Aidemy 2020/11/10
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、異常検知の3つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・累積和法を使った変化検知
・近傍法による異常部位検知
・特異スペクトル変換法
累積和法による変化検知
累積和法とは
・累積和法__は__変化点(Chapter1参照)を検出する__「変化検知」の一手法である。変化検知は外れ値の検出と違って「継続的な異常」__が発生するので、これを検出できる累積和法が使われる。
・累積和法は「異常である状態(変化度)」を__時間に沿って__カウントし、そのカウント(累積和)が閾値を超えたときに異常と判定する。つまり、時系列データにおける何らかの値の異常を検知するときにはこの手法が適していると言える。
・累積和法(変化が上振れ、つまり上昇するのが異常である場合)の流れは以下の通りである。
①正常時の目安と上振れの目安を与えて__変化度を定義する__
②変化度の__上側累積和を求める__
③閾値を超えていたら異常と判断する
①正常時の目安と上振れの目安を与えて変化度を定義する
・変化度__とは、データがどれぐらい異常状態に変化しているかを示す値である。
・ここでは変化度を定義するが、それには、「正常であるときに取る値(μ)」「異常と判定する上振れの値(ν+)」を事前に(過去の事例を分析して)取得する必要がある。
・また、データから「標準偏差(σ)」も求めておく。「np.std()」__で求められる。
・ここまで求めたら、時刻tにおける__変化度(a+(t))_は以下のように求められる。
$$
a{+}(t) = \left( \frac{\nu {+}}{\sigma} \right)\frac{{ x(t)} - \mu - \nu {+} / 2}{\sigma}
$$
(式の「x(t)」__は、時刻tにおける観測値)
・これにより、データが正常な時は変化度が負になり、異常な時は正になるので、累積和で処理することが可能になる。
・また、今回は変化が上振れの時を考えたが、下振れの時も同じように計算できる。
・コード(正常時10、上振れ時14として変化度を計算)

・結果
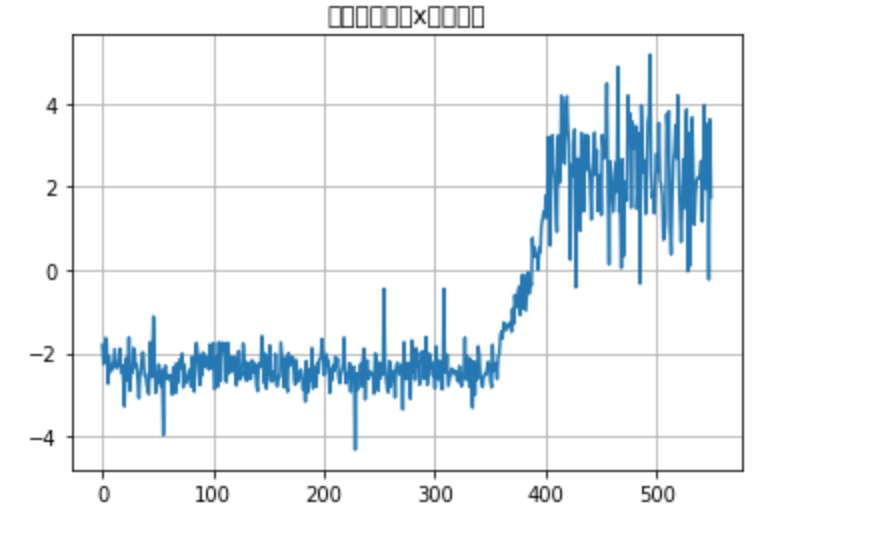
②変化度の上側累積和を求める
・前項で変化度を求めたので、次はそれを累積していく。前項で定義した変化度では、正常な時は負の値をとるが、累積するにあたっては、正常時は0となるようにする。つまり、異常な時だけ変化度は上昇していく。これが、__上側累積和__である。
・上側累積和の算出は、__forループ__を使って変化度を一つ一つ取り出して足し合わせることによって行う。具体的には以下の通り。

・上記コードの解説
・for文の__「range(x.size - 1)」の部分で「-1」しているのは、時刻tまでの上側累積和は「t-1までの変化度の合計 + tの変化度」で求められるため、この「t-1」を表現するためにこのように取り出している。
・「max(0, x_cumsum[i])」は、累積和を格納する配列には「0と変化度の大きい方を格納する」ことを示す。
・「x_cumsum[i + 1] = x_cumsum[i] + x[i + 1]」の「i+1」__は、__iがt-1を表している__ので、実質的に「t」であることを示す。
・上側累積和をグラフにすると以下のようになる。

