オフセット250件の壁
Tumble APIのダッシュボードからポストを取得する、/user/dashboardメソッドには、ポストの取得位置を指定するoffsetパラメーターに250までしか効かないという困った制限がかかっている。「使えない」でもなく「指定出来ない」でもなくあくまで「効かない」。offsetに251以上の値を指定しても、「400 Bad Request」が発生するわけでもなくポストの取得が出来る。しかしoffsetパラメーターは無視され offset=0 扱いとなり、先頭からのポストが返却される。取得件数を指定するlimitパラメーターの最大値は20であるから普通にAPIを使っている限り、250 + 20で最大でも270件までしか取得出来ない。普通にAPIを使っている以上270件以上深く潜る事が出来ないのだ。これこそが世に言うTumblr APIの「オフセット250件の壁」である。
since_id予測法
オフセット250件の壁は、偉大な先人によって、since_idパラメーターを使った奇策でもって突破する方法がすでに編み出されている。誠に勝手ながらこの手法を「since_id予測法」と命名させて頂く。しかしながら私が以前にsince_id予測法を教示されたサイトは、WEBの荒波に揉まれたのか現在は見当たらないようである。このまま座視していればこの技術は失われる可能性が高い。私は今ここに、先人の教えをベースとし、私自身の経験から得た知見を加え公開したい。偉大な先人の叡智を本稿で後世に伝える事は、かつて教えを受けた我が身の義務であると確信している。
since_idパラメーターとは?
since_idパラメーターとは、/user/dashboardメソッドに指定可能なパラメーターで、指定したポストIDより 新しいポスト を取得出来るパラメーターである。offsetを指定してポストを取得する場合と、since_idを指定してポストを取得した場合を以下に示す。
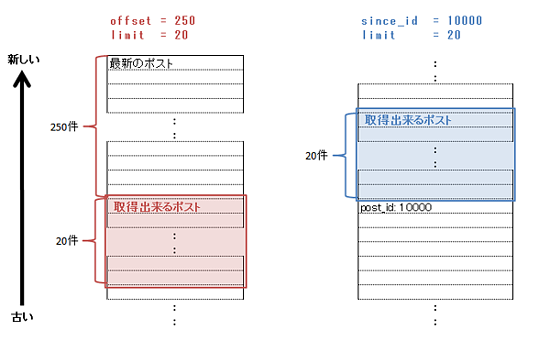
since_idパラメーターは、指定したポストIDより、古いポストではなく、新しいポストが返却されるために、より深く、より古く潜る用途には適していない。ページネーションにおける前のページの生成する際の利用を想定したパラメーターと思われる。
そのsince_idに関して、特記しておくべき特性がひとつある。since_idは、offset250件の制限の影響をまったく受けない。そのため、270件より以前のポストIDを指定しても、正常にそのポストから新しいポストが返却される。一週間前のポストIDを指定しても問題がなく、一ヶ月前、一年前のポストも指定可能である。また、自分のダッシュボードに存在しないIDを指定しても問題がない。仮にダッシュボードに post_id:100000 は存在しなく、post_id:100001 が存在している状態で、since_id=100000 を指定してもちゃんとpost_id:100001から20件のポストが返却される。
ポストIDについて
Tumblrは、一つ一つのポストに対してユニークなポストIDが付与されている。
http://foobar.tumblr.com/post/999999999999
例示したURLの「999999999999」となっている部分、これがポストIDである。ポストIDは英数字等を含まない単純な連番である。ユーザーごとの連番ではなく、すべてのユーザーで共通の連番のようである。そのため、あるユーザーがポストAとポストBという投稿をしたとして、ポストAとポストBの投稿の間に全世界で100個の投稿があった場合、ポストAのポストIDに、101を加算したIDがポストBに採用される。
since_id予測法 大戦略
since_idのoffset制限の影響を受けないという特性、およびポストIDが連番である程度予測可能であるという特性を活用することで、250件の壁は突破が可能となる。細かい条件分岐が実際には必要であるが、おおまかな大戦略は下記の通りである。
