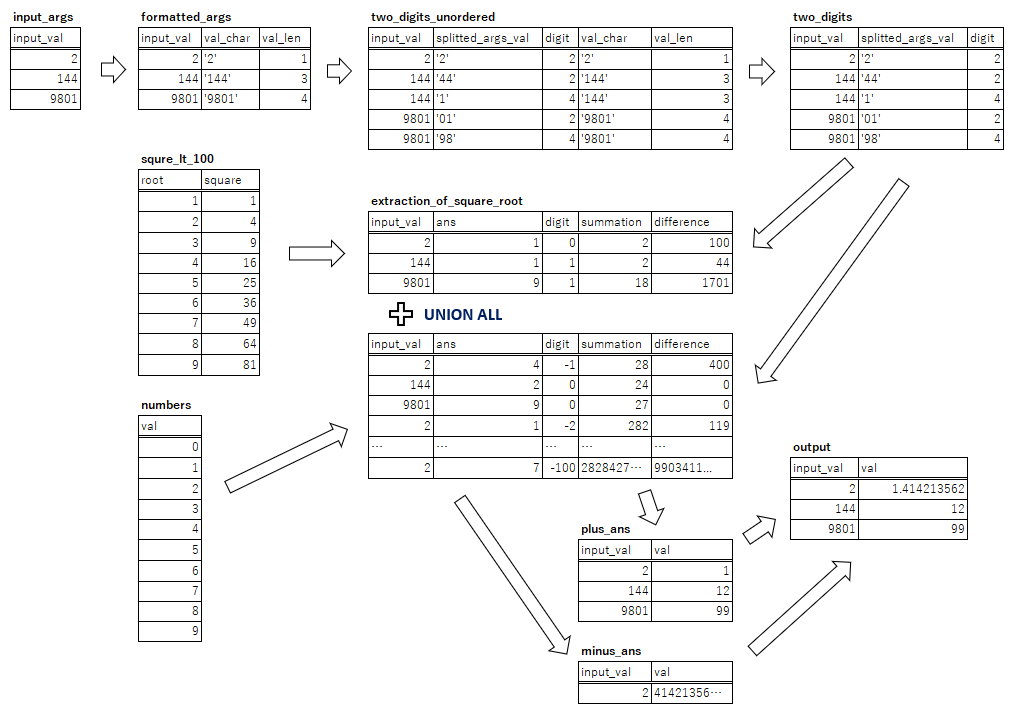
こう見ると100行以上のSQLの概要が掴めやすいですね。
WITH句の共通テーブル式でLinuxのパイプみたいに前の処理結果を受けてを繰り返して処理していく場合、
いくつ書いてもこの図のような閉路のない依存関係を構成するようになります。