1. 概要.
こちらの記事を読んだとき”この内容を理解し自分で実装できたらいいな〜”と憧れていました.
Deep Learning で航空写真から自動車をカウントする
こちらを自分で実装できることをターゲットに,PyTorchを学びました.ある程度できましたので,せっかくだから公開されている人工衛星の撮影画像に構築したモデルで車の台数を推量し,同様に車のマッピングを求めてみました.


Copyright©2016DigitalGlobe.
学習用および検証用の画像データの取得,PyTorchでモデル化するためのDatasetおよびDataloader処理,学習,検証と人工衛星の撮影画像によるデモンストレーションを紹介します.Pytorchによる航空画像の建物セグメンテーションの作成方法.と同様に,PyTorchや画像分類が初めての方を対象としたため,かなり細かく紹介しています.そのため長文となりましたので,PyTorchをご存知な方はポイントだけ見てください.
ここで用いたコード(Jupyter lab)はGithubに公開しています.ご自身の環境(Google Colaboratoryを含む)で試してみたい方は,下記よりダウンロードしてください.
pytorch_car_counting
環境
本記事の実装環境は以下となります.
OS:Ubuntu: 18.04LTS
GPU:GeoForce GTX1070
Python: 3.7
PyTorch: 1.1.0
2. 画像からの車のカウント方法.
画像から対象物の識別方法として,物体検知(Object detection)がはじめに思いつきます.
この技術は,はじめに画像内の物体の有無およびその位置を認識し,そして物体の分類を行うものです.例えば,以下のサイトで詳しく技術が紹介されています.
今回用いる航空写真(COWC: Car Overhead With Context)においても,その学習例として物体検知の方法が紹介されています.
はじめは一般的な物体検知(SSD)の方法をPytorchで実装し,画像内の車をカウントすることも考えましたが,こちらの記事で紹介されているような,画像に写っている車の数を画像の模様(テクスチャー)として識別し,台数に応じた画像分類にて車をカウントする方法に興味を持ち,どのようなサービスやアプリケーションを作るかによりますが,画像内の車の位置情報は必要でななく,あるグリッド内の車の数を把握し,その分布が得られることで十分と考えました.また,今回は車の数をターゲットとしましたが,対象を変えることで同様の分布地図を作成することができます.
といっても難しいことを考えているわけではなく,”アノテーションコストが低減できる”に魅力とその有効性に一番関心を持ちました.面白いアイデアです.
では,学習および検証用の画像データとアノテーション情報(画像内の車の台数)を準備します.
3. 学習および検証用データの準備.
COWCでのサイトから航空写真の画像データおよびアノテーションデータをダウロードし,学習用および検証用のデータを準備しようと思いましたが,すでに効果的なデータの準備がされていましたので,そちらを利用させていただきました.感謝いたします.
COWCのデータのダウンロードおよびその前処理方法について,こちらの記事をご確認ください.
ここでは,上記の前処理後のPyTorchでモデルを構築するための処理について紹介します.
なお,COWCのデータのダウロードから前処理の全般についてGithubにコードをアップしていますのでで,こちらもご参考ください.
まずは,各モジュールをインポートします.
import argparse
import os
import shutil
import math
import numpy as np
from PIL import Image
from skimage import io
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import cv2
Image.MAX_IMAGE_PIXELS = 1000000000
その後,取得した画像を確認します.
train_path = '../../data/cowc_processed/train_val/crop/train/'
files =os.listdir(train_path)
# ファイル名の取得
print(files[0])
# trainファイルの読み込み.
im = cv2.imread(train_path + files[0])
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
plt.imshow(im_rgb)

これより,左半分に車が写った航空写真が,右半分に車の位置がわかるアノテーション画像(白点が車の位置)で構成されているのがわかります.
次に航空写真とそれに対応する車の台数のペアのデータを準備します.
# 画像サイズの確認
v_size = im_rgb.shape[0]
h_size = im_rgb.shape[1]
print(h_size)
# 画像を左の撮像と右のアノテーション画像に分割する.
clp_l = im_rgb[0:v_size, 0:h_size//2]
clp_r = im_rgb[0:v_size, h_size//2:h_size]
# 撮像画像の確認
plt.imshow(clp_l)
# アノテーション画像の確認
plt.imshow(clp_r)

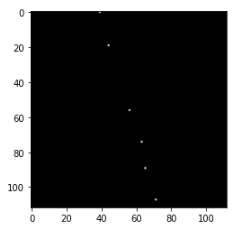
分離したアノテーション画像から車の台数を見積もります.
# アノテーション画像の積算値より車の台数を算出.(1台:765)
car_count = int(np.sum(clp_r) // 765)
print('車の台数: ', car_count)
アノテーション画像の信号強度から台数を見積もると,以下の出力となりました.
出力
車の台数: 6
上記の方法で,学習用(Train)および検証用(Validation)のすべての画像に対して,分割処理およびアノテーション画像からの車の台数を算出します.
分割した航空写真は車の台数名のフォルダ(ディレクトリ)に格納します.
for i in range(len(files)):
train_path = '../../data/cowc_processed/train_val/crop/train/'
files =os.listdir(train_path)
im = cv2.imread(train_path + files[i])
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
#画像サイズの確認
v_size = im_rgb.shape[0]
h_size = im_rgb.shape[1]
clp_l = im_rgb[0:v_size, 0:h_size//2]
clp_r = im_rgb[0:v_size, h_size//2:h_size]
car_count = int(np.sum(clp_r) // 765)
car_count
#rint(car_count)
path_train = '../../../data/train/'
#保存先のディレクトリがなければ作成
if not os.path.exists(path_train + str(car_count)):
os.mkdir(path_train + str(car_count))
#分離した画像の保存
Image.fromarray(clp_l).save(path_train + str(car_count) +'/' + files[i])
処理後のデータより,学習用データの車の台数分布やデータ数を確認します.
# trainデータ数
print('Trainの台数分布: ', len(os.listdir(path_train)))
# trainデータ数
import glob
print('Trainのデータ数: ', len(glob.glob(path_train + '/*/*')))
出力
Trainの台数分布: 21
Trainのデータ数: 37981
検証用データに対しても同様の処理を行い,画像の分割,および分割した画像を車の台数名のディレクトリに格納します.
ここで,検証用データの車の台数を確認したところ,最大台数が12台であったため,学習用データの12台以上の台数の画像をすべて12台として同じディレクトリに格納しました.
for i in range(13, 21, 1):
move_glob('./train/12/', './train/' + str(i) + '/*.png')
そして,Datasetにて分類名の文字数を固定するために,ディレクトリ名で車の台数がひと桁である場合,ふた桁に変更しました.
# ディレクトリ名を2桁に変更する.
for i in range(0,10,1):
os.rename('./train/'+ str(i), './train/0' + str(i))
os.rename('./val/'+ str(i), './val/0' + str(i))
こちらで学習用および検証用データの前準備が終了です.
4. Pytorchでの画像分類モデルの構築.
画像分類(Image Classificaton)のモデルは,Pytorchを学ぶのに参考にした「つくりながら学ぶ!PyTorchによる発展ディープラーニング」で紹介されているモデルをベースに作りました.

