【注意】本記事は適宜更新します.
概要
衛星画像には30cmの高分解能のものから,Copernicusで無料で提供されている10mの中分解能のものと,解像度がそれぞれ異なります.高い解像度のものを使いたいのですが,高価なため入手するのは難しいです.でも,目的によってはそれほどの解像度は不要なのではと考え,車を検出することをターゲット として実験しました.

(credit: Cars Overhead With Context (COWC))
ここで用いたコードは近々整理し,Githubにてシェアします.
1. 衛星画像の分解能と物体検知のレベルについて.
**衛星画像でどこまで見えるのか?例えば,報告されているものに以下があります.

(credit: FAS, Intelligence Resource Program)
ここでは,10cm分解能であれば一つ一つの車がわかり,25cm分解能で車の区別は可能,50cm分解能では車種まではわからず,1m分解能になると車とはわかるけども,車種までわからない,と報告されています.
これは20年以上前の評価であり,このときの”見える,見えない”**は,人が”見える,見えない”が判断基準であり,人によっては見え方も異なり,統一されていません.また,現在であれば衛星画像から人が判読するよりも,機械に自動で判読させるほうが,品質および処理速度を考えると望ましい(当たり前?)であると思います.
では,どこまで見えるのだろう?,ということで実験してみます.
1.1 衛星画像の分解能について
衛星画像の分解能については,以下の宙畑さんの記事がよくまとめられていますので,ご参考にしてください.
人工衛星から人は見える?~衛星別、地上分解能・地方時まとめ~
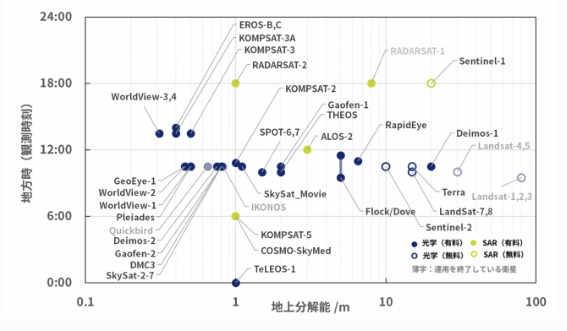
(クレジット:宙畑)
この図から,**一番高い分解能が30cm(WorldView-3,4)**であることがわかります.縦軸は地方時といって,観測時刻と思ってください.(この図のみ横軸のスケールが記載されていたので用いました.)
また,高い分解能の衛星画像は非常に高価になります.
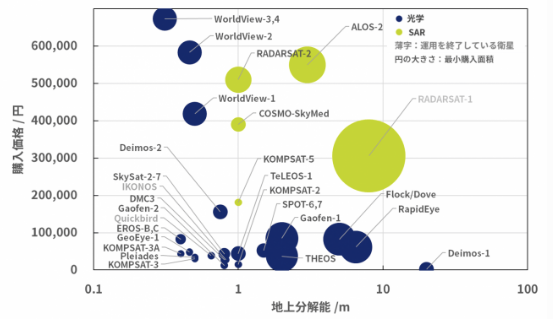
(クレジット:宙畑)
高い分解能の画像ほどきれいな画像なのでほしいのですが,目的によってはそこまでの分解能の画像は必要ないかもしれません.価格を低く抑えられるのであれば,より広範囲や異なる時期の多数の画像を入手できますね.
1.2 航空写真による車検知について.
下記の記事で紹介しましたが,航空写真より車の検出精度を競うプログラムに, Cars Overhead With Context (COWC)があります.
PyTorchによる人工衛星画像から車の推定分布地図を作成してみる.
ここでは,4カ国・6都市の航空写真(15cm分解能)の画像が提供されており,それぞれ一般自動車(トラックや重機は含まれません)の中心位置と間違うかもしれない物体の位置のアノテーションデータがセットで提供されています.
今回の評価ではこのデータ・セットを用いました.まずは,15cmの分解能の画像より得られた車の検出率を基準として,画像をResizeすることで擬似的に分解能を落とし,その検出精度がどのようになるのか調べます.
こちらにこのデータセットを用いた論文が紹介されていますが,極めて高い精度で検出できることが報告されています.興味のある方は,ご参考にしてください.
1.3 物体検知モデル
物体検知(Object Detection)としては,有名なSSDやその他各種の手法があります.今回は,最近リリースされたYOLO v5 を用いました.
Yolo(You Only Look Once)は有名なので多くの方がご存知かと思いますが,画像や動画より物体の位置と種類を検出する機械学習アルゴリズムです.そのVersion5が今年の春にリリースされました.(過去のYoloの開発者と異なるため,これをv5と言ってもよいのか,議論されているみたいです.)

(credit:YOLO v5)
このアルゴリズムの精度評価が掲載されています.
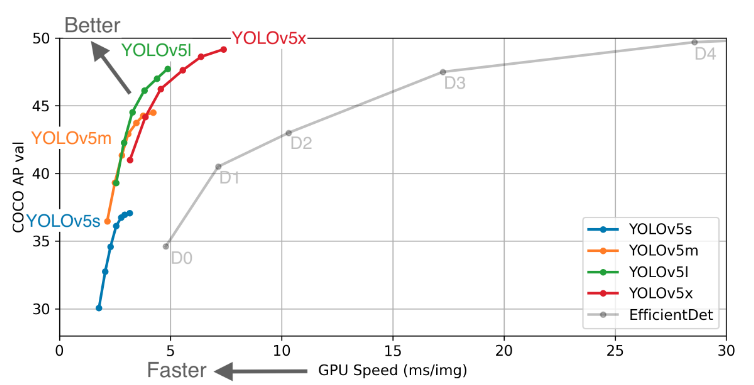
動画での高い精度の適用が考えられており,他のモデル(Efficient Det)と比べて高い精度で速く検知できるかが特徴になります.
今回は,航空写真や衛星画像は静止画像ですので,一番精度の高いYOLOv5xを用いることとしました.
2.異なる解像度の航空写真・衛星画像から車を検出してみる.
2.1 環境構築(YOLOv5を準備する.).
YOLOv5のサイトより以下のコマンドでモデルをダウンロードします.(私はYOLOv5の仮想環境を構築し,その環境で使用しています.)
git clone https://github.com/ultralytics/yolov5.git
次に,yolov5を動作させるために,必要なモジュールを下記のコマンドより準備します.
pip install -r requirements.txt
こちらのコマンドにより,以下のモジュールがインストールされます.
Cython
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3
scipy>=1.4.1
tensorboard>=2.2
torch>=1.6.0
torchvision>=0.7.0
tqdm>=4.41.0
これでYolov5が利用できる環境が整いました.ここからは,動作を確認するために,jupyter labで実行します.