- APIは一度に20件取得出来るので、offset=240、limit=20で260件までoffset指定で取得する。(offset=250は20で割り切れず使いにくいので240で止める)
- 取得出来た260件から、1ポスト辺りでポストIDがどれだけ加算されるか(以下ポストID増分)を計算する
- 260件以降は、ポストID増分を使って現在の位置から+20件のポストIDを 予測 する
- 予測したポストIDをsince_idにセットしポストを取得する
- 以降は+20件のポストIDを予測して取得する事を繰り返して深く潜る
予測値の決定方法
offsetで取得可能出来る260件から、ポストID増分を計算する。最も単純な方法は、最初と最後のポストIDの差分を総ポスト数で除する事でポストID増分を得る。
ポストID増分 = (最初のポストID - 最後のポストID) / 総ポスト数
実際とかけ離れた異常値を排除するために、中央値を導入すると精度が増す可能性がある。例えば、APIを一回コールして20件を取得するたびに上記計算式に当てはめポストID増分を計算、260件までの13個のポストID増分から中央値を取る。
そうやって得たポストID増分から+20件の時のポストIDがどれだけ増えるかを計算し、260件までで最後に取得出来たポストIDから引くことで予測値を決定する。
+20件のポストIDの予測値 = 取得出来た最後のポストID - (ポストID増分 * 20)
予測値のズレによる条件分岐
since_idに指定するポストIDはあくまで予測値であるため、予測通りの20件が取得できる事は稀である。APIを実行した結果と予測とのズレによって処理を分岐させる必要がある。
ケース1:予測がショートした場合
予想に反して20件より手前のポストIDを指定してしまった場合。重複して取得したポストを破棄して、残ったポストを利用する。このケースに入ったと判別する方法は以下。
APIから返却された最初のポストID >= 前回までに取得出来た最後のポストID
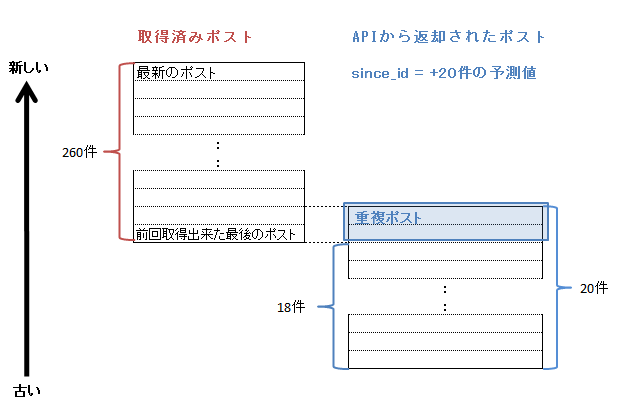
この例では、予測値が18件の位置だったために20件中2件のポストがすでに取得済みであって、新たに取得出来たポストは18件である。この場合重複している2件のポストを破棄し、新たに取得出来た18件のみを利用する。
ケース1-2:予測が大きくショートした場合
ケース1と同じく予測がショートした場合だが、重複ポストを除いた利用可能なポストがあきらかに少ない、もしくは一件も取得出来ない場合である。この場合予測値が大きく間違っている可能性が高い。そのため取得した情報を一旦破棄し予測値を修正し再度取得する。予測値の修正ロジックの例を以下に示す。
- 取得出来たポストが5件未満の場合、取得出来たポストを破棄して予測値を修正する
- ポストID増分*2で、再度予測値を計算しAPIをコール
- 5件以上取得出来るまで、破棄、ポストID増分*2で再計算、取得を繰り返す
- これを8回繰り返し、当初より256倍しても5件以上取得出来ない場合は処理を中断する(このダッシュボードにはこれ以上古いポストは存在しないと判断する)
ケース2-1:予測がオーバーしてしまった場合
予想に反して、20件より先のポストIDを指定しまった場合。その場合、APIから返却された最初のポストIDをsince_idにセットして再度APIをコールし、重複が発生するまで何度も同じ事を繰り返す。このケースに入ったと判別する方法は以下。
APIから返却された最初のポストID < 前回までに取得出来た最後のポストID
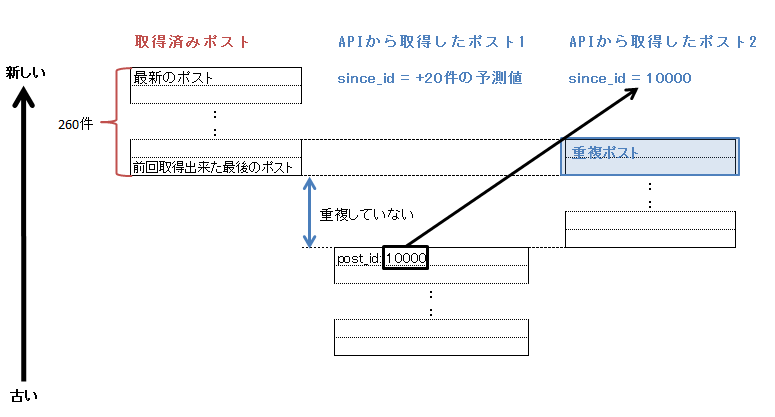