書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニング」(小川雄太郎、マイナビ出版 、19/07/29)
この本は,PyTorchのワークフローの考え方から,画像分類,物体検知,セグメンテーション,GAN,自然言語処理,動画分類と対象が広範囲と,自分が行いたいモデルを例として丁寧に学び構築できます.非常に参考になりました.
ここで紹介されている画像分類のなかで,VGG-16のモデルをベースとしたFine Tuningを採用しモデルを構築します.
Vgg-16や,PyTorchによるFine tuningの方法については,こちらの本をご参考ください.
また,本に記載されているコードは以下にて公開されています.どういった内容なのか関心のあるかたは,こちらもご参考ください.
つくりながら学ぶ! PyTorchによる発展ディープラーニング
MIT License
では,学習用および検証用データのDataset,Dataloaderの作成,およびモデルの構築と検証を実行します.
5. 画像分類による航空写真より車の分布地図を作成する.
5.1 Dataset,Dataloaderの作成
前処理にて準備した航空写真の画像データおよびそれに対応した車の台数情報による車の台数予測モデルを構築するために,PyTorchに対応したDatasetおよびDataloaderを作成します.
まずは必要なモジュールをインポートします.
# パッケージのimport
import glob
import os.path as osp
import random
import numpy as np
import json
from PIL import Image
from tqdm import tqdm
import matplotlib.pyplot as plt
%matplotlib inline
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import torchvision
from torchvision import models, transforms
次に乱数を固定し再現性を保ちます.
# 乱数のシードを設定
torch.manual_seed(1234)
np.random.seed(1234)
random.seed(1234)
そして,PyTorchのバージョンを確認します.
print(torch.__version__)
print(torchvision.__version__)
出力
1.1.0
0.3.0
私の環境は,それぞれ上記のバージョンとなります.
まずDatasetを作成します.
先に述べましたが,DatasetやFine tuningのモデルは,つくりながら学ぶ! PyTorchによる発展ディープラーニングで紹介されている設定をそのまま用いています.そのため,構築したモデルの精度を高めるにはどうしたらよいのか,など改善を考えている方は,こちらの設定をベースとしてAugmentationを変更したり,フィルターを加えたりなど色々試してみてください.
どういったパラメータが効果があるのかないのか,自分の感覚として身につくかと思います.
Datasetは学習用(Train)および検証用(Val)を共通して以下の関数で設定します.
まずは,画像データのAugmentation,標準化処理やサイズの変更,そしてPyTorchで扱うためのTensor変換を下記にて行います.
class ImageTransform():
"""
画像の前処理クラス。訓練時、検証時で異なる動作をする。
画像のサイズをリサイズし、色を標準化する。
訓練時はRandomResizedCropとRandomHorizontalFlipでデータオーギュメンテーションする。
Attributes
----------
resize : int
リサイズ先の画像の大きさ。
mean : (R, G, B)
各色チャネルの平均値。
std : (R, G, B)
各色チャネルの標準偏差。
"""
def __init__(self, resize, mean, std):
self.data_transform = {
'train': transforms.Compose([
transforms.RandomResizedCrop(
resize, scale=(0.5, 1.0)), # データオーギュメンテーション
transforms.RandomHorizontalFlip(), # データオーギュメンテーション
transforms.RandomVerticalFlip(), # データオーギュメンテーション
transforms.RandomAffine([-30, 30], scale=(0.8, 1.2)), # 回転とリサイズ
#transforms.RandomErasing(p=0.5), # 確率0.5でランダムに領域を消去
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean, std) # 標準化
]),
'val': transforms.Compose([
transforms.Resize(resize), # リサイズ
#transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean, std) # 標準化
])
}
def __call__(self, img, phase='train'):
"""
Parameters
----------
phase : 'train' or 'val'
前処理のモードを指定。
"""
return self.data_transform[phase](img)
では,この変換によって画像がどのように変化するのか.Train画像を見てみます.
# 訓練時の画像前処理の動作を確認
# 実行するたびに処理結果の画像が変わる
# 1. 画像読み込み
image_file_path = '../data/train/01/03553_97_597.png'
img = Image.open(image_file_path) # [高さ][幅][色RGB]
# 2. 元の画像の表示
plt.imshow(img)
plt.show()
# 3. 画像の前処理と処理済み画像の表示
size = 96
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
transform = ImageTransform(size, mean, std)
img_transformed = transform(img, phase="train") # torch.Size([3, 224, 224])
# (色、高さ、幅)を (高さ、幅、色)に変換し、0-1に値を制限して表示
img_transformed = img_transformed.numpy().transpose((1, 2, 0))
img_transformed = np.clip(img_transformed, 0, 1)
plt.imshow(img_transformed)
plt.show()
実行結果が以下となります.

上部の元画像に対して,傾きや標準化処理が行われている(色合いが変わっている)のがわかります.
次にDatasetを作成するための学習用および検証用のファイルのリストを作成します.
def make_datapath_list(phase="train"):
"""
データのパスを格納したリストを作成する。
Parameters
----------
phase : 'train' or 'val'
訓練データか検証データかを指定する
Returns
-------
path_list : list
データへのパスを格納したリスト
"""
rootpath = "../data/"
target_path = osp.join(rootpath+phase+'/**/*.png')
print(target_path)
path_list = [] # ここに格納する
# globを利用してサブディレクトリまでファイルパスを取得する
for path in glob.glob(target_path):
path_list.append(path)
return path_list
# 実行
train_list = make_datapath_list(phase="train")
val_list = make_datapath_list(phase="val")
ここで準備した学習用および検証用の画像数を確認してみます.
len(train_list), len(val_list)
出力
(37981, 10267)
学習用画像が37981枚,検証用画像が10267枚であることが確認されました.
次にDatasetを作成します.学習用および検証用の画像の車の台数分布は0から12台(学習用は13台以上はすべて12台に移動)としたことから,以下の設定となります.
class CarCountDataset(torch.utils.data.Dataset):
"""
車の数の画像のDatasetクラス。PyTorchのDatasetクラスを継承。
Attributes
----------
file_list : リスト
画像のパスを格納したリスト
transform : object
前処理クラスのインスタンス
phase : 'train' or 'test'
学習か訓練かを設定する。
"""
def __init__(self, file_list, transform=None, phase='train'):
self.file_list = file_list # ファイルパスのリスト
self.transform = transform # 前処理クラスのインスタンス
self.phase = phase # train or valの指定
def __len__(self):
'''画像の枚数を返す'''
return len(self.file_list)
def __getitem__(self, index):
'''
前処理をした画像のTensor形式のデータとラベルを取得
'''
# index番目の画像をロード
img_path = self.file_list[index]
img = Image.open(img_path) # [高さ][幅][色RGB]
# 画像の前処理を実施
img_transformed = self.transform(
img, self.phase) # torch.Size([3, 224, 224])
# 画像のラベルをファイル名から抜き出す
if self.phase == "train":
label = img_path[14:16]
#print(label)
elif self.phase == "val":
#print(img_path)
label = img_path[12:14]
#print(label)
# ラベルを数値に変更する
if label == "00":
label = 0
elif label == "01":
label = 1
elif label == "02":
label = 2
elif label == "03":
label = 3
elif label == "04":
label = 4
elif label == "05":
label = 5
elif label == "06":
label = 6
elif label == "07":
label = 7
elif label == "08":
label = 8
elif label == "09":
label = 9
elif label == "10":
label = 10
elif label == "11":
label = 11
elif label == "12":
label = 12
#elif label == "13": #calが12までなので,trainはそれ以上を12台に含めた.
