Aidemy 2020/12/3
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、ランキング学習の2つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・
・
前準備
データの準備
・今回は__LETORデータセット__を使っていく。これは、ランキング学習__の際に使われるデータセットであり、Microsoftによって公開されている。
・LETORデータセットには様々な形式が用意されているが、今回は__教師あり学習用のデータ__を使用する。また、バージョンはMQ2008を使用する。このデータセットは、「正解ラベル(0,1,2)」「クエリID」「46次元の特徴ベクトル」__を含む。
・コード(今回はあらかじめ取得したものを使用)
・結果(一部のみ)
データの整形
・前項で取得したデータセットについて、「訓練/テストデータへの分割」「ラベル・特徴ベクトル・クエリへの分割」の2つを行う。
・「訓練/テストデータへの分割」は通常の機械学習の時と同様、「train_test_split」で行う。テストサイズはデフォルトで0.25なので、今回はそのままで使用する。
・「ラベル・特徴ベクトル・クエリへの分割」について、「ラベル(y)」は__dataの0列目__にあり、順序はそのままで取り出す。「特徴ベクトル(X)」は__dataの2〜47行目__にある。「クエリ(qlist,qid)」は__dataの1行目__にあり、「qlist」はクエリの重複があっても良いが、「qid」はクエリの重複は削除される。
・以下はここまでを行ったコードである。qid以外は__DataFrame型、qidのみ__ndarray型__で作成する。さらにqidについては、「qlist」について「drop_duplicates()」__を使うことで__重複を削除する__ことができる。

・結果(それぞれ前から5つ取得)
二値分類
予測と重み更新
・ここでは__パーセプトロン__のアルゴリズムを実装していく。パーセプトロンは予測と重みベクトルの更新を繰り返して学習を行う。今回は、ラベルを予測する関数__「predict」、予測ラベルと正解ラベルが異なっていた時のみ重みベクトルを更新する関数「modify」__を実装する。
・実装は以下の通り。

・コードの説明として、「predict」は特徴ベクトルXと重みベクトルwを受け取り、「np.dot()」で__内積__を取り、この符号が正なら「+1」、負なら__「-1」を返すようにする。これは「np.sign()」で実装できる。
・「modify」__は、学習率c__を決め、渡された予測ラベルpredict_yと正解ラベルactual_yが同一でない場合は「w += actual_y*c*X」__で重みベクトルを修正し、これを返している。
・また、これらの関数に渡すデータについて、特徴ベクトルは__正規化__し、ラベルyは行列の形を加工している。