この例では、一回目のAPIコールでは重複ポストが発生せず取得出来ていないポストがある事がわかる。そのため取得したポストの最初のポストIDである "10000" をsince_idにセットし再度APIをコールしてポストを取得する。二度目のコールで重複ポストが発生したのでここで取得を止める。一回目、二回目の結果を連結し、かつ重複ポストを破棄して残りを利用する。二回分のポストを連結しているため取得出来たポストは20件より多くなる。
ケース2-2:予測が大きくオーバーしてしまった場合
ケース2と同じく予測がオーバーした場合だが、予測値が大きくオーバーしてしまい何度APIを再コールしても重複が発生せず延々と取得を繰り返している状態である。処理時間が異常にかかってしまうため何らかの対策を打つ必要がある。
ショートした場合と同様に、ポストを破棄、予測値を修正してやり直すという方法が考えらるがこの方法は推奨しない。例えば10回取得しても重複が発生しない場合に、ポストを破棄しポストID増分を2分の1としてやり直すというロジックとしたとする。この時2分の1にしても適切な予測になるとは限らず、延々10回取得→破棄→10回取得……と繰り返してしまう恐れがある。ここは、すっぱりと諦めて10回取得して重複が発生しない場合は、そこで取得を諦めるとしてしまった方がよい。取得するデータに欠損は生じるが、最大でも10回しかAPIをコールしないため、処理時間が異常にかかるという事はなくなる。
ポストID増分の修正
最初のポストID増分は、offsetパラメーターを指定して取得した260件から算出する。しかしずっと最初に算出したポストID増分を使い続けるのはナンセンスである。初回の260件のポストに偏りがあった可能性もあるし、また他のユーザーの投稿数に左右されるためポストID増分の最適値は時間と共に変化する。直近のAPIをコールした結果から常にポストID増分は再計算するべきである。ロジックの例は以下。
ポストID増分 = 中央値(直近15回分のAPIコールのポストID増分実績)
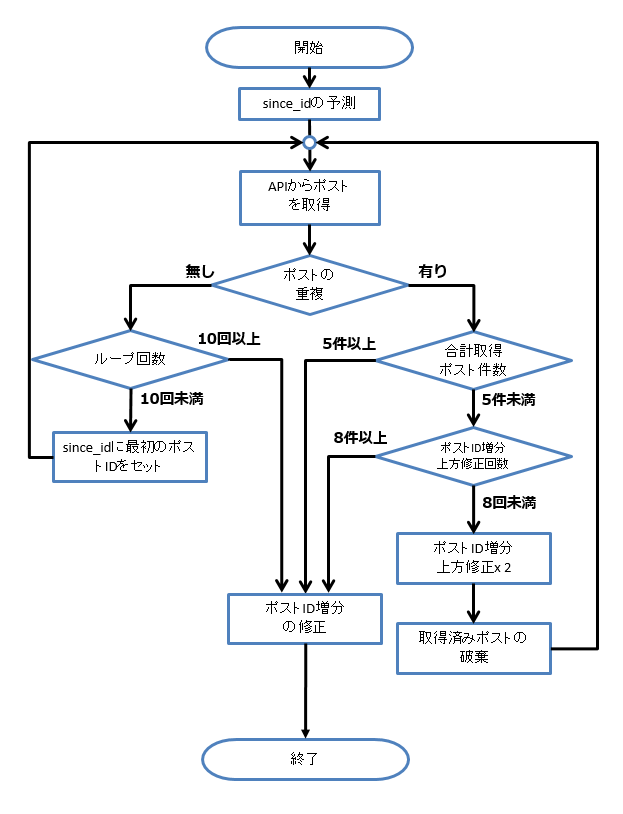
処理のフローチャート
since_id予測法の処理フローチャートを次に示す。
おわりに
Tumblrそのものは世界で最も美しいサービスであるが、一方でTumblr APIは世界で最も美しいAPIとはなれていない。例えば、Tumblr APIのドキュメントが雑で、offsetの制限についても書かれていないし、レスポンスデータについて説明がされてない項目があるため、実際に返ってくるデータから類推を強いられざるを得ない。また、APIから返却されるデータに驚かされる事も多い。何故か特定画像だけ403エラーでアクセス出来なかったり、縦に画像が3枚というレイアウトのはずなのに、画像のデータが2枚しか返ってこなかったりする。
Tumblrにおいてサードパーティーアプリケーションが今ひとつ盛り上がらない原因はTumblr APIの不備にこそあるのではと私は考えている。Tumblr APIの不備の中で最も致命的であるオフセット250件の壁の解決策としてsince_id予測法を本稿で示す事で、少しでもTumblr APIの利用が進み、Tumblr界全体の活性化に繋がる事を願ってやまない。世界一美しいサービスがAPIごときの不備によって足を引っ張られる事なぞあってはならないのだ。
※ 2016/09/04追記:
ドキュメントに無い「before_id」パラメータを利用すれば、この記事の方法を使わなくても270件以上深る事が出来るようです。before_idは、since_idの逆で指定したIDより古いポストを取得出来ます。つまり、offsetを指定して取得してから、最後のポストのIDをbefore_idに指定すれば延々と潜る事が出来ます。
但し、なぜかbefore_idはAPIドキュメントに記載されていません。つまり、使えるは使えるのですが、果たして使っていいものか判然としません。使えるなら何でもいいやという場合はbefore_idを、公式なものしか使いたく無い場合は、この記事のsince_idを使ったやり方をされるといいかと。