③閾値を超えていたら異常と判断する
・あとは、今までの手法と同様に、閾値と累積和を比較して異常かどうかを判定すれば良い。
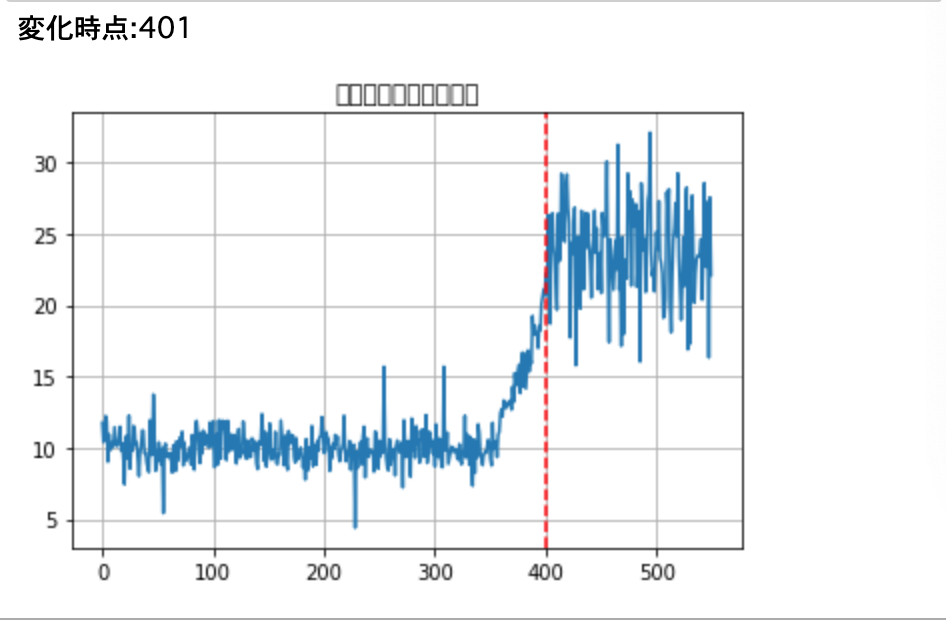
・また、初めて閾値を超えた点、すなわち「変化点」を見つけるには、__「0から累積和の大きさまでの間で、初めてpred==1となったインデックス」__を求めれば良いので、以下のように記述できる。
np.arange(score_cumsum.size)[pred==1][0]
・「np.arange__で範囲を0~累積和の大きさに限定して一つずつ参照し、[pred==1]で初めて異常と判定された部分を抽出し、[0]__でインデックスを取り出す」ということが行われている。
・異常について行ったものが以下になる。

・結果
近傍法による異常部位検出
スライド窓、部分時系列
・今回は、時系列データを__「外れ値検知」で異常検知を行う__。前項までの累積和法では閾値や変化点計算のパラメータなどを自分で用意しなければならず、__あまり実用的ではない__というデメリットがあったが、__近傍法を使う__ことで、この問題を解消できる。
・外れ値検知は時系列データの変化検出に向いていないのであるが、それは、時系列データのような__継続的なデータを観測できないから__である。今回の近傍法では、そのような問題を解決するように__工夫する__ことで、これを可能にしている。
・具体的には、各データをM個の隣接したデータとしてまとめる、すなわち、M次元のベクトルの集まりに変換する__ことで、時間的な影響を考慮することを可能にする。
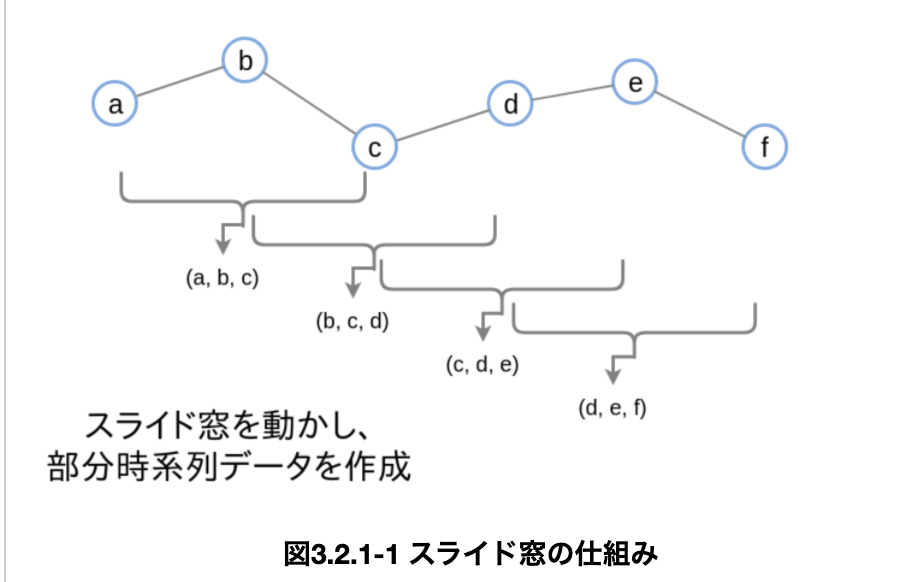
・この時の「M」個に分ける長さを「スライド窓」といい、これによって作成されたベクトルの集まりを「部分時系列データ」__という。例えば、以下では長さ3のスライド窓を使ってデータを変換している。
・コードとしては以下のようになる。データを__一次元から二次元に変換__したあと、スライド窓__Mの個数分のデータを分割__し、それを__抽出する__ことで作成する。
・コード(550個のデータxを部分時系列データに変換)