・最後に、実際にfor文の中で、すべてのトレーニングデータについて「predict」と「modify」関数を使い、重みベクトルを学習させている。

・結果
ランキングの作成、評価
・前項の操作によって、重みベクトルが学習されたので、これと特徴ベクトルXの__内積__を取ることで__ランキング関数を算出__し、これに基づいて各特徴ベクトル$X_i$にスコアをつけ、その__降順に並べたランキング__を生成する。
・さらに、性能評価指標である__「precision@K」「Average Presicion」「Reciprocial Rank」__を実装してランキングを評価する。
・ランキング関数を算出する関数__「f()」は、そのまま特徴ベクトルXと更新した重みwの内積を返せば良い。また、ランキングは「sort_values(ascending=False)」__でスコアの高い順(降順)に並べ替える。
・コード
・結果
・precision@Kを実装する関数__「precision_at()」__は、ランキングk位までの__適合である割合__を算出すればよいが、ランキングk位までにデータが存在しない場合、分母が0__になってしまいエラーが発生するため、この時は「0」を返すようにする。これを「ゼロ除算」という。
・ランキングi位が適合であるかどうかは「label」の「i番目」が「1」__であるかどうかでわかる。
・AveragePrecisionを実装する関数__「AP()」___は分子がランキングk位までprecition_at()で算出した値の合計(sum)、分母がランキングの個数(devby)として、平均を取る。ここでもゼロ除算を行う。
・ReciprocialRankを実装する関数__「RR()」は、初めて「適合」が出てきた順位の__逆数__を取れば良いので、普通に__for文で適合かどうかを探していき、適合なものがあった時点でその時の順位iについて__「1/(i+1)」__を返せば良い。(i+1なのはランキングは1位からであるが、インデックスは0からスタートしているため)また、今回は分母が0になることはないので、ゼロ除算は必要ない。
・コード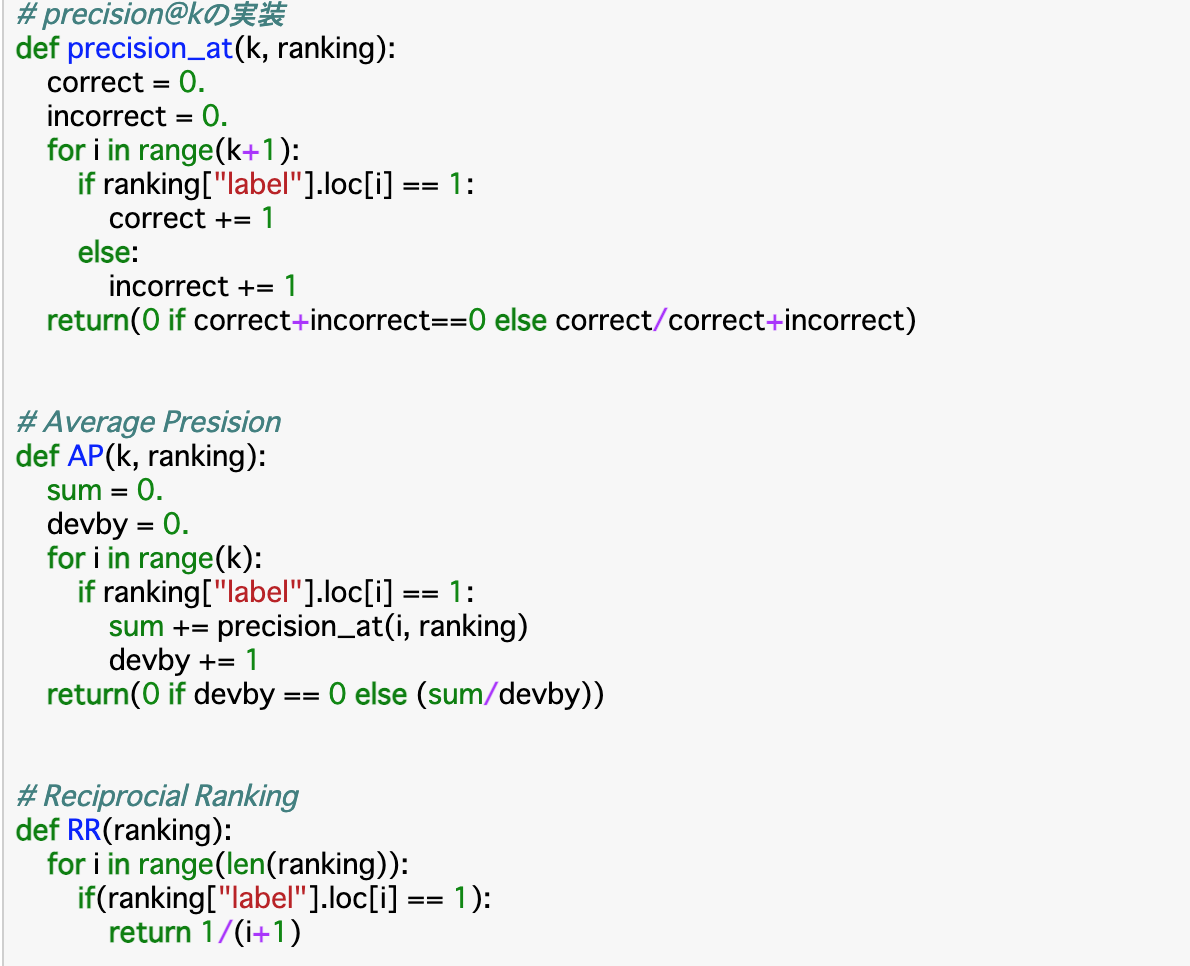
・結果

PRank
予測と重み更新
・__PRank__はランキング関数と複数の__閾値__によって__離散値のラベル__を予測する手法である。よって、重みベクトルwだけでなく、閾値$\tau$も学習させる必要がある。
・ラベルを学習し予測する関数__「predict()」について、渡された__label_list__と__b__からlabelとthを一つずつ取り出し、「np.dot(X,w)-th<0」を最初に満たすものが__最小のラベル値__となるので、これを__予測ラベルとして返す。
・閾値ベクトル$\tau$を更新する関数__「tau()」__について、Chapter1で確認したように、r__が「予測ラベル以上正解ラベル未満」なら「+1」、「正解ラベル以上予測ラベル未満」なら「-1」、それ以外なら「0」が$\tau^r_0$となる。よってここでもその通りに記述すれば良い。
・重みベクトルwを更新する関数「modify_w()」について、$w_t+1$は、$w_t$に、$\tau$の__要素和__を特徴ベクトルの各要素と__掛け合わせたものを足す__ことで算出できる。コードでは、「tau()」に「np.sum()」を使って$\tau$の要素和を算出し、これに「X」__をかけたものを、元の__w__に足している。
・閾値b__を更新する関数「modify_b()」について、これは、bから、その時点での__閾値ベクトル$\tau$を引くことで算出できる。