次に,今回は画像分類で有名なcocoのパラメータをベースとしたFine tuningを行います.そのため,必要なWeightsをダウンロードします.以下のサイトから必要なWeightsをダウンロードし,YOLOv5に置きます.
これでYolov5を用いる環境が構築できましたので,次に学習データである航空写真データを取得します.
2.2 COWCより学習データの取得,およびデータの前処理.
1.1項で述べたように,航空写真およびそのアノテーションデータ(車と非車の位置情報)をCOWCのサイトよりダウロードします.サイトの下部にダウンロード方法がいくつか紹介されていますが,私はhttpよりファイル(cowc-everything.txz)を選びダウンロードしました.
ダウンロードしたファイルは圧縮されていますので,解凍して以下のファイルを確認します.

ディレクトリ名は都市名になっており,そこに航空写真(png)とその画像のアノテーションデータ(車(annotated_cars)と非車(annotated_negatives)のpng)があります.
航空写真は学習時のimage sizeに分割し,アノテーション画像からはYOLOv5に用いるための位置情報のtxtを作成します.その手順を紹介します.
はじめに使用するモジュールを宣言します.
import os
import shutil
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
import cv2
import pandas as pd
Image.MAX_IMAGE_PIXELS = 1000000000
次に,都市名のディレクトリ構成を確認します.
dir_path = "../cowc/"
dirs =os.listdir(dir_path)
dirs
出力が以下となります.
['Toronto_ISPRS',
'Potsdam_ISPRS',
'Vaihingen_ISPRS',
'Utah_AGRC',
'Columbus_CSUAV_AFRL',
'Selwyn_LINZ',]
'Vaihingen_ISPRS'と 'Columbus_CSUAV_AFRL'はモノクロ画像でしたので,今回の対象から省きました.
では, Toronto_ISPRSのファイルを確認し,航空写真の確認,リサイズによる衛星画像のシミュレーション,アノテーション画像よりYOLOv5を実行するための位置情報のtxtファイルを作成します.
dirs_image = dirs[0]
image_path = dir_path + dirs_image
image_files =os.listdir(image_path)
image_files
こちらを実行することで,ディレクトリ内のファイル情報を取得します.出力結果がこちらとなります.
['03553.png',
'03553_Annotated.xcf',
'03553_Annotated_Cars.png',
'03559_Annotated_Cars.png',
'03559_Annotated_Negatives.png',
'03559.png',
'03747_Annotated_Negatives.png',
'README.ISPRS.txt',
'03747.png',
'03747_Annotated.xcf',
'03559_Annotated.xcf',
'03553_Annotated_Negatives.png',
'03747_Annotated_Cars.png']
これより,都市の航空写真とそのファイルと同じ名前と車の位置情報画像(Annotated_Cars)と非車の位置情報画像(Annotated_Negatives)で構成されているのがわかります.まず,航空写真のファイルのみを選択します.
# RGB画像のみのファイルリストを作成する.
file_name =[]
for i in image_files:
if 'Annotated'in i:
pass
else:
if 'png' in i:
file_name.append(i)
else:
pass
file_name
上記を実行すると,以下のファイルであることがわかります.
['03553.png', '03559.png', '03747.png']
では,03553.pngの航空写真を確認します.
file_image_name = file_name[0]
# opencvで画像のよみこみ
im = cv2.imread(dir_path + dirs_image +'/'+ file_image_name)
print(im.shape)
print(file_image_name)
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
plt.imshow(im_rgb)

カナダの都市トロントの都市域の航空写真です.一部を拡大してみます.
plt.imshow(im_rgb[0:500,100:1500])

車が多数写っているのがわかります.では,この画像を512x512の画像サイズに分割します.このとき,航空写真から衛星画像の分解能の異なる模擬画像を作成するため分解能を設定します.ここでは,現在の画像サイズの1/2や1/4とすることで,その解像度を低下させます.
# 分解能に合わせて,リサイズの分母を決める.
# 分解能30cmだと2,60cmで4,90cmで6となる.
rs = 1 #1, 2, 4, 6
im=Image.open(dir_path + dirs_image +'/'+ file_image_name)
img_resize = im.resize((im.size[0]//rs, im.size[1]//rs)) #ここで解像度をリサイズして変更している.
print(file_image_name)
file_name = os.path.splitext(os.path.basename(file_image_name))[0]
print(file_name)
DIR_OUTPUTS = '../cowc/crop_image'
height = 512
width = 512
img_size_v = img_resize.size[1]
img_size_h = img_resize.size[0]
# 画像の分割処理関数
def ImgSplit(im):
# 読み込んだ画像を512x512の画像サイズに分割する
buff = []
# 縦の分割枚数
for v1 in range(int(img_size_v/height)):
# 横の分割枚数
for h1 in range(int(img_size_h/width)):
h2 = h1 * width
v2 = v1 * height
#print(w2, h2, width + w2, height + h2)
c = im.crop((h2, v2, width + h2, height + v2))
buff.append(c)
return buff
# 画像の分割処理の実行
hi=0
for ig in ImgSplit(img_resize):
hi=hi+1
#print(hi)
# 保存先フォルダの指定
ig_jpeg = ig.convert('RGB')
ig_jpeg.save(DIR_OUTPUTS + "/" + str(file_name) + '_' + str(hi) + ".jpg") #yolo v5にはpngはNG?
このとき,2行目のresize関数にて画像の分解能をシミュレートします.後半でResizeした画像を512で分割し,DIR_OUTPUTS に保存します.
次に,アノテーション画像を同様の処理を行います.
im=Image.open(dir_path + dirs_image +'/'+ file_name + '_Annotated_Cars.png')
img_resize = im.resize((im.size[0]//rs, im.size[1]//rs)) #ここで解像度をリサイズして変更している.
print(file_name + '_Annotated_Cars.png')
print(file_name)
DIR_OUTPUTS_p = '../cowc/crop_annotated'
height = 512
width = 512
img_size_v = img_resize.size[1]
img_size_h = img_resize.size[0]
# 画像の分割処理関数
def ImgSplit(im):
# 読み込んだ画像を256*256のサイズで144枚に分割する
buff = []
# 縦の分割枚数
for v1 in range(int(img_size_v/height)):
# 横の分割枚数
for h1 in range(int(img_size_h/width)):
h2 = h1 * width
v2 = v1 * height
c = im.crop((h2, v2, width + h2, height + v2))
buff.append(c)
return buff
# 画像の分割処理の実行
hi=0
for ig in ImgSplit(img_resize):
hi=hi+1
# 保存先フォルダの指定
ig.save(DIR_OUTPUTS_p + "/" + str(file_name) + '_' + str(hi) + ".png")
この処理を行うことによって,車のアノテーション画像がリサイズされ512サイズに分割されます.同じく,非車のアノテーション画像も同様の処理を行います.