# label = 13
#elif label == "14":
# label = 14
#elif label == "15":
# label = 15
#elif label == "16":
# label = 16
#elif label == "17":
# label = 17
#elif label == "18":
# label = 18
#elif label == "19":
# label = 19
#elif label == "20":
# label = 20
#print(type(label))
return img_transformed, label
# 実行
train_dataset = CarCountDataset(
file_list=train_list, transform=ImageTransform(size, mean, std), phase='train')
val_dataset = CarCountDataset(
file_list=val_list, transform=ImageTransform(size, mean, std), phase='val')
# 動作確認
index = 0
print(train_dataset.__getitem__(index)[0].size())
print(train_dataset.__getitem__(index)[1])
ディレクトリ名を分類名(Class名)として扱う方法がPyTorchにありますが,今回は本で説明されている方法である,ディレクトリ名を分類名とする宣言を行っています.
上記を実行しDatasetの準備が終了しましたので,次にDataloaderを作成します.
学習用および検証のデータとして以下の処理を行います.
# ミニバッチのサイズを指定
batch_size = 32
# DataLoaderを作成
train_dataloader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False)
# 辞書型変数にまとめる
dataloaders_dict = {"train": train_dataloader, "val": val_dataloader}
print(type(dataloaders_dict))
print(dataloaders_dict["train"])
print(dataloaders_dict)
# 動作確認
batch_iterator = iter(dataloaders_dict["train"]) # イテレータに変換
print(type(batch_iterator))
inputs, labels = next(
batch_iterator) # 1番目の要素を取り出す
# print(inputs.size())
# print(labels)
# print(labels.size())
どういったデータ形式となるのか,Printにていくつか出力させていますが,これらは確認が目的ですので,それが終えた方はヘッドに#をつけて実行させないか,削除してください.(私の備忘録の意味でこのままとしておきます.)
これで,PyTorchを実行するためのインプイットデータの準備が終えました.次にモデルを構築します.
5.2 画像分類モデルのFine tuningの構築
ネットワークモデルはVGG-16をベースとしたFine Tuningで構築します.VGG-16をご存知の方は多いかと思いますが,「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルです.出力は1000クラスとなり,犬,鳥猫などの1000種類に分類された推定結果が出力されます.
まず,PyTorchでVGG16を使うためそれを呼び出します.
# 学習済みのVGG-16モデルをロード
# VGG-16モデルのインスタンスを生成
use_pretrained = True # 学習済みのパラメータを使用
net = models.vgg16(pretrained=use_pretrained)
print(net)
PyTorchにはVGG16以外にも多くの学習済みモデルが用意されています.関心のある方は公式ドキュメントをご参考ください.
モデルは以下となります.
出力.
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
最後のout_feature=1000となっており,これはアウトプットが1000種類に分類されていることを示しています.
そのため,最後の出力層に今回の車の台数分布の出力である,0台から12台の13種類となるよう変更します.
# VGG16の最後の出力層の出力ユニットを21の車の数のクラスに付け替える
net.classifier[6] = nn.Linear(in_features=4096, out_features=13)
# 訓練モードに設定
net.train()
print('ネットワーク設定完了:学習済みの重みをロードし、訓練モードに設定しました')
次にこのモデルのFine tuningを設定します.VGG16のモデルの中で,本と同じくいくつかのパラメータを学習によって更新するしないを設定します.
# ファインチューニングで学習させるパラメータを、変数params_to_updateの1~3に格納する
params_to_update_1 = []
params_to_update_2 = []
params_to_update_3 = []
# 学習させる層のパラメータ名を指定
update_param_names_1 = ["features"]
update_param_names_2 = ["classifier.0.weight",
"classifier.0.bias", "classifier.3.weight", "classifier.3.bias"]
update_param_names_3 = ["classifier.6.weight", "classifier.6.bias"]
# パラメータごとに各リストに格納する
for name, param in net.named_parameters():
if update_param_names_1[0] in name:
param.requires_grad = True
params_to_update_1.append(param)
print("params_to_update_1に格納:", name)
elif name in update_param_names_2:
param.requires_grad = True
params_to_update_2.append(param)
print("params_to_update_2に格納:", name)
elif name in update_param_names_3:
param.requires_grad = True
params_to_update_3.append(param)
print("params_to_update_3に格納:", name)
else:
param.requires_grad = False
print("勾配計算なし。学習しない:", name)
次に,損失関数を定義します.損失関数は,多数分類のためクロスエントロピーとします.
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
そして,最適化手法を設定します.最適化手法は一般的なSGDとし,それぞれのパラメータの学習率は,本と同じ重みにしています.
# 最適化手法の設定
optimizer = optim.SGD([
{'params': params_to_update_1, 'lr': 1e-4},
{'params': params_to_update_2, 'lr': 5e-4},
{'params': params_to_update_3, 'lr': 1e-3}
], momentum=0.9)
こちらも設定を変えることで結果(精度)がどのように変わるのか,実験すると理解が深まり面白いかと思います.学習に時間がかかるため,高い性能のGPUが欲しくなりますが.
では,最後に学習方法を設定します.
# モデルを学習させる関数を作成
def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs):
# 初期設定
# GPUが使えるかを確認
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#print("使用デバイス:", device)
print("device name", torch.cuda.get_device_name(0))
# ネットワークをGPUへ
net.to(device)
# ネットワークがある程度固定であれば、高速化させる
torch.backends.cudnn.benchmark = True
#train accurascy, train loss, val_accuracy, val_loss をグラフ化できるように設定.
x_epoch_data=[]
y_train_loss=[]
y_train_accuracy=[]
y_val_loss=[]
y_val_accuracy=[]
# epochのループ
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-------------')
x_epoch_data.append(epoch)
# epochごとの訓練と検証のループ
for phase in ['train', 'val']:
if phase == 'train':
net.train() # モデルを訓練モードに
else:
net.eval() # モデルを検証モードに
epoch_loss = 0.0 # epochの損失和
epoch_corrects = 0 # epochの正解数
# 未学習時の検証性能を確かめるため、epoch=0の訓練は省略
if (epoch == 0) and (phase == 'train'):
continue
# データローダーからミニバッチを取り出すループ
for inputs, labels in tqdm(dataloaders_dict[phase]):
# GPUが使えるならGPUにデータを送る
inputs = inputs.to(device)
labels = labels.to(device)
# optimizerを初期化
optimizer.zero_grad()
# 順伝搬(forward)計算
with torch.set_grad_enabled(phase == 'train'):
outputs = net(inputs)
loss = criterion(outputs, labels) # 損失を計算
_, preds = torch.max(outputs, 1) # ラベルを予測
# 訓練時はバックプロパゲーション
if phase == 'train':
loss.backward()
optimizer.step()
# 結果の計算
epoch_loss += loss.item() * inputs.size(0) # lossの合計を更新
# 正解数の合計を更新
epoch_corrects += torch.sum(preds == labels.data)
# epochごとのlossと正解率を表示
epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset)
epoch_acc = epoch_corrects.double(
) / len(dataloaders_dict[phase].dataset)
if phase == 'train':
y_train_loss.append(epoch_loss)
y_train_accuracy.append(epoch_acc)
else:
y_val_loss.append(epoch_loss)
y_val_accuracy.append(epoch_acc)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
return x_epoch_data, y_train_loss, y_train_accuracy, y_val_loss, y_val_accuracy
ここでは,本と同じく1回目は学習させずに読み込んだVGG16のモデルのまま検証用データを用いて精度を求めます.学習データを用いることでどれほど向上するのか,定量的な感覚がつかめるかと思います.