・以上を実行した時、部分時系列のデータの長さは__「((データ数 - M + 1), M)」__となる。
異常度の計算
・部分時系列データを作成したら、異常度を計算していく。今回は、最近傍との距離を異常度とした__「最近傍法」__を使っていく。詳しくはChapter2参照。KNeiborsClassifier__を使って__最近傍との距離__を算出していく。
・今回の「n_neighbors」は、1ではなく__2__に設定する。データの最近傍は「そのデータ自身」と扱われてしまうためである。そのため、最近傍距離は「2番目に近いデータの距離」ということになる。
・よって、「clf.kneighbors()」で各データの近傍距離を算出し、そこから「dist[:, 1]」__で二番目に近いデータの距離を取得すれば良い。
・コード

閾値の設定、異常判定
・次に、閾値を設定する。この手法ではデータの分布を定義しないので、1クラスSVMと同じ__ように閾値を設定する。
・具体的には「st.scoreatpercentile()」を使用する。「データには一定の割合で異常データがある」と仮定して、その割合「a」を設定し、異常度「distances」を渡すことで閾値を設定してくれる。
・今回は__異常度が大きいほど異常である__というようにしたいので、引数に渡す分位点は「100-a」__とする。
・コード(上位30%を分位点とする場合)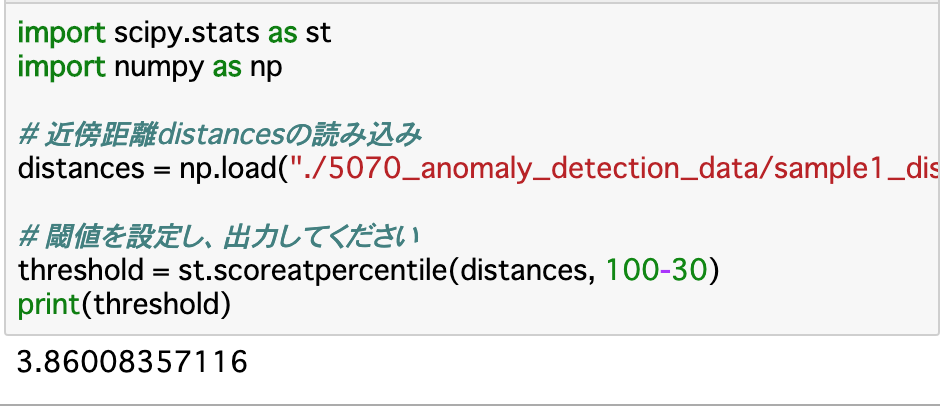
特異スペクトル変換法
履歴行列とテスト行列
・前項までの部分時系列データによって、過去と現在を分けることで、より高度な分布を考察することが可能になった。今回学ぶ__「特異スペクトル変換法」は、この高度な分布を定義することで「現時点のデータを代表するベクトルと過去のデータを代表するデータ」の二つを求め、この__二つの差異を変化点とする__ことで異常検知を行うという手法である。
・特異スペクトル変換法の流れは以下になる。
①時系列データに対し、窓幅M、履歴行列の行数n、テスト行列の列数k、ラグL__を与える
②データを窓幅Mの__部分時系列データに変換する
③__履歴行列__と__テスト行列__を作る
④履歴行列とテスト行列を__特異値分解__し、それぞれの__左特異ベクトルの行列__を求める
⑤2つの行列の差異から__変化度を計算する
・以上で出てきた__「履歴行列」とは、「現時点から__時間的に一つ前のデータ__をn個集めて並べたもの」である。また「テスト行列」__は「現時点から__L(ラグ)進み、そこからk個前までのデータ__を並べたもの」である。視覚的には以下を参照。

