Aidemy 2020/11/10
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、RNN_LSTMの一つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・
・
深層学習の復習
深層学習とは
(深層学習については「ディープラーニング基礎」で学習ずみ)
・深層学習__とは、ニューラルネットワークの__中間層(隠れ層)が深く設定されているモデル__のことを指す。
・ニューラルネットワークとは、脳の伝達の仕組みを応用した機械学習の一つで、「入力層」「中間層」「出力層」__からなる。
・情報が左から右に伝達するときは機械学習したい出力値が得られる一方、右から左に情報を与えてパラメータを調整する「学習」を行うことでモデルの精度を上げることもできる。
・層を深くすることで、そうしなかった場合に比べて__パラメータを少なくする__ことができ、また__学習の効率性が良い__と言う利点がある。
層の数、ユニット数の決定
・ニューラルネットワークのモデル構築において考える必要のあることの一つに、__「層の数」と「ユニットの数」がある。これらを決定する公式などはないため、探索的に決定していく__必要がある。
・一番明らかなのは、__出力層のユニット数(次元数)である。これは、分類したいカテゴリの数(クラス数)をそのまま指定すれば良い。
・その他の層のユニット数に関しては、慣習的には「(入力層+出力層)*2/3」__のユニット数からスタートすることが多い。それ以降の層は学習結果を確認しながら設定していく。
・__中間層の数__に関しては、上記手順の中でユニット数が大きくなりそうなときは追加する。
過学習対策
・過学習対策、すなわち__汎化する__手法としてまずあげられるのが__「DropOut()」__である。これは決められた割合だけノードを学習しないことで汎化する手法である。一般的には__50%の割合を設定する。
・ドロップアウトは「model.add(Dropout(割合))」__で行える。
・汎化のもう一つの手法としてあげられるのが__「Early Stopping」である。これは、繰り返しの学習の中で__精度が上がらなくなったら学習をストップ__し、過学習を防ぐ手法である。
・精度はトレーニングデータとテストデータの__誤差がほぼ等間隔__である時が最も良いと言える。
・Early Stoppingは「EarlyStopping()」で行うことができる。パラメータとしては「monitor='val_loss'」で誤差を精度の判断基準にすると決め、「patience」で誤差を判断する過去のデータ数を指定し、「mode」__で収束していると判定する定義(上限か下限か)を指定する。
RNN/LSTM
RNNについて
(RNNについても「時系列分析」で学習ずみ)
・__RNN__は、時系列データを扱える__ニューラルネットワークのことである。時間の概念をニューラルネットワークに取り込むために、過去の情報をモデル内で保持している。
・ただし、時系列が進むほど勾配が消失したり、演算量が爆発的に増える「勾配爆発」__を起こすことがあるため、長期の学習には適さない__と言う問題点がある。
・一応、勾配爆発に関しては、「勾配の値が閾値を超えていたら勾配を修正する」と言う「勾配クリッピング」__と言う解決策がある。
LSTMについて
・上記RNNの問題点を解決したものが__「LSTM」__である。RNNの中間層をLSTMブロックに置き換えることで長期に文脈を保持することができる。
ユニクロの株価データ予測
モデル作成までの処理を関数で定義
・今回のデータは__「ユニクロの株価データ」__を使用する。今回は「15日過去のデータ__から、翌日のデータ__を予測する」ということを行う。
・コードでは、まずデータをn日(window_size)ごとに分ける「apply_window()」関数を作成している。