また,これは本と異なりますが,学習を深めることでモデルの損失や精度がどのように向上するのかしないのか,グラフ化するためのデータを作りました.
では,以下にてモデルを実行します.エポック数は50としています.
# 学習・検証を実行する
num_epochs=50
train = train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)
5.3 モデルの検証
私の環境(GPU:GX 1070)で約2時間30分の学習時間となります.学習が終わりましたら,以下にて学習の評価を行います.
# Trainは1epoch目は実行していないため,対象のepochを削除する.
train_epoch = train[0].copy()
train_epoch.pop(0)
# 学習模様のグラフ化
fig = plt.figure(figsize=(14, 5))
ax1 = fig.add_subplot(1, 2, 1)
line1, = ax1.plot(train_epoch,train[1],label='loss')
line2, = ax1.plot(train_epoch,train[2],label='accuracy')
ax1.set_title("train")
ax1.set_xlabel('epoch')
ax1.set_ylabel('loss, accuracy')
ax1.legend(loc='upper right')
ax2 = fig.add_subplot(1, 2, 2)
line1, = ax2.plot(train[0],train[3],label='loss')
line2, = ax2.plot(train[0],train[4],label='accuracy')
ax2.set_ylim(0.5, 1.0) #y軸のスケールを固定.
ax2.set_title("validation")
ax2.set_xlabel('epoch')
ax2.set_ylabel('loss, accuracy')
ax2.legend(loc='upper right')
plt.show()
結果は以下となりました.
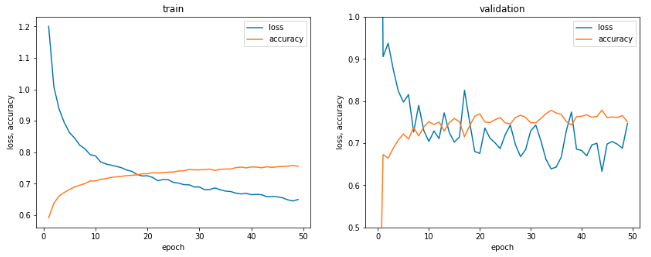
学習用データにおいては,学習回数が増える毎に損失が減少し精度が向上しています.一方,検証用データは,1エポック目のVGG16のままで精度がかなり低いですが,学習用データと同様に学習回数がふえることで精度が向上しています.ただ,その精度の向上率は学習用画像ほどではないですね.
学習用および検証用画像は同じ航空写真から準備したため,それに大きな違いはないと思います.もしかしたら,学習回数をより多くすると,学習用は精度はあがるが検証用は下がる’過学習’が現れるかもしれません.時間がある方は試してみてください.
では,ここで学習したモデルのパラメータを保存します.
# PyTorchのネットワークパラメータの保存
save_path = './carcount_weights_fine_tuning.pth'
torch.save(net.state_dict(), save_path)
次に,ここで保存した学習モデルを再生(読み込み)ます.モデルの学習から実行まで連続して行う場合はこちらは不要ですが,過去に学習したモデルを読み込みたいとき(学習には時間がかかるため,学習後から検証やテストモデルを実装するときなど),以下から実行することとなります.
GPU環境で作成したモデルをGPU環境で使用するとき,GPU環境で作成したモデルをGPUがないCPU環境で使用するとき,などのケースによって読み込み方が異なるそうです.詳しくは,こちらをご参考にしてください.
ここではGPU環境でのモデルの再生および実行例となります.
device = torch.device("cuda")
load_path = './carcount_weights_fine_tuning.pth'
net.load_state_dict(torch.load(load_path))
net.to(device)
では,読み込んだモデルの精度を検証用データを用いて確認します.
correct = 0
total = 0
net.eval() # 評価モード
for i, (x, t) in enumerate(val_dataloader):
x, t = x.cuda(), t.cuda() # GPU対応
y = net(x)
correct += (y.argmax(1) == t).sum().item()
total += len(x)
print("正解率:", str(correct/total*100) + "%")
出力は,正解率: 75.05600467517289%,となりました.
次に,この正解率の意味を理解していきます.
学習済みのモデルを使って検証用画像の検証結果を確認します.
例えば,以下のコードを実行してみます.
test_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=True)
dataiter = iter(test_dataloader)
images, labels = dataiter.next() # サンプルを1つだけ取り出す
plt.imshow(np.transpose(images[0], (1, 2, 0))) # チャンネルを一番後ろに
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に
plt.show()
net.eval() # 評価モード
x, t = images.cuda(), labels.cuda() # GPU対応
print(x.shape)
# x, t = images, labels # CPU対応
y = net(x)
print("予測された車の数:", y[0].argmax().item())
print('正解の車の数:', t[0])
出力は以下となります.

画像が分かり難いですが,写真には車が3台(正解の車の数)あり,モデルより予測された結果が3台と,一致しているのがわかります.
では,他の車の台数の場合はどうなのか? 車の台数分布に応じた精度を求めてみます.
# ミニバッチのサイズを指定
batch_size = 32
val_dataloader = torch.utils.data.DataLoader(
val_dataset, batch_size=batch_size, shuffle=False)
classes = list(range(13))
class_correct = list(0. for i in range(13))
class_total = list(0. for i in range(13))
predicted_class = list(0. for i in range(13))
dataiter = iter(val_dataloader)
images, labels = dataiter.next()
net.eval() # 評価モード
x, t = images, labels # GPU対応
for data in val_dataloader:
images, labels = data
x, t = images.cuda(), labels.cuda() # GPU対応
#x, t = images, labels # CPU対応
outputs = net(x)
_, predicted = torch.max(outputs, 1)
c = (predicted == t).squeeze()
for i in range(len(c)):
label = t[i]
label_p = predicted[i]
class_correct[label] += c[i].item()
predicted_class[label_p] += 1
class_total[label] += 1
for i in range(13):
print('Accuracy of %2s : %2d %%, %4d images, the number of predicted image: %4d' % (
classes[i], 100 * class_correct[i] / class_total[i], class_total[i], predicted_class[i]))
出力
Accuracy of 0 : 94 %, 5773 images, the number of predicted image: 5618
Accuracy of 1 : 68 %, 1546 images, the number of predicted image: 1419
Accuracy of 2 : 52 %, 1171 images, the number of predicted image: 976
Accuracy of 3 : 47 %, 733 images, the number of predicted image: 878
Accuracy of 4 : 26 %, 465 images, the number of predicted image: 449
Accuracy of 5 : 26 %, 284 images, the number of predicted image: 370
Accuracy of 6 : 12 %, 153 images, the number of predicted image: 107
Accuracy of 7 : 21 %, 76 images, the number of predicted image: 237
Accuracy of 8 : 0 %, 40 images, the number of predicted image: 12
Accuracy of 9 : 25 %, 12 images, the number of predicted image: 106
Accuracy of 10 : 12 %, 8 images, the number of predicted image: 43
Accuracy of 11 : 0 %, 5 images, the number of predicted image: 21
Accuracy of 12 : 100 %, 1 images, the number of predicted image: 31
0台の車の画像に対して0台と予測した精度は94%とかなり高いことがわかります.これは,画像の多くは車が写っていない画像であり(5773枚),0台となる精度が高くなることは想像できるかと思います.(0台と予測された画像の枚数は5618枚となります.)
