概要
@KSRG_Miyabi氏の、「キズナアイとねこますの声を入れ替える機械学習をした」を、Windows 10のコンピュータで動かしてみました。
(注:私は人工知能プログラミングについて、マトモな知識を持っていません。場当たり的操作で何とか動かしただけです。手順に不適切な点があるかもしれません。)
環境
ハードウェア
| 種類 | 説明 |
|---|---|
| CPU | Core i7 8700K |
| メモリ | 16GB |
| GPU | NVIDIA GTX 1080 8GB |
ソフトウェア
| 種類 | バージョン |
|---|---|
| OS | Windows 10 Pro 64bit 10.0.18362 |
| Python3 | 3.7.2 |
| Chainer | 6.2.0 |
| cupy-cuda101 | 6.2.0 |
| numpy | 1.17.0+mkl |
| scipy | 1.3.0 |
| CUDA | 10.1.105_418.96 |
環境構築
Pythonを入れる
Microsoft StoreでPython3.7をインストールした。
https://www.microsoft.com/store/productId/9NJ46SX7X90P
numpyが動かなかったのでインストールし直す
import numpyしたときに怒られました。
OSError: [WinError 193] %1 は有効な Win32 アプリケーションではありません。
「Python3.5 + NumPy + SciPy をWindows10にインストールして動かす」を参考にして、numpy‑1.17.0+mkl‑cp37‑cp37m‑win_amd64.whlをダウンロードしてpip installしました。
scipyを入れる…はずだが
インストールし直さなくても、import scipyできました。
Cupyを入れる
Cupyのdocを参考にして
- CUDA 10.1を入れる
-
pip uninstall cupyで最初から入ってるやつを削除 -
pip install cupy-cuda101でCUDA10.1用のcupyを入れる
Chainerを入れる…はずだが
インストールし直さなくても、import chainerできました。
以上で、環境構築が完了しました。
動かす
コードをダウンロード
Deep_VoiceChangerから、@KSRG_Miyabi氏のコードを落としてきます。
音声を準備
適当に2種類用意します。私は「VOICEROID 東北きりたん」と、私の声を準備しました。
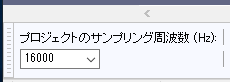
サンプリング周波数16kHzで書き出すのには、Audacityを使いました。「プロジェクトのサンプリング周波数」を16000にして書き出せばOKです。
きりたんを1_16.wav、私を2_16.wavとして、コードと同じディレクトリに保存しました。
プログラムに食わせて実行
一見すると、
python trainer.py -v 1_16.wav -w 2_16.wav
で動きそうですが、怒られます。
FileNotFoundError: [Errno 2] No such file or directory: '../src/KizunaAI_short.wav'
テスト用ファイル名のオプションを設定しないと、デフォルトでは../src/KizunaAI_short.wavが使われるようです。-s -uオプションも使って、
python trainer.py -v 1_16.wav -w 2_16.wav -s 1_16.wav -u 2_16.wav
とすると、うまく動きます。
ひたすら待つ
1.6 iters/secくらいの速度?が出ました。終了までの予想時間は16時間。学習データが5分と3分程度と、非常に少ないのが原因ですかね…
実行結果
1回の「epoch」が完了する毎に、resuitsフォルダに色々と出力されます。
previewに入っているのが、テスト用の音声を変換したものです。
imageの中身はFFTした画像かと思います。
追記
音声の変換
320epochほど回した後、音声の変換を試してみました。
テスト用の音声「test.wav」を、トレーニング用の音声と同じく、16kHzのモノラルで作成します。
その後、convertor.pyを実行します。
> python convertor.py
enter gpu number(if you have no gpu, enter -1)...0
enter netA path...results\generator_ab.npz
enter netB path...results\generator_ba.npz
enter wave path...test.wav
enter batch size...20
これで、3つのwavファイルが生成されました。

途中から再開
ある時点での結果を引き継いで学習を再開するには、
python trainer.py -i 200000 -r results\snapshot.npz -v k.wav -w t.wav -s k.wav -u t.wav
などと実行すればOKです。