im=Image.open(dir_path + dirs_image +'/'+ file_name + '_Annotated_Negatives.png')
img_resize = im.resize((im.size[0]//rs, im.size[1]//rs)) #ここで解像度をリサイズして変更している.
print(file_name + '_Annotated_Negatives.png')
print(file_name)
DIR_OUTPUTS_n = '../cowc/crop_annotated_negatives'
height = 512
width = 512
img_size_v = img_resize.size[1]
img_size_h = img_resize.size[0]
# 画像の分割処理関数
def ImgSplit(im):
# 読み込んだ画像を512*512のサイズに分割する
buff = []
# 縦の分割枚数
for v1 in range(int(img_size_v/height)):
# 横の分割枚数
for h1 in range(int(img_size_h/width)):
h2 = h1 * width
v2 = v1 * height
c = im.crop((h2, v2, width + h2, height + v2))
buff.append(c)
return buff
# 画像の分割処理の実行
hi=0
for ig in ImgSplit(img_resize):
hi=hi+1
# 保存先フォルダの指定
ig.save(DIR_OUTPUTS_n + "/" + str(file_name) + '_' + str(hi) + ".png")
アノテーション画像は分割後にそれぞれ,'../cowc/crop_annotated'と'../cowc/crop_annotated_negatives'に保存されます.
次に,分割したアノテーション画像から,車および非車位置のtxtデータを作成します.このtxtデータは,Yoloのフォーマットにあわせて作成します.
YOLOのアノテーション情報(txt)は以下のフォーマットとなります.
# class x_center y_center width height #
Classは車であれば0,非車は1に,x-center, y-centerは対象の中心位置,widthとheightは対象物体の周囲枠(Box)のサイズとなります.
このサイズは,ここでは**20ピクセル(300cm)**としました.車の縦幅より小さいですが,狭い間隔で駐車している車も識別したいため,まずはこの値としました.解像度を変えた場合,このピクセル値も300cmにあわせてみましたが,それよりも20ピクセルのまま(解像度によってBox値を変えた)場合のほうがPrecisionが高かったため,20ピクセルで固定しました.ここは,解像度によってパラメータを最適化する部分ですね.
今回は,512サイズで統一しましたので,それぞれを512で割って規格化しました.
では,アノテーション画像よりYOLOに用いるアノテーションファイルを作成します.
DIR_OUTPUTS_labels = '../cowc/crop_label'
for i in range(len(os.listdir(DIR_OUTPUTS))):
crop_file_name_jpg = os.path.splitext(os.path.basename(crop_file_name[i]))[0]
im = cv2.imread(DIR_OUTPUTS_p + '/' + crop_file_name_jpg +'.png')
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
row, cow = np.where(im_rgb==76)
arr = []
for ii in range(len(row)):
arr.append([row[ii],cow[ii]])
arr = np.array(arr)
if not len(arr) == 0:
array_pd = pd.DataFrame(arr)
array_ppd = array_pd.copy()
array_pd[0] = array_ppd[1]/512
array_pd[1] = array_ppd[0]/512
array_pd[2] = 20/512
array_pd[3] = 20/512
array_pd.insert(0,'car',0)
else:
array_pd = pd.DataFrame()
im = cv2.imread(DIR_OUTPUTS_n + '/' + crop_file_name_jpg +'.png')
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
row, cow = np.where(im_rgb==29)
arr = []
for ii in range(len(row)):
arr.append([row[ii],cow[ii]])
arr = np.array(arr)
if not len(arr) == 0:
array_nd = pd.DataFrame(arr)
array_nnd = array_nd.copy()
array_nd[0] = array_nnd[1]/512
array_nd[1] = array_nnd[0]/512
array_nd[2] = 20/512
array_nd[3] = 20/512
array_nd.insert(0,'car',1)
else:
array_nd = pd.DataFrame()
array_all = []
array_all = pd.concat([array_pd, array_nd])
text_name = crop_file_name_jpg
array_all.to_csv(DIR_OUTPUTS_labels + '/' + text_name + '.txt', sep=' ', index=False, header=False)
アノテーションファイルは以下に**'../cowc/crop_label'**保存されます.
例えば,以下となります.
0 0.966796875 0.248046875 0.0390625 0.0390625
0 0.896484375 0.26953125 0.0390625 0.0390625
0 0.82421875 0.291015625 0.0390625 0.0390625
0 0.490234375 0.32421875 0.0390625 0.0390625
0 0.55859375 0.375 0.0390625 0.0390625
0 0.5625 0.375 0.0390625 0.0390625
0 0.470703125 0.408203125 0.0390625 0.0390625
0 0.3828125 0.43359375 0.0390625 0.0390625
0 0.037109375 0.45703125 0.0390625 0.0390625
0 0.29296875 0.4609375 0.0390625 0.0390625
0 0.0625 0.53515625 0.0390625 0.0390625
1 0.83984375 0.541015625 0.0390625 0.0390625
1 0.873046875 0.625 0.0390625 0.0390625
1 0.763671875 0.630859375 0.0390625 0.0390625
1 0.314453125 0.6484375 0.0390625 0.0390625
1 0.65625 0.666015625 0.0390625 0.0390625
1 0.75390625 0.8125 0.0390625 0.0390625
1 0.41796875 0.986328125 0.0390625 0.0390625
この処理をそれぞれの都市で行い,Train用およびValidation用の画像とアノテーションファイルを準備します.このとき,Train用とValidation用のデータは分け,その割合は約7:3となります.
2.3 航空写真によるモデルの構築と検証.
YOLOv5のモデルは,githubのチュートリアルを参考に実行します.
はじめに必要なモジュールをインポートします.
import torch
from IPython.display import Image, clear_output # to display images
clear_output()
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
次に,学習結果を可視化するためにTensorboardを実行します.
# Start tensorboard
%load_ext tensorboard
%tensorboard --logdir runs
ここでTensorboardを実行状態すると,学習後にRecallやPrecisionなどの学習結果のグラフ化や異なる学習の比較を行うのに便利です.
そして,次のコマンドで学習を始めます.
%cd ../yolov5
!python train.py --img 512 --batch 5 --epochs 100 --data ../cowc/data_resize_30cm.yaml --cfg models/yolov5x.yaml --nosave --cache --name cowc_test_15cm_ep100 --weights yolov5x.pt
--img : 学習画像のサイズ
--bath :バッチサイズ
--epochs : エポック数
--data :train およびvalidationデータの場所とクラスの設定
--cfg :用いるモデルの設定
--name :学習名
--weights : fine tuningを行うときは,ここで設定します.