一方,台数が多い画像,例えば8台とすると,その精度は0%とまったく一致していません.(モデルは8台と予測された画像が12枚ありましたが,そのどれも8台の正解ラベルをもつ画像ではありませんでした.)
台数が増えることで,その精度は悪くなっているのがわかります.ただ,完全に一致していなくても,その前後である可能性は高いと思われます.記事の最初にかきましたが,今回は台数そのものを正確に求めることが目的ではなく,定性的になりますが,車の密集分布や,異なる時期の同地域の画像を比較することで,トレンドが求められればと思っています.推定された車の台数は実際の台数よりも多く推測されているのがわかりました.
ただ,精度が高いにこしたことはありませんので,モデルやパラメータの設定を変更したり,学習用画像の処理によって改善を試みたほうがよいですね.
構築したモデルの精度を評価しましたので,次にこのモデルを用いて航空写真に求めた車の分布地図を作成します.
5.3 航空写真の車の分布地図の作成
検証用画像を対象に,実際の航空写真に推定された車の分布や台数を重畳します.
すでにモジュールをインポートしている方は不要ですが,念の為記載します.
import argparse
import os
import shutil
import math
import numpy as np
from PIL import Image
from skimage import io
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import cv2
Image.MAX_IMAGE_PIXELS = 1000000000
次に処理する画像のファイル名を確認します.このとき,PyTorchで処理するために分割した画像を保存するディレクトリも作っておきます.
if not os.path.exists('../data/test'):
os.mkdir('../data/test')
val_path = '../cowc_car_counting/data/cowc/datasets/ground_truth_sets/Utah_AGRC/'
files =os.listdir(val_path)
# ファイル名の取得
print(files[0])
今回はUthaの航空写真を対象としました.
では,この画像を閲覧しサイズを確認します.
# opencvで検証用画像を読み込む.
im = cv2.imread(val_path + files[0])
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
# Image.fromarray(im_rgb).save('test.jpg')
plt.imshow(im_rgb)
# 画像サイズの確認
v_size = im_rgb.shape[0]
h_size = im_rgb.shape[1]
print('v_size:', v_size)
print('h_size:', h_size)
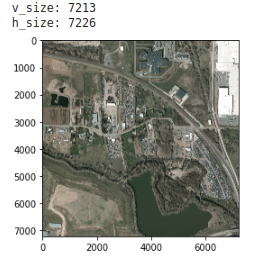
画像のサイズは7213 x 7226ピクセルであることが確認できました.グリッドサイズを100ピクセルとし(モデルが96ピクセルなため,それに近いサイズ),今回はその整数倍のサイズにリサイズしました.
# 検証画像の分割画像の置き場所を準備する.
if not os.path.exists('../data/test/val'):
os.mkdir('../data/test/val')
height = 100 #モデルが96ピクセルなので,それに近い100ピクセルとする.
width = 100
img_size = 7200 #imageサイズで100ピクセルに近い値とする.
DIR_OUTPUTS = '../data/test/val/'
# 画像の分割処理関数
def ImgSplit(im):
# 読み込んだ画像を100*100ピクセルのサイズに分割する.のサイズで72*72枚に分割する
buff = []
# 縦の分割枚数
for h1 in range(int(img_size/height)):
# 横の分割枚数
for w1 in range(int(img_size/width)):
w2 = w1 * height
h2 = h1 * width
#print(w2, h2, width + w2, height + h2)
c = im.crop((w2, h2, width + w2, height + h2))
buff.append(c)
return buff
# 画像の分割処理の実行
hi=0
for ig in ImgSplit(img_resize):
hi=hi+1
#print(hi)
# 保存先フォルダの指定
ig.save(DIR_OUTPUTS+str(hi)+".png")
分割した画像のリストおよび変換処理を行います.今回はテスト用画像ですので,変換は画像サイズ,標準化およびPyTorchで扱うためのTensor処理のみとします.
# test_listの作成
def make_datapath_list_test(phase="test"):
"""
データのパスを格納したリストを作成する。
Parameters
----------
phase : 'train' or 'val'
訓練データか検証データかを指定する
Returns
-------
path_list : list
データへのパスを格納したリスト
"""
rootpath = "../data/"
target_path = osp.join(rootpath+phase+'/val/*.png')
print(target_path)
path_list = [] # ここに格納する
# globを利用してサブディレクトリまでファイルパスを取得する
for path in glob.glob(target_path):
path_list.append(path)
return path_list
# 実行
test_list = make_datapath_list_test(phase="test")
# test画像の前処理をするクラス
# resize, normalize and totnesorを行う.
class ImageTransform_test():
"""
画像の前処理クラス。訓練時、検証時で異なる動作をする。
画像のサイズをリサイズし、色を標準化する。
訓練時はRandomResizedCropとRandomHorizontalFlipでデータオーギュメンテーションする。
Attributes
----------
resize : int
リサイズ先の画像の大きさ。
mean : (R, G, B)
各色チャネルの平均値。
std : (R, G, B)
各色チャネルの標準偏差。
"""
def __init__(self, resize, mean, std):
self.data_transform = {
'test': transforms.Compose([
transforms.Resize(resize), # リサイズ
#transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean, std) # 標準化
])
}
def __call__(self, img, phase='test'):
"""
Parameters
----------
phase : 'train' or 'val'
前処理のモードを指定。
"""
return self.data_transform[phase](img)
テストファイルのリストは分割順になっていないため,natsortを用いて順番に変更します.これは,モデルにて推定された車の台数分布の行列を作成するために必要な処理になります.natsortをインストールされていない方は以下にて実行してください.
# !pip install natsort
# natsoatを用いてファイルの順番をソートする
from natsort import natsorted
test_list = natsorted(test_list)
では,作成したテスト用画像を確認します.
# 訓練時の画像前処理の動作を確認
# 実行するたびに処理結果の画像が変わる
# 1. 画像読み込み
image_file_path = test_list[0]
img = Image.open(image_file_path).convert('RGB') # [高さ][幅][色RGB]
# 2. 元の画像の表示
plt.imshow(img)
plt.show()
# 3. 画像の前処理と処理済み画像の表示
size = 96
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
transform = ImageTransform(size, mean, std)
img_transformed = transform(img, phase="val") # torch.Size([3, 224, 224])
# (色、高さ、幅)を (高さ、幅、色)に変換し、0-1に値を制限して表示
print(img_transformed.shape)
出力

全体の航空写真の一番左上の画像になります.これを見ると車は写っていないですね.
この画像データのDatasetを作成します.