・①について、今回は__「M=50,n=25,k=25,L=13」を使用する。
・②について、部分時系列データへの変換は「近傍法による異常部位検出」__で行った手法と同様に行う。
・③について、②で作成した部分時系列データ(X_pts)から履歴行列とテスト行列の作成方法は以下を参照。

④履歴行列とテスト行列を特異値分解し、それぞれの左特異ベクトルの行列を求める
・③で作成した履歴行列とテスト行列に対して、__「特異値分解の低階層近似」__というものを行うことで、行列を代表する値を求める__ことができる。
・コードとしては、(m×n)の行列Aを特異値分解する時は「np.linalg.svd(A)」で行う。格納する変数としては、「U,S,V」の3つを用意する。今回使用するのは、そのうちの「U」__である。Uには__左特異ベクトル__というものが格納されている。左特異ベクトルとは、行列Aの代表的なベクトル__のことであり、Uはこれが優先度の高い順に並べられた行列になっているので、以下のように__階層「r」で指定する__ことで、より優先度の高い代表ベクトルを取り出せる。
・また、Uのshapeは(行列の行数,窓数M,左特異ベクトルの個数)__というようになっているので、低階層近似をするときは、第3軸をスライスする。

・これらを行ったコード([0]の部分は「U」のみを取り出している)
⑤2つの行列の差異から変化度を計算する
・前項で作成した二つの__左特異ベクトルの差異__を求めていく。差異は__ベクトルの内積__で求められる。今回はベクトルの集合、すなわち行列同士の内積を__「np.matmul()」で計算し、さらに「np.linalg.norm()」で距離を求める。
・この距離をnormとすると、変化度は「1-norm」__で求められる。
・これらを行ったコードは以下のようになる。

・結果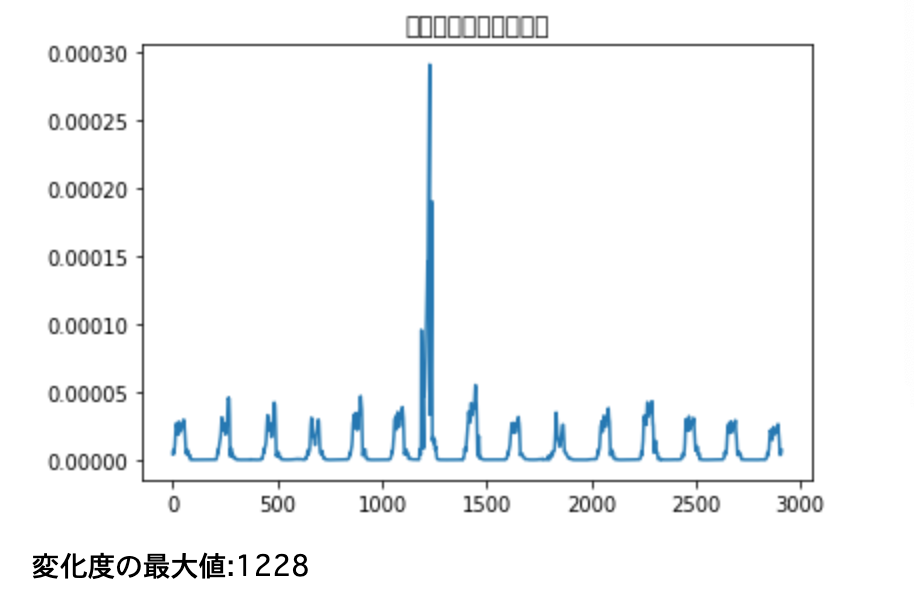
・以上のコードについて補足
・__「get_score」__は変化度を求める関数を自分で作成する。__np.matmul()では「x.T」__のように、履歴行列の方を転置させる__必要がある。
・「score」__の方は、上記get_scoreに__U_hist__と__U_test__をまとめて渡している。__for表記__になっているのは、__各時間における変化度__を計算しているからである。
まとめ
・時系列を持つ変化点検知の一手法として、「累積和法」がある。これは変化度を累積(足し算)していき、閾値以上になったら異常と判定する手法である。ただし、この閾値や計算のパラメータは自分で算出しなければならず、実用的ではない。
・この問題を解消するのが「近傍法」を使った手法である。この手法は時系列データを外れ値検知で異常かどうかを判定するものである。本来外れ値検知と時系列データは不和であるが、隣接したデータをM個ずつに分けることでこれを解消している。
・この時のM個に分ける長さをスライド窓、作成されたデータの集まりを部分時系列データという。これらを使って異常度を最近傍法によって算出する。
・以上の手法を応用した「特異スペクトル変換法」というものも存在する。これは「現時点の代表データとかこの代表データの差異」から変化点を検出する手法である。
今回は以上です。最後まで読んでいただき、ありがとうございました。