詳細は,train.py --helpを実行すると,各パラメータの説明があるのでご参照ください.ここでは,データを示data.yamlについて説明します.
train: ../cowc/data_train
val: ../cowc/data_val
nc: 2
names: ['car', 'not_car']
上記の通り,trainとvalのデータのアドレス,およびクラス数とその名前を設定しています.
trainとvalディレクトリにはimagesとlabelsのディレクトリがあり,imagesに画像ファイルが,labelsにアノテーションファイルが入っています.この画像とアノテーションファイルは同じファイル名(拡張子は異なる)である必要があります.ご注意ください.
Test用の画像およびモデルにて車検出後の画像の合成を行います.
dir_path = "../cowc/"
dirs =os.listdir(dir_path)
dirs_image = dirs[0] #'Toronto_ISPRS'
image_path = dir_path + dirs_image
image_files =os.listdir(image_path)
# RGB画像のみのファイルリストを作成する.
file_name =[]
for i in image_files:
if 'Annotated'in i:
#print(i)
pass
else:
if 'png' in i:
file_name.append(i)
else:
pass
file_image_name = file_name[2] #'03747.png'
まずは,Train用の画像準備と同じく対象となる画像を選択します.では,画像を確認します.
# opencvで画像のよみこみ
im = cv2.imread(dir_path + dirs_image +'/'+ file_image_name)
print(file_image_name)
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
# Image.fromarray(im_rgb).save('test.jpg')
plt.imshow(im_rgb)
それでは,この画像を512サイズに分割してTest用の画像を準備します.方法はTrainと同じです.
DIR_OUTPUTS = '../cowc/test_512/images_resize/'
im=Image.open(dir_path + dirs_image +'/'+ file_image_name)
img_resize = im.resize((im.size[0]//1, im.size[1]//1))
print(file_image_name)
file_name = os.path.splitext(os.path.basename(file_image_name))[0]
print(file_name)
height = 512
width = 512
img_size_v = img_resize.size[1]
img_size_h = img_resize.size[0]
# 画像の分割処理関数
def ImgSplit(im):
buff = []
# 縦の分割枚数
for v1 in range(int(img_size_v/height)):
# 横の分割枚数
for h1 in range(int(img_size_h/width)):
h2 = h1 * width
v2 = v1 * height
c = im.crop((h2, v2, width + h2, height + v2))
buff.append(c)
return buff
# 画像の分割処理の実行
hi=0
for ig in ImgSplit(img_resize):
hi=hi+1
# 保存先フォルダの指定
ig_jpeg = ig.convert('RGB')
ig_jpeg.save(DIR_OUTPUTS + "/" + str(file_name) + '_' + str(hi) + ".jpg")
その後,分割されたファイル数をx軸(width)とy軸(height)の数を確認します.
img_size_v = int(img_size_v/width)
img_size_h = int(img_size_h/height)
出力が以下となります.
img_size_v * img_size_h #308
img_size_v #14
img_size_h #22
念の為,ファイル数も確認しておきます.
image_list = os.listdir(DIR_INPUTS)
image_list_sort=natsorted(image_list)
len(image_list_sort)
出力
308
これでTest用の画像が準備できました.次に,学習したモデルを用いてテスト画像から車を検出させます.ここでは,Trainに用いた画像ではなくValidationで準備した画像を用いました.
!python detect.py --weights runs/train/cowc_test_15cm_ep100/weights/last.pt --img 512 --conf 0.4 --source ../cowc/test_512/images_resize/ --save-txt --class 0 --name cowc_15cm
--weights: train.pyの実行時に作成したWeightsを呼び出します.ファイル名は,train.pyを実行結果の下部に示されますのでご確認ください.
--img : テスト画像のファイルサイズ
--conf : テスト結果で車の有無を判断するためのしきい値
--source : テスト画像があるディレクトリのアドレス
--save-txt : 検出結果をtxtでも保存
-- class : 識別するクラスの指定.ここでは”0”としたため,車のみを検出します.
--name :検出結果の画像を保存するディレクトリ
解析処理後,データを確認します.このとき,yolov5のdetect.pyをCloneしたまま用いると,検出された車のBoxやその確信度(信頼度,Confidence)が大きく表示されるため,車が密集しているところではその違いが分かり難いです.そのため,utilsディレクトリにあるplot.pyのファイルの解析結果を表示するBoxのライン幅や信頼度のfontサイズを変更しました.コードで提供されているため,自分の利用方法にあわせて変更されることをお薦めします.
では,処理されたTest画像を確認し,合成します.
height = 512 #512
width = 512 #512
DIR_INPUTS = '../yolov5/runs/detect/cowc_15cmresize/'#detect のディレクトリを指定.
DIR_OUTPUTS = '../cowc/test_512/build_picture/' #合成後の画像ファイルのアドレス
image_list = os.listdir(DIR_INPUTS)
image_list_sort=natsorted(image_list)
max_height = width * img_size_v
total_width = height * img_size_h
new_im = Image.new("RGB", (int(total_width), int(max_height)))
h = 0
w = 0
for i in range(img_size_v*img_size_h):
new_im.paste(Image.open(DIR_INPUTS + "/"+ image_list_sort[i]), (w*width,h*height))
w = w +1
if img_size_h - w == 0:
w = 0
h = h +1
new_im.save(DIR_OUTPUTS + 'test_15cm_resize.jpg')
画像の合成後にファイルを確認します.