# test画像のDatasetを作成する
class CarCountDataset_test(torch.utils.data.Dataset):
def __init__(self, file_list, transform=None, phase='train'):
self.file_list = file_list # ファイルパスのリスト
self.transform = transform # 前処理クラスのインスタンス
self.phase = phase # train or valの指定
def __len__(self):
'''画像の枚数を返す'''
return len(self.file_list)
def __getitem__(self, index):
'''
前処理をした画像のTensor形式のデータとラベルを取得
'''
# index番目の画像をロード
img_path = self.file_list[index]
img = Image.open(img_path).convert('RGB') # [高さ][幅][色RGB]
# 画像の前処理を実施
img_transformed = self.transform(
img, self.phase) # torch.Size([3, 224, 224])
# 画像のラベルをファイル名から抜き出す
label == 0
return img_transformed, label
# 実行
test_dataset = CarCountDataset_test(
file_list=test_list, transform=ImageTransform(size, mean, std), phase='val')
# 動作確認
index = 0
print(test_dataset.__getitem__(index)[0].size())
print(test_dataset.__getitem__(index)[1])
その後,Dataloaderを作成し,先に構築したモデルにて車の台数を推定します.
batch_size =10
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False)
dataiter = iter(test_dataloader)
images, labels = dataiter.next() # サンプルを1つだけ取り出す
plt.imshow(np.transpose(images[0], (1, 2, 0))) # チャンネルを一番後ろに
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に
plt.show()
net.eval() # 評価モード
x, t = images.cuda(), labels.cuda() # GPU対応
print(x.shape)
# x, t = images, labels # CPU対応
y = net(x)
print("予測された車の数:", y[0].argmax().item())
# 2. 元の画像の表示
print('元の画像の表示')
plt.imshow(img)
plt.show()

推定結果は予測どおり車がないものでした.次に,分割したすべての画像に対してモデルによる台数の推定処理を行い,その分布(行例)を求めます.
# ミニバッチのサイズを指定
batch_size = 10
# 対象画像のdataloaderを作成
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False)
classes = list(range(13))
class_correct = list(0. for i in range(13))
class_total = list(0. for i in range(13))
net.eval() # 評価モード
test =[]
i = 0
for data in test_dataloader:
images, labels = data
x, t = images.cuda(), labels.cuda() # GPU対応
#x, t = images, labels # CPU対応
y = net(x)
for i in range(len(y)):
result = y[i].argmax().item() #GPUのtensorをnpに変換するにはargmaxを用いる必要がある.
test.append(result)
print('分割された画像の数: ',len(test))
分割した画像数を確認すると,5184とありました.
次に,このリストを元画像のグリッド数と同じ行列に変換します.
test2 = np.array(test)
cars_counted =test2.reshape(72, 72)
cars_counted
7200サイズの画像を,100x100サイズのグリッドで分割したため,72x72の行列となり,出力は以下となります.
array([[0, 0, 1, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])
次に,テスト画像に推定された車の台数の分布結果を重畳する処理を行います.
はじめに画像処理に必要なモジュールをインポートします.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import itertools
%matplotlib inline
次にテスト画像を読み込みます.
# 検証画像をベース画像として準備.
image_path = val_path + files[0]
mosaic_image = io.imread(image_path)[:, :, :3]
それでは,元画像に推定された車の分布地図を重畳します.ここでは,この記事のきっかけとなったDeep Learning で航空写真から自動車をカウントするのコードを使わせていただきました.感謝いたします.
詳細は以下をご参照ください.
[COWC Car Counting]
(https://github.com/motokimura/cowc_car_counting)
MIT License
def get_color_map(sns_palette):
color_map = np.empty(shape=[0, 3], dtype=np.uint8)
for color in sns_palette:
r = int(color[0] * 255)
g = int(color[1] * 255)
b = int(color[2] * 255)
rgb_byte = np.array([[r, g, b]], dtype=np.uint8)
color_map = np.append(color_map, rgb_byte, axis=0)
return color_map
def overlay_heatmap(
cars, background_image, car_max, grid_size, cmap,
line_rgb=[0, 0, 0], line_thickness=2, alpha=0.5, min_car_to_show=1, background_rgb=[0, 0, 0]):
yi_max, xi_max = cars.shape
result = background_image.copy()
heatmap = background_image.copy()
sns_palette = sns.color_palette(cmap, n_colors=car_max + 1)
color_map = get_color_map(sns_palette)
for yi in range(yi_max):
for xi in range(xi_max):
top, left = yi * grid_size, xi * grid_size
bottom, right = top + grid_size, left + grid_size
cars_counted = cars[yi, xi]
if cars_counted < min_car_to_show:
if background_rgb is not None:
heatmap[top:bottom, left:right] = np.array(background_rgb)
else:
heatmap[top:bottom, left:right] = color_map[cars_counted]
if line_thickness > 0:
cv2.rectangle(heatmap, (left, top), (right, bottom), line_rgb, thickness=line_thickness)
cv2.addWeighted(heatmap, alpha, result, 1 - alpha, 0, result)
return result
処理画像をresultディレクトリに保存します.
if not os.path.exists('../data/result'):
os.mkdir('../data/result')
heatmap_overlayed = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='viridis', line_thickness=-1)
fig = plt.figure(figsize=(15, 15))
plt.imshow(heatmap_overlayed)
plt.imsave('../data/result/heatmap_' + files[0], heatmap_overlayed)
出力

これでは分かり難いですね.詳しくはgithubにアップしたコードにてご確認ください.
次に,テスト画像に推定された車の台数も表示させます.こちらも,提供されているコードを利用させていただきました.
heatmap_overlayed_2 = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='Reds')
def plot_counts_on_heatmap_2(heatmap_overlayed, aoi_tblr, cars, grid_size, min_car_to_show=1, figsize=(15, 15)):
top, bottom, left, right = aoi_tblr
yi_min, xi_min = int(math.floor(top / grid_size)), int(math.floor(left / grid_size))
yi_max, xi_max = int(math.ceil(bottom / grid_size)), int(math.ceil(right / grid_size))
top, left, bottom, right = yi_min * grid_size, xi_min * grid_size, yi_max * grid_size, xi_max * grid_size
fig = plt.figure(figsize=figsize)
plt.imshow(heatmap_overlayed[top:bottom, left:right])
for (yi, xi) in itertools.product(range(yi_min, yi_max), range(xi_min, xi_max)):
car_num = cars[yi, xi]
if car_num < min_car_to_show:
continue
plt.text(
(xi + 0.5) * grid_size - left, (yi + 0.5) * grid_size - top, format(car_num, 'd'),
horizontalalignment="center", verticalalignment="center", color="black"
)
plt.show()
fig.savefig('../data/result/heatmap_carcount_' + files[0])
top, bottom, left, right = 1000, 4500, 2000, 4500
heatmap_carcount = plot_counts_on_heatmap_2(heatmap_overlayed_2, (top, bottom, left, right), cars_counted, grid_size)

おおよそ合っているかな.車の処理場なのか,一部に車が集中して駐車されていました.
これで,航空写真のデータから,車の台数を推定するモデルの構築,テスト画像による検証,そして元画像への重畳処理が準備できました.
長くなりましたが,次が衛星画像に同様の処理を行い,車の台数地図を作成してみます.
6. 人工衛星画像の車の台数分布を求める.
6.1 人工衛星画像のダウンロード.