・あとは、__train_X__のそれぞれについて、__predict()__で予測ラベルを定義し、__modify_w__と__modify_b__でそれぞれwとbを更新することで学習させる。そして、更新した値を使ってテストデータのラベルを予測し、正解ラベルと照らし合わせる。
・コード
・結果
ランキングの評価
・二値分類の時とは違い、PRankは__ラベルが0以上の離散値__で与えられているので、このような場合の評価指標は__DCG,NDCG__を使うと良い。
・DCG__はランキング第二位以降のk位に「$1/log2(k)$」をかけることで実装する。第一位はそのまま足せば良いので、_「ranking["actual_label"].iloc[0]」で第一位(iloc=0)のラベルを返り値「dcg」に格納する。第二位以降はforループで取り出し、「np.log2(i+1)」__で掛け合わせることで算出する。
・NDCG__は、算出したDCGを、ランキング中の__ラベルが全て最高値__であった場合のDCG「dcg_perfect」で割ることで実装する。
・ラベルの最高値「max_label」__は、label_listの最後尾の値__を見れば良い。最高値「max_label」はそのまま「dcg_perfect」__に足し合わせ、それ以下のランキングのものについては、最高値の部分をDCGと同じようにわりびいて「dcg_perfect」に足し合わせる。
・コード
Pairwise
ペアの作成
・Pairwise__では、学習データとして「クエリ文書ペア」を使うので、まずはこれを作成する。この作成にあたり、「makepair」「pairmerge」「qmerge」の3つの関数を作成する。各関数の意味などについては以下で説明する。
・Pairwiseで組とするのは、同一クエリで異なるラベルのもの__のみである。そのため、データ(train_X)を__クエリごとに分類し、さらにそれを__ラベルごとに分類__しなければならない。ここまで行って、初めて組を作ることができる。
・まずは「makepair()」で、クエリとラベルを指定して__train_Xのペアのリスト__を作成する。この時、それぞれのラベルを「score1」「score2」__として関数に渡す。
・makepair()で作成されたtrain_Xのペアについて、クエリを指定__してそれぞれの組ごとに__ラベルを統合__する関数「pairmerge()」を作成する。
・最後に__クエリを統合__する関数「qmerge()」を作成することで、「クエリとラベルが統合されたtrain_Xのペア」__が作成される。図示すると次のようになる。

・具体的なコードについて、「makepair()」は、引数で渡されたscore1,score2,qを参照して、「ラベルがscore1で、かつクエリがqであるX」を「X1」、同様にscore2について__「X2」を作成し、yについても同じように「y1」「y2」を作成する。
・この「X1」「X2」について、それぞれの組ごとに「X1.iloc[i,:]-X2.iloc[j,:]」で差分をとったものを返り値として設定するDataFrame「return_X」に格納する。「y1」「y2」についても同様に「return_y」__に格納し、これらを返す。
・コード
・「pairmerge()」について、こちらは__「クエリは指定し、ラベルは自由」であるので、「クエリは渡された__qで固定、ラベルは__(0,1,2)から選択」として「makepair()」関数で組を作成する。
・作成した全ての組について、Xとyそれぞれについて「pd.concat()」__で__連結__して、「pair_X」「pair_y」として返す。
・「qmerge()」に関しては、、__for文__で全てのクエリについて「pairmerge()」を適用することで、「ラベルとクエリが統合されたXとy」が作成されるので、これを返せば良い。
・コード
予測と重み更新
・基本的な学習、予測の流れは二値分類の時と同じ__パーセプトロン__のアルゴリズムを実装していく。すなわち、ラベルの予測と重みベクトルの更新を繰り返すことで学習を進めていく。関数についても、ラベルを予測する関数__「predict()」と、予測が異なった場合に重みベクトルを更新する関数「modify()」__を実装していく。
・predict()については、特徴ベクトルと重みベクトルの内積を__「np.dot(X,w)」で算出し、これに「np.sign()」を使うことで符号が正なら「+1」、負なら「-1」を返すようにする。
・modify()についても、predict_yとactual_yに「np.sign()」を使った上で符号が同じかを比較し、異なる場合は、「w+=c*np.sign(actual_y)*X」と__して重みを更新する。
・2つの関数が定義できたら、for文で全てのtrain_Xについてpredict関数とmodify関数を使って重みベクトルを学習させる。
・コード
ランキングの評価
・ランキング関数によって各特徴ベクトルにスコアをつけ、その__降順でランキングを作成__する。このランキングについて、他の手法でも扱った__precision@K,AP,RR__でランキングを評価する。これらは全て二値分類の時と同じコードで実装できるので、くわしくはそちらを参照。
まとめ
・ランキング学習のデータセットである__「LETORデータセット」__を使って学習データを作成する。__train_test_split()__を使う。
・この学習データを使って__重みベクトルを学習__する。二値分類__は__パーセプトロン__のアルゴリズムで作成できるので、予測関数「predict()」と、更新関数「modify()」を実装する。また、「precision@K」__などのランキング評価指標を使って評価を行う。
・__PRank__はラベルが__離散値__なので、閾値ベクトル$\tau$も学習させる。評価については、__DCG、NDCG__が有効である。
・Pairwise__は訓練データを「文書クエリペア」__にして渡す。それ以外は基本的に二値分類と同じ。
今回は以上です。最後まで読んでいただき、ありがとうございました。