img = Image.open(DIR_OUTPUTS + 'test_90cm_resize.jpg')
# 画像をarrayに変換
im_list = np.asarray(img)
# 貼り付け
plt.imshow(im_list)
# 表示
plt.show()
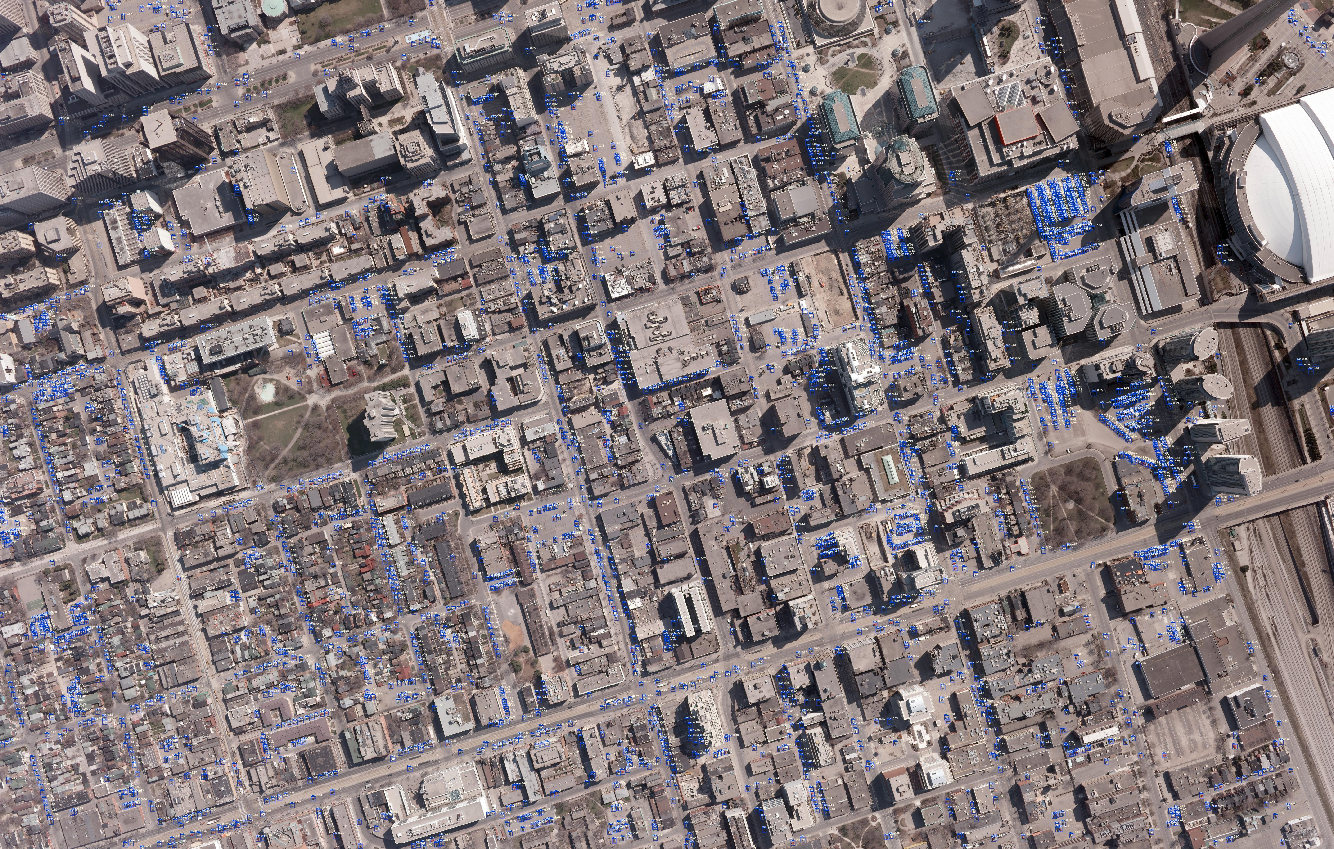
これで,航空写真(15cm分解能)のモデルの構築,およびそのモデルを用いた解析プロダクトが作成できました.画像を拡大して確認してみます.


航空写真(15cm分解能)の解析により検出された車
こちらの航空写真に写っているほぼすべての車が検知されており,その確信度は0.7以上と高い値となっています.
次に,航空写真をResizeすることで分解能を模擬的に低下させ,同様の処理を行い,結果にどのような違いとなるのか,評価してみます.