デモンストレーションする衛星画像を入手します.
モデルの構築で用いたい航空写真の分解能が15cmであり,その分解能になるべく近い高分解能の光学観測画像を探しました.商業衛星として画像提供がされているのは米国のDigital Globe社のWorld Viewシリーズが候補になります.この衛星の観測画像の分解能は30cmです.
高分解能の光学観測画像はかなり高価なため容易に購入することはできません.そのため,今回は公開されているサンプルデータを用いて処理を行いました.
サンプル画像は以下のサイトの画像を用いています.
WorldView-3 Satellite Sensor/Satellite image corporation
では,データのダウンロードを行います.
# 衛星画像を格納するディレクトリの準備
if not os.path.exists('../data/test/demo'):
os.mkdir('../data/test/demo')
if not os.path.exists('../data/test/demo/image'):
os.mkdir('../data/test/demo/image')
# 衛星画像のダウンロード(ブラジル リオデジャネイロ)
!wget -P ../data/test/demo https://content.satimagingcorp.com/static/galleryimages/Satellite-Image-2016-Olympics-Rio-De-Janeiro.jpg
では,取得した衛星画像を確認し前処理を行います.
6.2 人工衛星画像のデータ処理.
画像の閲覧およびサイズを確認します.
# ファイルのパスを取得する.
test_path = '../data/test/demo/'
files =os.listdir(test_path)
# ファイル名の取得
print(files[1])
# opencvで画像のよみこみ
im = cv2.imread(test_path + files[1])
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
# Image.fromarray(im_rgb).save('test.jpg')
plt.imshow(im_rgb)
# 画像サイズの確認
v_size = im_rgb.shape[0]
h_size = im_rgb.shape[1]
print('v_size:', v_size)
print('h_size:', h_size)
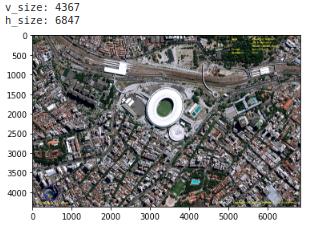
この画像は,2016年のリオデジャネイロオリンピック時の撮像画像になります.オリンピクックの競技場が確認できますね.近くの駅の周辺に多数の車が駐車されていることも確認できました.
次にこの画像を分割し,航空写真を学習した構築したモデルで車の台数を推定します.
分割する画像のグリッドサイズは,航空写真の半分の分解能となるため,スケールを合わせる意味で50ピクセルとしました.
# 分割する画像サイズを50ピクセルとする.
vn = v_size //50 #100pixleに分割
hn = h_size // 50
# グリッドサイズの整数倍になるように画像をリサイズする.
img = Image.open(test_path + files[1])
img_size_v = vn * 50
img_size_h = hn * 50
# 画像のリサイズ処理
img_resize=img.resize((img_size_h,img_size_v))
plt.imshow(img_resize)
では,画像の分割処理,およびいつものDataset,Dataloaderを作成します.
# デモ画像を基準のグリッドサイズで分割する.
width = 50
height = 50
DIR_OUTPUTS = '../data/test/demo/image/'
# 画像の分割処理関数
def ImgSplit(im):
# 読み込んだ画像を100*100ピクセルのサイズに分割する.のサイズで72*72枚に分割する
buff = []
# 縦の分割枚数
for h1 in range(int(vn)):
# 横の分割枚数
for w1 in range(int(hn)):
w2 = w1 * height
h2 = h1 * width
#print(w2, h2, width + w2, height + h2)
c = im.crop((w2, h2, width + w2, height + h2))
buff.append(c)
return buff
# 画像の分割処理の実行
hi=0
for ig in ImgSplit(img_resize):
hi=hi+1
#print(hi)
# 保存先フォルダの指定
ig.save(DIR_OUTPUTS+str(hi)+".png")
# test_listの作成
def make_datapath_list_test(phase="test"):
rootpath = "../data/test/demo/image"
target_path = osp.join(rootpath +'/*.png')
print(target_path)
path_list = [] # ここに格納する
# globを利用してサブディレクトリまでファイルパスを取得する
for path in glob.glob(target_path):
path_list.append(path)
return path_list
# 実行
test_list = make_datapath_list_test(phase="test")
# test画像の前処理をするクラス
# resize, normalize and totnesorを行う.
class ImageTransform_test():
def __init__(self, resize, mean, std):
self.data_transform = {
'test': transforms.Compose([
transforms.Resize(resize), # リサイズ
#transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り
transforms.ToTensor(), # テンソルに変換
transforms.Normalize(mean, std) # 標準化
])
}
def __call__(self, img, phase='test'):
"""
Parameters
----------
phase : 'train' or 'val'
前処理のモードを指定。
"""
return self.data_transform[phase](img)
航空写真と同様にnatsortでファイルの順番を行列の順序にあわせてソートします.
# natsoatを用いてファイルの順番をソートする
from natsort import natsorted
test_list = natsorted(test_list)
分割した画像を読み込んでみます.
# 訓練時の画像前処理の動作を確認
# 実行するたびに処理結果の画像が変わる
# 1. 画像読み込み
image_file_path = test_list[0]
img = Image.open(image_file_path).convert('RGB') # [高さ][幅][色RGB]
# 2. 元の画像の表示
plt.imshow(img)
plt.show()
# 3. 画像の前処理と処理済み画像の表示
size = 96
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
transform = ImageTransform(size, mean, std)
img_transformed = transform(img, phase="val") # torch.Size([3, 224, 224])
# (色、高さ、幅)を (高さ、幅、色)に変換し、0-1に値を制限して表示
print(img_transformed.shape)

この分割された画像は衛星画像の左上の画像で,どうみても山道で車はみあたらないですね.
では,この画像の構築したモデルで車の台数を推定してみます.
Dataset, Dataloaderを作成します.
# test画像のDatasetを作成する
class CarCountDataset_test(torch.utils.data.Dataset):
def __init__(self, file_list, transform=None, phase='train'):
self.file_list = file_list # ファイルパスのリスト
self.transform = transform # 前処理クラスのインスタンス
self.phase = phase # train or valの指定
def __len__(self):
'''画像の枚数を返す'''
return len(self.file_list)
def __getitem__(self, index):
'''
前処理をした画像のTensor形式のデータとラベルを取得
'''
# index番目の画像をロード
img_path = self.file_list[index]
img = Image.open(img_path).convert('RGB') # [高さ][幅][色RGB]
# 画像の前処理を実施
img_transformed = self.transform(
img, self.phase) # torch.Size([3, 224, 224])
# 画像のラベルをファイル名から抜き出す
label == 0
return img_transformed, label
# 実行
test_dataset = CarCountDataset_test(
file_list=test_list, transform=ImageTransform(size, mean, std), phase='val')
# 動作確認
index = 0
print(test_dataset.__getitem__(index)[0].size())
print(test_dataset.__getitem__(index)[1])
batch_size =10
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False)
dataiter = iter(test_dataloader)
images, labels = dataiter.next() # サンプルを1つだけ取り出す
plt.imshow(np.transpose(images[0], (1, 2, 0))) # チャンネルを一番後ろに
plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に
plt.show()
net.eval() # 評価モード
x, t = images.cuda(), labels.cuda() # GPU対応
print(x.shape)
# x, t = images, labels # CPU対応
y = net(x)
print("予測された車の数:", y[0].argmax().item())
# 2. 元の画像の表示
print('元の画像の表示')
plt.imshow(img)
plt.show()

モデルによる推定結果は,0台,となりました.予測通りですね.