・次に、データをトレーニングデータとテストデータに分ける「split_train_test()」関数を作成する。今回はデフォルトで__7割__をトレーニングデータとしている。
・データを読み込む関数「data_load()」も作成する。データを読み込んだら、'Date'列を日付データとして認識させ、それに基づいて日付順にソートする。最後にその順番で__終値('Close'列)を取得する。
・ここまで行ったら、モデルを定義して学習までを行う「train_model()」を作成する。入力層のユニットサイズは、今回は「15日分のデータ」が入力されるので、「15」__とする。モデルは__Sequential()__を使い、時系列データは__LSTM層__で扱う。層を定義したらコンパイルを行い、今回は学習回数(epochs)10__で学習させる。
・最後にモデルを予測する「predict()」関数を作成する。返すときは「pred.flatten()」のようにして「一次元のNumPy配列」__にして返す。
・コード
スケール調整(標準化)
・これまでの関数を使っていよいよモデルを実装する。データを__「data_load()」で読み込み、終値を取得し、「split_train_test()」でデータを分割したら、モデルにデータを渡す前に、データをスケール調整する。今回は__標準化__を行う。
・標準化は「StandardScaler()」でインスタンスを作成し、トレーニングデータには「fit_transform()」でデータの平均分散を求めた上で標準化を行い、testとデータには「transform()」__で標準化のみを行う(テストデータを標準化の定義に使うと精度が低くなるため)。
・標準化を行ったら、__「apply_window()」でデータを分割していく。今回window_sizeは15としているが、ここでは「次の日の終値」もサイズに入れたいので、引数は「window_size+1」とする。これによって分割されたデータのリストの一番後ろ(-1)を正解ラベル(y_train)、それ以外の15個のデータを訓練データ(X_train)として、「train_model()」__に渡す。あとは「predict()」で予測したら完了。
・さらに今回predictで予測したデータとテストデータを図で比較したいときは、__「inverse_transform()」でデータを元に戻してから「plt.plot()」__で図示すれば良い。
・コード
・結果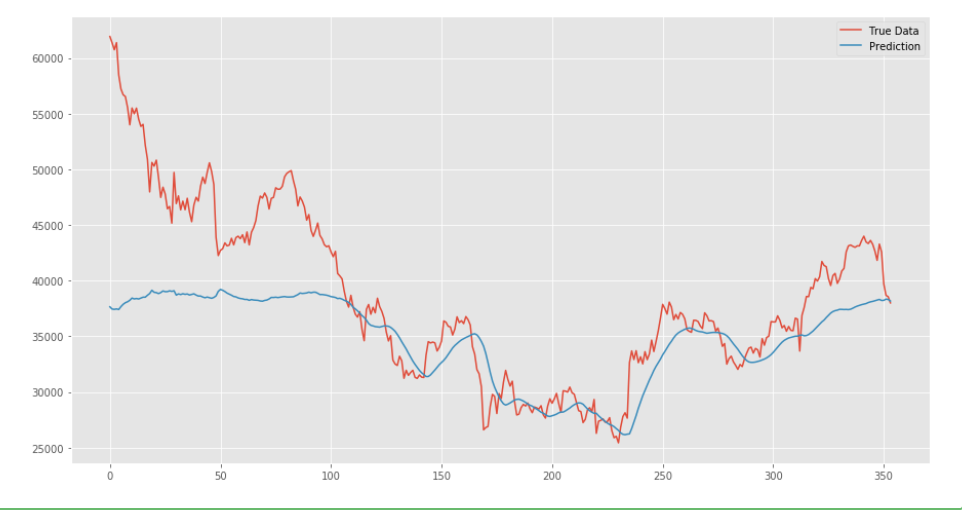
(発展)10日後の終値を予測する
・前項では、予測できた終値は一日分であったが、この予測を__一日ずつずらして十日分行うこ__とで、10日後の終値を予測するモデル__が作成できる。
・具体的な手法としては、10回分の予測を行う関数「predict_ten_days()」関数を作成し、これにデータとモデルを渡せば良い。ただし、「window_size以上(365-window_size)未満」のテストデータのどこを始点とするかを「start_point」__で定義し、この位置からデータを使用する。
・コード(追加点のみ、start_pointは任意)

・結果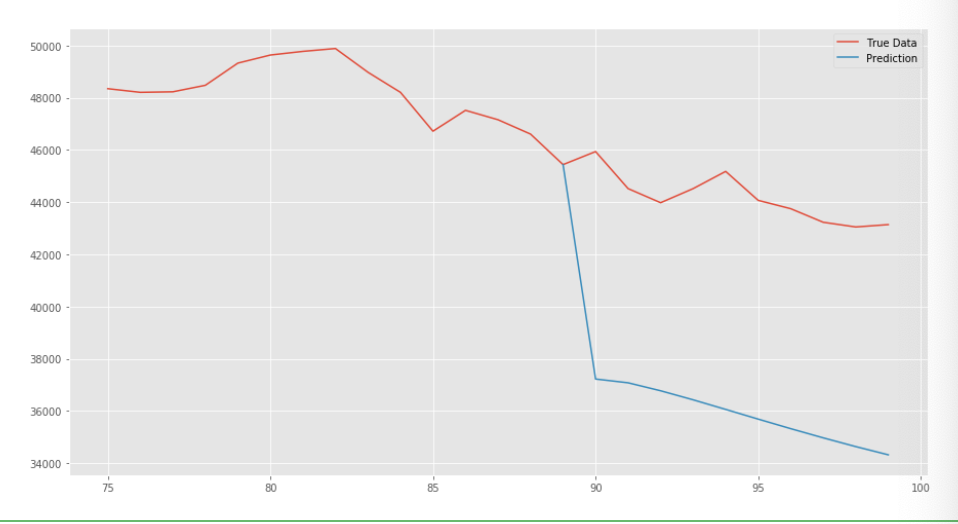
まとめ
・汎化する方法として、今まで出てきた「ドロップアウト」の他に、「EarlyStopping」というものも存在する。これは、精度が上がらなくなったら学習を自動でストップすることで過学習を防ぐというものである。
・過去n日のデータからある予測を行うモデルを作成するときは、データをnごとに切り分けるということを行い、モデルの入力サイズもそれに合わせる。
・数日後の株価予測など、より未来の時系列解析を行いたいときは、一日ごとの予測を繰り返すことでモデルを作成することができる。
今回は以上です。最後まで読んでいただき、ありがとうございました。