2.4 異なる解像度の衛星画像と検知精度
コードは2.3項で用いたものと同じになります.ただし,模擬する分解能に合わせてrsの値を変えます.例えば,分解能が半分の30cmにするのであればrsを2にします.
# 分解能に合わせて,リサイズの分母を決める.
# 分解能30cmだと2,60cmで4,90cmで6となる.
rs = 1 #1, 2, 4, 6
TrainデータおよびValデータが作成したのち,前項とおなじくdata.yamlにて対象とするデータのディレクトリを指定し,train.pyを実行します.そして,実行にて作成されたそれぞれのweightを指定して,Test画像(比較のために,すべて同じカナダ・トロントの画像(Validationで使用))に解析処理を行い車を推定します.
それでは,すべての処理画像を比較します.
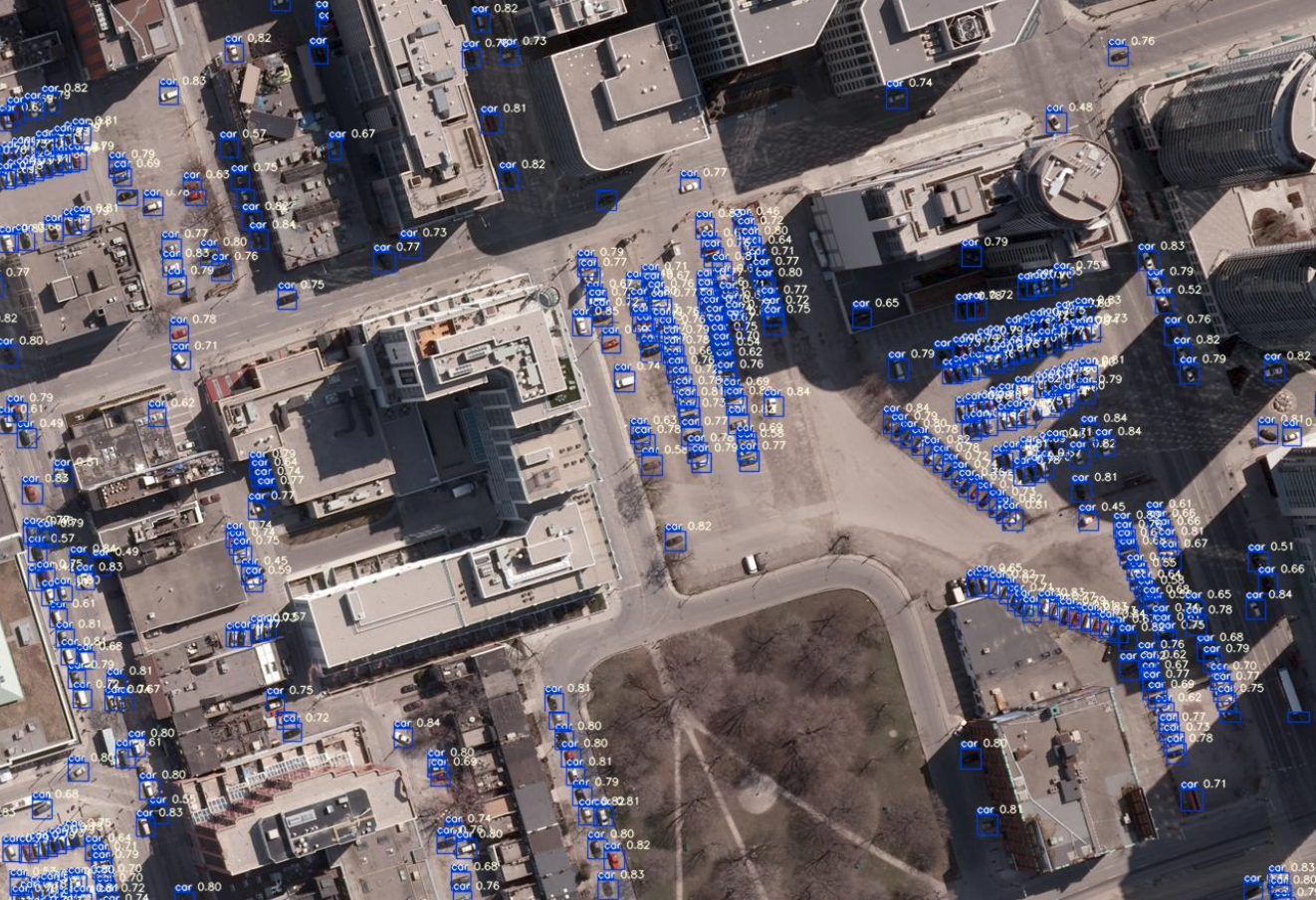
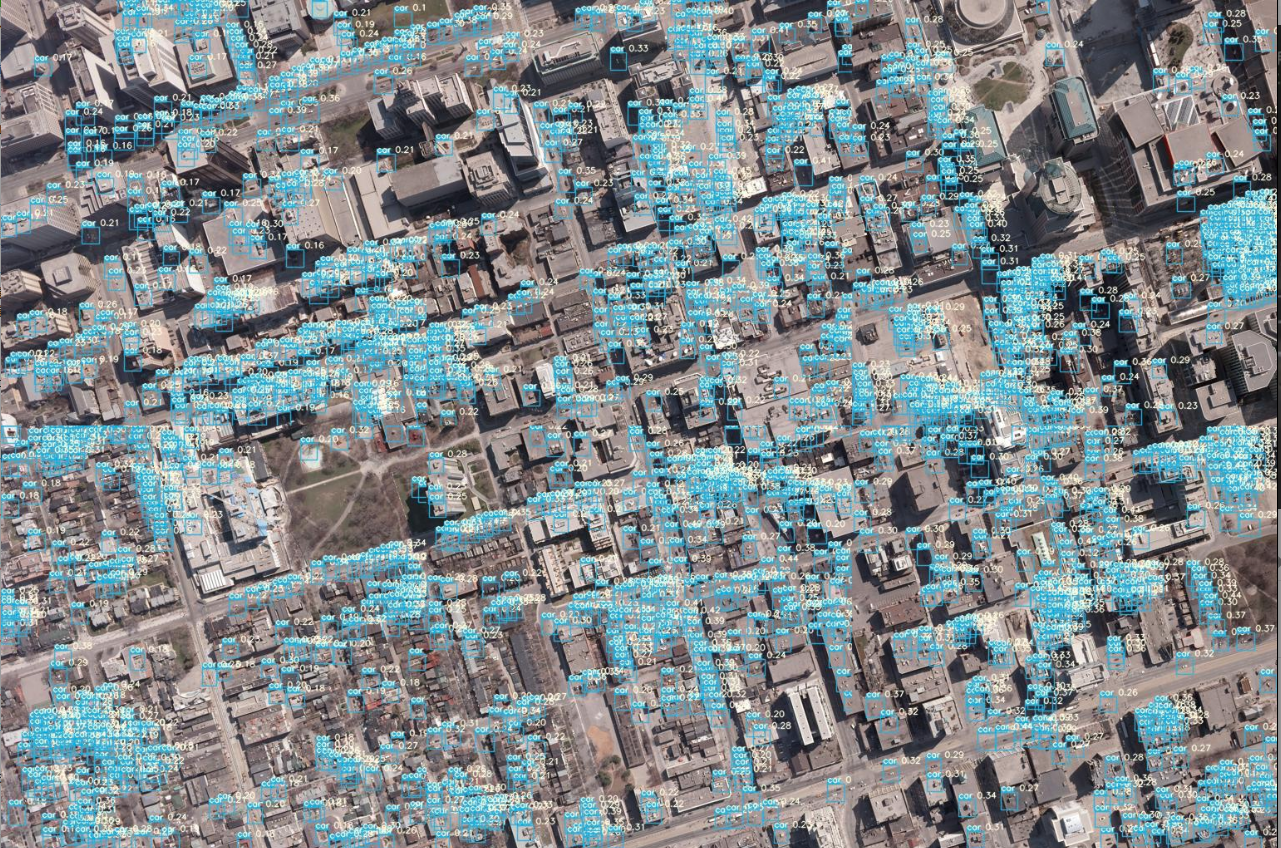
模擬衛星画像(30cm分解能)の解析により検出された車
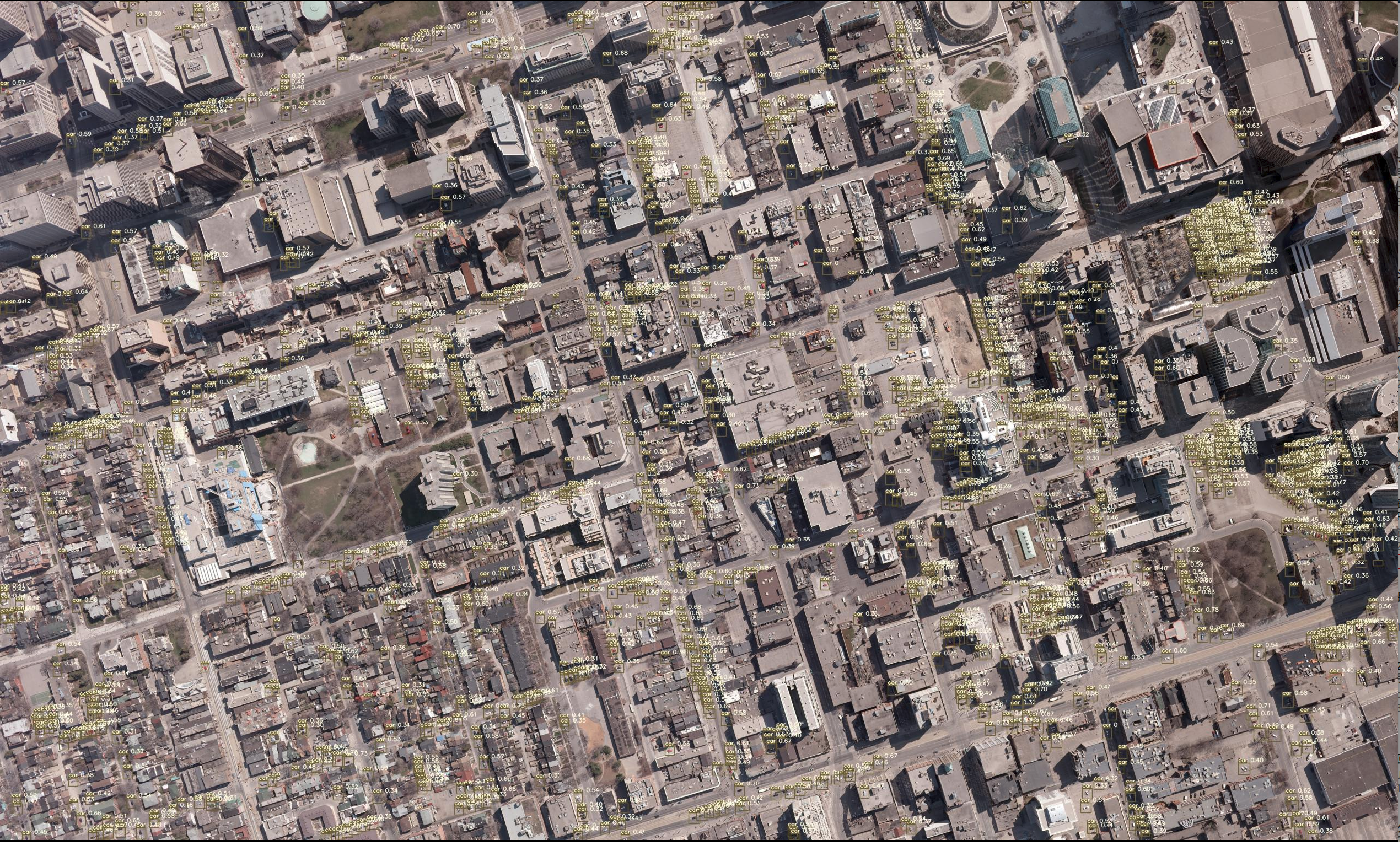

模擬衛星画像(60cm分解能)の解析により検出された車
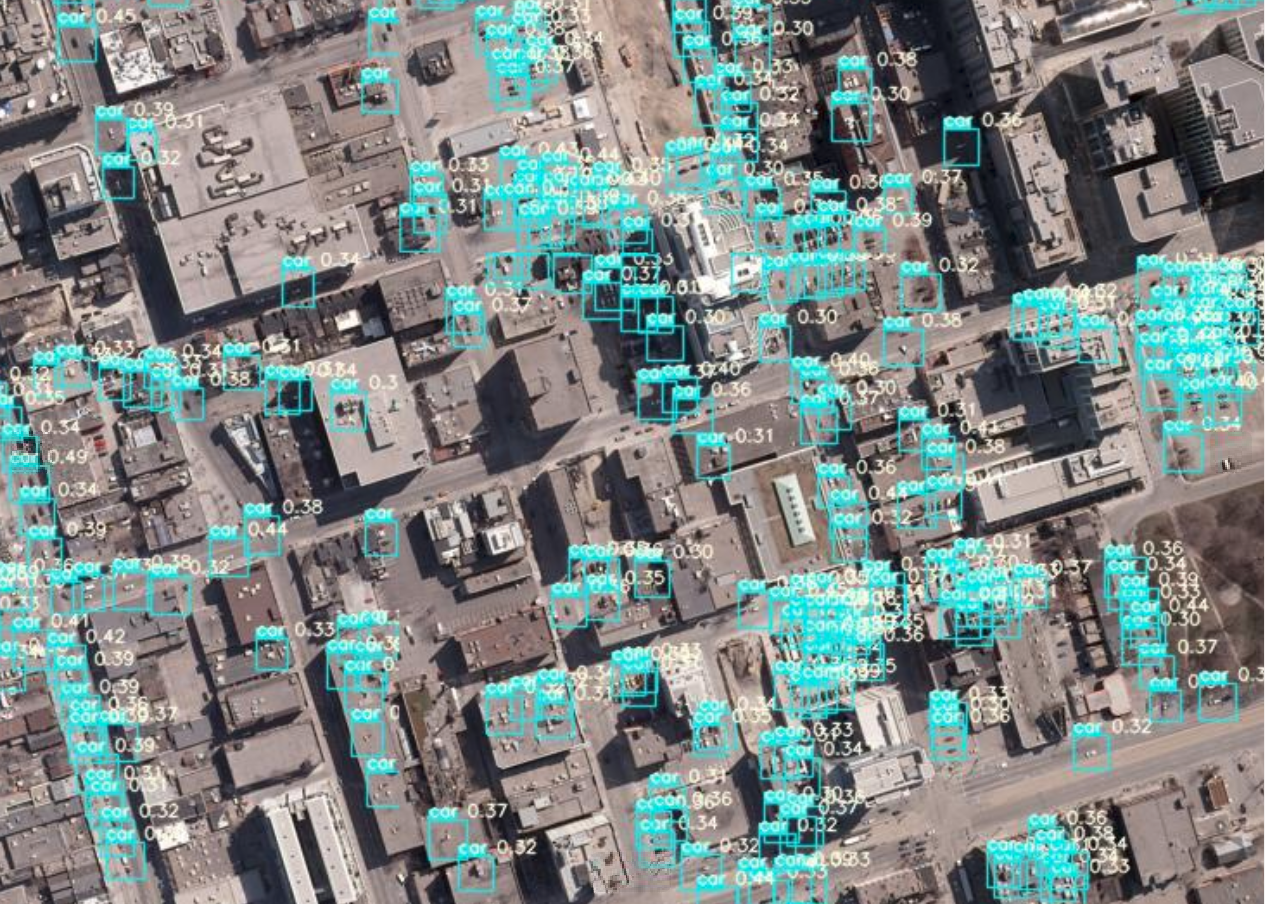
模擬衛星画像(90cm分解能)の解析により検出された車
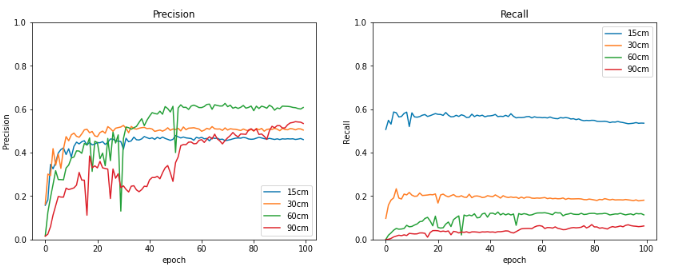
Test画像のそれぞれの解像度における車の検出結果を比較すると,15cm分解能と比べても,他の解像度でも多くは検出できているように見えます.それぞれの結果を比較してみます.