推定処理のための画像データの準備が終わりましたので,全画像に対する推定処理,および人工衛星画像への重畳処理を航空写真と同様に行います.
6.3 人工衛星画像の車の台数分布の作成.
分割した衛星画像を航空写真より構築したモデルにて推定処理を行います.
# ミニバッチのサイズを指定
batch_size = 10
# 対象画像のdataloaderを作成
test_dataloader = torch.utils.data.DataLoader(
test_dataset, batch_size=batch_size, shuffle=False)
classes = list(range(13))
class_correct = list(0. for i in range(13))
class_total = list(0. for i in range(13))
net.eval() # 評価モード
test =[]
i = 0
for data in test_dataloader:
images, labels = data
x, t = images.cuda(), labels.cuda() # GPU対応
#x, t = images, labels # CPU対応
#outputs = net(x)
#_, predicted = torch.max(outputs, 1)
#print('predicted:', predicted)
y = net(x)
for i in range(len(y)):
result = y[i].argmax().item() #GPUのtensorをnpに変換するにはargmaxを用いる必要がある.
test.append(result)
print('分割された画像数: ', len(test))
分割した画像数は11832でした.では,この推定結果を衛星画像に重畳するための行列に変換します.
test2 = np.array(test)
cars_counted =test2.reshape(int(vn), int(hn))
次に,衛星画像を読み込みます.
file_path = test_path + files[1]
mosaic_image = io.imread(file_path)[:, :, :3]
mosaic_image=cv2.resize(mosaic_image, (img_size_h,img_size_v))
print(mosaic_image.shape)
そして,航空写真と同様にこちらのコード[COWC Car Counting]
(https://github.com/motokimura/cowc_car_counting)を利用させていただき,衛星画像への重畳処理(台数が多い地域をフォーカスしたヒートマップ)を行います.
heatmap_overlayed = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='viridis', line_thickness=-1)
fig = plt.figure(figsize=(15, 15))
plt.imshow(heatmap_overlayed)
plt.imsave('../data/result/heatmap_' + files[1], heatmap_overlayed)
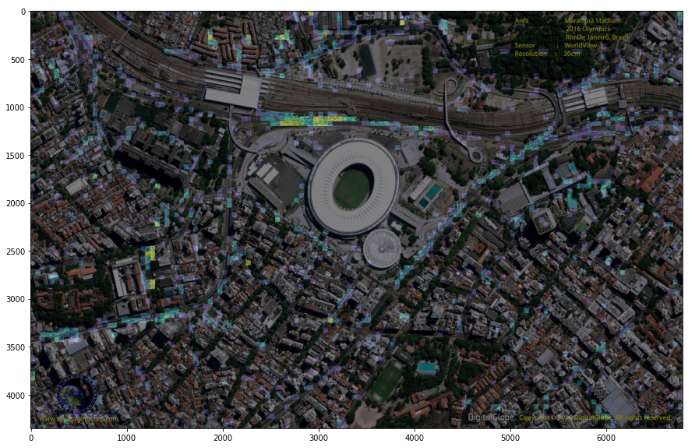
Copyright©2016DigitalGlobe.
オリンピックの競技場の左上の駅周辺に車が多く駐車されているのがわかります.
この画像では分かり難いと思いますので,ぜひご自身でコードを実行するか,Githubのサンプル画像をご確認ください.
次に,航空写真と同じく車の台数を表示させます.
heatmap_overlayed_2 = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='Reds')
def plot_counts_on_heatmap_2(heatmap_overlayed, aoi_tblr, cars, grid_size, min_car_to_show=1, figsize=(100, 100)):
top, bottom, left, right = aoi_tblr
yi_min, xi_min = int(math.floor(top / grid_size)), int(math.floor(left / grid_size))
yi_max, xi_max = int(math.ceil(bottom / grid_size)), int(math.ceil(right / grid_size))
top, left, bottom, right = yi_min * grid_size, xi_min * grid_size, yi_max * grid_size, xi_max * grid_size
fig = plt.figure(figsize=figsize)
plt.imshow(heatmap_overlayed[top:bottom, left:right])
for (yi, xi) in itertools.product(range(yi_min, yi_max), range(xi_min, xi_max)):
car_num = cars[yi, xi]
if car_num < min_car_to_show:
continue
plt.text(
(xi + 0.5) * grid_size - left, (yi + 0.5) * grid_size - top, format(car_num, 'd'),
horizontalalignment="center", verticalalignment="center", color="black", size=25
)
plt.show()
fig.savefig('../data/result/heatmap_carcount_' + files[1])
top, bottom, left, right = 0, 1550,2000, 4000
heatmap_carcount = plot_counts_on_heatmap_2(heatmap_overlayed_2, (top, bottom, left, right), cars_counted, grid_size)

Copyright©2016DigitalGlobe.
車の台数の表示数が小さくて見づらいです.フォントサイズは上記のコードのSizeを変更すれば変えられますので,試してみて下さい.こちらもgithubにサンプル画像をアップしていますので,そちらでもご確認ください.
7. まとめ
こちらの記事を参考に,PyTorchによる航空写真を用いた車の台数の推定モデルの構築,および構築したモデルを用いた衛星画像の車の台数分布地図を作成しました.
衛星画像を対象とするのであれば,学習画像も同じ性能(分解能)の画像のほうがより精度の高い結果が得られると思います.手間はかかりますが,分割した画像に写った車の台数を見て確認し,それを区分けして学習用データを作ってもいいですね.
衛星画像の利用方法としてよく紹介されている写っている車の台数を推定する方法の一例を紹介いたしました.実際に提供されているサービスは,より高精度のモデルで構築されていると思います.ここで紹介したモデルは一つの例であり,学習画像をより汎用性の高いものにするために種類を増やしたり,Augmentationの方法を工夫したり,モデルを変更したりなど,色々試してみると面白いかもしれません.
また,ここでは車の台数を対象としましたが,今回のように物体検知ではなく画像分類の方法であれば,車以外の対象物にも同じ方法が適用できますので,試してみるのもよいですね.
本文にも記述しましたが,車の台数の絶対値を求めるのではなく,異なる時期の複数の画像をもちいて,時系列的な変化を求めてみるのがおもしろいかと思います.ある地域を対象として,年間でどのように分布がかわるのか,時期に依存するのか,年レベルでの長期間の傾向は,などのトレンドが把握できるかと思います.
最後になりますが,この実験および記事のきっかけとなったDeep Learning で航空写真から自動車をカウントするにあらためて感謝いたします.
こちらの記事がみなさんの活動のご参考になれば幸いです.間違いやコメントなどありましたら,いただければ幸いです.
参考記事
Deep Learning で航空写真から自動車をカウントする
Pytorchによる航空画像の建物セグメンテーションの作成方法.
書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニング」(小川雄太郎、マイナビ出版 、19/07/29)
ディープ・ラーニングにおける物体検出
Cars Overhead With Context
WorldView-3 Satellite Sensor/Satellite image corporation