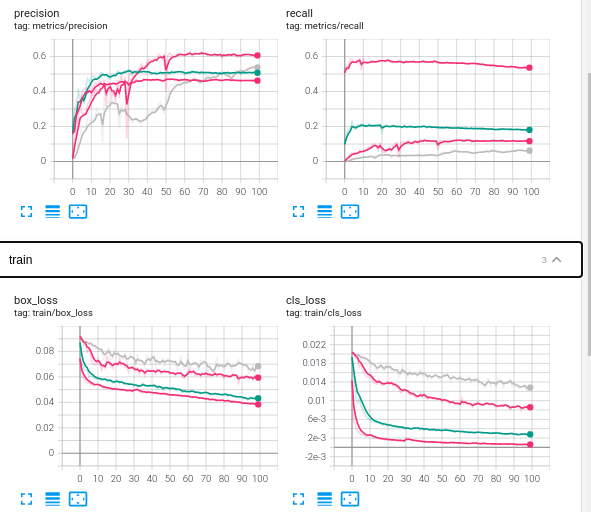
こちらは,Tesorboardの結果の一部になります.ValidationデータのPrecisionをみると,解像度に変わらずほぼ同じ値になっています.一方,Recallをみると,解像度が15cm(濃い赤)が一番高いですが,ほかは大きく低下しています.これから,解像度に依存せず車と推定されたものは多くは正解となりますが,解像度が低下すると取りこぼしが多いことが予想されます.
ただ,Trainデータのロス(Class loss)をみるとかなり低い値をとっており,解像度が90cmであっても学習量を100エポックより大きくすることで,より低下することが期待できます.
Trainの結果は保存されているため,それより比較してみます.
run_dir = "../yolov5/runs/train/"
train_dirs =os.listdir(run_dir )
train_dirs.sort()
train_dirs
上記を実行すると,それぞれの学習結果が保存されているのがわかります.
['.ipynb_checkpoints',
'cowc_test_15cm_ep100',
'cowc_test_30cmresize_ep100',
'cowc_test_60cmresize_ep100',
'cowc_test_90cmresize_ep100']
では,15cmの解像度の画像の学習結果を見てみます.
df_15= pd.read_table(run_dir +train_dir + '/results.txt', header=None, delim_whitespace=True)
columns = ['Epoch','gpu_mem','Box','Objecness','Classsfication','total','targets','img_size','Precison','Recall','mAP@0.5','mAP@0.5:0.95','val Box','val Objectness','val Classification']
RS = '_15cm'
for i in range(len(columns)):
column = columns[i] + RS
columns[i] = column
df_15.columns = columns
df_15
出力.
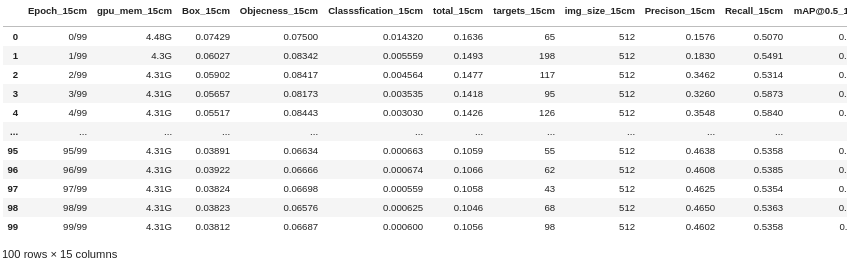
ここから,PrecisionとRecall,それぞれからf1scoreを求めてグラフにします.
df_15['f1score_15cm'] = 2 * df_15['Precison_15cm'] * df_15['Recall_15cm'] / (df_15['Precison_15cm'] + df_15['Recall_15cm'])
df_15[['Precison_15cm','Recall_15cm', 'f1score_15cm']].plot()
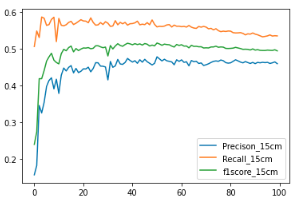
同様の処理を30cm,60cm,90cmの学習結果よりそれぞれのパラメータを比較します.
# 学習結果のグラフ化
fig = plt.figure(figsize=(14, 5))
ax1 = fig.add_subplot(1, 2, 1)
line1, = ax1.plot(df_15.index.values,df_15['Precison_15cm'],label='15cm')
line2, = ax1.plot(df_30.index.values,df_30['Precison_30cm'],label='30cm')
line3, = ax1.plot(df_60.index.values,df_60['Precison_60cm'],label='60cm')
line4, = ax1.plot(df_90.index.values,df_90['Precison_90cm'],label='90cm')
ax1.set_ylim(0.0, 1.0)
ax1.set_title("Precision")
ax1.set_xlabel('epoch')
ax1.set_ylabel('Precision')
ax1.legend(loc='lower right')
ax2 = fig.add_subplot(1, 2, 2)
line1, = ax2.plot(df_15.index.values,df_15['Recall_15cm'],label='15cm')
line2, = ax2.plot(df_30.index.values,df_30['Recall_30cm'],label='30cm')
line2, = ax2.plot(df_30.index.values,df_60['Recall_60cm'],label='60cm')
line2, = ax2.plot(df_30.index.values,df_90['Recall_90cm'],label='90cm')
ax2.set_ylim(0.0, 1.0)
ax2.set_title("Recall")
ax2.set_xlabel('epoch')
ax2.set_ylabel('Recall')
ax2.legend(loc='upper right')
plt.show()
TensorboardのグラフをMatplotlibでグラフ化しただけですが,出力パラメータの加工や組み合わせによって,より詳細に解像度による違いを考察できそうです.
3.まとめ.
解像度が15cmの航空写真をベースに,低解像度の画像をResize処理により模擬し,車の検出ができるのかどうか,Yolov5モデルを用いて評価しました.
1m以下の解像度であれば,学習画像の作り方や,モデルのパラメータを最適化することで,高解像度と変わらない精度で検出できそうです.今回の結果をベースとして,色々試してみます.
こちらの記事がみなさんの活動のご参考になれば幸いです.間違いやコメントなどありましたら,いただければ励みになりますのでお気軽にご連絡ください.
参考記事:
Deep Learning で航空写真から自動車をカウントする
PyTorchによる人工衛星画像から車の推定分布地図を作成してみる.
Cars Overhead With Context (COWC)
YOLO v5
人工衛星から人は見える?~衛星別、地上分解能・地方時まとめ~
FAS, Intelligence Resource Program